ملاحظة
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تسجيل الدخول أو تغيير الدلائل.
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تغيير الدلائل.
في هذه المقالة، ستتعلم كيفية ضبط صوت احترافي من خلال مدخل Azure الذكاء الاصطناعي Foundry.
مهم
لا يتوفر ضبط الصوت الاحترافي حاليا إلا في بعض المناطق. بعد تدريب نموذج الصوت في منطقة مدعومة، يمكنك نسخ نموذج الصوت الاحترافي إلى مورد Azure الذكاء الاصطناعي Foundry في منطقة أخرى حسب الحاجة. لمزيد من المعلومات، راجع الحواشي السفلية في جدول خدمة الكلام.
تختلف مدة التدريب حسب كمية البيانات التي تستخدمها. يستغرق الأمر حوالي 40 ساعة حساب في المتوسط لضبط صوت احترافي. باستخدام مورد Azure الذكاء الاصطناعي Foundry القياسي (S0)، يمكنك تدريب أربعة أصوات في وقت واحد. إذا وصلت إلى الحد الأقصى، فانتظر حتى ينتهي أحد النماذج الصوتية على الأقل من التدريب، ثم حاول مرة أخرى.
مُلاحَظةٌ
على الرغم من أن إجمالي عدد الساعات المطلوبة لكل طريقة تدريب يختلف، فإن سعر الوحدة نفسه ينطبق على كل منها. لمزيد من المعلومات، راجع تفاصيل تسعير التدريب العصبي المخصص.
اختيار أسلوب تدريب
بعد التحقق من صحة ملفات البيانات، استخدمها لإنشاء نموذج صوت مخصص. عند إنشاء صوت مخصص، يمكنك اختيار تدريبه باستخدام إحدى الطرق التالية:
العصبية: إنشاء صوت بنفس لغة بيانات التدريب الخاصة بك.
العصبية - عبر اللغات: إنشاء صوت يتحدث لغة مختلفة عن بيانات التدريب الخاصة بك. على سبيل المثال، باستخدام
zh-CNبيانات التدريب، يمكنك إنشاء صوت يتحدثen-US.يجب أن تكون لغة بيانات التدريب واللغة المستهدفة إحدى اللغات المدعومة للتدريب الصوتي عبر اللغات. لا تحتاج إلى إعداد بيانات التدريب باللغة الهدف، ولكن يجب أن يكون البرنامج النصي للاختبار باللغة الهدف.
العصبية - متعددة الأنماط: إنشاء صوت مخصص يتحدث بأنماط وعواطف متعددة، دون إضافة بيانات تدريب جديدة. تعد أصوات الأنماط المتعددة مفيدة لأحرف ألعاب الفيديو روبوتات المحادثة والكتب الصوتية وقارئات المحتوى والمزيد.
لإنشاء صوت متعدد الأنماط، تحتاج إلى إعداد مجموعة من بيانات التدريب العامة، على الأقل 300 كلمة. حدد نمطا واحدا أو أكثر من أنماط التحدث المستهدفة المحددة مسبقا. يمكنك أيضا إنشاء أنماط مخصصة متعددة من خلال توفير نماذج أنماط، من 100 تعبير على الأقل لكل نمط، كبيانات تدريب إضافية لنفس الصوت. تختلف أنماط الإعداد المسبق المدعومة وفقا للغات مختلفة. اطلع على أنماط الإعداد المسبق المتوفرة عبر لغات مختلفة.
العصبية - متعددة اللغات (معاينة): إنشاء صوت يتحدث لغات متعددة باستخدام بيانات التدريب بلغة واحدة. على سبيل المثال، باستخدام
en-USبيانات التدريب الأساسية، يمكنك إنشاء صوت يتحدثen-US،de-DEzh-CNو، وما إلى ذلك. اللغات الثانوية.يجب أن تكون اللغة الأساسية لبيانات التدريب واللغات الثانوية باللغات المدعومة للتدريب الصوتي متعدد اللغات. لا تحتاج إلى إعداد بيانات التدريب باللغات الثانوية.
يجب أن تكون لغة بيانات التدريب إحدى اللغات المدعومة للصوت المخصص أو عبر اللغات أو التدريب متعدد الأنماط.
تدريب نموذج الصوت المخصص
لإنشاء صوت مخصص في مدخل Microsoft Azure الذكاء الاصطناعي Foundry، اتبع الخطوات التالية لإحدى الطرق التالية:
- عصبي
- العصبية - اللغات المتقاطعة
- العصبية - نمط متعدد
- العصبية - متعددة اللغات (معاينة)
- العصبية - صوت عالي الدقة (معاينة)
سجل الدخول إلى مدخل Azure الذكاء الاصطناعي Foundry.
حدد "Fine-tuning" من الجزء الأيمن ثم حدد "الذكاء الاصطناعي Service fine-tuning".
حدد مهمة ضبط الصوت الاحترافي (حسب اسم النموذج) التي بدأتها كما هو موضح في مقالة إنشاء صوت احترافي.
حدد Train model>+ Train model.
حدد العصبيةكطريقة تدريب لنموذجك. لاستخدام طريقة تدريب مختلفة، راجع العصبية - اللغات التبادلية، العصبية - متعددة الأنماط، العصبية - متعددة اللغات (معاينة)، أو العصبية - صوت عالي الدقة (معاينة).
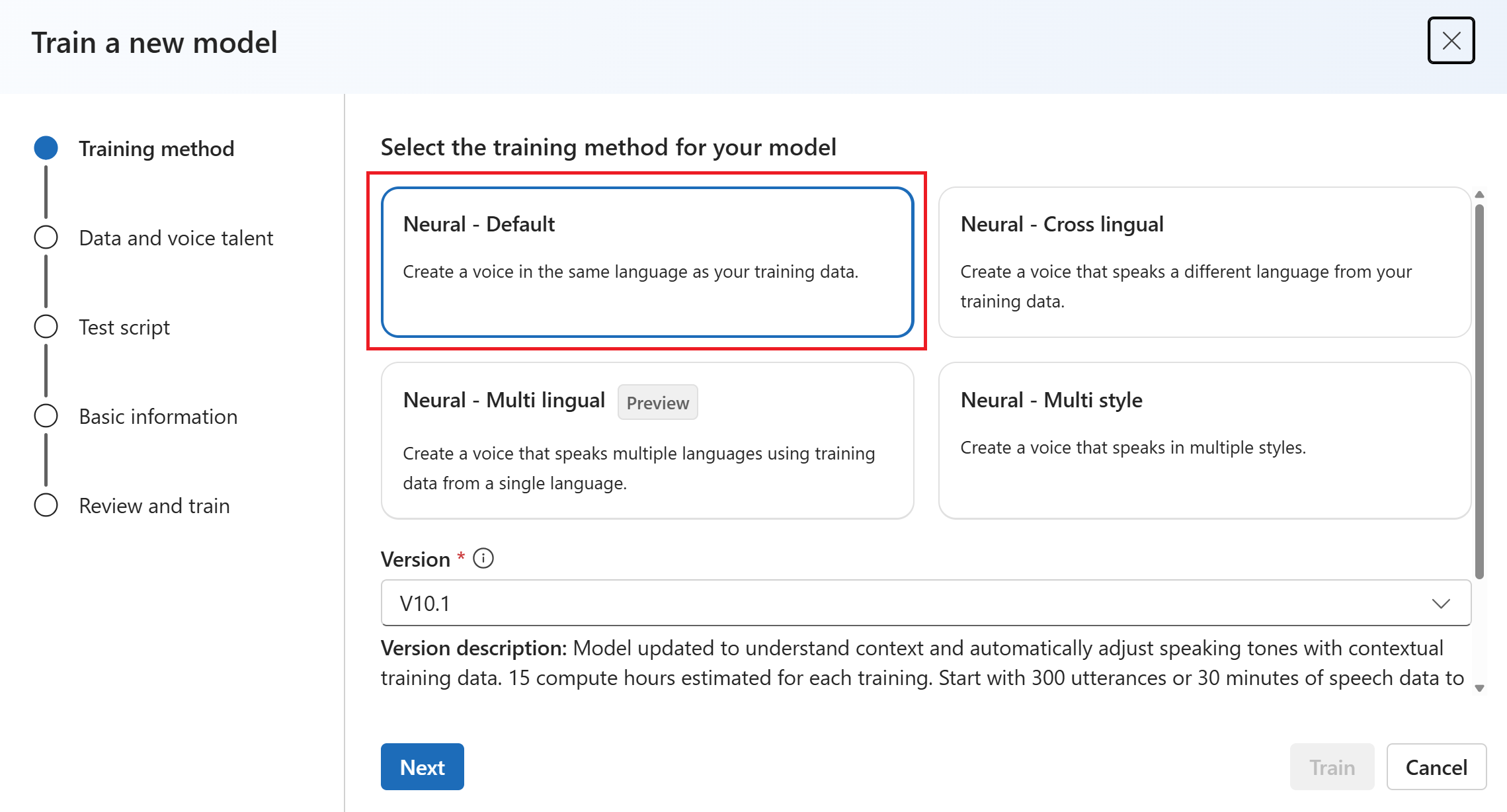
حدد إصدارا من وصفة التدريب للنموذج الخاص بك. يتم تحديد أحدث إصدار بشكل افتراضي. يمكن أن تختلف الميزات المدعومة ووقت التدريب حسب الإصدار. عادة، نوصي بأحدث إصدار. في بعض الحالات، يمكنك اختيار إصدار سابق لتقليل وقت التدريب. راجع التدريب ثنائي اللغة لمزيد من المعلومات حول التدريب ثنائي اللغة والاختلافات بين اللغات.
حدد التالي.
حدد البيانات التي تريد استخدامها للتدريب. تتم إزالة الأسماء الصوتية المكررة من التدريب. تأكد من أن البيانات التي تحددها لا تحتوي على نفس أسماء الصوت عبر ملفات .zip متعددة.
يمكنك تحديد مجموعات البيانات التي تمت معالجتها بنجاح فقط للتدريب. إذا كنت لا ترى مجموعة التدريب الخاصة بك في القائمة، فتحقق من حالة معالجة البيانات.
حدد ملف المتحدث مع بيان المواهب الصوتية الذي يتوافق مع المتحدث في بيانات التدريب الخاصة بك.
حدد التالي.
حدد برنامج نصي للاختبار ثم حدد التالي.
- ينشئ كل تدريب 100 عينة من ملفات الصوت تلقائيا لمساعدتك في اختبار النموذج باستخدام برنامج نصي افتراضي.
- بدلا من ذلك، يمكنك تحديد Add my own test script وتوفير برنامجك النصي للاختبار الخاص بك مع ما يصل إلى 100 تعبير لاختبار النموذج دون أي تكلفة إضافية. تعد الملفات الصوتية التي تم إنشاؤها مزيجا من البرامج النصية للاختبار التلقائي والبرامج النصية المخصصة للاختبار. لمزيد من المعلومات، راجع متطلبات البرنامج النصي للاختبار.
أدخل اسم نموذج الصوت. اختر الاسم بعناية. يتم استخدام اسم النموذج كاسم صوتي في طلب تركيب الكلام بواسطة إدخال SDK وSSML. يسمح بالأحرف والأرقام وبعض أحرف الترقيم فقط. استخدم أسماء مختلفة لنماذج صوتية عصبية مختلفة.
اختياريا، أدخل الوصف لمساعدتك في تحديد النموذج. الاستخدام الشائع للوصف هو تسجيل أسماء البيانات التي استخدمتها لإنشاء النموذج.
حدد خانة الاختيار لقبول شروط الاستخدام ثم حدد التالي.
راجع الإعدادات وحدد المربع لقبول شروط الاستخدام.
حدد تدريب لبدء تدريب النموذج.

تدريب ثنائي اللغة
إذا حددت نوع التدريب العصبي ، يمكنك تدريب صوت على التحدث بلغات متعددة.
zh-CN
zh-HKتدعم و و zh-TW المحلية التدريب ثنائي اللغة للصوت للتحدث باللغتين الصينية والإنجليزية. اعتمادا جزئيا على بيانات التدريب الخاصة بك، يمكن للصوت المركب التحدث باللغة الإنجليزية بلكنة إنجليزية أصلية أو الإنجليزية بنفس لهجة بيانات التدريب.
مُلاحَظةٌ
لتمكين صوت في zh-CN الإعدادات المحلية من التحدث باللغة الإنجليزية بنفس تشكيلة البيانات النموذجية، يجب تحميل البيانات الإنجليزية إلى مجموعة تدريب سياقية ، أو اختيار Chinese (Mandarin, Simplified), English bilingual عند إنشاء مشروع أو تحديد zh-CN (English bilingual) الإعدادات المحلية لبيانات مجموعة التدريب عبر REST API.
في مجموعة التدريب السياقية، قم بتضمين ما لا يقل عن 100 جملة أو 10 دقائق من محتوى اللغة الإنجليزية ولا تتجاوز كمية المحتوى الصيني.
يوضح الجدول التالي الاختلافات بين الشبكات المحلية:
| إعدادات Speech Studio المحلية | إعدادات REST API المحلية | دعم ثنائي اللغة |
|---|---|---|
Chinese (Mandarin, Simplified) |
zh-CN |
إذا كانت بيانات العينة الخاصة بك تتضمن اللغة الإنجليزية، فإن الصوت المركب يتحدث الإنجليزية بلكنة أصلية إنجليزية، بدلا من نفس لهجة بيانات العينة، بغض النظر عن كمية البيانات الإنجليزية. |
Chinese (Mandarin, Simplified), English bilingual |
zh-CN (English bilingual) |
إذا كنت تريد أن يتحدث الصوت المركب اللغة الإنجليزية بنفس تشكيلة بيانات العينة، نوصي بتضمين أكثر من 10% بيانات اللغة الإنجليزية في مجموعة التدريب الخاصة بك. وإلا، فقد لا تكون لهجة اللغة الإنجليزية مثالية. |
Chinese (Cantonese, Simplified) |
zh-HK |
إذا كنت ترغب في تدريب صوت مركب قادر على التحدث باللغة الإنجليزية بنفس تشكيلة بيانات العينة الخاصة بك، فتأكد من توفير أكثر من 10% بيانات اللغة الإنجليزية في مجموعة التدريب الخاصة بك. وإلا، تعيينه افتراضيا إلى لهجة أصلية إنجليزية. يتم حساب عتبة 10% استنادا إلى البيانات المقبولة بعد التحميل الناجح، وليس البيانات قبل التحميل. إذا تم رفض بعض البيانات الإنجليزية التي تم تحميلها بسبب عيوب ولا تفي بالحد 10%، يتم تعيين الصوت المركب افتراضيا إلى لهجة أصلية إنجليزية. |
Chinese (Taiwanese Mandarin, Traditional) |
zh-TW |
إذا كنت ترغب في تدريب صوت مركب قادر على التحدث باللغة الإنجليزية بنفس تشكيلة بيانات العينة الخاصة بك، فتأكد من توفير أكثر من 10% بيانات اللغة الإنجليزية في مجموعة التدريب الخاصة بك. وإلا، تعيينه افتراضيا إلى لهجة أصلية إنجليزية. يتم حساب عتبة 10% استنادا إلى البيانات المقبولة بعد التحميل الناجح، وليس البيانات قبل التحميل. إذا تم رفض بعض البيانات الإنجليزية التي تم تحميلها بسبب عيوب ولا تفي بالحد 10%، يتم تعيين الصوت المركب افتراضيا إلى لهجة أصلية إنجليزية. |



مراقبة عملية التدريب
يعرض جدول نموذج التدريب إدخالا جديدا يتوافق مع هذا النموذج الذي تم إنشاؤه حديثا. تعكس الحالة عملية تحويل بياناتك إلى نموذج صوتي، كما هو موضح في هذا الجدول:
| الولاية | المعنى |
|---|---|
| قيد المعالجة | يتم إنشاء نموذج الصوت الخاص بك. |
| نجح | تم إنشاء نموذج الصوت الخاص بك ويمكن نشره. |
| فشل | فشل نموذجك الصوتي في التدريب. قد يكون سبب الفشل، على سبيل المثال، مشاكل البيانات غير المرئية أو مشكلات الشبكة. |
| تم الإلغاء | تم إلغاء التدريب لنموذج الصوت الخاص بك. |
أثناء معالجة حالة النموذج، يمكنك تحديد النموذج ثم تحديد إلغاء التدريب لإلغاء التدريب. لا يتم تحصيل رسوم منك مقابل هذا التدريب الذي تم إلغاؤه.

بعد الانتهاء من تدريب النموذج بنجاح، يمكنك مراجعة تفاصيل النموذج واختبار نموذج الصوت الخاص بك.
إعادة تسمية النموذج الخاص بك
يجب عليك استنساخ النموذج الخاص بك لإعادة تسميته. لا يمكنك إعادة تسمية النموذج مباشرة.
- حدد النموذج.
- حدد Clone model لإنشاء نسخة من النموذج باسم جديد في المشروع الحالي.
- أدخل الاسم الجديد في نافذة Clone voice model .
- حدد إرسَال. تتم إضافة النص العصبي تلقائيا كلاحقة إلى اسم النموذج الجديد.
اختبار نموذج الصوت الخاص بك
بعد إنشاء نموذج الصوت بنجاح، يمكنك استخدام نموذج ملفات الصوت التي تم إنشاؤها لاختباره قبل نشره.
مُلاحَظةٌ
العصبية - متعددة اللغات (معاينة)والعصبية - HD الصوت (معاينة) لا تدعم هذا النوع من الاختبارات.
تعتمد جودة الصوت على العديد من العوامل، مثل:
- حجم بيانات التدريب.
- جودة التسجيل.
- دقة ملف النسخة المكتوبة.
- مدى تطابق الصوت المسجل في بيانات التدريب مع شخصية الصوت المصمم لحالة الاستخدام المقصودة.
حدد DefaultTests ضمن Testing للاستماع إلى ملفات الصوت النموذجية. تتضمن نماذج الاختبار الافتراضية 100 عينة من ملفات الصوت التي تم إنشاؤها تلقائيا أثناء التدريب لمساعدتك في اختبار النموذج. بالإضافة إلى هذه الملفات الصوتية ال 100 المقدمة بشكل افتراضي، تتم أيضا إضافة تعبيرات البرنامج النصي للاختبار الخاص بك إلى مجموعة DefaultTests . هذه الإضافة هي على الأكثر 100 كلمة. لا يتم تحصيل رسوم منك مقابل الاختبار باستخدام DefaultTests.
إذا كنت ترغب في تحميل البرامج النصية للاختبار الخاصة بك لاختبار النموذج الخاص بك بشكل أكبر، فحدد إضافة برامج نصية للاختبار لتحميل البرنامج النصي للاختبار الخاص بك.
قبل تحميل البرنامج النصي للاختبار، تحقق من متطلبات البرنامج النصي للاختبار. يتم تحصيل رسوم منك مقابل الاختبار الإضافي باستخدام تركيب الدفعة استنادا إلى عدد الأحرف القابلة للفوترة. راجع أسعار Azure الذكاء الاصطناعي Speech.
ضمن Add test scripts، حدد Browse for a file لتحديد البرنامج النصي الخاص بك، ثم حدد Add لتحميله.
اختبار متطلبات البرنامج النصي
يجب أن يكون البرنامج النصي للاختبار ملف .txt أقل من 1 ميغابايت. تتضمن تنسيقات الترميز المدعومة ANSI/ASCII أو UTF-8 أو UTF-8-BOM أو UTF-16-LE أو UTF-16-BE.
على عكس ملفات كتابة التدريب، يجب أن يستبعد البرنامج النصي الاختبار معرف التعبير، وهو اسم الملف لكل تعبير. وإلا، يتم التحدث بهذه المعرفات.
فيما يلي مثال لمجموعة من التعبيرات في ملف .txt واحد:
This is the waistline, and it's falling.
We have trouble scoring.
It was Janet Maslin.
ينتج عن كل فقرة من التعبير صوت منفصل. إذا كنت تريد دمج كل الجمل في صوت واحد، فاجعلها فقرة واحدة.
مُلاحَظةٌ
تعد الملفات الصوتية التي تم إنشاؤها مزيجا من البرامج النصية للاختبار التلقائي والبرامج النصية المخصصة للاختبار.
تحديث إصدار المحرك لنموذج الصوت الخاص بك
يتم تحديث نص Azure إلى محركات الكلام من وقت لآخر لالتقاط أحدث نموذج لغة يحدد نطق اللغة. بعد تدريب صوتك، يمكنك تطبيق صوتك على نموذج اللغة الجديد عن طريق التحديث إلى أحدث إصدار من المحرك.
- عندما يتوفر محرك جديد، تتم مطالبتك بتحديث نموذج الصوت العصبي.
- انتقل إلى صفحة تفاصيل النموذج واتبع الإرشادات التي تظهر على الشاشة لتثبيت أحدث محرك.
- بدلا من ذلك، حدد تثبيت أحدث محرك لاحقا لتحديث الطراز الخاص بك إلى أحدث إصدار من المحرك. لا يتم تحصيل رسوم منك مقابل تحديث المحرك. لا يزال يتم الاحتفاظ بالإصدارات السابقة.
- يمكنك التحقق من جميع إصدارات المحرك للنموذج من قائمة إصدار المحرك ، أو إزالة إصدار إذا لم تعد بحاجة إليه.
يتم تعيين الإصدار المحدث تلقائيا كافتراضي. ولكن يمكنك تغيير الإصدار الافتراضي عن طريق تحديد إصدار من القائمة المنسدلة وتحديد تعيين كافتراضي.
إذا كنت ترغب في اختبار كل إصدار محرك من طراز الصوت الخاص بك، يمكنك تحديد إصدار من القائمة، ثم تحديد DefaultTests ضمن Testing للاستماع إلى نموذج ملفات الصوت. إذا كنت ترغب في تحميل البرامج النصية للاختبار الخاصة بك لاختبار إصدار المحرك الحالي، فتأكد أولا من تعيين الإصدار كافتراضي، ثم اتبع الخطوات الواردة في اختبار نموذج الصوت الخاص بك.
يؤدي تحديث المحرك إلى إنشاء إصدار جديد من النموذج دون أي تكلفة إضافية. بعد تحديث إصدار المحرك لنموذج الصوت الخاص بك، تحتاج إلى نشر الإصدار الجديد لإنشاء نقطة نهاية جديدة. يمكنك نشر الإصدار الافتراضي فقط.
بعد إنشاء نقطة نهاية جديدة، تحتاج إلى نقل نسبة استخدام الشبكة إلى نقطة النهاية الجديدة في منتجك.
لمعرفة المزيد حول قدرات وحدود هذه الميزة، وأفضل الممارسات لتحسين جودة النموذج الخاص بك، راجع خصائص وقيود استخدام الصوت المخصص.
نسخ نموذج الصوت إلى مشروع آخر
مُلاحَظةٌ
في هذا السياق يشير "المشروع" إلى مهمة ضبط دقيقة بدلا من مشروع Azure الذكاء الاصطناعي Foundry.
بعد التدريب، يمكنك نسخ نموذج الصوت الخاص بك إلى مشروع آخر لنفس المنطقة أو منطقة أخرى.
على سبيل المثال، يمكنك نسخ نموذج صوت بارع تم تدريبه في منطقة واحدة، إلى مشروع لمنطقة أخرى. لا يتوفر ضبط الصوت الاحترافي حاليا إلا في بعض المناطق.
لنسخ نموذج الصوت المخصص إلى مشروع آخر:
- في علامة التبويب Train model ، حدد نموذجا صوتيا تريد نسخه، ثم حدد Copy to project.
- حدد الاشتراكوالمنطقة المستهدفةومورد خدمة الذكاء الاصطناعي المتصل (الذكاء الاصطناعي مورد Foundry) ومهمة ضبط الهدف حيث تريد نسخ النموذج.
- حدد نسخ إلى لنسخ النموذج.
- حدد عرض النموذج ضمن رسالة الإعلام للنسخ الناجح.
انتقل إلى المشروع حيث قمت بنسخ النموذج لنشر نسخة النموذج.
الخطوات التَالية
في هذه المقالة، ستتعلم كيفية ضبط صوت احترافي من خلال مدخل Speech Studio.
مهم
لا يتوفر ضبط الصوت الاحترافي حاليا إلا في بعض المناطق. بعد تدريب نموذج الصوت الخاص بك في منطقة مدعومة، يمكنك نسخه إلى مورد الذكاء الاصطناعي Foundry للكلام في منطقة أخرى حسب الحاجة. لمزيد من المعلومات، راجع الحواشي السفلية في جدول خدمة الكلام.
تختلف مدة التدريب حسب كمية البيانات التي تستخدمها. يستغرق الأمر حوالي 40 ساعة حساب في المتوسط لضبط صوت احترافي. يمكن لمستخدمي الاشتراك القياسي (S0) تدريب أربعة أصوات في وقت واحد. إذا وصلت إلى الحد الأقصى، فانتظر حتى ينتهي أحد النماذج الصوتية على الأقل من التدريب، ثم حاول مرة أخرى.
مُلاحَظةٌ
على الرغم من أن إجمالي عدد الساعات المطلوبة لكل طريقة تدريب يختلف، فإن سعر الوحدة نفسه ينطبق على كل منها. لمزيد من المعلومات، راجع تفاصيل تسعير التدريب العصبي المخصص.
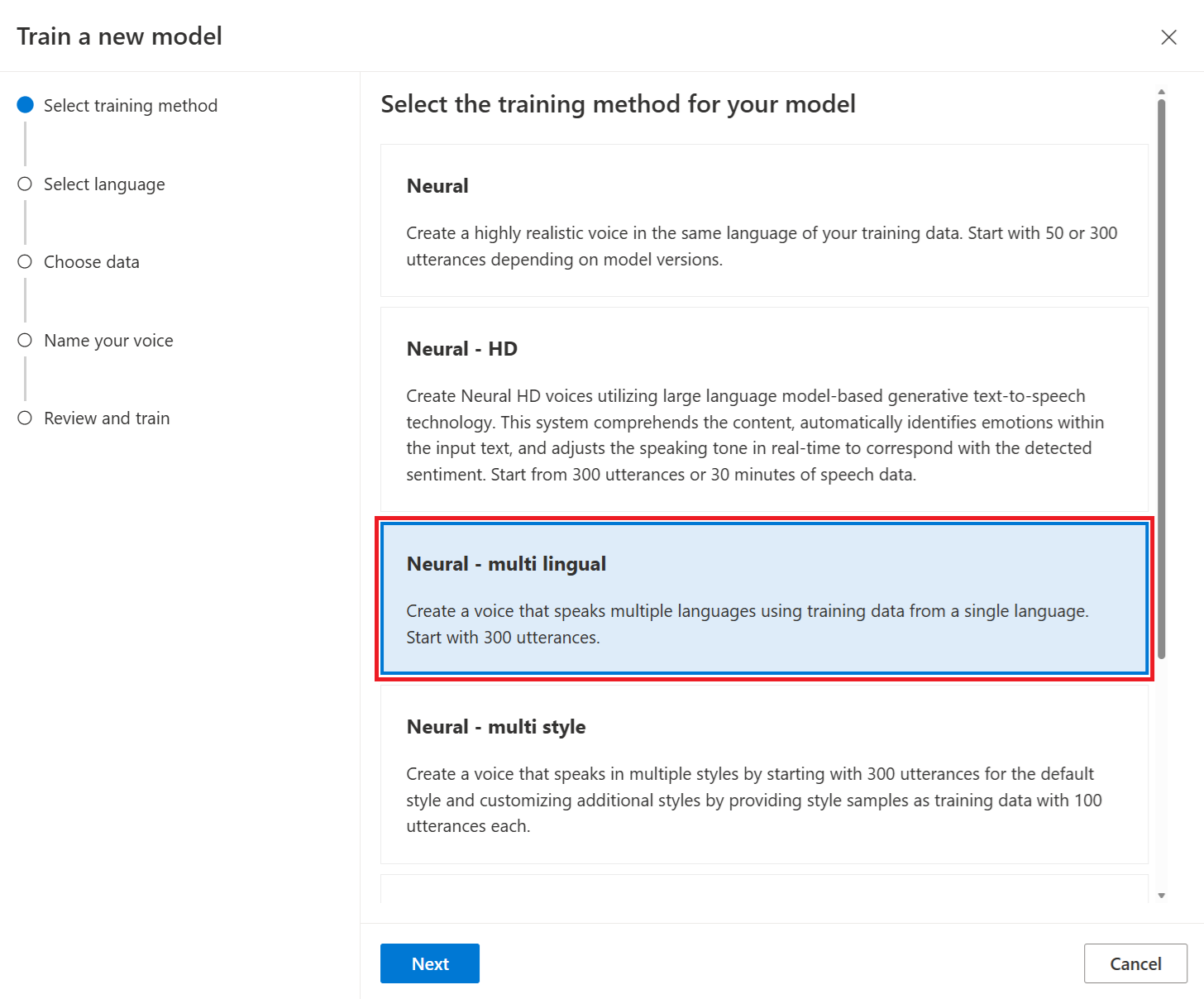
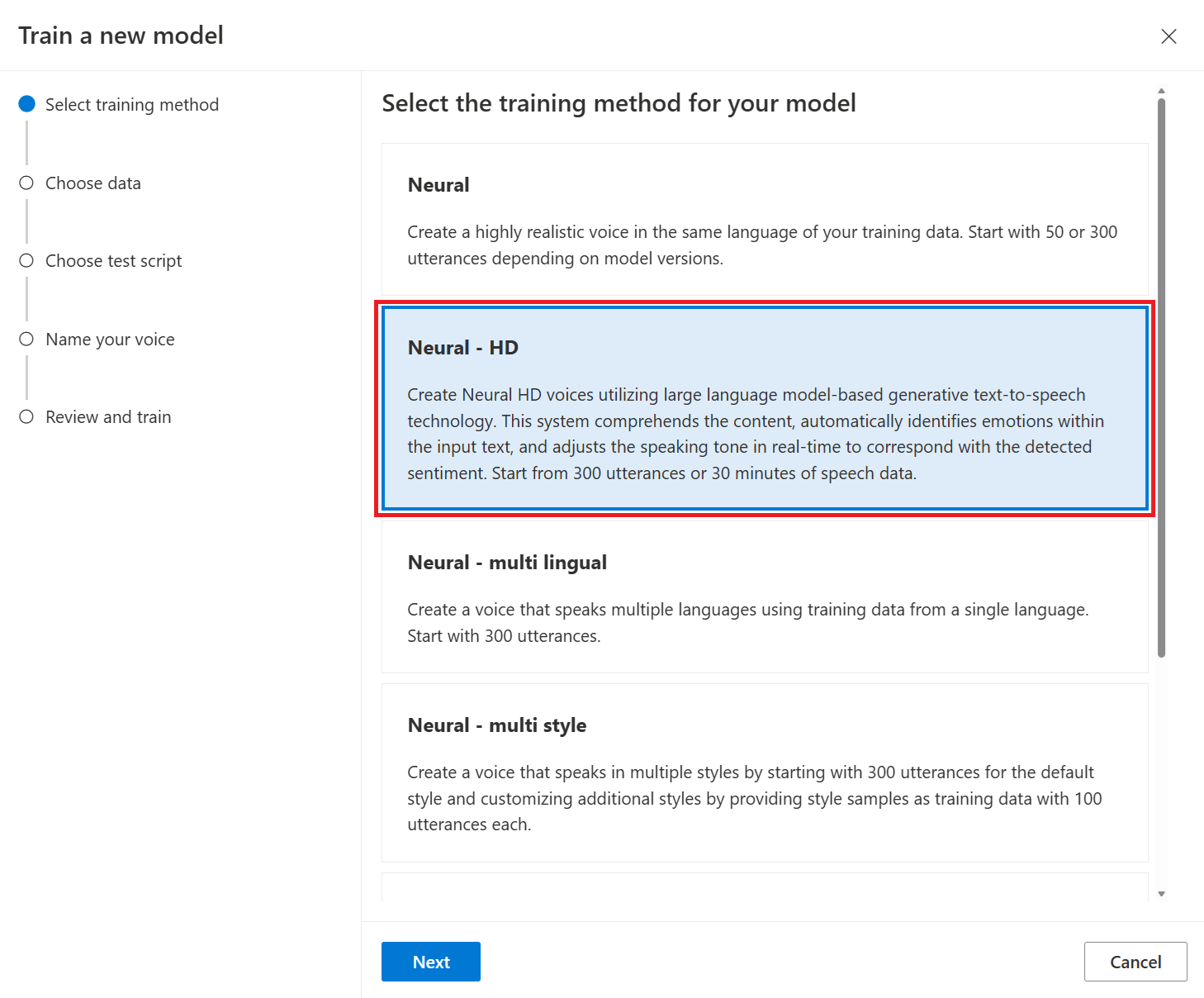
اختيار أسلوب تدريب
بعد التحقق من صحة ملفات البيانات، استخدمها لإنشاء نموذج صوت مخصص. عند إنشاء صوت مخصص، يمكنك اختيار تدريبه باستخدام إحدى الطرق التالية:
العصبية: إنشاء صوت بنفس لغة بيانات التدريب الخاصة بك.
العصبية - عبر اللغات: إنشاء صوت يتحدث لغة مختلفة عن بيانات التدريب الخاصة بك. على سبيل المثال، باستخدام
zh-CNبيانات التدريب، يمكنك إنشاء صوت يتحدثen-US.يجب أن تكون لغة بيانات التدريب واللغة المستهدفة إحدى اللغات المدعومة للتدريب الصوتي عبر اللغات. لا تحتاج إلى إعداد بيانات التدريب باللغة الهدف، ولكن يجب أن يكون البرنامج النصي للاختبار باللغة الهدف.
العصبية - متعددة الأنماط: إنشاء صوت مخصص يتحدث بأنماط وعواطف متعددة، دون إضافة بيانات تدريب جديدة. تعد أصوات الأنماط المتعددة مفيدة لأحرف ألعاب الفيديو روبوتات المحادثة والكتب الصوتية وقارئات المحتوى والمزيد.
لإنشاء صوت متعدد الأنماط، تحتاج إلى إعداد مجموعة من بيانات التدريب العامة، على الأقل 300 كلمة. حدد نمطا واحدا أو أكثر من أنماط التحدث المستهدفة المحددة مسبقا. يمكنك أيضا إنشاء أنماط مخصصة متعددة من خلال توفير نماذج أنماط، من 100 تعبير على الأقل لكل نمط، كبيانات تدريب إضافية لنفس الصوت. تختلف أنماط الإعداد المسبق المدعومة وفقا للغات مختلفة. اطلع على أنماط الإعداد المسبق المتوفرة عبر لغات مختلفة.
العصبية - متعددة اللغات (معاينة): إنشاء صوت يتحدث لغات متعددة باستخدام بيانات التدريب بلغة واحدة. على سبيل المثال، باستخدام
en-USبيانات التدريب الأساسية، يمكنك إنشاء صوت يتحدثen-US،de-DEzh-CNو، وما إلى ذلك. اللغات الثانوية.يجب أن تكون اللغة الأساسية لبيانات التدريب واللغات الثانوية باللغات المدعومة للتدريب الصوتي متعدد اللغات. لا تحتاج إلى إعداد بيانات التدريب باللغات الثانوية.
العصبية - صوت عالي الدقة (معاينة): إنشاء صوت عالي الدقة بنفس لغة بيانات التدريب الخاصة بك. تستند أصوات Azure العصبية عالية الدقة إلى LLM، ومحسنة للمحادثات الديناميكية. تعرف على المزيد حول الأصوات العصبية عالية الدقة هنا.
يجب أن تكون لغة بيانات التدريب إحدى اللغات المدعومة للصوت المخصص أو عبر اللغات أو التدريب متعدد الأنماط.
تدريب نموذج الصوت المخصص
لإنشاء صوت مخصص في Speech Studio، اتبع الخطوات التالية لإحدى الطرق التالية:
- عصبي
- العصبية - اللغات المتقاطعة
- العصبية - نمط متعدد
- العصبية - متعددة اللغات (معاينة)
- العصبية - صوت عالي الدقة (معاينة)
سجل الدخول إلى Speech Studio.
حدد صوت><مخصص اسم>> المشروعتدريب نموذج>تدريب نموذج جديد.
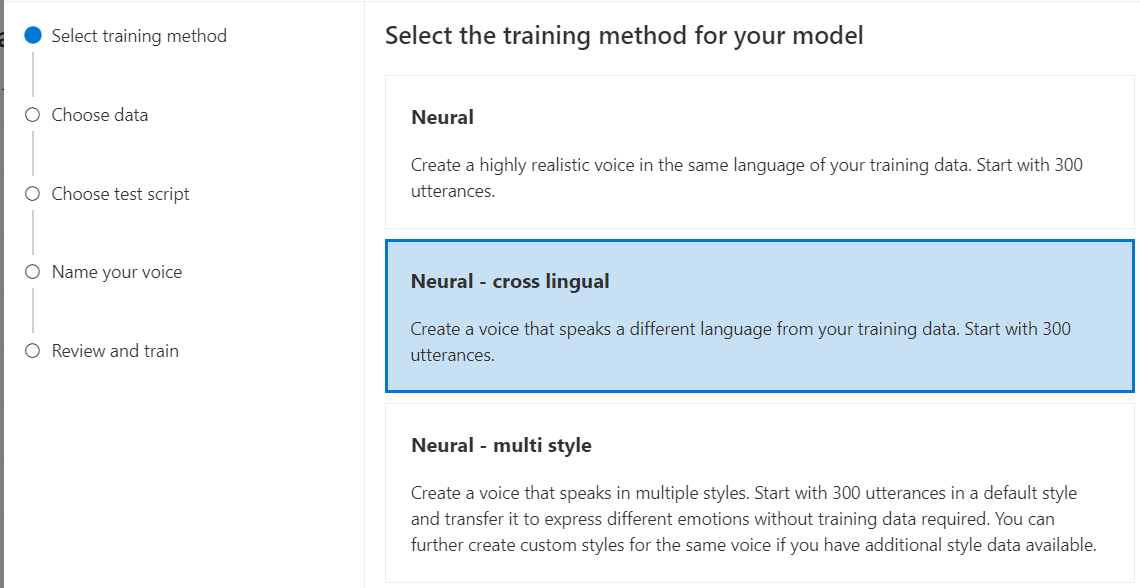
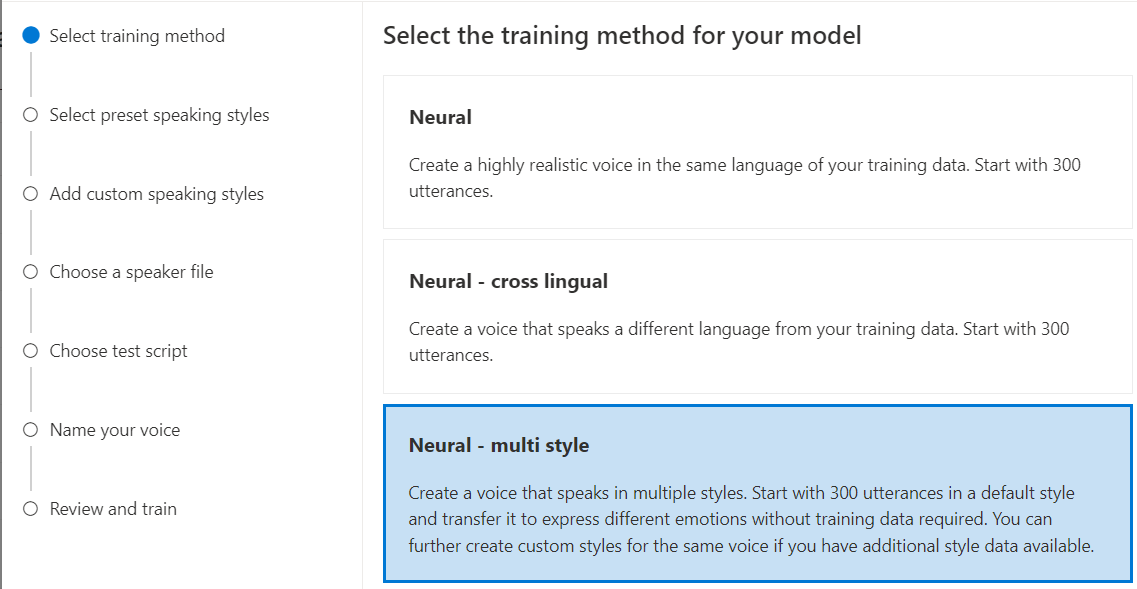
حدد العصبيةكطريقة تدريب للنموذج الخاص بك ثم حدد التالي. لاستخدام طريقة تدريب مختلفة، راجع العصبية - اللغات التبادلية أو العصبية - أنماط متعددة أو عصبية - متعددة اللغات (معاينة) أو عصبية - صوت عالي الدقة (معاينة).
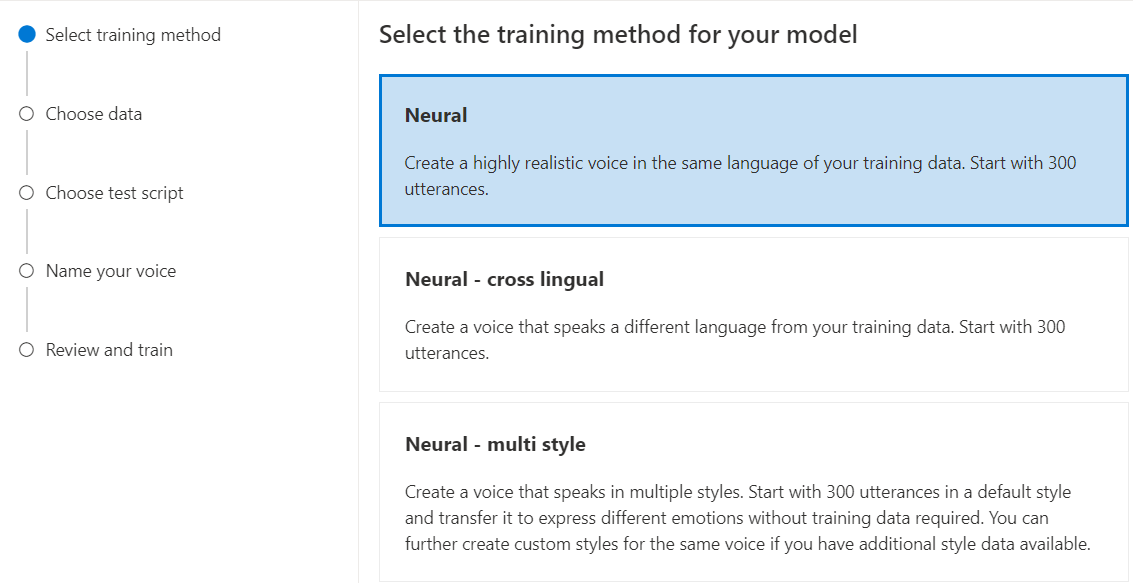
حدد إصدارا من وصفة التدريب للنموذج الخاص بك. يتم تحديد أحدث إصدار بشكل افتراضي. يمكن أن تختلف الميزات المدعومة ووقت التدريب حسب الإصدار. عادة، نوصي بأحدث إصدار. في بعض الحالات، يمكنك اختيار إصدار سابق لتقليل وقت التدريب. راجع التدريب ثنائي اللغة لمزيد من المعلومات حول التدريب ثنائي اللغة والاختلافات بين اللغات.
مُلاحَظةٌ
إصدارات
V3.0النموذج ،V7.0V8.0وسيتم إيقافها بحلول 25 يوليو 2025. لن تتأثر النماذج الصوتية التي تم إنشاؤها بالفعل على هذه الإصدارات المتوقفة.حدد البيانات التي تريد استخدامها للتدريب. تتم إزالة الأسماء الصوتية المكررة من التدريب. تأكد من أن البيانات التي تحددها لا تحتوي على نفس أسماء الصوت عبر ملفات .zip متعددة.
يمكنك تحديد مجموعات البيانات التي تمت معالجتها بنجاح فقط للتدريب. إذا كنت لا ترى مجموعة التدريب الخاصة بك في القائمة، فتحقق من حالة معالجة البيانات.
حدد ملف المتحدث مع بيان المواهب الصوتية الذي يتوافق مع المتحدث في بيانات التدريب الخاصة بك.
حدد التالي.
ينشئ كل تدريب 100 عينة من ملفات الصوت تلقائيا لمساعدتك في اختبار النموذج باستخدام برنامج نصي افتراضي.
اختياريا، يمكنك أيضا تحديد إضافة البرنامج النصي للاختبار الخاص بي وتوفير برنامجك النصي للاختبار الخاص بك مع ما يصل إلى 100 تعبير لاختبار النموذج دون أي تكلفة إضافية. تعد الملفات الصوتية التي تم إنشاؤها مزيجا من البرامج النصية للاختبار التلقائي والبرامج النصية المخصصة للاختبار. لمزيد من المعلومات، راجع متطلبات البرنامج النصي للاختبار.
أدخل اسما لمساعدتك في تحديد النموذج. اختر الاسم بعناية. يتم استخدام اسم النموذج كاسم صوتي في طلب تركيب الكلام بواسطة إدخال SDK وSSML. يسمح بالأحرف والأرقام وبعض أحرف الترقيم فقط. استخدم أسماء مختلفة لنماذج صوتية عصبية مختلفة.
اختياريا، أدخل الوصف لمساعدتك في تحديد النموذج. الاستخدام الشائع للوصف هو تسجيل أسماء البيانات التي استخدمتها لإنشاء النموذج.
حدد التالي.
راجع الإعدادات وحدد المربع لقبول شروط الاستخدام.
حدد إرسال لبدء تدريب النموذج.
تدريب ثنائي اللغة
إذا حددت نوع التدريب العصبي ، يمكنك تدريب صوت على التحدث بلغات متعددة.
zh-CN
zh-HKتدعم و و zh-TW المحلية التدريب ثنائي اللغة للصوت للتحدث باللغتين الصينية والإنجليزية. اعتمادا جزئيا على بيانات التدريب الخاصة بك، يمكن للصوت المركب التحدث باللغة الإنجليزية بلكنة إنجليزية أصلية أو الإنجليزية بنفس لهجة بيانات التدريب.
مُلاحَظةٌ
لتمكين صوت في zh-CN الإعدادات المحلية من التحدث باللغة الإنجليزية بنفس تشكيلة البيانات النموذجية، يجب تحميل البيانات الإنجليزية إلى مجموعة تدريب سياقية ، أو اختيار Chinese (Mandarin, Simplified), English bilingual عند إنشاء مشروع أو تحديد zh-CN (English bilingual) الإعدادات المحلية لبيانات مجموعة التدريب عبر REST API.
في مجموعة التدريب السياقية، قم بتضمين ما لا يقل عن 100 جملة أو 10 دقائق من محتوى اللغة الإنجليزية ولا تتجاوز كمية المحتوى الصيني.
يوضح الجدول التالي الاختلافات بين الشبكات المحلية:
| إعدادات Speech Studio المحلية | إعدادات REST API المحلية | دعم ثنائي اللغة |
|---|---|---|
Chinese (Mandarin, Simplified) |
zh-CN |
إذا كانت بيانات العينة الخاصة بك تتضمن اللغة الإنجليزية، فإن الصوت المركب يتحدث الإنجليزية بلكنة أصلية إنجليزية، بدلا من نفس لهجة بيانات العينة، بغض النظر عن كمية البيانات الإنجليزية. |
Chinese (Mandarin, Simplified), English bilingual |
zh-CN (English bilingual) |
إذا كنت تريد أن يتحدث الصوت المركب اللغة الإنجليزية بنفس تشكيلة بيانات العينة، نوصي بتضمين أكثر من 10% بيانات اللغة الإنجليزية في مجموعة التدريب الخاصة بك. وإلا، فقد لا تكون لهجة اللغة الإنجليزية مثالية. |
Chinese (Cantonese, Simplified) |
zh-HK |
إذا كنت ترغب في تدريب صوت مركب قادر على التحدث باللغة الإنجليزية بنفس تشكيلة بيانات العينة الخاصة بك، فتأكد من توفير أكثر من 10% بيانات اللغة الإنجليزية في مجموعة التدريب الخاصة بك. وإلا، تعيينه افتراضيا إلى لهجة أصلية إنجليزية. يتم حساب عتبة 10% استنادا إلى البيانات المقبولة بعد التحميل الناجح، وليس البيانات قبل التحميل. إذا تم رفض بعض البيانات الإنجليزية التي تم تحميلها بسبب عيوب ولا تفي بالحد 10%، يتم تعيين الصوت المركب افتراضيا إلى لهجة أصلية إنجليزية. |
Chinese (Taiwanese Mandarin, Traditional) |
zh-TW |
إذا كنت ترغب في تدريب صوت مركب قادر على التحدث باللغة الإنجليزية بنفس تشكيلة بيانات العينة الخاصة بك، فتأكد من توفير أكثر من 10% بيانات اللغة الإنجليزية في مجموعة التدريب الخاصة بك. وإلا، تعيينه افتراضيا إلى لهجة أصلية إنجليزية. يتم حساب عتبة 10% استنادا إلى البيانات المقبولة بعد التحميل الناجح، وليس البيانات قبل التحميل. إذا تم رفض بعض البيانات الإنجليزية التي تم تحميلها بسبب عيوب ولا تفي بالحد 10%، يتم تعيين الصوت المركب افتراضيا إلى لهجة أصلية إنجليزية. |
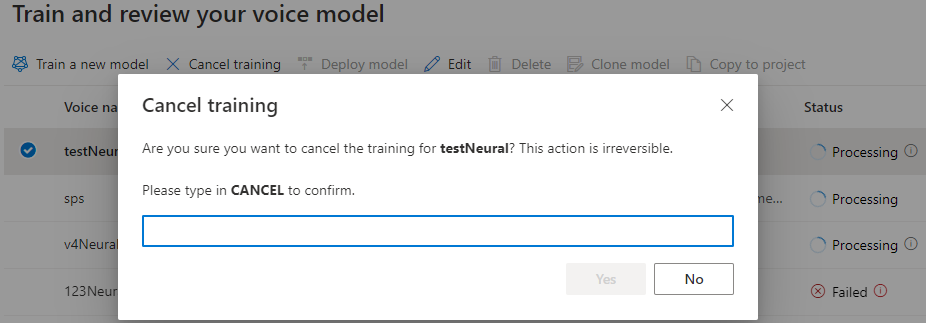
مراقبة عملية التدريب
يعرض جدول نموذج التدريب إدخالا جديدا يتوافق مع هذا النموذج الذي تم إنشاؤه حديثا. تعكس الحالة عملية تحويل بياناتك إلى نموذج صوتي، كما هو موضح في هذا الجدول:
| الولاية | المعنى |
|---|---|
| قيد المعالجة | يتم إنشاء نموذج الصوت الخاص بك. |
| نجح | تم إنشاء نموذج الصوت الخاص بك ويمكن نشره. |
| فشل | فشل نموذجك الصوتي في التدريب. قد يكون سبب الفشل، على سبيل المثال، مشاكل البيانات غير المرئية أو مشكلات الشبكة. |
| تم الإلغاء | تم إلغاء التدريب لنموذج الصوت الخاص بك. |
أثناء معالجة حالة النموذج، يمكنك تحديد إلغاء التدريب لإلغاء نموذجك الصوتي. لا يتم تحصيل رسوم منك مقابل هذا التدريب الذي تم إلغاؤه.
بعد الانتهاء من تدريب النموذج بنجاح، يمكنك مراجعة تفاصيل النموذج واختبار نموذج الصوت الخاص بك.
يمكنك استخدام أداة إنشاء محتوى الصوت في Speech Studio لإنشاء صوت وضبط صوتك المنشور. إذا كان ذلك ممكنا على صوتك، يمكنك تحديد أحد الأنماط المتعددة.
إعادة تسمية النموذج الخاص بك
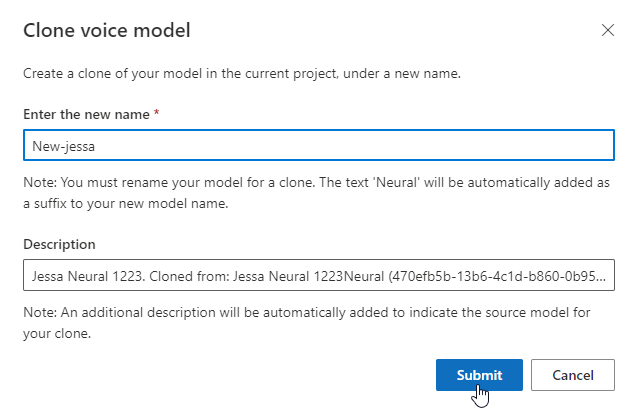
إذا كنت ترغب في إعادة تسمية النموذج الذي أنشأته، فحدد استنساخ نموذج لإنشاء نسخة من النموذج باسم جديد في المشروع الحالي.
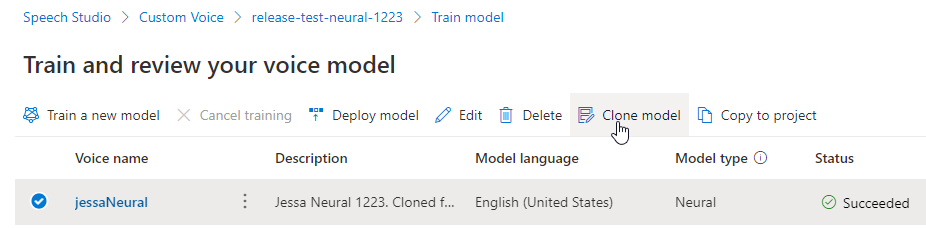
أدخل الاسم الجديد في نافذة Clone voice model ، ثم حدد Submit. تتم إضافة النص العصبي تلقائيا كلاحقة إلى اسم النموذج الجديد.
اختبار نموذج الصوت الخاص بك
بعد إنشاء نموذج الصوت بنجاح، يمكنك استخدام نموذج ملفات الصوت التي تم إنشاؤها لاختباره قبل نشره.
مُلاحَظةٌ
العصبية - متعددة اللغات (معاينة)والعصبية - HD الصوت (معاينة) لا تدعم هذا النوع من الاختبارات.
تعتمد جودة الصوت على العديد من العوامل، مثل:
- حجم بيانات التدريب.
- جودة التسجيل.
- دقة ملف النسخة المكتوبة.
- مدى تطابق الصوت المسجل في بيانات التدريب مع شخصية الصوت المصمم لحالة الاستخدام المقصودة.
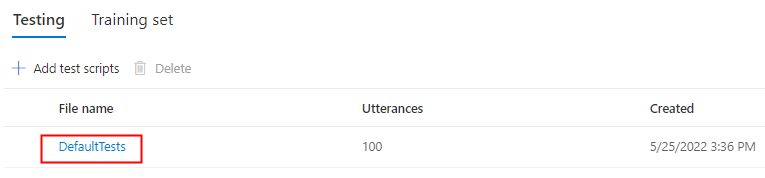
حدد DefaultTests ضمن Testing للاستماع إلى ملفات الصوت النموذجية. تتضمن نماذج الاختبار الافتراضية 100 عينة من ملفات الصوت التي تم إنشاؤها تلقائيا أثناء التدريب لمساعدتك في اختبار النموذج. بالإضافة إلى هذه الملفات الصوتية ال 100 المقدمة بشكل افتراضي، تتم أيضا إضافة تعبيرات البرنامج النصي للاختبار الخاص بك إلى مجموعة DefaultTests . هذه الإضافة هي على الأكثر 100 كلمة. لا يتم تحصيل رسوم منك مقابل الاختبار باستخدام DefaultTests.
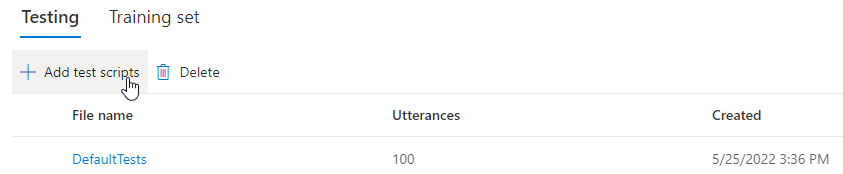
إذا كنت ترغب في تحميل البرامج النصية للاختبار الخاصة بك لاختبار النموذج الخاص بك بشكل أكبر، فحدد إضافة برامج نصية للاختبار لتحميل البرنامج النصي للاختبار الخاص بك.
قبل تحميل البرنامج النصي للاختبار، تحقق من متطلبات البرنامج النصي للاختبار. يتم تحصيل رسوم منك مقابل الاختبار الإضافي باستخدام تركيب الدفعة استنادا إلى عدد الأحرف القابلة للفوترة. راجع أسعار Azure الذكاء الاصطناعي Speech.
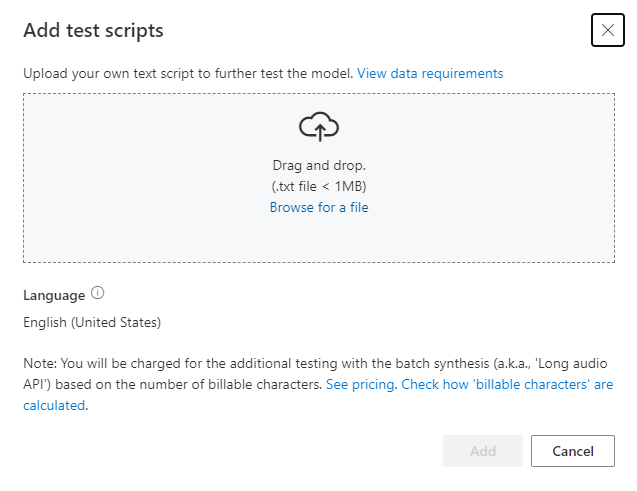
ضمن Add test scripts، حدد Browse for a file لتحديد البرنامج النصي الخاص بك، ثم حدد Add لتحميله.
اختبار متطلبات البرنامج النصي
يجب أن يكون البرنامج النصي للاختبار ملف .txt أقل من 1 ميغابايت. تتضمن تنسيقات الترميز المدعومة ANSI/ASCII أو UTF-8 أو UTF-8-BOM أو UTF-16-LE أو UTF-16-BE.
على عكس ملفات كتابة التدريب، يجب أن يستبعد البرنامج النصي الاختبار معرف التعبير، وهو اسم الملف لكل تعبير. وإلا، يتم التحدث بهذه المعرفات.
فيما يلي مثال لمجموعة من التعبيرات في ملف .txt واحد:
This is the waistline, and it's falling.
We have trouble scoring.
It was Janet Maslin.
ينتج عن كل فقرة من التعبير صوت منفصل. إذا كنت تريد دمج كل الجمل في صوت واحد، فاجعلها فقرة واحدة.
مُلاحَظةٌ
تعد الملفات الصوتية التي تم إنشاؤها مزيجا من البرامج النصية للاختبار التلقائي والبرامج النصية المخصصة للاختبار.
تحديث إصدار المحرك لنموذج الصوت الخاص بك
يتم تحديث نص Azure إلى محركات الكلام من وقت لآخر لالتقاط أحدث نموذج لغة يحدد نطق اللغة. بعد تدريب صوتك، يمكنك تطبيق صوتك على نموذج اللغة الجديد عن طريق التحديث إلى أحدث إصدار من المحرك.
عندما يتوفر محرك جديد، تتم مطالبتك بتحديث نموذج الصوت العصبي.

انتقل إلى صفحة تفاصيل النموذج واتبع الإرشادات التي تظهر على الشاشة لتثبيت أحدث محرك.
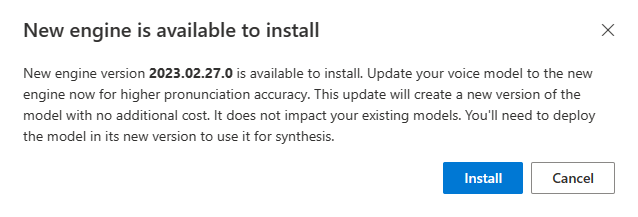
بدلا من ذلك، حدد تثبيت أحدث محرك لاحقا لتحديث الطراز الخاص بك إلى أحدث إصدار من المحرك.
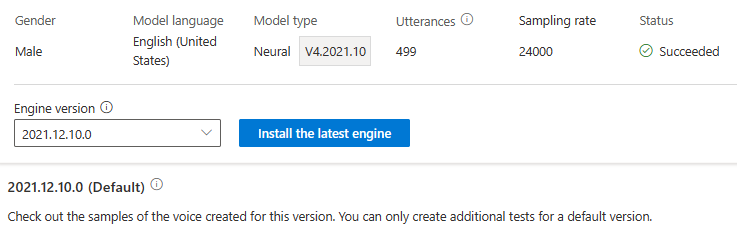
لا يتم تحصيل رسوم منك مقابل تحديث المحرك. لا يزال يتم الاحتفاظ بالإصدارات السابقة.
يمكنك التحقق من جميع إصدارات المحرك للنموذج من قائمة إصدار المحرك ، أو إزالة إصدار إذا لم تعد بحاجة إليه.
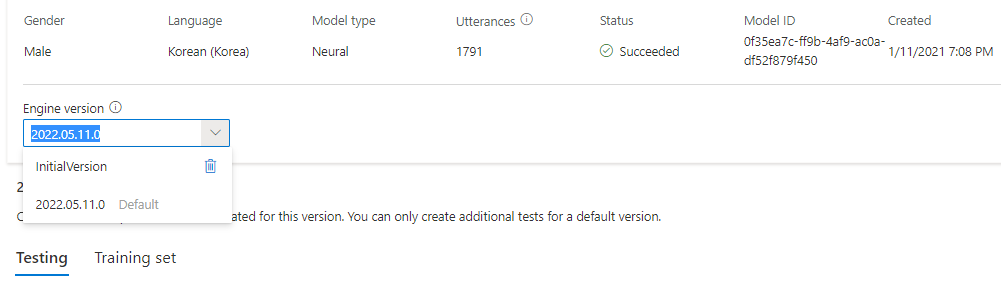
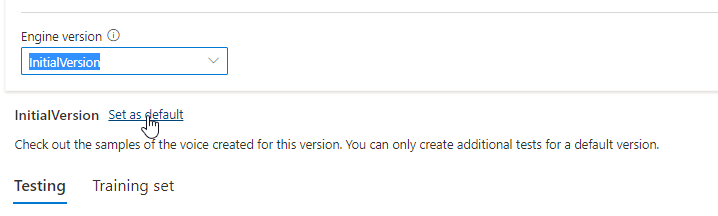
يتم تعيين الإصدار المحدث تلقائيا كافتراضي. ولكن يمكنك تغيير الإصدار الافتراضي عن طريق تحديد إصدار من القائمة المنسدلة وتحديد تعيين كافتراضي.

إذا كنت ترغب في اختبار كل إصدار محرك من طراز الصوت الخاص بك، يمكنك تحديد إصدار من القائمة، ثم تحديد DefaultTests ضمن Testing للاستماع إلى نموذج ملفات الصوت. إذا كنت ترغب في تحميل البرامج النصية للاختبار الخاصة بك لاختبار إصدار المحرك الحالي، فتأكد أولا من تعيين الإصدار كافتراضي، ثم اتبع الخطوات الواردة في اختبار نموذج الصوت الخاص بك.
يؤدي تحديث المحرك إلى إنشاء إصدار جديد من النموذج دون أي تكلفة إضافية. بعد تحديث إصدار المحرك لنموذج الصوت الخاص بك، تحتاج إلى نشر الإصدار الجديد لإنشاء نقطة نهاية جديدة. يمكنك نشر الإصدار الافتراضي فقط.
بعد إنشاء نقطة نهاية جديدة، تحتاج إلى نقل نسبة استخدام الشبكة إلى نقطة النهاية الجديدة في منتجك.
لمعرفة المزيد حول قدرات وحدود هذه الميزة، وأفضل الممارسات لتحسين جودة النموذج الخاص بك، راجع خصائص وقيود استخدام الصوت المخصص.
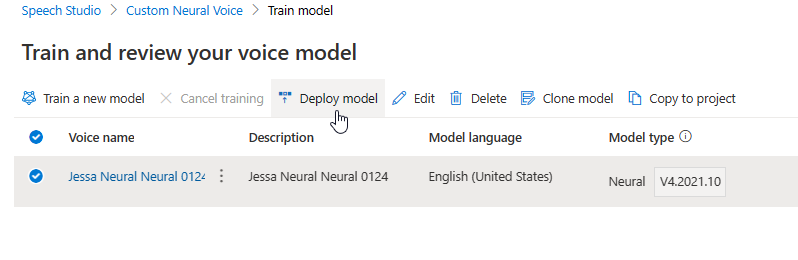
نسخ نموذج الصوت إلى مشروع آخر
يمكنك نسخ نموذج الصوت الخاص بك إلى مشروع آخر لنفس المنطقة أو منطقة أخرى. على سبيل المثال، يمكنك نسخ نموذج صوت عصبي تم تدريبه في منطقة واحدة، إلى مشروع لمنطقة أخرى.
مُلاحَظةٌ
لا يتوفر ضبط الصوت الاحترافي حاليا إلا في بعض المناطق. يمكنك نسخ نموذج صوت عصبي من تلك المناطق إلى مناطق أخرى. لمزيد من المعلومات، راجع المناطق المخصصة للصوت.
لنسخ نموذج الصوت المخصص إلى مشروع آخر:
في علامة التبويب Train model ، حدد نموذجا صوتيا تريد نسخه، ثم حدد Copy to project.
حدد الاشتراكوالمنطقةومورد الكلاموالمشروع حيث تريد نسخ النموذج. يجب أن يكون لديك مورد الكلام ومشروع في المنطقة المستهدفة، وإلا فأنت بحاجة إلى إنشائها أولا.
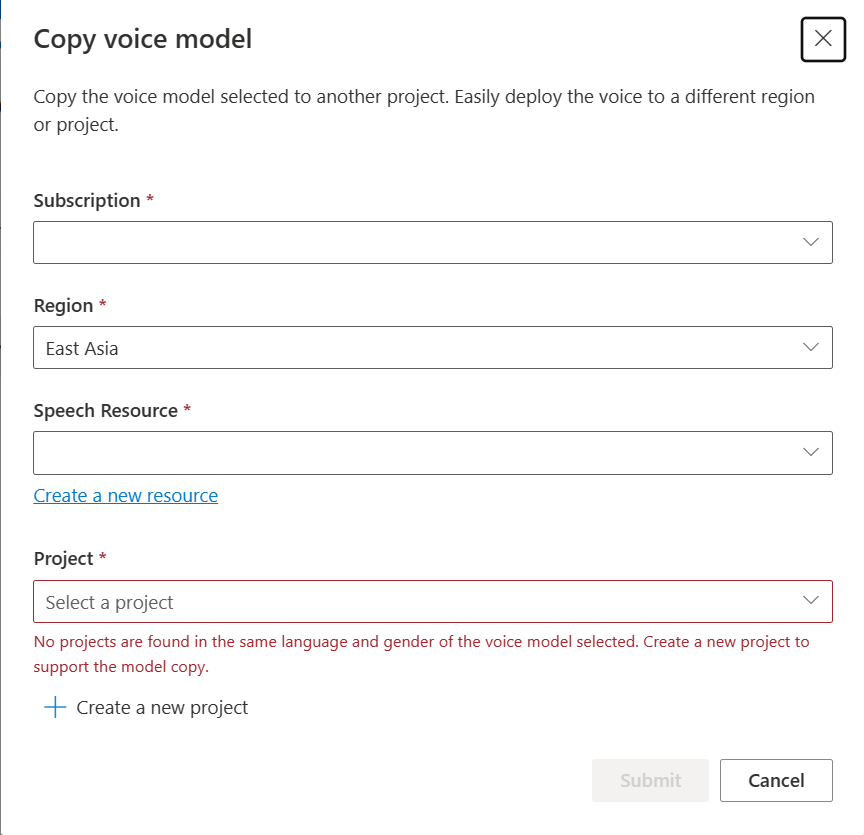
حدد إرسال لنسخ النموذج.
حدد عرض النموذج ضمن رسالة الإعلام للنسخ الناجح.
انتقل إلى المشروع حيث قمت بنسخ النموذج لنشر نسخة النموذج.
الخطوات التَالية
في هذه المقالة، ستتعلم كيفية ضبط صوت احترافي من خلال واجهة برمجة تطبيقات الصوت المخصصة.
مهم
لا يتوفر ضبط الصوت الاحترافي حاليا إلا في بعض المناطق. بعد تدريب نموذجك الصوتي في منطقة مدعومة، يمكنك نسخه إلى مورد الذكاء الاصطناعي Foundry في منطقة أخرى حسب الحاجة. لمزيد من المعلومات، راجع الحواشي السفلية في جدول خدمة الكلام.
تختلف مدة التدريب حسب كمية البيانات التي تستخدمها. يستغرق الأمر حوالي 40 ساعة حساب في المتوسط لضبط صوت احترافي. يمكن لمستخدمي الاشتراك القياسي (S0) تدريب أربعة أصوات في وقت واحد. إذا وصلت إلى الحد الأقصى، فانتظر حتى ينتهي أحد النماذج الصوتية على الأقل من التدريب، ثم حاول مرة أخرى.
مُلاحَظةٌ
على الرغم من أن إجمالي عدد الساعات المطلوبة لكل طريقة تدريب يختلف، فإن سعر الوحدة نفسه ينطبق على كل منها. لمزيد من المعلومات، راجع تفاصيل تسعير التدريب العصبي المخصص.
اختيار أسلوب تدريب
بعد التحقق من صحة ملفات البيانات، استخدمها لإنشاء نموذج صوت مخصص. عند إنشاء صوت مخصص، يمكنك اختيار تدريبه باستخدام إحدى الطرق التالية:
العصبية: إنشاء صوت بنفس لغة بيانات التدريب الخاصة بك.
العصبية - عبر اللغات: إنشاء صوت يتحدث لغة مختلفة عن بيانات التدريب الخاصة بك. على سبيل المثال، باستخدام
fr-FRبيانات التدريب، يمكنك إنشاء صوت يتحدثen-US.يجب أن تكون لغة بيانات التدريب واللغة المستهدفة إحدى اللغات المدعومة للتدريب الصوتي عبر اللغات. لا تحتاج إلى إعداد بيانات التدريب باللغة الهدف، ولكن يجب أن يكون البرنامج النصي للاختبار باللغة الهدف.
العصبية - متعددة الأنماط: إنشاء صوت مخصص يتحدث بأنماط وعواطف متعددة، دون إضافة بيانات تدريب جديدة. تعد أصوات الأنماط المتعددة مفيدة لأحرف ألعاب الفيديو روبوتات المحادثة والكتب الصوتية وقارئات المحتوى والمزيد.
لإنشاء صوت متعدد الأنماط، تحتاج إلى إعداد مجموعة من بيانات التدريب العامة، على الأقل 300 كلمة. حدد نمطا واحدا أو أكثر من أنماط التحدث المستهدفة المحددة مسبقا. يمكنك أيضا إنشاء أنماط مخصصة متعددة من خلال توفير نماذج أنماط، من 100 تعبير على الأقل لكل نمط، كبيانات تدريب إضافية لنفس الصوت. تختلف أنماط الإعداد المسبق المدعومة وفقا للغات مختلفة. اطلع على أنماط الإعداد المسبق المتوفرة عبر لغات مختلفة.
- العصبية - صوت عالي الدقة (معاينة): إنشاء صوت عالي الدقة بنفس لغة بيانات التدريب الخاصة بك. تستند أصوات Azure العصبية عالية الدقة إلى LLM، ومحسنة للمحادثات الديناميكية. تعرف على المزيد حول الأصوات العصبية عالية الدقة هنا.
يجب أن تكون لغة بيانات التدريب إحدى اللغات المدعومة للصوت المخصص أو اللغات التبادلية أو متعددة الأنماط أو التدريب الصوتي عالي الجودة.
إنشاء نموذج صوتي
- عصبي
- العصبية - اللغات المتقاطعة
- العصبية - نمط متعدد
- العصبية - متعددة اللغات (معاينة)
- العصبية - صوت عالي الدقة (معاينة)
لإنشاء صوت عصبي، استخدم عملية Models_Create لواجهة برمجة تطبيقات الصوت المخصصة. إنشاء نص الطلب وفقًا للإرشادات التالية:
- عيّن الخاصية
projectIdالمطلوبة. راجع إنشاء مشروع. - عيّن الخاصية
consentIdالمطلوبة. راجع إضافة موافقة المواهب الصوتية. - عيّن الخاصية
trainingSetIdالمطلوبة. راجع إنشاء مجموعة تدريب. - قم بتعيين خاصية الوصفة
kindالمطلوبة إلىDefaultللتدريب الصوتي العصبي. يشير نوع الوصفة إلى أسلوب التدريب ولا يمكن تغييره لاحقا. لاستخدام طريقة تدريب مختلفة، راجع العصبية - اللغات التبادلية أو العصبية - أنماط متعددة أو عصبية - صوت عالي الدقة (معاينة). راجع التدريب ثنائي اللغة لمزيد من المعلومات حول التدريب ثنائي اللغة والاختلافات بين اللغات. - عيّن الخاصية
voiceNameالمطلوبة. اختر الاسم بعناية. يتم استخدام اسم الصوت في طلب تركيب الكلام بواسطة إدخال SDK وSSML. يسمح بالأحرف والأرقام وبعض أحرف الترقيم فقط. استخدم أسماء مختلفة لنماذج صوتية عصبية مختلفة. - اختياريا، قم بتعيين الخاصية
descriptionللوصف الصوتي. يمكن تغيير الوصف الصوتي لاحقا.
قم بإجراء طلب HTTP PUT باستخدام URI كما هو موضح في المثال Models_Create التالي.
- استبدل
YourResourceKeyبمفتاح مورد Speech. - استبدل
YourResourceRegionبمنطقة مورد Speech. - استبدل
JessicaModelIdبمعرف نموذج من اختيارك. سيتم استخدام المعرف الحساس لحالة الأحرف في URI الخاص بالنموذج ولا يمكن تغييره لاحقا.
curl -v -X PUT -H "Ocp-Apim-Subscription-Key: YourResourceKey" -H "Content-Type: application/json" -d '{
"voiceName": "JessicaNeural",
"description": "Jessica voice",
"recipe": {
"kind": "Default"
},
"projectId": "ProjectId",
"consentId": "JessicaConsentId",
"trainingSetId": "JessicaTrainingSetId"
} ' "https://YourResourceRegion.api.cognitive.microsoft.com/customvoice/models/JessicaModelId?api-version=2024-02-01-preview"
يجب أن تتلقى نص الاستجابة بالتنسيق التالي:
{
"id": "JessicaModelId",
"voiceName": "JessicaNeural",
"description": "Jessica voice",
"recipe": {
"kind": "Default",
"version": "V10.0"
},
"projectId": "ProjectId",
"consentId": "JessicaConsentId",
"trainingSetId": "JessicaTrainingSetId",
"locale": "en-US",
"engineVersion": "2023.07.04.0",
"status": "NotStarted",
"createdDateTime": "2023-04-01T05:30:00.000Z",
"lastActionDateTime": "2023-04-02T10:15:30.000Z"
}
تدريب ثنائي اللغة
إذا حددت نوع التدريب العصبي ، يمكنك تدريب صوت على التحدث بلغات متعددة.
zh-CN
zh-HKتدعم و و zh-TW المحلية التدريب ثنائي اللغة للصوت للتحدث باللغتين الصينية والإنجليزية. اعتمادا جزئيا على بيانات التدريب الخاصة بك، يمكن للصوت المركب التحدث باللغة الإنجليزية بلكنة إنجليزية أصلية أو الإنجليزية بنفس لهجة بيانات التدريب.
مُلاحَظةٌ
لتمكين صوت في zh-CN الإعدادات المحلية من التحدث باللغة الإنجليزية بنفس تشكيلة البيانات النموذجية، يجب تحميل البيانات الإنجليزية إلى مجموعة تدريب سياقية ، أو اختيار Chinese (Mandarin, Simplified), English bilingual عند إنشاء مشروع أو تحديد zh-CN (English bilingual) الإعدادات المحلية لبيانات مجموعة التدريب عبر REST API.
في مجموعة التدريب السياقية، قم بتضمين ما لا يقل عن 100 جملة أو 10 دقائق من محتوى اللغة الإنجليزية ولا تتجاوز كمية المحتوى الصيني.
يوضح الجدول التالي الاختلافات بين الشبكات المحلية:
| إعدادات Speech Studio المحلية | إعدادات REST API المحلية | دعم ثنائي اللغة |
|---|---|---|
Chinese (Mandarin, Simplified) |
zh-CN |
إذا كانت بيانات العينة الخاصة بك تتضمن اللغة الإنجليزية، فإن الصوت المركب يتحدث الإنجليزية بلكنة أصلية إنجليزية، بدلا من نفس لهجة بيانات العينة، بغض النظر عن كمية البيانات الإنجليزية. |
Chinese (Mandarin, Simplified), English bilingual |
zh-CN (English bilingual) |
إذا كنت تريد أن يتحدث الصوت المركب اللغة الإنجليزية بنفس تشكيلة بيانات العينة، نوصي بتضمين أكثر من 10% بيانات اللغة الإنجليزية في مجموعة التدريب الخاصة بك. وإلا، فقد لا تكون لهجة اللغة الإنجليزية مثالية. |
Chinese (Cantonese, Simplified) |
zh-HK |
إذا كنت ترغب في تدريب صوت مركب قادر على التحدث باللغة الإنجليزية بنفس تشكيلة بيانات العينة الخاصة بك، فتأكد من توفير أكثر من 10% بيانات اللغة الإنجليزية في مجموعة التدريب الخاصة بك. وإلا، تعيينه افتراضيا إلى لهجة أصلية إنجليزية. يتم حساب عتبة 10% استنادا إلى البيانات المقبولة بعد التحميل الناجح، وليس البيانات قبل التحميل. إذا تم رفض بعض البيانات الإنجليزية التي تم تحميلها بسبب عيوب ولا تفي بالحد 10%، يتم تعيين الصوت المركب افتراضيا إلى لهجة أصلية إنجليزية. |
Chinese (Taiwanese Mandarin, Traditional) |
zh-TW |
إذا كنت ترغب في تدريب صوت مركب قادر على التحدث باللغة الإنجليزية بنفس تشكيلة بيانات العينة الخاصة بك، فتأكد من توفير أكثر من 10% بيانات اللغة الإنجليزية في مجموعة التدريب الخاصة بك. وإلا، تعيينه افتراضيا إلى لهجة أصلية إنجليزية. يتم حساب عتبة 10% استنادا إلى البيانات المقبولة بعد التحميل الناجح، وليس البيانات قبل التحميل. إذا تم رفض بعض البيانات الإنجليزية التي تم تحميلها بسبب عيوب ولا تفي بالحد 10%، يتم تعيين الصوت المركب افتراضيا إلى لهجة أصلية إنجليزية. |
أنماط الإعداد المسبق المتوفرة عبر لغات مختلفة
يلخص الجدول التالي أنماط الإعداد المسبق المختلفة وفقا للغات مختلفة.
| نمط التحدث | اللغة (اللغة المحلية) |
|---|---|
| غاضب | الإنجليزية (الولايات المتحدة) (en-US)اليابانية (اليابان) ( ja-JP) 1الصينية (الماندارين، المبسطة) ( zh-CN) 1 |
| هادئ | الصينية (الماندارين، المبسطة) (zh-CN) 1 |
| ثَرْثَرَ | الصينية (الماندارين، المبسطة) (zh-CN) 1 |
| البهجه | الإنجليزية (الولايات المتحدة) (en-US)اليابانية (اليابان) ( ja-JP) 1الصينية (الماندارين، المبسطة) ( zh-CN) 1 |
| الساخطين | الصينية (الماندارين، المبسطة) (zh-CN) 1 |
| متحمس | الإنجليزية (الولايات المتحدة) (en-US) |
| خائف | الصينية (الماندارين، المبسطة) (zh-CN) 1 |
| ودي | الإنجليزية (الولايات المتحدة) (en-US) |
| الامل | الإنجليزية (الولايات المتحدة) (en-US) |
| حزين | الإنجليزية (الولايات المتحدة) (en-US)اليابانية (اليابان) ( ja-JP) 1الصينية (الماندارين، المبسطة) ( zh-CN) 1 |
| هاتف | الإنجليزية (الولايات المتحدة) (en-US) |
| جاد | الصينية (الماندارين، المبسطة) (zh-CN) 1 |
| الرعب | الإنجليزية (الولايات المتحدة) (en-US) |
| وديه | الإنجليزية (الولايات المتحدة) (en-US) |
| يهمس | الإنجليزية (الولايات المتحدة) (en-US) |
1 يتوفر نمط الصوت العصبي في المعاينة العامة. تتوفر الأنماط في المعاينة العامة فقط في مناطق الخدمة هذه: شرق الولايات المتحدة وغرب أوروبا وجنوب شرق آسيا.
الحصول على حالة التدريب
للحصول على حالة التدريب لنموذج صوتي، استخدم Models_Get تشغيل واجهة برمجة التطبيقات الصوتية المخصصة. أنشئ عنوان URI للطلب وفقا للإرشادات التالية:
قم بإجراء طلب HTTP GET باستخدام URI كما هو موضح في المثال Models_Get التالي.
- استبدل
YourResourceKeyبمفتاح مورد Speech. - استبدل
YourResourceRegionبمنطقة مورد Speech. - استبدل
JessicaModelIdإذا قمت بتحديد معرف نموذج مختلف في الخطوة السابقة.
curl -v -X GET "https://YourResourceRegion.api.cognitive.microsoft.com/customvoice/models/JessicaModelId?api-version=2024-02-01-preview" -H "Ocp-Apim-Subscription-Key: YourResourceKey"
يجب أن تتلقى نص استجابة بالتنسيق التالي.
مُلاحَظةٌ
تعتمد الوصفة kind والخصائص الأخرى على كيفية تدريب الصوت. في هذا المثال، نوع الوصفة هو Default للتدريب الصوتي العصبي.
{
"id": "JessicaModelId",
"voiceName": "JessicaNeural",
"description": "Jessica voice",
"recipe": {
"kind": "Default",
"version": "V7.2023.03"
},
"projectId": "ProjectId",
"consentId": "JessicaConsentId",
"trainingSetId": "JessicaTrainingSetId",
"locale": "en-US",
"engineVersion": "2023.07.04.0",
"status": "Succeeded",
"createdDateTime": "2023-04-01T05:30:00.000Z",
"lastActionDateTime": "2023-04-02T10:15:30.000Z"
}
قد تحتاج إلى الانتظار لعدة دقائق قبل اكتمال التدريب. في النهاية ستتغير الحالة إلى أو SucceededFailed.