ملاحظة
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تسجيل الدخول أو تغيير الدلائل.
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تغيير الدلائل.
هام
سيتم إيقاف التعرف على المتحدث في Azure الذكاء الاصطناعي Speech في 30 سبتمبر 2025. لن تتمكن تطبيقاتك من استخدام التعرف على المتحدث بعد هذا التاريخ.
لا يؤثر هذا التغيير على قدرات Azure الذكاء الاصطناعي Speech الأخرى مثل تحويل الكلام إلى نص (بما في ذلك عدم تغيير يوميات المحاضر) والنص إلى كلاموترجمة الكلام.
يمكن أن يساعد التعرف على المتحدث في تحديد من يتحدث في مقطع صوتي. يمكن للخدمة التحقق من السماعات وتحديدها من خلال خصائصها الصوتية الفريدة، باستخدام القياسات الحيوية الصوتية.
يمكنك توفير بيانات التدريب الصوتي لمكبر صوت واحد، ما ينشئ ملف تعريف تسجيل استنادا إلى الخصائص الفريدة لصوت المتحدث. يمكنك بعد ذلك التحقق من عينات الصوت الصوتية مقابل ملف التعريف هذا للتحقق من أن المتحدث هو نفس الشخص (التحقق من المتحدث). يمكنك أيضا التحقق من عينات الصوت الصوتي مقابل مجموعة من ملفات تعريف السماعات المسجلة لمعرفة ما إذا كان يطابق أي ملف تعريف في المجموعة (تعريف المتحدث).
التحقق من المتحدث
يعمل التحقق من السماعة على تبسيط عملية التحقق من هوية المتحدث المسجلة إما باستخدام عبارات المرور أو إدخال صوت النموذج الحر. على سبيل المثال، يمكنك استخدامه للتحقق من هوية العميل في مراكز الاتصال أو الوصول إلى منشأة بدون تلامس.
كيف يعمل التحقق من المتحدث؟
يوفر المخطط الانسيابي التالي مرئية لكيفية عمل ذلك:
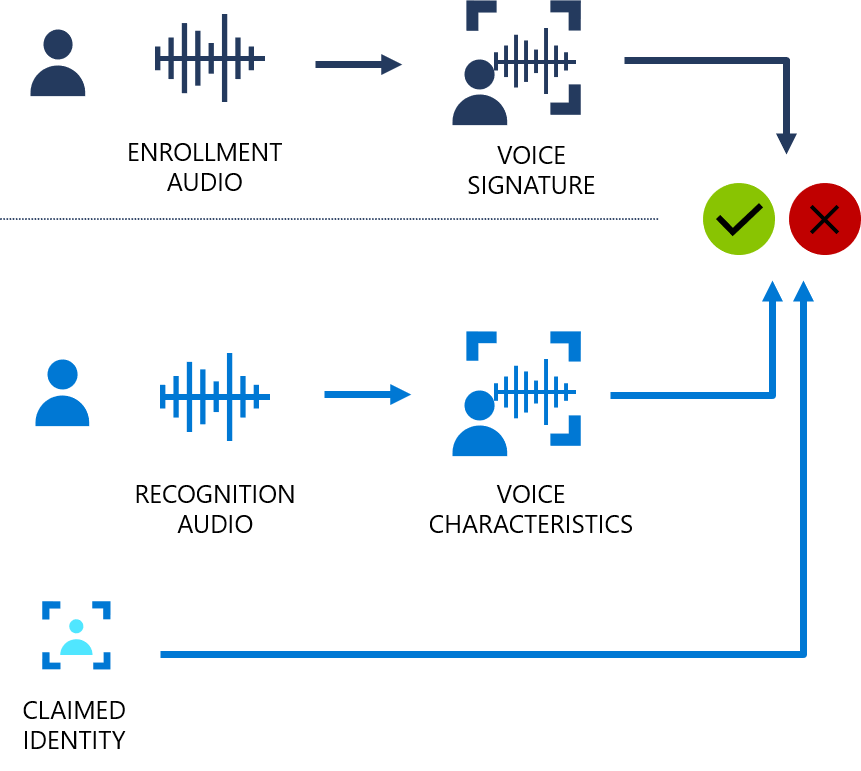
يمكن أن يكون التحقق من السماعة إما معتمدا على النص أو مستقلا عن النص. يعني التحقق المعتمد على النص أن المتحدثين بحاجة إلى اختيار نفس عبارة المرور لاستخدامها أثناء مرحلتي التسجيل والتحقق. يعني التحقق المستقل عن النص أنه يمكن للمتحدثين التحدث بلغة يومية في عبارات التسجيل والتحقق.
للتحقق المعتمد على النص، يتم تسجيل صوت المتحدث من خلال قول عبارة مرور من مجموعة من العبارات المعرفة مسبقا. يتم استخراج الميزات الصوتية من التسجيل الصوتي لتشكيل توقيع صوتي فريد، كما يتم التعرف على عبارة المرور المختارة. يتم استخدام توقيع الصوت وعبارة المرور معا للتحقق من السماعة.
لا توجد قيود على ما يقوله المتحدث أثناء التسجيل، بالإضافة إلى عبارة التنشيط الأولية عند تمكين التسجيل النشط. لا يحتوي على أي قيود على عينة الصوت التي سيتم التحقق منها، لأنه يستخرج الميزات الصوتية فقط لتسجيل التشابه.
لا تهدف واجهات برمجة التطبيقات إلى تحديد ما إذا كان الصوت من شخص مباشر، أو من تقليد أو تسجيل مكبر صوت مسجل.
تعريف المتحدث
يساعدك تعريف المتحدث على تحديد هوية متحدث غير معروف ضمن مجموعة من المتكلمين المسجلين. يتيح لك تعريف السماعة سمة الكلام إلى مكبرات الصوت الفردية، وإلغاء تأمين القيمة من السيناريوهات ذات السماعات المتعددة، مثل:
- دعم الحلول لإنتاجية الاجتماع عن بعد.
- إنشاء تخصيص أجهزة متعددة المستخدمين.
كيف يعمل تعريف المتحدث؟
التسجيل لتعريف المتحدث مستقل عن النص. لا توجد قيود على ما يقوله المتحدث في الصوت، بالإضافة إلى عبارة التنشيط الأولية عند تمكين التسجيل النشط. على غرار التحقق من المتحدث، يتم تسجيل صوت المتحدث في مرحلة التسجيل، ويتم استخراج الميزات الصوتية لتشكيل توقيع صوتي فريد. في مرحلة التعريف، تتم مقارنة عينة صوت الإدخال بقائمة محددة من الأصوات المسجلة (حتى 50 في كل طلب).
الخصوصية وأمان البيانات
يتم تخزين بيانات تسجيل المتحدث في نظام آمن، بما في ذلك صوت الكلام للتسجيل وميزات التوقيع الصوتي. يتم استخدام صوت الكلام للتسجيل فقط عند ترقية الخوارزمية، ويجب استخراج الميزات مرة أخرى. لا تحتفظ الخدمة بتسجيل الكلام أو الميزات الصوتية المستخرجة التي يتم إرسالها إلى الخدمة أثناء مرحلة التعرف.
يمكنك التحكم في المدة التي يجب الاحتفاظ بالبيانات فيها. يمكنك إنشاء بيانات التسجيل وتحديثها وحذفها لمكبرات الصوت الفردية من خلال استدعاءات واجهة برمجة التطبيقات. عند حذف مورد الكلام، يتم أيضا حذف جميع بيانات تسجيل المتحدث المقترنة بمورد الكلام.
كما هو الحال مع جميع موارد Azure الذكاء الاصطناعي Foundry، يجب أن يكون المطورون الذين يستخدمون ميزة التعرف على المتحدث على دراية بنهج Microsoft على بيانات العملاء. يجب عليك التأكد من تلقي الأذونات المناسبة من المستخدمين. يمكنك العثور على مزيد من التفاصيل في البيانات والخصوصية للتعرف على المتحدث. لمزيد من المعلومات، راجع صفحة خدمات azure الذكاء الاصطناعي في مركز توثيق Microsoft.
الأسئلة والحلول الشائعة
| السؤال | الحل |
|---|---|
| ما هي المواقف التي من المرجح أن أستخدم التعرف على المتحدث؟ | تتضمن الأمثلة الجيدة التحقق من عملاء مركز الاتصال، وتسجيل وصول المريض المستند إلى الصوت، وكتابة الاجتماعات، وتخصيص الأجهزة متعددة المستخدمين. |
| ما الفرق بين تحديد الهوية والتحقق؟ | التعريف هو عملية الكشف عن العضو من مجموعة من المتحدثين الذي يتحدث. التحقق هو إجراء للتأكد من أن مكبر الصوت يطابق صوتا معروفا ومسجلا . |
| ما اللغات المدعومة؟ | راجع دعم لغة التعرف على المتحدث. |
| ما هي مناطق Azure المدعومة؟ | راجع دعم منطقة التعرف على المتحدث. |
| ما هي تنسيقات الصوت المعتمدة؟ | Mono 16 bit, 16 kHz PCM-encoded WAV. |
| هل يمكنك تسجيل مكبر صوت واحد عدة مرات؟ | نعم، للتحقق المعتمد على النص، يمكنك تسجيل مكبر صوت حتى 50 مرة. للتحقق من صحة النص المستقل أو تعريف السماعة، يمكنك التسجيل مع ما يصل إلى 300 ثانية من الصوت. |
| ما هي البيانات المخزنة في Azure؟ | يتم تخزين صوت التسجيل في الخدمة حتى يتم حذف ملف التعريف الصوتي. لا يتم الاحتفاظ بعينات صوت التعرف أو تخزينها. |
الذكاء الاصطناعي المسؤول
لا يتضمن نظام الذكاء الاصطناعي التكنولوجيا فحسب، بل يشمل أيضا الأشخاص الذين يستخدمونها، والأشخاص المتأثرين بها، والبيئة التي يتم نشرها فيها. اقرأ ملاحظات الشفافية للتعرف على الذكاء الاصطناعي المسؤولة واستخدامها ونشرها في أنظمتك.