Azure Synapse Analytics
An Azure analytics service that brings together data integration, enterprise data warehousing, and big data analytics. Previously known as Azure SQL Data Warehouse.
4,621 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.

I would like to run spatial queries on large data sets; e.g. geopandas would be too slow. Inspiration I found here: https://anant-sharma.medium.com/apache-sedona-geospark-using-pyspark-e60485318fbe
But I have trouble registering the spatial functions I would like to use in SparkSQL (or PySpark).
In Spark Pool of Synapse Analytics I prepared (via Azure Portal):
Apache Spark Pool / Settings / Packages / Requirement files / requirement.txt: apache-sedona
Apache Spark Pool / Settings / Packages / Workspace packages:
geotools-wrapper-geotools-24.1.jar
sedona-sql-3.0_2.12-1.2.0-incubating.jar
Apache Spark Pool / Settings / Packages / Spark configuration / config.txt:
spark.serializer org.apache.spark.serializer.KryoSerializer
spark.kryo.registrator org.apache.sedona.core.serde.SedonaKryoRegistrator
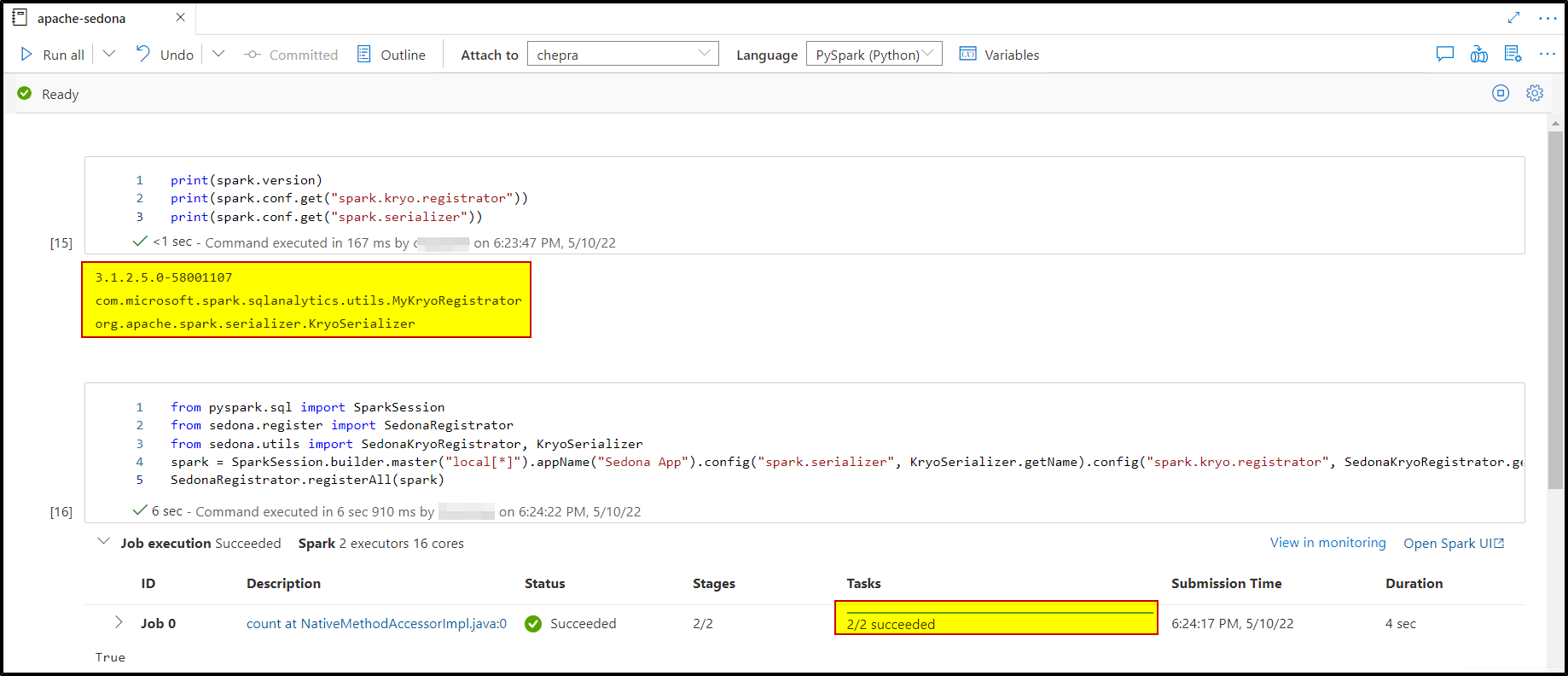
Pyspark Notebook:
print(spark.version)
print(spark.conf.get("spark.kryo.registrator"))
print(spark.conf.get("spark.serializer"))
Print output from notebook:
3.1.2.5.0-58001107
org.apache.sedona.core.serde.SedonaKryoRegistrator
org.apache.spark.serializer.KryoSerializer
Then trying:
from pyspark.sql import SparkSession
from sedona.register import SedonaRegistrator
from sedona.utils import SedonaKryoRegistrator, KryoSerializer
spark = SparkSession.builder.master("local[*]").appName("Sedona App").config("spark.serializer", KryoSerializer.getName).config("spark.kryo.registrator", SedonaKryoRegistrator.getName).getOrCreate()
SedonaRegistrator.registerAll(spark)
But it failed: Py4JJavaError: An error occurred while calling o636.count. : org.apache.spark.SparkException: Job aborted due to stage failure: Task serialization failed: org.apache.spark.SparkException: Failed to register classes with Kryo
A simple check that stuff is correctly installed would probaly allow this:
%%sql
SELECT ST_Point(0,0);
Please help with getting the spatial functions registered in pyspark running in Synapse notebook!

Hello @BjornD Jensen ,
Thanks for the question and using MS Q&A platform.
As per the repro from my end, I'm able to successfully run the above commands without any issue.
I just installed the requirement[dot]txt file and downloaded below two jar files:
Note: config[dot]txt file is not required.
If you are still facing the same error message, I would request you to share the complete stack trace of the error message which you are experiencing.
Hope this will help. Please let us know if any further queries.
------------------------------
 or upvote
or upvote  button whenever the information provided helps you. Original posters help the community find answers faster by identifying the correct answer. Here is how
button whenever the information provided helps you. Original posters help the community find answers faster by identifying the correct answer. Here is how
Turns out I used the wrong jar... :-0
I can continue now. Thanks for helping!
But let me know if you have an hint about how to get the total list of available spatial functions in the particular spark session.
Here a refined version that seems to work (-:
Uploading workspace packages (2 jar’s) in Synapse Studio / Manage / Configuration+libraries/Workspace packages:
geotools-wrapper-geotools-24.1.jar (downloaded from https://mvnrepository.com/artifact/org.datasyslab/geotools-wrapper/geotools-24.1 )
sedona-python-adapter-3.0_2.12-1.0.0-incubating.jar (downloaded from https://search.maven.org/artifact/org.apache.sedona/sedona-python-adapter-3.0_2.12/1.0.0-incubating/jar )
Then in
Apache Spark Pool / Settings / Packages / Workspace packages : selecting the above workspace packages
Uploading txt file:
Apache Spark Pool / Settings / Packages / Requirement files / requirements.txt : apache-sedona
Further uploading config.txt:
Apache Spark Pool / Settings / Packages / Spark configuration / config.txt:
spark.serializer org.apache.spark.serializer.KryoSerializer
spark.kryo.registrator org.apache.sedona.core.serde.SedonaKryoRegistrator
The above configuration stuff allows me write fewer lines:
from sedona.register import SedonaRegistrator
from sedona.utils import SedonaKryoRegistrator, KryoSerializer
SedonaRegistrator.registerAll(spark)
print(spark.version)
print(spark.conf.get("spark.kryo.registrator"))
print(spark.conf.get("spark.serializer"))
And now the fun starts:
%%sql
SELECT st_point(0.0,0.0);
Hello @BjornD Jensen ,
Glad to know that your issue has been resolved. And thanks for sharing the solution, which might be beneficial to other community members reading this thread.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EAM%3C/text%3E%3C/svg%3E)
Hi Experts,
Please could you suggest the step by step approach for setting it up in Microsoft Fabric environment?
Regards
Adil