適用於:SQL Server
本文提供在執行 Microsoft SQL Server 的電腦上診斷和修正高 CPU 使用率所造成之問題的程式。 雖然在 SQL Server 中發生高 CPU 使用率的可能原因有很多,但下列是最常見的原因:
- 數據表或索引掃描所造成的高邏輯讀取,原因如下:
- 過期的統計資料
- 遺漏索引。
- 參數敏感性計畫 (PSP) 問題
- 設計不良的查詢
- 工作負載增加
您可以使用下列步驟,針對 SQL Server 中的高 CPU 使用率問題進行疑難排解。
步驟 1:確認 SQL Server 造成高 CPU 使用率
使用下列其中一個工具來檢查 SQL Server 程式是否真的造成高 CPU 使用率:
任務管理員:在 [行程] 索引標籤上,檢查 SQL Server Windows NT-64 位的 CPU 資料行值是否接近 100%。
效能和資源監視器 (效能)
- 計數器:
Process/%User Time,% Privileged Time - 執行個體:sqlservr
- 計數器:
您可以使用下列 PowerShell 指令碼來收集超過 60 秒範圍的計數器資料:
$serverName = $env:COMPUTERNAME $Counters = @( ("\\$serverName" + "\Process(sqlservr*)\% User Time"), ("\\$serverName" + "\Process(sqlservr*)\% Privileged Time") ) Get-Counter -Counter $Counters -MaxSamples 30 | ForEach { $_.CounterSamples | ForEach { [pscustomobject]@{ TimeStamp = $_.TimeStamp Path = $_.Path Value = ([Math]::Round($_.CookedValue, 3)) } Start-Sleep -s 2 } }如果
% User Time持續大於 90%(% 使用者時間是每個處理器的處理器時間總和,其最大值為 100% * (無 CPU),SQL Server 進程會造成高 CPU 使用量。 不過,如果% Privileged time持續大於 90%,則您的防毒軟體、其他驅動程式或電腦上的其他 OS 元件會造成高 CPU 使用率。 您應該與系統管理員合作,以分析此行為的根本原因。效能儀錶板:在 SQL Server Management Studio 中,以滑鼠右鍵按兩下 <>],然後選取 [效能儀錶板]。
儀錶板說明標題為 系統CPU使用率 與條形圖的圖表。 較深的色彩表示 SQL Server 引擎 CPU 使用率,而較淺的色彩代表整體操作系統 CPU 使用率(請參閱圖表上的圖例以取得參考)。 選取迴圈重新整理按鈕或 F5 以查看更新的使用率。
步驟 2:識別造成 CPU 使用率的查詢
Sqlservr.exe如果進程造成高 CPU 使用量,到目前為止,最常見的原因是執行數據表或索引掃描的 SQL Server 查詢,後面接著排序和哈希作業和迴圈(巢狀循環運算符或 WHILE (T-SQL))。 若要瞭解查詢目前使用多少 CPU,請在整體 CPU 容量中執行下列語句:
DECLARE @init_sum_cpu_time int,
@utilizedCpuCount int
--get CPU count used by SQL Server
SELECT @utilizedCpuCount = COUNT( * )
FROM sys.dm_os_schedulers
WHERE status = 'VISIBLE ONLINE'
--calculate the CPU usage by queries OVER a 5 sec interval
SELECT @init_sum_cpu_time = SUM(cpu_time) FROM sys.dm_exec_requests
WAITFOR DELAY '00:00:05'
SELECT CONVERT(DECIMAL(5,2), ((SUM(cpu_time) - @init_sum_cpu_time) / (@utilizedCpuCount * 5000.00)) * 100) AS [CPU from Queries as Percent of Total CPU Capacity]
FROM sys.dm_exec_requests
若要識別目前負責高 CPU 活動的查詢,請執行下列語句:
SELECT TOP 10 s.session_id,
r.status,
r.cpu_time,
r.logical_reads,
r.reads,
r.writes,
r.total_elapsed_time / (1000 * 60) 'Elaps M',
SUBSTRING(st.TEXT, (r.statement_start_offset / 2) + 1,
((CASE r.statement_end_offset
WHEN -1 THEN DATALENGTH(st.TEXT)
ELSE r.statement_end_offset
END - r.statement_start_offset) / 2) + 1) AS statement_text,
COALESCE(QUOTENAME(DB_NAME(st.dbid)) + N'.' + QUOTENAME(OBJECT_SCHEMA_NAME(st.objectid, st.dbid))
+ N'.' + QUOTENAME(OBJECT_NAME(st.objectid, st.dbid)), '') AS command_text,
r.command,
s.login_name,
s.host_name,
s.program_name,
s.last_request_end_time,
s.login_time,
r.open_transaction_count
FROM sys.dm_exec_sessions AS s
JOIN sys.dm_exec_requests AS r ON r.session_id = s.session_id CROSS APPLY sys.Dm_exec_sql_text(r.sql_handle) AS st
WHERE r.session_id != @@SPID
ORDER BY r.cpu_time DESC
如果查詢目前並未驅動 CPU,您可以執行下列語句來尋找歷程記錄的 CPU 系結查詢:
SELECT TOP 10 qs.last_execution_time, st.text AS batch_text,
SUBSTRING(st.TEXT, (qs.statement_start_offset / 2) + 1, ((CASE qs.statement_end_offset WHEN - 1 THEN DATALENGTH(st.TEXT) ELSE qs.statement_end_offset END - qs.statement_start_offset) / 2) + 1) AS statement_text,
(qs.total_worker_time / 1000) / qs.execution_count AS avg_cpu_time_ms,
(qs.total_elapsed_time / 1000) / qs.execution_count AS avg_elapsed_time_ms,
qs.total_logical_reads / qs.execution_count AS avg_logical_reads,
(qs.total_worker_time / 1000) AS cumulative_cpu_time_all_executions_ms,
(qs.total_elapsed_time / 1000) AS cumulative_elapsed_time_all_executions_ms
FROM sys.dm_exec_query_stats qs
CROSS APPLY sys.dm_exec_sql_text(sql_handle) st
ORDER BY(qs.total_worker_time / qs.execution_count) DESC
步驟 3:更新統計資料
識別 CPU 耗用量最高的查詢之後, 請對這些查詢所使用之資料表的統計資料進行更新。 您可以使用 sp_updatestats 系統預存程序來更新目前資料庫中所有使用者定義和內部資料表的統計資料。 例如:
exec sp_updatestats
注意
sp_updatestats 系統 預存程序會針對目前資料庫中的所有使用者定義和內部資料表執行 UPDATE STATISTICS。 針對定期維護,請確保定期排程維護會將統計資料保持在最新狀態。 利用自適性索引子磁碟重組等解決方案,為一或多個資料庫自動管理索引重組以及統計資料更新。 這項程序會根據索引分散程度與其他參數,自動選擇要進行重建或是重新組織索引,並以線性閾值更新統計資料。
如需有關 sp_updatestats 的詳細資訊,請參閱 sp_updatestats。
如果 SQL Server 仍然使用過多的 CPU 容量,請移至下一個步驟。
步驟 4:新增遺漏的索引
遺漏索引可能會導致執行中的查詢變慢,且 CPU 使用率偏高。 您可以識別遺漏的索引並加以建立,以協助改善此效能影響。
執行下列查詢,以識別導致高 CPU 使用率且在查詢計劃中至少包含一個遺漏索引的查詢:
-- Captures the Total CPU time spent by a query along with the query plan and total executions SELECT qs_cpu.total_worker_time / 1000 AS total_cpu_time_ms, q.[text], p.query_plan, qs_cpu.execution_count, q.dbid, q.objectid, q.encrypted AS text_encrypted FROM (SELECT TOP 500 qs.plan_handle, qs.total_worker_time, qs.execution_count FROM sys.dm_exec_query_stats qs ORDER BY qs.total_worker_time DESC) AS qs_cpu CROSS APPLY sys.dm_exec_sql_text(plan_handle) AS q CROSS APPLY sys.dm_exec_query_plan(plan_handle) p WHERE p.query_plan.exist('declare namespace qplan = "http://schemas.microsoft.com/sqlserver/2004/07/showplan"; //qplan:MissingIndexes')=1檢閱所識別查詢的執行計畫,並藉由進行必要的變更來微調查詢。 下列螢幕擷取畫面顯示 SQL Server 會指出查詢的遺漏索引的範例。 以滑鼠右鍵按一下查詢計劃的 [遺漏索引] 部分,然後選取 [遺漏索引詳細資料] 以在 SQL Server Management Studio 中的另一個視窗中建立索引。
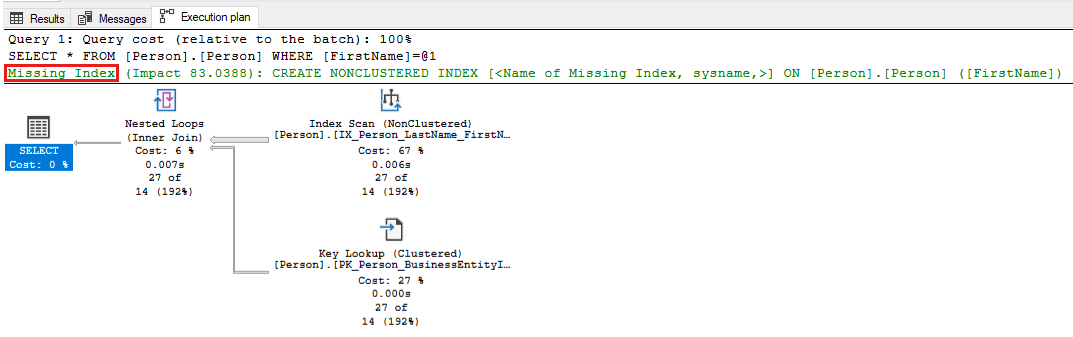
使用下列查詢來檢查遺漏的索引,並套用任何具有高改善量值的建議索引。 從具有最高 improvement_measure 值的輸出中的前 5 或 10 個建議開始。 這些索引對效能有最重要的正面影響。 決定是否要套用這些索引,並確定已針對應用程式完成效能測試。 然後,繼續套用遺漏索引建議,直到您達到所需的應用程式效能結果為止。 如需本主題的詳細資訊,請參閱 使用遺漏的索引建議來微調非叢集索引。
SELECT CONVERT(VARCHAR(30), GETDATE(), 126) AS runtime, mig.index_group_handle, mid.index_handle, CONVERT(DECIMAL(28, 1), migs.avg_total_user_cost * migs.avg_user_impact * (migs.user_seeks + migs.user_scans)) AS improvement_measure, 'CREATE INDEX missing_index_' + CONVERT(VARCHAR, mig.index_group_handle) + '_' + CONVERT(VARCHAR, mid.index_handle) + ' ON ' + mid.statement + ' (' + ISNULL(mid.equality_columns, '') + CASE WHEN mid.equality_columns IS NOT NULL AND mid.inequality_columns IS NOT NULL THEN ',' ELSE '' END + ISNULL(mid.inequality_columns, '') + ')' + ISNULL(' INCLUDE (' + mid.included_columns + ')', '') AS create_index_statement, migs.*, mid.database_id, mid.[object_id] FROM sys.dm_db_missing_index_groups mig INNER JOIN sys.dm_db_missing_index_group_stats migs ON migs.group_handle = mig.index_group_handle INNER JOIN sys.dm_db_missing_index_details mid ON mig.index_handle = mid.index_handle WHERE CONVERT (DECIMAL (28, 1), migs.avg_total_user_cost * migs.avg_user_impact * (migs.user_seeks + migs.user_scans)) > 10 ORDER BY migs.avg_total_user_cost * migs.avg_user_impact * (migs.user_seeks + migs.user_scans) DESC

步驟 5:調查並解決參數敏感性問題
您可以使用 DBCC FREEPROCCACHE 命令來釋放計畫快取,並檢查這是否可解決高 CPU 使用率問題。 如果問題已修正,表示這是參數敏感性問題 (PSP,也稱為「參數探查問題」) 。
注意
使用不含參數的 DBCC FREEPROCCACHE 會從計畫快取中移除所有已編譯的計畫。 這會導致重新編譯新的查詢執行,這會導致每個新查詢的持續時間延長一次。 最佳方法是使用 DBCC FREEPROCCACHE ( plan_handle | sql_handle ) 來識別哪些查詢可能造成問題,然後解決該個別查詢或查詢。
若要緩解敏感參數問題,請使用下列步驟: 每個方法都有相關聯的取捨和缺點。
使用 RECOMPILE 查詢提示。 您可以新增
RECOMPILE查詢提示至 步驟 2中識別的一或多個高 CPU 查詢。 此提示有助於平衡編譯 CPU 使用量稍微增加與每個查詢執行的最佳效能。 如需詳細資訊,請參閱 參數和執行計畫重複使用、 參數敏感度 和 RECOMPILE 查詢提示。以下是如何將此提示套用至查詢的範例。
SELECT * FROM Person.Person WHERE LastName = 'Wood' OPTION (RECOMPILE)使用 OPTIMIZE FOR 查詢提示,以涵蓋資料中大部分值的較一般參數值覆寫實際參數值。 此選項需要完全瞭解最佳參數值和相關聯的計畫特性。 以下是如何在查詢中使用此提示的範例。
DECLARE @LastName Name = 'Frintu' SELECT FirstName, LastName FROM Person.Person WHERE LastName = @LastName OPTION (OPTIMIZE FOR (@LastName = 'Wood'))使用 OPTIMIZE FOR UNKNOWN 查詢提示,以密度向量平均值覆寫實際參數值。 您也可以藉由擷取區域變數中的傳入參數值,然後在述詞內使用區域變數,而不是使用參數本身來執行此動作。 針對此修正,平均密度可能足以提供可接受的效能。
使用 DISABLE_PARAMETER_SNIFFING 查詢提示來完全停用參數探查。 以下是如何在查詢中使用它的範例:
SELECT * FROM Person.Address WHERE City = 'SEATTLE' AND PostalCode = 98104 OPTION (USE HINT ('DISABLE_PARAMETER_SNIFFING'))使用 KEEPFIXED PLAN 查詢提示來防止在快取中重新編譯。 此因應措施假設「足夠好」的常見計畫是已在快取中的方案。 您也可以停用自動統計資料更新,以降低將收回良好計畫並編譯新的不良計畫的機率。
使用 DBCC FREEPROCCACHE 命令作為暫時解決方案,直到修正應用程式程式碼為止。 您可以使用
DBCC FREEPROCCACHE (plan_handle)命令,只移除造成問題的計畫。 例如,若要尋找在 AdventureWorks 中參考Person.Person資料表的查詢計劃,您可以使用此查詢來尋找查詢控制代碼。 然後,您可以使用查詢結果第二個欄中產生的DBCC FREEPROCCACHE (plan_handle),從快取釋放特定查詢計劃。SELECT text, 'DBCC FREEPROCCACHE (0x' + CONVERT(VARCHAR (512), plan_handle, 2) + ')' AS dbcc_freeproc_command FROM sys.dm_exec_cached_plans CROSS APPLY sys.dm_exec_query_plan(plan_handle) CROSS APPLY sys.dm_exec_sql_text(plan_handle) WHERE text LIKE '%person.person%'
步驟 6:調查並解決 SARGability 問題
當 SQL Server 引擎可以使用索引搜尋來加速執行查詢時,查詢中的述詞會被視為 SARGable (Search ARGument-able)。 許多查詢設計都防止 SARGability,並導致資料表或索引掃描和高 CPU 使用量。 請針對 AdventureWorks 資料庫考慮下列查詢,其中必須擷取每個 ProductNumber 資料庫,並將 SUBSTRING() 函式套用至該資料庫,再將它與字串常值進行比較。 如您所見,您必須先擷取資料表的所有資料列,然後套用函式,才能進行比較。 從資料表擷取所有資料列表示資料表或索引掃描,這會導致 CPU 使用量較高。
SELECT ProductID, Name, ProductNumber
FROM [Production].[Product]
WHERE SUBSTRING(ProductNumber, 0, 4) = 'HN-'
在搜尋述詞的資料行上套用任何函式或計算通常會讓查詢變成不 sargable,並導致 CPU 耗用量較高。 解決方案通常牽涉到以創意的方式重寫查詢,以讓其 SARGable。 此範例的可能解決方案是此重寫,其中函式會從查詢述詞中移除、搜尋另一個資料行,並達到相同的結果:
SELECT ProductID, Name, ProductNumber
FROM [Production].[Product]
WHERE Name LIKE 'Hex%'
以下是另一個範例,其中銷售經理可能會想要在大型訂單上提供 10% 的銷售額度,並想要查看哪些訂單的佣金會超過 $300 美元。 以下是符合邏輯但不可搜尋的方式。
SELECT DISTINCT SalesOrderID, UnitPrice, UnitPrice * 0.10 [10% Commission]
FROM [Sales].[SalesOrderDetail]
WHERE UnitPrice * 0.10 > 300
以下是可能較不直覺但可重寫的查詢重寫,其中計算會移至述詞的另一端。
SELECT DISTINCT SalesOrderID, UnitPrice, UnitPrice * 0.10 [10% Commission]
FROM [Sales].[SalesOrderDetail]
WHERE UnitPrice > 300/0.10
SARGability 不只適用于 WHERE 子句,也適用于 JOINs 、 HAVINGGROUP BY 和 ORDER BY 子句。 查詢中經常出現的 SARGability 防護涉及 CONVERT()、 CAST()、 ISNULL()、 COALESCE() ,這些函式用於導致欄掃描的 WHERE 或 JOIN 子句中。 在資料類型轉換案例 (CONVERT 或 CAST) 中,解決方案可能是確保您要比較的是相同的資料類型。 以下是將 T1.ProdID 欄明確轉換成 INT 中 JOIN 資料類型的範例 。 轉換會使聯結欄上索引的使用失敗。
隱含轉換會發生相同的問題,其中資料類型不同,SQL Server 轉換其中一個類型來執行聯結。
SELECT T1.ProdID, T1.ProdDesc
FROM T1 JOIN T2
ON CONVERT(int, T1.ProdID) = T2.ProductID
WHERE t2.ProductID BETWEEN 200 AND 300
若要避免掃描 T1 資料表,您可以在適當規劃和設計之後變更欄的基礎資料類型 ProdID ,然後在不使用轉換 函式 ON T1.ProdID = T2.ProductID 的情況下聯結這兩個欄。
另一個解決方案是在 T1 中建立使用相同 CONVERT() 函式的計算欄,然後在其中建立索引。 此舉可讓查詢最佳化工具使用該索引,而不需要變更查詢。
ALTER TABLE dbo.T1 ADD IntProdID AS CONVERT (INT, ProdID);
CREATE INDEX IndProdID_int ON dbo.T1 (IntProdID);
在某些情況下,無法輕鬆地重寫查詢以允許 SARGability。 在這些情況下,請查看其上具有索引的計算欄是否有説明,或讓查詢保持原狀,並瞭解它可能會導致較高的 CPU 案例。
步驟 7:停用大量追蹤
檢查 SQL 追蹤或 XEvent 追蹤,這些追蹤會影響 SQL Server 效能,並造成高 CPU 使用率。 例如,如果您追蹤大量 SQL Server 活動,使用下列事件可能會導致高 CPU 使用量:
- 查詢計劃 XML 事件 (
query_plan_profile、query_post_compilation_showplan、query_post_execution_plan_profile、query_post_execution_showplan、query_pre_execution_showplan) - 語句層級事件 (
sql_statement_completed、sql_statement_starting、sp_statement_starting、sp_statement_completed) - 登入和登出事件 (
login、process_login_finish、login_event、logout) - 鎖定事件 (
lock_acquired、lock_cancel、lock_released) - 等候事件 (
wait_info、wait_info_external) - SQL 稽核事件 (視群組中已稽核和 SQL Server 活動的群組而定)
執行下列查詢以識別作用中的 XEvent 或伺服器追蹤:
PRINT '--Profiler trace summary--'
SELECT traceid, property, CONVERT(VARCHAR(1024), value) AS value FROM::fn_trace_getinfo(
default)
GO
PRINT '--Trace event details--'
SELECT trace_id,
status,
CASE WHEN row_number = 1 THEN path ELSE NULL end AS path,
CASE WHEN row_number = 1 THEN max_size ELSE NULL end AS max_size,
CASE WHEN row_number = 1 THEN start_time ELSE NULL end AS start_time,
CASE WHEN row_number = 1 THEN stop_time ELSE NULL end AS stop_time,
max_files,
is_rowset,
is_rollover,
is_shutdown,
is_default,
buffer_count,
buffer_size,
last_event_time,
event_count,
trace_event_id,
trace_event_name,
trace_column_id,
trace_column_name,
expensive_event
FROM
(SELECT t.id AS trace_id,
row_number() over(PARTITION BY t.id order by te.trace_event_id, tc.trace_column_id) AS row_number,
t.status,
t.path,
t.max_size,
t.start_time,
t.stop_time,
t.max_files,
t.is_rowset,
t.is_rollover,
t.is_shutdown,
t.is_default,
t.buffer_count,
t.buffer_size,
t.last_event_time,
t.event_count,
te.trace_event_id,
te.name AS trace_event_name,
tc.trace_column_id,
tc.name AS trace_column_name,
CASE WHEN te.trace_event_id in (23, 24, 40, 41, 44, 45, 51, 52, 54, 68, 96, 97, 98, 113, 114, 122, 146, 180) THEN CAST(1 as bit) ELSE CAST(0 AS BIT) END AS expensive_event FROM sys.traces t CROSS APPLY::fn_trace_geteventinfo(t.id) AS e JOIN sys.trace_events te ON te.trace_event_id = e.eventid JOIN sys.trace_columns tc ON e.columnid = trace_column_id) AS x
GO
PRINT '--XEvent Session Details--'
SELECT sess.NAME 'session_name', event_name, xe_event_name, trace_event_id,
CASE WHEN xemap.trace_event_id IN(23, 24, 40, 41, 44, 45, 51, 52, 54, 68, 96, 97, 98, 113, 114, 122, 146, 180)
THEN Cast(1 AS BIT)
ELSE Cast(0 AS BIT)
END AS expensive_event
FROM sys.dm_xe_sessions sess
JOIN sys.dm_xe_session_events evt
ON sess.address = evt.event_session_address
INNER JOIN sys.trace_xe_event_map xemap
ON evt.event_name = xemap.xe_event_name
GO
步驟 8:修正線程同步鎖定爭用所造成的高 CPU 使用量
若要解決同步鎖定爭用所造成的常見高 CPU 使用量,請參閱下列各節。
SOS_CACHESTORE線程同步鎖定爭用
如果您的 SQL Server 實例遇到繁重SOS_CACHESTORE的線程同步鎖定爭用,或您注意到查詢計劃通常會在非計劃性查詢工作負載上移除,請參閱下列文章,並使用 T174 命令啟用追蹤旗標DBCC TRACEON (174, -1):
修正:SOS_CACHESTORE 隨選操作 SQL Server 計畫快取上的執行緒同步鎖定爭用會導致 SQL Server 中的 CPU 使用率偏高。
如果使用 T174 來解析高 CPU 條件,請使用 SQL Server Configuration Manager,將它啟用為啟動參數。
由於大型記憶體計算機上SOS_BLOCKALLOCPARTIALLIST同步鎖定爭用而導致隨機高 CPU 使用量
如果您的 SQL Server 實例因為同步鎖定競爭而SOS_BLOCKALLOCPARTIALLIST遇到隨機高 CPU 使用量,建議您針對 SQL Server 2019 套用累積更新 21。 如需如何解決此問題的詳細資訊,請參閱提供暫時緩和功能的 BUG 參考 2410400 和 DBCC DROPCLEANBUFFERS 。
高 CPU 使用量,因為高階計算機上XVB_list上的同步鎖定爭用
如果您的 SQL Server 實例遇到高 CPU 案例,因為高組態機器上的微調鎖定爭用 XVB_LIST 所造成的 CPU 案例(具有大量較新一代處理器(CPU)的高階系統,請啟用追蹤旗 標 TF8102 與 TF8101。
注意
高 CPU 使用量可能會因為其他許多線程同步鎖定類型的線程同步鎖定爭用所造成。 如需有關微調鎖定的詳細資訊,請參閱 診斷和解決 SQL Server 上的線程同步鎖定爭用。
步驟 9:檢查作業系統層級的電源計劃設定
當 Windows 設定預設 平衡 電源計劃時,SQL Server 工作負載可能會遇到效能降低,並在系統上造成高 CPU。 平衡電源計劃設定可能會降低 CPU 時鐘速度以節省能源。 例如,3.00 GHz 頻率的處理器可能會降頻至 1.2 GHz。 因此,通常耗用大約 30%(%)CPU 的工作負載,可能會因為時脈速度降低而達到 100%(%)使用率。 若要維持計算密集型 SQL Server 工作負載的一致且最佳效能,建議您將系統設定為使用 高效能 電源計劃。 此設定可確保 CPU 以完全額定速度運作,以協助避免效能瓶頸。 如需詳細資訊,請參閱 使用平衡電源計劃時的 Windows Server 效能變慢。
步驟 10:設定虛擬機
如果您使用虛擬機器,請確定您並未過度佈建 CPU,而且它們已正確設定。 如需詳細資訊,請參閱 針對 ESX/ESXi 虛擬機器效能問題進行疑難排解 (2001003)。
步驟 11:擴充系統以使用更多的 CPU
如果個別查詢執行個體使用較少的 CPU 容量,但所有查詢的整體工作負載都會造成高 CPU 耗用量,請考慮新增更多 CPU 來相應升級您的電腦。 使用下列查詢來尋找每個執行超過特定平均閾值和最大 CPU 耗用量的查詢數目,並在系統上執行多次 (請務必修改兩個變數的值,以符合您的環境) :
-- Shows queries where Max and average CPU time exceeds 200 ms and executed more than 1000 times
DECLARE @cputime_threshold_microsec INT = 200*1000
DECLARE @execution_count INT = 1000
SELECT qs.total_worker_time/1000 total_cpu_time_ms,
qs.max_worker_time/1000 max_cpu_time_ms,
(qs.total_worker_time/1000)/execution_count average_cpu_time_ms,
qs.execution_count,
q.[text]
FROM sys.dm_exec_query_stats qs CROSS APPLY sys.dm_exec_sql_text(plan_handle) AS q
WHERE (qs.total_worker_time/execution_count > @cputime_threshold_microsec
OR qs.max_worker_time > @cputime_threshold_microsec )
AND execution_count > @execution_count
ORDER BY qs.total_worker_time DESC