Hyper-V
A Windows technology providing a hypervisor-based virtualization solution enabling customers to consolidate workloads onto a single server.
2,589 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EP%3C/text%3E%3C/svg%3E)
Hello all,
So we are facing very frustrating issue with Hyper-v Cluster. Issue happens randomly, we cannot get hang of it.
Just...like that, random VM or VMs cluster resources goes in let's say LOOP state. Pictures will say everything my words cannot.




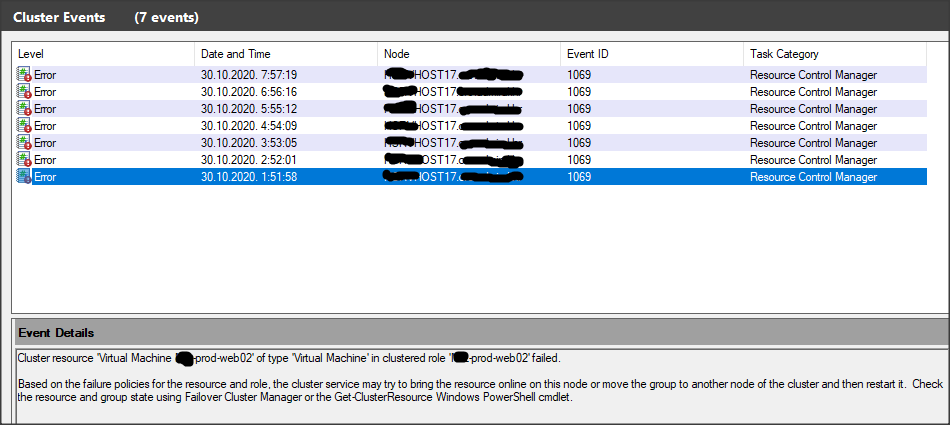
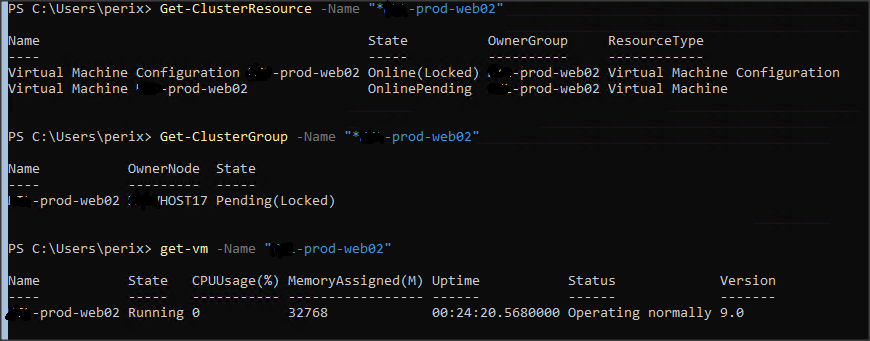
And what you see in first 4 pictures goes in loop like 100 per minute. If you click on it Cluster management console will crash.
On the other side you can manage machine trough hyper-v console, but VM did reset few times during this error.
When I go trough logs I cannot figure out what could cause this, because VM is actually working (until it gets reset)
Log entry from: "Applications and Services Logs\Microsoft\Windows\Hyper-V-StorageVSP" last 9 entrys out of 1800 all made inside one second
1.)Storage device '\?\UNC\NAMEsofs01\Cluster\VMs\XXX-PROD-WEB02\VHDs\XXX-prod-web02_sys.vhdx' received a recovery status notification. Current device state = Recoverable Error Detected, Last status = No Errors, New status = Disconnected.
2.)Storage device '\?\UNC\NAMEsofs01\Cluster\VMs\XXX-PROD-WEB02\VHDs\XXX-prod-web02_sys.vhdx' changed recovery state. Previous state = Recoverable Error Detected, New state = Recoverable Error Detected.
3.)Storage device '\?\UNC\NAMEsofs01\Cluster\VMs\XXX-PROD-WEB02\VHDs\XXX-prod-web02_sys.vhdx' received a recovery status notification. Current device state = Recoverable Error Detected, Last status = Disconnected, New status = No Errors.
4.)Storage device '\?\UNC\NAMEsofs01\Cluster\VMs\XXX-PROD-WEB02\VHDs\XXX-prod-web02_sys.vhdx' changed recovery state. Previous state = Recoverable Error Detected, New state = No Errors.
5.)Storage device '\?\UNC\NAMEsofs01\Cluster\VMs\XXX-PROD-WEB02\VHDs\XXX-prod-web02_sys.vhdx' received an IO failure with error = SRB_STATUS_ERROR_RECOVERY. Current device state = No Errors, New state = Recoverable Error Detected, Current status = No Errors.
6.)Storage device '\?\UNC\NAMEsofs01\Cluster\VMs\XXX-PROD-WEB02\VHDs\XXX-prod-web02_sys.vhdx' received a recovery status notification. Current device state = Recoverable Error Detected, Last status = No Errors, New status = Disconnected.
7.)Storage device '\?\UNC\NAMEsofs01\Cluster\VMs\XXX-PROD-WEB02\VHDs\XXX-prod-web02_sys.vhdx' changed recovery state. Previous state = Recoverable Error Detected, New state = Recoverable Error Detected.
8.)An I/O request for device '\?\UNC\NAMEsofs01\Cluster\VMs\XXX-PROD-WEB02\VHDs\XXX-prod-web02_sys.vhdx' took 1216203 miliseconds to complete. Operation code = READ16, Data transfer length = 512, Status = SRB_STATUS_ABORTED. ###HERE VM has quit unexpectedly
9.)Storage device '\?\UNC\NAMEsofs01\Cluster\VMs\XXX-PROD-WEB02\VHDs\XXX-prod-web02_sys.vhdx' received a recovery status notification. Current device state = Shutting Down, Last status = Disconnected, New status = No Errors.
This entry has timestamp when problem started 1:51:46. And there is no later logs of this kind but ClusterResurce was still in Loop like in first 4 pictures. And you cannot kill that loop.
Logo from Hyper-V worker:
1.)'name-prod-web02' was resumed from critical error. (Virtual machine ID 08BFD5A3-AF52-4F66-BD01-C635FED8F87A)
2.)'name-prod-web02' was paused for critical error. (Virtual machine ID 08BFD5A3-AF52-4F66-BD01-C635FED8F87A)
3.)'name-prod-web02' was resumed from critical error. (Virtual machine ID 08BFD5A3-AF52-4F66-BD01-C635FED8F87A)
and i circle 2000 logs in one second in time 1:51:46
Can you please give me some idea, directions, anything. Problem is random on windows and linux machines, and random nodes.
I will provide you with any additional info, I simply have nothing else to give from logs.
Pero
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EJT%3C/text%3E%3C/svg%3E)
I have the same problem - did anyone find a root cause of this yet please?
We're running a 16 node failover cluster with storage hosted on an SMB3 share with RDMA on a Windows 2019 server.
Most of our VMs use a differencing VHDX with the same parent VHDX, and when we need another batch of VMs I create 8 at a time.
When I create a batch and start them all, often one or two of the VMs will get stuck in a loop as described above, which is a nightmare to resolve without affecting the in-use VMs.
Occasionally this happens when bringing the cluster back up from maintenance on an established VM too, but mostly its the new ones, which after booting install updates etc so rapidly expand their VHDXs.
If I kill the VM process on the hosting HyperV server, then try to start it again, I usually get one of the two errors:
"Cluster resource 'Virtual Machine XXXX' of type 'Virtual Machine' in clustered role 'YYYY' failed. The error code was '0x26' ('Reached the end of the file.')."
or
"Cluster resource 'Virtual Machine XXXX' of type 'Virtual Machine' in clustered role 'YYYY' failed. The error code was '0xc03a0016' ('The chain of virtual hard disks is inaccessible. The process has not been granted access rights to the parent virtual hard disk for the differencing disk.')."
Permissions don't seem to be the problem though, I can grant the everyone group access to the VHDX file with no change in outcome.
Once the VM process is killed, the VM status viewed from the individual HyperV host is 'Off', however the failover cluster still shows it looping through starting, paused, etc. If you click on the VM in the Failover Cluster Manager it crashes mmc.
If I restart the VMMS service on that host I can usually get the VM running again, though that doesn't seem to fix the state of the VM in the cluster (which keeps looping). If I can get the other VMs migrated from the host (temperamental when the cluster is experiencing the rapid looping status issue on a VM) and restart it, all is reset and I can continue again.
Often when I resolve one of these looping VMs though, I find another one starts...
There are no storage issues as far as I can see - the established VMs are all happy and I can save/resume 10 or more at a time fairly rapidly.
All very odd, the above is the only mention of this issue I can find on the web.
Any further info from others experiences appreciated, this problem makes me nervous touching the cluster in working hours...
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EMW%3C/text%3E%3C/svg%3E)
Hi James, did you manage to find a solution to your problem?
Hi Maciej,
yes I think so - or at least I have prevented it happening now.
We were using differencing VHDs - we had one W10 image which we had setup how we wanted then sysprepped etc and then created 40 VMs each using a differencing VHDX referring to the same parent VHDX.
Whether the issue was directly due to the differencing VHDXs or whether it was because our HyperV servers are using SMB(3) to connect to their VHDs, and there was some max handle limit that we exceeded on the parent VHDX file I didn't discover.
What I've done now though is to convert all of them to be their own standalone VHDXs and there have been no more reoccurrences. For a while I only converted those on which the problem occurred, and once converted they were always fine, so I'm pretty confident of this fix.
I also read that using differencing VHDs is not recommended in a production environment, oh well.
HTH
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EE%3C/text%3E%3C/svg%3E)
Hi,
Have a same problem on Hyper-V Failover Cluster within 3 Windows Server 2019 Standard nodes. Actually i think that happens when virtual machine disk resize. After some time VM shows in LOOP state. Pero-7573 have you contact with MS with that issue? If You get some answer from MS please post information there. Thanks.
Hi Eimantas,
It could be. It happened again yesterday with our exchange VM. Hosts are srv19 and it was day after virtual disk resize. In the end we migrated healthy vms to another host and then we killed host. After that, cluster resource was down and vm just disappeared in hyper-v (not vhds they were ok).
But I never contacted MS with that issue.

Hi,
According to your description, please check the following things:
Thanks for your time!
Best Regards,
Anne
-----------------------------
If the Answer is helpful, please click "Accept Answer" and upvote it.
Note: Please follow the steps in our documentation to enable e-mail notifications if you want to receive the related email notification for this thread.
Thank you for response.
If you have any other ideas I will be thankful.
Hi,
Based on my experience, for such a random issue, usually due to the above reasons, if they are not your case, and if the issue reoccurs, I would suggest you open a case with MS for deep troubleshooting. Since it's hard to troubleshoot random issues on the forum due to some limitations, thanks for your understanding.
Below is the link to open a case with MS:
https://support.microsoft.com/en-us/gp/customer-service-phone-numbers
Best Regards,
Anne
Thank You,
I understand it is hard to troubleshoot. Just wanted to know if someone had similar issue.
Best regards,
Pero
Hi,
That's ok, we will leave this thread open, if others have any opinions can be put forward.
Best Regards,
Anne