AI Toolkit for VS Code (AI Toolkit) 是一個 VS Code 延伸模組,可讓您使用您的應用程式或雲端下載、測試、微調及部署 AI 模型。 如需詳細資訊,請參閱 AI 工具組概觀。
注意
如需 AI 工具組VS Code的其他文件和教學課程,請參閱VS Code檔:Visual Studio Code的 AI 工具組。 您會發現遊樂場、使用 AI 模型、微調本機和雲端式模型等等的指引。
在本文中,您將學會如何:
- 設定本機環境以微調。
- 執行微調作業。
必要條件
- 已完成 開始使用適用於的 Visual Studio CodeAI 工具組。
- 如果您使用 。 請參閱 如何使用 WSL 在 Windows 上安裝 Linux ,以取得已安裝 WSL 和預設 Linux 發行版。 WSL Ubuntu 散發套件 18.04 或更新版本必須先安裝並設定為預設散發套件,才能使用適用於的 VS CodeAI 工具組。 瞭解如何 更改預設分配。
- 如果您使用 Linux 計算機,它應該是 Ubuntu 發行版 18.04 或更新版本。
- 在本教學課程中使用模型需要 NVIDIA GPU 來進行微調。 目錄中還有其他模型可以使用 CPU 或 NPU 在 Windows 裝置上載入。
提示
請確定您的電腦已安裝最新的 NVIDIA 驅動程式 。 如果您在 遊戲就緒驅動程式 或 Studio 驅動程式之間有選擇,請下載 Studio 驅動程式。
您必須知道 GPU 的模型,才能下載正確的驅動程式。 若要瞭解您擁有的 GPU,請參閱 如何檢查您的 GPU 及其重要原因。
環境設定
若要檢查您是否擁有在本機裝置或雲端 VM 上執行微調作業所需的所有必要條件,請開啟命令選擇區 (Shift+Control+P) 並搜尋 AI 工具組:驗證環境必要條件。
如果您的本機裝置通過驗證檢查,將會啟用 [ 設定 WSL 環境 ] 按鈕,讓您選取。 這會安裝執行微調作業所需的所有相依性。
雲端 VM
如果您的本機計算機沒有 Nvidia GPU 裝置,則可以使用 Nvidia GPU 在雲端 VM 上微調 -- Windows 和 Linux (如果您有配額)。 在 Azure 中,您可以使用下列 VM 系列來微調:
- NCasT4 v3 系列
- NC A100 v4 系列
- ND A100 v4 系列
- NCads H100 v5 系列
- NCv3 系列
- NVadsA10 v5 系列
提示
VS Code 可讓您從遠端連線到雲端 VM。 如果您不熟悉這項功能,請閱讀 透過 SSH 進行遠端開發教學課程
微調模型
AI 工具組會使用稱為 QLoRA 的方法,將量化和低秩適應(LoRA)結合在一起,以便使用您自己的數據進行微調。 深入瞭解 QLoRA:請參閱 QLoRA:量化 LLM 的有效微調。
步驟 1:設定專案
若要使用 QLoRA 啟動新的微調工作階段,請選取 AI 工具組左面板中 [工具] 區段中的 [微調] 專案。
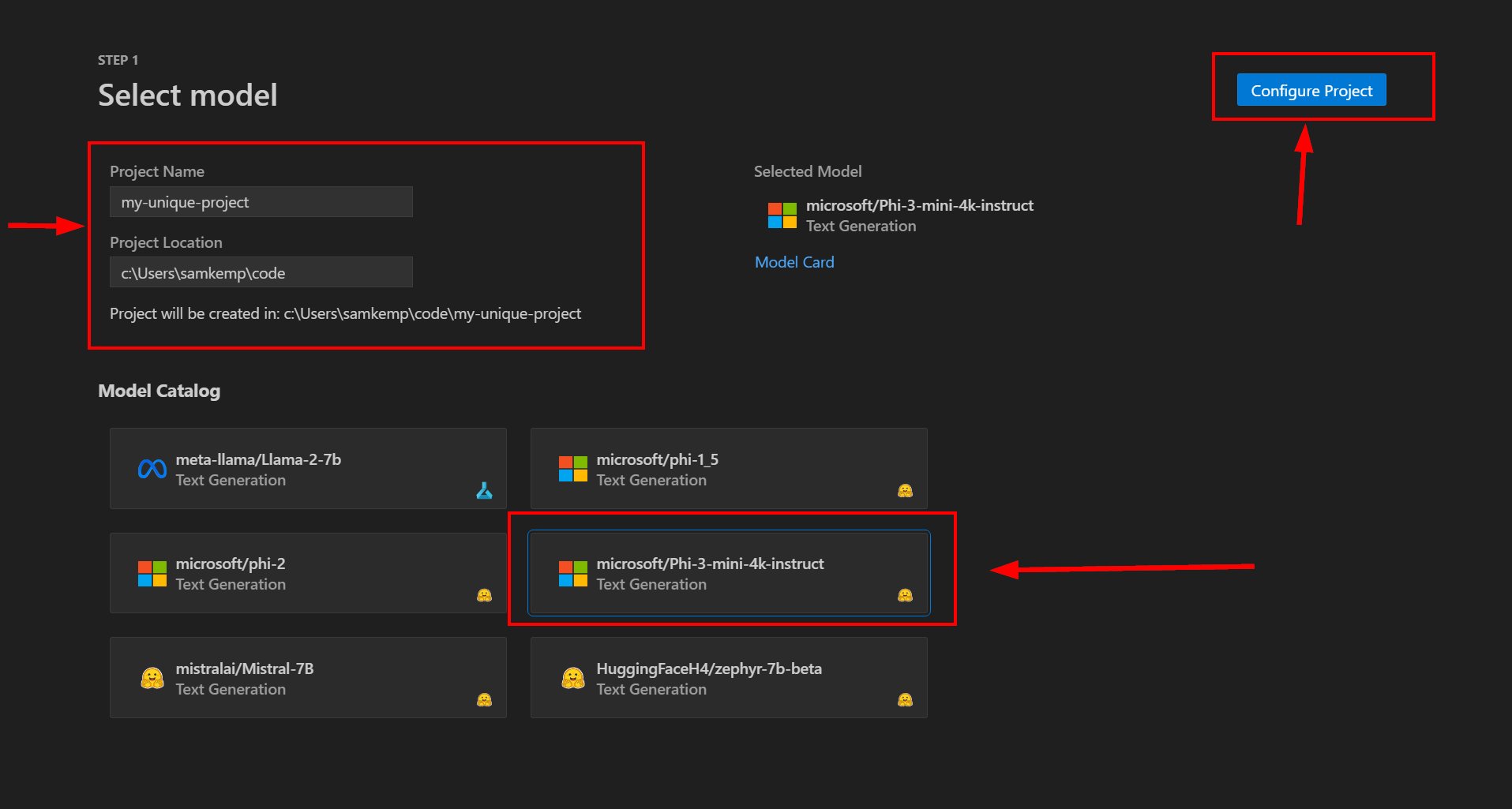
首先輸入唯一的專案名稱和專案位置。 系統會在您選取用來儲存項目檔的位置中建立具有指定項目名稱的新資料夾。
接下來,從模型目錄選取模型 - 例如 Phi-3-mini-4k-指示 -,然後選取 [設定專案]:
接著,系統會提示您設定微調項目設定。 確定勾選 [ 在本地進行微調 ] 複選框(未來擴充功能可讓您將微調移至雲端):
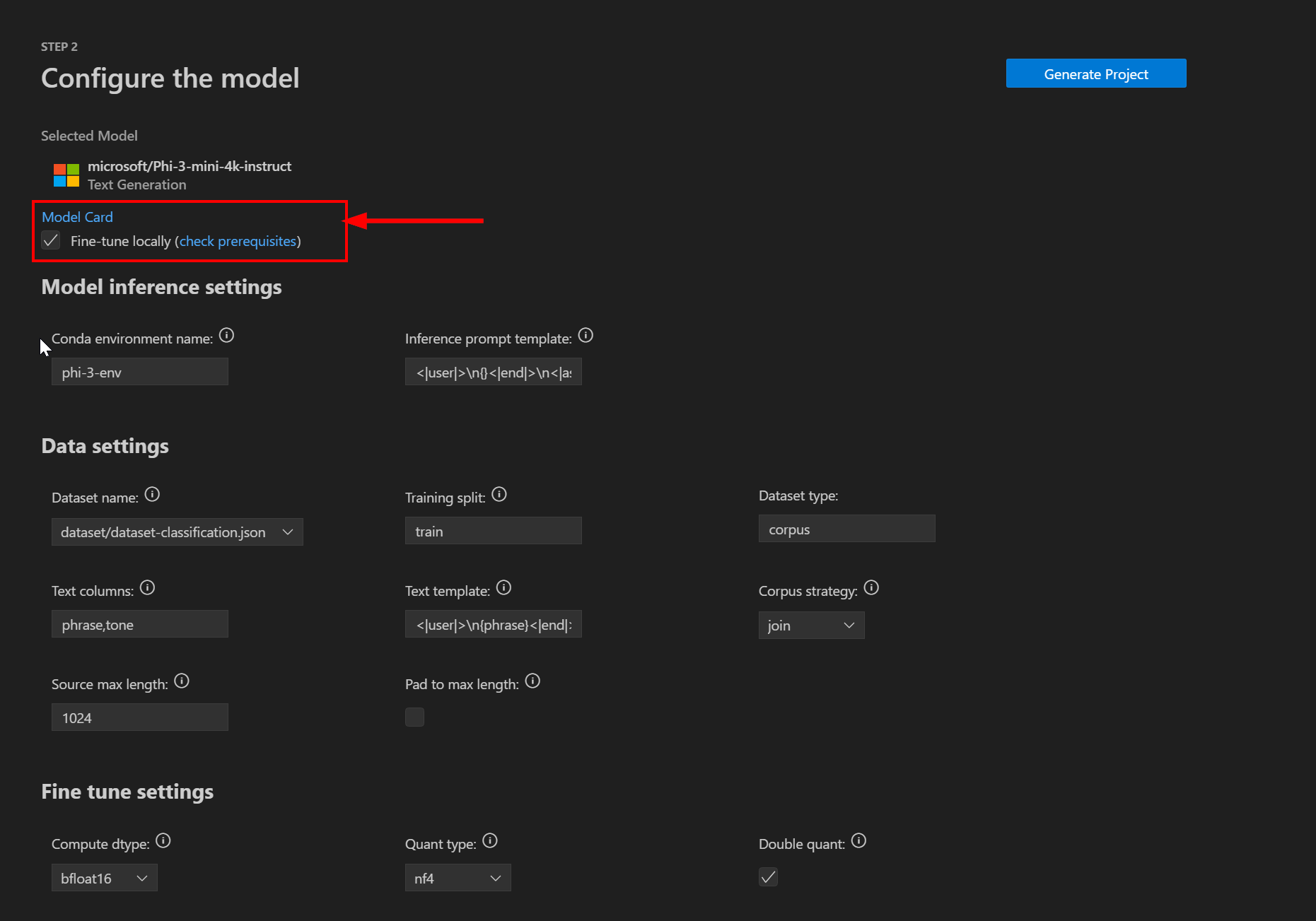
模型推斷設定
[ 模型推斷 ] 區段中有兩個可用的設定:
| 設定 | 描述 |
|---|---|
| Conda 環境名稱 | 要啟動並用於微調程式的 conda 環境名稱。 此名稱在您的 conda 安裝中必須是唯一的。 |
| 推論提示模板 | 提示範本在推斷時間使用。 請確定這符合微調的版本。 |
資料設定
下列設定可在 [數據 ] 區段中取得,以設定數據集資訊:
| 設定 | 描述 |
|---|---|
| 數據集名稱 | 要用於微調模型的數據集名稱。 |
| 訓練集切分 | 數據集的定型分割名稱。 |
| 數據集類型 | 要使用的數據集類型。 |
| 文字數據行 | 數據集中要填入定型提示的數據行名稱。 |
| 文字範本 | 用來微調模型的提示範本。 這會使用 文本欄位中的替換標記。 |
| 公司策略 | 表示您是否要 合併 樣本或 逐行處理它們。 |
| 來源最大長度 | 每個定型範例的令牌數目上限。 |
| 填充至最大長度 | 將 PAD 令牌新增至定型範例,直到令牌數目上限為止。 |
微調設定
下列設定可在 [微調 ] 區段中取得,以進一步設定微調程式:
| 設定 | 資料類型 | 預設值 | 描述 |
|---|---|---|---|
| 計算 Dtype | 繩子 | bfloat16 | 模型權數和配接器權數的數據類型。 對於 4 位量子化模型,它也是量化模組的計算數據類型。 有效值:bfloat16、float16 或 float32。 |
| Quant 類型 | 繩子 | nf4 | 要使用的量化數據類型。 有效值:fp4 或 nf4。 |
| 雙量化 | 布林值 | 是 | 是否要使用巢狀量化,其中第一個量子化中的量化常數會再次量化。 |
| Lora r | 整數 | 64 | Lora 關注維度。 |
| Lora alpha | 浮動 | 16 | Lora 縮放的 Alpha 參數。 |
| LoRA 隨機失活 | 浮動 | 0.1 | Lora 層的卸除機率。 |
| 評估數據集大小 | 浮動 | 1024 | 驗證數據集的大小。 |
| 種子 | 整數 | 0 | 初始化的隨機種子。 |
| 數據種子 | 整數 | 42 | 要與數據取樣器搭配使用的隨機種子。 |
| 每個裝置定型批次大小 | 整數 | 1 | 每個 GPU 的批次大小以進行定型。 |
| 每個裝置的評估批次大小 | 整數 | 1 | 要評估的每個 GPU 批次大小。 |
| 漸層累積步驟 | 整數 | 4 | 執行回溯/更新傳遞之前,要累積漸層的更新步驟數目。 |
| 啟用漸層檢查點 | 布林值 | 是 | 使用漸層檢查點。 建議使用 來儲存記憶體。 |
| 學習率 | 浮動 | 0.0002 | AdamW 的初始學習速率。 |
| 最大步驟 | 整數 | -1 | 如果設定為正數,則會執行定型步驟的總數。 這會覆寫num_train_epochs。 如果使用有限的可反覆運算數據集,定型可能會在所有數據用盡時到達設定的步驟數目之前停止。 |
步驟 2:產生專案
設定所有參數之後,按兩下 [ 產生專案]。 這會執行下列動作:
- 起始模型下載。
- 安裝所有必要條件和相依性。
- 建立 VS Code 工作區。
下載模型並準備好環境時,您可以從 AI 工具組啟動專案,方法是在 [步驟 3 - 產生專案] 頁面上選取 [工作區中的重新啟動視窗]。 這會啟動連線至您環境的新實例 VS Code 。
注意
系統可能會提示您安裝其他擴充功能,例如Prompt flowVS Code。 為了獲得最佳微調體驗,請安裝它們以繼續進行。
重新啟動的視窗將會在其工作區中具有下列資料夾:
| 資料夾名稱 | 描述 |
|---|---|
| 資料集 | 此資料夾包含 範本 的數據集(dataset-classification.json - 包含片語和音調的 JSON 行檔案)。 如果您將項目設定為使用本機檔案或擁抱臉部數據集,您可以忽略此資料夾。 |
| 微調 | 要執行微調作業的 Olive 組態檔。 Olive 是一種易於使用的硬體感知模型優化工具,可跨模型壓縮、優化和編譯撰寫領先業界的技術。 根據模型和目標硬體,Olive 會撰寫最適合的優化技術,以輸出最有效率的模型來推斷雲端或邊緣,同時考慮一組限制,例如精確度和延遲。 |
| 推理 | 使用微調模型推斷的程式代碼範例。 |
| infra | 若要使用 Azure Container App Service 進行微調和推斷(即將推出)。 此資料夾包含 Bicep 和組態檔,可用來布建 Azure Container App Service。 |
| 安裝程式 | 用來設定 conda 環境的檔案。 例如,pip 需求。 |
步驟 3:執行微調作業
您現在可以使用下列專案來微調模型:
# replace {conda-env-name} with the name of the environment you set
conda activate {conda-env-name}
python finetuning/invoke_olive.py
重要
微調所需的時間將取決於 GPU 類型、GPU 數目、步驟數目和 Epoch 數目。 這很耗時(例如,可能需要 數小時的時間)。
如果您只想進行快速測試,請考慮減少檔案中的最大步驟olive-config.json。 使用檢查點,因此下一個微調回合會從最後一個檢查點繼續執行。
檢查點和最終模型將會儲存在您的 models 項目資料夾中。
步驟 4:將微調的模型整合到您的應用程式中
接下來,透過、 或console中的web browserprompt flow聊天,使用微調的模型執行推斷。
cd inference
# Console interface.
python console_chat.py
# Web browser interface allows to adjust a few parameters like max new token length, temperature and so on.
# User has to manually open the link (e.g. http://127.0.0.1:7860) in a browser after gradio initiates the connections.
python gradio_chat.py
提示
您也可以在 README.md 頁面中找到可在項目資料夾中找到的指示。