GPU-P 裝置上的即時移轉
本文說明透過SR-IOV(單一根 I/O 虛擬化)分割虛擬化異質計算裝置(GPU、NPU 等)即時移轉的功能設計。 支援透過 WDDM 和 MCDM 驅動程式模型進行分割的裝置現在是虛擬化供應專案不可或缺的一部分。 因此,請務必支援即時移轉,並協助虛擬化抽象概念在資源指派必須變更時,對客戶的影響變得極可靠。 本文也會說明 這些裝置的快速移 轉。
從 Windows 11 版本 24H2 (WDDM 3.2) 開始支援即時移轉。 對於公開功能的驅動程式而言,這通常是 GPU 半虛擬化 (GPU-P) DIS 的延伸模組。 實作 GPU-P 虛擬化介面的 MCDM 驅動程式也可以選擇性地實作這些即時移轉介面,包括具有分級事件的擴充功能。
在本文中,「GPU」只是指實作 GPU-P 虛擬化架構的裝置,無論是 WDDM 還是 MCDM,以及 GPU、NPU 或其他異質計算裝置。
資源移轉的種類和用途
資源移轉是將虛擬化移至新實體資源的能力。 有各種方式可以移動虛擬化執行,包括:
硬力壓倒。 虛擬主機板可以直接關閉電源,停止執行虛擬資源。 任何無法承受電源的應用程式都會遺失其正在運作的數據,且會抹除所有裝置狀態。 然後,虛擬硬碟 (VHD) 可以在不同的主計算機上虛擬化,這會導致冷開機。
軟電源關閉。 此關閉電源不同於硬式電源關閉,因為它只會將電源要求傳送至客體 OS。 然後,客體OS會將電源關閉機制散發給應用程式,以清除關機。 應用程式可以使用此通知安全地儲存所有數據,並在開機時註冊以重新啟動,不過它相依於每個應用程式的程序設計。 軟電源關閉需要客體 OS,其支援此清除關機機制,以及適當的服務來儲存目前狀態,並在重新啟動時重新啟動。
冬眠。 這個其他客體產生的技術可讓客體轉換到快速啟動的睡眠電源狀態,其中所有應用程式進程都會凍結,裝置狀態會清除至 CPU 記憶體,然後將所有記憶體傳送到記憶體,以允許硬體關閉電源。 然後,VM 記憶體 VHD 可以在不同的電腦上重新啟動,並載入記憶體、還原裝置狀態,以及未凍結的進程。 休眠僅適用於支援休眠的客體OS。 這是一個相當侵入性的程式,相依於客體穩定性,但它提供一個機制來還原應用程式進程,並提供關閉電源機制未提供的狀態。
快速移轉(也稱為 VM 儲存和還原)。 透過這項技術,VM 會暫停(vCPU 停止排程),而還原新實體資源所需的所有狀態都會收集在主機 OS 內,包括 VM 的記憶體和所有裝置的狀態。 然後,此狀態會傳送至新的主機,以建立已載入所有 vCPU 內容的 VM、將記憶體對應至 VM 空間,以及還原裝置狀態。 PowerOnRestore 接著會重新啟動 vCPU 的執行。 這項技術與客體 OS 無關,且不相依於客體環境中的執行,因此維護程式與裝置狀態的方式比休眠更可靠。 虛擬化使用者可能會注意到大量中斷時間,因為 VM 記憶體可能會有許多 GB,而且傳輸時間可能會明顯。
即時移轉。 如果我們能夠在虛擬化資源仍在使用中時傳輸內容,而且我們可以追蹤已遭抹去的內容,我們可以在讓虛擬化處於作用中狀態時傳輸重要內容。 然後,當 VM 暫停時,需要傳輸的內容要少得多,而且我們可以將虛擬化未執行的時間降到最低。 結果是將使用者的影響降至最低,因為移轉期間發生的所有作業都會繼續不受阻礙,而且資源耗用量率的影響會盡可能降低。 特別是中斷期限(虛擬化中斷的外部時間限制,例如 TCP 和其他外部端點的通訊協定逾時),可以最小化或消除。
每個進展都會減少或移除對虛擬化實體指派變更的一些(通常是主要)客戶感知,讓虛擬化對使用者更完整且更透明。 與其他技術(例如主機當機隔離)分開客戶對基礎結構的相依性,它會將虛擬化解決方案移至指派獨立和真正的暫時計算的理想。
大規模設計
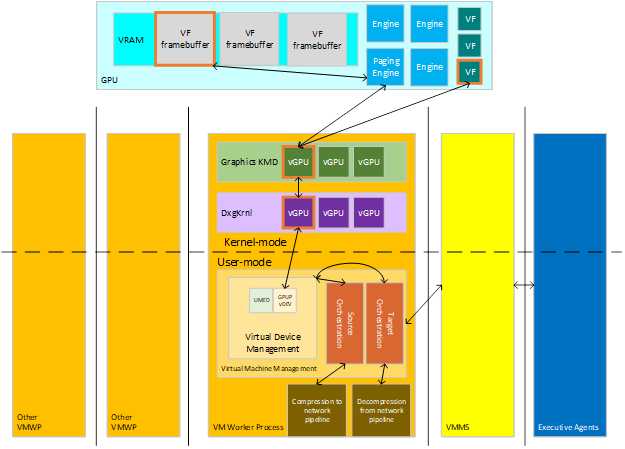
即時移轉會將虛擬化內容從來源主機傳輸到目標主機。 虛擬化包含各種具狀態裝置,可包含記憶體、計算和記憶體,每個裝置都必須從來源上的裝置傳輸到目標上的裝置的數據。 管理跨叢集虛擬化的執行代理程式會與主機通訊,讓他們知道為現有 VM 的來源移轉設定協調流程(當內容離開主機時)或目標移轉至新的 VM(以接收內容)。 下圖顯示此互動的主要參與者。
:
來源主機的 Epochs
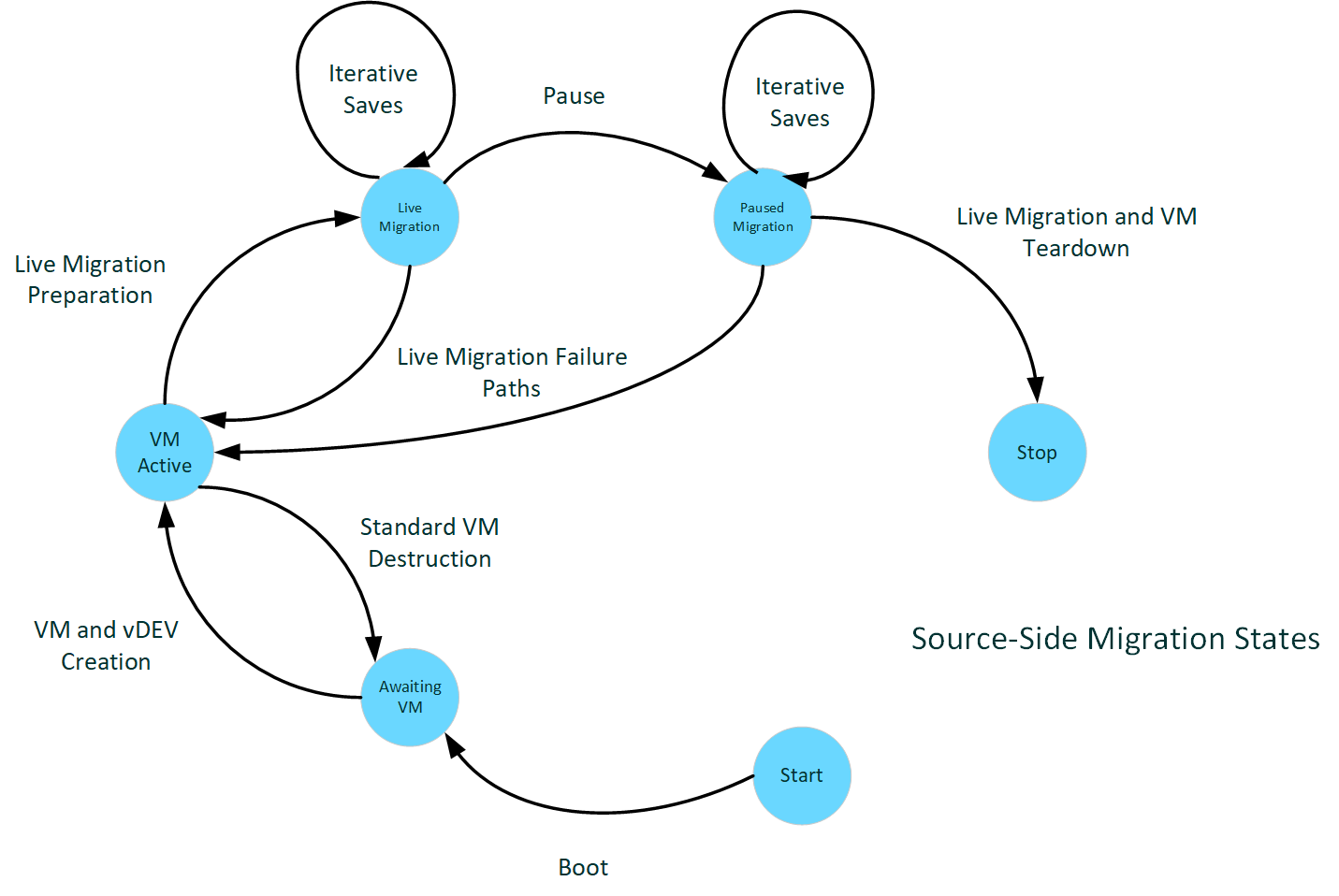
下圖說明來源端移轉狀態。
:
來源端開機
一般而言,當主機開機時,KMD 會透過各種初始化呼叫,向核心報告裝置功能。
當 KMD 收到DXGKQAITYPE_GPUPCAPS數據的 DxgkDdiQueryAdapterInfo 呼叫時,可以將新增至 DXGK_GPUPCAPS 的 LiveMigration 功能位。 當 KMD 設定此位時,表示驅動程式支援即時移轉。
即時移轉支援的必要條件是支持追蹤所有 GPU 本機記憶體區段上已修改 VRAM 頁面,如 Dirty 位追蹤中所述。 該支援會透過其他 DxgkDdiQueryAdapterInfo 呼叫其他指定的資訊類型來回報。 報告即時移轉支持的驅動程式也必須報告對髒位追蹤的支援。 支援即時移轉,但不是臟位追蹤是無效的組態, 且 Dxgkrnl 無法啟動配接器。
VM 上線
主機開機並管理堆疊上線后,虛擬機活動就會開始上線。 啟動和停止 VM 的要求會開始到達,我們開始查看投影到這些虛擬化的 GPU-P vCPU。
假設有效能的臟位平面功能,Dxgkrnl 會在保留 VF (虛擬函式)的 VRAM 資源之後呼叫 DxgkDdiStartDirtyTracking,讓系統在 VF 稍後參與移轉案例的情況下追蹤 VRAM 清潔度。
此 VM 啟動會開始攔截中斷數據表存取,以虛擬化中斷支援,這會繼續進行 VM 存留期。
即時移轉傳送準備
管理堆疊會傳送事件,以在其控件指出時開始即時移轉,而移轉狀態機器管理會從虛擬設備收集所有狀態,這些虛擬設備在虛擬化 (vGPU 數據分割組態計量) 的存留期內是不可變的,以便重新建構目標上的 vGPU。 準備好之後,會開始準備傳輸緩衝區和傳輸堆疊初始化的程式。
這個 epoch 會產生對引進的 DxgkDdiPrepareLiveMigration DDI 的呼叫。 KMD 應建立 PF/VF 排程原則,以提供即時移轉從主機中的 VRAM 串流臟內容的能力,同時保留 VF 的公平效能。 如果髒追蹤回報為效能不佳,此點也會是啟動骯髒追蹤的位置。
即時移轉傳送
:
然後,我們會進入髒 VRAM 傳輸的作用中階段。 此階段牽涉到透過骯髒的位平面 DDI 進行呼叫,以取得 VF framebuffer 的快照集,然後將這些頁面從 GPU 分頁到稍早備妥的 CPU 緩衝區。
此傳輸有一個階段,其中 VM 及其所有虛擬設備都會暫停。 VF 可以停止為來賓排程,而此時,可以提供給 PF 完成內容分頁的任何額外時間。 由於 VF 和 vCPU 都會在 VM 中暫停,因此在此點之後,應該不會進一步變更正在移轉的內容(CPU 或裝置本機記憶體)。
暫停的移轉傳送
已暫停時,會傳輸髒頁的最後一次反覆運算。 此時,系統會呼叫 來收集任何在作用中且無法在先前的準備中轉移的裝置和驅動程式狀態的最後一個片段。 此狀態可以是另一端所需的任何狀態重建、任何追蹤結構,或通常完成目標端 VF 狀態還原所需的所有資訊。
即時移轉終止
最後,一旦 VM 及其所有虛擬設備已將其狀態傳輸至其新的實體實現,來源端就可以清除 VM 剩餘專案。 清除緩衝區和其他移轉狀態,並終結 vGPU。
目標主機的 Epochs
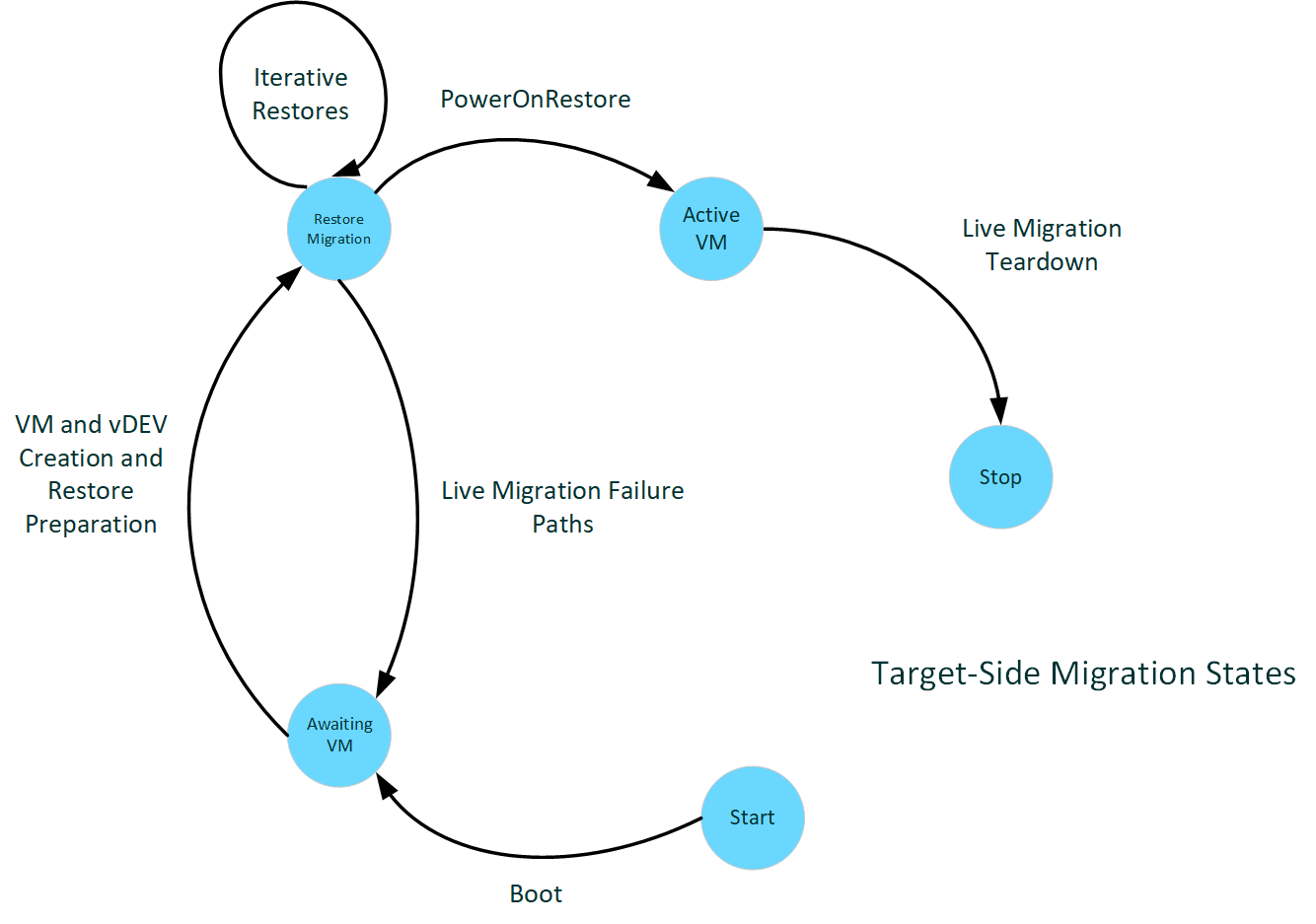
下圖說明目標端移轉狀態。
:
目標端開機
在目標上開機看起來與來源上的相同。 開機適用於整個系統,它可以是整個生命週期中不同 VF 的來源和目標。 驅動程式只需要指定即時移轉的支援才能參與。
即時移轉接收準備
在目標端,VM 的建構會如同是新的 VM 一樣開始建構。 VM 和虛擬設備會建立。 此建立程式包含虛擬 GPU,其使用在來源端建立的相同參數所建立。 建立之後,會接收驗證數據並傳遞至驅動程式,以驗證目標端是否與來源相容,以還原 VM。 此時,它應該確保任何可能會影響這類相容性的任何專案,包括驅動程式版本、韌體版本和其他目標系統和驅動程式的環境狀態。 驅動程式會設定為允許 PF 存取分頁的所有時間,這些分頁通常會指派給 VF,而該 VF 尚未使用中。
即時移轉接收
:
除了分頁方向是從 CPU 緩衝區到 VRAM 之外,接收髒頁面數據的階段與來源上的階段類似。 VF 暫停時會進行所有傳輸,因此可以在 VF 預算內完成整個傳輸。
VM 啟動和卸除
完成所有 VRAM 移轉之後,vGPU 就有機會設定任何需要傳輸的額外狀態(最終可變動的儲存數據)。 然後,我們會在目標上啟動 VM,並卸除移轉狀態,包括用於傳輸的緩衝區。
效能目標
即時移轉的重要部分是其回應性。 特別是,它會將虛擬化的停機時間降到最低,因為虛擬化不會在外部回應(無論是對虛擬化的使用者,或是可能進一步連線到的任何端點)。 許多網路堆棧通訊協定在重試/重新建立失敗之前,在遠端計算機之間都有相當短暫的逾時,因此在卸載時可能會對使用者造成干擾。 作為一個常見的固定目標,傳輸和開始的總暫停時間應該低於每秒三分之三(750毫秒),這會將時間從接觸推送到許多最常見的堆疊逾時之下。
此外,如果可能的話,作用中系統的效能變更不應該觸發其他終端用戶中斷。 在使用這些 DIS 的裝置中,系統不應該藉由減緩排程的時數,大幅提高 TDR 的速率。 現在,我們預期大部分的 TDR 不是很長的封包,而是會停止裝置,而執行封包的時間會翻倍或翻倍,不應該在數秒的大型逾時期間推送大部分封包。 但我們必須注意不要在一般效能圖片中觸發逾時。
設備驅動器介面
一般而言,即時移轉 DIS 是指 WDDM 和 MCDM DIS 的一般概念,特別是 GPU-P 虛擬化 DIS。
hAdapter 通常是指代表此驅動程式所管理之特定裝置的句柄令牌。 系統列舉多個實體裝置的系統可能會有驅動程式管理多個 hAdapter,因此 hAdapter 會當地語系化至特定裝置。
vfIndex 會識別所參考的虛擬函式 / vDEV。 它會當地語系化為特定的虛擬設備。 有時也稱為分割區標識碼。
DeviceLuid 也會當地語系化特定的虛擬設備,但會以 UMED 介面的語言與虛擬設備管理一起關閉。
SegmentId 會在參考儲存在裝置上的內容時識別特定的 VidMm 區段曝光,例如 VRAM 保留。
介面定義的注意事項
本文指的是動態大小的結構。 這些結構是透過動態大小的數位來實作,參考頁面會描述如下:
size_t ArraySize;
ElementType Array[ArraySize];
其中介面會傳遞稍早在 結構中的數位大小,以及介面物件的剖析,然後在提供數位時逐一查看該許多元素。 這些宣告無效,因為這些語言表示靜態大小的片段。 先在靜態大小結構中讀取,然後以動態方式剖析程序代碼。
裝置啟動和上限報告
下列功能會新增至 DXGK_GPUPCAPS:
- LiveMigration 上限表示驅動程式對即時移轉功能的支援(一般而言,除了 DxgkDdiSetVirtualGpuResources2 之外,本文所述的新增 DIS)。
- ScatterMapReserve cap 表示 DxgkDdiSetVirtualGpuResources2 的驅動程序支援,這會在未來版本中新增。
當OS以DXGKQAITYPE_GPUPCAPS要求呼叫 DxgkDdiQueryAdapterInfo 時,KMD 必須填寫這些上限。 呼叫 DxgkDdiStartDevice 之後,以及適配卡支援 GPU 分割之後,OS 會查詢裝置初始化期間上限。
如果驅動程式傳 回 ScatterMapReserve 上限,它必須公開具有下列相關結構的新增 DXGKQAITYPE_SCATTER_RESERVE 類型,讓 OS 可以查詢驅動程式的散佈保留功能:
- pInputData 的DXGK_QUERYSCATTERRESERVEIN
- pOutputData 的DXGK_QUERYSCATTERRESERVEOUT
散布分頁支援
為了支援從 framebuffer 來回傳輸不連續的髒頁面,此功能是第一個練習不受連續實體地址支援的 GPU-VA 對應之一。 目前的分頁介面不需要更新此支持,因為頁面數據表一直是一般的可能性。 但是,對於連續性做出假設的任何潛在實作詳細數據,都可能會受到這項變更的公開。 因此,請務必瞭解此OS機制、其如何執行虛擬分頁介面,並確保分頁對這項變更具有強固性。
特別是, TransferVirtual 介面現在會傳遞在 framebuffer 上未連續對應的 VA 範圍。
即時移轉開始傳送端
當系統啟動移轉的即時元件時,它必須呼叫新增 的 DxgkDdiPrepareLiveMigration DDI。 此呼叫會通知驅動程式此 Epoch 已啟動,並允許其設定移轉的 VF 排程原則,這應該為 PF 分頁分配一些免費和移轉 VF 預算。
Dxgkrnl 接著呼叫 KMD 的 DxgkDdiSaveImmutableMigrationData DDI 來收集裝置的相關信息,以在目標端還原。
系統收集並傳送不可變的數據和驗證數據之後,就會開始進行骯髒傳送的主要反覆迴圈。
反覆儲存/傳送
如概觀一節所述,反覆執行的儲存作業會使用 DxgkDdiQueryDirtyBitData,在每次反覆項目開始時建立 VF 目前的臟位平面快照,並使用標準DXGK_OPERATION_VIRTUAL_TRANSFER作業來分頁回報的髒頁面。 如果這項作業發生在其骯髒追蹤功能中回報的裝置上,表示其效能不會造成微不足道的影響,系統反覆專案控件會先啟用骯髒的追蹤,然後在第一次呼叫查詢臟位平面之前傳輸整個框架緩衝區。
針對虛擬傳輸,主要更新的行為是對應不是連續 VA 到連續 PA。 相反地,對應的PA頁面可能會中斷連線。 否則,行為如原始分頁和骯髒的位平面追蹤檔所述,此功能不會新增至該檔案。
即時移轉端傳送端
在移轉結束時,系統必須收集完成尚未傳輸之重建狀態和追蹤所需的所有裝置和驅動程序狀態。 無法傳輸此數據,因為它不符合先前移轉數據的不變性需求,而且不是VRAM臟內容。 Dxgkrnl 會呼叫新增 的 DxgkDdiSaveMutableMigrationData DDI 來執行此動作。 此 DDI 的使用方式類似於 DxgkDdiSaveImmutableMigrationData。
最後,當不再需要此 VF 上的移轉設定時,會呼叫 DxgkDdiEndLiveMigration。 所有排程和狀態都應該回到非移轉組態。
即時移轉開始接收端
當不可變的數據出現在接收端時,系統會透過對 DxgkDdiRestoreImmutableMigrationData 的呼叫,將它直接傳遞給 KMD。
這個 DDI 應該只針對目前暫停的 VF 呼叫。
反覆還原/接收
同樣地,散佈圖分頁會以反覆方式運作,但這次沒有呼叫來檢查 VF 所保留之 framebuffer 所保留的臟位平面,因為目標上的臟位平面是由分頁所建構。 分頁的方向會反轉。 接收緩衝區中的內容會傳送至 VRAM,並指定頁面的位置。
即時移轉端接收端
移轉即將結束之後,接收端系統會呼叫驅動程式的 DxgkDdiRestoreMutableMigrationData 函式,並搭配狀態的最終套件進行還原。 此套件應該提供驅動程式為了還原其狀態和追蹤而轉移的所有內容,以及剩餘的 VF 狀態還原。
這個 DDI 應該只針對目前暫停的 VF 呼叫。
在此呼叫之後,系統會呼叫 KMD 的 DxgkDdiEndLiveMigration 函式,讓目標端知道清除即時移轉周圍的任何狀態,包括還原正常的 VF 排程。
與 UMED 的通訊
使用者模式模擬 DLL (UMED) 介面會使用 IGPUPMigration 介面擴充,以公開在即時移轉期間儲存和驗證內容的能力。
HRESULT SaveImmutableGpup(
[in] PLUID DeviceLuid,
[in,out] UINT64 * Length,
[in,out] BYTE * SaveBuffer
);
HRESULT RestoreImmutableGpup(
[in] PLUID DeviceLuid,
[in] UINT64 Length,
[in] BYTE * RestoreBuffer
);
在類似呼叫 KMD 的即時移轉準備動作期間,UMED 有機會傳送任何可能有助於準備 UMED 的資訊,或驗證 環境支援 UMED 層級的移轉。 它是 UMED 標準介面合約的 UMED 選擇性介面(線程和進程內容、受限制的 OS 暴露等等)。 其呼叫模式會模擬 KMD DIS,並儲存兩個階段。 這些呼叫中沒有任何狀態旗標,就像其他儲存/還原UMED介面一樣,因為這些介面在裝置及其LUID生命週期中應該有效且持續。
UMED 的可變狀態會在現有的儲存/還原介面中傳輸。 在過去,此介面已封鎖使用 GPU-P 驅動程式執行,但在 KMD 報告 LiveMigration 支援時解除封鎖。 這個 UMED 圖說文字函式和 KMD 功能的系結是刻意的。 即時移轉是系統如何針對這些裝置的虛擬化實作快速移轉。 已完成相同的工作順序,而且您可以將快速移轉 (Save/Restore) 想像成沒有作用中傳輸的即時移轉特殊案例。 支援儲存/還原的UMED仍然需要具有支持即時移轉 DIS 的 KMD。 同樣地,UMED 必須注意 IGPUPMigration 介面,並評估其設計是否需要 KMD 才能即時移轉。
中斷虛擬化
客體中斷管理的實體尋址必須虛擬化,才能在移轉期間適當地服務 MSI-X 數據表存取,因為基礎硬體變更。 UMED 必須攔截支援即時移轉之所有驅動程式的 MSI-X 中斷數據表。 任何對 [訊息上限位址] 和 [郵件位址] 字段的讀取或寫入都必須對應至實際的硬體值。 Dxgkrnl 會維護虛擬化(或客體)地址的對應,並在呼叫堆疊中執行所需的替代作業。
OS 會管理數據表讀取或寫入之客體實體位址的虛擬化/對應,可能會參考客體端與實際中斷服務所需的主機實體位址。 此常見路徑不需要個別的 UMED 實作或核心轉送,而且 OS 不會在 OS 攔截數據表時通知 UMED。 UMED 的唯一需求是必須針對數據表的 BAR 頁面設定裝置風險降低功能。
不過,在核心中, Dxgkrnl 希望 KMD 服務實際寫入。 KMD 會藉由實作新增 的 DxgkDdiWriteVirtualizedInterrupt 回呼函式來執行此動作。
不應該需要讀取,因為 UMD 在本機追蹤寫入(以虛擬化/客體翻譯形式),因此不需要昂貴的核心跳躍。 此追蹤會使用虛擬設備進行移轉。
DDI 同步處理和 IRQL 內容
| DDI | 同步層級 | IRQL |
|---|---|---|
| DxgkDdiPrepareLiveMigration | 0 | PASSIVE |
| DxgkDdiEndLiveMigration | 0 | PASSIVE |
| DxgkDdiSaveImmutableMigrationData | 0 | PASSIVE |
| DxgkDdiSaveMutableMigrationData | 0 | PASSIVE |
| DxgkDdiRestoreImmutableMigrationData | 0 | PASSIVE |
| DxgkDdiRestoreMutableMigrationData | 0 | PASSIVE |
| DxgkDdiWriteVirtualizedInterrupt | 0 | PASSIVE |
| DxgkDdiSetVirtualGpuResources2 | 0 | PASSIVE |
| DxgkDdiSetVirtualFunctionPauseState | 0 | PASSIVE |
| IGPUPMigration::SaveImmutableGpup | 0 | PASSIVE |
| IGPUPMigration::RestoreImmutableGpup | 0 | PASSIVE |
VF 排程的重要考慮
傳輸的效率是由 PF 上的分頁傳輸排程所決定。 PF 可用來使總線飽和並取得最佳輸送量的裝置分頁引擎越多,傳輸一般效能越強,而且特別暫停的傳輸。 可以在指定時間內擷取和傳送的內容越多,越好:至少最多網路飽和度。
最好讓排程的變更只會影響分頁引擎,而不會影響其他裝置資源,但並非所有 VF 排程設計都允許這樣做。 至少需要排程:
- 只需從要移轉的 VF 或從未指派的 VF 排程取得預算。
- 不會降低電腦上任何其他虛擬化的效能。
請注意,在目標端,這些條件可以更容易滿足,因為 VF 會暫停整個傳輸,而且整個預算可供使用。 在來源端,它需要平衡移轉需求和 VM 需求,最終需要符合暫停傳輸目標。