Sync-async tasks pattern in MLOps Pipeline
Machine learning operations (MLOps) process needs to combine practices in DevOps and machine learning. In a software project, testing and validating pipelines usually takes a few hours or less to run. Most software projects can complete their unit tests in a few hours. Pipeline tasks that run synchronously or in parallel are enough in most cases. However, in a machine learning project, the training and validation steps can take a long time to run, from a few hours to a few days. It's not practical to wait for the training to finish before moving on to the next step. So, during the MLOps flow design, we need to take different approaches and find a way to combine synchronous and asynchronous steps in order to run the end-to-end training process efficiently.
We will introduce different practices to implement Sync-Async tasks patterns in the MLOps pipeline using the Azure pipeline.
Use synchronous task and toy dataset for ML build validation and unit testing
During the build validation phase, we want to validate the code quality quickly and ensure we implement the data processing code and ML algorithm correctly. The algorithm code should be able to train a model successfully using the provided dataset. To speed up the process, we can use a small toy dataset to reduce the resource and time required for training the model. We can also reduce the training epoch and parameter range to reduce the training time further. This approach uses synchronous pipeline tasks for preparing data and running the training. Because ML model training time is limited, the task can wait for the training to finish and then move on to the next step.

The following code snippet submits an ML training using Azure ML CLI v2 and waits for the result in an ADO task.
parameters:
- name: amlJobExecutionScript
type: string
- name: amlJobSetCommand
type: string
steps:
- task: AzureCLI@2
displayName: Run Azure ML Pipeline and Wait for Results
inputs:
azureSubscription: $(AZURE_RM_SVC_CONNECTION)
scriptType: bash
workingDirectory: $(System.DefaultWorkingDirectory)
scriptLocation: inlineScript
inlineScript: |
export AZUREML_CURRENT_CLOUD="AzureCloud" #Choose a different value according to your cloud environement: AzureCloud, AzureChinaCloud, AzureUSGovernment, AzureGermanCloud
run_id=$(az ml job create -f ${{ parameters.amlJobExecutionScript }} \
${{ parameters.amlJobSetCommand }})
echo "RunID is $run_id"
if [[ -z "$run_id" ]]
then
echo "Job creation failed"
exit 3
fi
az ml job show -n $run_id --web
status=$(az ml job show -n $run_id --query status -o tsv)
if [[ -z "$status" ]]
then
echo "Status query failed"
exit 4
fi
running=("NotStarted" "Queued" "Starting" "Preparing" "Running" "Finalizing")
while [[ ${running[*]} =~ $status ]]
do
sleep 15
status=$(az ml job show -n $run_id --query status -o tsv)
echo $status
done
if [[ "$status" != "Completed" ]]
then
echo "Training Job failed"
exit 3
fi
Other parameters:
AZURE_RM_SVC_CONNECTION: Azure DevOps service connection name.amlJobExecutionScript: Local path to the YAML file containing the Azure ML job specification.amlJobSetCommand: Additional Azure ML job parameters. For example,--name training-object-detectionto specify the job name.
Use asynchronous tasks
Use asynchronous tasks for ML model training steps in both test and production pipelines.
MLOps pipeline usually includes multiple steps, such as data preprocessing, model training, model evaluation, model registration, and model deployment. Sometimes, we need to run ML training in both the integration test and production environments. For example, a defect detection system might want to retrain an ML model using the existing algorithm with a newly updated dataset from a production line. To automate the process, we want to ensure the whole MLOps pipeline can pass the integration test and then run correctly in the production environment. However, the model training step could take a long time to finish. We need to use asynchronous tasks to run the model training step and prevent the long waiting time in the main pipeline.

In Azure DevOps, the Microsoft-hosted agent has a job time-out limitation. You can have a job running for the maximum of 360 minutes (6 hours). The pipeline will fail if the model training step is longer than the time limitation. There are a few ways to implement an asynchronous pipeline task in Azure DevOps to prevent this problem.
Use Azure Pipeline REST API tasks
We recommend using Azure Pipeline REST API tasks to invoke published Azure ML pipelines. A post-back event is sent when the task is complete.
In this approach, you publish your Azure ML pipeline and get a REST endpoint for the pipeline. Then you can use Azure Pipeline REST API task to invoke published Azure ML pipelines and wait for the post-back events. To wait for the post-back event, we need to set the waitForCompletion attribute of the REST API task to true.

Use REST calls to invoke other Azure Pipelines
You can use an Azure ML component to invoke other Azure Pipelines using a REST call.
An Azure ML component is a self-contained piece of code that accomplishes a task in a machine learning pipeline. It is the building block of an Azure ML pipeline.
In this implementation, we use Azure ML CLI/SDK v2 to submit the Azure ML pipeline job. And in the final step of a pipeline job, use an Azure ML component to invoke the REST API of another Azure Pipeline to trigger the next steps.

Following are code snippets of an abbreviate reference implementation of the trigger Azure pipeline Azure ML component.
- Trigger Azure Pipeline python code:
ado-pipeline-trigger.py
import requests
from requests.structures import CaseInsensitiveDict
import os
import argparse
from azure.keyvault.secrets import SecretClient
from azure.identity import DefaultAzureCredential
def parse_args():
"""Parse input args"""
# setup arg parser
parser = argparse.ArgumentParser()
# add arguments
parser.add_argument("--modelpath", required=True, type=str, help="Path to input model")
parser.add_argument("--modelname", required=True, type=str, help="Name of the registered model")
parser.add_argument("--kvname", required=True, type=str, help="Key Vault Resource Name")
parser.add_argument("--secretname", required=True, type=str, help="Secret name for ADO Personal Access Token")
parser.add_argument("--org", required=True, type=str, help="ADO organization Name")
parser.add_argument("--project", required=True, type=str, help="ADO project Name")
parser.add_argument("--branch", required=True, type=str, help="ADO repo branch name")
parser.add_argument("--apiversion", required=True, type=str, help="ADO restful api version")
parser.add_argument("--pipelineid", required=True, type=str, help="ID of the pipeline you need to trigger")
parser.add_argument("--pipelineversion", required=True, type=str, help="Pipeline version")
# parse args
args = parser.parse_args()
# return args
return args
def get_run_id(modelpath):
"""Read run_id from MLmodel"""
mlmodel_path = os.path.join(modelpath, "MLmodel")
run_id = ""
with open(mlmodel_path, "r") as modelfile:
while(True):
line = modelfile.readline()
if not line:
break
if "run_id" in line:
run_id = line.split(':')[1].strip()
break
return run_id
def get_secret_value(kv_name, secret_name):
"""Get the secret value from keyvault"""
kv_uri = f"https://{kv_name}.vault.azure.com"
credential = DefaultAzureCredential()
client = SecretClient(vault_url=kv_uri, credential=credential)
print(f"Retrieving ADO personal access token {secret_name} from {kv_name}.")
retrieved_secret = client.get_secret(secret_name)
return retrieved_secret.value
def trigger_pipeline(args):
"""Trigger Azure Pipeline"""
run_id = get_run_id(args.modelpath)
secret_value = get_secret_value(args.kvname, args.secretname)
headers = CaseInsensitiveDict()
basic_auth_credentials = ('', secret_value)
headers["Content-Type"] = "application/json"
request_body = {
"resources": {
"repositories": {
"self": {
"refName": args.branch
}
}
},
"variables": {
"model_name": {
"value": args.modelname
},
"run_id": {
"value": run_id
}
}
}
url = "https://dev.azure.com/{}/{}/_apis/pipelines/{}/runs?pipelineVersion={}&api-version={}".format(
args.org, args.project, args.pipelineid, args.pipelineversion, args.apiversion
)
print(f"url: {url}")
resp = requests.post(url, auth=basic_auth_credentials, headers=headers, json=request_body)
print(f"response code {resp.status_code}")
resp.raise_for_status()
# run script
if __name__ == "__main__":
# parse args
args = parse_args()
# trigger model registration pipeline
trigger_pipeline(args)
- Trigger Azure Pipeline Azure ML component:
component_pipeline_trigger.yaml
$schema: https://azuremlschemas.azureedge.net/latest/commandComponent.schema.json
name: trigger_pipeline
display_name: trigger Azure pipeline
version: 1
type: command
inputs:
modelpath:
type: mlflow_model
modelname:
type: string
kvname:
type: string
secretname:
type: string
org:
type: string
project:
type: string
branch:
type: string
apiversion:
type: string
pipelineid:
type: integer
pipelineversion:
type: integer
code: ../../../src/pipeline_trigger/
environment: azureml:sklearn-jsonline-keyvault-env@latest
command: >-
python ado-pipeline-trigger.py
--modelpath ${{inputs.modelpath}}
--modelname ${{inputs.modelname}}
--kvname ${{inputs.kvname}}
--secretname ${{inputs.secretname}}
--org ${{inputs.org}}
--project ${{inputs.project}}
--branch ${{inputs.branch}}
--apiversion ${{inputs.apiversion}}
--pipelineid ${{inputs.pipelineid}}
--pipelineversion ${{inputs.pipelineversion}}
Subscribe to Azure ML Event Grid events
You can subscribe to Azure ML Event Grid events and use a supported event handler to trigger another Azure Pipeline.
Azure Machine Learning manages the entire lifecycle of machine learning process. During the lifecycle, Azure ML will publish several status events in Event Grid, such as a completion of training runs event or a registration and deployment of models event. We can use a supported event handler to subscribe these events and react to them.
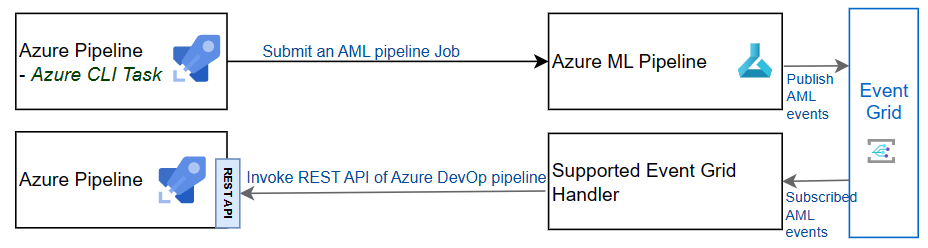
Here are the supported Azure ML events:
| Event type | Subject format |
|---|---|
Microsoft.MachineLearningServices.RunCompleted |
experiments/{ExperimentId}/runs/{RunId} |
Microsoft.MachineLearningServices.ModelRegistered |
models/{modelName}:{modelVersion} |
Microsoft.MachineLearningServices.ModelDeployed |
endpoints/{serviceId} |
Microsoft.MachineLearningServices.DatasetDriftDetected |
datadrift/{data.DataDriftId}/run/{data.RunId} |
Microsoft.MachineLearningServices.RunStatusChanged |
experiments/{ExperimentId}/runs/{RunId} |
For example, to continue the MLOps pipeline when the ML training is finished, we will subscribe RunCompleted event and trigger another Azure Pipeline when the event is published. To trigger another Azure Pipeline, we can use Azure Automation runbooks, Logic Apps, or Azure Functions and implement the trigger next step code in one of them.
Run Azure ML pipelines using Azure Pipeline agents
In this approach, we use Azure Pipeline agents to run the Azure ML pipeline. Because there is no job time-out for self-hosted agents, it can trigger an Azure ML training task and wait for the training to finish, then move on to the next step.

This approach uses synchronized tasks. However, we need to install the agent and maintain the environment that runs the agent.
For more information
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for