低等級適應 (LoRA) 可用來微調 Phi 矽模型 ,以增強其特定使用案例的效能。 藉由使用 LoRA 來優化 Phi Silica 這款 Microsoft Windows 的本地語言模型,您可以達成更精確的結果。 此程式牽涉到定型 LoRA 配接器,然後在推斷期間套用它,以改善模型的精確度。
先決條件
- 您已識別出一個用於提升 Phi Silica 反應的使用案例。
- 您已選擇評估準則來決定什麼是「良好回應」。
- 您已嘗試 Phi 矽 API,且它們不符合您的評估準則。
訓練配接器
若要使用 Windows 11 將 LoRA 配接器定型,以便微調 Phi 二氧化二色模型,您必須先產生定型程式將使用的數據集。
產生數據集以搭配LoRA配接器使用
若要產生數據集,您必須將數據分割成兩個檔案:
train.json– 用於定型配接器。test.json– 用於評估配接器在定型期間和之後的效能。
這兩個檔案都必須使用 JSON 格式,其中每一行都是代表單一範例的個別 JSON 物件。 每個範例都應該包含使用者與助理之間交換的訊息清單。
每個訊息物件都需要兩個字段:
content:訊息的文字。role"user":或"assistant",表示寄件者。
請參閱下列範例:
{"messages": [{"content": "Hello, how do I reset my password?", "role": "user"}, {"content": "To reset your password, go to the settings page and click 'Reset Password'.", "role": "assistant"}]}
{"messages": [{"content": "Can you help me find nearby restaurants?", "role": "user"}, {"content": "Sure! Here are some restaurants near your location: ...", "role": "assistant"}]}
{"messages": [{"content": "What is the weather like today?", "role": "user"}, {"content": "Today's forecast is sunny with a high of 25°C.", "role": "assistant"}]}
訓練秘訣:
每個范例行結尾不需要逗號。
盡可能包含盡可能多的高品質和多樣化的範例。 為了獲得最佳結果,請在您的
train.json檔案中收集至少數千個訓練樣本。檔案
test.json可能較小,但應該涵蓋您預期模型要處理的互動類型。請創建
train.json和test.json文件,並在每行加入一個 JSON 物件,每個物件都包含使用者與助理之間的簡短對話。 數據的質量和數量將大幅影響LoRA配接器的有效性。
在 AI 工具組中訓練 LoRA 配接器
若要使用 適用於 Visual Studio Code 的 AI 工具組來定型 LoRA 配接器,您必須先具備下列必要條件:
在 Azure Container Apps 中具有可用配額的 Azure 訂用帳戶。
- 建議您使用 A100 GPU 或更佳的方式有效率地執行微調作業。
- 檢查您在 Azure 入口網站中是否有可用的配額。 如果您想要協助尋找配額,請參閱 檢視配額。
如果您還沒有 Visual Studio Code ,則必須安裝它。
若要安裝適用於 Visual Studio Code 的 AI 工具組:
下載 AI 工具組延伸模組之後,您就可以從 Visual Studio Code 內的左工具列窗格存取它。
流覽至 [工具>微調]。
輸入專案名稱和專案位置。
從「模型目錄」選取「microsoft/phi-silica」。
選取 [設定專案]。
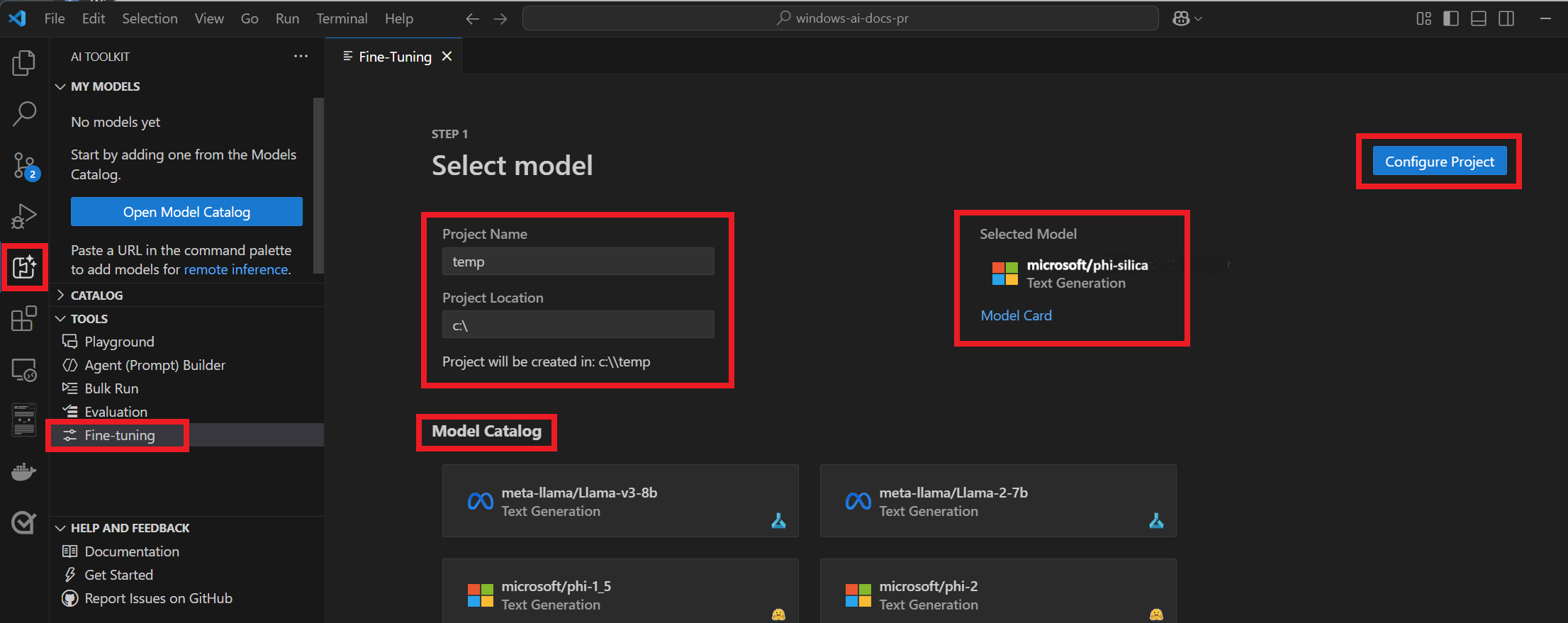
選取最新版本的 Phi 矽石。
在 [數據>定型數據集名稱 ] 和 [ 測試數據集名稱] 下,選取您的
train.json和test.json檔案。選取 [產生專案] - 將會開啟新的 VS Code 視窗。
請確定 bicep 檔案中已選取正確的工作負載配置檔,讓 Azure 作業正確部署並執行。
workloadProfiles底下新增下列內容:{ workloadProfileType: 'Consumption-GPU-NC24-A100' name: 'GPU' }選取 [新增微調作業],然後輸入作業的名稱。
隨即會出現對話框,要求您選取要用來存取 Azure 訂用帳戶的Microsoft帳戶。
選取您的帳戶之後,您必須從訂用帳戶下拉功能表中選取資源群組。
您現在會看到您的微調作業已成功啟動,並顯示其作業狀態。 作業完成後,您可以選擇選取 [下載] 按鈕來下載新訓練的 LoRA 配接器。 微調作業通常需要平均 45 - 60 分鐘才能完成。
推斷
定型是 AI 模型從大型數據集學習、辨識模式和相互關聯的初始階段。 另一方面,推理是應用階段,當中已訓練的模型(在我們的案例中為 Phi 矽)會使用新的數據(LoRA 配接器)來進行預測或做出決策,以生成更客製化的輸出。
若要套用已定型的LoRA配接器:
使用 AI 開發人員資源庫應用程式。 AI Dev Gallery 是一個應用程式,讓您可以實驗本機 AI 模型和 API,並且檢視和匯出範例程式代碼。 深入瞭解 AI 開發展示館。
安裝 AI Dev Gallery 之後,請開啟應用程式,並選取(AI API)標籤,接著選取(Phi Silica LoRA)。
選取配接器檔案。 要儲存這些項目的預設位置是:
Desktop/lora_lab/trainedLora。完成 [系統提示] 和 [提示] 欄位。 然後選取 [產生],以查看與沒有LoRA配接器之 Phi 矽之間的差異。
試驗提示和系統提示,看看這對您的輸出有何不同。
選取 [匯出範例] 以下載只包含此範例程式代碼的獨立 Visual Studio 解決方案。
產生回應
使用 AI 開發人員資源庫測試新的 LoRA 配接器之後,您可以使用下列程式代碼範例,將配接器新增至 Windows 應用程式。
using Microsoft.Windows.AI.Text;
using Microsoft.Windows.AI.Text.Experimental;
// Path to the LoRA adapter file
string adapterFilePath = "C:/path/to/adapter/file.safetensors";
// Prompt to be sent to the LanguageModel
string prompt = "How do I add a new project to my Visual Studio solution?";
// Wait for LanguageModel to be ready
if (LanguageModel.GetReadyState() == AIFeatureReadyState.NotReady)
{
var languageModelDeploymentOperation = LanguageModel.EnsureReadyAsync();
await languageModelDeploymentOperation;
}
// Create the LanguageModel session
var session = LanguageModel.CreateAsync();
// Create the LanguageModelExperimental
var languageModelExperimental = new LanguageModelExperimental(session);
// Load the LoRA adapter
LowRankAdaptation loraAdapter = languageModelExperimental.LoadAdapter(adapterFilePath);
// Set the adapter in LanguageModelOptionsExperimental
LanguageModelOptionsExperimental options = new LanguageModelOptionsExperimental
{
LoraAdapter = loraAdapter
};
// Generate a response with the LoRA adapter provided in the options
var response = await languageModelExperimental.GenerateResponseAsync(prompt, options);
負責任的 AI - 微調的風險和限制
當客戶微調 Phi Silica 時,它可以改善特定任務和領域的模型效能和精確度,但也可能會帶來需注意的新風險和限制。 其中一些風險和限制如下:
數據品質與表示:用於微調的數據品質和代表性可能會影響模型的行為和輸出。 如果數據是嘈雜、不完整、過時或包含有害內容如刻板印象,模型可能會繼承這些問題,並產生不正確或有害的結果。 例如,如果數據包含性別刻板印象,模型可以放大它們併產生性別歧視語言。 客戶應仔細選取並預先處理其數據,以確保其與預定的工作和網域相關、多樣化且平衡。
模型健全性和一般化:模型處理多樣化且複雜的輸入和案例的能力,在微調之後可能會降低,特別是如果數據太窄或特定時。 模型可以過度適應數據,並失去其一些一般知識和功能。 例如,如果數據只與運動有關,模型就很難回答問題或產生其他主題的文字。 客戶應該評估模型在各種輸入和案例上的效能和健全性,並避免將模型用於超出其範圍的工作或領域。
Regurgitation:雖然您的訓練數據不適用於Microsoft或任何第三方客戶,但經過不佳微調的模型可能會回吐,或直接重複訓練數據。 客戶應負責從其定型數據中移除任何 PII 或其他受保護的資料,並應評估其微調模型是否存在過度擬合或其他低質量回應。 為避免重複或冗餘,建議客戶提供大規模且多樣化的資料集。
模型透明度和可解釋性:模型邏輯和推理在微調後可能會變得更不透明且難以理解,特別是如果數據很複雜或抽象時。 微調的模型可能會產生非預期、不一致或矛盾的輸出,而且客戶可能無法解釋模型到達這些輸出的方式或原因。 例如,如果數據與法律或醫療條款有關,模型可能會產生不正確或誤導性的輸出,而且客戶可能無法驗證或證明其合理性。 客戶應監視和稽核模型的輸出和行為,並提供清楚且準確的資訊和指引給模型的終端使用者。