ساعد هذا المشروع العميل شركة فورتشن 500 للأغذية على تحسين توقعاتها للطلب. تقوم الشركة بشحن المنتجات مباشرة إلى العديد من منافذ البيع بالتجزئة. وساعدهم هذا التحسن على تحسين تخزين منتجاتهم في متاجر مختلفة عبر عدة مناطق في الولايات المتحدة. لتحقيق ذلك، عمل فريق هندسة البرمجيات التجارية (CSE) من Microsoft مع علماء بيانات العميل على دراسة تجريبية لتطوير نماذج التعلم الآلي المخصصة للمناطق المحددة. تأخذ النماذج في الاعتبار:
- التركيبة السكانية للمتسوقين
- الطقس التاريخي والمتوقع
- الشحنات السابقة
- إرجاع المنتج
- أحداث هامة
يمثل الهدف من تحسين التخزين مكونا رئيسيا للمشروع، وأدرك العميل رفعا كبيرا للمبيعات في الإصدارات التجريبية الميدانية المبكرة. كما شهد الفريق انخفاضا بنسبة 40٪ في توقع متوسط خطأ النسبة المئوية المطلقة (MAPE) بالمقارنة مع نموذج الأساس المتوسط التاريخي.
وكان أحد الأجزاء الرئيسية للمشروع هو معرفة كيفية توسيع نطاق سير عمل علم البيانات من الدراسة التجريبية إلى مستوى الإنتاج. وتطلب سير العمل على مستوى الإنتاج قيام فريق CSE بالمهام التالية:
- تطوير نماذج لمناطق عديدة.
- تحديث ومراقبة أداء النماذج باستمرار.
- تسهيل التعاون بين فرق البيانات والهندسة.
سير عمل علم البيانات النموذجي اليوم أقرب إلى بيئة معملية لمرة واحدة من سير عمل الإنتاج. يجب أن تكون بيئة علماء البيانات مناسبة لهم من أجل:
- إعداد البيانات.
- تجربة نماذج مختلفة.
- ضبط المعلمات الفائقة.
- إنشاء دورة بناء-اختبار-تقييم-تحسين.
معظم الأدوات المستخدمة لهذه المهام لها أغراض محددة ولا تناسب الأتمتة بشكل جيد. في عملية التعلم الآلي على مستوى الإنتاج، يجب أن يكون هناك المزيد من الاعتبار لإدارة دورة حياة التطبيق وDevOps.
ساعد فريق CSE العميل على توسيع نطاق العملية إلى مستويات الإنتاج. نفذوا جوانب مختلفة من التكامل المستمر وقدرات التسليم المستمر (CI/CD) وعالجوا مشكلات مثل إمكانية المراقبة والتكامل مع قدرات Azure. خلال التنفيذ، كشف الفريق عن فجوات في إرشادات MLOps الحالية. وينبغي سد هذه الثغرات حتى يتسنى فهم عملية MLOps وتطبيقها على نطاق واسع.
يساعد فهم ممارسات MLOps المؤسسات على ضمان أن نماذج التعلم الآلي التي ينتجها النظام هي نماذج جودة الإنتاج التي تحسن أداء الأعمال. عند تنفيذ MLOps، لم يعد على المؤسسة قضاء الكثير من وقتها في التفاصيل منخفضة المستوى المتعلقة بالبنية التحتية والعمل الهندسي المطلوب لتطوير نماذج التعلم الآلي وتشغيلها لعمليات مستوى الإنتاج. يساعد تنفيذ MLOps أيضا مجتمعات علوم البيانات وهندسة البرمجيات على تعلم العمل معا لتقديم نظام جاهز للإنتاج.
استخدم فريق CSE هذا المشروع لتلبية احتياجات مجتمع التعلم الآلي من خلال معالجة مشكلات مثل تطوير نموذج نضج MLOps. تهدف هذه الجهود إلى تحسين اعتماد MLOps من خلال فهم التحديات النموذجية للاعبين الرئيسيين في عملية MLOps.
المشاركة والسيناريوهات التقنية
يناقش سيناريو المشاركة تحديات العالم الحقيقي التي كان على فريق CSE حلها. يحدد السيناريو التقني متطلبات إنشاء دورة حياة MLOps موثوق بها مثل دورة حياة DevOps الراسخة.
سيناريو تفاعل المستخدم
يُسلم العميل المنتجات مباشرة إلى منافذ سوق البيع بالتجزئة في مواعيد منتظمة. يختلف كل منفذ بيع بالتجزئة في أنماط استخدام المنتج، لذلك يجب أن يختلف مخزون المنتج في كل عملية تسليم أسبوعية. إن زيادة المبيعات وتقليل عائدات المنتج وفرص المبيعات المفقودة هي أهداف منهجيات التنبؤ بالطلب التي يستخدمها العميل. ركز هذا المشروع على استخدام التعلم الآلي لتحسين التنبؤات.
قام فريق CSE بتقسيم المشروع إلى مرحلتين. ركزت المرحلة الأولى على تطوير نماذج التعلم الآلي لدعم دراسة تجريبية ميدانية حول فعالية التنبؤ بالتعلم الآلي لمنطقة مبيعات مختارة. أدى نجاح المرحلة الأولى إلى المرحلة 2، حيث قام الفريق بتوسيع نطاق الدراسة التجريبية الأولية من مجموعة صغيرة من النماذج التي دعمت منطقة جغرافية واحدة إلى مجموعة من النماذج المستدامة على مستوى الإنتاج لجميع مناطق مبيعات العميل. وكان أحد الاعتبارات الرئيسية للحل المتدرج هو الحاجة إلى استيعاب العدد الكبير من المناطق الجغرافية ومنافذ البيع بالتجزئة المحلية. وقام الفريق بتخصيص نماذج التعلم الآلي لكل من منافذ التجزئة الكبيرة والصغيرة في كل منطقة.
حددت الدراسة التجريبية للمرحلة الأولى أن النموذج المخصص لمنافذ البيع بالتجزئة في منطقة واحدة يمكن أن يستخدم سجل المبيعات المحلي، والديمغرافيا المحلية، والطقس، والأحداث الخاصة لتحسين توقعات الطلب على المنافذ في المنطقة. قدمت أربعة نماذج للتنبؤ بالتعلم الآلي لمنافذ السوق في منطقة واحدة. قامت النماذج بمعالجة البيانات على دفعات أسبوعية. كما طور الفريق نموذجين أساسيين باستخدام البيانات السابقة لإجراء المقارنة.
بالنسبة للنسخة الأولى من حل المرحلة الثانية الموسع، اختار فريق CSE 14 منطقة جغرافية للمشاركة، بما في ذلك منافذ السوق الصغيرة والكبيرة. استخدموا أكثر من 50 نموذج تنبؤ بالتعلم الآلي. تنبأ الفريق حدوث نمو أكبر للنظام وإجراء تحسينات مستمرة لنماذج التعلم الآلي. أصبح من الواضح بسرعة أن حل التعلم الآلي هذا على نطاق أوسع مستدام فقط إذا كان يستند إلى مبادئ أفضل الممارسات ل DevOps لبيئة التعلم الآلي.
| البيئة | منطقة السوق | Format | النماذج | تقسيم النموذج | وصف النموذج |
|---|---|---|---|---|---|
| بيئة التطوير | كل سوق/منطقة جغرافية (على سبيل المثال شمال تكساس) | مخازن التنسيقات الكبيرة (محلات السوبر ماركت ومتاجر العلب الكبيرة وما إلى ذلك) | نموذجان للمجموعتين | منتجات ذات معدل دوران بطيء | يحتوي كل من البطيء والسريع على مجموعة من نموذج الانحدار الخطي لعامل التقليص والاختيار الأقل مطلقة (LASSO) وشبكة عصبية مع تضمينات فئوية |
| منتجات ذات معدل دوران عالي | يحتوي كل من البطيء والسريع على مجموعة من نموذج الانحدار الخطي LASSO وشبكة عصبية مع تضمينات فئوية | ||||
| نموذج واحد | غير متوفر | المتوسط التاريخي | |||
| مخازن التنسيقات الصغيرة (الصيدليات، المتاجر الملائمة، وما إلى ذلك) | نموذجان للمجموعتين | منتجات ذات معدل دوران بطيء | يحتوي كل من البطيء والسريع على مجموعة من نموذج الانحدار الخطي LASSO وشبكة عصبية مع تضمينات فئوية | ||
| منتجات ذات معدل دوران عالي | بطيء وكلاهما لديه مجموعة من نموذج الانحدار الخطي LASSO وشبكة عصبية مع تضمينات فئوية | ||||
| نموذج واحد | غير متوفر | المتوسط التاريخي | |||
| كما هو الحال أعلاه بالنسبة إلى 13 منطقة جغرافية إضافية | |||||
| نفس ما ذكر أعلاه لبيئة prod |
وفرت عملية MLOps إطار عمل للنظام الموسع الذي يعالج دورة الحياة الكاملة لنماذج التعلم الآلي. يتضمن إطار العمل التطوير والاختبار والنشر والتشغيل والمراقبة. وهو يلبي احتياجات عملية CI/CD الكلاسيكية. ولكن نظرًا لانعدام النضج النسبي مقارنة بـ DevOps، أصبح من الواضح وجود ثغرات كثيرة في إرشادات MLOps. وعمل فريق المشروع على سد بعض هذه الثغرات. وأرادوا توفير نموذج عملية وظيفي يضمن استمرارية حل التعلم الآلي الذي تم توسيع نطاقه.
اتخذت عملية MLOps التي تم تطويرها من هذا المشروع خطوة كبيرة في العالم الحقيقي لنقل عملية MLOps إلى مستوى أعلى من النضج وقابلية البقاء. وتنطبق العملية الجديدة مباشرة على مشاريع التعلم الآلي الأخرى. استخدم فريق CSE ما تعلموه لبناء مسودة لنموذج نضج MLOps يمكن لأي شخص تطبيقه على مشاريع التعلم الآلي الأخرى.
السيناريو التقني
MLOps، المعروف أيضا باسم DevOps للتعلم الآلي، هو مصطلح شامل يشمل الفلسفات والممارسات والتقنيات المتعلقة بتنفيذ دورات حياة التعلم الآلي في بيئة الإنتاج. وهو مفهوم لا يزال جديدا نسبيا. كانت هناك العديد من المحاولات لتحديد ماهية عملية MLOps، وتساءل العديد من الأشخاص عما إذا كان بإمكان MLOps أن يخزن كل شيء فرعيا بدءا من كيفية إعداد علماء البيانات للبيانات إلى كيفية تقديم نتائج التعلم الآلي ومراقبتها وتقييمها في نهاية المطاف. بينما كان لدى DevOps سنوات لتطوير مجموعة من الممارسات الأساسية، لا يزال MLOps في وقت مبكر من تطويره. ومع تطوره، نكتشف تحديات الجمع بين تخصصين يعملان غالبا مع مجموعات وأولويات مختلفة من المهارات: هندسة البرمجيات/العمليات، وعلوم البيانات.
هناك تحديات فريدة يجب التغلب عليها عند تنفيذ MLOps في بيئات الإنتاج في العالم الحقيقي. يمكن للفرق استخدام Azure لدعم أنماط MLOps. يمكن أن يوفر Azure أيضا للعملاء خدمات إدارة الأصول والتزامن لإدارة دورة حياة التعلم الآلي بشكل فعال. تعد خدمات Azure الأساس لحل MLOps الذي نصفه في هذه المقالة.
متطلبات نموذج التعلم الآلي
كان جزء كبير من العمل خلال الدراسة الميدانية التجريبية للمرحلة الأولى هو إنشاء نماذج التعلم الآلي التي طبقها فريق CSE على متاجر البيع بالتجزئة الكبيرة والصغيرة في منطقة واحدة. وشملت المتطلبات البارزة للنماذج ما يلي:
استخدام خدمة Azure التعلم الآلي.
النماذج التجريبية الأولية التي تم تطويرها في دفاتر Jupyter وتنفيذها في Python.
إشعار
استخدمت الفرق نفس نهج التعلم الآلي للمتاجر الكبيرة والصغيرة، ولكن بيانات التدريب وتسجيل النقاط تعتمد على حجم المتجر.
البيانات التي تتطلب التحضير لاستهلاك النموذج.
البيانات التي تتم معالجتها على أساس دفعي بدلا من الوقت الحقيقي.
إعادة تدريب النموذج كلما تغيرت التعليمات البرمجية أو البيانات، أو كان النموذج قديما.
عرض أداء النموذج في لوحات معلومات Power BI.
أداء النموذج في تسجيل النقاط الذي يعتبر مهما عند MAPE <= 45٪ بالمقارنة مع نموذج الأساس المتوسط التاريخي.
متطلبات MLOps
وكان على الفريق أن يفي بعدة متطلبات رئيسية لتوسيع نطاق الحل من الدراسة الميدانية التجريبية للمرحلة الأولى، التي لم يتم فيها تطوير سوى عدد قليل من النماذج لمنطقة مبيعات واحدة. نفذت المرحلة 2 نماذج التعلم الآلي المخصصة لمناطق متعددة. وشمل التنفيذ ما يلي:
معالجة الدفعات الأسبوعية للمتاجر الكبيرة والصغيرة في كل منطقة لإعادة تدريب النماذج باستخدام مجموعات بيانات جديدة.
التحسين المستمر لنماذج التعلم الآلي.
تكامل عملية التطوير/الاختبار/الحزمة/الاختبار/التوزيع الشائعة في CI/CD في بيئة معالجة تشبه DevOps لـ MLOps.
إشعار
يمثل هذا تحولا في الطريقة الشائعة التي اتبعها علماء البيانات ومهندسي البيانات في الماضي.
نموذج فريد يمثل كل منطقة للمتاجر الكبيرة والصغيرة استنادا إلى سجل المتجر والديمغرافيا والمتغيرات الرئيسية الأخرى. كان على النموذج معالجة مجموعة البيانات بأكملها لتقليل مخاطر خطأ المعالجة.
القدرة على التوسع في البداية لدعم 14 منطقة مبيعات مع خطط لتوسيع نطاقها بشكل أكبر.
خطط لنماذج إضافية للتنبؤ على المدى الطويل للمناطق ومجموعات المتاجر الأخرى.
حل نموذج التعلم الآلي
تناسب دورة حياة التعلم الآلي، والمعروفة أيضا باسم دورة حياة علم البيانات، تقريبا في تدفق العملية عالية المستوى التالية:
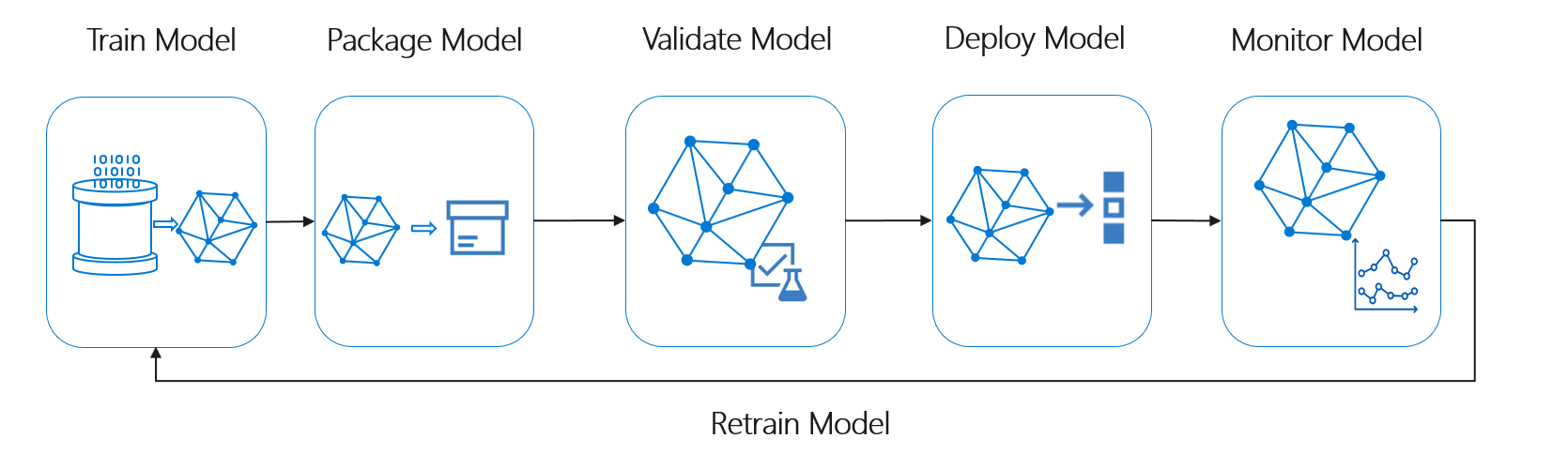
توزيع النموذج هنا يمكن أن يمثل أي استخدام تشغيلي لنموذج التعلم الآلي الذي تم التحقق من صحته. بالمقارنة مع DevOps، يمثل MLOps تحديا إضافيا يتمثل في دمج دورة حياة التعلم الآلي في عملية CI/CD النموذجية.
لا تتبع دورة حياة علم البيانات دورة حياة تطوير البرامج النموذجية. يتضمن استخدام Azure التعلم الآلي لتدريب النماذج وتسجيلها، لذلك يجب تضمين هذه الخطوات في أتمتة CI/CD.
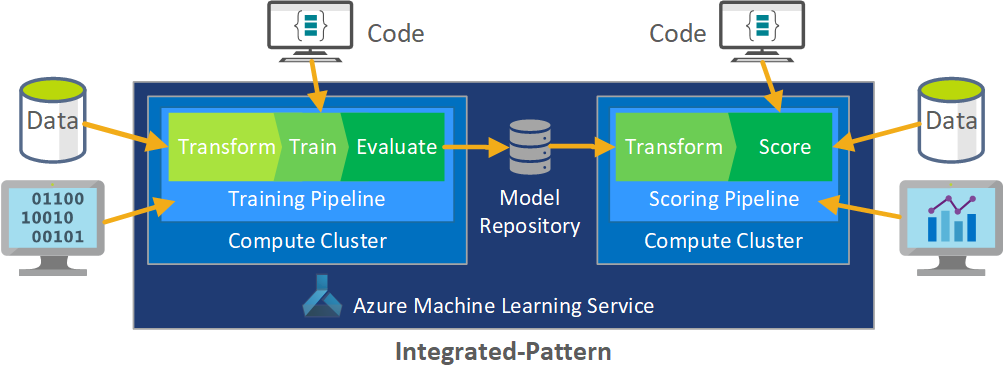
المعالجة الدفعية للبيانات هي أساس البنية. هناك مساران للتعلم الآلي من Azure، أحدهما للتدريب والأخرى للتسجيل. يوضح هذا الرسم التخطيطي منهجية علم البيانات التي تم استخدامها للمرحلة الأولية من مشروع العميل:
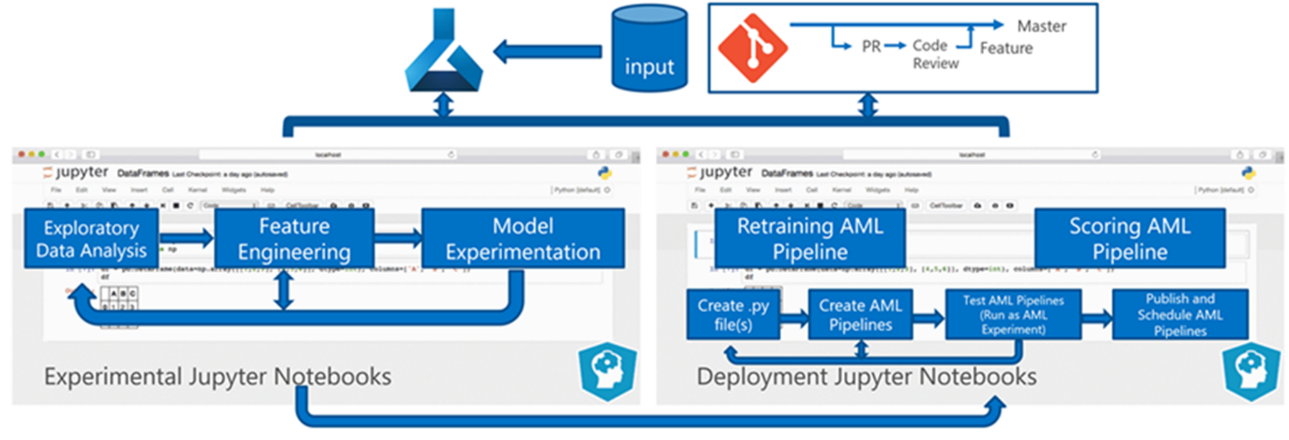
اختبر الفريق العديد من الخوارزميات. اختاروا في نهاية المطاف تصميم مجموعة لنموذج انحدار خطي LASSO وشبكة عصبية مع تضمينات قاطعة. استخدم الفريق نفس النموذج لكل من المتاجر الكبيرة والصغيرة، المحدد بمستوى المنتج الذي يمكن للعميل تخزينه في الموقع. وقسم الفريق النموذج إلى منتجات ذات معدل دوران سريع وأخرى ذات معدل بطيء.
يقوم علماء البيانات بتدريب نماذج التعلم الآلي عندما يصدر الفريق تعليمة برمجية جديدة وعندما تتوفر بيانات جديدة. عادة ما يحدث التدريب أسبوعيا. وبالتالي، يتضمن كل تشغيل معالجة كمية كبيرة من البيانات. نظرا لأن الفريق يجمع البيانات من العديد من المصادر بتنسيقات مختلفة، فإنه يتطلب تكييفا لوضع البيانات في تنسيق قابل للاستهلاك قبل أن يتمكن علماء البيانات من معالجتها. يتطلب تكييف البيانات جهدا يدويا كبيرا وحدده فريق CSE كمرشح أساسي للأتمتة.
كما ذكرنا، قام علماء البيانات بتطوير وتطبيق نماذج Azure التعلم الآلي التجريبية على منطقة مبيعات واحدة في الدراسة الميدانية التجريبية للمرحلة الأولى لتقييم فائدة نهج التنبؤ هذا. وقضى فريق CSE أن رفع المبيعات للمتاجر في الدراسة التجريبية كان كبيرا. وقد برر هذا النجاح تطبيق الحل على مستويات الإنتاج الكاملة في المرحلة الثانية، بدءا من 14 منطقة جغرافية وآلاف المتاجر. يمكن للفريق بعد ذلك اتباع نفس النمط لإضافة مناطق إضافية.
وكان النموذج التجريبي بمثابة الأساس للحل المتدرج، ولكن فريق CSE علم أن النموذج يحتاج إلى مزيد من التحسين على أساس مستمر لتحسين أدائه.
حل MLOps
مع نضج مفاهيم MLOps، تكتشف الفرق غالبا تحديات في الجمع بين تخصصات علم البيانات وDevOps. والسبب هو أن اللاعبين الرئيسيين في التخصصات ومهندسي البرمجيات وعلماء البيانات، يعملون مع مجموعات المهارات والأولويات المختلفة.
ولكن هناك أوجه تشابه للبناء عليها. MLOps، مثل DevOps، هي عملية تطوير تنفذها سلسلة الأدوات. تتضمن سلسلة أدوات MLOps أشياء مثل:
- التحكم بالإصدار
- تحليل التعليمات البرمجية
- بناء الأتمتة
- التكامل المستمر
- أطر عمل الاختبار والأتمتة
- نهج التوافق المدمجة في مسارات CI/CD
- أتمتة التوزيع
- مراقبة
- التعافي من الكوارث وقابلية الوصول العالية
- إدارة الحزم والحاويات
كما هو مذكور أعلاه، يستفيد الحل من إرشادات DevOps الحالية، ولكن يتم تعزيزه لإنشاء تنفيذ MLOps أكثر نضجا يلبي احتياجات العميل ومجتمع علوم البيانات. يعتمد MLOps على إرشادات DevOps مع هذه المتطلبات الإضافية:
- تعيين إصدار البيانات والنموذج ليس هو نفسه تعيين إصدار التعليمات البرمجية: يجب أن يكون هناك إصدار لمجموعات البيانات مع تغير المخطط وبيانات الأصل.
- متطلبات سجل التدقيق الرقمي: تعقب جميع التغييرات عند التعامل مع التعليمات البرمجية وبيانات العميل.
- التعميم: تختلف النماذج عن التعليمات البرمجية لإعادة استخدامها، حيث يجب على علماء البيانات ضبط النماذج استنادا إلى بيانات الإدخال والسيناريو. لإعادة استخدام نموذج لسيناريو جديد، قد تحتاج إلى ضبط/نقل/تعلم عليه. تحتاج إلى تدريب البنية الأساسية لبرنامج ربط العمليات التجارية.
- النماذج القديمة: عادة ما تتقادم النماذج بمرور الوقت وتحتاج إلى إعادة تدريبها عند الطلب لضمان بقاء قدرتها على الإنتاج.
تحديات MLOps
معيار MLOps غير ناضج
لا يزال النمط القياسي لـ MLOps قيد التطوير. عادة ما يتم إنشاء حل من البداية ويتم تصميمه ليناسب احتياجات عميل أو مستخدم معين. لاحظ فريق CSE وجود هذه الفجوة وسعى إلى استخدام أفضل ممارسات DevOps في هذا المشروع. لقد قاموا بتحسين عملية DevOps لتناسب المتطلبات الإضافية لـ MLOps. تعتبر العملية التي طورها الفريق مثال واقعي لما يجب أن يبدو عليه نمط MLOps القياسي.
الاختلافات في مجموعات المهارات
يجلب مهندسو البرمجيات وعلماء البيانات مجموعات مهارات فريدة للفريق. يمكن أن تجعل مجموعات المهارات المختلفة هذه العثور على حل يناسب احتياجات الجميع أمرا صعبا. من المهم بناء سير عمل مفهوم جيدا لتسليم النموذج من التجربة إلى الإنتاج. يجب أن يشارك أعضاء الفريق فهما لكيفية دمج التغييرات في النظام دون قطع عملية MLOps.
إدارة نماذج متعددة
غالبا ما تكون هناك حاجة إلى نماذج متعددة لحلها لسيناريوهات التعلم الآلي الصعبة. يتمثل أحد تحديات MLOps في إدارة هذه النماذج، بما في ذلك:
- وجود نظام إصدار متماسك.
- تقييم ومراقبة جميع النماذج باستمرار.
هناك حاجة أيضا إلى دورة حياة قابلة للتتبع لكل من التعليمات البرمجية والبيانات لتشخيص مشكلات النموذج وإنشاء نماذج قابلة للتكرار. يمكن أن تكون لوحات المعلومات المخصصة منطقية لكيفية أداء النماذج المنشورة وتشير إلى وقت التدخل. أنشأ الفريق لوحات المعلومات لهذا المشروع.
الحاجة إلى تكييف البيانات
تأتي البيانات المستخدمة مع هذه النماذج من العديد من المصادر الخاصة والعامة. نظرا لأن البيانات الأصلية غير منظمة، فمن المستحيل على نموذج التعلم الآلي استهلاكها في حالته الأولية. يجب على علماء البيانات تكييف البيانات إلى تنسيق قياسي لاستهلاك نموذج التعلم الآلي.
تُركز الكثير من اختبارات الحقل التجريبي على تكييف البيانات الأولية بحيث يمكن لنموذج التعلم الآلي معالجتها. في نظام MLOps، يجب على الفريق أتمتة هذه العملية، وتتبع المخرجات.
نموذج نضج MLOps
الغرض من نموذج نضج MLOps هو توضيح المبادئ والممارسات وتحديد الثغرات في تنفيذ MLOps. كما أنها طريقة لإظهار كيفية زيادة قدرة MLOps الخاصة به بشكل متزايد بدلا من محاولة القيام بكل ذلك في وقت واحد. يجب أن يستخدمه العميل كدليل ل:
- تقدير نطاق العمل للمشروع.
- وضع معايير النجاح.
- تحديد التسليمات.
يحدد نموذج نضج MLOps خمسة مستويات من القدرة التقنية:
| المستوى | الوصف |
|---|---|
| 0 | بلا عمليات |
| 1 | DevOps ولكن لا تتوفر عمليات MLOps |
| 2 | التدريب التلقائي |
| 3 | توزيع النموذج التلقائي |
| 4 | العمليات التلقائية (MLOps الكاملة) |
للحصول على الإصدار الحالي من نموذج نضج MLOps، راجع مقالة نموذج نضج MLOps.
تعريف عملية MLOps
يتضمن MLOps جميع الأنشطة بدءا من الحصول على البيانات الأولية إلى تقديم إخراج النموذج، والمعروف أيضا باسم تسجيل النقاط:
- تكييف البيانات
- تدريب النموذج
- اختبار وتقييم النموذج
- تعريف الإصدار والبنية الأساسية لبرنامج ربط العمليات التجارية
- مسارات الإصدار
- التوزيع
- سجل
عملية التعلّم الآلي الأساسية
تشبه عملية التعلم الآلي الأساسية تطوير البرامج التقليدية، ولكن هناك اختلافات كبيرة. يوضح هذا الرسم التخطيطي الخطوات الرئيسية في عملية التعلم الآلي:
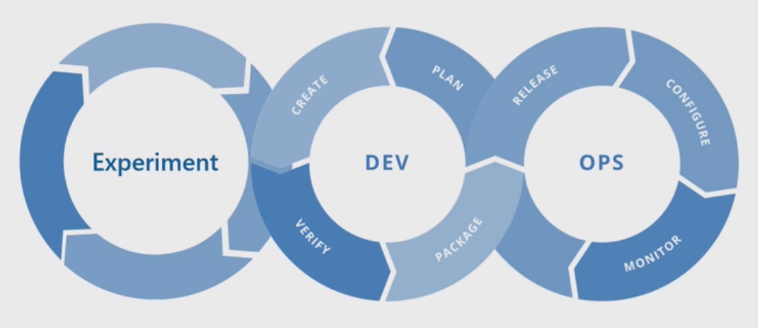
تعتبر مرحلة التجربة فريدة من نوعها لدورة حياة علم البيانات، والتي تعكس كيف يقوم علماء البيانات بعملهم تقليديا. وهو يختلف عن كيفية عمل مطوري التعليمات البرمجية. يوضح الرسم التخطيطي التالي دورة الحياة هذه بمزيد من التفصيل.
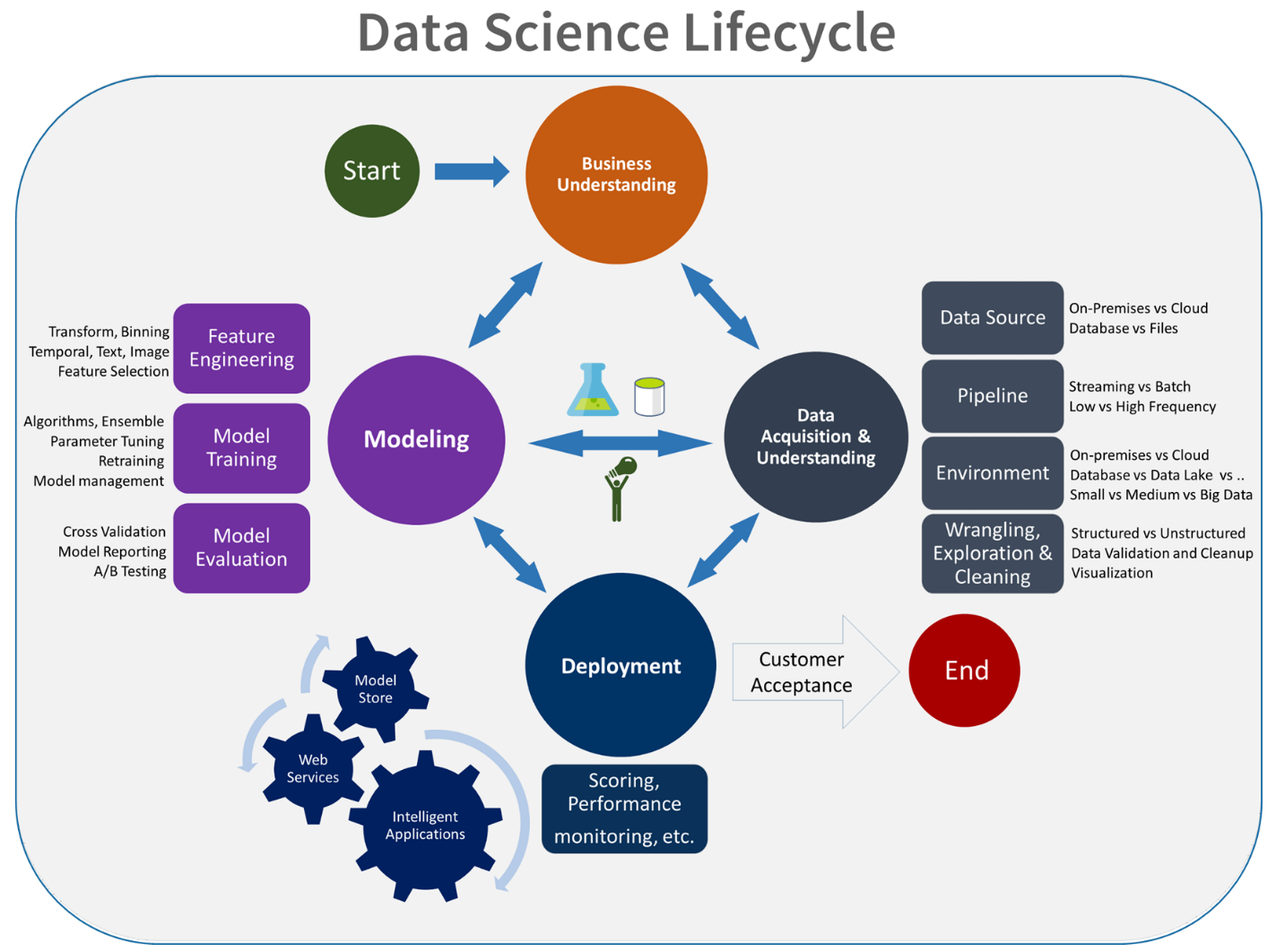
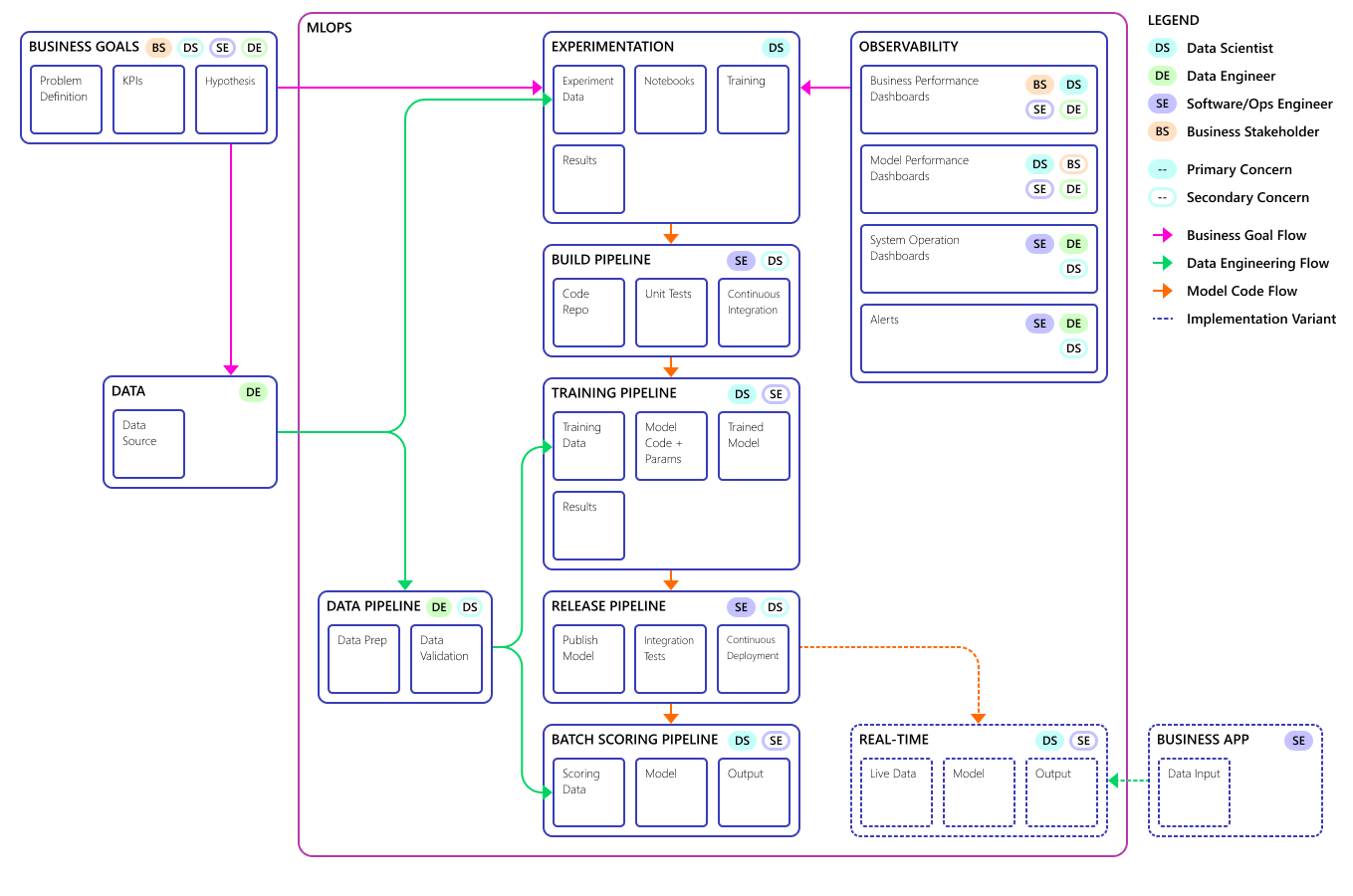
يشكل دمج عملية تطوير البيانات هذه في MLOps تحديا. هنا ترى النمط الذي استخدمه الفريق لدمج العملية في نموذج يمكن أن يدعمه MLOps:
يتمثل دور MLOps في إنشاء عملية منسقة يمكنها دعم بيئات CI/CD واسعة النطاق الشائعة في أنظمة مستوى الإنتاج بكفاءة. من الناحية المفاهيمية، يجب أن يتضمن نموذج MLOps جميع متطلبات العملية بداية من مرحلة التجريب حتى مرحلة التسجيل.
صقل فريق CSE عملية MLOps لتناسب الاحتياجات الخاصة للعميل. وكانت الحاجة الأكثر بروزا هي معالجة الدفعات بدلا من المعالجة في الوقت الحقيقي. ومع تطوير الفريق لنظام التوسيع، حددوا بعض أوجه القصور وحلوها. أدت أهم أوجه القصور هذه إلى تطوير جسر بين Azure Data Factory وAzure التعلم الآلي، والذي نفذه الفريق باستخدام موصل مضمن في Azure Data Factory. قاموا بإنشاء مجموعة المكونات هذه بغرض تسهيل عملية التشغيل ومراقبة الحالة اللازمة لضمان عمل الأتمتة بشكل سليم.
تغيير أساسي آخر هو أن علماء البيانات يحتاجون إلى القدرة على تصدير التعليمات البرمجية التجريبية من دفاتر Jupyter إلى عملية نشر MLOps بدلا من تشغيل التدريب وتسجيل النقاط مباشرة.
فيما يلي مفهوم نموذج عملية MLOps النهائي:
هام
التسجيل هو الخطوة الأخيرة. تقوم العملية بتشغيل نموذج التعلم الآلي لإجراء تنبؤات. يتعلق هذا الإجراء بمتطلبات حالة استخدام الأعمال الأساسية للتنبؤ بالطلب. يقوم الفريق بمعدل جودة التنبؤات باستخدام MAPE، وهو مقياس لدقة التنبؤ لأساليب التنبؤ الإحصائي ووظيفة الخسارة لمشاكل الانحدار في التعلم الآلي. في هذا المشروع، اعتبر الفريق MAPE <= 45٪ نسبة هامة.
تدفق عملية MLOps
يصف الرسم التخطيطي التالي كيفية تطبيق تطوير CI/CD وإصدار مهام سير العمل على دورة حياة التعلم الآلي:
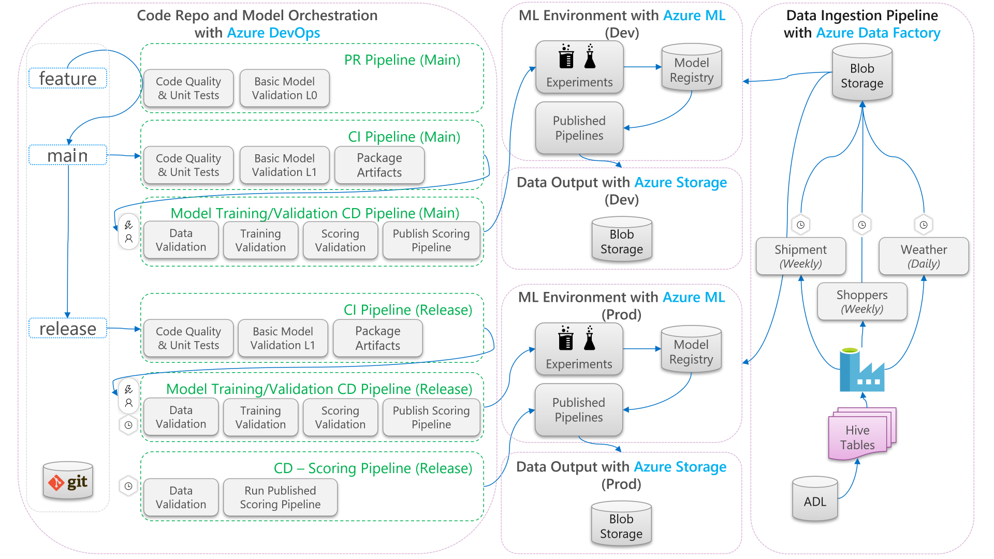
- عند إنشاء طلب سحب (PR) من فرع ميزة، يقوم المسار بتشغيل اختبارات التحقق من صحة التعليمات البرمجية للتحقق من جودة التعليمات البرمجية عبر اختبارات الوحدة واختبارات جودة التعليمات البرمجية. للتحقق من جودة المصدر، تقوم البنية الأساسية لبرنامج ربط العمليات التجارية أيضا بتشغيل اختبارات التحقق من صحة النموذج الأساسية للتحقق من صحة التدريب الشامل وخطوات تسجيل النقاط باستخدام مجموعة عينة من البيانات الوهمية.
- عند دمج PR في الإصدار الأساسي، سيقوم مسار CI بتشغيل نفس اختبارات التحقق من صحة التعليمات البرمجية واختبارات التحقق من صحة النموذج الأساسية لكن مع زيادة الفترة الزمنية. بعدها ستقوم البنية الأساسية لبرنامج ربط العمليات التجارية بعد ذلك بعمل حزمة من البيانات الاصطناعية التي تتضمن التعليمات البرمجية والثنائيات، لتشغيلها في بيئة التعلم الآلي.
- بعد توفر البيانات الاصطناعية، يتم تشغيل مسار CD للتحقق من صحة النموذج. يقوم بتشغيل التحقق من الصحة من البداية للنهاية على بيئة التعلم الآلي للتطوير. يتم نشر آلية تسجيل النقاط. بالنسبة لسيناريو تسجيل الدفعات، يتم نشر البنية الأساسية لبرنامج ربط العمليات التجارية لتسجيل النقاط إلى بيئة التعلم الآلي وتشغيله لإظهار النتائج. إذا كنت ترغب في استخدام سيناريو تسجيل النقاط في الوقت الحقيقي، يمكنك نشر تطبيق ويب أو نشر حاوية.
- بمجرد إنشاء حدث رئيسي ودمجه في فرع الإصدار، يتم تشغيل نفس مسار CI ومسار CD للتحقق من صحة النموذج. هذه المرة، يتم تشغيلها مقابل التعليمات البرمجية من فرع الإصدار.
يمكنك اعتبار تدفق بيانات عملية MLOps الموضح أعلاه كإطار عمل أصلي للمشاريع التي تتخذ خيارات معمارية مماثلة.
اختبارات التحقق من الصحة
تركز اختبارات التحقق من صحة التعليمات البرمجية للتعلم الآلي على التحقق من صحة جودة قاعدة التعليمات البرمجية. إنه نفس مفهوم أي مشروع هندسي يحتوي على اختبارات جودة التعليمات البرمجية (التحليل) واختبارات الوحدة وقياسات تغطية التعليمات البرمجية.
اختبارات التحقق من صحة النموذج الأساسية
عادة يشير التحقق من صحة النموذج إلى التحقق من صحة خطوات العملية الشاملة المطلوبة لإنتاج نموذج تعلم آلي سليم. ويتضمن خطوات مثل:
- التحقق من صحة البيانات: يضمن أن بيانات الإدخال صالحة.
- التحقق من صحة التدريب: يضمن إمكانية تدريب النموذج بنجاح.
- التحقق من صحة التسجيل: يضمن أن الفريق يمكنه استخدام النموذج المدَرب بنجاح لتسجيل النقاط باستخدام بيانات الإدخال.
يعد تشغيل هذه المجموعة الكاملة من الخطوات على بيئة التعلم الآلي مكلفا ويستغرق وقتا طويلا. ونتيجة لذلك، أجرى الفريق اختبارات التحقق من صحة النموذج الأساسية محليا على جهاز تطوير. شغل الخطوات أعلاه واستخدم ما يلي:
- مجموعة بيانات الاختبار المحلي: مجموعة بيانات صغيرة، غالبا ما تكون مشوشة، يتم إيداعها في المستودع وتستهلك كمصدر بيانات الإدخال.
- العلامة المحلية: علامة أو وسيطة في التعليمات البرمجية للنموذج تشير إلى أن التعليمات البرمجية تنوي تشغيل مجموعة البيانات محليا. تخبر العلامة التعليمات البرمجية بتجاوز أي استدعاء لبيئة التعلم الآلي.
لا يتمثل الهدف من اختبارات التحقق هذه في تقييم أداء النموذج المدرب. بدلا من ذلك، هو التحقق من أن التعليمات البرمجية للعملية الشاملة ذات جودة جيدة. وهو يضمن جودة التعليمات البرمجية التي يتم دفعها في المصدر، مثل دمج اختبارات التحقق من صحة النموذج في بناء PR وCI. كما أنه يجعل من الممكن للمهندسين وعلماء البيانات وضع نقاط توقف في التعليمات البرمجية لأغراض تصحيح الأخطاء.
البنية الأساسية لبرنامج ربط العمليات التجارية CD للتحقق من صحة النموذج
يهدف المسار التحقق من صحة النموذج إلى التحقق من صحة تدريب النموذج الشامل وخطوات تسجيل النقاط على بيئة التعلم الآلي بالبيانات الفعلية. ستتم إضافة أي نموذج مدرب يتم إنتاجه إلى سجل النموذج ووضع علامة عليه، لانتظار الترقية بعد اكتمال التحقق من الصحة. للتنبؤ الدفعي، يمكن أن يكون الترقية نشر مسار تسجيل النقاط الذي يستخدم هذا الإصدار من النموذج. لتسجيل النقاط في الوقت الحقيقي، يمكن وضع علامة على النموذج للإشارة إلى أنه تمت ترقيته.
تسجيل البنية الأساسية لبرنامج ربط العمليات التجارية CD
تنطبق البنية الأساسية لبرنامج ربط العمليات التجارية لتسجيل النقاط على سيناريو الاستدلال الدفعي، حيث يقوم نفس منسق النموذج المستخدم للتحقق من صحة النموذج بتشغيل مسار تسجيل النقاط المنشور.
بيئات التطوير وبيئات الإنتاج
من الممارسات الجيدة فصل بيئة التطوير (التطوير) عن بيئة الإنتاج (prod). يسمح الفصل للنظام بتشغيل مسار CD للتحقق من صحة النموذج وتسجيل مسار CD على جداول زمنية مختلفة. بالنسبة لتدفق MLOps الموضح، تعمل المسارات التي تستهدف الفرع الرئيسي في بيئة التطوير، ويتم تشغيل البنية الأساسية لبرنامج ربط العمليات التجارية التي تستهدف فرع الإصدار في بيئة prod.
تغييرات التعليمات البرمجية وتغيير البيانات
تتعامل الأقسام السابقة في الغالب مع كيفية التعامل مع تغييرات التعليمات البرمجية من التطوير إلى الإصدار. ومع ذلك، يجب أن تتبع تغييرات البيانات نفس الصرامة مثل تغييرات التعليمات البرمجية لتوفير نفس جودة التحقق من الصحة والاتساق في الإنتاج. باستخدام مشغل تغيير البيانات أو مشغل مؤقت، يمكن للنظام تشغيل مسار CD للتحقق من صحة النموذج ومسار CD المسجل من منسق النموذج لتشغيل نفس العملية التي يتم تشغيلها لتغييرات التعليمات البرمجية في بيئة prod فرع الإصدار.
شخصية MLOps وأدوارها
أحد المتطلبات الرئيسية لأي عملية MLOps هو أنها تلبي احتياجات العديد من مستخدمي العملية. لأغراض التصميم، ضع في اعتبارك هؤلاء المستخدمين كأشخاص فرديين. بالنسبة لهذا المشروع، حدد الفريق هذه الشخصيات:
- عالم البيانات: ينشئ نموذج التعلم الآلي وخوارزمياته.
- المهندس
- مهندس البيانات: يعالج تكييف البيانات.
- مهندس البرمجيات: يعالج تكامل النموذج في حزمة الأصول وسير عمل CI/CD.
- العمليات أو تكنولوجيا المعلومات: يشرف على عمليات النظام.
- أصحاب المصلحة في الأعمال: يهتمون بالتنبؤات التي قدمها نموذج التعلم الآلي وكيف تساعد الأعمال.
- مستخدم البيانات النهائي: يستهلك مخرجات النموذج بطريقة تساعده على اتخاذ قرارات الأعمال.
وكان على الفريق أن يتعامل مع ثلاث نتائج للدراسة التي أجريت على الشخصيات والأدوار:
- علماء ومهندسو البيانات لديهم نهج مختلفة ومهارات مختلفة لأداء عملهم. يعد تسهيل تعاون عالم البيانات والمهندس أحد الاعتبارات الرئيسية لتصميم تدفق عملية MLOps. يتطلب اكتساب مهارات جديدة من قبل جميع أعضاء الفريق.
- هناك حاجة لتوحيد جميع الشخصيات الرئيسية دون تنفير أي شخص. طريقة للقيام بذلك هي:
- تأكد من فهمهم للنموذج المفاهيمي ل MLOps.
- وافق على أعضاء الفريق الذين سيعملون معا.
- وضع مبادئ توجيهية للعمل لتحقيق الأهداف المشتركة.
- إذا كان أصحاب المصلحة في الأعمال ومستخدم البيانات النهائي بحاجة إلى طريقة للتفاعل مع إخراج البيانات من النماذج، فإن واجهة المستخدم سهلة الاستخدام هي الحل القياسي.
بالتأكيد ستظهر بعض المشكلات المماثلة في مشاريع التعلم الآلي الأخرى أثناء توسيع نطاقها لاستخدام الإنتاج.
هندسة الحلول MLOps
البنية المنطقية
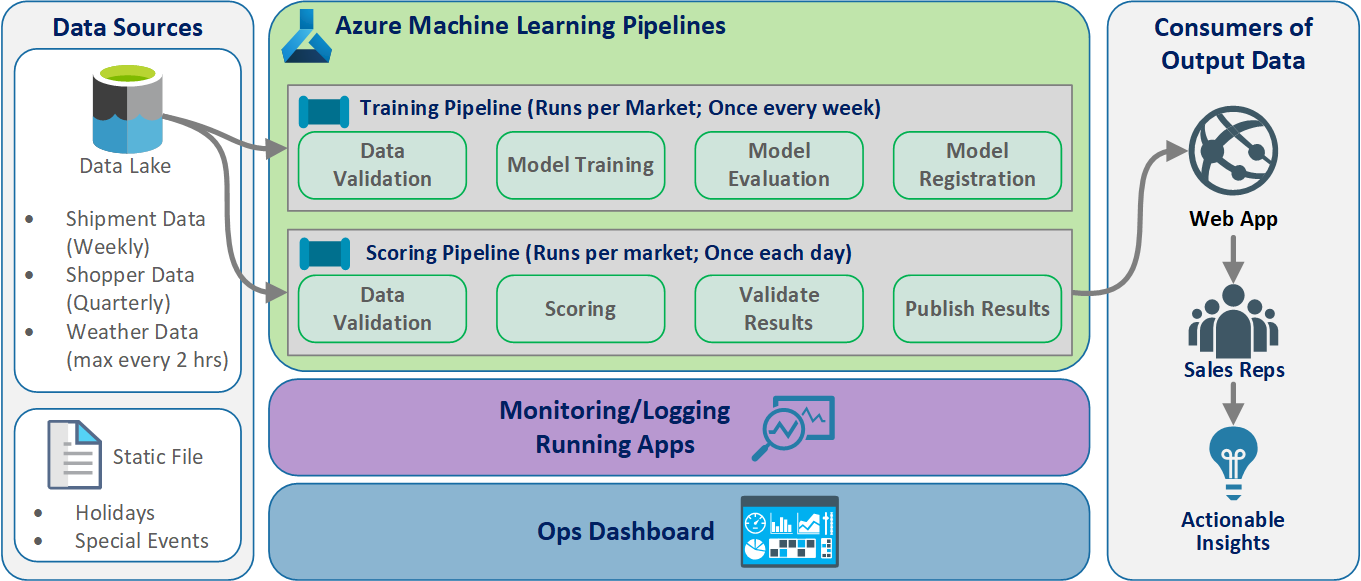
تأتي البيانات من العديد من المصادر في العديد من التنسيقات المختلفة، لذلك يتم تكييفها قبل إدراجها في مستودع البيانات. يتم تكييف باستخدام الخدمات المصغرة التي تعمل كوظائف Azure. يقوم العملاء بتخصيص الخدمات المصغرة لتناسب مصادر البيانات وتحويلها إلى تنسيق csv موحد تستهلكه مسارات التدريب وتسجيل النقاط.
بنية النظام
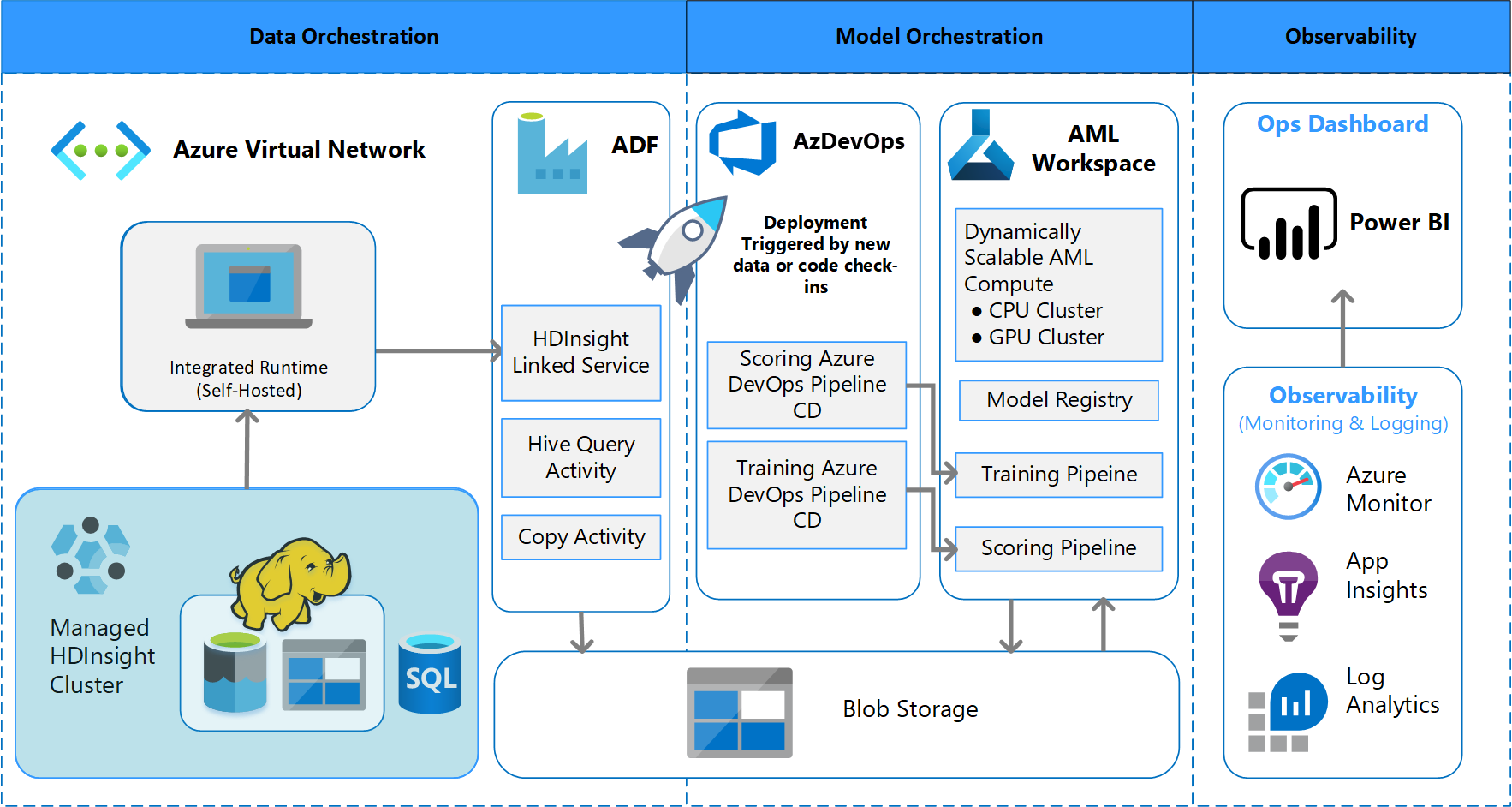
بنية معالجة الدفعات
ابتكر الفريق تصميم معماري لدعم نظام معالجة البيانات الدفعية. هناك بدائل، ولكن كل ما يتم استخدامه يجب أن يدعم عمليات MLOps. أحد متطلبات التصميم الأساسية هو الاستخدام الكامل لخدمات Azure المتوفرة. يوضح الرسم التخطيطي التالي البنية الأساسية:
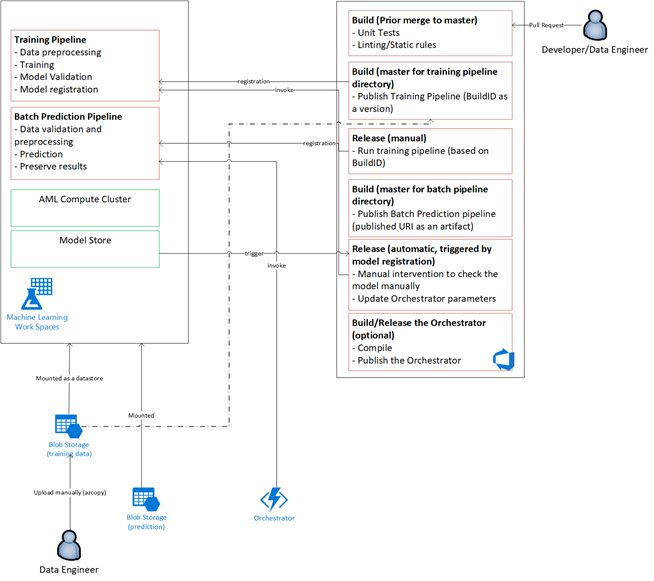
نظرة عامة على الحل
يقوم Azure Data Factory بالآتي:
- تشغيل دالة Azure لبدء استيعاب البيانات وتشغيل البنية الأساسية لبرنامج ربط العمليات التجارية التعلم الآلي Azure.
- تشغيل دالة دائمة لاستقصاء البنية الأساسية لبرنامج ربط العمليات التجارية التعلم الآلي Azure لإكمالها.
لوحات معلومات مخصصة في Power BI لعرض النتائج. لوحات معلومات Azure الأخرى المتصلة ب Azure SQL وAzure Monitor وApp Insights عبر OpenCensus Python SDK، وتتبع موارد Azure. توفر لوحات المعلومات هذه معلومات حول صحة نظام التعلم الآلي. كما أنها تسفر عن البيانات التي يستخدمها العميل للتنبؤ بأمر المنتج.
تنسيق النموذج
يتبع تنسيق النموذج الخطوات التالية:
- عند إرسال طلب السحب، يقوم DevOps بتشغيل مسار التحقق من صحة التعليمات البرمجية.
- يقوم المسار بتشغيل اختبارات الوحدة واختبارات جودة التعليمات البرمجية واختبارات التحقق من صحة النموذج.
- عند دمجها في الفرع الرئيسي، يتم تشغيل نفس اختبارات التحقق من صحة التعليمات البرمجية، وحزم DevOps البيانات الاصطناعية.
- يؤدي تجميع DevOps للبيانات الاصطناعية إلى تشغيل Azure التعلم الآلي القيام به:
- التحقق من صحة البيانات.
- التحقق من صحة التدريب.
- التحقق من صحة تسجيل النقاط.
- بعد اكتمال التحقق من الصحة، يتم تشغيل البنية الأساسية لبرنامج ربط العمليات التجارية النهائية لتسجيل النقاط.
- يؤدي تغيير البيانات وإرسال طلب سحب جديد إلى تشغيل مسار التحقق من الصحة مرة أخرى، متبوعا بمسار التسجيل النهائي.
تمكين الخطوة التجريبية
كما ذكرنا، لا تدعم دورة حياة التعلم الآلي لعلوم البيانات التقليدية عملية MLOps دون تعديل. ويستخدم أنواعا مختلفة من الأدوات اليدوية والتجريب والتحقق من الصحة والتعبئة وتسليم النموذج التي لا يمكن قياسها بسهولة لعملية CI/CD فعالة. يتطلب MLOps مستوى عاليا من أتمتة العمليات. سواء تم تطوير نموذج جديد للتعلم الآلي أو تم تعديل نموذج قديم، فمن الضروري أتمتة دورة حياة نموذج التعلم الآلي. في مشروع المرحلة 2، استخدم الفريق Azure DevOps لتنسيق وإعادة نشر مسارات Azure التعلم الآلي لمهام التدريب. ينفذ الفرع الرئيسي طويل الأمد الاختبار الأساسي للنماذج، ويدفع الإصدارات الثابتة من خلال فرع الإصدار طويل الأمد.
يعد التحكم بالمصادر جزءا مهما من هذه العملية. Git هو نظام التحكم في الإصدار المستخدم لتعقب دفتر الملاحظات ورمز النموذج. كما أنه يدعم أتمتة العمليات. يطبق سير العمل الأساسي الذي يتم تنفيذه للتحكم بالمصادر المبادئ التالية:
- استخدم تعيين الإصدار الرسمي للتعليمات البرمجية ومجموعات البيانات.
- استخدم فرعا لتطوير التعليمات البرمجية الجديدة حتى يتم تطوير التعليمات البرمجية والتحقق من صحتها بالكامل.
- بعد التحقق من صحة التعليمات البرمجية الجديدة، يمكن دمجها في الفرع الرئيسي.
- للإصدار، يتم إنشاء فرع دائم تم إصداره منفصل عن الفرع الرئيسي.
- استخدم الإصدارات والتحكم بالمصادر لمجموعات البيانات التي تم تكييفها للتدريب أو الاستهلاك، بحيث يمكنك الحفاظ على تكامل كل مجموعة بيانات.
- استخدم التحكم بالمصادر لتعقب تجارب Jupyter Notebook.
التكامل مع مصادر بيانات
يستخدم علماء البيانات العديد من مصادر البيانات الأولية ومجموعات البيانات المعالجة لتجربة نماذج التعلم الآلي المختلفة. يمكن أن يكون حجم البيانات في بيئة الإنتاج كبيرا. لكي يجرب علماء البيانات نماذج مختلفة، يحتاجون إلى استخدام أدوات الإدارة مثل Azure Data Lake. ينطبق شرط التحديد الرسمي والتحكم في الإصدار على جميع البيانات الأولية ومجموعات البيانات المعدة ونماذج التعلم الآلي.
في المشروع، قام علماء البيانات بتكييف البيانات التالية لإدخالها في النموذج:
- بيانات الشحن الأسبوعية التاريخية منذ يناير 2017
- بيانات الطقس اليومية التاريخية والمتوقعة لكل رمز بريدي
- بيانات المتسوقين لكل معرف متجر
التكامل مع التحكم بالمصادر
لجعل علماء البيانات يطبقون أفضل الممارسات الهندسية، من الضروري دمج الأدوات التي يستخدمونها بسهولة مع أنظمة التحكم بالمصادر مثل GitHub. تسمح هذه الممارسة بإصدار نموذج التعلم الآلي والتعاون بين أعضاء الفريق والتعافي من الكوارث إذا واجهت الفرق فقدانا للبيانات أو انقطاعا في النظام.
دعم مجموعة النموذج
صمم النموذج في هذا المشروع ليكون متعددًا. أي أن علماء البيانات استخدموا العديد من الخوارزميات في تصميم النموذج النهائي. في هذه الحالة، استخدمت النماذج نفس تصميم الخوارزمية الأساسية. الفرق الوحيد هو أنهم استخدموا بيانات تدريب وبيانات تسجيل نقاط مختلفة. استخدمت النماذج مزيجا من خوارزمية انحدار خطي LASSO وشبكة عصبية.
واستكشف الفريق، ولكنه لم ينفذ، خيارا للمضي قدما بالعملية إلى النقطة التي سيدعم فيها وجود العديد من النماذج في الوقت الحقيقي قيد التشغيل في الإنتاج لخدمة طلب معين. يمكن أن يستوعب هذا الخيار استخدام نماذج المجموعة في اختبار A/B والتجارب المتداخلة.
واجهات المستخدم النهائي
طور الفريق واجهات المستخدم النهائي لأغراض الرصد والمراقبة وإصدار تقرير عن حالة النظام. كما ذكرنا، تعرض لوحات المعلومات بيانات نموذج التعلم الآلي بشكل مرئي. تعرض لوحات المعلومات هذه البيانات التالية بتنسيق سهل الاستخدام:
- خطوات المسار، بما في ذلك المعالجة المسبقة لبيانات الإدخال.
- لمراقبة صحة معالجة نموذج التعلم الآلي:
- ما هي المقاييس التي تجمعها من النموذج المستخدم؟
- MAPE: متوسط خطأ النسبة المئوية المطلقة، المقياس الرئيسي لتتبع الأداء العام. (استهداف قيمة MAPE = <0.45 لكل نموذج.)
- RMSE 0: خطأ الجذر الوسط التربيعي (RMSE) عندما تكون القيمة الهدف الفعلية = 0.
- RMSE All: RMSE على مجموعة البيانات بأكملها.
- كيف تقيم ما إذا كان نموذجك يعمل كما هو متوقع في الإنتاج؟
- هل هناك طريقة لمعرفة ما إذا كانت بيانات الإنتاج تنحرف كثيرا عن القيم المتوقعة؟
- هل يوجد ضعف في أداء نموذجك في الإنتاج؟
- هل لديك حالة تجاوز الفشل؟
- ما هي المقاييس التي تجمعها من النموذج المستخدم؟
- تتبع جودة البيانات المعالجة.
- عرض النقاط/التنبؤات التي ينتجها نموذج التعلم الآلي.
يملأ التطبيق لوحات المعلومات وفقا لطبيعة البيانات وكيفية معالجة البيانات وتحليلها. ولذلك يجب على الفريق تصميم تخطيط دقيق للوحات المعلومات لكل حالة استخدام. فيما يلي نموذجان للوحات المعلومات:
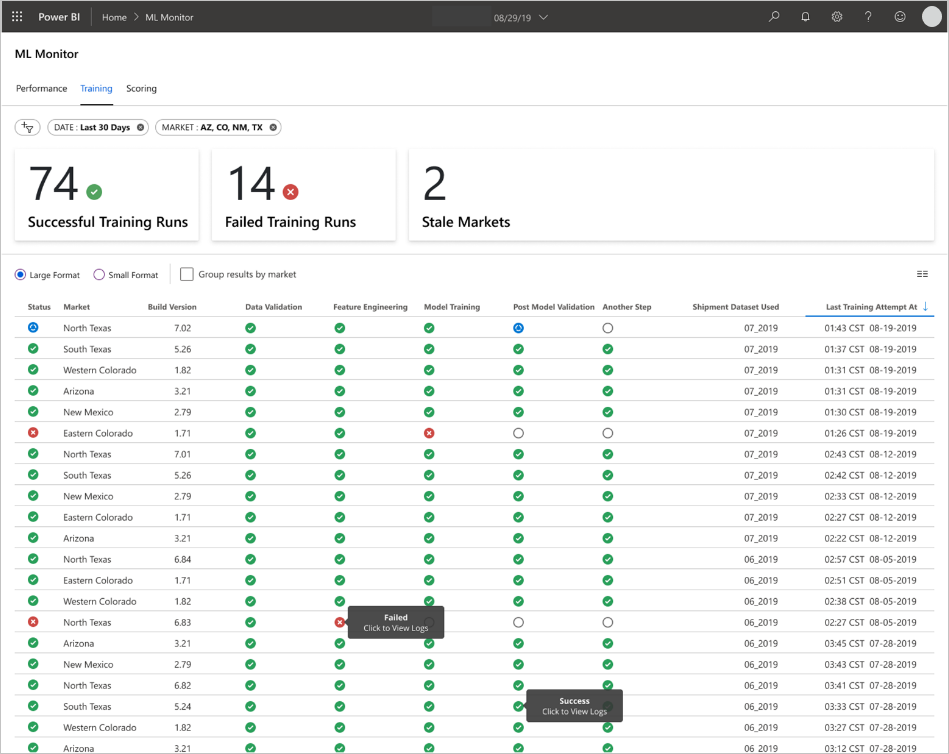
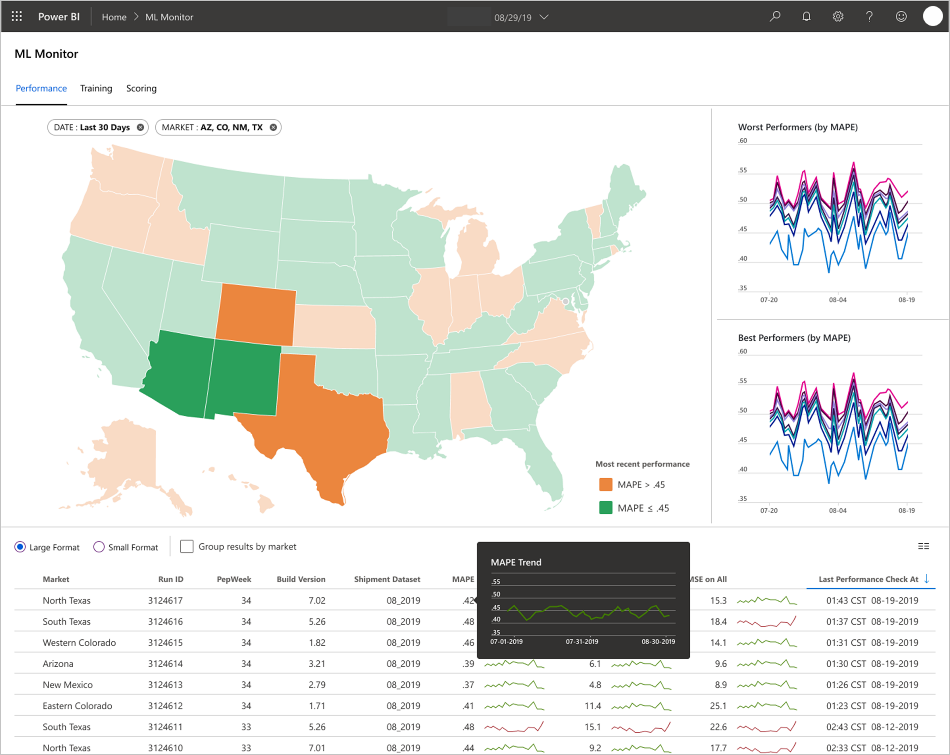
تم تصميم لوحات المعلومات لتوفير معلومات سهلة الاستخدام للاستهلاك من قبل المستخدم النهائي للتنبؤات نموذج التعلم الآلي.
إشعار
تعمل النماذج القديمة على تسجيل النقاط حيث قام علماء البيانات بتدريب النموذج المستخدم لتسجيل أكثر من 60 يوما من وقت تسجيل النقاط. تعرض صفحة تسجيل النقاط في لوحة معلومات مراقبة التعلم الآلي مقياس الصحة.
المكونات
- التعلم الآلي من Microsoft Azure
- مخزن البيانات الثنائية كبيرة الحجم لـ Azure
- Azure Data Lake Storage
- مسارات Azure
- Azure Data Factory
- وظائف Azure لـ Python
- Azure Monitor
- قاعدة بيانات Azure SQL
- لوحات معلومات Azure
- Power BI
الاعتبارات
ستجد هنا قائمة بالاعتبارات التي يجب استكشافها. وهي اعتبارات تستند إلى الدروس التي تعلمها فريق CSE أثناء المشروع.
اعتبارات البيئة
- يقوم علماء البيانات بتطوير معظم نماذج التعلم الآلي الخاصة بهم باستخدام Python، وغالبا ما تبدأ بدفاتر Jupyter. قد يمثل تحديًا تنفيذ دفاتر الملاحظات هذه مثل التعليمة البرمجية للإنتاج. دفاتر ملاحظات Jupyter تشبه أداة تجريبية إلى حد كبير، في حين أن برامج Python النصية أكثر ملاءمة للإنتاج. غالبا ما تحتاج الفرق لقضاء بعض الوقت في إعادة بناء التعليمات البرمجية لإنشاء النموذج في برامج Python النصية.
- اجعل العملاء الجدد في DevOps والتعلم الآلي يدركون أن التجريب والإنتاج يتطلبان دقة مختلفة، لذلك من الممارسات الجيدة فصل الاثنين.
- يمكن أن تكون أدوات مثل Azure التعلم الآلي Visual Designer أو AutoML فعالة في الحصول على النماذج الأساسية على الأرض بينما يكثف العميل ممارسات DevOps القياسية للتطبيق على بقية الحل.
- يحتوي Azure DevOps على مكونات إضافية يمكن دمجها مع Azure التعلم الآلي للمساعدة في تشغيل خطوات البنية الأساسية لبرنامج ربط العمليات التجارية. يحتوي MLOpsPython مستودع على بعض أمثلة المسارات.
- غالبا ما يتطلب التعلم الآلي أجهزة قوية لوحدة معالجة الرسومات (GPU) للتدريب. إذا لم يكن لدى العميل مثل هذه الأجهزة المتوفرة بالفعل، يمكن أن توفر مجموعات حساب Azure التعلم الآلي مسارا فعالا لتوفير أجهزة فعالة فعالة من حيث التكلفة بسرعة والتي تقوم بالتحجيم التلقائي. إذا كان العميل لديه احتياجات أمان أو مراقبة متقدمة، فهناك خيارات أخرى مثل الأجهزة الظاهرية القياسية أو Databricks أو الحوسبة المحلية.
- لكي ينجح العميل، يجب أن يكون لدى فرق بناء النموذج (علماء البيانات) وفرق التوزيع (مهندسو DevOps) قناة اتصال قوية. يمكنهم تحقيق ذلك من خلال الاجتماعات المستقلة اليومية أو خدمة دردشة رسمية عبر الإنترنت. يساعد كلا النهجين في دمج جهود التطوير الخاصة بهم في إطار عمل MLOps.
اعتبارات إعداد البيانات
أبسط حل لاستخدام التعلم الآلي Azure هو تخزين البيانات في حل تخزين البيانات المدعوم. تعد أدوات مثل Azure Data Factory فعالة في نقل البيانات من وإلى تلك المواقع في الوقت المحدد.
من المهم للعملاء التقاط بيانات إعادة تدريب إضافية بشكل متكرر للحفاظ على نماذجهم محدثة. إذا لم يكن لديهم بالفعل مسار بيانات، فإن إنشاء مسار هو بالتأكيد أحد الحلول الهامة. يمكن أن يكون استخدام حل مثل Datasets في التعلم الآلي Azure مفيدا لإصدار البيانات للمساعدة في تتبع النماذج.
اعتبارات التدريب والتقييم النموذجية
إنه أمر غامر للعميل الذي بدأ للتو في رحلة التعلم الآلي الخاصة به محاولة تنفيذ مسار MLOps كامل. إذا لزم الأمر، يمكنهم السهولة في ذلك باستخدام Azure التعلم الآلي لتتبع تشغيل التجربة وباستخدام حساب Azure التعلم الآلي كهدف للتدريب. قد تساعد هذه الخيارات على تيسير حل الإدخال لبدء دمج خدمات Azure.
الانتقال من تجربة دفتر الملاحظات إلى البرامج النصية القابلة للتكرار هو انتقال تقريبي للعديد من علماء البيانات. كلما أسرعت في الحصول على كتابة التعليمات البرمجية للتدريب في نصوص Python، كان من الأسهل عليهم البدء في إصدار التعليمات البرمجية للتدريب وتمكين إعادة التدريب.
هذه ليست الطريقة الوحيدة الممكنة. يدعم Databricks جدولة دفاتر الملاحظات كمهام. ولكن، استنادا إلى تجربة العميل الحالية، من الصعب وضع علامة على هذا النهج مع ممارسات DevOps الكاملة بسبب قيود الاختبار.
من المهم أيضا فهم المقاييس المستخدمة للنظر في نجاح النموذج. غالبا لا تكفي الدقة وحدها لتحديد الأداء العام لنموذج واحد مقابل آخر.
اعتبارات الحساب
- يجب على العملاء التفكير في استخدام الحاويات لتوحيد بيئات الحوسبة الخاصة بهم. تدعم جميع أهداف الحوسبة في Azure التعلم الآلي تقريبا باستخدام Docker. يمكن أن يؤدي وجود حاوية تتعامل مع التبعيات إلى تقليل الاحتكاك بشكل كبير، خاصة إذا كان الفريق يستخدم العديد من أهداف الحوسبة.
اعتبارات خدمة النموذج
- يوفر Azure التعلم الآلي SDK خيارا للتوزيع مباشرة إلى Azure Kubernetes Service (AKS) من نموذج مسجل، ما يخلق حدودا على الأمان/المقاييس الموجودة. يمكنك محاولة العثور على حل أسهل للعملاء لاختبار نموذجهم، ولكن من الأفضل تطوير توزيع أكثر قوة إلى AKS لأحمال عمل الإنتاج.
الخطوات التالية
- تعرف على المزيد حول MLOps
- MLOps على Azure
- مرئيات Azure Monitor
- دورة حياة التعلّم الآلي
- ملحق التعلم الآلي من Microsoft Azure
- سطر أوامر التعلم الآلي من Azure
- تشغيل التطبيقات أو العمليات أو سير عمل CI/CD استنادا إلى أحداث التعلم الآلي من Azure
- إعداد تدريب النموذج وتوزيعه باستخدام Azure DevOps
الموارد ذات الصلة
- نموذج نضج MLOps
- تنسيق MLOps على Azure Databricks باستخدام دفتر ملاحظات Databricks
- MLOps لنماذج Python باستخدام التعلم الآلي من Microsoft Azure
- علم البيانات والتعلم الآلي باستخدام Azure Databricks
- ذكاء اصطناعي مواطن مع منصة الطاقة Power Platform
- نشر حوسبة الذكاء الاصطناعي والتعلم الآلي محليا وعلى الحافة