Azure Data Lake Storage
An Azure service that provides an enterprise-wide hyper-scale repository for big data analytic workloads and is integrated with Azure Blob Storage.
1,355 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EKS%3C/text%3E%3C/svg%3E)
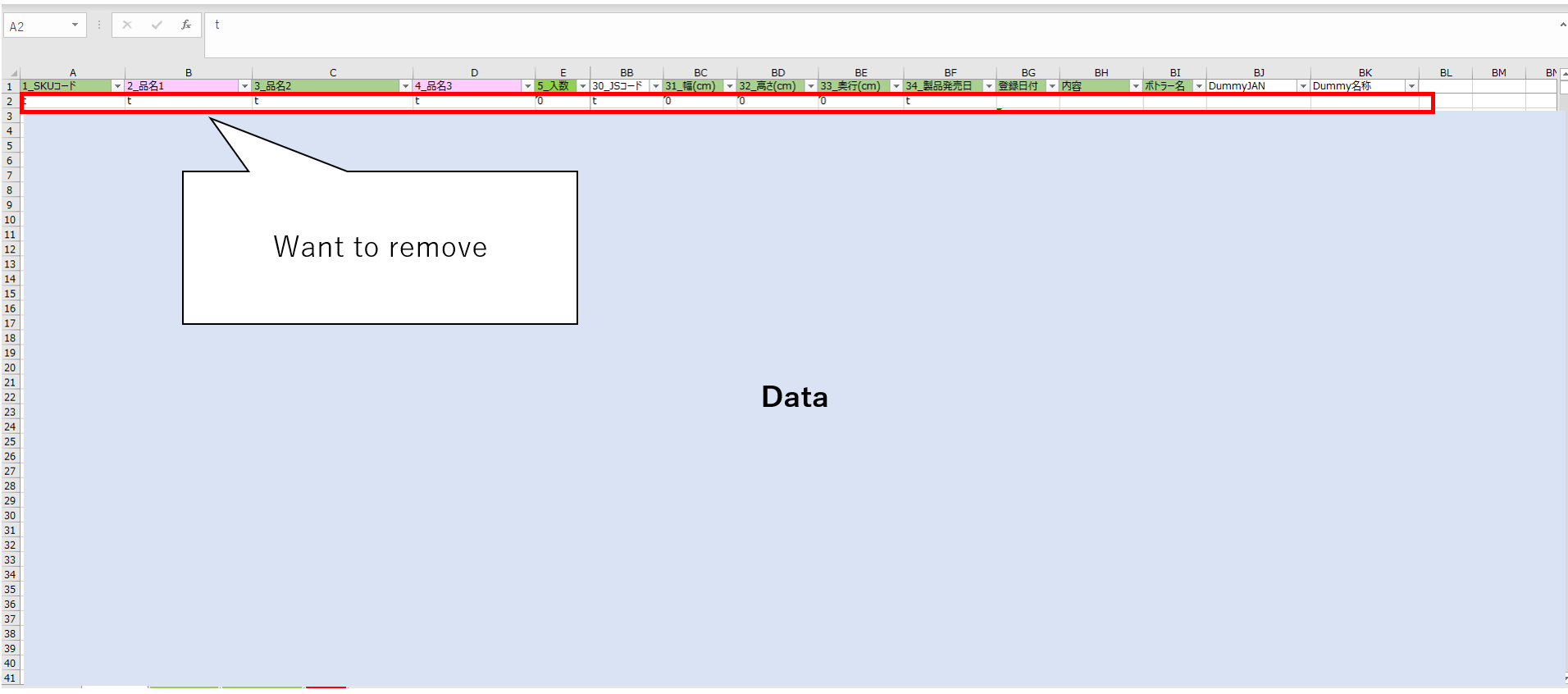
Hi, I wanna remove the row in Excel file in Azure Synapse Analytics.
As shown in the attached image, the source Excel file has an unnecessary second row.
I tried to remove it in ADF, but I don't know what condition to set in the component "Alter Row".
Do you know any solution?
Any help would be appreciated.

Hi @Kakehi Shunya (筧 隼弥) ,
Thankyou for sharing more details on your requirement. Additionally , you can try following approach to achive the requirement:
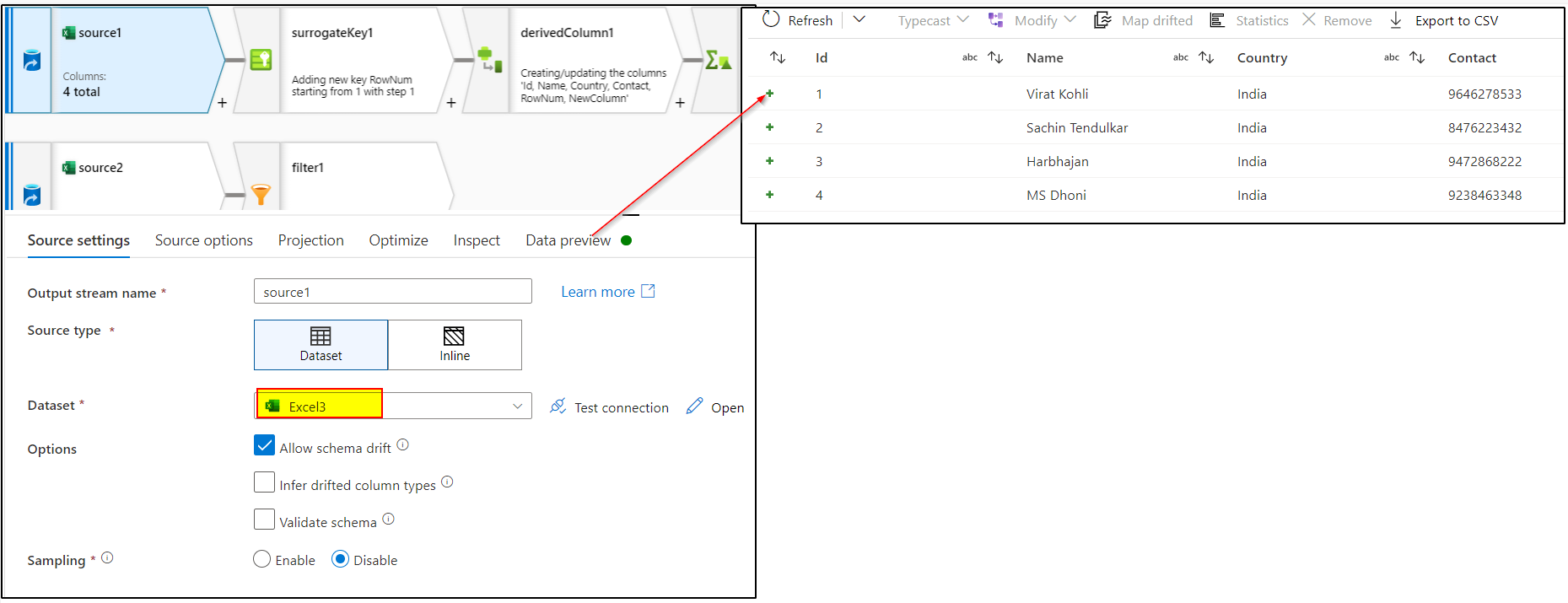
1. Create the dataset pointing to your excel, make sure to import the schema and check first row as header.
2. In the source transformation of the dataflow, select the above dataset and preview the data.
3. Use surrogate key transformation to generate column say RowNum which would add an incrementing key value to each row of data.
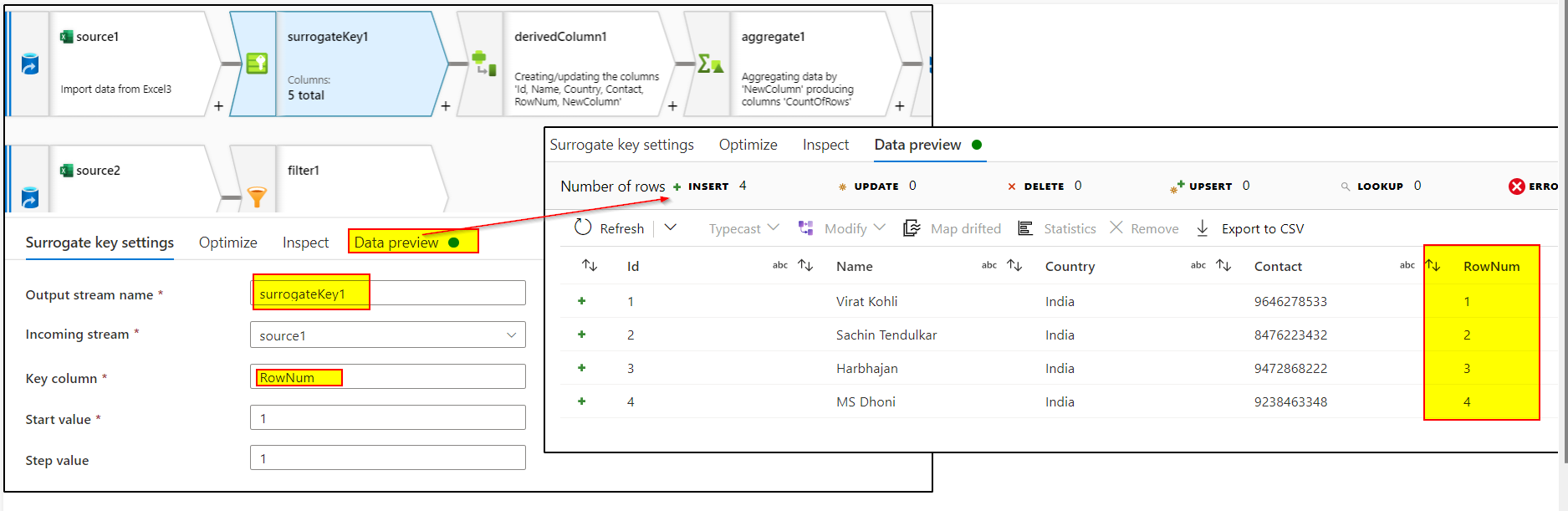
4. Use aggregate transformation to find out the maximum RowNum by using the expression : max(RowNum) in aggregate tab. As group by tab is optional, you can skip that.
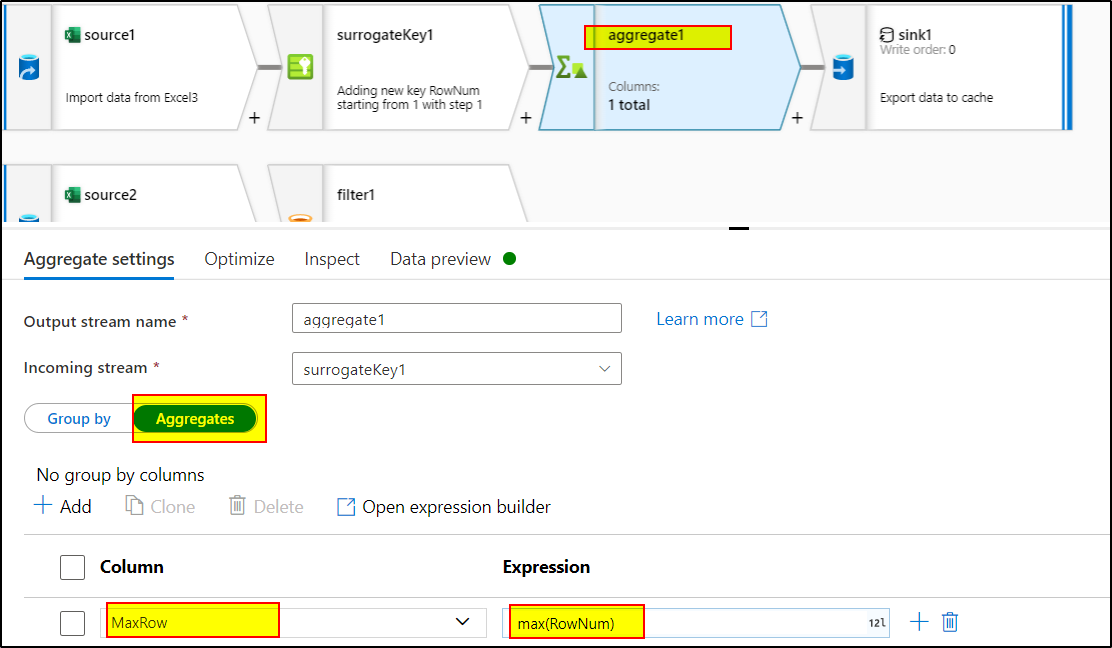
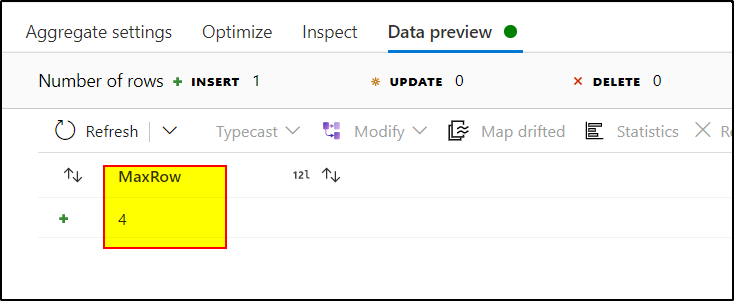
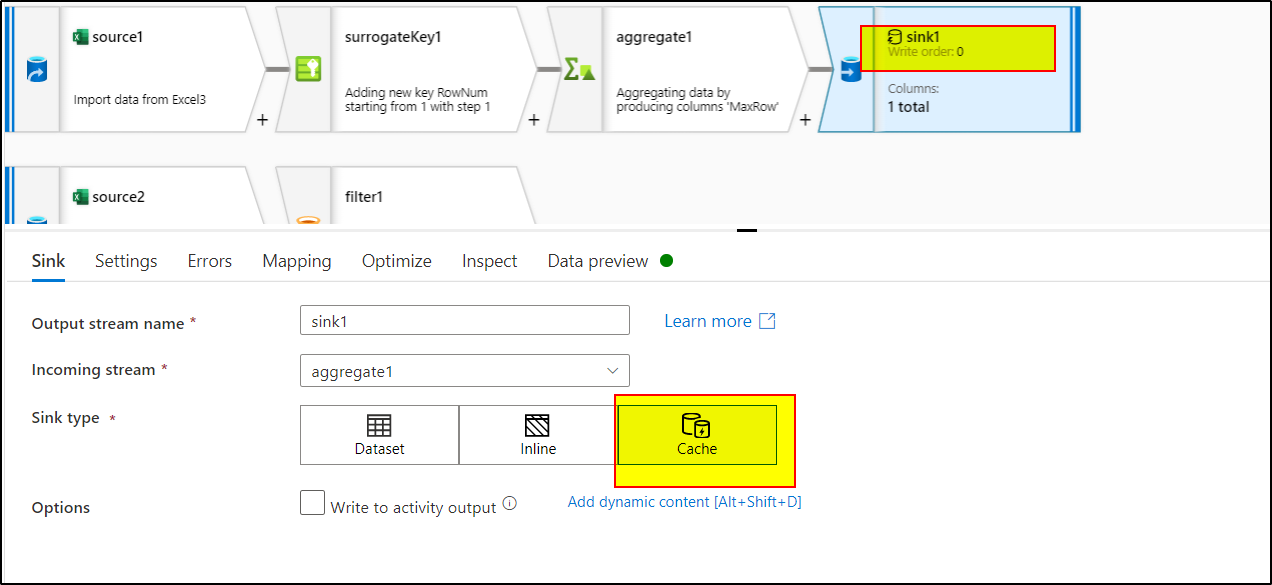
5. Use Sink transformation and select cache as the sink type to write the data into spark cache that can be referenced in other transformations.
6. Add another source transformation and refer to the same source dataset.
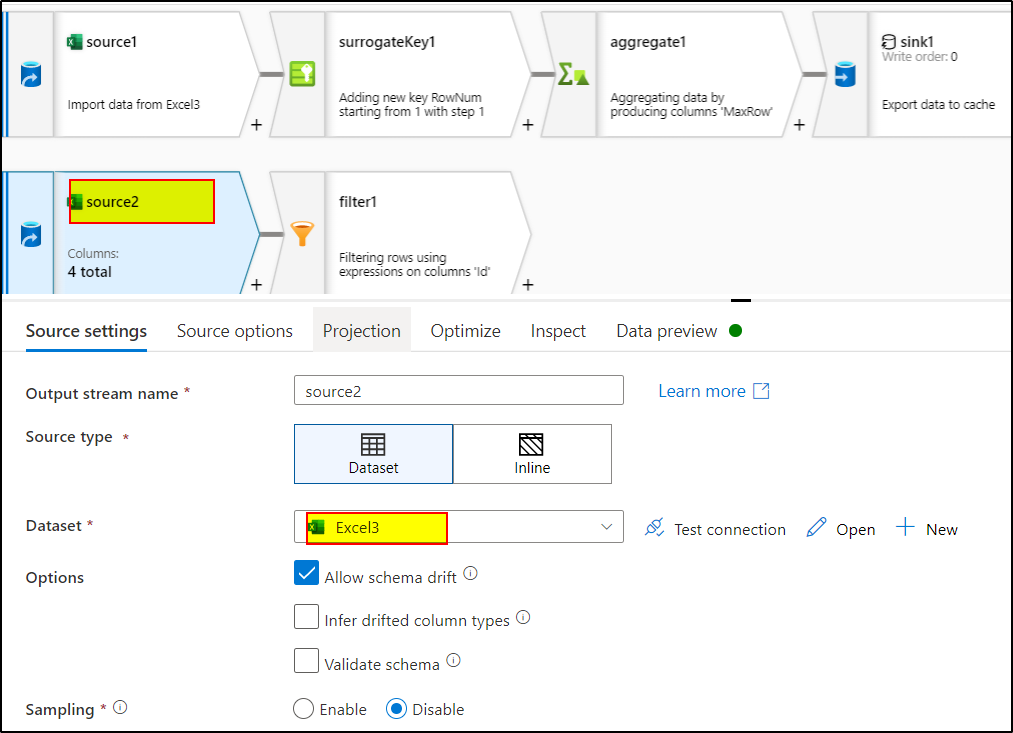
7. Use Surrogate key again to generate the RowNum again as done in step 3
8. Use Filter transformation and use this expression : toInteger(RowNum) < toInteger(sink1#outputs()[1].MaxRow) - 1
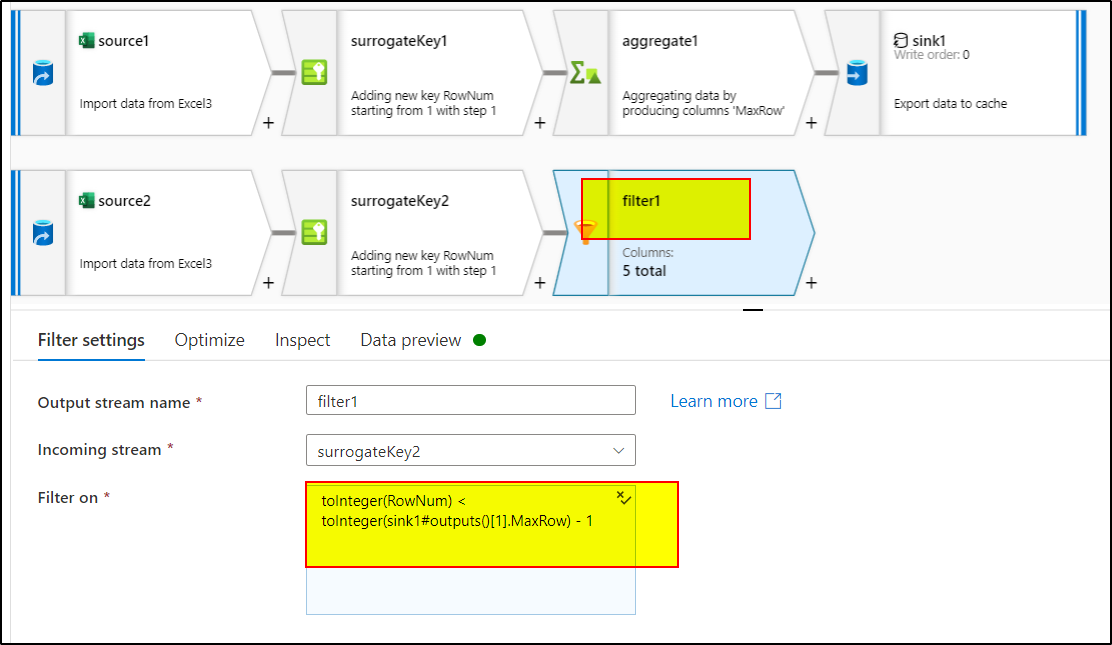
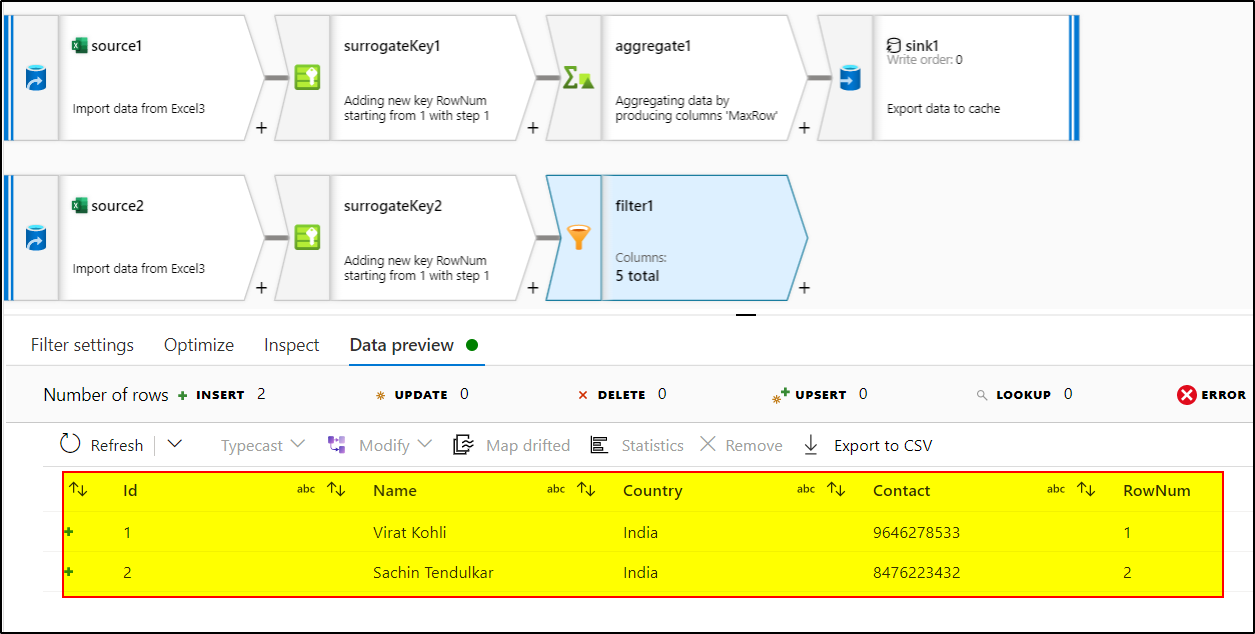
9. Use sink transformation to load this data to the target database.
You can use the similar approach to filter out the first row as well by getting the min(RowNum) and using expression in the filter transformation : toInteger(RowNum) > toInteger(sink1#outputs()[1].MinRow)
Hope this will help. Please let us know if any further queries.
------------------------------
 or upvote
or upvote  button whenever the information provided helps you.
button whenever the information provided helps you.
Hi @Kakehi Shunya (筧 隼弥) ,
Just checking in to see if the above answer helped. Please do consider clicking Accept Answer and Up-Vote for the same as accepted answers help community as well. If you have any further query do let us know.
Hi, @AnnuKumari-MSFT
I tried it and it worked well.
Thank you so much!!
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ESB%3C/text%3E%3C/svg%3E)
If you want to filter out such rows which don't bring any useful data, you can use filter transformation in data flow.
You can mention expression like below,
length (column1)>1
This will filter out those rows which bring one character in the column1.
Try this out and let us know
Thanks
Reference video : I7P66soo7Xo
Hi @Kakehi Shunya (筧 隼弥) ,
Thankyou for using Microsoft Q&A platform and thanks for posting your question here.
As I understand your ask , you want to skip first row of the excel while processing it via Azure data factory. Please let me know if my understanding is incorrect .
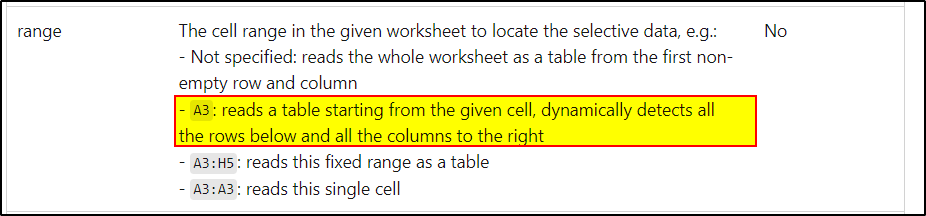
While creating the dataset, you can use the range in the excel dataset which will allow you to read the excel starting from a particular cell . You can provide the range value as A3 in the dataset.
For more details, kindly check this article: Dataset properties in excel
Hope this will help. Please let us know if any further queries.
------------------------------
or upvote button whenever the information provided helps you.
@AnnuKumari-MSFT
Thanks for your answer.
I also read this.
If I set it up as A3 to skip the first row, what happens to the header?
(First line as header is checked.)
Also, in a different file than this, I need to remove 2 lines from the end, which is a different number of lines each time, so I am looking for a smart way to do this.