針對受查詢優化器逾時影響的慢速查詢進行疑難解答
適用于:SQL Server
本文介紹優化工具逾時、其如何影響查詢效能,以及如何優化效能。
什麼是優化工具逾時?
SQL Server 使用以成本為基礎的查詢優化器 (QO) 。 如需 QO 的相關信息,請 參閱查詢處理架構指南。 成本型查詢優化器會在建置並評估多個查詢計劃之後,選取成本最低的查詢執行計劃。 與查詢執行相比,SQL Server 查詢優化器的其中一個目標是在查詢優化中花費合理的時間。 優化查詢的速度應該比執行它快很多。 若要完成此目標,QO 在停止優化程式之前,必須考慮內建的工作閾值。 在 QO 考慮所有可能的計劃之前達到臨界值時,它會達到優化工具逾時限制。 在查詢計劃中,會在語句優化的早期終止原因下,將 Optimizer Timeout 事件回報為 TimeOut。 請務必瞭解,此臨界值不是以時鐘時間為基礎,而是根據優化工具所考慮的可能性數目而定。 在目前的 SQL Server QO 版本中,超過 50 萬個工作會在達到逾時之前考慮。
優化工具逾時是設計成 SQL Server,而且在許多情況下,它不是影響查詢效能的因素。 不過,在某些情況下,SQL 查詢計劃選擇可能會受到優化工具逾時的負面影響,而查詢效能可能會變慢。 當您遇到這類問題時,瞭解優化工具逾時機制以及複雜查詢會如何受到影響,可協助您進行疑難解答並改善查詢速度。
達到優化工具逾時閾值的結果是 SQL Server 並未考慮優化的整組可能性。 也就是說,可能遺漏了可能會產生較短運行時間的計劃。 QO 會在臨界值停止,並在該時間點考慮成本最低的查詢計劃,即使可能有更好、未探索的選項。 請記住,達到優化器逾時之後選取的計劃可能會產生合理的查詢執行持續時間。 不過,在某些情況下,選取的計劃可能會導致查詢執行不佳。
如何偵測優化工具逾時?
以下是指出優化工具逾時的徵兆:
複雜的查詢
您有一個涉及許多聯結數據表的複雜查詢 (例如,有八個或多個數據表已聯結) 。
慢速查詢
查詢的執行速度可能會比在另一個 SQL Server 版本或系統上執行的速度慢或慢。
查詢計劃顯示 StatementOptmEarlyAbortReason=Timeout
查詢計劃會顯示
StatementOptmEarlyAbortReason="TimeOut"在 XML 查詢計劃中。<?xml version="1.0" encoding="utf-16"?> <ShowPlanXML xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:xsd="http://www.w3.org/2001/XMLSchema" Version="1.518" Build="13.0.5201.2" xmlns="http://schemas.microsoft.com/sqlserver/2004/07/showplan"> <BatchSequence> <Batch> <Statements> <StmtSimple ..." StatementOptmLevel="FULL" StatementOptmEarlyAbortReason="TimeOut" ......> ... <Statements> <Batch> <BatchSequence>在 Microsoft SQL Server Management Studio 中檢查最左邊計劃操作員的屬性。 您可以看到語 句優化的早期終止原因 值為 TimeOut。
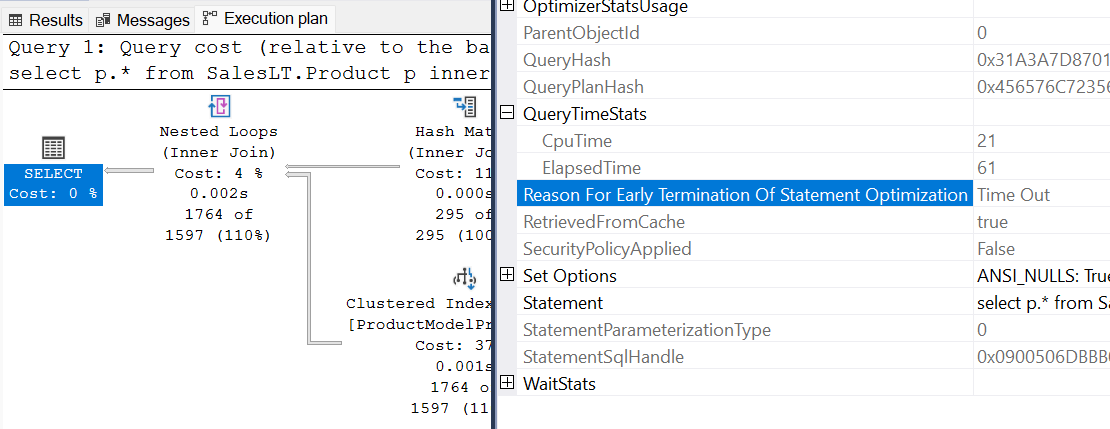
造成優化工具逾時的原因為何?
沒有簡單的方法可以判斷哪些條件會達到或超過優化工具閾值。 下列各節是一些影響 QO 在尋找最佳方案時所探索方案數的因素。
數據表應該以何種順序聯結?
以下是三個數據表聯結的執行選項範例, (
Table1、Table2、Table3) :- 與聯
Table1結Table2,並將結果與Table3 - 與聯
Table1結Table3,並將結果與Table2 - 與聯
Table2結Table3,並將結果與Table1
注意: 數據表數目越大,可能性越大。
- 與聯
HoBT (哪些堆積或二進位樹狀結構) 用來從數據表擷取數據列的存取結構?
- 叢集索引
- 非叢集索引1
- 非叢集索引2
- 數據表堆積
要使用哪些實體存取方法?
- 索引搜尋
- 索引掃描
- 數據表掃描
要使用的實體聯結運算符為何?
- 巢狀循環聯結 (NJ)
- HJ) (哈希聯結
- 合併聯結 (MJ)
- 自適性聯結 (從 SQL Server 2017 (14.x) )
如需詳細資訊,請參閱 聯結。
要平行或循序執行部分查詢?
如需詳細資訊,請參閱 平行查詢處理。
雖然下列因素會減少考慮的存取方法數目,因而考慮可能性:
- 子句中的查詢述詞 (篩選
WHERE) - 條件約束的存在
- 設計完善和最新統計數據的組合
注意: QO 達到臨界值並不表示其最終會出現較慢的查詢。 在大部分情況下,查詢會執行良好,但在某些情況下,您可能會看到較慢的查詢執行。
考慮因素的範例
為了說明這三個數據表之間的聯結範例, (t1、 t2和 t3) ,而且每個數據表都有叢集索引和非叢集索引。
首先,請考慮實體聯結類型。 這裡涉及兩個聯結。 此外,由於 NJ、HJ 和 MJ) (有三種實體聯結可能性,因此查詢可以透過 32 = 9 的方式執行。
- NJ - NJ
- NJ - HJ
- NJ - MJ
- HJ - NJ
- HJ - HJ
- HJ - MJ
- MJ - NJ
- MJ - HJ
- MJ - MJ
然後,請考慮使用排列計算的聯結順序:P (n、r) 。 前兩個數據表的順序並不重要,因此 P (3,1) = 3 種可能性:
- 與聯
t1結t2,然後與t3 - 與聯
t1結t3,然後與t2 - 與聯
t2結t3,然後與t1
接下來,請考慮可用於擷取數據的叢集和非叢集索引。 此外,針對每個索引,我們有兩種存取方法:搜尋或掃描。 這表示每個數據表都有 22 = 4 個選擇。 我們有三個數據表,因此可以有 43 = 64 個選擇。
最後,考慮到所有這些條件,可以有 9*3*64 = 1728 個可能的計劃。
現在,假設查詢中聯結了 n 個數據表,而且每個數據表都有叢集索引和非叢集索引。 請考慮下列因素:
- 聯結訂單:P (n,n-2) = n!/2
- 聯結類型:3n-1
- 具有搜尋和掃描方法的不同索引類型:4n
將上述所有專案相乘,我們可以取得可能的計劃數目:2*n!*12n-1。 當 n = 4 時,數位為 82,944。 當 n = 6 時,數位為 358,318,080。 因此,隨著查詢所涉及的數據表數目增加,可能的計劃數目會以幾何方式增加。 此外,如果您包含平行處理原則的可能性和其他因素,您可以想像將考慮多少個可能的計劃。 因此,相較於聯結較少的查詢,具有許多聯結的查詢更可能達到優化工具逾時臨界值。
請注意,上述計算說明最糟的案例。 如我們所述,有一些因素會減少可能性,例如篩選述詞、統計數據和條件約束。 例如,篩選述詞和更新的統計數據會減少實體存取方法的數目,因為使用索引搜尋比掃描更有效率。 這也會導致較少選取的聯結等等。
為什麼我會看到具有簡單查詢的優化工具逾時?
查詢優化器的功能並不簡單。 有許多可能的案例,而且複雜度太高,因此很難掌握所有的可能性。 查詢優化器可能會根據在特定階段找到的計劃成本,動態設定逾時閾值。 例如,如果找到看起來相對有效率的計劃,搜尋較佳方案的工作限制可能會降低。 因此,CE) (基 數估計 過小可能是提早達到優化工具逾時的其中一個案例。 在此情況下,調查的重點是CE。 相較於執行上一節所討論之複雜查詢的案例,這種情況比較罕見,但有可能。
解決方案
查詢計劃中出現的優化工具逾時不一定表示這是查詢效能不佳的原因。 在大部分情況下,您可能不需要對此情況執行任何動作。 SQL Server 結束的查詢計劃可能很合理,而且您執行的查詢可能執行良好。 您可能永遠不知道您遇到優化工具逾時。
如果您發現需要微調和優化,請嘗試下列步驟。
步驟 1:建立基準
檢查您是否可以在不同的 SQL Server 組建上、使用不同的 CE 組態,或在不同的系統上執行相同的查詢, (硬體規格) 。 效能微調的指導準則是「沒有基準就不會有效能問題」。因此,請務必為相同的查詢建立基準。
步驟 2:尋找導致優化工具逾時的「隱藏」條件
詳細檢查您的查詢,以判斷其複雜性。 在初始檢查時,查詢可能並不明顯複雜,而且牽涉到許多聯結。 這裡的常見案例是涉及檢視或數據表值函式。 例如,在表面上,查詢可能看起來很簡單,因為它會聯結兩個檢視。 但是當您檢查檢視內的查詢時,您可能會發現每個檢視會聯結七個數據表。 因此,當兩個檢視聯結時,您最後會聯結 14 個數據表。 如果您的查詢使用下列物件,請向下切入至每個物件,以查看其中的基礎查詢外觀:
針對上述所有案例,最常見的解決方式是重寫查詢,並將其分成多個查詢。 如需詳細資訊,請參閱 步驟 7:精簡查詢 。
子查詢或衍生數據表
下列查詢是將兩組不同的查詢聯結 (衍生數據表的範例,) 每個數據表有 4-5 個聯結。 不過,由 SQL Server 剖析之後,它會編譯成已聯結八個數據表的單一查詢。
SELECT ...
FROM
( SELECT ...
FROM t1
JOIN t2 ON ...
JOIN t3 ON ...
JOIN t4 ON ...
WHERE ...
) AS derived_table1
INNER JOIN
( SELECT ...
FROM t5
JOIN t6 ON ...
JOIN t7 ON ...
JOIN t8 ON ...
WHERE ...
) AS derived_table2
ON derived_table1.Co1 = derived_table2.Co10
AND derived_table1.Co2 = derived_table2.Co20
(CTE) 的通用數據表運算式
使用多個通用數據表運算式 (CTE) 不是簡化查詢並避免優化工具逾時的適當解決方案。 多個 CTE 只會增加查詢的複雜度。 因此,在解決優化器逾時時使用 CTE 會產生反作用。 CTE 看起來就像是以邏輯方式中斷查詢,但它們會合併成單一查詢,並優化為單一大型數據表聯結。
以下是將編譯為具有許多聯結之單一查詢的 CTE 範例。 針對my_cte的查詢可能是兩個對象的簡單聯結,但事實上,CTE 中還有七個其他數據表已聯結。
WITH my_cte AS (
SELECT ...
FROM t1
JOIN t2 ON ...
JOIN t3 ON ...
JOIN t4 ON ...
JOIN t5 ON ...
JOIN t6 ON ...
JOIN t7 ON ...
WHERE ... )
SELECT ...
FROM my_cte
JOIN t8 ON ...
檢視
請確定您已檢查檢視定義,並已涉及所有數據表。 與 CTE 和衍生數據表類似,聯結可以在檢視內隱藏。 例如,兩個檢視之間的聯結最終可能是包含八個數據表的單一查詢:
CREATE VIEW V1 AS
SELECT ...
FROM t1
JOIN t2 ON ...
JOIN t3 ON ...
JOIN t4 ON ...
WHERE ...
GO
CREATE VIEW V2 AS
SELECT ...
FROM t5
JOIN t6 ON ...
JOIN t7 ON ...
JOIN t8 ON ...
WHERE ...
GO
SELECT ...
FROM V1
JOIN V2 ON ...
TVF) (數據表值函式
某些聯結可能會隱藏在 TFV 內。 下列範例顯示兩個 TFV 之間的聯結,而數據表可能是九個數據表聯結。
CREATE FUNCTION tvf1() RETURNS TABLE
AS RETURN
SELECT ...
FROM t1
JOIN t2 ON ...
JOIN t3 ON ...
JOIN t4 ON ...
WHERE ...
GO
CREATE FUNCTION tvf2() RETURNS TABLE
AS RETURN
SELECT ...
FROM t5
JOIN t6 ON ...
JOIN t7 ON ...
JOIN t8 ON ...
WHERE ...
GO
SELECT ...
FROM tvf1()
JOIN tvf2() ON ...
JOIN t9 ON ...
Union
等位運算子會將多個查詢的結果合併成單一結果集。 它們也會將多個查詢合併成單一查詢。 然後,您可能會收到單一、複雜的查詢。 下列範例最後會包含包含12個數據表的單一查詢計劃。
SELECT ...
FROM t1
JOIN t2 ON ...
JOIN t3 ON ...
JOIN t4 ON ...
UNION ALL
SELECT ...
FROM t5
JOIN t6 ON ...
JOIN t7 ON ...
JOIN t8 ON ...
UNION ALL
SELECT ...
FROM t9
JOIN t10 ON ...
JOIN t11 ON ...
JOIN t12 ON ...
步驟 3:如果您有執行速度較快的基準查詢,請使用其查詢計劃
如果您判斷您從 步驟 1 取得的特定基準計劃更適合透過測試進行查詢,請使用下列其中一個選項來強制 QO 選取該計劃:
步驟 4:減少計劃選擇
若要降低優化器逾時的機會,請嘗試降低 QO 在選擇方案時需要考慮的可能性。 此程式牽涉到使用不同的 提示選項來測試查詢。 和 QO 的大部分決策一樣,這些選擇在表面上不一定具決定性,因為需要考慮的因素有很多種。 因此,沒有單一保證成功的策略,而且選取的計劃可能會改善或降低所選查詢的效能。
強制聯結順序
使用 OPTION (FORCE ORDER) 來消除順序排列:
SELECT ...
FROM t1
JOIN t2 ON ...
JOIN t3 ON ...
JOIN t4 ON ...
OPTION (FORCE ORDER)
降低 JOIN 的可能性
如果其他替代方案沒有説明,請嘗試透過使用 聯結提示限制實體聯結運算符的選擇來減少查詢計劃組合。 例如: OPTION (HASH JOIN, MERGE JOIN)、 OPTION (HASH JOIN, LOOP JOIN) 或 OPTION (MERGE JOIN)。
注意: 使用這些提示時,您應該小心。
在某些情況下,使用較少的聯結選項來限制優化工具可能會導致無法使用最佳的聯結選項,而且實際上可能會使查詢變慢。 此外,在某些情況下,優化工具 (需要特定的聯結,例如數據 列目標) ,而且如果該聯結不是選項,查詢可能會無法產生計劃。 因此,將特定查詢的聯結提示設為目標之後,請檢查您是否找到可提供更佳效能的組合,並消除優化工具逾時。
以下是如何使用這類提示的兩個範例:
使用
OPTION (HASH JOIN, LOOP JOIN)僅允許哈希和循環聯結,並避免在查詢中合併聯結:SELECT ... FROM t1 JOIN t2 ON ... JOIN t3 ON ... JOIN t4 ON ... JOIN t5 ON ... OPTION (HASH JOIN, LOOP JOIN)在兩個資料表之間強制執行特定聯結:
SELECT ... FROM t1 INNER MERGE JOIN t2 ON ... JOIN t3 ON ... JOIN t4 ON ... JOIN t5 ON ...
步驟 5:變更 CE 設定
嘗試在舊版 CE 與新 CE 之間切換來變更 CE 設定。 當 SQL Server 評估並建立查詢計劃時,變更 CE 組態可能會導致 QO 挑選不同的路徑。 因此,即使發生優化器逾時問題,您最終還是可能會有比使用替代 CE 組態所選取的方案更理想的執行計劃。 如需詳細資訊,請 參閱如何啟用最佳查詢計劃 (基數估計) 。
步驟 6:啟用優化工具修正
如果您尚未啟用查詢優化器修正程式,請考慮使用下列兩種方法之一加以啟用:
- 伺服器層級:使用追蹤旗標 T4199。
- 資料庫層級:使用
ALTER DATABASE SCOPED CONFIGURATION ..QUERY_OPTIMIZER_HOTFIXES = ON或變更 SQL Server 2016 和更新版本的資料庫相容性層級。
QO 修正可能會導致優化工具在計劃探索中採取不同的路徑。 因此,它可能會選擇更理想的查詢計劃。 如需詳細資訊,請參閱 SQL Server 查詢優化器 Hotfix 追蹤旗標 4199 維護模型。
步驟 7:精簡查詢
請考慮使用臨時表,將單一多數據表查詢分割成多個個別查詢。 中斷查詢只是簡化優化工具工作的其中一種方式。 請參閱下列範例:
SELECT ...
FROM t1
JOIN t2 ON ...
JOIN t3 ON ...
JOIN t4 ON ...
JOIN t5 ON ...
JOIN t6 ON ...
JOIN t7 ON ...
JOIN t8 ON ...
若要將查詢優化,請嘗試將聯結結果的一部分插入臨時表中,以將單一查詢細分為兩個查詢:
SELECT ...
INTO #temp1
FROM t1
JOIN t2 ON ...
JOIN t3 ON ...
JOIN t4 ON ...
GO
SELECT ...
FROM #temp1
JOIN t5 ON ...
JOIN t6 ON ...
JOIN t7 ON ...
JOIN t8 ON ...
意見反應
即將登場:在 2024 年,我們將逐步淘汰 GitHub 問題作為內容的意見反應機制,並將它取代為新的意見反應系統。 如需詳細資訊,請參閱:https://aka.ms/ContentUserFeedback。
提交並檢視相關的意見反應