Uniscribe 詞彙
此詞彙包含 Uniscribe 檔中所用詞彙的定義。
ABC 寬度
ABC 寬度是由 GDI ABC 結構所定義的複合值。 結構包含成員 abcA、abcB 和 abcC,對應至字元或執行的「A」、「B」 和 「C」 寬度。
「A」 寬度 低於正 數 (;也稱為「填補」) 或 上方 ( 負數) 到代表圖像或執行之筆跡的螢幕上左邊。 「B」 寬度是黑色寬度,從最左邊的筆跡到最右邊的筆跡寬度。 「C」 寬度在筆跡右邊的上方。
下圖顯示斜體小寫 F,其左和右上方有一個斜體。 也就是說,這裡的 「A」 和 「C」 寬度都是負數。 如需正面 「A」 和 「C」 寬度的圖例,請參閱 下行 。
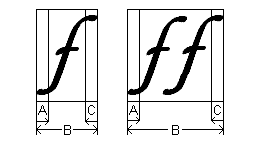
當兩個以上的圖像顯示為單位時,通常只有最左邊的字元會參與執行的 「A」 寬度,而最右邊的字元則只會參與執行的 「C」 寬度。 不過,這不是嚴格的規則。 例如,如果執行中的第一個圖像是窄字母,而第二個字元是寬音符號,而且會以個別字元處理,則讀音符號實際上可能會超過字母。
進階寬度
圖像的進階寬度是從轉譯該圖像的起點到轉譯下一個圖像的起點的書寫方向移動。
雙向堆疊
雙向堆疊是 5 位的整數,可追蹤從左至右與從右至左文字之間的巢狀層級。 從左至右一律會從零開始。 因此,所有偶數值都代表由左至右的文字,而所有奇數值都代表由右至左的文字。 雙向堆疊會以SCRIPT_STATE結構的uBidiLevel成員表示。
雙向文字
雙向文字同時包含由左至右和由右至左部分,但字詞有時也會鬆散地套用至純右至左文字。 所有由右至左的文字都需要使用 雙向堆疊,因為預設 的內嵌層級 為零表示由左至右的文字。
儲存格寬度
應用程式可以藉由調整特定字元的儲存格寬度,來調整文字以符合線條。 若為未正確文字,圖像的儲存格寬度會與其 進階寬度相同。
叢集
叢集是可成形的最小語言單位。 在阿拉伯文和許多索引語言等語言中,用來代表每個字元的字元 (Unicode 字碼點) 取決於構成叢集的周圍字碼點。 在這些語言中,應用程式只能藉由查看叢集,將程式碼點轉譯成適當的字元。 在某些腳本中,例如 Devanagari,叢集中的字元順序可能會與對應的 Unicode 字碼點順序不同。 如需詳細資訊,請參閱 Microsoft 印刷樣式網站上的 Windows 字元處理 。
複雜字集
複雜字集是具有下列任何屬性的 腳本 :
- 允許雙向轉譯。
- 具有內容成形。
- 具有合併字元。
- 具有特製化的斷詞和理由規則。
- 篩選出不合法的字元組合。
- 核心 Windows 字型不支援 ,因此可能需要 字型後援。
在某些複雜的腳本中,字元的順序可能與它們所代表的基礎 Unicode 字元順序相當不同。 如需詳細資訊,請參閱 關於複雜字集 。
注意
在印刷樣式的內容中,有時最好處理用來撰寫英文為複雜字集的拉丁腳本。 範例包括 OPENTYPE_FEATURE_RECORD檔中所述的 Stylistic Alternates 功能,例如 「fi」,其中單一字元代表兩個或多個連續字元。
內嵌層級
字型後援
字型後援是自動選取應用程式中使用者選取的字型以外的字型。 在 Uniscribe 中,當文字的所有或部分都位於使用者選取字型不支援的腳本中時, ScriptStringAnalyse 函式會套用字型後援。
Glyph - 圖像
圖像是字型中的單一顯示單位。 針對 OpenType,此單元是由大綱所定義。 針對其他類型的字型,它可以由點陣圖、一組圖形命令和類似定義。 字元不一定對應至單一字元。 例如,「fi」 ligature (「fi」) 代表兩個字元 「f」 和 「i」。 越南小寫 「o」 與周圓符號和波狀符號 (「ỗ」) 通常由多個字元組成。
item
專案具有單一 腳本 和方向。 ScriptItemize或ScriptItemizeOpenType函式可以將段落分析成專案。 專案不一定是 執行。 它可以包含多個樣式的字元。 專案和執行資訊必須結合,才能判斷 範圍。
LRM
LRM 表示左至右標記 (Unicode 字碼點 U+200E) 。 此標記指定邏輯順序後面的字元應該由左至右轉譯。
LTR
LTR 表示由左至右。
range
範圍是 執行的特殊案例。 它完全落在一 個專案內。 因此,如果專案分成回合,則每個執行都是範圍。
RLM
RLM 表示由右至左標記 (Unicode 字碼點 U+200F) 。 此標記表示應該以邏輯順序呈現其後面的字元,以從右至左呈現。
RTL
RTL 表示由右至左。
執行
執行是 Uniscribe 轉譯的一段文字。 它應該具有單一樣式,也就是字型、大小和色彩,但可以從各種 腳本繪製。 執行可以同時包含由左至右和由右至左的內容。
NADS
NADS 表示國家數位圖形 (Unicode 字碼點 U+206E。 此字詞指定歐洲數位 (U+0030 到 U+0039) 應轉譯為國家數位。 如需國家數位的進一步討論,請參閱 數位圖形 。
點頭
NODS 表示 UNIcode 字碼指標 U+206F () 的 UNIcode 數位圖形。 此字詞指定歐洲數位 (U+0030 到 U+0039) 應該正常轉譯,而不是國家/地區數位。
過剩
超寬是圖像筆跡的一部分,其延伸超過圖像的 進階寬度 。 大部分的字元 (例如 「H」) 沒有過度,因為任一邊有一點空白字元可將它們與相鄰字元分開。 具有超寬的圖像範例是本主題中用來說明 ABC 寬度的斜體 「f」。 斜體 「f」 上方和底部的相鄰字元。 上移對應至負數 「A」 或 「C」 寬度。
填補 (padding)
請參閱 underhang。
指令碼
腳本是撰寫語言的系統,例如拉丁腳本、阿拉伯文腳本、中文腳本。 單一腳本可以套用至一或多個人類語言。 腳本與字型沒有特定的關聯性。 例如,拉丁腳本可以透過 Times New Roman 或 Arial 字型來轉譯得同樣良好。
underhang
底下是圖像之實心部分左邊或右邊的空白字元寬度。 Underhang 對應至正 「A」 或 「C」 寬度,如 ABC 寬度所述。 Underhang 有時稱為「填補」。 下圖顯示小寫字母 n 的下限。
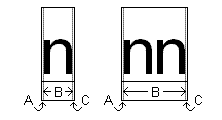
相關主題