SQL Server Integration Services
A Microsoft platform for building enterprise-level data integration and data transformations solutions.
2,454 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EBG%3C/text%3E%3C/svg%3E)
Maybe I am over thinking it. But we have several new files to load into SQL Tables. We have not decided on the exact way to load them into SQL. But in thinking about the SQL to retrieve the table data for the ETL process, how can you guarantee that the rows will be retrieve in file record order? Some of our ETL processes require that the file records are processed in exact order. Also some files have multiple headers and some have trailers. We would actually want to skip those for the ETL. There is nothing in the files to do an ORDER BY on.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EYK%3C/text%3E%3C/svg%3E)
How about SSIS?
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EEM%3C/text%3E%3C/svg%3E)
Hi @brenda grossnickle ,
Your question involves SSIS, I have added the corresponding tag for you.SSIS engineers will help you solve the problem.
Regards
Echo
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EJW%3C/text%3E%3C/svg%3E)
You can use SSIS to load the files - in the connection manager you would define the file as ragged-right with a single field for the entire record from the file. You then add a row number function to the constraint - which adds a row number for every row that is read from the pipeline. This row number becomes your record identifier and can then be used to select the data in row number order.
To parse the data - you can do that in SSIS or SQL. In SSIS you add a script component and define 3 separate outputs...a header output, detail and trailer outputs. In the script component you then evaluate each row and determine if that row is a header, detail or trailer record, parse the row according to the requirements (using substring if fixed length or comma separate processing) and populate each output field. In SQL Server - you will have separate tables for each type and you can use substring (for fixed length) or string_split for delimited to parse each field (and validate data type).
The key is in SSIS you add the row number function to the pipeline so that each record/row read from the file has a row number identifier.
https://richardswinbank.net/ssis/adding_row_numbers_to_ssis_dataflows
http://www.sqlis.com/post/row-number-transformation.aspx
https://www.timmitchell.net/post/2015/05/26/row-numbers-and-running-totals-in-ssis/
You can also combine the row number function into the script component that creates the separate outputs - so each output type would have different counters and row numbers, in case you have multiple header/trailer records.

Yithazk, I think there are simpler solutions than changing the file format. (Which I suspect beyond Brenda's powers to do anyway.)
Given that the trailer has deviating formats, I don't think the bulk-load tools in SQL Server are a good option, although you could read the file on a table with an IDENTITY column and a single nvarchar(MAX) column which you then parse in T-SQL. Which is not that func.
Since I don't know SSIS, I can't speak to that option, but one option is to write a C# program or Powershell script that reads the file and parses out the various fields and trailers and then sends them to SQL Server through a table-valued parameter, or the SqlBulkCopy class. Since you now have control of the whole thing, you can add a row number as you read the file.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EMM%3C/text%3E%3C/svg%3E)
Hi @brenda grossnickle ,
The Sort transformation sorts input data in ascending or descending order and copies the sorted data to the transformation output. You can apply multiple sorts to an input; each sort is identified by a numeral that determines the sort order.
We can use Sort Transformation in SSIS Data Flow Task to get data in certain order.
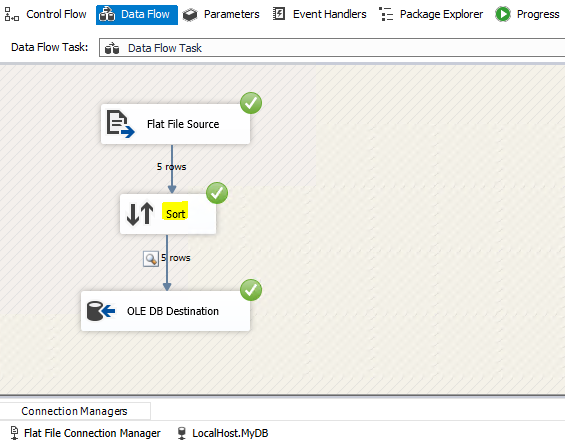
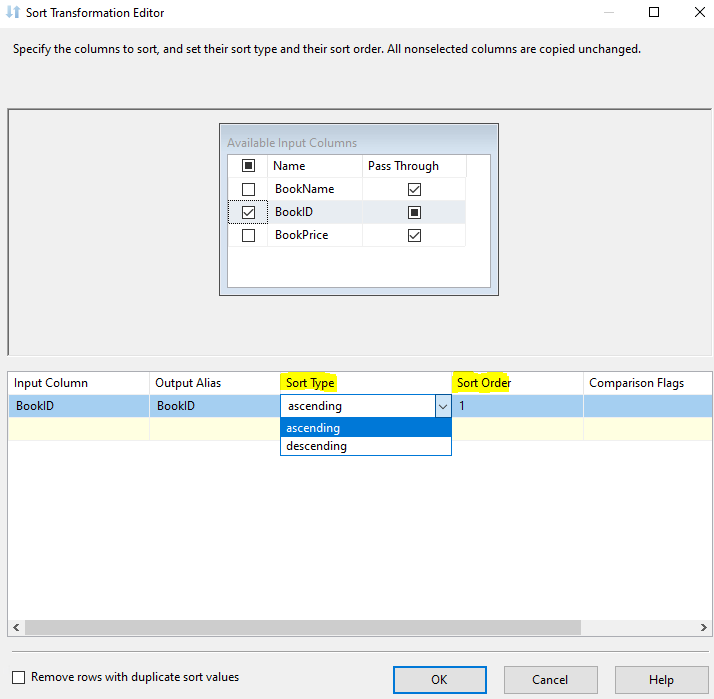
Best Regards,
Mona
----------
If the answer is helpful, please click "Accept Answer" and upvote it.
Note: Please follow the steps in our documentation to enable e-mail notifications if you want to receive the related email notification for this thread.
Hot issues in November--What can I do if my transaction log is full?
Hot issues in November--How to convert Profiler trace into a SQL Server table?
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ES%3C/text%3E%3C/svg%3E)
you are expert in explaining things. its easy for newbie to understand the ssis process. thanks much
When you work with data in a database, there has to be something in the data that defines the order, since tables themselves are unordered objects.
You talk about ETL, but you don't say how you load them. If you are using BULK INSERT, you can add an IDENTITY column, and I seem to recall that Microsoft at least some circumstances guarantees that IDENTITY values will reflect the order in the file. BULK INSERT also permits you to skip headers and trailers - but the headers and trailers must look like the rest of the file.
My trailer records are something like "TRAILERXYA 0000203043". So they are not formatted like the rest of the records. I am not sure exactly what method will be used to load the file data into the SQL tables. It might be a variety of methods. I just have to take the SQL table rows and ETL them into a master table. But it bothers me that I cannot read the rows in the same order that they were in the file. Along with wanting to skip possible multiple headers and footers, some of the files have transactional data that needs to be processed and the row order is extremely important. Like ADD ACCT 123 had better be before DELETE ACCT 123.
I have ingested plenty of files, but now i am on a new project and it has me wondering how can you SELECT the SQL rows to be in the same order as the file records? I suppose an identity column. But it does not sound like that is a guarantee.
Is it possible to switch your data feeds into XML format?
If the answer is YES, all your problems will be gone: headers, footers, predefined order, etc.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EG%3C/text%3E%3C/svg%3E)
You can load data from those files to the staging tables first and then you can select data in orders to achieve your tasks.