本文提供記錄傳送佇列相關問題的解決方法。
什麼是記錄傳送佇列?
對主要複本上可用性群組資料庫所做的變更,會INSERTUPDATEDELETE寫入事務歷史記錄,並傳送至可用性群組次要複本。 記錄 傳送佇列 會定義尚未傳送至次要複本之主資料庫的記錄檔中的記錄檔記錄數目。
記錄傳送佇列的徵兆和效果
記錄傳送佇列會儲存所有易受攻擊的數據
如果主要複本在突然災害中遺失,而且您故障轉移至尚未抵達這些變更的次要複本,這些變更將不會出現在資料庫的新主要複本複本中。 這會排除執行完整資料庫和記錄備份時所儲存的任何變更。
成長記錄傳送佇列會導致事務歷史記錄檔成長
對於可用性群組中定義的資料庫,Microsoft SQL Server 必須在主要復本保留尚未傳遞至次要複本之事務歷史記錄中的所有交易。 記錄傳送佇列代表在一般記錄截斷事件期間無法截斷之主要復本的記錄變更數量(例如,在資料庫記錄備份期間)。 大型且成長的記錄傳送佇列可能會耗盡裝載資料庫記錄檔的磁碟驅動器可用空間,或超過設定的事務歷史記錄檔大小上限。 如需詳細資訊,請參閱 事務歷史記錄大型時的錯誤 9002。
各種診斷功能報告可用性群組記錄傳送佇列
SQL Server Management Studio 中的 AlwaysOn 儀錶板會報告記錄傳送佇列。 它可能會報告可用性群組狀況不良。
如何檢查記錄傳送佇列
記錄傳送佇列是每個資料庫度量。 您可以在主要複本上使用 Always On 儀錶板,或使用 主要或次要複本上的 sys.dm_hadr_database_replica_states 動態管理檢視 (DMV) 來檢查此值。 效能監視器 計數器可用來檢查次要複本的記錄傳送佇列。
接下來的幾個區段提供方法來主動監視可用性群組資料庫記錄傳送佇列。
查詢sys.dm_hadr_database_replica_state
DMV 會 sys.dm_hadr_database_replica_states 報告每個可用性群組資料庫的數據列。 該報表中的一個資料列是 log_send_queue_size。 此值是以 KB 為單位的記錄傳送佇列大小。 您可以設定查詢,例如下列查詢,以監視記錄傳送佇列大小中的任何趨勢。 查詢會在主要複本上執行。 它會使用 is_local=0 述詞來報告次要複本的數據,其中 log_send_queue_size 和 log_send_rate 是相關的。
WHILE 1=1
BEGIN
SELECT drcs.database_name, ars.role_desc, drs.log_send_queue_size, drs.log_send_rate,
ars.recovery_health_desc, ars.connected_state_desc, ars.operational_state_desc, ars.synchronization_health_desc, *
FROM sys.dm_hadr_availability_replica_states ars JOIN sys.dm_hadr_database_replica_cluster_states drcs ON ars.replica_id=drcs.replica_id
JOIN sys.dm_hadr_database_replica_states drs ON drcs.group_database_id=drs.group_database_id
WHERE ars.role_desc='SECONDARY' AND drs.is_local=0
waitfor delay '00:00:30'
END
輸出看起來像這樣。

在AlwaysOn儀錶板中檢閱記錄傳送佇列
若要檢閱記錄傳送佇列,請遵循下列步驟:
在 SQL Server Management Studio (SSMS) 中開啟 AlwaysOn 儀錶板,方法是以滑鼠右鍵按兩下 SSMS 中的可用性群組 物件總管。
選取 [ 顯示儀錶板]。
可用性群組資料庫會列出最後一個,而且有一些資料庫報告的數據。 雖然 預設未列出記錄傳送佇列大小 (KB) 和 記錄傳送速率 (KB/秒), 但您可以將它們新增至此檢視,如下一個步驟中的螢幕快照所示。
若要新增這些資料列,請以滑鼠右鍵按鍵按下可用性群組資料庫資料列標頭,然後從可用資料列清單中選取 。
若要 新增記錄傳送佇列大小,請在下列螢幕快照中以紅色醒目提示的標頭上按下滑鼠右鍵。
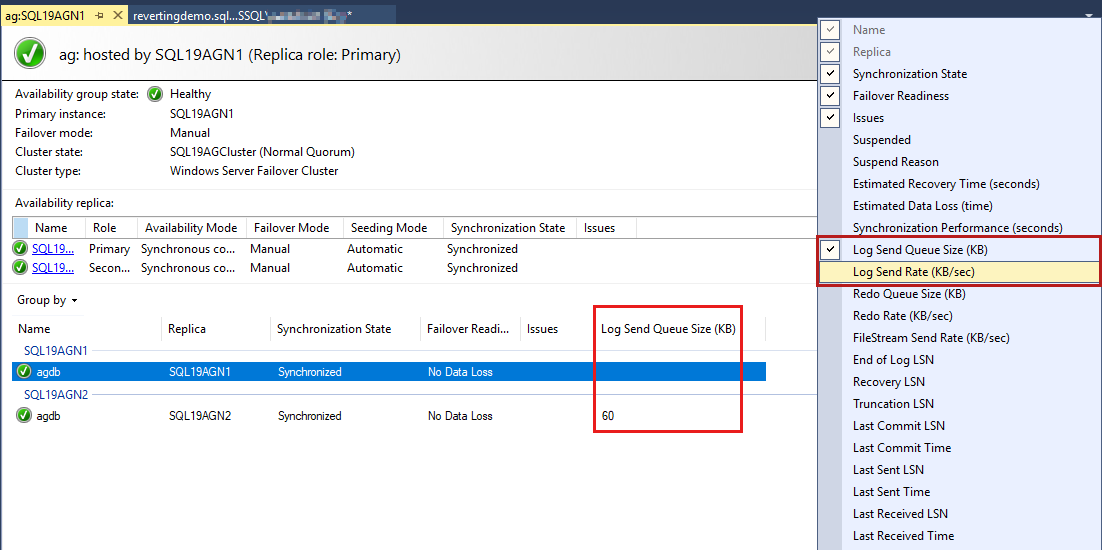
根據預設,AlwaysOn 儀錶板會每隔 60 秒自動重新整理此數據。
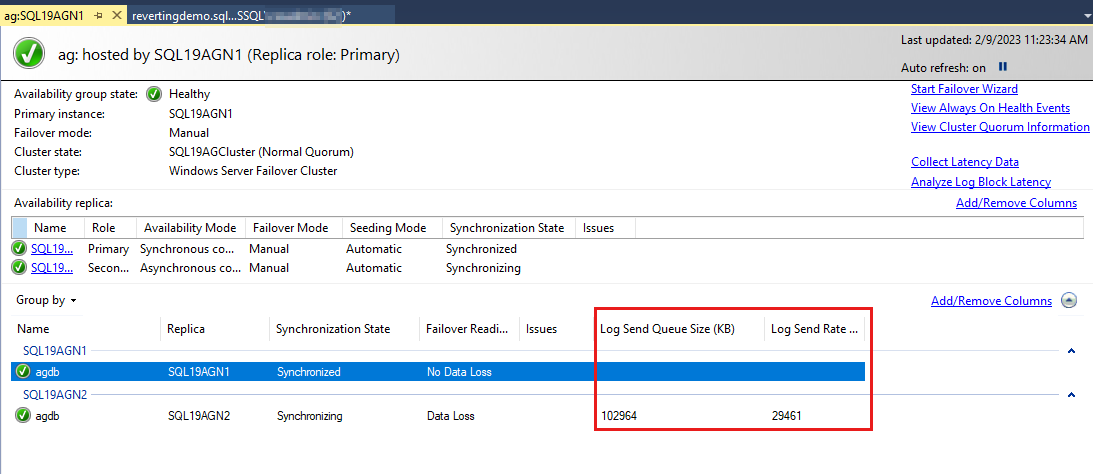


檢閱 效能監視器 中的記錄傳送佇列
記錄傳送佇列是每個次要復本資料庫特有的。 因此,若要檢閱可用性群組資料庫的記錄傳送佇列,請遵循下列步驟:
在次要復本上開啟 效能監視器。
選取 [ 新增 ][計數器] 按鈕。
在 [可用的計數器] 下,選取 [SQLServer:Database 複本] 和 [記錄傳送佇列計數器]。
在 [ 實例 ] 列表框中,選取您要檢查記錄傳送佇列的可用性群組資料庫。
選取 [新增] 和 [確定]。
以下是增加記錄傳送佇列的外觀。
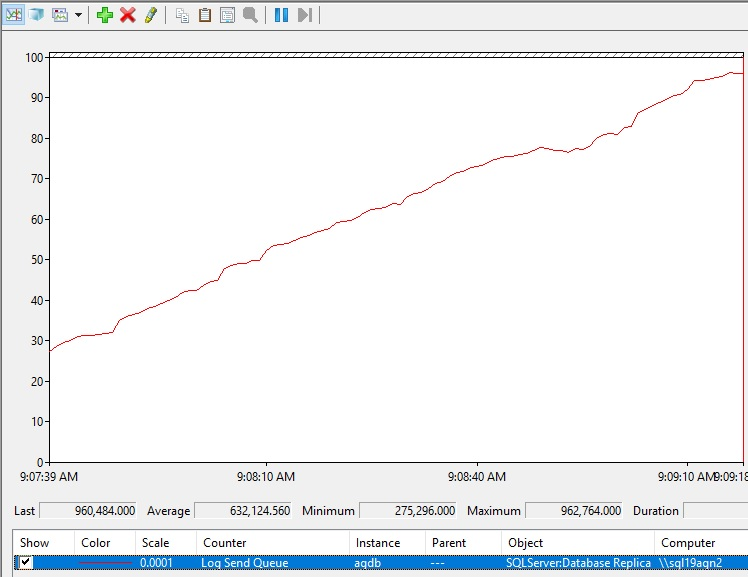

解譯記錄傳送佇列值
本節說明如何解譯記錄傳送佇列大小的值。
記錄傳送佇列何時不正確? 應該容許多少記錄傳送佇列?
您可能會假設如果記錄傳送佇列報告值為 0,這表示該報表時不會發生任何記錄傳送佇列。 不過,當生產環境忙碌時,您應該預期會觀察記錄傳送佇列經常報告零以外的值,即使在狀況良好的 AlwaysOn 環境中也一樣。 在一般生產期間,您應該預期此值會在 0 與非零值之間波動。
如果您觀察到隨著時間增加記錄傳送佇列,則會需要進一步調查。 此額外活動表示某個項目已變更。 如果您在記錄傳送佇列中觀察到突然成長,下列度量有助於進行疑難解答:
- 記錄傳送速率 (KB/秒) (AlwaysOn 儀錶板)
- sys.dm_hadr_database_replica_states (DMV)
- 資料庫複本::鏡像交易/秒(效能監視器)
取得記錄傳送速率和鏡像交易/秒的基準速率
在狀況良好的 AlwaysOn 效能期間,監視 忙碌可用性群組資料庫的記錄傳送速率 和 鏡像交易/秒 值。 在通常忙碌的上班時間里,他們看起來會是什麼樣子? 在維護期間,當大型交易驅動系統上較高的交易輸送量時,它們看起來會是什麼樣子? 當您觀察記錄傳送佇列成長時,您可以比較這些值,以協助判斷變更的內容。 工作負載可能大於一般。 如果記錄傳送速率低於平常,可能需要進一步調查來判斷原因。
工作負載磁碟區很重要
當您有大型工作負載(例如 UPDATE 針對1百萬個數據列的語句、在1 TB資料表上重建索引,甚至是插入數百萬個數據列的ETL批次),您應該會看到一些記錄傳送佇列成長,無論是立即還是一段時間。 當可用性群組資料庫中突然進行大量變更時,這是預期的。
如何診斷記錄傳送佇列
識別特定可用性群組資料庫的記錄傳送佇列之後,您應該檢查問題的幾個可能根本原因,如下列各節所述。
重要
如需有意義的等候類型輸出,請使用您在監視下列條件時,使用前幾節所述的其中一種方法,檢查記錄傳送佇列是否增加。
系統太忙碌
檢查主要複本上的工作負載是否多載系統的CPU。 如果您看到記錄傳送佇列增加,請查詢 sys.dm_os_schedulers DMV 並監視 high runnable_tasks_count。 此計數表示當時執行的未完成工作。
SELECT scheduler_address, scheduler_id, cpu_id, status, current_tasks_count, runnable_tasks_count, current_workers_count, active_workers_count
FROM sys.dm_os_schedulers
下表是結果範例。 值增加 runnable_tasks_count 表示大量工作正在等候 CPU 時間。
| scheduler_address | scheduler_id | cpu_id | status | current_tasks_count | runnable_tasks_count | current_workers_count | active_workers_count |
|---|---|---|---|---|---|---|---|
| 0x000002778D 200040 | 0 | 0 | VISIBLE OFFLINE | 1 | 0 | 2 | 1 |
| 0x000002778D 220040 | 1 | 1 | 線上可見 | 108 | 12 | 115 | 107 |
| 0x000002778D 240040 | 2 | 2 | 線上可見 | 113 | 2 | 123 | 113 |
| 0x000002778D 260040 | 3 | 3 | 線上可見 | 105 | 11 | 116 | 105 |
| 0x000002778D 480040 | 4 | 4 | 線上可見 | 108 | 15 | 117 | 108 |
| 0x000002778D 4A0040 | 5 | 5 | 線上可見 | 100 | 25 | 110 | 99 |
| 0x000002778D 4C0040 | 6 | 6 | 線上可見 | 105 | 23 | 113 | 105 |
| 0x000002778D 4E0040 | 7 | 7 | 可見 | 109 | 25 | 116 | 109 |
| 0x000002778D 700040 | 8 | 8 | 線上可見 | 98 | 10 | 112 | 98 |
| 0x000002778D 720040 | 9 | 9 | 線上可見 | 114 | 1 | 130 | 114 |
| 0x000002778D 740040 | 10 | 10 | 線上可見 | 110 | 25 | 120 | 110 |
| 0x000002778D 760040 | 11 | 11 | 線上可見 | 83 | 8 | 93 | 83 |
| 0x000002778D A00040 | 12 | 12 | 線上可見 | 104 | 4 | 117 | 104 |
| 0x000002778D A20040 | 13 | 13 | 線上可見 | 108 | 32 | 118 | 108 |
| 0x000002778D A40040 | 14 | 14 | 線上可見 | 102 | 12 | 113 | 102 |
| 0x000002778D A60040 | 15 | 15 | 線上可見 | 104 | 16 | 116 | 103 |
解決方案:如果您偵測到高 runnable_task_count,請減少系統上的工作負載,或增加系統可用的CPU數目。
網路延遲
如果次要複本與主要複本實際遠端,這種情況特別常見。 多月臺可用性群組可讓客戶跨多個月臺部署商務數據複本,以進行災害復原和報告。 這可讓遠端位置的生產數據復本使用近乎即時的變更。
如果次要複本裝載於遠離主要複本,記錄傳送佇列可能是網路等待時間所造成,而且無法儘快將變更傳送至遠端次要複本,因為它們是在主要複本資料庫中產生。
重要
SQL Server 會使用單一連線,將主要複本的變更同步處理至次要複本。 因此,如果次要複本是遠端的,管道的寬度不會影響 SQL Server 可以傳送多少數據。 相反地,此數量更取決於管道中的網路等待時間(連線速度)。
測試網路等待時間
檢查流量控制設定是否有助於網路等待時間
Microsoft SQL Server 可用性群組使用流量控制網關,以避免在所有可用性複本上過度耗用網路資源、記憶體和其他資源。 這些流量控制網關不會影響可用性復本的同步處理健康情況狀態。 不過,它們可能會影響可用性資料庫的整體效能,包括 RPO。
較新版本的 SQL Server 會變更輸入流量控制的臨界值。 這有助於減輕流量控制對記錄傳送佇列等徵兆的影響。 如需流量控制及流量控制閾值變更歷程記錄的詳細資訊,請參閱 流量控制網關。
您可以使用 效能監視器 來擷取主要複本上的數據,以監視流程控制。 若要監視資料庫流程控制,請新增 SQLServer:Database Replica 計數器,然後選取 [資料庫流程控制延遲] 和 [資料庫流程控制/秒] 計數器。 在 [ 實例 ] 對話框中,選取您要檢查資料庫流程控制的可用性群組資料庫。 若要偵測及監視可用性複本流量控制,請新增 SQLServer:Availability Replica 計數器,然後選取 [流程控制時間] (ms/sec) 和 Flow Control/sec 計數器。
檢查壅塞 Windows 重新啟動是否會導致網路等待時間
將壅塞 Windows 重新啟動 TCP 設定設為 True,即可觸發導致記錄傳送佇列的網路效能問題。 這是 Windows Server 2016 中的預設設定。 請確定 壅塞視窗重新啟動 在觀察到記錄傳送佇列的 Windows 伺服器上裝載可用性群組複本的 Windows 伺服器上設定為 False 。
PS C:\WINDOWS\system32> Get-NetTCPSetting | Select SettingName, CwndRestart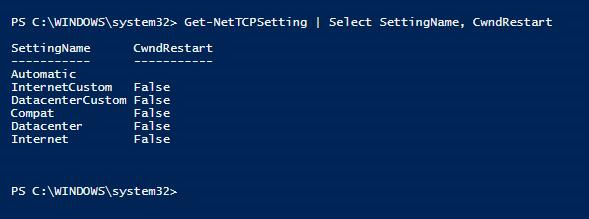
如需如何將 TCP 壅塞 Windows 重新啟動屬性設定為 False 的詳細資訊,請參閱 Set-NetTCPSetting (NetTCPIP) 。
另請參閱 監視 AlwaysOn 可用性群組 的效能,以取得同步處理程式的相關信息。 本文也會說明如何計算一些關鍵計量,並提供一些常見效能疑難解答案例的連結。
使用 ping 來取得延遲範例
在 node1 (主要複本) 的命令行上,ping node2 (次要複本):
C:\Users\customer>ping node2 Pinging node2.customer.corp.company.com [<ip address>] with 32 bytes of data: Reply from 2001:4898:4018:3005:25f3:d931:2507:e353: time=94ms Reply from 2001:4898:4018:3005:25f3:d931:2507:e353: time=97ms Reply from 2001:4898:4018:3005:25f3:d931:2507:e353: time=94ms Reply from 2001:4898:4018:3005:25f3:d931:2507:e353: time=119ms Ping statistics for 2<ip address>: Packets: Sent = 4, Received = 4, Lost = 0 (0% loss), Approximate round trip times in milli-seconds: Minimum = 94ms, Maximum = 119ms, Average = 101ms使用獨立工具測試從主要到次要的網路輸送量
使用 NTttcp 之類的工具,使用單一連線獨立偵測主要和次要複本之間的網路輸送量。 網路等待時間是記錄傳送佇列的常見原因。 下列步驟示範如何使用 NTttcp 之類的獨立工具來測量網路輸送量。
重要
SQL Server 會使用單一連接,將主要複本的變更傳送至次要複本。 在下一節中,我們會設定並執行 NTttcp ,以使用單一連線(與 SQL Server 相同方式)來準確地比較輸送量。
您可以從 Github 下載 NTttcp - microsoft/ntttcp。
若要執行 NTttcp,請遵循下列步驟:
下載工具並將其複製到主要和次要 SQL Server 伺服器。
在次要復本伺服器上,開啟提升許可權的命令提示字元視窗,將目錄變更為 NTttcp 工具資料夾,然後執行下列命令:
ntttcp.exe -r -m 1,0,<secondaryipaddress>-a 16 -t 60注意
在此命令中,
<secondaryipaddress>是次要複本伺服器實際IP位址的佔位元元。在主要復本伺服器上,開啟提升許可權的命令提示字元視窗,將目錄變更為 NTttcp 工具資料夾,然後再次指定次要複本伺服器的實際 IP 位址來執行下列命令:
ntttcp.exe -s -m 1,0,<secondaryipaddress>-a 16 -t 60下列螢幕快照顯示在次要和主要複本上執行的 NTttcp。 由於網路等待時間,此工具只能傳送 739 KB/秒的數據。 這就是您可以預期 SQL Server 能夠傳送的內容。
次要復本上的 NTttcp
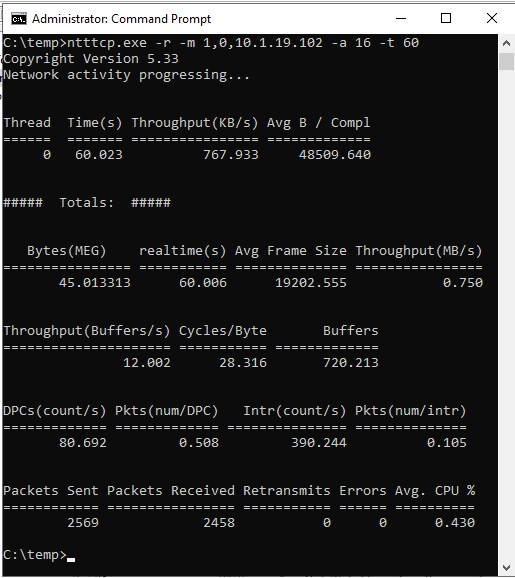
主要復本上的 NTttcp
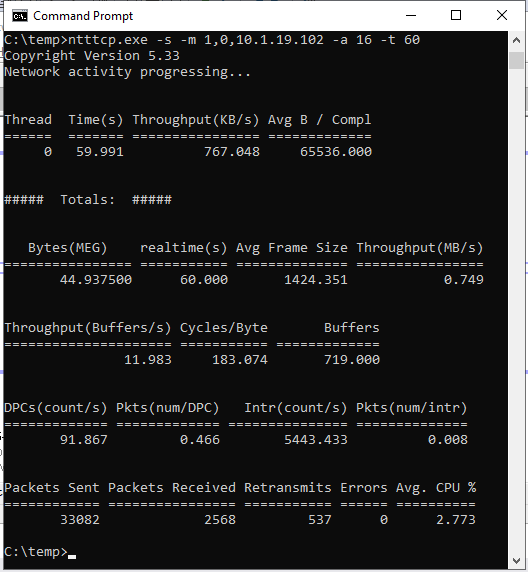
檢閱 效能監視器 計數器
確認 NTttcp 報告的內容。 大型交易會在主要複本上的 SQL Server 中執行。 在主要復本上啟動 效能監視器 之後,請新增網路介面::Bytes Sent/sec 計數器。 此計數器會確認主要複本可以傳送大約 777 KB/秒的數據。 這類似於 NTttcp 測試所報告的 739 KB/秒值。

比較主要復本上 SQL Server::D atabases::Log Bytes Flushed/sec 值與次要複本上相同資料庫的 SQL Server::D atabase Replica::Log Bytes Received/sec 也很有用。 平均而言,我們觀察到在 「agdb」 資料庫中建立的變更大約 20 MB/秒。 不過,次要復本平均只會接收 5.4 MB 的變更。 這會導致資料庫事務歷史記錄中尚未傳送至次要複本之未完成變更之主要複本上的記錄傳送佇列。
“agdb” 資料庫的主要復本記錄位元組 Flushed/sec

資料庫 agdb 的次要複本記錄檔位元組接收/秒
