إشعار
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تسجيل الدخول أو تغيير الدلائل.
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تغيير الدلائل.
في هذا التشغيل السريع، تتعلم كيفية إنشاء تجمع Apache Spark بلا خادم في Azure Synapse باستخدام أدوات الويب. تتعلم بعد ذلك الاتصال بتجمع Apache Spark وتشغيل استعلامات Spark SQL مقابل الملفات والجداول. يتيح Apache Spark تحليلات البيانات السريعة والحوسبة العنقودية باستخدام المعالجة في الذاكرة. للحصول على معلومات حول Spark في Azure Synapse، راجع نظرة عامة: Apache Spark على Azure Synapse.
هام
يتم تقسيم فوترة مثيلات Spark بالتناسب في الدقيقة ، سواء كنت تستخدمها أم لا. تأكد من إيقاف تشغيل مثيل Spark الخاص بك بعد الانتهاء من استخدامه، أو تعيين مهلة قصيرة. لمزيد من المعلومات، راجع قسم تنظيف الموارد في هذه المقالة.
إذا لم يكن لديك اشتراك Azure، فقم بإنشاء حساب مجاني قبل البدء.
المتطلبات الأساسية
- ستحتاج إلى اشتراك Azure. إذا لزم الأمر، قم بإنشاء حساب Azure مجاني
- مساحة عمل Synapse Analytics
- تجمع Apache Spark بدون خادم
سجِّل الدخول إلى مدخل Azure
قم بتسجيل الدخول إلى بوابة Azure.
إذا لم يكن لديك اشتراك Azure، فقم بإنشاء حساب Azure مجاني قبل البدء.
إنشاء دفتر ملاحظات
دفتر الملاحظات هو بيئة تفاعلية تدعم لغات البرمجة المختلفة. يتيح لك دفتر الملاحظات التفاعل مع بياناتك ، ودمج التعليمات البرمجية مع markdown ، والنص ، وإجراء تصورات بسيطة.
من طريقة عرض مدخل Microsoft Azure لمساحة عمل Azure Synapse التي تريد استخدامها، حدد تشغيل Synapse Studio.
بمجرد تشغيل Synapse Studio، حدد تطوير. ثم حدد أيقونة "+" لإضافة مورد جديد.
من هناك، حدد دفتر الملاحظات. يتم إنشاء دفتر ملاحظات جديد وفتحه باسم يتم إنشاؤه تلقائيا.

في نافذة الخصائص ، قم بتوفير اسم لدفتر الملاحظات.
في شريط الأدوات، انقر فوق نشر.
إذا كان هناك تجمع Apache Spark واحد فقط في مساحة العمل الخاصة بك، تحديده افتراضيا. استخدم القائمة المنسدلة لتحديد تجمع Apache Spark الصحيح إذا لم يتم تحديد أي منها.
انقر على إضافة رمز. اللغة الافتراضية هي
Pyspark. ستستخدم مزيجا من Pyspark و Spark SQL ، لذا فإن الخيار الافتراضي جيد. اللغات الأخرى المدعومة هي Scala و.NET for Spark.بعد ذلك ، يمكنك إنشاء كائن Spark DataFrame بسيط لمعالجته. في هذه الحالة ، يمكنك إنشاؤه من التعليمات البرمجية. هناك ثلاثة صفوف وثلاثة أعمدة:
new_rows = [('CA',22, 45000),("WA",35,65000) ,("WA",50,85000)] demo_df = spark.createDataFrame(new_rows, ['state', 'age', 'salary']) demo_df.show()الآن قم بتشغيل الخلية باستخدام إحدى الطرق التالية:
اضغط على SHIFT + ENTER.
حدد رمز التشغيل الأزرق على يسار الخلية.
حدد الزر تشغيل الكل على شريط الأدوات.
إذا لم يكن مثيل تجمع Apache Spark قيد التشغيل بالفعل، بدء تشغيله تلقائيا. يمكنك رؤية حالة مثيل تجمع Apache Spark أسفل الخلية التي تقوم بتشغيلها وأيضا على لوحة الحالة في الجزء السفلي من دفتر الملاحظات. اعتمادا على حجم المسبح ، يجب أن يستغرق البدء من 2 إلى 5 دقائق. بمجرد انتهاء تشغيل التعليمات البرمجية، تعرض المعلومات الموجودة أسفل الخلية التي توضح المدة التي استغرقها التشغيل وتنفيذها. في خلية الإخراج ، سترى الإخراج.
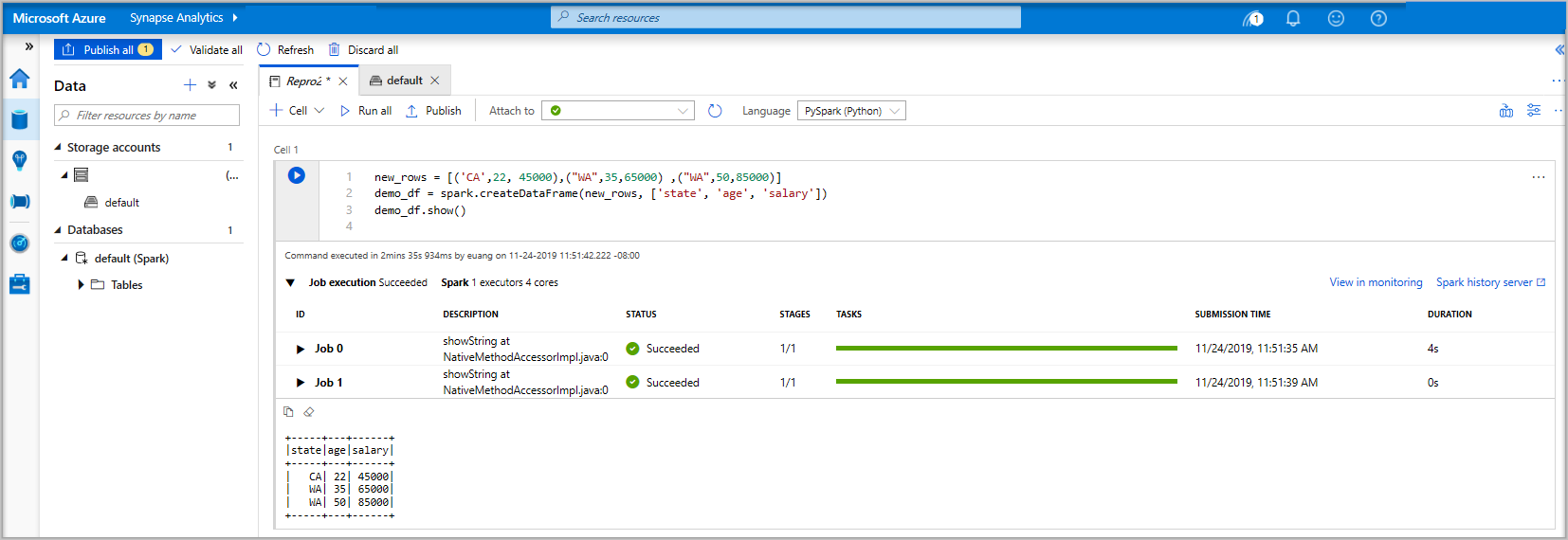
البيانات موجودة الآن في DataFrame من هناك يمكنك استخدام البيانات بعدة طرق مختلفة. ستحتاج إليه بتنسيقات مختلفة لبقية هذا التشغيل السريع.
أدخل التعليمات البرمجية أدناه في خلية أخرى وقم بتشغيلها ، وهذا ينشئ جدول Spark و CSV وملف Parquet مع نسخ من البيانات:
demo_df.createOrReplaceTempView('demo_df') demo_df.write.csv('demo_df', mode='overwrite') demo_df.write.parquet('abfss://<<TheNameOfAStorageAccountFileSystem>>@<<TheNameOfAStorageAccount>>.dfs.core.windows.net/demodata/demo_df', mode='overwrite')إذا كنت تستخدم مستكشف التخزين، فمن الممكن رؤية تأثير الطريقتين المختلفتين لكتابة ملف مستخدم أعلاه. عندما لا يتم تحديد نظام ملفات ، يتم استخدام الافتراضي ، في هذه الحالة
default>user>trusted-service-user>demo_df. يتم حفظ البيانات في موقع نظام الملفات المحدد.لاحظ في كل من تنسيقات "csv" و "parquet" ، عمليات الكتابة يتم إنشاء دليل مع العديد من الملفات المقسمة.


تشغيل عبارات Spark SQL
لغة الاستعلام المنظمة (SQL) هي اللغة الأكثر شيوعا والأكثر استخداما للاستعلام عن البيانات وتعريفها. يعمل Spark SQL كملحق ل Apache Spark لمعالجة البيانات المنظمة، باستخدام بناء جملة SQL المألوف.
الصق التعليمات البرمجية التالية في خلية فارغة، ثم قم بتشغيل التعليمات البرمجية. يسرد الأمر الجداول الموجودة في مخزن السكون.
%%sql SHOW TABLESعند استخدام دفتر ملاحظات مع تجمع Azure Synapse Apache Spark، تحصل على إعداد
sqlContextمسبق يمكنك استخدامه لتشغيل الاستعلامات باستخدام Spark SQL.%%sqlيخبر دفتر الملاحظات باستخدام الإعدادsqlContextالمسبق لتشغيل الاستعلام. يسترد الاستعلام أعلى 10 صفوف من جدول نظام يأتي مع جميع تجمعات Azure Synapse Apache Spark بشكل افتراضي.قم بتشغيل استعلام آخر لرؤية البيانات في
demo_df.%%sql SELECT * FROM demo_dfتنتج التعليمات البرمجية خليتين إخراجيتين، إحداهما تحتوي على نتائج بيانات والأخرى تعرض طريقة عرض الوظيفة.
بشكل افتراضي، تعرض طريقة عرض النتائج شبكة. ولكن ، يوجد محول عرض أسفل الشبكة يسمح للعرض بالتبديل بين طرق عرض الشبكة والرسم البياني.

في مبدل العرض ، حدد مخطط .
حدد رمز خيارات العرض من أقصى الجانب الأيمن.
في حقل نوع الرسم البياني ، حدد "مخطط شريطي".
في حقل عمود المحور X، حدد "الحالة".
في حقل عمود المحور الصادي، حدد "الراتب".
في حقل التجميع ، حدد إلى "AVG".
حدد تطبيق.

من الممكن الحصول على نفس تجربة تشغيل SQL ولكن دون الحاجة إلى تبديل اللغات. يمكنك القيام بذلك عن طريق استبدال خلية SQL أعلاه بخلية PySpark هذه ، وتكون تجربة الإخراج هي نفسها لأنه يتم استخدام أمر العرض :
display(spark.sql('SELECT * FROM demo_df'))كان لكل خلية من الخلايا التي تم تنفيذها مسبقا خيار الانتقال إلى خادم المحفوظاتوالمراقبة. يؤدي النقر فوق الروابط إلى نقلك إلى أجزاء مختلفة من تجربة المستخدم.
إشعار
تعتمد بعض وثائق Apache Spark الرسمية على استخدام وحدة تحكم Spark ، والتي لا تتوفر على Synapse Spark. استخدم دفتر الملاحظات أو تجارب IntelliJ بدلا من ذلك.
تنظيف الموارد
يحفظ Azure Synapse بياناتك في Azure Data Lake Storage. يمكنك السماح بإيقاف تشغيل مثيل Spark بأمان عندما لا يكون قيد الاستخدام. يتم تحصيل رسوم منك مقابل تجمع Apache Spark بدون خادم طالما أنه قيد التشغيل ، حتى عندما لا يكون قيد الاستخدام.
نظرا لأن رسوم المجمع تزيد بعدة مرات عن رسوم التخزين ، فمن المنطقي اقتصاديا السماح بإغلاق مثيلات Spark عندما لا تكون قيد الاستخدام.
لضمان إيقاف تشغيل مثيل Spark، قم بإنهاء أي جلسات (دفاتر ملاحظات) متصلة. يتم إيقاف تشغيل المسبح عند الوصول إلى وقت الخمول المحدد في تجمع Apache Spark. يمكنك أيضا تحديد إنهاء الجلسة من شريط الحالة أسفل دفتر الملاحظات.
الخطوات التالية
في هذا التشغيل السريع، تعلمت كيفية إنشاء تجمع Apache Spark بلا خادم وتشغيل استعلام Spark SQL أساسي.