Tune prompts using variants
Crafting a good prompt is a challenging task that requires a lot of creativity, clarity, and relevance. A good prompt can elicit the desired output from a pretrained language model, while a bad prompt can lead to inaccurate, irrelevant, or nonsensical outputs. Therefore, it's necessary to tune prompts to optimize their performance and robustness for different tasks and domains.
So, we introduce the concept of variants which can help you test the model’s behavior under different conditions, such as different wording, formatting, context, temperature, or top-k, compare and find the best prompt and configuration that maximizes the model’s accuracy, diversity, or coherence.
In this article, we'll show you how to use variants to tune prompts and evaluate the performance of different variants.
Prerequisites
Before reading this article, it's better to go through:
How to tune prompts using variants?
In this article, we'll use Web Classification sample flow as example.
Open the sample flow and remove the prepare_examples node as a start.
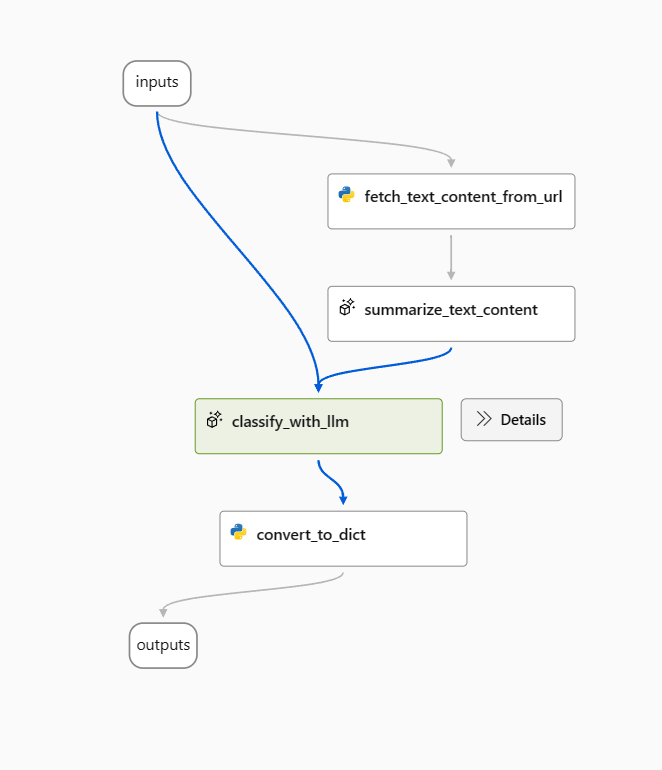
Use the following prompt as a baseline prompt in the classify_with_llm node.

Your task is to classify a given url into one of the following types:
Movie, App, Academic, Channel, Profile, PDF or None based on the text content information.
The classification will be based on the url, the webpage text content summary, or both.
For a given URL : {{url}}, and text content: {{text_content}}.
Classify above url to complete the category and indicate evidence.
The output shoule be in this format: {"category": "App", "evidence": "Both"}
OUTPUT:
To optimize this flow, there can be multiple ways, and following are two directions:
For classify_with_llm node: I learned from community and papers that a lower temperature gives higher precision but less creativity and surprise, so lower temperature is suitable for classification tasks and also few-shot prompting can increase LLM performance. So, I would like to test how my flow behaves when temperature is changed from 1 to 0, and when prompt is with few-shot examples.
For summarize_text_content node: I also want to test my flow's behavior when I change summary from 100 words to 300, to see if more text content can help improve the performance.
Create variants
- Select Show variants button on the top right of the LLM node. The existing LLM node is variant_0 and is the default variant.
- Select the Clone button on variant_0 to generate variant_1, then you can configure parameters to different values or update the prompt on variant_1.
- Repeat the step to create more variants.
- Select Hide variants to stop adding more variants. All variants are folded. The default variant is shown for the node.
For classify_with_llm node, based on variant_0:
- Create variant_1 where the temperature is changed from 1 to 0.
- Create variant_2 where temperature is 0 and you can use the following prompt including few-shots examples.
Your task is to classify a given url into one of the following types:
Movie, App, Academic, Channel, Profile, PDF or None based on the text content information.
The classification will be based on the url, the webpage text content summary, or both.
Here are a few examples:
URL: https://play.google.com/store/apps/details?id=com.spotify.music
Text content: Spotify is a free music and podcast streaming app with millions of songs, albums, and original podcasts. It also offers audiobooks, so users can enjoy thousands of stories. It has a variety of features such as creating and sharing music playlists, discovering new music, and listening to popular and exclusive podcasts. It also has a Premium subscription option which allows users to download and listen offline, and access ad-free music. It is available on all devices and has a variety of genres and artists to choose from.
OUTPUT: {"category": "App", "evidence": "Both"}
URL: https://www.youtube.com/channel/UC_x5XG1OV2P6uZZ5FSM9Ttw
Text content: NFL Sunday Ticket is a service offered by Google LLC that allows users to watch NFL games on YouTube. It is available in 2023 and is subject to the terms and privacy policy of Google LLC. It is also subject to YouTube's terms of use and any applicable laws.
OUTPUT: {"category": "Channel", "evidence": "URL"}
URL: https://arxiv.org/abs/2303.04671
Text content: Visual ChatGPT is a system that enables users to interact with ChatGPT by sending and receiving not only languages but also images, providing complex visual questions or visual editing instructions, and providing feedback and asking for corrected results. It incorporates different Visual Foundation Models and is publicly available. Experiments show that Visual ChatGPT opens the door to investigating the visual roles of ChatGPT with the help of Visual Foundation Models.
OUTPUT: {"category": "Academic", "evidence": "Text content"}
URL: https://ab.politiaromana.ro/
Text content: There is no content available for this text.
OUTPUT: {"category": "None", "evidence": "None"}
For a given URL : {{url}}, and text content: {{text_content}}.
Classify above url to complete the category and indicate evidence.
OUTPUT:
For summarize_text_content node, based on variant_0, you can create variant_1 where 100 words is changed to 300 words in prompt.
Now, the flow looks as following, 2 variants for summarize_text_content node and 3 for classify_with_llm node.

Run all variants with a single row of data and check outputs
To make sure all the variants can run successfully, and work as expected, you can run the flow with a single row of data to test.
Note
Each time you can only select one LLM node with variants to run while other LLM nodes will use the default variant.
In this example, we configure variants for both summarize_text_content node and classify_with_llm node, so you have to run twice to test all the variants.
- Select the Run button on the top right.
- Select an LLM node with variants. The other LLM nodes will use the default variant.
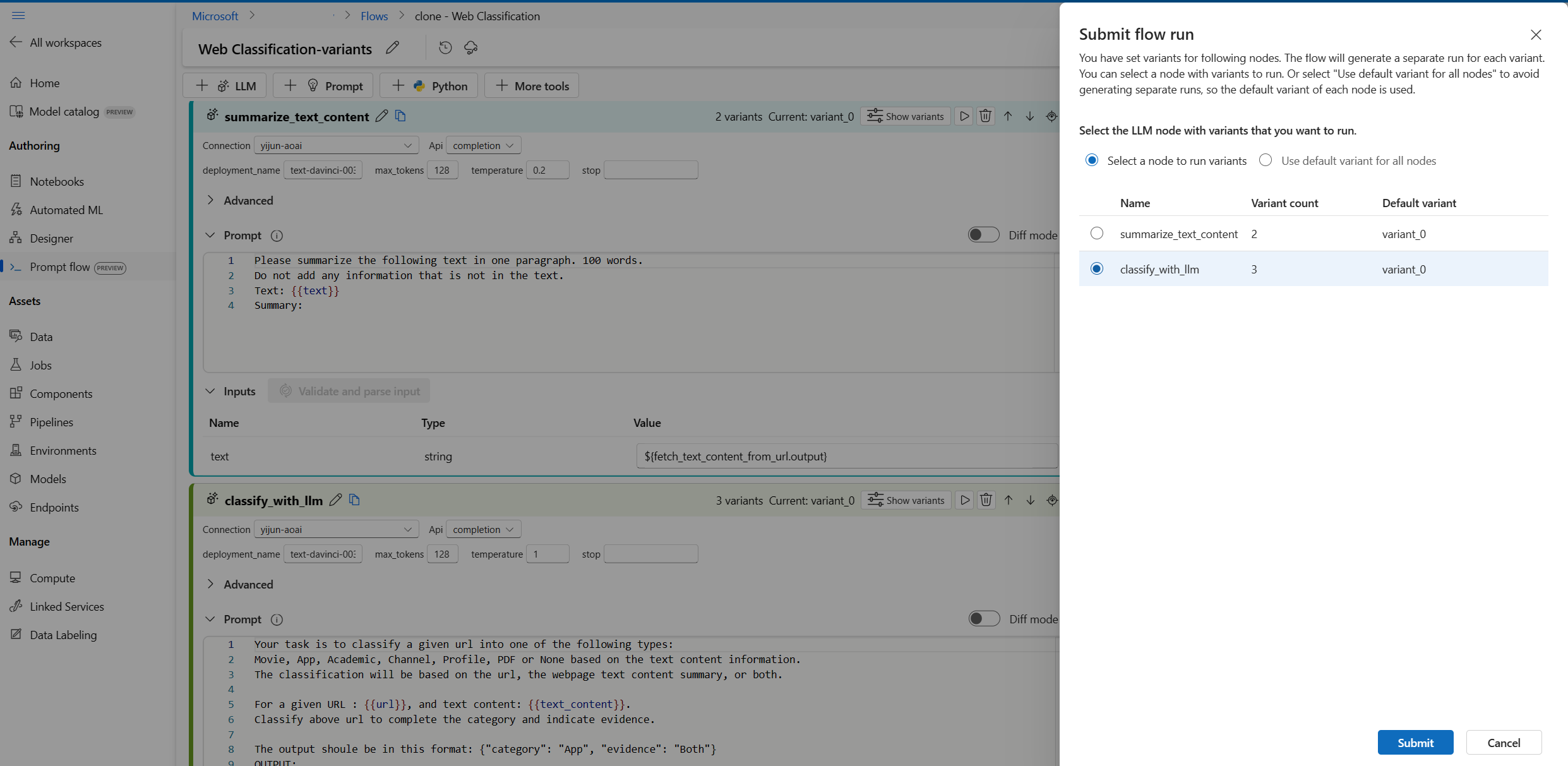
- Submit the flow run.
- After the flow run is completed, you can check the corresponding result for each variant.
- Submit another flow run with the other LLM node with variants, and check the outputs.
- You can change another input data (for example, use a Wikipedia page URL) and repeat the steps above to test variants for different data.

Evaluate variants
When you run the variants with a few single pieces of data and check the results with the naked eye, it cannot reflect the complexity and diversity of real-world data, meanwhile the output isn't measurable, so it's hard to compare the effectiveness of different variants, then choose the best.
You can submit a batch run, which allows you test the variants with a large amount of data and evaluate them with metrics, to help you find the best fit.
First you need to prepare a dataset, which is representative enough of the real-world problem you want to solve with prompt flow. In this example, it's a list of URLs and their classification ground truth. We'll use accuracy to evaluate the performance of variants.
Select Evaluate on the top right of the page.
A wizard for Batch run & Evaluate occurs. The first step is to select a node to run all its variants.
To test how well different variants work for each node in a flow, you need to run a batch run for each node with variants one by one. This helps you avoid the influence of other nodes' variants and focus on the results of this node's variants. This follows the rule of the controlled experiment, which means that you only change one thing at a time and keep everything else the same.
For example, you can select classify_with_llm node to run all variants, the summarize_text_content node will use it default variant for this batch run.
Next in Batch run settings, you can set batch run name, choose a runtime, upload the prepared data.
Next, in Evaluation settings, select an evaluation method.
Since this flow is for classification, you can select Classification Accuracy Evaluation method to evaluate accuracy.
Accuracy is calculated by comparing the predicted labels assigned by the flow (prediction) with the actual labels of data (ground truth) and counting how many of them match.
In the Evaluation input mapping section, you need to specify ground truth comes from the category column of input dataset, and prediction comes from one of the flow outputs: category.
After reviewing all the settings, you can submit the batch run.
After the run is submitted, select the link, go to the run detail page.
Note
The run may take several minutes to complete.
Visualize outputs
- After the batch run and evaluation run complete, in the run detail page, multi-select the batch runs for each variant, then select Visualize outputs. You will see the metrics of 3 variants for the classify_with_llm node and LLM predicted outputs for each record of data.
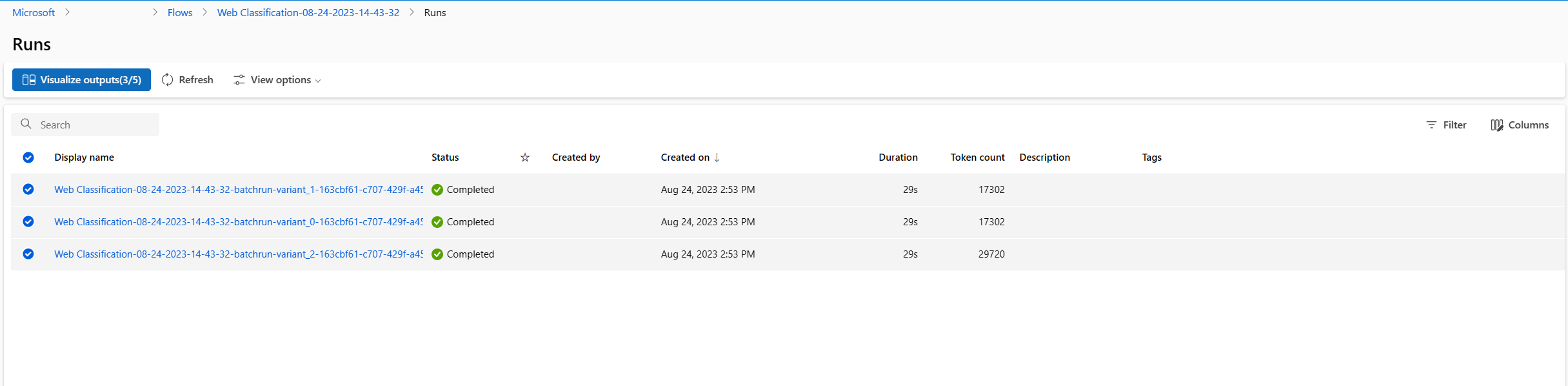
- After you identify which variant is the best, you can go back to the flow authoring page and set that variant as default variant of the node
- You can repeat the above steps to evaluate the variants of summarize_text_content node as well.
Now, you've finished the process of tuning prompts using variants. You can apply this technique to your own prompt flow to find the best variant for the LLM node.
Next steps
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for