ملاحظة
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تسجيل الدخول أو تغيير الدلائل.
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تغيير الدلائل.
توفر خدمة الكلام قدرات تحويل الكلام إلى نص ونص إلى كلام مع مورد الكلام. يمكنك نسخ الكلام إلى نص بدقة عالية، وإنتاج نص طبيعي إلى أصوات الكلام، وترجمة الصوت المنطوق، واستخدام التعرف على السماعات أثناء المحادثات.

أنشئ أصواتا مخصصة، أو أضف كلمات معينة إلى المفردات الأساسية، أو أنشئ نماذجك الخاصة. قم بتشغيل Speech في أي مكان أو في السحابة أو على الحافة في حاويات. من السهل تمكين الكلام لتطبيقاتك وأدواتك وأجهزتك باستخدام Speech CLIوS speech SDKوواجهات برمجة تطبيقات REST.
يتوفر الكلام للعديد من اللغاتوالمناطقونقاط الأسعار.
سيناريوهات الكلام
تتضمن السيناريوهات الشائعة للكلام ما يلي:
- التسمية التوضيحية: تعرف على كيفية مزامنة التسميات التوضيحية مع صوت الإدخال، وتطبيق عوامل تصفية الألفاظ النابية، والحصول على نتائج جزئية، وتطبيق التخصيصات، وتحديد اللغات المنطوقة للسيناريوهات متعددة اللغات.
- إنشاء محتوى صوتي: يمكنك استخدام الأصوات العصبية لجعل التفاعلات مع روبوتات الدردشة والوكلاء الصوتيين أكثر طبيعية وجاذبية، وتحويل النصوص الرقمية مثل الكتب الإلكترونية إلى كتب صوتية وتحسين أنظمة التنقل داخل السيارة.
- مركز الاتصال: قم بنسخ المكالمات في الوقت الفعلي أو معالجة مجموعة من المكالمات، ونقاحة معلومات التعريف الشخصية، واستخراج رؤى مثل التوجه للمساعدة في حالة استخدام مركز الاتصال.
- تعلم اللغة: تقديم ملاحظات تقييم النطق لمتعلمي اللغة، ودعم النسخ في الوقت الحقيقي لمحادثات التعلم عن بعد، وقراءة المواد التعليمية بصوت عال مع الأصوات العصبية.
- الصوت المباشر: إنشاء واجهات طبيعية وبشرية مثل واجهات المحادثة للتطبيقات والتجارب. توفر الميزة الصوتية المباشرة تفاعلا سريعا وموثوقا بين تطبيق الإنسان والعامل.
تستخدم Microsoft Speech للعديد من السيناريوهات، مثل التسمية التوضيحية في Teams والإملاء في Office 365 والقراءة بصوت عال في مستعرض Microsoft Edge.
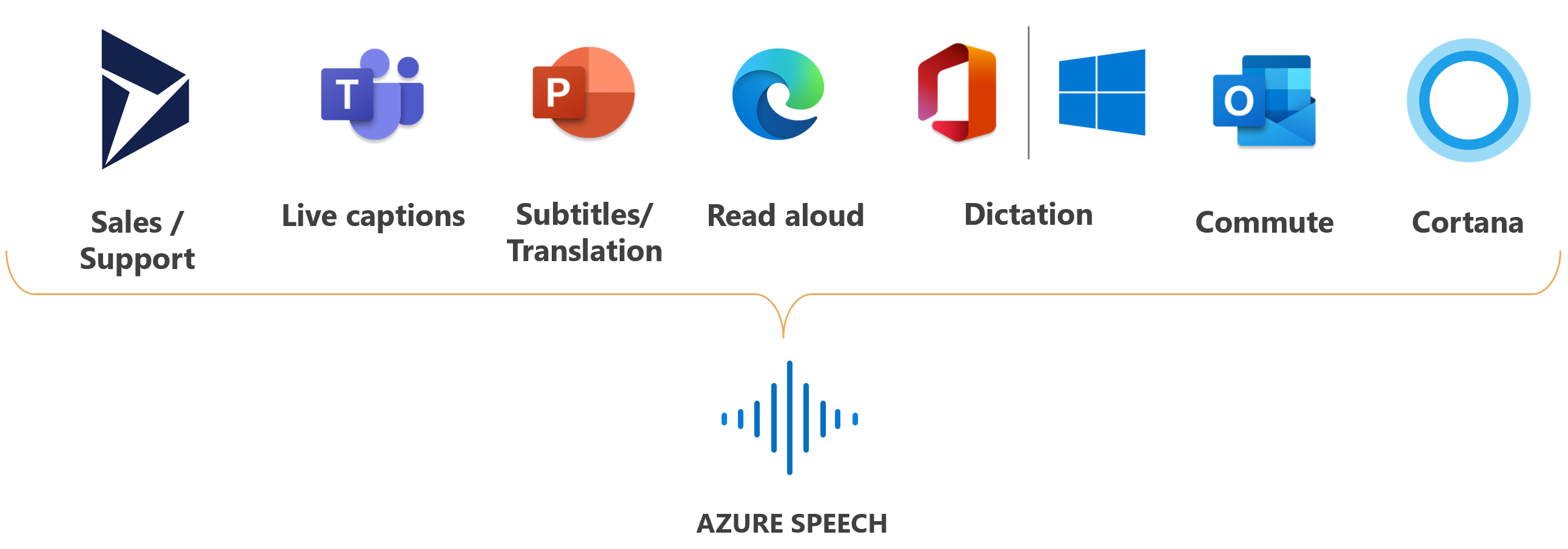
قدرات الكلام
تلخص هذه الأقسام ميزات الكلام مع ارتباطات للحصول على مزيد من المعلومات.
الكلام إلى النص
استخدم الكلام إلى نص لنسخ الصوت إلى نص، إما في الوقت الحقيقي أو بشكل غير متزامن مع النسخ الدفعي.
تلميح
يمكنك تجربة الكلام في الوقت الحقيقي إلى نص في Speech Studio دون الاشتراك أو كتابة أي تعليمة برمجية.
تحويل الصوت إلى نص من مجموعة من المصادر، بما في ذلك الميكروفونات والملفات الصوتية وتخزين الكائنات الثنائية كبيرة الحجم. استخدم يوميات المتحدث لتحديد من قال ماذا ومتى. احصل على نسخ قابلة للقراءة مع التنسيق التلقائي وعلامات الترقيم.
قد لا يكون النموذج الأساسي كافيا إذا كان الصوت يحتوي على ضوضاء محيطة أو يتضمن العديد من المصطلحات الخاصة بالصناعة والمجال. في هذه الحالات، يمكنك إنشاء نماذج كلام مخصصة وتدريبها باستخدام البيانات الصوتية واللغة والنطق. نماذج الكلام المخصصة خاصة ويمكن أن تقدم ميزة تنافسية.
تحويل الكلام إلى نص في الوقت الحقيقي
مع تحويل الكلام إلى نص في الوقت الحقيقي، يتم نسخ الصوت حيث يتم التعرف على الكلام من ميكروفون أو ملف. استخدم الكلام في الوقت الحقيقي إلى نص للتطبيقات التي تحتاج إلى نسخ الصوت في الوقت الفعلي مثل:
- النسخ أو التسميات التوضيحية أو الترجمة للاجتماعات المباشرة
- يوميات
- تقييم النطق
- مساعدة وكلاء مركز الاتصال
- الإملاء
- وكلاء الصوت
واجهة برمجة تطبيقات النسخ السريع
يتم استخدام واجهة برمجة تطبيقات النسخ السريع لنسخ الملفات الصوتية مع إرجاع النتائج بشكل متزامن وأسرع بكثير من الصوت في الوقت الحقيقي. استخدم النسخ السريع في السيناريوهات التي تحتاج فيها إلى نسخة تسجيل صوتي في أسرع وقت ممكن مع زمن انتقال يمكن التنبؤ به، مثل:
- النسخ السريع للصوت أو الفيديو والترجمة والتحرير.
- ترجمة الفيديو
للبدء في النسخ السريع، راجع استخدام واجهة برمجة تطبيقات النسخ السريع.
النسخ الدفعي
يتم استخدام النسخ الدفعي لنسخ كمية كبيرة من الصوت في التخزين. يمكنك الإشارة إلى ملفات الصوت مع URI توقيع الوصول المشترك (SAS) وتلقي نتائج الكتابة بشكل غير متزامن. استخدم النسخ الدفعي للتطبيقات التي تحتاج إلى نسخ الصوت بشكل مجمع مثل:
- النسخ أو التسميات التوضيحية أو الترجمة للصوت المسجل مسبقا
- تحليلات ما بعد المكالمة في مركز الاتصال
- يوميات
نص إلى كلام
مع تحويل النص إلى كلام، يمكنك تحويل نص الإدخال إلى نص بشري مثل الكلام المركب. استخدم الأصوات العصبية، وهي أصوات بشرية مثل الأصوات التي تعمل بالشبكات العصبية العميقة. استخدم لغة ترميز تركيب الكلام (SSML) لضبط درجة الصوت والنطق ومعدل التحدث ومستوى الصوت والمزيد.
- الصوت القياسي: أصوات طبيعية للغاية خارج الصندوق. تحقق من عينات الصوت القياسية في معرض الصوت وحدد الصوت المناسب لاحتياجات عملك.
- الصوت المخصص: إلى جانب الأصوات القياسية التي تخرج من الصندوق، يمكنك أيضا إنشاء صوت مخصص يمكن التعرف عليه وفريد من نوعه للعلامة التجارية أو المنتج الخاص بك. الأصوات المخصصة خاصة ويمكن أن تقدم ميزة تنافسية. تحقق من عينات الصوت المخصصة هنا.
ترجمة الكلام
تتيح ترجمة الكلام الترجمة متعددة اللغات في الوقت الحقيقي للكلام إلى تطبيقاتك وأدواتك وأجهزتك. استخدم هذه الميزة لترجمة الكلام إلى الكلام والكلام إلى نص.
تعريف اللغة
يتم استخدام تعريف اللغة لتحديد اللغات المنطوقة بالصوت عند مقارنتها بقائمة اللغات المدعومة. استخدم تعريف اللغة في حد ذاته، مع التعرف على الكلام إلى النص، أو مع ترجمة الكلام.
التعرف على المتحدث
يوفر التعرف على المتحدث خوارزميات تتحقق من السماعات وتحددها من خلال خصائصها الصوتية الفريدة. يتم استخدام التعرف على المتحدث للإجابة على السؤال، "من يتحدث؟".
تقييم النطق
تقييم النطق يقيم نطق الكلام ويعطي المتحدثين ملاحظات حول دقة وطلاقة الصوت المنطوق. من خلال تقييم النطق، يمكن لمتعلمي اللغة ممارسة التعليقات الفورية والحصول عليها وتحسين نطقهم حتى يتمكنوا من التحدث وتقديمها بثقة.
التعرف على الهدف
التعرف على الهدف: استخدم الكلام إلى نص مع فهم لغة المحادثة لاشتقاق أهداف المستخدم من الكلام المنسوخ والعمل على الأوامر الصوتية.
التسليم والحضور
يمكنك نشر ميزات Azure الذكاء الاصطناعي Speech في السحابة أو في الموقع.
باستخدام الحاويات، يمكنك جعل الخدمة أقرب إلى بياناتك لأسباب تتعلق بالتوافق أو الأمان أو لأسباب تشغيلية أخرى.
يتوفر نشر خدمة الكلام في السحب السيادية لبعض الكيانات الحكومية وشركائها. على سبيل المثال، تتوفر سحابة Azure Government للكيانات الحكومية الأمريكية وشركائها. يتوفر Microsoft Azure الذي تديره سحابة 21Vianet للمؤسسات ذات التواجد التجاري في الصين. لمزيد من المعلومات، راجع السحب السيادية.
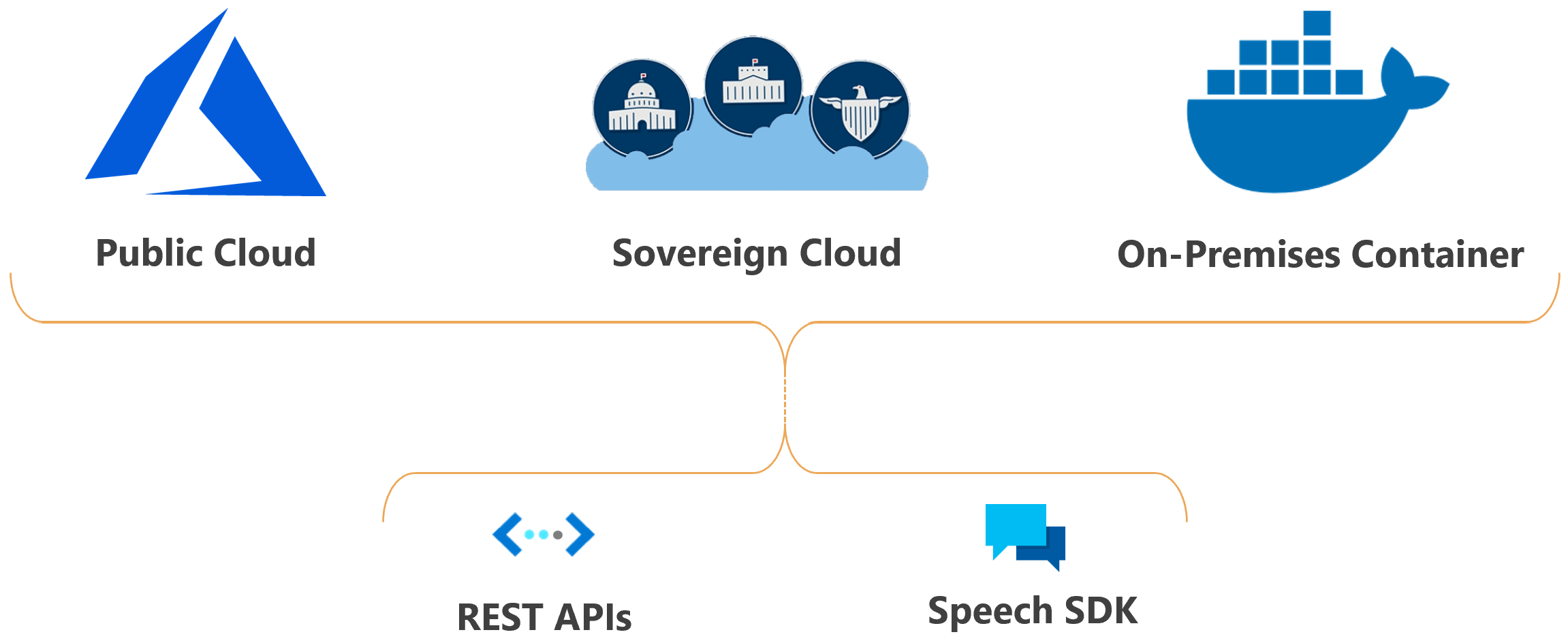
استخدام الكلام في التطبيق الخاص بك
يعد Speech Studio مجموعة من الأدوات المستندة إلى واجهة المستخدم لإنشاء الميزات ودمجها من خدمة Azure الذكاء الاصطناعي Speech في تطبيقاتك. يمكنك إنشاء مشاريع في Speech Studio باستخدام نهج بدون تعليمات برمجية، ثم الرجوع إلى هذه الأصول في تطبيقاتك باستخدام Speech SDK أو Speech CLI أو واجهات برمجة تطبيقات REST.
Speech CLI هو أداة سطر أوامر لاستخدام خدمة الكلام دون الحاجة إلى كتابة أي تعليمة برمجية. تتوفر معظم الميزات في Speech SDK في Speech CLI، ويتم تبسيط بعض الميزات والتخصيصات المتقدمة في Speech CLI.
يعرض Speech SDK العديد من قدرات خدمة الكلام التي يمكنك استخدامها لتطوير التطبيقات الممكنة للكلام. يتوفر Speech SDK في العديد من لغات البرمجة وعبر جميع الأنظمة الأساسية.
في بعض الحالات، لا يمكنك أو لا يجب عليك استخدام Speech SDK. في هذه الحالات، يمكنك استخدام واجهات برمجة تطبيقات REST للوصول إلى خدمة الكلام. على سبيل المثال، استخدم واجهات برمجة تطبيقات REST للنسخ الدفعي وواجهات برمجة تطبيقات REST للتعرف على المتحدث .
الشروع في العمل
نحن نقدم قوالب التشغيل السريع في العديد من لغات البرمجة الشائعة. تم تصميم كل بداية سريعة لتعليمك أنماط التصميم الأساسية وتشغيل التعليمات البرمجية في أقل من 10 دقائق. راجع القائمة التالية لبدء التشغيل السريع لكل ميزة:
- التشغيل السريع لتحويل الكلام إلى نص
- التشغيل السريع لتحويل النص إلى كلام
- التشغيل السريع لترجمة الكلام
نماذج التعليمات البرمجية
يتوفر نموذج التعليمات البرمجية لخدمة Speech على GitHub. تغطي هذه العينات السيناريوهات الشائعة مثل قراءة الصوت من ملف أو دفق، والتعرف المستمر والفردي، والعمل مع النماذج المخصصة. استخدم هذه الارتباطات لعرض نماذج SDK وREST:
- عينات تحويل الكلام إلى نص ونص إلى كلام وترجمة الكلام (SDK)
- عينات النسخ الدفعي (REST)
- نماذج تحويل النص إلى كلام (REST)
الذكاء الاصطناعي المسؤول
لا يتضمن نظام الذكاء الاصطناعي التكنولوجيا فحسب، بل يشمل أيضا الأشخاص الذين يستخدمونها، والأشخاص المتأثرين بها، والبيئة التي يتم نشرها فيها. اقرأ ملاحظات الشفافية للتعرف على الذكاء الاصطناعي المسؤولة واستخدامها ونشرها في أنظمتك.
الكلام إلى النص
تقييم النطق
صوت مخصص
- ملاحظة الشفافية وحالات الاستخدام
- الخصائص والقيود
- وصول محدود
- النشر المسؤول للكلام الاصطناعي
- الكشف عن المواهب الصوتية
- الكشف عن إرشادات التصميم
- الكشف عن أنماط التصميم
- قواعد السلوك
- خصوصية وأمان البيانات