適用於:SQL Server
本文提供效能問題的疑難解答步驟,其中查詢在一部伺服器上執行速度比另一部伺服器慢。
徵兆
假設已安裝兩部 SQL Server 的伺服器。 其中一個 SQL Server 實例包含另一個 SQL Server 實例中的資料庫複本。 當您對兩部伺服器上的資料庫執行查詢時,查詢在一部伺服器上執行的速度比另一部伺服器慢。
下列步驟可協助針對此問題進行疑難解答。
步驟 1:判斷是否為多個查詢的常見問題
使用下列兩種方法之一來比較兩部伺服器上兩個或多個查詢的效能:
在兩部伺服器上手動測試查詢:
- 選擇數個查詢,以優先於下列查詢進行測試:
- 一部伺服器上的速度明顯快於另一部伺服器。
- 對使用者/應用程式很重要。
- 經常執行或設計以視需要重現問題。
- 足以擷取其上的數據(例如,而不是 5 毫秒的查詢,請選擇 10 秒的查詢)。
- 在兩部伺服器上執行查詢。
- 針對每個查詢,比較兩部伺服器上的經過時間(持續時間)。
- 選擇數個查詢,以優先於下列查詢進行測試:
使用 SQL Nexus 分析效能數據。
- 收集 兩部伺服器上的查詢的 PSSDiag/SQLdiag 或 SQL LogScout 數據。
- 使用 SQL Nexus 匯入收集的數據檔,並比較來自兩部伺服器的查詢。 如需詳細資訊,請參閱兩個記錄集合之間的效能比較(例如慢速和快速)。
案例 1:在兩部伺服器上,只有一個單一查詢以不同的方式執行
如果只有一個查詢以不同的方式執行,問題就更可能專屬於個別查詢,而不是環境。 在此情況下,請移至 步驟 2:收集數據,並判斷效能問題的類型。
案例 2:在兩部伺服器上執行多個查詢的方式不同
如果多個查詢在一部伺服器上執行的速度比另一個伺服器慢,最可能的原因是伺服器或數據環境的差異。 移至診斷 環境差異 ,並查看兩部伺服器之間的比較是否有效。
步驟 2:收集數據並判斷效能問題的類型
收集經過的時間、CPU 時間和邏輯讀取
若要在兩部伺服器上收集查詢的經過時間和CPU時間,請使用下列最符合您情況的方法之一:
針對目前執行的語句,請檢查sys.dm_exec_requests中的total_elapsed_time和cpu_time數據行。 執行下列查詢以取得資料:
SELECT req.session_id , req.total_elapsed_time AS duration_ms , req.cpu_time AS cpu_time_ms , req.total_elapsed_time - req.cpu_time AS wait_time , req.logical_reads , SUBSTRING (REPLACE (REPLACE (SUBSTRING (ST.text, (req.statement_start_offset/2) + 1, ((CASE statement_end_offset WHEN -1 THEN DATALENGTH(ST.text) ELSE req.statement_end_offset END - req.statement_start_offset)/2) + 1) , CHAR(10), ' '), CHAR(13), ' '), 1, 512) AS statement_text FROM sys.dm_exec_requests AS req CROSS APPLY sys.dm_exec_sql_text(req.sql_handle) AS ST ORDER BY total_elapsed_time DESC;如需查詢的過去執行,請檢查sys.dm_exec_query_stats中的last_elapsed_time和last_worker_time數據行。 執行下列查詢以取得資料:
SELECT t.text, (qs.total_elapsed_time/1000) / qs.execution_count AS avg_elapsed_time, (qs.total_worker_time/1000) / qs.execution_count AS avg_cpu_time, ((qs.total_elapsed_time/1000) / qs.execution_count ) - ((qs.total_worker_time/1000) / qs.execution_count) AS avg_wait_time, qs.total_logical_reads / qs.execution_count AS avg_logical_reads, qs.total_logical_writes / qs.execution_count AS avg_writes, (qs.total_elapsed_time/1000) AS cumulative_elapsed_time_all_executions FROM sys.dm_exec_query_stats qs CROSS apply sys.Dm_exec_sql_text (sql_handle) t WHERE t.text like '<Your Query>%' -- Replace <Your Query> with your query or the beginning part of your query. The special chars like '[','_','%','^' in the query should be escaped. ORDER BY (qs.total_elapsed_time / qs.execution_count) DESC注意
如果
avg_wait_time顯示負值,則為 平行查詢。如果您可以在 SQL Server Management Studio (SSMS) 或 Azure Data Studio 中視需要執行查詢,請使用 SET STATISTICS TIME
ON和 SET STATISTICS IOON來執行查詢。SET STATISTICS TIME ON SET STATISTICS IO ON <YourQuery> SET STATISTICS IO OFF SET STATISTICS TIME OFF然後,您會從 訊息中看到 CPU 時間、經過的時間,以及如下所示的邏輯讀取:
Table 'tblTest'. Scan count 1, logical reads 3, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0. SQL Server Execution Times: CPU time = 460 ms, elapsed time = 470 ms.如果可以收集查詢計劃,請檢查執行 計劃屬性中的數據。
使用 [包含實際執行計劃] 執行查詢。
從 [執行計劃] 選取最左邊的運算子。
從 [屬性] 展開 [QueryTimeStats ] 屬性。
檢查 ElapsedTime 和 CpuTime。
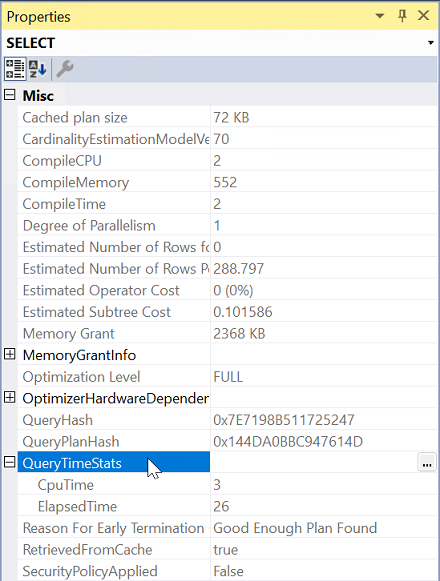
比較查詢經過的時間和CPU時間,以判斷這兩部伺服器的問題類型。
類型 1:CPU 系結(執行器)
如果 CPU 時間接近、等於或高於經過的時間,您可以將它視為 CPU 系結查詢。 例如,如果經過的時間是 3000 毫秒(毫秒),而 CPU 時間是 2900 毫秒,這表示大部分經過的時間都花在 CPU 上。 然後我們可以說這是 CPU 系結的查詢。
執行 (CPU 系結) 查詢的範例:
| 經過的時間 (毫秒) | CPU 時間 (毫秒) | 讀取 (邏輯) |
|---|---|---|
| 3200 | 3000 | 300000 |
| 1080 | 1000 | 20 |
邏輯讀取 - 讀取快取中的數據/索引頁面 - 最常是 SQL Server 中 CPU 使用率的驅動程式。 在某些情況下,CPU 使用來自其他來源:while 迴圈(在 T-SQL 或其他程式代碼中,例如 XProcs 或 SQL CRL 物件)。 數據表中的第二個範例說明這類案例,其中大部分的CPU不是來自讀取。
注意
如果 CPU 時間大於持續時間,這表示已執行平行查詢;多個線程同時使用CPU。 如需詳細資訊,請參閱 平行查詢 - 執行器或等候者。
類型 2:等候瓶頸 (等候者)
如果經過的時間明顯大於 CPU 時間,查詢會等候瓶頸。 經過的時間包括在 CPU 上執行查詢的時間(CPU 時間),以及等候釋放資源的時間(等候時間)。 例如,如果經過的時間是 2000 毫秒,而 CPU 時間是 300 毫秒,則等候時間為 1700 毫秒(2000 - 300 = 1700)。 如需詳細資訊,請參閱 等候類型。
等候查詢的範例:
| 經過的時間 (毫秒) | CPU 時間 (毫秒) | 讀取 (邏輯) |
|---|---|---|
| 2000 | 300 | 28000 |
| 10080 | 700 | 80000 |
平行查詢 - 執行器或等候者
平行查詢可能會使用比整體持續時間更多的CPU時間。 平行處理原則的目標是允許多個線程同時執行查詢的部分。 在時鐘時間的一秒內,查詢可能會藉由執行八個平行線程來使用八秒的CPU時間。 因此,根據經過的時間和CPU時間差異,判斷CPU系結或等候查詢會變得很困難。 不過,一般規則遵循上述兩節所列的原則。 摘要為:
- 如果經過的時間遠大於 CPU 時間,請考慮它是等候者。
- 如果 CPU 時間遠大於經過的時間,請考慮它為執行器。
平行查詢的範例:
| 經過的時間 (毫秒) | CPU 時間 (毫秒) | 讀取 (邏輯) |
|---|---|---|
| 1200 | 8100 | 850000 |
| 3080 | 12300 | 1500000 |
步驟 3:比較這兩部伺服器的數據、找出案例,以及針對問題進行疑難解答
假設有兩部名為 Server1 和 Server2 的電腦。 而查詢在 Server1 上執行的速度比 Server2 慢。 比較兩部伺服器的時間,然後遵循最符合您下列各節之案例的動作。
案例 1:Server1 上的查詢會使用較多的 CPU 時間,而 Server1 上的邏輯讀取比 Server2 上的更高
如果 Server1 上的 CPU 時間遠大於 Server2,且經過的時間與兩部伺服器上的 CPU 時間緊密相符,則沒有任何主要等候或瓶頸。 Server1 上的 CPU 時間增加很可能是因為邏輯讀取增加所造成。 邏輯讀取的重大變更通常表示查詢計劃的差異。 例如:
| 伺服器 | 經過的時間 (毫秒) | CPU 時間 (毫秒) | 讀取 (邏輯) |
|---|---|---|---|
| Server1 | 3100 | 3000 | 300000 |
| Server2 | 1100 | 1000 | 90200 |
動作:檢查執行計劃和環境
- 比較這兩部伺服器上的查詢執行計劃。 若要這樣做,請使用下列兩種方法之一:
- 以可視化方式比較執行計劃。 如需詳細資訊,請參閱顯示實際執行計劃。
- 儲存執行計劃,並使用 SQL Server Management Studio 方案比較功能加以比較。
- 比較環境。 不同的環境可能會導致查詢計劃差異或CPU使用量的直接差異。 環境包括伺服器版本、資料庫或伺服器組態設定、追蹤旗標、CPU 計數或時鐘速度,以及虛擬機與實體機器。 如需詳細資訊,請參閱診斷查詢計劃差異。
案例 2:查詢是 Server1 上的等候者,但在 Server2 上不是
如果這兩部伺服器上的查詢 CPU 時間類似,但 Server1 上經過的時間遠大於 Server2,則 Server1 上的查詢會花費較長的時間 等候瓶頸。 例如:
| 伺服器 | 經過的時間 (毫秒) | CPU 時間 (毫秒) | 讀取 (邏輯) |
|---|---|---|---|
| Server1 | 4500 | 1000 | 90200 |
| Server2 | 1100 | 1000 | 90200 |
- Server1 上的等候時間:4500 - 1000 = 3500 毫秒
- Server2 上的等候時間:1100 - 1000 = 100 毫秒
動作:檢查 Server1 上的等候類型
識別並消除 Server1 上的瓶頸。 等候範例包括封鎖(鎖定等候)、閂鎖等候、磁碟 I/O 等候、網路等候和記憶體等候。 若要針對常見的瓶頸問題進行疑難解答,請繼續診斷 等候或瓶頸。
案例 3:這兩部伺服器上的查詢都是服務員,但等候類型或時間不同
例如:
| 伺服器 | 經過的時間 (毫秒) | CPU 時間 (毫秒) | 讀取 (邏輯) |
|---|---|---|---|
| Server1 | 8000 | 1000 | 90200 |
| Server2 | 3000 | 1000 | 90200 |
- Server1 上的等候時間:8000 - 1000 = 7000 毫秒
- Server2 上的等候時間:3000 - 1000 = 2000 毫秒
在此情況下,這兩部伺服器上的CPU時間都類似,這表示查詢計劃可能相同。 如果兩部伺服器沒有等待瓶頸,查詢就會同樣地執行。 因此,持續時間差異來自不同的等候時間量。 例如,查詢會在 Server1 上的鎖定等候 7000 毫秒,而 Server2 上的 I/O 等候 2000 毫秒。
動作:檢查兩部伺服器上的等候類型
解決每個伺服器個別等候的每個瓶頸,並加快這兩部伺服器上的執行速度。 此問題的疑難解答需要大量人力,因為您需要消除兩部伺服器上的瓶頸,並讓效能可比較。 若要針對常見的瓶頸問題進行疑難解答,請繼續診斷 等候或瓶頸。
案例 4:Server1 上的查詢使用比 Server2 更多的 CPU 時間,但邏輯讀取已關閉
例如:
| 伺服器 | 經過的時間 (毫秒) | CPU 時間 (毫秒) | 讀取 (邏輯) |
|---|---|---|---|
| Server1 | 3000 | 3000 | 90200 |
| Server2 | 1000 | 1000 | 90200 |
如果資料符合下列條件:
- Server1 上的 CPU 時間遠大於 Server2。
- 經過的時間會比對每部伺服器上的CPU時間,這表示沒有等候。
- 邏輯讀取通常是 CPU 時間最高的驅動程式,這兩部伺服器上都很類似。
然後,額外的CPU時間來自一些其他CPU系結活動。 此案例是所有案例中最罕見的情況。
原因:追蹤、UDF 和 CLR 整合
此問題可能是由下列原因所造成:
- XEvents/SQL Server 追蹤,特別是篩選文字數據行(資料庫名稱、登入名稱、查詢文字等等)。 如果在一部伺服器上啟用追蹤,但未啟用另一部伺服器,這可能是差異的原因。
- 執行 CPU 系結作業的使用者定義函式 (UDF) 或其他 T-SQL 程式代碼。 這通常是 Server1 和 Server2 上其他條件不同的原因,例如數據大小、CPU 時鐘速度或電源計劃。
- SQL Server CLR 整合 或 擴充預存程式(XP) 可能會驅動 CPU,但不會執行邏輯讀取。 DLL 的差異可能會導致不同的CPU時間。
- CPU 系結的 SQL Server 功能差異(例如字串操作程式碼)。
動作:檢查追蹤和查詢
檢查這兩部伺服器上的追蹤,以取得下列專案:
- 如果 Server1 上已啟用任何追蹤,但未在 Server2 上啟用。
- 如果已啟用任何追蹤,請停用追蹤,然後在 Server1 上再次執行查詢。
- 如果這次查詢執行得更快,請啟用追蹤,但如果有的話,請從中移除文字篩選。
檢查查詢是否使用執行字串操作的 UDF,或在清單中對資料行
SELECT執行大量處理。檢查查詢是否包含迴圈、函式遞歸或巢狀。
診斷環境差異
檢查下列問題,並判斷兩部伺服器之間的比較是否有效。
這兩個 SQL Server 實例是否為相同版本或組建?
如果沒有,可能會有一些導致差異的修正程式。 執行下列查詢以取得這兩部伺服器上的版本資訊:
SELECT @@VERSION這兩部伺服器上的物理記憶體數量是否相似?
如果一部伺服器有 64 GB 的記憶體,而另一部伺服器有 256 GB 的記憶體,那將會是顯著的差異。 使用更多記憶體可快取數據/索引頁面和查詢計劃,查詢可能會根據硬體資源可用性以不同的方式進行優化。
這兩部伺服器上的 CPU 相關硬體設定是否類似? 例如:
CPU 數目會因計算機而異(一部計算機上的 24 個 CPU,另一部計算機為 96 個 CPU)。
電源計劃 - 平衡與高效能。
虛擬機 (VM) 與實體 (裸機) 機器。
Hyper-V 與 VMware- 組態的差異。
時鐘速度差異(時鐘速度較低,時鐘速度與頻率速度較高)。 例如,2 GHz 與 3.5 GHz 可能會有所差異。 若要取得伺服器上的時鐘速度,請執行下列 PowerShell 命令:
Get-CimInstance Win32_Processor | Select-Object -Expand MaxClockSpeed
使用下列兩種方式之一來測試伺服器的CPU速度。 如果它們不會產生可比較的結果,問題就不在 SQL Server 之外。 這可能是電源計劃差異、CPU 較少、VM 軟體問題或時鐘速度差異。
在兩部伺服器上執行下列 PowerShell 腳本,並比較輸出。
$bf = [System.DateTime]::Now for ($i = 0; $i -le 20000000; $i++) {} $af = [System.DateTime]::Now Write-Host ($af - $bf).Milliseconds " milliseconds" Write-Host ($af - $bf).Seconds " Seconds"在兩部伺服器上執行下列 Transact-SQL 程式代碼,並比較輸出。
SET NOCOUNT ON DECLARE @spins INT = 0 DECLARE @start_time DATETIME = GETDATE(), @time_millisecond INT WHILE (@spins < 20000000) BEGIN SET @spins = @spins +1 END SELECT @time_millisecond = DATEDIFF(millisecond, @start_time, getdate()) SELECT @spins Spins, @time_millisecond Time_ms, @spins / @time_millisecond Spins_Per_ms
診斷等候或瓶頸
若要優化等候瓶頸的查詢,請找出等候的時間長度,以及瓶頸所在的位置(等候類型)。 確認等候類型之後,請減少等候時間,或完全排除等候。
若要計算大約等候時間,請從查詢經過的時間減去 CPU 時間(背景工作時間)。 一般而言,CPU 時間是實際運行時間,而查詢存留期的剩餘部分正在等候。
如何計算近似等候持續時間的範例:
| 經過的時間 (毫秒) | CPU 時間 (毫秒) | 等候時間 (毫秒) |
|---|---|---|
| 3200 | 3000 | 200 |
| 7080 | 1000 | 6080 |
識別瓶頸或等候
若要識別歷程記錄長時間等候的查詢(例如, >20% 的整體經過時間是等候時間),請執行下列查詢。 此查詢會針對 SQL Server 開頭之後的快取查詢計劃使用效能統計數據。
SELECT t.text, qs.total_elapsed_time / qs.execution_count AS avg_elapsed_time, qs.total_worker_time / qs.execution_count AS avg_cpu_time, (qs.total_elapsed_time - qs.total_worker_time) / qs.execution_count AS avg_wait_time, qs.total_logical_reads / qs.execution_count AS avg_logical_reads, qs.total_logical_writes / qs.execution_count AS avg_writes, qs.total_elapsed_time AS cumulative_elapsed_time FROM sys.dm_exec_query_stats qs CROSS apply sys.Dm_exec_sql_text (sql_handle) t WHERE (qs.total_elapsed_time - qs.total_worker_time) / qs.total_elapsed_time > 0.2 ORDER BY qs.total_elapsed_time / qs.execution_count DESC若要識別目前執行超過 500 毫秒的查詢,請執行下列查詢:
SELECT r.session_id, r.wait_type, r.wait_time AS wait_time_ms FROM sys.dm_exec_requests r JOIN sys.dm_exec_sessions s ON r.session_id = s.session_id WHERE wait_time > 500 AND is_user_process = 1如果可以收集查詢計劃,請檢查 SSMS 中執行計劃屬性中的 WaitStats:
- 使用 [包含實際執行計劃] 執行查詢。
- 在 [執行計劃] 索引標籤中,以滑鼠右鍵按兩下最左邊的運算子
- 選取 [屬性],然後選取 [WaitStats] 屬性。
- 檢查 WaitTimeMs 和 WaitType。
如果您熟悉 PSSDiag/SQLdiag 或 SQL LogScout LightPerf/GeneralPerf 案例,請考慮使用其中一個來收集效能統計數據,並識別 SQL Server 實例上的等候查詢。 您可以匯入收集的數據檔,並使用 SQL Nexus 分析效能數據。
協助消除或減少等候的參考
每個等候類型的原因和解決方式會有所不同。 沒有一個一般方法可以解析所有等候類型。 以下是疑難解答和解決常見等候類型問題的文章:
- 瞭解並解決封鎖問題 (LCK_M_*)
- 了解並解決 Azure SQL 資料庫封鎖問題
- 針對 I/O 問題所造成的 SQL Server 效能緩慢進行疑難解答(PAGEIOLATCH_*、WRITELOG、IO_COMPLETION、BACKUPIO)
- 解決 SQL Server 中最後一頁插入 PAGELATCH_EX 爭用
- 記憶體授與說明和解決方案 (RESOURCE_SEMAPHORE)
- 針對ASYNC_NETWORK_IO等候類型所產生的慢速查詢進行疑難解答
- 針對具有AlwaysOn可用性群組的高HADR_SYNC_COMMIT等候類型進行疑難解答
- 運作方式:CMEMTHREAD 和偵錯
- 讓平行處理原則等候可採取動作 (CXPACKET 和 CXCONSUMER)
- THREADPOOL 等候
如需許多 Wait 類型及其指示的描述,請參閱 Waits 類型中的表格。
診斷查詢計劃差異
以下是查詢計劃差異的一些常見原因:
數據大小或數據值差異
這兩部伺服器上是否使用相同的資料庫—使用相同的資料庫備份? 與另一部伺服器相比,數據是否已修改? 數據差異可能會導致不同的查詢計劃。 例如,聯結數據表 T1 (1000 個數據列)與數據表 T2 (2,000,000 個數據列) 與聯結數據表 T1 (100 個數據列) 與數據表 T2 (2,000,000 個數據列) 不同。 作業的類型
JOIN和速度可能會有很大的不同。統計數據差異
統計數據是否已更新一個資料庫,而不是另一個資料庫? 統計數據是否已以不同的取樣率更新(例如,30% 與 100% 完整掃描)? 請確定您使用相同的取樣率來更新這兩端的統計數據。
資料庫相容性層級差異
檢查兩部伺服器之間的資料庫相容性層級是否不同。 若要取得資料庫相容性層級,請執行下列查詢:
SELECT name, compatibility_level FROM sys.databases WHERE name = '<YourDatabase>'伺服器版本/組建差異
兩部伺服器之間的 SQL Server 版本或組建是否不同? 例如,一部伺服器 SQL Server 版本 2014 和另一個 SQL Server 版本 2016 嗎? 可能會有產品變更,可能會導致選取查詢計劃的方式變更。 請務必比較相同的 SQL Server 版本和組建。
SELECT ServerProperty('ProductVersion')基數估算器 (CE) 版本差異
檢查舊版基數估算器是否在資料庫層級啟動。 如需 CE 的詳細資訊,請參閱 基數估計 (SQL Server) 。
SELECT name, value, is_value_default FROM sys.database_scoped_configurations WHERE name = 'LEGACY_CARDINALITY_ESTIMATION'已啟用/停用優化工具 Hotfix
如果在一部伺服器上啟用查詢優化器 Hotfix,但另一部伺服器上已停用,則可以產生不同的查詢計劃。 如需詳細資訊,請參閱 SQL Server 查詢優化器 Hotfix 追蹤旗標 4199 服務模型。
若要取得查詢優化器 Hotfix 的狀態,請執行下列查詢:
-- Check at server level for TF 4199 DBCC TRACESTATUS (-1) -- Check at database level USE <YourDatabase> SELECT name, value, is_value_default FROM sys.database_scoped_configurations WHERE name = 'QUERY_OPTIMIZER_HOTFIXES'追蹤旗標差異
某些追蹤旗標會影響查詢計劃選取。 檢查某部伺服器上是否已啟用追蹤旗標,但未在其他伺服器上啟用。 在兩部伺服器上執行下列查詢,並比較結果:
-- Check at server level for trace flags DBCC TRACESTATUS (-1)硬體差異(CPU 計數、記憶體大小)
若要取得硬體資訊,請執行下列查詢:
SELECT cpu_count, physical_memory_kb/1024/1024 PhysicalMemory_GB FROM sys.dm_os_sys_info根據查詢優化器的硬體差異
檢查查詢計劃的 ,
OptimizerHardwareDependentProperties並查看硬體差異是否對不同的方案而言相當重要。WITH xmlnamespaces(DEFAULT 'http://schemas.microsoft.com/sqlserver/2004/07/showplan') SELECT txt.text, t.OptHardw.value('@EstimatedAvailableMemoryGrant', 'INT') AS EstimatedAvailableMemoryGrant , t.OptHardw.value('@EstimatedPagesCached', 'INT') AS EstimatedPagesCached, t.OptHardw.value('@EstimatedAvailableDegreeOfParallelism', 'INT') AS EstimatedAvailDegreeOfParallelism, t.OptHardw.value('@MaxCompileMemory', 'INT') AS MaxCompileMemory FROM sys.dm_exec_cached_plans AS cp CROSS APPLY sys.dm_exec_query_plan(cp.plan_handle) AS qp CROSS APPLY qp.query_plan.nodes('//OptimizerHardwareDependentProperties') AS t(OptHardw) CROSS APPLY sys.dm_exec_sql_text (CP.plan_handle) txt WHERE text Like '%<Part of Your Query>%'優化器逾時
是否有優化工具逾時問題? 如果執行的查詢太複雜,查詢優化器可以停止評估計劃選項。 停止時,它會挑選當時成本最低的方案。 這可能會導致某個伺服器上的任意計劃選擇與另一部伺服器。
Set 選項
某些 SET 選項會影響計劃,例如 SET ARITHABORT。 如需詳細資訊,請參閱 SET 選項。
查詢提示差異
一個查詢是否使用 查詢提示 ,而另一個查詢則不使用? 手動檢查查詢文字,以建立查詢提示是否存在。
參數敏感計劃 (參數探查問題)
您是否使用完全相同的參數值來測試查詢? 如果沒有,您可以從該處開始。 計劃先前是以不同的參數值為基礎在一部伺服器上編譯的嗎? 使用 RECOMPILE 查詢提示測試這兩個查詢,以確保不會重複執行計劃。 如需詳細資訊,請參閱調查和解決參數敏感性問題。
不同的資料庫選項/範圍組態設定
這兩部伺服器上所使用的資料庫選項或範圍組態設定是否相同? 某些資料庫選項可能會影響計劃選擇。 例如,資料庫相容性、舊版CE與預設CE,以及參數探查。 從一部伺服器執行下列查詢,以比較兩部伺服器上所使用的資料庫選項:
-- On Server1 add a linked server to Server2 EXEC master.dbo.sp_addlinkedserver @server = N'Server2', @srvproduct=N'SQL Server' -- Run a join between the two servers to compare settings side by side SELECT s1.name AS srv1_config_name, s2.name AS srv2_config_name, s1.value_in_use AS srv1_value_in_use, s2.value_in_use AS srv2_value_in_use, Variance = CASE WHEN ISNULL(s1.value_in_use, '##') != ISNULL(s2.value_in_use,'##') THEN 'Different' ELSE '' END FROM sys.configurations s1 FULL OUTER JOIN [server2].master.sys.configurations s2 ON s1.name = s2.name SELECT s1.name AS srv1_config_name, s2.name AS srv2_config_name, s1.value srv1_value_in_use, s2.value srv2_value_in_use, s1.is_value_default, s2.is_value_default, Variance = CASE WHEN ISNULL(s1.value, '##') != ISNULL(s2.value, '##') THEN 'Different' ELSE '' END FROM sys.database_scoped_configurations s1 FULL OUTER JOIN [server2].master.sys.database_scoped_configurations s2 ON s1.name = s2.name計畫指南
是否有任何計劃指南用於一部伺服器上的查詢,但不用於另一部伺服器? 執行下列查詢來建立差異:
SELECT * FROM sys.plan_guides