إضافة مجموعة بيانات تدريب صوتي احترافي
عندما تكون مستعدا لإنشاء نص مخصص لصوت الكلام للتطبيق الخاص بك، فإن الخطوة الأولى هي جمع التسجيلات الصوتية والبرامج النصية المقترنة لبدء تدريب النموذج الصوتي. للحصول على تفاصيل حول تسجيل عينات صوتية، راجع البرنامج التعليمي. خدمة Speech تستخدم هذه البيانات لإنشاء صوت فريد تم ضبطه لمطابقة الصوت في التسجيلات. بعد تدريب الصوت، يمكنك البدء في تركيب الكلام في تطبيقاتك.
يجب أن تستوفي جميع البيانات التي تحمّلها متطلبات نوع البيانات الذي تختاره. من المهم تنسيق بياناتك بشكل صحيح قبل تحميلها، مما يضمن معالجة البيانات بدقة بواسطة خدمة الكلام. للتأكد من تنسيق بياناتك بشكل صحيح، راجع أنواع بيانات التدريب.
إشعار
- يمكن لمستخدمي الاشتراك القياسي (S0) تحميل خمسة ملفات بيانات في وقت واحد. إذا وصلت إلى الحد الأقصى، فانتظر حتى ينتهي استيراد واحد على الأقل من ملفات البيانات الخاصة بك. ثم حاول مرة أخرى.
- الحد الأقصى لعدد ملفات البيانات المسموح باستيرادها لكل اشتراك هو 500 ملف .zip لمستخدمي الاشتراك القياسي (S0). لمزيد من التفاصيل، يُرجى الاطّلاع على الحصص النسبية وحدود خدمة الكلام.
تحميل بياناتك
عندما تكون مستعدًا لتحميل البيانات، انتقل إلى علامة التبويب إعداد بيانات التدريب لإضافة مجموعة التدريب الأولى وتحميل البيانات. مجموعة التدريب عبارة عن مجموعة من الكلمات المنطوقة ونصوص المخطط المستخدمة لتدريب نموذج صوتي. يمكنك استخدام مجموعة تدريب لتنظيم بيانات تدريبك. تتحقق الخدمة من جاهزية البيانات لكل مجموعة تدريب. يمكنك استيراد بيانات متعددة إلى مجموعة تدريب.
لتحميل بيانات التدريب، اتبع الخطوات التالية:
- سجّل الدخول إلـى Speech Studio.
- حدد صوت> مخصص اسم >المشروع إعداد بيانات>التدريب تحميل البيانات.
- في معالج تحميل البيانات ، اختر نوع بيانات ثم حدد التالي.
- حدد الملفات المحلية من الكمبيوتر أو أدخل عنوان URL لتخزين Azure Blob لتحميل البيانات.
- ضمن تحديد مجموعة التدريب الهدف، حدد مجموعة تدريب موجودة أو أنشئ مجموعة جديدة. إذا قمت بإنشاء مجموعة تدريب جديدة، فتأكد من تحديدها في القائمة المنسدلة قبل المتابعة.
- حدد التالي.
- أدخل اسما ووصفا لبياناتك ثم حدد التالي.
- راجع تفاصيل التحميل، وحدد إرسال.
إشعار
لا يتم قبول المعرفين المكررين. ستتم إزالة الألفاظ التي لها نفس المعرف.
تتم إزالة الأسماء الصوتية المكررة من التدريب. تأكد من أن البيانات التي تحددها لا تحتوي على نفس أسماء الصوت داخل ملف .zip أو عبر ملفات .zip متعددة. إذا كانت معرفات التعبير (سواء في ملفات الصوت أو ملفات البرامج النصية) مكررة، فسيتم رفضها.
يتم التحقق من صحة ملفات البيانات تلقائيًا عند تحديد Submit. يتضمن التحقق من صحة البيانات سلسلة من عمليات التحقق من الملفات الصوتية للتحقق من تنسيق الملف وحجمه ومعدل أخذ العينات. في حالة وجود أي أخطاء، أصلحها وأرسلها مرة أخرى.
بعد تحميل البيانات، يمكنك التحقق من التفاصيل في عرض تفاصيل مجموعة التدريب. في صفحة التفاصيل، يمكنك التحقق من مشكلة النطق ومستوى الضوضاء لكل من بياناتك. تتراوح درجة النطق على مستوى الجملة من 0 إلى 100. تشير الدرجة الأقل من 70 عادةً إلى وجود خطأ في الكلام أو عدم تطابق في النص. سيتم رفض التعبيرات ذات الدرجة الإجمالية الأقل من 70. يمكن أن تقلل اللهجة الثقيلة من درجة نطقك وتؤثر على الصوت الرقمي الذي تم إنشاؤه.
حل مشكلات البيانات عبر الإنترنت
بعد التحميل، يمكنك التحقق من تفاصيل بيانات مجموعة التدريب. قبل الاستمرار في تدريب نموذجك الصوتي، يجب أن تحاول حل أي مشكلات في البيانات.
يمكنك تحديد وحل مشكلات البيانات لكل تعبير في Speech Studio.
في صفحة التفاصيل، انتقل إلى صفحة البيانات المقبولة أو البيانات المرفوضة. حدد التعبيرات الفردية التي تريد تغييرها، ثم حدد تحرير.
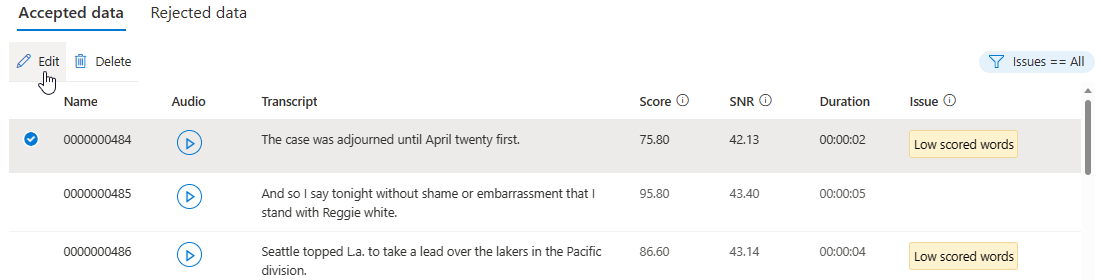
يمكنك اختيار مشكلات البيانات التي سيتم عرضها استنادا إلى معاييرك.
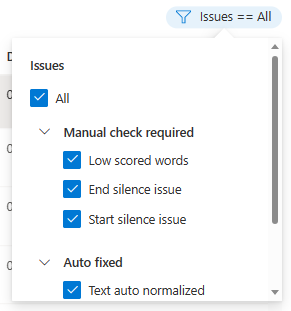
سيتم عرض نافذة التحرير.
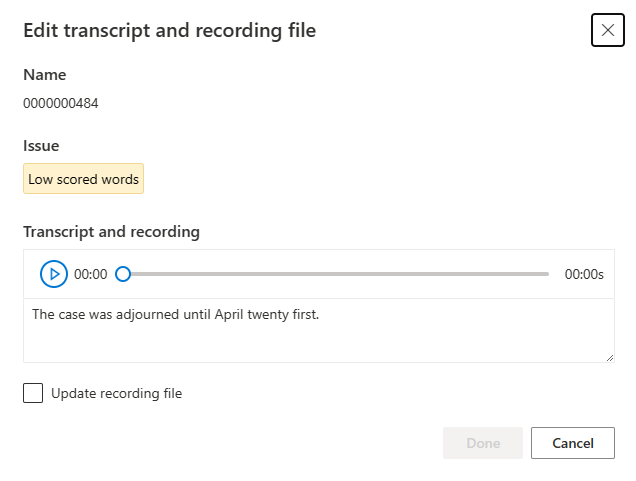
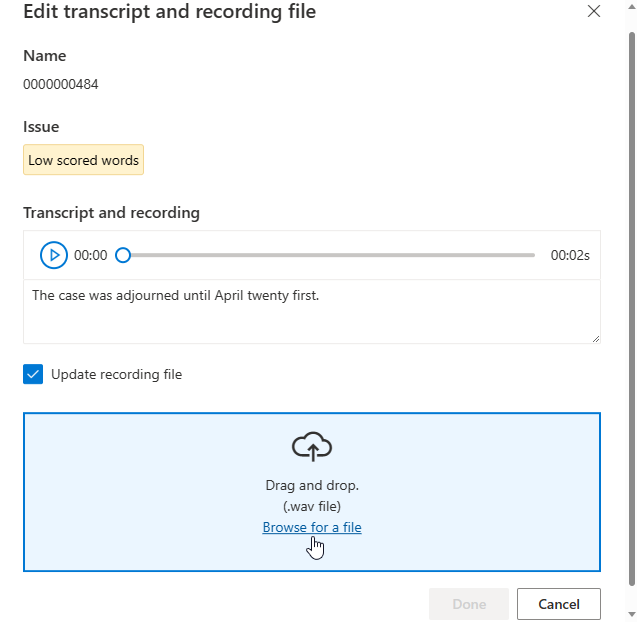
تحديث النص المنطوق أو ملف التسجيل وفقًا لوصف المشكلة في نافذة التعديل.
يمكنك تحرير النسخة المكتوبة في مربع النص، ثم تحديد تم
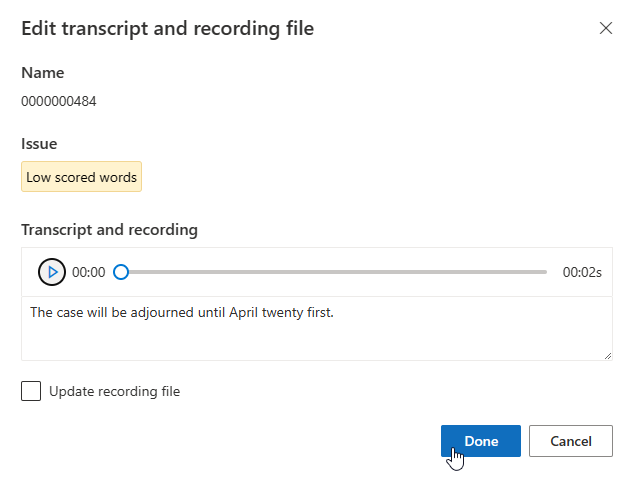
إذا كنت تريد تحديث ملف التسجيل، فحدد Update recording file، ثم قم بتحميل ملف التسجيل الثابت (.wav).
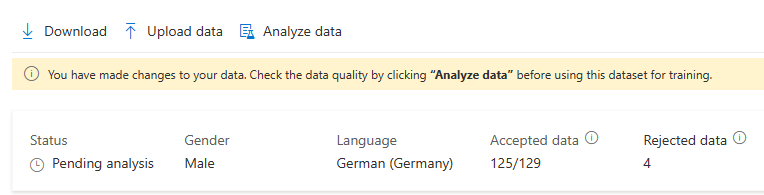
بعد إجراء تغييرات على بياناتك، تحتاج إلى التحقق من جودة البيانات بالنقر فوق تحليل البيانات قبل استخدام مجموعة البيانات هذه للتدريب.
لا يمكنك تحديد مجموعة التدريب هذه لنموذج التدريب قبل اكتمال التحليل.
يمكنك أيضًا حذف الكلمات المنطوقة التي بها مشاكل بتحديدها والنقر فوق Delete.
مشاكل البيانات النموذجية
وتنقسم المشاكل إلى ثلاثة أنواع. راجع الجداول التالية للتحقق من أنواع الأخطاء ذات الصلة.
مرفوض تلقائيًا
لن يتم استخدام البيانات التي تحتوي على هذه الأخطاء للتدريب. سيتم تجاهل البيانات المستوردة التي تحتوي على أخطاء، لذا لن تحتاج إلى حذفها. يمكنك إصلاح أخطاء البيانات هذه عبر الإنترنت أو تحميل البيانات المصححة مرة أخرى للتدريب.
| Category | الاسم | الوصف |
|---|---|---|
| البرنامج النصي | فاصل غير صالح | يجب عليك فصل معرف الكلمات المنطوقة ومحتوى البرنامج النصي بحرف الجدولة. |
| البرنامج النصي | معرف البرنامج النصي غير صالح | يجب أن يكون معرف خط البرنامج النصي رقميًا. |
| البرنامج النصي | البرنامج النصي المكرر | يجب أن يكون كل خط من محتوى البرنامج النصي فريدًا. يتم تكرار الخط باستخدام {}. |
| البرنامج النصي | البرنامج النصي طويل جدًا | يجب أن يكون البرنامج النصي أقل من 1000 حرف. |
| البرنامج النصي | لا يوجد صوت مطابق | يجب أن يتطابق معرّف كل تعبير (كل خط من ملف البرنامج النصي) مع معرّف الصوت. |
| البرنامج النصي | لا يوجد برنامج نصي صالح | لم يتم العثور على برنامج نصي صالح في مجموعة البيانات هذه. إصلاح خطوط البرنامج النصي التي تظهر في قائمة المشاكل التفصيلية. |
| الصوت | لا يوجد برنامج نصي مطابق | لا توجد ملفات صوتية تطابق معرّف البرنامج النصي. يجب أن يتطابق اسم ملفات .wav مع المعرفات الموجودة في ملف البرنامج النصي. |
| الصوت | تنسيق الصوت غير صالح | تنسيق الصوت لملفات .wav غير صالح. تحقق من تنسيق ملف .wav باستخدام أداة صوت مثل SoX. |
| الصوت | انخفاض معدل أخذ العينات | لا يمكن أن يكون معدل أخذ العينات لملفات .wav أقل من 16 كيلو هرتز. |
| الصوت | صوت طويل جدًا | مدة الصوت أطول من 30 ثانية. قسّم الصوت الطويل إلى عدة ملفات. إنها لفكرة جيدة أن تجعل الكلمات المنطوقة أقصر من 15 ثانية. |
| الصوت | لا يوجد صوت صالح | لم يتم العثور على صوت صالح في مجموعة البيانات هذه. تحقق من بياناتك الصوتية وقم بالتحميل مرة أخرى. |
| عدم تطابق | كلام منطوق منخفض الدرجات | درجة النطق على مستوى الجملة أقل من 70. راجع البرنامج النصي والمحتوى الصوتي للتأكد من تطابقهما. |
إصلاح تلقائي
يتم إصلاح الأخطاء التالية تلقائيًا، ولكن يجب عليك مراجعة التصحيحات وتأكيدها بشكل صحيح.
| Category | الاسم | الوصف |
|---|---|---|
| عدم تطابق | إصلاح الصمت التلقائي | تم اكتشاف أن صمت البداية أقصر من 100 مللي ثانية، وتم تمديده إلى 100 مللي ثانية تلقائيًا. قم بتنزيل مجموعة البيانات التي تمت تسويتها وراجعها. |
| عدم تطابق | إصلاح الصمت التلقائي | تم كشف أن صمت النهاية أقصر من 100 مللي ثانية، وتم تمديده إلى 100 مللي ثانية تلقائيًا. قم بتنزيل مجموعة البيانات التي تمت تسويتها وراجعها. |
| البرنامج النصي | تسوية النص تلقائيا | تتم تسوية النص تلقائيا للأرقام والرموز والاختصارات. راجع البرنامج النصي والصوت للتأكد من تطابقهما. |
الفحص اليدوي مطلوب
تؤثر الأخطاء التي لم يتم حلها المدرجة في الجدول التالي على جودة التدريب، ولكن لن يتم استبعاد البيانات التي تحتوي على هذه الأخطاء أثناء التدريب. للحصول على تدريب عالي الجودة، من الأفضل إصلاح هذه الأخطاء يدويًا.
| Category | الاسم | الوصف |
|---|---|---|
| البرنامج النصي | نص غير طبيعي | يحتوي هذا البرنامج النصي على رموز. تسوية الرموز لمطابقة الصوت. على سبيل المثال، التطبيع / إلى شرطة مائلة. |
| البرنامج النصي | ليس هناك ما يكفي من الكلمات المنطوقة | يجب أن تكون 10 في المائة على الأقل من إجمالي الكلمات المنطوقة عبارة عن جمل استفهام. يساعد هذا النموذج الصوتي على التعبير عن نغمة الاستجواب بشكل صحيح. |
| البرنامج النصي | لا يوجد ما يكفي من كلمات التعجب المنطوقة | يجب أن تكون 10 بالمائة على الأقل من إجمالي عدد الكلمات المنطوقة عبارة عن جمل تعجب. يساعد هذا النموذج الصوتي على التعبير عن نغمة حماسية بشكل صحيح. |
| البرنامج النصي | لا توجد علامات ترقيم نهاية صالحة | أضف واحدًا مما يلي في نهاية السطر: نقطة توقف (نصف عرض "." أو عرض كامل " ")، أو علامة تعجب (نصف عرض "!" أو عرض كامل "!")، أو علامة السؤال (نصف العرض "؟" أو "؟" العرض الكامل). |
| الصوت | انخفاض معدل أخذ العينات للصوت العصبي | يوصى بأن يكون معدل أخذ العينات لملفات .wav 24 كيلو هرتز أو أعلى لإنشاء أصوات عصبية. إذا كان أقل، فسيتم رفعه تلقائيًا إلى 24 كيلو هرتز. |
| الحجم | الحجم الإجمالي منخفض جدًا | يجب ألا تكون وحدة التخزين أقل من -18 ديسيبل (10 بالمائة من الحد الأقصى لوحدة التخزين). التحكم في متوسط مستوى الصوت ضمن النطاق المناسب أثناء تسجيل العينة أو إعداد البيانات. |
| الحجم | تجاوز وحدة التخزين | تم الكشف عن حجم تجاوز في {} ثانية. اضبط معدات التسجيل لتجنب تجاوز وحدة التخزين عند قيمتها القصوى. |
| الحجم | بدء مشكلة الصمت | أول 100 مللي ثانية من الصمت ليست نظيفة. قم بتقليل مستوى ضوضاء التسجيل، واترك أول 100 مللي ثانية في البداية صامتة. |
| الحجم | إنهاء مشكلة الصمت | آخر 100 مللي ثانية من الصمت ليست نظيفة. قم بتقليل مستوى ضوضاء التسجيل، واترك آخر 100 مللي ثانية في النهاية صامتة. |
| عدم تطابق | الكلمات ذات الدرجات المنخفضة | راجع البرنامج النصي والمحتوى الصوتي للتأكد من تطابقهما، والتحكم في مستوى الضوضاء. قلل من مدة الصمت الطويل، أو قسّم الصوت إلى عدة كلمات منطوقة إذا كان طويلاً جدًا. |
| عدم تطابق | بدء مشكلة الصمت | تم سماع صوت إضافي قبل الكلمة الأولى. راجع البرنامج النصي والمحتوى الصوتي للتأكد من تطابقهما، والتحكم في مستوى الضوضاء، وجعل أول 100 مللي ثانية صامتة. |
| عدم تطابق | إنهاء مشكلة الصمت | تم سماع صوت إضافي بعد الكلمة الأخيرة. قم بمراجعة البرنامج النصي والمحتوى الصوتي للتأكد من تطابقهما، والتحكم في مستوى الضوضاء، وجعل آخر 100 مللي ثانية صامتة. |
| عدم تطابق | نسبة ضوضاء الإشارة المنخفضة | مستوى SNR الصوتي أقل من 20 ديسيبل. يوصى بما لا يقل عن 35 ديسيبل. |
| عدم تطابق | لا توجد درجات متاحة | فشل التعرف على محتوى الكلام في هذا الصوت. تحقق من محتوى الصوت والبرنامج النصي للتأكد من أن الصوت صالح ومطابق للبرنامج النصي. |
الخطوات التالية
تحتاج إلى مجموعة بيانات تدريب لإنشاء صوت احترافي. تتضمن مجموعة بيانات التدريب ملفات الصوت والبرامج النصية. الملفات الصوتية هي تسجيلات للموهبة الصوتية التي تقرأ ملفات البرنامج النصي. ملفات البرنامج النصي هي نص الملفات الصوتية.
في هذه المقالة، يمكنك إنشاء مجموعة تدريب والحصول على معرف المورد الخاص بها. بعد ذلك، باستخدام معرف المورد، يمكنك تحميل مجموعة من ملفات الصوت والبرامج النصية.
إنشاء مجموعة تدريب
لإنشاء مجموعة تدريب، استخدم عملية TrainingSets_Create لواجهة برمجة التطبيقات الصوتية المخصصة. إنشاء نص الطلب وفقًا للإرشادات التالية:
- عيّن الخاصية
projectIdالمطلوبة. راجع إنشاء مشروع. - تعيين الخاصية المطلوبة
voiceKindإلىMaleأوFemale. لا يمكن تغيير النوع لاحقا. - عيّن الخاصية
localeالمطلوبة. يجب أن يكون هذا هو الإعدادات المحلية لبيانات مجموعة التدريب. يجب أن تكون الإعدادات المحلية لمجموعة التدريب هي نفس الإعدادات المحلية لبيان الموافقة. لا يمكن تغيير الإعدادات المحلية لاحقًا. يمكنك العثور على القائمة المحلية لتحويل النص إلى كلام هنا. - اختياريا، قم بتعيين الخاصية
descriptionلوصف مجموعة التدريب. يمكن تغيير وصف مجموعة التدريب لاحقا.
قم بإجراء طلب HTTP PUT باستخدام URI كما هو موضح في المثال TrainingSets_Create التالي.
- استبدل
YourResourceKeyبمفتاح مورد الكلام. - استبدل
YourResourceRegionبمنطقة مورد Speech. - استبدل
JessicaTrainingSetIdبمعرف مجموعة تدريب من اختيارك. سيتم استخدام المعرف الحساس لحالة الأحرف في URI الخاص بمجموعة التدريب ولا يمكن تغييره لاحقا.
curl -v -X PUT -H "Ocp-Apim-Subscription-Key: YourResourceKey" -H "Content-Type: application/json" -d '{
"description": "300 sentences Jessica data in general style.",
"projectId": "ProjectId",
"locale": "en-US",
"voiceKind": "Female"
} ' "https://YourResourceRegion.api.cognitive.microsoft.com/customvoice/trainingsets/JessicaTrainingSetId?api-version=2023-12-01-preview"
يجب أن تتلقى نص الاستجابة بالتنسيق التالي:
{
"id": "JessicaTrainingSetId",
"description": "300 sentences Jessica data in general style.",
"projectId": "ProjectId",
"locale": "en-US",
"voiceKind": "Female",
"status": "Succeeded",
"createdDateTime": "2023-04-01T05:30:00.000Z",
"lastActionDateTime": "2023-04-02T10:15:30.000Z"
}
تحميل بيانات مجموعة التدريب
لتحميل مجموعة تدريب من الصوت والبرامج النصية، استخدم TrainingSets_UploadData تشغيل واجهة برمجة التطبيقات الصوتية المخصصة.
قبل استدعاء واجهة برمجة التطبيقات هذه، يرجى تخزين ملفات التسجيل والبرامج النصية في Azure Blob. في المثال أدناه، ملفات التسجيل هي https://contoso.blob.core.windows.net/voicecontainer/jessica300/*.wav، وملفات البرنامج النصي هي https://contoso.blob.core.windows.net/voicecontainer/jessica300/*.txt.
إنشاء نص الطلب وفقًا للإرشادات التالية:
- تعيين الخاصية المطلوبة
kindإلىAudioAndScript. يحدد النوع نوع مجموعة التدريب. - عيّن الخاصية
audiosالمطلوبة. ضمن الخاصيةaudios، قم بتعيين الخصائص التالية:- قم بتعيين الخاصية المطلوبة
containerUrlإلى عنوان URL لحاوية Azure Blob Storage التي تحتوي على ملفات الصوت. استخدم توقيعات الوصول المشترك (SAS) لحاوية بأذونات القراءة والقائمة. - تعيين الخاصية المطلوبة
extensionsإلى ملحقات الملفات الصوتية. - اختياريا، قم بتعيين الخاصية
prefixلتعيين بادئة لاسم الكائن الثنائي كبير الحجم.
- قم بتعيين الخاصية المطلوبة
- عيّن الخاصية
scriptsالمطلوبة. ضمن الخاصيةscripts، قم بتعيين الخصائص التالية:- قم بتعيين الخاصية المطلوبة
containerUrlإلى عنوان URL لحاوية Azure Blob Storage التي تحتوي على ملفات البرنامج النصي. استخدم توقيعات الوصول المشترك (SAS) لحاوية بأذونات القراءة والقائمة. - تعيين الخاصية المطلوبة
extensionsإلى ملحقات ملفات البرنامج النصي. - اختياريا، قم بتعيين الخاصية
prefixلتعيين بادئة لاسم الكائن الثنائي كبير الحجم.
- قم بتعيين الخاصية المطلوبة
قم بإجراء طلب HTTP POST باستخدام URI كما هو موضح في المثال TrainingSets_UploadData التالي.
- استبدل
YourResourceKeyبمفتاح مورد الكلام. - استبدل
YourResourceRegionبمنطقة مورد Speech. - استبدل
JessicaTrainingSetIdإذا حددت معرف مجموعة تدريب مختلف في الخطوة السابقة.
curl -v -X POST -H "Ocp-Apim-Subscription-Key: YourResourceKey" -H "Content-Type: application/json" -d '{
"kind": "AudioAndScript",
"audios": {
"containerUrl": "https://contoso.blob.core.windows.net/voicecontainer?mySasToken",
"prefix": "jessica300/",
"extensions": [
".wav"
]
},
"scripts": {
"containerUrl": "https://contoso.blob.core.windows.net/voicecontainer?mySasToken",
"prefix": "jessica300/",
"extensions": [
".txt"
]
}
} ' "https://YourResourceRegion.api.cognitive.microsoft.com/customvoice/trainingsets/JessicaTrainingSetId:upload?api-version=2023-12-01-preview"
يحتوي عنوان الاستجابة على الخاصية Operation-Location . استخدم URI هذا للحصول على تفاصيل حول عملية TrainingSets_UploadData . فيما يلي مثال على رأس الاستجابة:
Operation-Location: https://eastus.api.cognitive.microsoft.com/customvoice/operations/284b7e37-f42d-4054-8fa9-08523c3de345?api-version=2023-12-01-preview
Operation-Id: 284b7e37-f42d-4054-8fa9-08523c3de345
الخطوات التالية
الملاحظات
قريبًا: خلال عام 2024، سنتخلص تدريجيًا من GitHub Issues بوصفها آلية إرسال ملاحظات للمحتوى ونستبدلها بنظام ملاحظات جديد. لمزيد من المعلومات، راجع https://aka.ms/ContentUserFeedback.
إرسال الملاحظات وعرضها المتعلقة بـ