本文提供 Active Directory 網域服務 容量規劃的建議(AD DS)。
容量規劃的目標
容量規劃與疑難解答效能事件不同。 容量規劃的目標是:
- 正確實作及操作環境。
- 將疑難解答效能問題所花費的時間降到最低。
在容量規劃中,組織在尖峰期間可能有 40% 處理器使用率的基準目標,以符合用戶端效能需求,並有足夠的時間升級數據中心的硬體。 同時,他們會在 5 分鐘的間隔內,將效能問題的監視警示閾值設定為 90%。
當您持續超過容量管理閾值時,新增更多或更快的處理器來增加容量,或調整跨多部伺服器的服務是解決方案。 當效能問題對客戶端體驗造成負面影響時,效能警示閾值可讓您知道何時需要立即採取行動。 相反地,疑難解答解決方案更關心處理一次性事件。
容量管理就像是避免車禍的預防措施,如防守駕駛、確保剎車正常運作等。 當員警、消防部門和緊急醫療專業人員回應事故時,效能疑難解答更像是。
過去幾年來,擴大系統的容量規劃指引有很大的變化。 系統架構中的下列變更會挑戰設計和調整服務的基本假設:
- 64 位元伺服器平台
- 虛擬化
- 日漸重視耗電量
- SSD 儲存體
- 雲端案例
容量規劃的方法也會從伺服器型規劃練習轉移到以服務為基礎的規劃練習。 Active Directory 網域服務 (AD DS)是一項成熟的分散式服務,許多Microsoft和第三方產品都作為後端使用,現在是確保其他應用程式擁有執行所需容量的最重要產品之一。
開始規劃之前要考慮的重要資訊
若要充分利用本文,您應該執行下列動作:
- 請確定您已閱讀並瞭解 Windows Server 2012 R2 的效能微調指導方針。
- 瞭解 Windows Server 平臺是以 x64 為基礎的架構。 此外,您必須瞭解本文的指導方針仍然適用,即使您的 Active Directory 環境安裝在 Windows Server 2003 x86 上(現在超過支援生命周期結束),而且具有小於 1.5 GB 且可以輕鬆地儲存在記憶體中的目錄資訊樹狀結構 (DIT)。
- 瞭解容量規劃是連續的程式,因此您應該定期檢閱您建置的環境是否符合預期。
- 瞭解隨著硬體成本變更,優化會在多個硬體生命週期上發生。 例如,如果記憶體變便宜,則每個核心的成本會降低,或不同記憶體選項的價格會變更。
- 規劃每天的高峰時段。 建議您根據 30 分鐘或小時間隔來制定計劃。 當服務實際達到尖峰容量時,大於一小時的間隔可能會隱藏,而小於 30 分鐘的間隔可提供不正確的資訊,讓暫時性增加看起來比實際更重要。
- 規劃企業在硬體生命週期各階段的成長。 此規劃可以包含以錯開的方式升級或新增硬體的策略,或每三到五年完整重新整理一次。 每個成長計劃都需要您估計 Active Directory 負載增加多少。 歷程記錄數據可協助您進行更精確的評量。
- 規劃容錯。 一旦您推導出估計值 N,請規劃考慮 N - 1、N - 2 和 N - x 的情境。
根據您的成長計劃,根據組織需要新增額外的伺服器,以確保遺失一或多部伺服器不會使系統超過最大尖峰容量估計值。
也請記住,您必須整合成長和容錯計劃。 例如,如果您知道您的部署目前需要一個域控制器 (DC) 來支援負載,但您的估計值表示,明年負載會加倍,而且需要兩個 DC 才能攜帶,則您的系統沒有足夠的容量來支援容錯。 為了防止這種容量不足,您應該改為計劃從三個 DC 開始。 如果您的預算不允許三個 DC,您也可以從兩個 DC 開始,然後計劃三到六個月後再增加三分之一。
注意
新增 Active Directory 感知應用程式可能會對 DC 負載造成明顯影響,無論負載來自應用程式伺服器還是用戶端。
三部分容量規劃週期
開始規劃週期之前,您必須決定組織所需的服務品質。 本文中的所有建議和指引都適用於最佳效能環境。 不過,您可以在不需要優化的情況下選擇性地放寬它們。 例如,如果您的組織需要較高層級的並行存取和更一致的用戶體驗,您應該查看設定數據中心。 數據中心可讓您更加注意備援,並將系統和基礎結構瓶頸降到最低。 相較之下,如果您只規劃一些使用者的衛星辦公室部署,就不需要擔心硬體和基礎結構優化,這可讓您選擇低成本的選項。
接下來,您應該決定要使用虛擬或實體機器。 從容量規劃的觀點來看,沒有正確或錯誤的答案。 不過,您必須記住,每個案例都會提供一組不同的變數來處理。
虛擬化案例提供兩個選項:
- 直接對應,其中每個宿主只有一個來賓。
- 共用主機 情境,其中在一個主機上有多個來賓。
您可以處理與實體主機相同的直接對應案例。 如果您選擇共用主機案例,它會介紹您應該在後續章節中考慮的其他變數。 共用主機也會與 Active Directory 網域服務 (AD DS) 競爭資源,這可能會影響系統效能和用戶體驗。
既然我們已回答這些問題,讓我們看看容量規劃週期本身。 每個容量規劃週期都包含三個步驟的程式:
- 測量現有的環境、判斷系統瓶頸目前的位置,並取得規劃部署需求容量所需的環境基本概念。
- 根據容量需求判斷您需要的硬體。
- 監視並驗證您設定的基礎結構是否在規格內運作。 您在此步驟中收集的數據會成為下一個容量規劃週期的基準。
運用程序
若要將效能優化,請確定已正確選取下列主要元件,並調整為應用程式負載:
- 記憶體
- 網路
- 儲存體
- 處理器
- Netlogon
AD DS 的基本記憶體需求和相容用戶端軟體的一般行為可讓多達 10,000 到 20,000 位使用者的環境忽略實體硬體的容量規劃,因為大多數新式伺服器類別系統已經可以處理該大小的負載。 不過, 數據收集摘要表中 的數據表會說明如何評估現有的環境以選取正確的硬體。 之後的各節會進一步詳細說明硬體的基準建議和環境特定原則,以協助AD DS系統管理員評估其基礎結構。
規劃時,您應該記住的其他資訊:
- 根據目前數據的任何重設大小都僅適用於目前環境。
- 進行預估時,預期需求會在硬體生命週期內成長。
- 藉由判斷您今天應該將環境過大,或逐漸在生命周期過程中新增容量,以因應未來的成長。
- 您套用至實體部署的所有容量規劃原則和方法,也適用於虛擬化部署。 不過,在規劃虛擬化環境時,您必須記得將虛擬化額外負荷新增至任何與網域相關的規劃或估計。
- 容量規劃是預測,不是完全正確的值,所以不要期望它完全準確。 請記得視需要調整容量,並持續驗證您的環境是否如預期般運作。
資料收集摘要表
下表列出並說明判斷硬體估計值的準則。
工作環境
| 元件 | 估計值 |
|---|---|
| 儲存體/資料庫大小 | 每個使用者 40 KB 到 60 KB |
| 記憶體 | 資料庫大小 基本作業系統建議 第三方應用程式 |
| 網路 | 1 GB |
| 中央處理器 | 每個核心有 1,000 個並行使用者 |
高階評估準則
| 元件 | 評估準則 | 規劃考量 |
|---|---|---|
| 記憶體/資料庫大小 | 離線重組 | |
| 記憶體/資料庫效能 |
|
|
| 記憶體 |
|
|
| 網路 |
|
|
| 中央處理器 |
|
|
| NetLogon(網路登入) |
|
|
規劃
很長一段時間,AD DS 重設大小的一般建議是將 RAM 放入資料庫大小一樣多。 現在,AD DS 環境和取用它們的生態系統已經成長得更大,事情已經改變。 雖然從 x86 架構增加計算能力和從 x64 切換到 x64,但對於在實體機器上執行 AD DS 的客戶而言,調整效能的細微層面並不重要,但虛擬化已大幅調整。
為了解決這些問題,下列各節說明如何判斷及規劃 Active Directory 即服務的需求。 不論您的環境是實體、虛擬化還是混合,您都可以將這些指導方針套用至任何環境。 為了將效能最大化,您的目標應該是盡可能接近處理器系結的 AD DS 環境。
記憶體
您可以在 RAM 中快取的記憶體越多,就不需要移至磁碟。 若要最大化伺服器延展性,您使用的 RAM 數量應該等於目前資料庫大小的總和、系統總值大小、操作系統的建議數量,以及代理程式 (防病毒軟體程式、監視、備份等) 的廠商建議。 您也應該包含額外的 RAM,以因應伺服器存留期的未來成長。 此估計值會根據資料庫成長和環境變更而變更。
對於將記憶體最大化在成本效益上不合算或不可行的環境,例如衛星據點或當目錄資訊樹狀結構(DIT)過大時,請直接跳到儲存空間,以確保您的儲存空間已正確設定。
重設大小記憶體的另一個重要事項是頁面檔案重設大小。 在磁碟大小調整中,就像與記憶體相關的一切一樣,目標是將磁碟使用量降至最低。 特別是您需要多少 RAM 才能將分頁降到最低? 接下來的幾節應該提供您回答這個問題所需的資訊。 不一定影響 AD DS 效能的頁面大小其他考慮是作業系統 (OS) 建議,以及設定您的系統以進行記憶體轉儲。
由於許多複雜的因素,判斷域控制器 (DC) 需要多少 RAM 可能會很困難:
- 現有的系統不一定是 RAM 需求的可靠指標,因為本地安全機構子系統服務 (LSSAS) 會在記憶體壓力條件下修剪 RAM,人為地降低需求。
- 個別 DC 只需要快取其用戶端感興趣的數據。 這表示在不同環境中快取的數據會根據它所包含的用戶端類型而變更。 例如,在具有 Exchange Server 的環境中,DC 會收集與只驗證使用者的 DC 不同的數據。
- 您必須依案例評估每個 DC 的 RAM 投入量,通常是過度的,而且隨著環境變更而變更。
建議背後的準則可協助您做出更明智的決策:
- 在 RAM 中快取越多,您只需要移至磁碟。
- 記憶體是電腦最慢的元件。 以主軸為基礎的和 SSD 儲存媒體上的數據存取速度比 RAM 中的數據存取慢一百萬倍。
RAM 的虛擬化考量
優化 RAM 的目標是將花費的時間量降到最低。 您也應該避免主機上的記憶體過度認可。 在虛擬化案例中,記憶體過度認可是當系統配置更多 RAM 給客體時,比實體機器本身存在更多的 RAM。 雖然過度認可本身並無問題,但當所有來賓使用的記憶體總計超過主機 RAM 的功能時,就會讓主機分頁。 分頁會在 DC 移至 NTDS.nit 或頁面檔案以取得數據或主機移至磁碟以嘗試存取 RAM 數據的情況下,進行效能磁碟系結。 因此,此程式可大幅降低效能和整體用戶體驗。
計算摘要範例
| 元件 | 估計記憶體 (範例) |
|---|---|
| 基本作業系統建議的 RAM (Windows Server 2008) | 2 GB |
| LSASS 內部工作 | 200 MB |
| 監視代理程式 | 100 MB |
| 防毒 | 100 MB |
| 資料庫 (通用類別目錄) | 8.5 吉位元組 |
| 讓備份得以執行的緩衝,系統管理員可順利登入不受影響 | 1 GB |
| 總數 | 12 GB |
建議:16 GB
經過一段時間后,資料庫會新增更多數據,而平均伺服器壽命約為三到五年。 根據成長估計值 333%,16 GB 是放入實體伺服器的合理 RAM 數量。
網路
本節將討論評估部署所需的總頻寬和網路容量、包含客戶端查詢、組策略設定等等。 您可以使用和 Network Interface(*)\Bytes Received/sec 性能計數器收集數據,以進行預估Network Interface(*)\Bytes Sent/sec。 網路介面計數器的取樣間隔應該是 15、30 或 60 分鐘。 對於良好的測量而言,任何較少的項目都會太揮發,任何更大的項目都會過度平滑每日尖峰。
注意
一般而言,DC 上的多數網路流量都是輸出流量,因為 DC 會回應用戶端查詢。 因此,本節主要著重於輸出流量。 不過,我們也建議您評估每個環境是否有輸入流量。 您也可以使用本文中的指導方針來評估輸入網路流量需求。 如需詳細資訊,請參閱 929851:Windows Vista 和 Windows Server 2008 中 TCP/IP 的預設動態埠範圍已變更。
頻寬需求
規劃網路可擴縮性涵蓋兩個不同的類別:流量的數量,以及來自網路流量的 CPU 負載。
規劃流量支援時,您需要考慮兩件事。 首先,您必須知道 DC 之間有多少 Active Directory 複寫流量 。 其次,您必須評估內部月臺用戶端對伺服器流量。 站內流量主要會接收來自用戶端的小型要求,相對於其傳回給用戶端的大量數據。 100 MB 通常足以讓每部伺服器最多5,000位用戶的環境使用。 針對超過 5,000 位使用者的環境,建議您改用 1 GB 的網路適配器和接收端調整 (RSS) 支援。
若要評估網站內部流量容量,特別是在伺服器匯總案例中,您應該查看 Network Interface(*)\Bytes/sec 站臺中所有 DC 的性能計數器,將它們加在一起,然後將總和除以 DC 的目標數目。 計算此數字的簡單方式是開啟 Windows 可靠性和效能監視器 ,並查看 堆棧區域 檢視。 請確定所有計數器的縮放比例都相同。
讓我們看看一個更複雜的方法範例,以驗證此一般規則是否適用於特定環境。 在此範例中,我們會進行下列假設:
- 目標是盡可能減少伺服器的耗用資源。 在理想情況下,一部伺服器會攜帶負載,然後您部署額外的伺服器以進行備援(n + 1 案例)。
- 在此案例中,目前的網路適配器僅支援 100 MB,且位於交換器環境中。
- 在 n 情境(資料中心失效)中,目標網路頻寬利用率上限為 60%。
- 每部伺服器約有 10,000 個連線的用戶端。
現在,讓我們看看計數器中 Network Interface(*)\Bytes Sent/sec 有關此範例案例的圖表內容:
- 營業日開始在上午5:30左右上升,下午7:00開始下降。
- 最繁忙的期間是從上午 8:00 到上午 8:15,在最繁忙的 DC 上每秒傳送超過 25 個字節。
注意
所有效能數據都是歷史數據,因此尖峰數據點在上午 8:15 表示從上午 8:00 到上午 8:15 的負載。
- 上午 4:00 之前有尖峰,在最繁忙的 DC 上每秒傳送超過 20 個字節,這可能表示來自不同時區或背景基礎結構活動的負載,例如備份。 由於上午 8:00 的尖峰超過此活動,因此並不相關。
- 網站中有五個 DC。
- 每個 DC 的負載上限約為 5.5 MBps,代表 100 MB 連線的 44%。 使用此數據,我們估計上午 8:00 到上午 8:15 之間的總頻寬為 28 MBps。
注意
網路介面傳送/接收計數器是以位元組為單位,但網路頻寬是以位來測量。 因此,若要計算總頻寬,您必須執行 100 MB ÷ 8 = 12.5 MB 和 1 GB ÷ 8 = 128 MB。
既然我們已經檢閱過數據,我們可以從中得出哪些結論?
- 目前的環境達到 n + 1 容錯層級, 並符合 60% 目標使用率。 離線一個系統會將每部伺服器的頻寬從大約5.5 MBps (44%) 轉移到約7 MBps (56%)。
- 根據先前所述的合併到一部伺服器的目標,這項變更超過最大目標使用率和 100 MB 連線的可能使用率。
- 使用 1 GB 連線時,此值代表總容量的 22%。
- 在 n + 1 案例的正常作業條件下,用戶端負載相對平均地分散在每部伺服器約 14 MBps,或總容量的 11%。
- 為了確保在DC無法使用時有足夠的容量,每部伺服器的一般作業目標大約是30%的網路使用率或每部伺服器的38 MBps。 故障轉移目標為每部伺服器 60% 的網路使用率或 72 MBps。
最終系統部署必須有 1 GB 的網路適配器,以及連線到將支援上述負載的網路基礎結構。 由於網路流量數量,來自網路通訊的CPU負載可能會限制AD DS的最大延展性。 您可以使用這個相同的程式來估計 DC 的輸入通訊。 不過,在大部分情況下,您不需要計算輸入流量,因為它小於輸出流量。
請務必確定您的硬體在具有每部伺服器超過5,000位用戶的環境中支援 RSS。 針對高網路流量案例,平衡中斷負載可能是瓶頸。 您可以藉由檢查 Processor(*)\% Interrupt Time 計數器來偵測潛在的瓶頸,以查看中斷時間是否不平均分散於 CPU。 啟用 RSS 的網路介面控制器 (NIC) 可以減輕這些限制並增加延展性。
注意
您可以在合併數據中心或淘汰衛星位置中的DC時,採取類似的方法來估計是否需要更多容量。 若要估計所需的容量,只需查看客戶端輸出和輸入流量的數據。 結果是廣域網 (WAN) 連結中存在的 od 流量量。
在某些情況下,由於流量速度較慢 (例如,憑證檢查未能符合 WAN 上的主動逾時),可能會產生比預期更多的流量。 因此,WAN 大小調整和使用率應為反覆持續進行的程序。
網路頻寬的虛擬化考量
實體伺服器的一般建議是支持超過5,000位使用者之伺服器的1 GB。 一旦多個來賓開始共享基礎虛擬交換器基礎結構,您應該特別注意主機是否有足夠的網路頻寬來支持系統中的所有來賓。 不論網路是否包含以 VM 身分在主機上執行的 DC,以及透過虛擬交換器或直接連線到實體交換器的網路流量,您都需要考慮頻寬。 虛擬交換器是上行鏈接必須支援連線傳輸的數據量,這表示連結至交換器的實體主機網路適配器應該能夠支援 DC 負載,以及共用連線到實體網路適配器之虛擬交換器的其他所有來賓。
網路計算摘要範例
下表包含範例案例中的值,可用來計算網路容量:
| 系統 | 尖峰頻寬 |
|---|---|
| 直流 1 | 6.5 Mbps 的 |
| 直流 2 | 6.25 Mbps 的 |
| 直流 3 | 6.25 Mbps 的 |
| 直流 4 | 5.75 兆位元組 |
| 直流 5 | 4.75 Mbps |
| 總數 | 28.5 Mbps |
根據下表,建議的頻寬為 72 MBps (28.5 MBps ÷ 40%)。
| 目標係統計數 | 總頻寬 (如前所述) |
|---|---|
| 2 | 28.5 Mbps |
| 產生的正常行為 | 28.5 ÷ 2 = 14.25 Mbps |
一如往常,您應該假設用戶端負載會隨著時間增加,因此您應該儘早規劃此成長。 建議您規劃至少 50% 的估計網路流量成長。
儲存體
儲存體容量規劃時,您應該考慮兩件事:
- 容量或記憶體大小
- 效能
雖然容量很重要,但請務必不要忽視效能。 由於目前的硬體成本,大部分的環境都不夠大,因此任一因素都不足以成為主要考慮。 因此,通常的建議是只放入與資料庫大小一樣多的 RAM。 不過,對於較大環境中的衛星位置,這項建議可能會過度使用。
調整大小
評估儲存體
相較於 Active Directory 第一次到達時,4 GB 和 9 GB 磁碟驅動器是最常見的磁碟驅動器大小,現在 Active Directory 的大小甚至不是除了最大的環境考慮。 使用 180 GB 範圍內的最小可用硬碟大小時,整個作業系統、SYSVOL 和 NTDS.dit 都可輕易安置在一個磁碟機上。 因此,我們建議您避免在此領域投入太多資金。
我們唯一的建議是,您確定有 110% 的 NTS.dit 大小可供使用,以便重組您的記憶體。 除此之外,您應該採取一般考慮來適應未來的增長。
如果您要評估記憶體,您必須先評估NTDS.dit和SYSVOL的大小。 這些度量可協助您調整固定磁碟和 RAM 配置的大小。 由於元件成本相對較低,因此在進行數學運算時不需要超級精確。 如需記憶體評估的詳細資訊,請參閱 Active Directory 使用者和組織單位的記憶體限制和成長估計值。
注意
上一個段落中連結的文章是以 Windows 2000 中 Active Directory 版本期間所做的數據大小估計為基礎。 進行自己的估計時,請使用物件大小來反映環境中對象的實際大小。
當您檢閱具有多個網域的現有環境時,您可能會注意到資料庫大小的變化。 當您發現這些變化時,請使用最小的全域編錄 (GC) 和非 GC 大小。
資料庫大小可能會因操作系統版本而異。 執行 Windows Server 2003 等舊版作業系統的 DC,其資料庫大小比執行 Windows Server 2008 R2 等更新版本的電腦還要小。 已啟用 Active Directory REcycle Bin 或認證漫遊等功能的 DC 也會影響資料庫大小。
注意
- 針對新的環境,請記住,相同網域中的100,000位使用者耗用大約450 MB的空間。 您填入的屬性可能會對耗用的總空間量產生巨大影響。 屬性會由來自第三方和Microsoft產品的許多物件填入,包括 exchange Server 和 Lync Microsoft。 因此,建議您根據環境的產品組合進行評估。 不過,您也應該記住,針對除了最大環境的所有精確估計值執行數學和測試,可能不值得大量時間或精力。
- 請確定您可用的可用空間是 NTDS.dit 大小的 110%,以啟用離線重組。 此可用空間也可讓您規劃伺服器三到五年硬體生命周期的成長。 如果您有記憶體,配置足夠的可用空間以等於 300% 的 DIT 進行儲存是一種安全的方式來容納成長和脫落。
儲存體的虛擬化考量
在將多個虛擬硬碟 (VHD) 檔案配置給單一磁碟區的案例中,您應該使用至少 210% 的固定狀態磁碟 DIT 大小(100% 的 DIT + 110% 可用空間),以確保您有足夠的空間保留您的需求。
記憶體計算摘要範例
下表列出您用來估計假設儲存案例空間需求的值。
| 在評估階段收集的資料 | 大小 |
|---|---|
| NTDS.dit 大小 | 35 吉位元組 |
| 允許離線磁碟重組的修飾詞 | 2.1 吉位元組 |
| 所需的儲存體總計 | 73.5 吉位元組 |
注意
記憶體估計值也應該包含 SYSVOL、OS、頁面檔案、臨時檔、本機快取數據,例如安裝程式檔案和應用程式所需的記憶體量。
儲存體效能
作為任何電腦內最慢的元件,儲存體可能會對用戶端體驗產生最大的負面影響。 對於足以讓本文中的 RAM 重設大小建議無法運作的環境,忽略記憶體容量規劃的後果可能會對系統效能造成毀滅性的影響。 可用儲存技術的複雜性和品種會進一步增加風險,因為將OS、記錄和資料庫放在不同實體磁碟上的一般建議不會在所有案例中普遍套用。
關於磁碟的舊建議假設磁碟是允許隔離 I/O 的專用主軸。 由於引進下列記憶體類型,此假設已不再成立:
- 襲擊
- 新的儲存體類型和虛擬化與共用儲存體案例
- 存放區域網路 (SAN) 上的共用主軸
- SAN 或網路連結儲存體上的 VHD 檔案
- 固態硬碟 (SSD)
- 分層式儲存架構,例如 SSD 儲存層快取較大的主軸型記憶體
共用記憶體,例如RAID、SAN、NAS、JBOD、儲存空間和 VHD,都能夠由您在後端記憶體上放置的其他工作負載多載。 這些類型的記憶體也帶來額外的挑戰:實體磁碟與 AD 應用程式之間的 SAN、網路或驅動程式問題可能會導致節流和延遲。 為了釐清這些設定不是錯誤的組態,但它們更為複雜,這表示您需要特別注意,以確保每個元件都能如預期般運作。 如需更詳細的說明,請參閱本文稍後的 附錄 C 和 附錄 D 。 此外,雖然 SSD 不受一次只能處理一個 I/O 的硬碟所限制,但它們仍有可多載的 I/O 限制。
總而言之,不論記憶體架構為何,所有記憶體效能規劃的目標是確保所需的 I/O 數目一律可供使用,而且它們會在可接受的時間範圍內發生。 如需本機附加儲存裝置的案例,請參閱 附錄 C 以了解設計和規劃的更多資訊。 您可以將附錄中的原則套用至更複雜的記憶體案例,以及與支援後端記憶體解決方案的廠商交談。
由於目前可用的記憶體選項數目,建議您諮詢硬體支援小組或廠商,同時規劃確保解決方案符合 AD DS 部署的需求。 在這些交談期間,您可能會發現下列性能計數器很有説明,特別是當您的資料庫太大而無法使用 RAM 時:
-
LogicalDisk(*)\Avg Disk sec/Read(例如,如果 NTDS.dit 儲存在磁碟驅動器 D 上,則完整路徑會是LogicalDisk(D:)\Avg Disk sec/Read) LogicalDisk(*)\Avg Disk sec/WriteLogicalDisk(*)\Avg Disk sec/TransferLogicalDisk(*)\Reads/secLogicalDisk(*)\Writes/secLogicalDisk(*)\Transfers/sec
當您提供數據時,您應該確定其取樣間隔為15、30或60分鐘,以盡可能精確呈現您目前環境的情況。
評估結果
本節著重於從資料庫讀取,因為資料庫通常是最苛刻的元件。 您可以藉由替代 <NTDS Log>)\Avg Disk sec/Write 和 LogicalDisk(<NTDS Log>)\Writes/sec),將相同的邏輯套用至記錄檔。
計數器 LogicalDisk(<NTDS>)\Avg Disk sec/Read 會顯示目前記憶體的大小是否適當。 如果值大致等於磁碟類型預期的磁碟存取時間,計數器 LogicalDisk(<NTDS>)\Reads/sec 就是有效的量值。 如果結果大致等於磁碟類型的磁碟存取時間,計數器 LogicalDisk(<NTDS>)\Reads/sec 就是有效的量值。 雖然這可能會根據後端記憶體的製造商規格而變更,但 適合 LogicalDisk(<NTDS>)\Avg Disk sec/Read 的範圍大致如下:
- 7200 rpm:9 到 12.5 毫秒 (毫秒)
- 10,000 rpm:6 到 10 毫秒
- 15,000 rpm:4 到 6 毫秒
- SSD – 1 到 3 毫秒
您可能會收到其他來源,指出記憶體效能會降低為 15 毫秒到 20 毫秒。 這些值與上述清單中的值之間的差異在於清單值會顯示一般作業範圍。 其他值用於疑難解答目的,可協助您識別客戶端體驗何時降級,使其變得明顯。 如需詳細資訊,請參閱 附錄 C。
-
LogicalDisk(<NTDS>)\Reads/sec是系統目前正在執行的 I/O 數量。- 如果
LogicalDisk(<NTDS>)\Avg Disk sec/Read位於後端記憶體的最佳範圍內,您可以直接用來LogicalDisk(<NTDS>)\Reads/sec調整記憶體的大小。 - 如果
LogicalDisk(<NTDS>)\Avg Disk sec/Read不是後端記憶體的最佳範圍,則根據下列公式需要額外的 I/O:LogicalDisk(<NTDS>)\Avg Disk sec/Read÷實體媒體磁碟存取時間×LogicalDisk(<NTDS>)\Avg Disk sec/Read
- 如果
當您進行這些計算時,以下是您應該考慮的一些事項:
- 如果伺服器有次佳的 RAM 數量,產生的值會太高,而且無法正確進行規劃。 不過,您仍然可以使用它們來預測最壞的情況。
- 如果您新增或優化 RAM,也會減少讀取 I/O
LogicalDisk(<NTDS>)\Reads/Sec的數量。 此減少可能會導致記憶體解決方案不如原始計算所猜測的健全。 不幸的是,我們無法更具體說明此語句的意義,因為計算會因個別環境,特別是用戶端負載而有很大的差異。 不過,建議您在優化 RAM 之後調整記憶體大小。
效能的虛擬化考量
就像前幾節一樣,我們的目標是確保共用基礎結構可支援所有取用者的總負載。 規劃下列案例時,您必須記住此目標:
- 實體 CD 會與其他伺服器或應用程式共用 SAN、NAS 或 iSCSI 基礎結構上的相同媒體。
- 使用傳遞存取共享媒體之SAN、NAS 或iSCSI基礎結構的使用者。
- 在本機共用媒體或SAN、NAS 或iSCSI基礎結構上使用 VHD 檔案的使用者。
從來賓用戶的觀點來看,必須經過主機來存取任何記憶體會影響效能,因為用戶必須向下移動其他程式碼路徑以取得存取權。 效能測試表示虛擬化會影響根據主機系統使用多少處理器的輸送量。 處理器使用率也會受到客體使用者要求主機多少資源的影響。 此需求會影響您在虛擬化場景中針對處理需求所需考量的虛擬化因素。 如需詳細資訊,請參閱 附錄 A。
進一步複雜的事情是目前可用的記憶體選項數目,每個選項都有非常不同的效能影響。 這些選項包括傳遞記憶體、SCSI 適配卡和 IDE。 從實體移轉至虛擬環境時,您應該使用乘數 1.10 來調整虛擬化來賓使用者的不同記憶體選項。 不過,在不同的儲存案例之間傳輸時,您不需要考慮調整,因為記憶體是本機、SAN、NAS 或 iSCSI 更重要。
虛擬化計算範例
確認正常作業條件下,狀況良好的系統所需的 I/O 數量:
- LogicalDisk(
<NTDS Database Drive>) 在尖峰期間 15 分鐘期間每秒÷傳輸 - 若要確認超過基礎儲存體容量的儲存體所需的 I/O 數量:
所需的 IOPS = (LogicalDisk(
<NTDS Database Drive>) ÷ Avg Disk Read/sec ÷<Target Avg Disk Read/sec>) × LogicalDisk(<NTDS Database Drive>)\Read/sec
| 計數器 | 值 |
|---|---|
Actual LogicalDisk(<NTDS Database Drive>)\Avg Disk sec/Transfer |
.02 秒 (20 毫秒) |
Target LogicalDisk(<NTDS Database Drive>)\Avg Disk sec/Transfer |
.01 秒 |
| 可用 I/O 變更的乘數 | 0.02 ÷ 0.01 = 2 |
| 值名稱 | 值 |
|---|---|
LogicalDisk(<NTDS Database Drive>)\Transfers/sec |
400 |
| 可用 I/O 變更的乘數 | 2 |
| 尖峰時段所需的 IOPS 總計 | 800 |
若要判斷您應該將快取暖的速率:
- 決定您在快取變暖上花費可接受的時間上限。 在一般案例中,可接受的時間量是從磁碟載入整個資料庫所花費的時間長度。 在 RAM 無法載入整個資料庫的案例中,請使用填滿整個 RAM 所需的時間。
- 判斷資料庫的大小,但不包括您不打算使用的空間。 如需詳細資訊,請參閱 評估儲存。
- 將資料庫大小除以 8 KB,以取得載入資料庫所需的 I/O 總數。
- 將 I/O 總數除以所定義時間範圍內秒數。
您計算的數位大多精確,但可能不是確切的,因為您尚未設定 (Extensible Storage Engine) ESE 具有固定快取大小,因此 AD DS 會收回先前載入的頁面,因為它預設會使用可變快取大小。
| 要收集的資料點 | 值 |
|---|---|
| 暖化可接受的時間上限 | 10 分鐘 (600 秒) |
| 資料庫大小 | 2 GB |
| 計算步驟 | 公式 | 結果 |
|---|---|---|
| 計算資料庫的大小 (以頁面為單位) | (2 GB × 1024 × 1024) = KB 中的資料庫大小 | 2,097,152 KB |
| 計算資料庫中的頁數 | 2,097,152 KB ÷ 8 KB = 頁數 | 262,144 個頁面 |
| 計算完全暖化快取所需的 IOPS | 262,144 頁÷ 600 秒 = 所需的 IOPS | 437 次 IOPS |
加工業
評估 Active Directory 處理器使用量
對於大部分的環境而言,管理處理容量是值得最注意的元件。 當您評估部署所需的 CPU 容量時,您應該考慮下列兩件事:
- 您環境中的應用程式是否如預期般在共用服務基礎結構中運作,以 追蹤昂貴且無效率的搜尋中所述的準則為基礎? 在較大的環境中,程式代碼不佳的應用程式可能會讓CPU負載變得不穩定、花費大量CPU時間,以犧牲其他應用程式為代價、提高容量需求,以及不平均地將負載分散到DC。
- AD DS 是分散式環境,有許多潛在用戶端的處理需求差異很大。 每個客戶端的估計成本可能會因使用模式和使用 AD DS 而有所不同。 就像在網路中一樣,您應該將評估視為對環境中所需總容量的評估,而不是一次只關注每個用戶。
只有在完成 記憶體 估計之後,您才應該進行此估計,因為若沒有處理器負載的有效數據,就無法進行精確的猜測。 在針對處理器進行疑難解答之前,請務必確定記憶體不會造成任何瓶頸。 當您移除處理器等候狀態時,CPU 使用率會增加,因為它不再需要等候數據。 因此,您應該最注意的性能計數器是 Logical Disk(<NTDS Database Drive>)\Avg Disk sec/Read 和 Process(lsass)\ Processor Time。
Logical Disk(<NTDS Database Drive>)\Avg Disk sec/Read如果計數器超過 10 或 15 毫秒,則中的Process(lsass)\ Processor Time數據會人為地低,且問題與記憶體效能有關。 我們建議您將取樣間隔設定為15、30或60分鐘,以取得最精確的數據。
處理概觀
進行網域控制站的容量規劃時,最需要關注和了解的是處理能力。 當調整系統的大小以確保最大效能時,一律會有瓶頸的元件,而且在適當大小的域控制器中,此元件是處理器。
類似於就個別站台來檢閱環境需求的網路區段,對於所需的計算容量也必須執行相同的作業。 不同於網路區段 (其可用的網路技術遠遠超出正常需求),請更加專注於 CPU 容量的大小調整。 與任何中等規模的環境相同;只要有超過數千名並行使用者,都可能對 CPU 造成龐大負載。
遺憾的是,由於利用 AD 的用戶端應用程式有很大的差異,因此個別 CPU 的一般使用者估計無法一體適用於所有環境。 具體而言,計算需求會受到使用者行為和應用程式設定檔的影響。 因此,各個環境必須個別調整大小。
目標網站行為設定檔
當您規劃整個網站的容量時,您的目標應該是 N + 1 容量設計。 在此設計中,即使一個系統在尖峰期間失敗,服務仍可在可接受的品質層級繼續。 在 N 案例中,在尖峰期間,所有方塊的負載應小於 80%-100%。
此外,網站的應用程式和用戶端會使用建議的 DsGetDcName 函數 方法來尋找域控制器,它們應該已經均勻分佈,且只有次要的暫時性尖峰。
現在,我們將探討兩個以為目標和關閉目標的環境範例。 首先,我們將探討一個如預期運作的環境範例,且不會超過容量規劃目標。
在第一個範例中,我們會進行下列假設:
- 站台中五個 DC 中的每一個都有四個 CPU。
- 在正常營業時間的運作條件下,目標 CPU 使用量總計為 40%(N + 1),而在其他情況下則為 60%(N)。 在非上班時間,目標 CPU 使用量為 80%,因為我們預期備份軟體和其他維護程式會取用所有可用的資源。
現在,讓我們看看 (Processor Information(_Total)\% Processor Utility) 每個DC的圖表,如下圖所示。
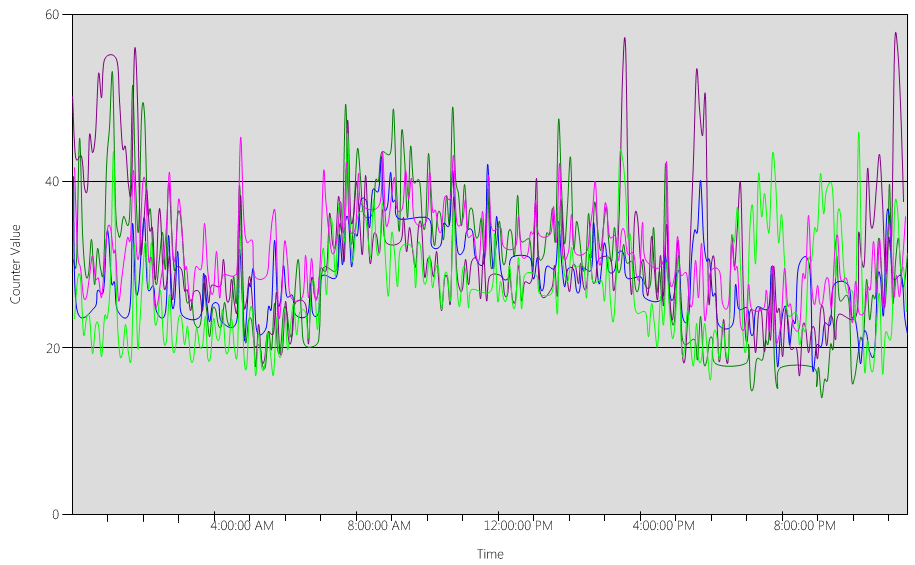
負載相對平均分散,也就是當用戶端使用DC定位器和寫入良好的搜尋時,我們預期的情況。
在數個五分鐘的間隔中,尖峰為 10%,有時甚至 20%。 不過,除非這些尖峰導致CPU使用量超過容量計劃目標,否則您不需要調查它們。
所有系統的尖峰期間介於上午 8:00 到上午 9:15 之間。 平均工作日從上午 5:00 持續到下午 5:00。 因此,任何在下午 5:00 到上午 4:00 之間發生的 CPU 使用量隨機尖峰都在上班時間之外,因此您不需要將它們包含在容量規劃考慮中。
注意
在妥善管理的系統上,在離峰期間發生的尖峰通常是由備份軟體、完整系統防病毒軟體掃描、硬體或軟體清查、軟體或修補程式部署等所造成。 由於這些尖峰會在上班時間以外發生,因此不會計入超過容量規劃目標。
因為每個系統大約是 40%,而且它們都有相同的 CPU 數目,如果其中一個 CPU 離機,其餘系統會以估計 53% 的速度執行。 系統 D 有 40% 的負載,平均分割並新增至系統 A 和 C 的現有 40% 負載。 此線性假設並不完全準確,但提供足夠的精確度來量測。
接下來,讓我們看看沒有良好CPU使用量的環境範例,並超過容量規劃目標。
在此範例中,我們有兩個 DC 在 40% 執行。 一個域控制器脫機,這會導致其餘DC上的預估CPU使用量達到80%。 此 CPU 使用量層級遠遠超過容量計劃的閾值,並開始限制 10% 到 20% 負載設定檔的前端空間量。 因此,每個尖峰都可能會使在 N 案例期間的 DC 驅動至 90% 或甚至 100 %,進而降低其回應性。
計算 CPU 需求
性能 Process\% Processor Time 計數器會追蹤所有應用程式線程在CPU上花費的總時間量,然後將該總和除以經過的系統時間總量。 多 CPU 系統上的 Mutlithread 應用程式可能超過 100% 的 CPU 時間,而且您解譯其數據的方式與計數器大不相同 Processor Information\% Processor Utility 。 在實務上 Process(lsass)\% Processor Time ,計數器會追蹤系統在 100% 執行多少 CPU,以支援進程的需求。 例如,如果計數器的值為 200%,這表示系統需要執行 100% 的兩個 CPU 來支援完整的 AD DS 負載。 雖然以 100%% 效能運行的 CPU 在電力和耗電量方面是最符合成本效益的,但基於附錄 A中所述的原因,多線程系統在其系統未以 100%運行時會更有回應性。
若要容納用戶端負載中的暫時性尖峰,建議您以 40% 到 60% 的系統容量之間的尖峰期間 CPU 為目標。 例如,在 目標站點行為設定檔的第一個範例中,您需要介於 3.33 CPU(60% 目標)和 5 CPU(40% 目標)之間,以支援 AD DS 負載。 您應該根據OS和任何其他必要代理程式的需求新增額外的容量,例如防毒、備份、監視等等。 雖然您應該根據每個環境評估代理程式對 CPU 代理程式的影響,但一般而言,單一 CPU 上的代理程式進程可以分配介於 5% 到 10% 之間。 若要重新流覽我們的範例,我們需要介於 3.43(60% 目標)和 5.1(40% 目標)CPU 之間,以支援尖峰期間負載。
現在,讓我們看看計算特定進程的範例。 在此情況下,我們會查看 LSASS 程式。
計算 LSASS 進程的 CPU 使用量
在此範例中,系統是 N + 1 案例,其中一部伺服器攜帶 AD DS 負載,而額外的伺服器則有備援。
下圖顯示此範例案例中所有處理器之 LSASS 進程的處理器時間。 此數據是從 Process(lsass)\% Processor Time 性能計數器收集而來。
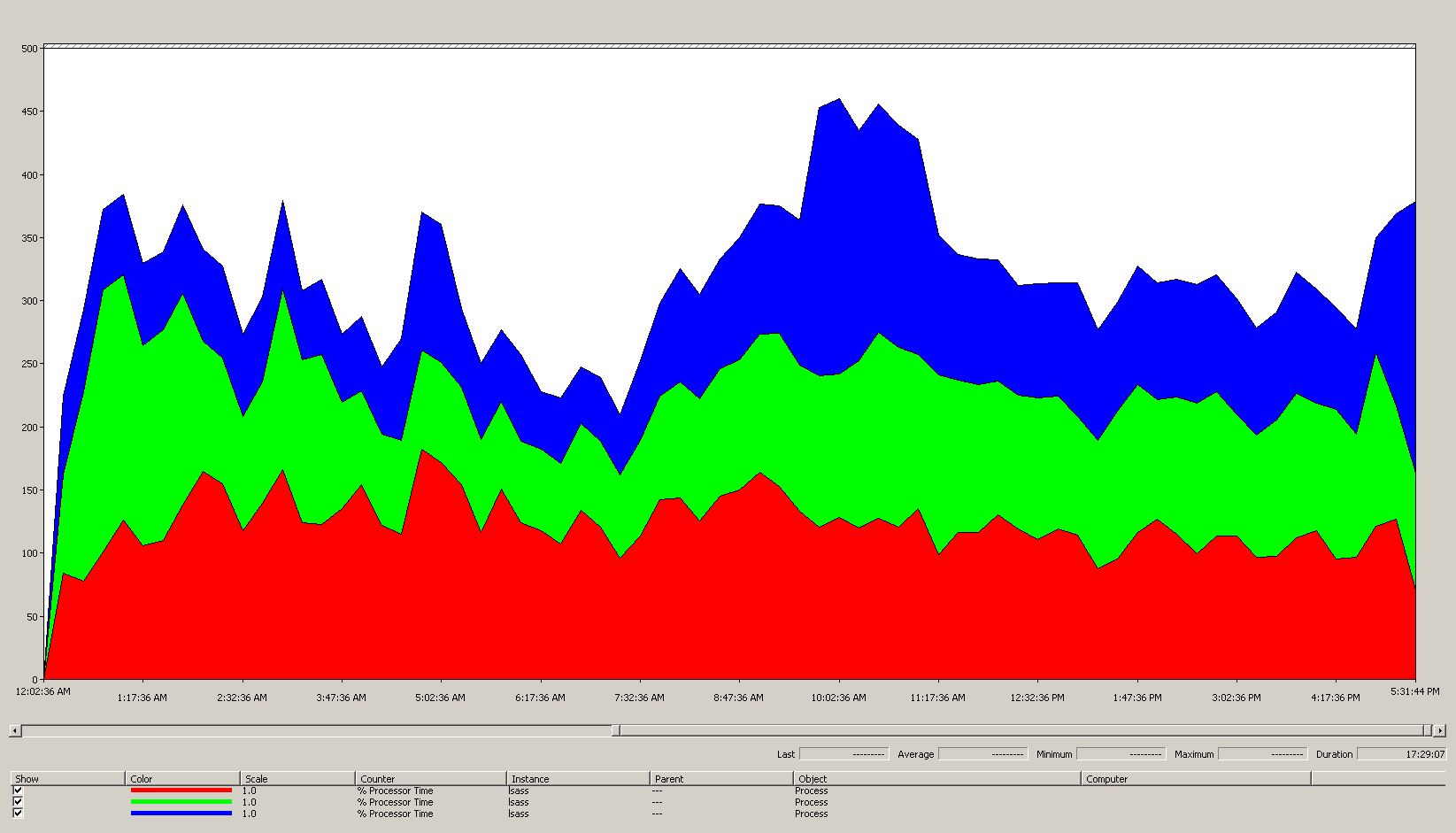
以下是此圖表告訴我們案例環境的內容:
- 站台中有三個網域控制站。
- 營業日開始在上午 7:00 左右上升,下午 5:00 開始下降。
- 最繁忙的一天時間是從上午 9:30 到上午 11:00。
注意
所有效能資料都是歷程記錄資料。 上午 9:15 的尖峰數據點表示從上午 9:00 到上午 9:15 的負載。
- 上午 7:00 之前的尖峰可能表示來自不同時區或背景基礎結構活動的額外負載,例如備份。 不過,由於這個尖峰低於上午 9:30 的尖峰活動,所以這不是值得關注的原因。
在最大負載時,lsass 進程會耗用大約 4.85 個 CPU,在單一 CPU 上執行 100%,這會是 485%。 這些結果建議案例網站需要大約 12/25 個 CPU 來處理 AD DS。 當您針對背景進程引進建議的 5% 到 10% 額外容量時,伺服器需要 12.30 到 12.25 個 CPU 以支援其目前的負載。 預計未來增長的估計使這個數位更高。
調整 LDAP 權數的時機
在某些情況下,應考慮微調 LdapSrvWeight。 在容量規劃的內容中,當您的應用程式、使用者載入或基礎系統功能未平均平衡時,您會調整它。
下列各節說明您應該微調輕量型目錄存取通訊協定 (LDAP) 權數的兩個範例案例。
範例 1:PDC 模擬器環境
如果您使用主要域控制器 (PDC) 模擬器,平均分散的使用者或應用程式行為可能會一次影響多個環境。 PDC 模擬器上的 CPU 資源通常比部署中的其他位置更需要 CPU 資源,因為有數個工具和動作以它為目標,例如組策略管理工具、第二次驗證嘗試、信任建立等等。
- 只有在 CPU 使用率明顯差異時,才應該調整 PDC 模擬器。 微調應該會減少 PDC 模擬器上的負載,並增加其他 DC 上的負載,以允許更均勻的負載分佈。
- 在這些情況下,請為 PDC 模擬器設定介於 50 到 75 之間的值
LDAPSrvWeight。
| 系統 | 使用預設值的CPU使用率 | 新的 LdapSrvWeight | 估計的新 CPU 使用率 |
|---|---|---|---|
| DC 1 (PDC 模擬器) | 53% | 57 | 40% |
| 直流 2 | 33% | 100 | 40% |
| 直流 3 | 33% | 100 | 40% |
catch 是,如果 PDC 模擬器角色已傳輸或擷取,特別是移轉至站臺中的另一個域控制器,則新的 PDC 模擬器上的 CPU 使用率會大幅增加。
在此範例案例中,我們根據目標站點行為設定檔,假設此站點中的所有三個域控制器都有四個 CPU。 在正常情況下,如果其中一個 DC 有八個 CPU,會發生什麼情況? 將有兩個 DC 的使用率為 40%,一個是 20% 使用率。 雖然此設定不一定不好,但您在這裡有機會使用LDAP權數調整來平衡更好的負載。
範例 2:具有不同 CPU 計數的環境
當您在同一個站台中有不同 CPU 計數和速度的伺服器時,您必須確定伺服器平均分散。 例如,如果您的月臺有兩部八核心伺服器和一部四核心伺服器,則四核心伺服器只有其他兩部伺服器的處理能力的一半。 如果客戶端負載平均分散,這表示四核心伺服器需要像兩個八核心伺服器一樣努力運作,才能管理 CPU 負載。 除此之外,如果八核心伺服器之一脫機,四核心伺服器就會超載。
| 系統 | 處理器資訊\ % 處理器公用程式(_Total) 使用預設值的CPU使用率 |
新的 LdapSrvWeight | 估計的新 CPU 使用率 |
|---|---|---|---|
| 4 CPU DC 1 | 40 | 100 | 30% |
| 4 CPU DC 2 | 40 | 100 | 30% |
| 8 CPU DC 3 處理器 | 20 | 200 | 30% |
規劃「N + 1」案例非常重要。 您必須計算一個 DC 離線在各種情況下的影響。 在緊接前一個負載均勻分配的情況中,為了確保在「N」情況下達到60%的負載,隨著所有伺服器上的負載均衡地分配,分配是正常的,因為比例保持一致。 當您查看 PDC 模擬器微調案例,或使用者或應用程式負載不平衡的任何一般案例時,效果會非常不同:
| 系統 | 微調的使用率 | 新的 LdapSrvWeight | 估計的新使用率 |
|---|---|---|---|
| DC 1 (PDC 模擬器) | 40% | 85 | 47% |
| 直流 2 | 40% | 100 | 53% |
| 直流 3 | 40% | 100 | 53% |
處理的虛擬化考量
當您規劃虛擬化環境的容量時,需要考慮兩個層級:主機層級和客體層級。 在主機層級,您必須識別商務週期的尖峰期間。 由於排程虛擬機 CPU 上的客體線程類似於在實體機器的 CPU 上取得 AD DS 線程,因此仍建議您使用 40% 到 60% 的基礎主機。 在客體層級,因為基礎線程排程原則不變,我們也建議您在 40% 到 60% 範圍內保留 CPU 使用量。
在每部主機有一個來賓的直接對應案例中,您必須引進您在先前各節中完成的所有容量規劃預估,才能進行預估。 針對共用主機的情境,基礎處理器的效率會受到大約 10 個% 的影響,這表示如果網站在目標設定為 40%時需要 10 個 CPU,則建議您在所有 N 個客體中分配的虛擬 CPU 數量應為 11。 在實體和虛擬伺服器混合散發的站臺中,此修飾詞僅適用於虛擬機(VM)。 例如,在 N + 1 案例中,一台擁有 10 個 CPU 的實體或直接對應伺服器幾乎等同於一個客體,該客體配置了 11 個 CPU,且主機上另外預留 11 個 CPU 給資料中心。
當您在分析和計算支援AD DS負載所需的CPU數目時,請記住,如果您打算購買實體硬體,市場上可用的硬體類型可能無法完全對應到您的估計值。 不過,當您使用虛擬化時,沒有這個問題。 使用 VM 可減少將計算容量新增至月臺所需的工作,因為您可以使用您想要 VM 的確切規格來新增數目的 CPU。 不過,虛擬化不會消除您的責任,以準確評估您需要多少計算能力,以確保客體需要更多 CPU 時,您的基礎硬體可供使用。 和往常一樣,請記得提前規劃成長。
虛擬化計算摘要範例
| 系統 | 尖峰 CPU |
|---|---|
| 直流 1 | 120% |
| 直流 2 | 147% |
| 直流 3 | 218% |
| CPU 使用量總計 | 485% |
| 目標系統計數 | 總頻寬 (如前所述) |
|---|---|
| 40% 的目標下所需的 CPU | 4.85 ÷ .4 = 12.25 |
在此案例中預先規劃成長時,如果您假設未來三年的需求將增長 50%,您必須確定該需求在該時間有 18.375 個 CPU(12.25 × 1.5)。 或者,您可以在第一年之後檢閱需求,然後根據結果告訴您的內容新增額外的容量。
NTLM 的跨信任用戶端驗證負載
評估跨信任用戶端驗證負載
許多環境可能會有一或多個透過信任連線的網域。 其他網域中不使用 Kerberos 之身分識別的驗證要求需要使用兩個域控制器之間的安全通道來周遊信任。 用戶嘗試在站台中存取的域控制器會連線到位於目的地網域的另一個域控制器,或位於目的地網域路徑的更遠位置。 DC 可以對受信任網域中的其他 DC 進行多少呼叫,是由 *MaxConcurrentAPI 設定所控制。 為了確保安全通道可以處理DC彼此通訊所需的負載量,您可以微調 MaxConcurrentAPI,或者,如果您是在樹系中,請建立快捷方式信任。 在 如何使用 MaxConcurrentApi 設定執行NTLM驗證的效能微調,深入瞭解如何判斷信任之間的流量量。
如同先前的案例,您必須在一天的尖峰忙碌期間收集數據,才能使其很有用。
注意
內林和跨林案例可能會導致驗證周游多個信任,這表示您需要在程式的每個階段進行微調。
虛擬化規劃
規劃虛擬化的容量時,您應該記住一些事項:
- 許多應用程式預設或在特定組態中使用網路層級信任管理員 (NTLM) 驗證。
- 隨著作用中用戶端的數目增加,應用程式伺服器需要更多容量。
- 客戶端有時會讓會話保持開啟一段時間,而是定期重新連線,例如電子郵件提取同步處理。
- 需要因特網存取驗證的 Web Proxy 伺服器可能會導致高 NTLM 負載。
這些應用程式可以建立NTLM驗證的大型負載,這會對DC造成重大壓力,尤其是在使用者和資源位於不同網域時。
您可以採取許多方法來管理跨信任負載,這通常可以且應該同時搭配使用:
- 藉由找出使用者在所在網域中取用的服務,以減少跨信任客戶端驗證。
- 增加可用的安全通道數目。 這些通道稱為 捷徑信任,且與林內流量以及跨樹系流量相關。
- 微調 MaxConcurrentAPI 的默認設定。
若要在現有的伺服器上微調 MaxConcurrentAPI ,請使用下列方程式:
New_MaxConcurrentApi_setting ≥ (semaphore_acquires + + semaphore_time-outs) × average_semaphore_hold_time ÷ time_collection_length
如需詳細資訊,請參閱 知識庫文章2688798:如何使用 MaxConcurrentApi 設定執行NTLM驗證的效能微調。
虛擬考量
您不需要進行任何特殊考慮,因為虛擬化是操作系統微調設定。
虛擬化微調計算範例
| 數據類型 | 值 |
|---|---|
| 旗號取得 (最小值) | 6,161 |
| 旗號取得 (最大值) | 6,762 |
| 旗號逾時 | 0 |
| 平均旗號保留時間 | 0.012 |
| 收集持續時間 (秒) | 1:11 分鐘 (71 秒) |
| 公式 (取自 KB 2688798) | ((6762 - 6161) + 0) × 0.012 / |
| MaxConcurrentAPI 的最小值 | ((6762 - 6161) + 0) × 0.012 ÷ 71 = .101 |
在此期間內,此系統可接受預設值。
監視是否符合容量規劃目標
在本文中,我們已討論規劃和調整如何針對使用率目標進行調整。 下表摘要說明您必須監視的建議閾值,以確保系統如預期般運作。 請記住,這些不是效能閾值,只是容量規劃閾值。 超過這些閾值的伺服器仍可運作,但您需要驗證應用程式是否如預期般運作,才能開始在使用者需求增加時看到效能問題。 如果應用程式沒問題,您應該開始評估硬體升級或其他組態變更。
| 類別 | 效能計數器 | 間隔/取樣 | 目標 | 警告 |
|---|---|---|---|---|
| 處理器 | Processor Information(_Total)\% Processor Utility |
60 分鐘 | 40% | 60% |
| RAM (Windows Server 2008 R2 或更早版本) | 記憶體\可用 MB | < 100 兆位元組 | N/A | < 100 兆位元組 |
| RAM (Windows Server 2012) | Memory\Long-Term 平均備用快取存留期(秒) | 30 分鐘 | 必須經過測試 | 必須經過測試 |
| 網路 | 網路介面(*)\已傳送位元組數/秒 網路介面 每秒接收位元組數 |
30 分鐘 | 40% | 60% |
| 儲存體 | LogicalDisk()<NTDS Database Drive>\Avg Disk sec/ReadLogicalDisk() |
60 分鐘 | 10 毫秒 | 15 毫秒 |
| AD 服務 | Netlogon(*)\平均信號燈保持時間 | 60 分鐘 | 0 | 1 秒 |
附錄 A:CPU 大小調整準則
本附錄討論實用的詞彙和概念,可協助您預估環境的 CPU 大小需求。
定義:CPU 大小調整
處理器(微控制器)是讀取和執行程式指令的元件。
多核心處理器在同一個積體電路上有多個 CPU。
多中央處理器系統有多個不在相同積體電路上的中央處理器。
邏輯處理器是一種處理器,從作系統的觀點來看,只有一個邏輯運算引擎。
這些定義包括超線程、多核心處理器上的一個核心或單一核心處理器。
由於現今的伺服器系統有多個處理器、多個多核心處理器和超線程,因此這些定義已一般化以涵蓋這兩個案例。 我們使用邏輯處理器一詞,因為它代表可用運算引擎的 OS 和應用程式觀點。
執行緒層級平行處理原則
每個執行緒都是獨立的工作,因為每個執行緒都有其本身的堆疊和指令。 AD DS 是多執行緒的,您可以遵循 如何在 Active Directory 中使用 Ntdsutil.exe來檢視和設定 LDAP 原則中的指示,調整可用執行緒的數量,以便其在多個邏輯處理器上良好擴充。
資料層級平行處理原則
數據層級平行處理原則是當服務跨多個線程共用相同進程的數據,以及跨多個進程共用許多線程時。 單一 AD DS 進程會算作單一進程跨數個線程共用數據的服務。 數據的任何變更都會反映在快取所有層級的所有執行中線程、每個核心,以及共用記憶體的任何更新。 效能在寫入作業期間可能會降低,因為所有記憶體位置都會調整為變更,然後指令處理才能繼續。
CPU 速度與多個核心考慮
一般而言,更快的邏輯處理器可縮短處理一系列指令所需的時間。 更多邏輯處理器表示您可以同時執行更多工作。 不過,這些規則不適用於更複雜的案例,例如從共用記憶體擷取數據、等候數據層級平行處理原則,以及同時管理多個線程的額外負荷。 因此,多核心系統中的延展性並不線性。
若要瞭解為什麼發生這項變更,它有助於思考這些案例,例如高速公路。 每個線程都是個別的汽車,每個車道都是核心,而速度限制則是時鐘速度。
如果高速公路上只有一輛車,那麼有兩條或12條車道就無關緊要了。 那輛車只會像限速一樣快。
如果線程所需的數據無法立即使用,則線程在從記憶體擷取相關數據之前,無法處理指示。 就像高速公路的一段關閉一樣。 即使高速公路上只有一輛車,限速不會影響其行駛能力,因為它不能去任何地方,直到道路重新開放。
隨著汽車數量的增加,高速公路需要管理汽車數量的額外負荷也會增加。 司機在高峰時段在高速公路上開車時需要更加努力,而不是當道路大部分是空的時晚。 此外,在兩車道高速公路上行駛,您只需要擔心另一條車道需要比在六車道高速公路上開車少,而您在有另外五條車道的交通要注意。
總而言之,關於您是否應該新增更多或更快速的處理器變得高度主觀的問題,應該逐案考慮。 特別是針對 AD DS,其處理需求取決於環境因素,而且可能會因單一環境內的伺服器而異。 因此,本文先前的章節並沒有大量投資進行超精確的計算。 當您做出預算驅動購買決策時,建議您先以 40% 或特定環境所需的號碼優化處理器使用量。 如果您的系統未優化,則您不會從購買其他處理器中獲益。
回應時間和系統活動層級如何影響效能
佇列理論是等候線或 佇列的數學研究。 在計算佇列理論中,使用率法是以 t 方程式表示:
U k = B ÷ T
其中 U k 是使用率百分比, B 是忙碌所花費的時間量, 而 T 則是觀察系統的總時間。 在Microsoft內容中,這表示處於執行中狀態的 100 奈秒間隔線程數目除以指定時間間隔中有多少 100-ns 間隔可用。 這是計算 Processor Object 和 PERF_100NSEC_TIMER_INV 中所顯示處理器使用率百分比的相同公式。
佇列理論也提供公式: N = U k ÷ (1 - U k) 根據使用率來估計等候項目的數目,其中 N 是佇列的長度。 在所有使用率間隔上繪製此方程式圖,提供下列估計佇列在處理器上取得的時間長度,以及任何指定的 CPU 負載。
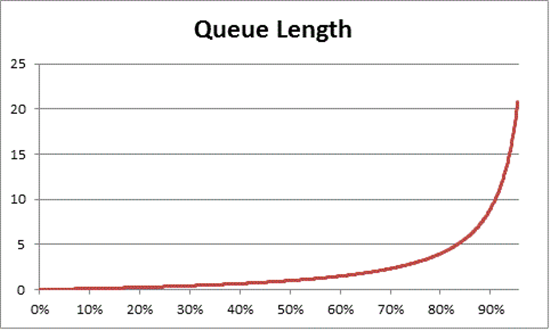
根據這項估計,我們可以觀察到,在 50% 的 CPU 負載之後,平均等候通常會在佇列中包含其他專案,並快速增加至 70% 的 CPU 使用率。
若要瞭解佇列理論如何應用於 AD DS 部署,讓我們回到之前在 CPU 速度與多核心考量中使用的高速公路比喻。
下午更繁忙的時間將落在40%至70%的容量範圍內。 有足夠的交通,你選擇車道開車的能力並沒有受到嚴重限制。 雖然另一名司機進入你的方式的機會很高,但它不需要同樣的努力,你需要找到其他汽車在車道上的安全差距,就像在高峰時段一樣。
隨著高峰時段的臨近,道路系統接近100%的容量。 在高峰時段換車道會變得非常具有挑戰性,因為汽車在一起非常接近,以至於在換車道時,你沒有那麼多的空間可以機動。
這就是為什麼估計容量的長期平均值為 40%, 可讓更多的前端有異常負載尖峰、這些尖峰是否為暫時性,例如執行一段時間的不正常編碼查詢,或一般負載中的異常高載,例如假日週末後早上的活動尖峰。
上一個語句將處理器時間計算的百分比視為與使用率法方程式相同。 這個簡化的版本旨在向新用戶介紹概念。 不過,如需更進階的數學,您可以使用下列參考做為指南:
- 正在翻譯 PERF_100NSEC_TIMER_INV
- 數學計算:
- U k = 1 – %Processor 時間
- %Processor 時間 = 1 – U k
- %Processor 時間 = 1 – B / T
- %Processor 時間 = 1 – X1 – X0 / Y1 – Y0
將這些概念套用至容量規劃
上一節中的數學運算可能會決定系統中您需要多少邏輯處理器看起來非常複雜。 因此,調整系統大小的方法應該著重於根據目前的負載判斷最大目標使用率,然後計算您需要達到該目標的邏輯處理器數目。 此外,您的估計不需要完全精確。 雖然邏輯處理器速度確實會對同步處理產生重大影響,但效能也可能受到其他區域的影響:
- 快取效率
- 記憶體一致性需求
- 線程排程和同步處理
- 不完全平衡的用戶端載入
由於計算能力相對低成本,因此不值得花費太多時間來計算所需的完全確切 CPU 數目。
請務必記住,在此情況下,40% 的建議不是必要需求。 我們使用它作為進行計算的合理起點。 不同類型的 AD 使用者需要不同層級的回應性。 甚至在某些情況下,環境可以在持續平均執行 80% 或甚至 90% 的使用率,而處理器存取的等候時間會明顯影響用戶端效能。
系統中還有其他區域比邏輯處理器慢很多,您也應該微調這些處理器,包括 RAM 存取、磁碟存取,以及透過網路傳輸回應。 例如:
如果您將處理器新增至以磁碟系結的 90% 使用率執行的系統,它可能不會大幅改善效能。 如果您更仔細地查看系統,則有許多線程甚至無法進入處理器,因為它們正在等待I/O 作業完成。
解決磁碟系結問題可能表示先前卡在等候狀態中的線程停止停滯,從而為 CPU 時間創造更多的競爭。 因此,90% 使用率會移至 100%。 您必須調整這兩個元件,才能讓使用率降低到可管理的層級。
注意
計數器
Processor Information(*)\% Processor Utility可以超過 100% 且具有 Turbo 模式的系統。 Turbo 模式可讓 CPU 在短時間內超過分級處理器速度。 如果您需要詳細資訊,請參閱 CPU 製造商的檔和計數器描述。
討論整個系統使用率考慮也牽涉到域控制器作為虛擬化來賓。 主機和客體的回應時間及系統活動層級如何影響效能,適用於虛擬化情境中的兩者。 在只有一個來賓的主機中,DC 或系統在實體硬體上具有幾乎相同的效能。 將更多來賓新增至主機會增加基礎主機的使用率,也會增加等候時間以取得處理器的存取權。 因此,您必須同時管理主機和客體層級的邏輯處理器使用率。
讓我們回顧前幾節的高速公路隱喻,這次我們才將客體 VM 想像成快速總線。 快速巴士,與公共交通或校車相反,直接前往乘客的目的地,而不進行任何停車。
現在,讓我們想像四個案例:
- 系統的離峰時間就像深夜乘坐快速巴士一樣。 當車手上車時,幾乎沒有其他乘客,道路幾乎空無一人。 因為公共汽車沒有交通要與之競爭,這趟車程很容易,就像車手在自己的車裡開車一樣快。 然而,騎手的旅行時間也受到當地速度限制的限制。
- 當系統的CPU使用率太高時,當高速公路上的大部分車道關閉時,離峰時間就像深夜乘坐。 儘管巴士本身大部分是空的,但道路仍然因處理受限制車道的剩餘交通而擁擠。 雖然車手可以自由坐在他們想要的任何位置,但他們的實際車程時間取決於公共汽車外的交通。
- 高峰時段高 CPU 使用率的系統就像高峰時段擁擠的公共汽車一樣。 行程不僅需要更長的時間,而且上車和下車更難,因為公共汽車充滿了其他乘客。 將更多邏輯處理器新增至客體系統,以嘗試加速等候時間,就像藉由新增更多公交車來解決交通問題。 問題不是公交車數量,而是車程需要多久時間。
- 在離峰時段高 CPU 使用率的系統就像在夜間大部分空路上擁擠的公共汽車一樣。 雖然車手可能很難找到座位或上下車,但一旦公共汽車接上所有乘客,行程相當順利。 此案例是唯一可藉由新增更多總線來改善效能的案例。
根據先前的範例,您可以看到在 0% 到 100% 使用率之間有許多案例會對效能產生不同程度的影響。 此外,新增更多邏輯處理器不一定能改善非常特定案例以外的效能。 將這些原則套用至主機和來賓的建議 40% CPU 使用率目標應該相當簡單。
附錄 B:關於不同處理器速度的考慮
在處理中,我們假設處理器在收集數據時以100%的時鐘速度執行,而且任何取代系統都有相同的處理速度。 儘管這些假設不正確,尤其是 Windows Server 2008 R2 和更新版本,其中預設電源計畫是平衡的,但這些假設仍適用於保守的估計。 雖然潛在的錯誤可能會增加,但它只會隨著處理器速度增加而增加安全性的邊界。
- 例如,在需要 11.25 CPU 的案例中,如果處理器在收集數據時以半速執行,則其需求的估計值會是 5.125 ÷ 2。
- 無法保證兩倍的時鐘速度會將記錄期間內發生的處理量加倍。 處理器在 RAM 或其他元件上等候的時間量大致相同。 因此,較快的處理器可能會在等候系統擷取數據時花費較大百分比的時間閑置。 我們建議您堅持最低的共同分母,保持估計保守,並避免假設處理器速度之間的線性比較,這可能會使結果不正確。
如果更換硬體中的處理器速度低於您目前的硬體,您應該按比例增加所需處理器數目的估計值。 例如,讓我們看看計算您需要10個處理器來維持月臺負載的案例。 目前的處理器會在 3.3 GHz 上執行,而您打算將處理器取代為以 2.6 GHz 執行的處理器。 只更換10個原始處理器,會讓您速度降低21%。 若要提高速度,您必須取得至少12個處理器,而不是10個處理器。
不過,這種變化不會變更容量管理處理器使用率目標。 處理器時鐘速度會根據負載需求動態調整,因此在較高的負載下執行系統會導致 CPU 花費更多時間進入較高的時鐘速度狀態。 最終目標是讓 CPU 在尖峰上班時間處於 100% 時鐘速度狀態的 40% 使用率。 任何較少的項目都會在離峰案例期間節流 CPU 速度來節省電力。
注意
您可以將電源計劃設定為 高效能,以在數據收集期間關閉處理器的電源管理。 關閉電源管理可讓您更準確地讀取目標伺服器中的CPU耗用量。
若要調整不同處理器的估計值,建議您使用標準效能評估公司的SPECint_rate2006基準檢驗。 若要使用此基準檢驗:
選擇 結果。
輸入 CPU2006 ,然後選取 [搜尋]。
在 [可用的組態] 下拉功能表中,選取 [所有 SPEC CPU2006]。
在 [ 搜尋表單要求] 字段中,選取 [ 簡單],然後選取 [Go!]。
在 [簡單要求] 下,輸入目標處理器的搜尋準則。 例如,如果您要尋找ES-2630處理器,請在下拉功能表中選取 [ 處理器],然後在搜尋欄位中輸入處理器名稱。 完成後,選取 [ 執行簡單擷取]。
在搜尋結果中尋找您的伺服器和處理器組態。 如果搜尋引擎未傳回完全相符專案,請尋找最接近的相符專案。
記錄 Result 和 # Cores 數據 行中的值。
使用此方程序來判斷修飾詞:
((目標平台每核心分數值) × (基準平台每核心 MHz)) ÷ ((基準每核心分數值) × (目標平台每核心 MHz))
例如,以下說明如何尋找ES-2630處理器的修飾詞:
(35.83 × 2000) ÷ (33.75 × 2300) = 0.92
將此修飾詞估計的處理器數目乘以。
針對 ES-2630 處理器範例,0.92 × 10.3 = 10.35 處理器。
附錄 C:作業系統如何與記憶體互動
我們在回應時間中討論的佇列理論概念 ,以及系統活動層級如何影響效能 也適用於記憶體。 您必須熟悉操作系統如何處理 I/O,才能有效地套用這些概念。 在 Windows OS 中,OS 會建立一個佇列,以保存每個實體磁碟的 I/O 要求。 不過,實體磁碟不一定是單一磁碟。 OS 也可以將數位控制器或 SAN 上的主軸匯總註冊為實體磁碟。 數位控制器和SAN也可以將多個磁碟匯總成單一陣列集,將其分割成多個分割區,然後使用每個分割區作為實體磁碟,如下圖所示。
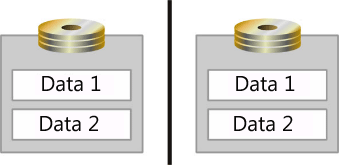
在此圖中,兩個主軸會鏡像並分割成數據儲存的邏輯區域,標示為數據 1 和數據 2。 OS 會將每個邏輯區域註冊為個別的實體磁碟。
既然我們已釐清定義實體磁碟的內容,您也應該熟悉下列詞彙,以協助您進一步瞭解本附錄中的資訊。
- 磁軸是實際安裝在伺服器中的設備。
- 陣列是控制器匯總的主軸集合。
- 數組分區是匯總數組的分區。
- 邏輯單元編號 (LUN) 是連線到電腦的 SCSI 裝置陣列。 本文會在討論 SAN 時使用這些詞彙。
- 磁碟包含作系統註冊為單一實體磁碟的任何主軸或磁碟分區。
- 分割區是操作系統註冊為實體磁碟的邏輯分割。
作業系統架構考量
OS 會為其註冊的每個磁碟建立第一進、先出 (FIFO) I/O 佇列。 這些磁碟可以是主軸、陣列或數位分割區。 當談到操作系統如何處理 I/O 時,較使用中的佇列愈好。 當OS串行化FIFO佇列時,它必須處理發出給儲存子系統的所有FIFO I/O要求,才能到達。 當 OS 將每個磁碟與主軸或數位相互關聯時,它會針對每個唯一的磁碟集維護 I/O 佇列,並消除跨磁碟的稀缺 I/O 資源的競爭,並將 I/O 需求隔離至單一磁碟。 不過,Windows Server 2008 引進了 I/O 優先順序形式的例外狀況。 設計來使用低優先順序 I/O 的應用程式,無論 OS 收到它們時,都移至佇列的後端。 應用程式未特別編碼為使用低優先順序設定,而是預設為一般優先順序。
簡單儲存子系統簡介
在本節中,我們將討論簡單的儲存子系統。 讓我們從範例開始:計算機內的單一硬碟。 如果我們將此系統分解成其主要儲存子系統元件,以下是我們得到的內容:
- 一個 10,000 RPM Ultra Fast SCSI HD (Ultra Fast SCSI 有 20 MBps 傳輸速率)
- 一輛 SCSI 總線 (纜線)
- 一個 Ultra Fast SCSI 配接器
- 一個 32 位 33 MHz PCI 總線
注意
此範例不會反映系統通常會保留一個圓柱體數據的磁碟快取。 在此情況下,第一個 I/O 需要 10 毫秒,磁碟會讀取整個圓柱體。 快取會滿足所有其他循序 I/O。 因此,磁碟內快取或許可改善循序 I/O 效能。
識別元件之後,您可以開始了解系統可以傳輸的數據量,以及它可以處理的 I/O 數量。 可以傳輸系統的 I/O 數量和數據數量彼此相關,但不是相同的值。 此相互關聯取決於區塊大小,以及磁碟 I/O 是隨機還是循序。 系統會將所有數據寫入磁碟作為區塊,但不同的應用程式可以使用不同的區塊大小。
接下來,讓我們以元件為基礎來分析這些專案。
硬碟存取時間
平均 10,000-RPM 硬碟有 7 毫秒的搜尋時間和 3 毫秒的存取時間。 搜尋時間是讀取或寫入頭移至拼盤位置所花費的平均時間量。 存取時間是一旦數據位於正確位置,前端讀取或寫入磁碟所花費的平均時間量。 因此,在 10,000-RPM HD 中讀取唯一數據區塊的平均時間包括搜尋和存取時間,總計約 10 毫秒或 .010 秒,每個數據區塊。
當每個磁碟存取都需要前端移至磁碟上的新位置時,讀取或寫入行為稱為隨機。 當所有 I/O 都是隨機的時,10,000-RPM HD 每秒可以處理大約 100 個 I/O (IOPS)。
當硬碟上的相鄰扇區發生所有 I/O 時,我們會將其稱為 循序 I/O。 循序 I/O 沒有搜尋時間,因為在第一個 I/O 完成之後,讀取或寫入前端位於硬碟儲存下一個數據區塊的開頭。 例如,根據下列方程式,10,000-RPM HD 能夠每秒處理大約 333 個 I/O:
每秒 1000 毫秒÷每個 I/O 3 毫秒
到目前為止,硬碟的傳輸速率與我們範例無關。 無論硬碟大小為何,10,000-RPM HD 可處理的 IOPS 實際數量一律約為 100 個隨機或 300 個循序 I/O。 當區塊大小根據應用程式寫入磁碟驅動器時變更,每個 I/O 提取的數據量也會變更。 例如,如果區塊大小為 8 KB,則 100 個 I/O 作業會對硬碟讀取或寫入共計 800 KB。 不過,如果區塊大小為 32 KB,則 100 個 I/O 會讀取或寫入硬碟 3,200 KB(3.2 MB)。 如果 SCSI 傳輸速率超過傳輸的數據總量,則取得更快的傳輸速率不會變更任何專案。 如需詳細資訊,請參閱下表:
| 描述 | 7200 RPM 9 毫秒搜尋, 4 毫秒存取 | 10,000 RPM 7 毫秒搜尋, 3 毫秒存取 | 15,000 RPM 4 毫秒搜尋, 2 毫秒存取 |
|---|---|---|---|
| 隨機 I/O | 80 | 100 | 150 |
| 循序 I/O | 250 | 300 | 500 |
| 10,000 RPM 磁碟機 | 8 KB 區塊大小 (Active Directory Jet) |
|---|---|
| 隨機 I/O | 800 KB/秒 |
| 循序 I/O | 2400 KB/秒 |
SCSI 背板
SCSI 背板,在此範例案例中,功能區纜線如何影響儲存子系統的輸送量取決於區塊大小。 如果 I/O 位於 8 KB 區塊中,則總線可以處理多少 I/O? 在此案例中,SCSI 總線為 20 MBps 或 20480 KB/秒。 20480 KB/秒除以 8 KB 區塊,算出 SCSI 匯流排最多約可支援 2500 個 IOPS。
注意
下表中的數位代表範例案例。 多數已連結的存放裝置目前都使用 PCI Express,可提供更高的輸送量。
| SCSI 匯流排的每個區塊大小支援的 I/O | 2 KB 區塊大小 | 8 KB 區塊大小 (AD Jet) (SQL Server 7.0/SQL Server 2000) |
|---|---|---|
| 20 Mbps | 1萬 | 2,500 |
| 40 MBps | 20,000 | 5,000 |
| 128 兆位元組 | 65,536 | 16,384 |
| 320 Mbps | 160,000 | 40,000 |
如上表所示,在我們的範例案例中,總線絕不是瓶頸,因為主軸最大值是 100 I/O,遠遠低於任何列出的臨界值。
注意
在此案例中,我們假設 SCSI 總線效率為 100%。
SCSI 配接器
若要判斷系統可以處理的 I/O 數目,您必須檢查製造商的規格。 將 I/O 要求導向到適當的裝置需要處理能力,因此系統可以處理的 I/O 數目取決於 SCSI 配接器或數位控制器處理器。
在此範例案例中,我們假設系統可以處理 1,000 個 I/O。
PCI 匯流排
PCI 總線是一個被忽略的元件。 在此範例案例中,PCI 總線不是瓶頸。 不過,隨著系統相應增加,未來可能會成為瓶頸。
我們可以看到PCI總線可以使用下列方程式,在範例案例中傳輸數據量:
32 位÷ 8 個字節,× 33 MHz = 133 MBps
因此,我們可以假設在 33 Mhz 上運作的 32 位 PCI 總線可以傳輸 133 MBps 的數據。
注意
此方程序的結果代表已傳輸數據的理論限制。 實際上,大部分的系統只會達到上限的50%左右。 在某些高載案例中,系統可以在短時間內達到 75% 的限制。
66 MHz 64 位 PCI 總線可以根據此方程式支持理論上限 528 MBps:
64 位÷ 8 個字節× 66 Mhz = 528 MBps
當您新增任何其他裝置,例如網路適配器或第二個 SCSI 控制器時,它會減少系統可用的頻寬,因為所有裝置共用頻寬,而且可以彼此競爭有限的處理資源。
分析儲存子系統以找出瓶頸
在此案例中,主軸是您可以要求多少 I/O 的限制因素。 因此,此瓶頸也會限制系統可以傳輸的數據量。 由於我們的範例是 AD DS 案例,因此當您存取 Jet 資料庫時,可傳輸的數據量為每秒 100 個隨機 I/O,以 8 KB 遞增計算,總計為每秒 800 KB。 相較之下,您設定為獨佔配置給記錄檔的軸最大輸送量限制為 8 KB 分期的每秒 300 個循序 I/O,總計每秒 2,400 KB 或 2.4 MB。
既然我們已分析範例組態的元件,讓我們看看一個數據表,示範在記憶體子系統中新增和變更元件時,可能發生瓶頸的位置。
| 備註 | 瓶頸分析 | 磁碟 | 公車 | 介面卡 | PCI 匯流排 |
|---|---|---|---|---|---|
| 這是新增第二個磁碟之後的網域控制站設定。 磁碟設定顯示 800 KB/秒的瓶頸。 | 新增 1 個磁碟 (總計=2) I/O 是隨機的 4 KB 區塊大小 10,000 RPM 硬碟 |
總計 200 個 I/O 總計 800 KB/秒。 |
|||
| 新增 7 個磁碟之後,磁碟設定仍顯示 3200 KB/秒的瓶頸。 | 新增 7 個磁碟 (Total=8) I/O 是隨機的 4 KB 區塊大小 10,000 RPM 硬碟 |
總計 800 個 I/O。 總計 3200 KB/秒 |
|||
| 將 I/O 變更為循序之後,網路適配器會變成瓶頸,因為其限製為 1000 IOPS。 | 新增 7 個磁碟 (總計=8) I/O 是循序的 4 KB 區塊大小 10,000 RPM 硬碟 |
每秒可對磁碟讀取/寫入 2400 個 I/O,控制器限制為 1000 IOPS | |||
| 將網路介面卡替換為支援 10,000 IOPS 的 SCSI 介面卡後,瓶頸會回到磁碟設定上。 | 新增 7 個磁碟 (總計=8) I/O 是隨機的 4 KB 區塊大小 10,000 RPM 硬碟 升級 SCSI 介面卡 (現在支援 10,000 個 I/O) |
總計 800 個 I/O。 總計 3,200 KB/秒 |
|||
| 將區塊大小增加到 32 KB 之後,總線會變成瓶頸,因為它只支援 20 MBps。 | 新增 7 個磁碟 (總計=8) I/O 是隨機的 32 KB 區塊大小 10,000 RPM 硬碟 |
總計 800 個 I/O。 25,600 KB/秒 (25 MBps) 可以讀取/寫入磁碟。 總線僅支援 20 MBps |
|||
| 升級匯流排並新增更多磁碟後,磁碟仍是瓶頸。 | 新增 13 個磁碟 (總計=14) 新增第二個具有 14 個磁碟的 SCSI 介面卡 I/O 是隨機的 4 KB 區塊大小 10,000 RPM 硬碟 升級至 320 MBps SCSI 匯流線 |
2800 個 I/O 11,200 KB/秒 (10.9 MBps) |
|||
| 將 I/O 變更為循序後,磁碟仍是瓶頸。 | 新增 13 個磁碟 (總計=14) 新增第二個具有 14 個磁碟的 SCSI 介面卡 I/O 是循序的 4 KB 區塊大小 10,000 RPM 硬碟 升級至 320 MBps SCSI 匯流線 |
8,400 個 I/O 33,600 KB\秒 (32.8 MB\秒) |
|||
| 新增更快速的硬碟後,磁碟仍是瓶頸。 | 新增 13 個磁碟 (總計=14) 新增第二個具有 14 個磁碟的 SCSI 介面卡 I/O 是循序的 4 KB 區塊大小 15,000 RPM 硬碟 升級至 320 MBps SCSI 匯流線 |
14,000 個 I/O 56,000 KB/秒 (54.7 MBps) |
|||
| 將區塊大小增加到 32 KB 後,PCI 匯流排會成為瓶頸。 | 新增 13 個磁碟 (總計=14) 新增第二個具有 14 個磁碟的 SCSI 介面卡 I/O 是循序的 32 KB 區塊大小 15,000 RPM 硬碟 升級至 320 MBps SCSI 匯流線 |
14,000 個 I/O 448,000 KB/秒 (437 MBps) 是主軸的讀取/寫入限制。 PCI 總線最多支援 133 MBps(最高效率 75%) 的理論上限。 |
RAID 簡介
當您將數位控制器引入記憶體子系統時,它不會大幅變更其本質。 數位控制器只會取代計算中的SCSI適配卡。 不過,當您使用各種數位級時,讀取和寫入數據到磁碟的成本確實會變更。
在RAID 0中,寫入數據會將數據等量分割到RAID集合中的所有磁碟。 在讀取或寫入作業期間,系統會從中提取數據,或將其推送至每個磁碟,以增加系統在這一特定時段內傳輸的數據量。 因此,在此範例中,我們使用10,000 RPM磁碟驅動器,使用RAID 0可讓您執行100個I/O作業。 系統支援的 I/O 總數是 N 個軸乘以每秒每軸 100 次 I/O,或 N 個軸 × 每秒每軸 100 次 I/O。

在RAID 1中,系統會鏡像或重複一對主軸的數據,以備援。 當系統執行讀取 I/O 作業時,它可以從集合中的兩個主軸讀取數據。 此鏡像可讓這兩個磁碟在讀取作業期間都能使用 I/O 容量。 不過,RAID 1 不會提供寫入作業任何效能優點,因為系統也需要鏡像兩個主軸上的寫入數據。 雖然鏡像不會讓寫入作業花費較長的時間,但它確實會防止系統同時進行多個讀取作業。 因此,每個寫入 I/O 作業都會花費兩個讀取 I/O 作業。
下列方程式會計算此案例中有多少 I/O 作業發生:
讀取 I/O + 2 ×寫入 I/O =
當您知道讀取與寫入的比例,以及部署中的主軸數目時,您可以使用此方程式來計算陣列可支援的 I/O 數量:
每個主軸的最大 IOPS × 2 個主軸 × [(% 讀取 + % 寫入) ÷ (% 讀取 + + 2 × % 寫入)] = 總計 IOPS
使用 RAID 1 和 RAID 0 的案例在讀取和寫入作業的成本上的行為與 RAID 1 完全相同。 不過,I/O 現在會等量分割到每個鏡像集。 這表示方程式會變更為此:
每個 Spindle 的最大 IOPS × 2 個 Spindle × [(% 讀取 + % 寫入) ÷ (% 讀取 + 2 × % 寫入)] = 總 I/O
在RAID 1集合中,當您等量 N 個 RAID 1 集合時,陣列可以處理的 I/O 總數會變成每個 RAID 1 集 的 N × I/O:
N × {每個主軸的最大 IOPS × 2 個× [(% 讀取 + ) ÷ (% 讀取 + 2 × % 寫入)]} = 總計 IOPS
我們有時會呼叫 RAID 5 N + 1 RAID,因為系統會將數據等量分割到 N 個主軸,並將同位資訊寫入 + 1 個主軸。 不過,RAID 5 在執行寫入 I/O 比 RAID 1 或 RAID 1 + 0 時會使用更多資源。 每次作業系統將寫入 I/O 提交至陣列時,RAID 5 都會執行下列程式:
- 讀取舊數據。
- 讀取舊的同位。
- 寫入新的數據。
- 撰寫新的同位。
OS 傳送至數位控制器的每個寫入 I/O 要求都需要四個 I/O 作業才能完成。 因此,N + 1 個 RAID 寫入請求所需時間是讀取 I/O 完成的四倍。 換句話說,若要判斷 OS 中有多少 I/O 要求會轉譯為主軸取得多少要求,您可以使用此方程式:
讀取 I/O + 4 ×寫入 I/O 總計 I/O =
同樣地,在 RAID 1 集合中,您知道讀取與寫入的比例,以及有多少個主軸,您可以使用此方程式來識別數位可支援多少 I/O:
每個主軸的 IOPS × (主軸 – 1) × [(% 讀取% 寫入) ÷ ( + + 4 × % 寫入)] = 總計 IOPS
注意
上一個方程序的結果不包含失去同位的磁碟驅動器。
SAN 簡介
當您將儲存局域網路 (SAN) 引入您的環境中時,這不會影響我們先前各節所述的規劃原則。 不過,您應該考慮 SAN 可以針對連線到它的所有系統變更 I/O 行為。 使用 SAN 的主要優點之一是,它可讓您在內部或外部鏈接的記憶體上提供更多備援,但也表示您的容量規劃需要考慮容錯需求。 此外,當您向系統介紹更多元件時,您也需要將這些新元件納入計算中。
現在,讓我們將 SAN 細分成其元件:
- SCSI 或光纖通道硬碟
- 儲存單位通道背板
- 儲存單位本身
- 記憶體控制器模組
- 一或多個SAN交換器
- 一或多個主機總線配接器 (HBA)
- 周邊元件互連 (PCI) 總線
當您設計系統以進行備援時,您必須包含額外的元件,以確保系統在一或多個原始元件停止運作的危機案例中持續運作。 不過,當您進行容量規劃時,您必須從可用的資源中排除備援元件,以準確估計系統的基準容量,因為這些元件通常不會上線,除非發生緊急狀況。 例如,如果您的 SAN 有兩個控制器模組,則只有在計算可用 I/O 輸送量總計時,您只需要使用一個,因為除非原始模組停止運作,否則另一個控制器模組不會開啟。 您也不應該將備援 SAN 交換器、儲存單位或主軸帶入 I/O 計算中。
此外,因為容量規劃只會考慮尖峰使用量的期間,所以您不應該將備援元件因素納入您的可用資源。 尖峰使用率不應超過系統的80%飽和度,以容納高載或其他不尋常的系統行為。
當您分析 SCSI 或光纖通道硬碟的行為時,您應該根據上一節所述的原則來分析它。 儘管每個通訊協定都有自己的優點和缺點,但限制每個磁碟效能的主要因素是硬碟的機械限制。
當您分析儲存單位上的通道時,應該採用計算 SCSI 總線上有多少資源可用時所使用的相同方法:將頻寬除以區塊大小。 例如,如果您的儲存單位有六個通道,每個通道都支援 20 MBps 最大傳輸速率,則可用 I/O 和數據傳輸的總數為 100 MBps。 總計為 100 MBps 而非 120 MBps 的原因是,如果其中一個通道突然關閉,則記憶體通道總輸送量不應超過所使用的輸送量量,而只剩下五個可運作的通道。 當然,此範例也會假設系統會平均分散所有通道的負載和容錯。
您是否可以將上一個範例轉換成 I/O 設定檔,視應用程式行為而定。 針對 Active Directory Jet I/O,最大值約為每秒 12,500 個 I/O,或 100 MBps ÷每個 I/O 8 KB。
若要瞭解控制器模組支援的輸送量,您也需要取得其製造商規格。 在此範例中,SAN 有兩個控制器模組,各支援 7,500 個 I/O。 如果您未使用備援,則系統輸送量總計會是 15,000 IOPS。 不過,在需要備援的案例中,您會根據其中一個控制器的限制來計算最大輸送量,也就是 7,500 IOPS。 假設區塊大小為 4 KB,此閾值遠低於記憶體通道可支援的 12,500 IOPS 上限,因此是分析中的瓶頸。 不過,為了規劃目的,您應該規劃的所需最大 I/O 為 10,400 I/O。
當數據離開控制器模組時,它會傳輸 1 GBps 或 128 MBps 的光纖通道連線。 由於此數量超過所有儲存單位通道的 100 MBps 總頻寬,因此不會瓶頸系統。 此外,由於由於備援,此傳輸只位於兩個光纖通道的其中一個,如果一個光纖通道連線停止運作,剩餘的連線仍有足夠的容量來處理數據傳輸需求。
然後,數據會將SAN交換器傳輸至伺服器。 交換器會限制它可以處理的 I/O 數量,因為它需要處理連入要求,然後將它轉送至適當的埠。 不過,如果您查看製造商規格,您只能知道切換限制為何。 例如,如果您的系統有兩個交換器,而且每個交換器可以處理 10,000 IOPS,則輸送量總計會是 20,000 IOPS。 根據容錯規則,如果一個交換器停止運作,則系統輸送量總計會是 10,000 IOPS。 因此,在正常情況下,您不應該使用超過80%使用率或8,000個I/O。
最後,您在伺服器中安裝的 HBA 也會限制其可處理的 I/O 量。 一般而言,您會安裝第二個 HBA 進行備援,但就像使用 SAN 交換器一樣,當您計算系統可以處理的 I/O 數量時,總輸送量將是 N - 1 個 HBA。
快取考量
快取是其中一個元件,可大幅影響記憶體系統中任何位置的整體效能。 不過,對快取演算法的詳細分析超出本文的範圍。 相反地,我們會為您提供有關磁碟子系統快取的快速清單。
- 快取可改善持續的循序寫入 I/O,因為它會將許多較小的寫入作業緩衝到較大的 I/O 區塊。 它也會將作業取消儲存在幾個大型區塊中,而不是許多小型區塊。 此優化可減少隨機和循序 I/O 作業總數,讓其他 I/O 作業有更多資源可供使用。
- 快取不會改善記憶體子系統上的持續寫入 I/O 輸送量,因為它只會緩衝寫入,直到有主軸可供認可數據為止。 當來自主軸的所有可用 I/O 都由數據長時間飽和時,快取最終就會填滿。 若要清空快取,您必須提供足夠的 I/O 讓快取自行清除,方法是提供額外的主軸,或在高載之間提供足夠的時間讓系統趕上。
- 較大的快取允許更多數據緩衝處理,這表示快取可以處理較長的飽和期間。
- 在一般記憶體子系統中,OS 體驗使用快取改善寫入效能,因為系統只需要將數據寫入快取。 不過,一旦基礎媒體與 I/O 作業飽和,快取就會填滿並寫入效能回到一般磁碟速度。
- 當您快取讀取 I/O 時,當您循序將數據儲存在桌面上,並允許快取提前讀取時,快取最有用。 預先讀取是快取可以立即移至下一個扇區,就像下一個扇區包含系統下一步要求的數據一樣。
- 讀取 I/O 是隨機的,磁碟控制器上的快取並不會增加磁碟可讀取的數據量。 如果 OS 或應用程式型快取大小大於硬體型快取大小,則任何增強磁碟讀取速度的嘗試不會變更任何專案。
- 在 Active Directory 中,快取只會受限於系統保留的 RAM 數量。
SSD 考量
固態硬碟(SSD)與以主軸為基礎的硬碟基本不同。 SSD 可以處理較高的 I/O 磁碟區,且延遲較低。 雖然 SSD 在每 GB 的成本上可能很昂貴,但就每一 I/O 的成本而言,它們非常便宜。 不過,使用 SSD 的容量規劃牽涉到詢問自己關於主軸的相同問題:它們可以處理多少 IOPS,以及這些 IOPS 的延遲為何?
以下是規劃 SSD 時應考慮的一些事項:
- IOPS 和延遲都受限於製造商設計。 在某些情況下,某些 SSD 設計的執行效能可能會比以主軸為基礎的技術更差。 當您嘗試決定是否應該使用 SSD 或主軸時,您應該檢閱並驗證製造商規格磁碟驅動器,而不是假設所有技術都能以某種方式運作。
- IOPS 類型可以有不同的值,視其為讀取或寫入而定。 AD DS 服務主要是以讀取為基礎,因此,相較於其他應用程式案例,您使用的寫入技術較不具效果。
- 寫入耐力是假設 SSD 單元格的壽命有限,而且最終會在您使用它們之後磨損。 對於資料庫磁碟驅動器,以讀取為主的 I/O 配置檔會將數據格的寫入耐力延伸到您不需要擔心寫入耐力的地步。
摘要
想像儲存就像房子的室內管道一樣。 您儲存資料之媒體的 IOPS 就像家庭的主要清空一樣。 當主排水溝被堵塞或受限於大小或管道坍塌時,排水溝就會恢復,當家庭使用大量的水時,水管無法正常運作。 此案例就像共用環境在同一個SAN、NAS 或iSCSI上使用相同的基礎媒體使用共用記憶體的一或多個系統時。 因為使用者需求超過系統跟上的能力,因此效能會受到影響。
同樣地,在我們的虛構管道案例中,您可以採取不同的方法來解決木塊和其他效能問題:
- 若要解決折疊的排水管道或太小的排水管,您需要將管道取代為使用且大小正確的管道。 在共用記憶體條款中,它就像在基礎結構中新增硬體或重新發佈共享系統上的使用方式。
- 取消清空需要識別基礎問題及其位置,然後使用適當的工具加以移除。 例如,廚房水槽排水溝中相對簡單的木塊只需要柱塞或排水清潔器才能移除,而涉及被困物件的更複雜的木塊可能需要排水蛇。 同樣地,在共用記憶體系統中,識別效能問題的原因可協助您找出您是否需要建立系統層級備份、在所有伺服器上同步處理防病毒軟體掃描,或同步處理您在尖峰期間執行的重組軟體。
在大部分管道設計中,多個排水管會饋送至主要排水溝。 當排水溝堵塞時,水只會被困在木塊所在的點後面。 如果連接點被堵塞,則該連接點後面的所有排水道都會停止排水。 在記憶體案例中,連接點被堵塞就像是多載開關、驅動程式相容性問題或未同步處理的軟體工作。 您必須測量 IOPS 和 I/O 大小,以判斷您的記憶體系統是否可以處理負載,然後視需要調整系統。
附錄 D:更多 RAM 不是選項的環境中的記憶體疑難解答
虛擬化記憶體之前的許多記憶體建議都提供兩個用途:
- 隔離 I/O 以防止 OS 軸上的效能問題影響資料庫和 I/O 配置檔的效能。
- 利用以主軸為基礎的硬碟和快取的效能提升,可在搭配AD DS記錄檔的循序 I/O 使用時提供您的系統。 將循序 I/O 隔離至個別實體磁碟驅動器也可以增加輸送量。
使用新的記憶體選項,先前記憶體建議背後的許多基本假設已不再成立。 虛擬化記憶體案例,例如iSCSI、SAN、NAS 和虛擬磁碟映像檔,通常會在多部主機之間共用基礎儲存媒體。 這項差異否定了您必須隔離 I/O 並優化循序 I/O 的假設。 現在,存取共享媒體的其他主機可以降低域控制器的回應能力。
當您容量規劃記憶體效能時,您應該考慮三件事:
- 冷快取狀態
- 暖快取狀態
- 備份和還原
冷快取狀態是您一開始重新啟動域控制器或重新啟動 Active Directory 服務時,因此 RAM 中沒有 Active Directory 數據。 暖快取狀態是域控制器處於穩定狀態且已快取資料庫時。 在效能設計方面,將冷快取變暖就像短期衝刺,而執行具有完全熱快取的伺服器就像馬拉松。 定義這些狀態和它們所驅動的不同效能配置檔很重要,因為您需要在評估容量時考慮兩者。 例如,因為您有足夠的 RAM 在暖快取狀態期間快取整個資料庫,這無法協助您在冷快取狀態期間優化效能。
對於這兩個快取案例,最重要的是記憶體將數據從磁碟移至記憶體的速度。 當您將快取暖時,隨著查詢重複使用數據,快取命中率增加,以及前往磁碟以擷取數據的頻率降低,效能會改善。 因此,必須移至磁碟的不良效能影響也會降低。 任何效能降低都是暫時性的,而且通常會在快取達到其暖狀態且系統允許的大小上限時消失。
您可以藉由測量 Active Directory 中的可用 IOPS,測量系統從磁碟取得數據的速度。 有多少可用的 IOPS 也會受限於基礎記憶體中有多少 IOPS 可用。 從規劃的觀點來看,因為將快取和備份或還原狀態變暖是通常會在尖峰時段發生且受限於 DC 負載的特殊事件,因此我們無法在離峰時段只輸入這些狀態以外的一般建議。
在大部分情況下,AD DS 主要是讀取 I/O,且讀取比例為 90% 到 10% 寫入。 讀取 I/O 是用戶體驗的典型瓶頸,而寫入 I/O 是降低寫入效能的瓶頸。 快取通常會為讀取 I/O 提供最少的優點,因為 NTDS.dit 檔案的 I/O 作業主要是隨機的。 因此,您的主要優先順序是確定您已正確設定讀取 I/O 配置檔記憶體。
在正常作業條件下,您的記憶體規劃目標是將系統將AD DS的要求傳回磁碟的等候時間降至最低。 未處理的 I/O 作業數目應該小於或等於磁碟上的路徑數目。 針對效能監視案例,我們通常建議 LogicalDisk((<NTDS Database Drive>))\Avg Disk sec/Read 計數器應該小於 20 毫秒。 您應該根據記憶體類型,將作業閾值設定得較低,盡可能接近記憶體的速度,在 2 到 6 毫秒的範圍內。
下列折線圖顯示記憶體系統中的磁碟延遲測量。
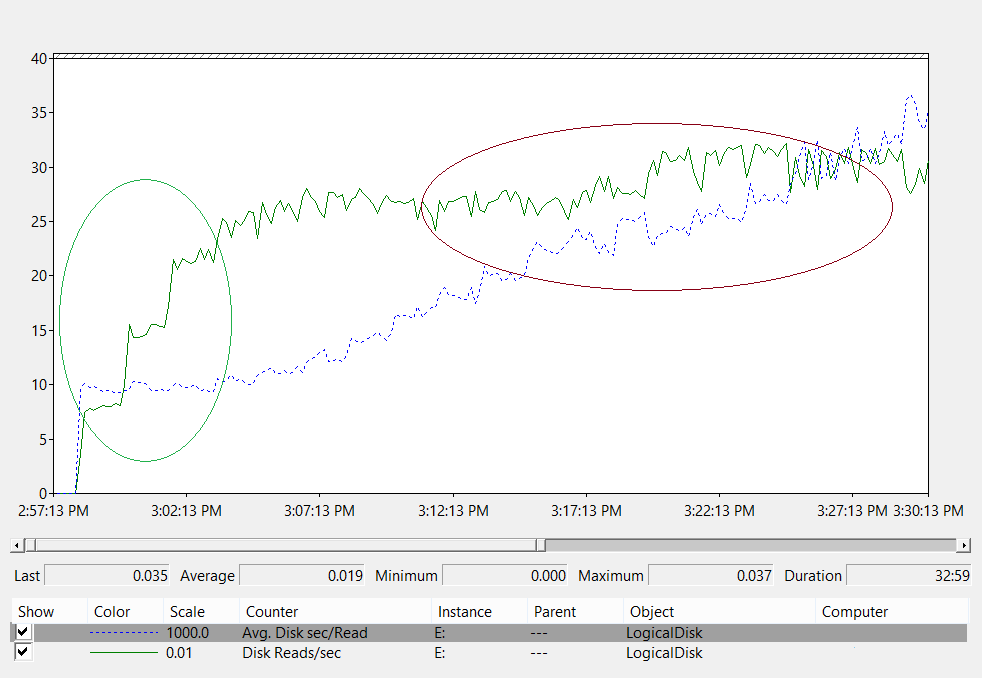
讓我們分析此折線圖:
- 以綠色圓圈的圖表左側區域會顯示延遲在 10 毫秒時保持一致,因為負載從 800 IOPS 增加到 2,400 IOPS。 此區域是基礎記憶體處理 I/O 要求速度的基準。 不過,此基準會受到您使用何種記憶體解決方案的影響。
- 在maroon中圓圈的圖表右側區域會顯示基準與數據收集結尾之間的系統輸送量。 輸送量本身不會變更,但延遲會增加。 此區域示範每當要求磁碟區超過基礎記憶體的實體限制時,要求在佇列中等候的時間較長的時間才能傳送至記憶體子系統。
現在,讓我們來思考此數據告訴我們的內容。
首先,假設使用者查詢大型群組的成員資格需要系統從磁碟讀取 1 MB 的數據。 您可以評估所需的 I/O 數量,以及這些值所花費的作業時間:
- 每個 Active Directory 資料庫頁面的大小為 8 KB。
- 系統讀取的頁數下限為 128。
- 因此,在圖表的基準區域中,系統至少需要 1.28 秒的時間才能從磁碟載入數據,並將其傳回用戶端。 在 20 毫秒的標記中,輸送量遠高於建議的最大值,此程式需要 2.5 秒的時間。
根據這些數位,您可以使用下列方程式來計算快取將加熱的速度:
每個 I/O × 8 KB 2,400 IOPS
執行此計算之後,我們可以說此案例中的快取暖率是 20 MBps。 換句話說,系統會每隔 53 秒將大約 1 GB 的資料庫載入 RAM。
注意
當元件積極讀取或寫入磁碟時,通常會在短時間內增加延遲。 例如,當系統正在備份或 AD DS 執行垃圾收集時,延遲會增加。 在原始使用量估計值之上,您應該為這些定期事件提供額外的空間。 您的目標是提供足夠的輸送量來容納這些尖峰,而不會影響整體運作。
根據您設計記憶體系統的方式,快取的暖和速度有實體限制。 將快取暖至基礎記憶體所能容納速率的唯一專案,就是傳入的用戶端要求。 執行腳本以嘗試在尖峰時段預先準備快取與實際用戶端要求競爭、增加整體負載、載入與用戶端要求無關的數據,以及降低效能。 建議您避免使用人工量值來將快取暖。