إشعار
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تسجيل الدخول أو تغيير الدلائل.
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تغيير الدلائل.
Natural language processing encompasses techniques that analyze, understand, and generate human language from text data. Azure provides managed API-driven services and distributed open-source frameworks that address natural language processing workloads that range from sentiment analysis and entity recognition to document classification and text summarization. This guide helps you evaluate and choose from the primary natural language processing options on Azure so that you can match the right technology to your workload requirements.
Note
This guide focuses on natural language processing capabilities available through Azure Language and Apache Spark with Spark NLP on Azure Databricks or Microsoft Fabric. It doesn't provide guidance for how to select language models or design Azure OpenAI solutions. Some platform descriptions might reference supported foundation-model or speech-model integrations as implementation details, but this guide focuses on natural language processing service selection. For more information, see Choose an AI services technology.
Understand natural language processing and language models
Before you evaluate Azure services, understand what natural language processing is, how it differs from language models, and what tasks it addresses.
Distinguish natural language processing from language models
This section clarifies the boundary between natural language processing and language models, and surveys the core capabilities that natural language processing techniques enable.
| Dimension | Natural language processing | Language models |
|---|---|---|
| Scope | A broad field that covers diverse text-processing techniques, including tokenization, stemming, entity recognition, sentiment analysis, and document classification. | A deep-learning subset of natural language processing focused on high-level language understanding and generation tasks. |
| Examples | Rule-based parsers, term frequency-inverse document frequency (TF-IDF) classifiers, named entity recognizers, sentiment analyzers. | GPT, BERT, and similar transformer-based models that generate humanlike, contextually aware text. |
| Output | Structured signals like labels, scores, extracted spans, and parsed syntax. | Fluent natural language like generated text, summaries, answers, and completions. |
| Relationship | The parent domain. Natural language processing encompasses the full spectrum of text-processing methods. | A tool within natural language processing. Language models enhance natural language processing without replacing it. They handle broader cognitive tasks but aren't synonymous with natural language processing. |
Natural language processing capabilities
Classify documents by labeling them as sensitive or spam. Natural language processing automatically categorizes documents based on content to support compliance and filtering workflows.
Summarize text by identifying entities in the document. Natural language processing extracts key entities to produce concise summaries that capture the most important information.
Tag documents with keywords by using identified entities. After you identify entities, you can generate keyword tags that simplify document organization. Use these tags for content-based search and retrieval.
Detect topics for navigation and related document discovery. Natural language processing identifies key topics by using extracted entities, which supports document categorization and topic-based navigation.
Assess text sentiment. Sentiment analysis evaluates the emotional tone of text and classifies content as positive, negative, or neutral.
Feed natural language processing outputs into downstream workflows. Results like extracted entities, sentiment scores, and topic labels serve as inputs for processing, search indexing, and analytics.
Identify potential use cases
Business scenarios across many industries benefit from natural language processing solutions. The following use cases show how natural language processing techniques address real-world challenges, from processing unstructured documents to enabling emerging applications in cybersecurity and accessibility.
Process documents and unstructured text
Extract intelligence from machine-created documents. Natural language processing enables document processing across finance, healthcare, retail, government, and other sectors. You can analyze digitally created documents to extract structured information from unstructured inputs. For handwritten documents, use Azure Document Intelligence to convert handwritten content to text before you apply natural language processing techniques.
Apply industry-agnostic natural language processing tasks for text processing. Named entity recognition (NER), classification, summarization, and relation extraction help you automatically process and analyze unstructured document content. These tasks work across domains and don't require industry-specific customization.
Build domain-specific models for specialized analysis. Examples of these tasks include risk stratification models for healthcare, ontology classification for knowledge management, and retail summarizations for product and customer data. Custom model training in Azure Language and Spark NLP helps improve accuracy for these domain-specific document formats.
Generate automated reports from structured data inputs. You can synthesize and generate comprehensive textual reports from structured data. This capability helps sectors like finance and compliance that require thorough documentation.
Enable search, translation, and analytics
Create knowledge graphs and enable semantic search through information retrieval. Natural language processing supports knowledge graph creation and semantic search, which lets systems interpret query meaning rather than rely on keyword matching only.
Support drug discovery and clinical trials with medical knowledge graphs. Natural language processing systems analyze clinical text. Medical knowledge graphs built from that text support drug discovery pipelines and clinical trial matching. These graphs connect entities like drugs, conditions, and outcomes to accelerate research workflows. Text analytics for health in Azure Language extracts medical entities, relations, and assertions that you can use to construct these graphs.
Translate text for conversational AI in customer-facing applications. Text translation enables conversational AI across multiple industries. You can build multilingual customer-facing applications that process and respond in the user's preferred language. Spark NLP provides translation capabilities directly. On Azure, use Azure Translator, which is a separate service from Azure Language.
Analyze sentiment and emotional intelligence for brand perception. Sentiment analysis helps you monitor brand perception and analyze customer feedback by surfacing positive, negative, and nuanced emotional signals from text.
Extend natural language processing to emerging domains
Build voice-activated interfaces for Internet of Things (IoT) and smart devices. Natural language processing handles the text output of speech recognition systems to understand user intent and extract meaning in IoT and smart device scenarios. Voice-activated scenarios require Azure Speech for speech-to-text conversion before natural language processing.
Adjust language output dynamically by using adaptive language models. Adaptive language models dynamically adjust language output to suit different audience comprehension levels, which supports educational content delivery and accessibility.
Detect phishing and misinformation through cybersecurity text analysis. Natural language processing analyzes communication patterns and language usage in real time to identify potential security threats in digital communication. This analysis helps detect phishing attempts and misinformation campaigns.
Evaluate Azure Language
Azure Language is a cloud-based service that provides natural language processing features for understanding and analyzing text. You can access it through the Foundry portal, REST APIs, and client libraries for Python, C#, Java, and JavaScript with no infrastructure to manage. For AI agent development, you can also access these capabilities through the Azure Language Model Context Protocol (MCP) server. You can access it as a remote server in the Microsoft Foundry tool catalog or as a local self-hosted server.
Prebuilt features
Prebuilt features require no model training and are ready to use:
NER: Identifies and categorizes entities in text into predefined types like people, organizations, locations, and dates.
PII detection: Identifies and redacts personally identifiable information (PII), including sensitive personal and health data, in text and transcribed conversations.
Language detection: Detects the language of a document across a wide range of languages and dialects.
Sentiment analysis and opinion mining: Identifies positive, negative, or neutral sentiment in text and links opinions to specific elements like product attributes or service aspects.
Key phrase extraction: Evaluates unstructured text and returns a list of main concepts and key phrases.
Summarization: Condenses documents and conversations by using extractive or abstractive approaches, which supports text, chat, and call center summarization.
Text analytics for health: Extracts and labels relevant health information from unstructured clinical text, including medical entities, relations, and assertions.
Train custom models
You can use customizable features to train models on your data to handle domain-specific natural language processing tasks:
- Custom named entity recognition (CNER): Build custom models to extract domain-specific entity categories from unstructured text. Use CNER when prebuilt NER categories don't cover your domain vocabulary.
Azure Language MCP server and agents
Note
The Azure Language MCP server and both the intent routing and exact question answering agents are in preview. Preview features don't include a service-level agreement (SLA), and we don't recommend them for production workloads. Some features might not be supported or might have limited capabilities. For more information, see Supplemental terms of use for Microsoft Azure previews.
Azure Language provides prebuilt agents and flexible deployment options for production natural language processing workloads:
Intent routing agent: Manages conversation flows. It understands user intentions and routes to accurate responses through deterministic, auditable logic. Use this agent when you need transparent, deterministic conversational routing.
Exact question answering agent: Provides reliable, word-for-word responses to business-critical questions while maintaining human oversight and quality control. Use this agent when response accuracy and consistency are essential.
You can access both agents through the Foundry tool catalog. For more information, see Azure Language MCP server and agents (preview).
The Azure Language MCP server supports multiple deployment options:
Remote cloud-hosted MCP server: The Foundry tool catalog lists this server. The server provides cloud-managed access to Azure Language capabilities and requires no local infrastructure.
Local self-hosted MCP server: Supports on-premises or self-managed deployments for compliance, security, or data residency requirements.
Containerized deployment: The following features support containerized deployment for scenarios that require local processing or air-gapped environments. For the full list of available containers and their availability status, see Azure AI containers support.
- Sentiment analysis
- Language detection
- Key phrase extraction
- NER
- PII detection
- CNER
- Text analytics for health
- Summarization (preview)
Evaluate Apache Spark with Spark NLP
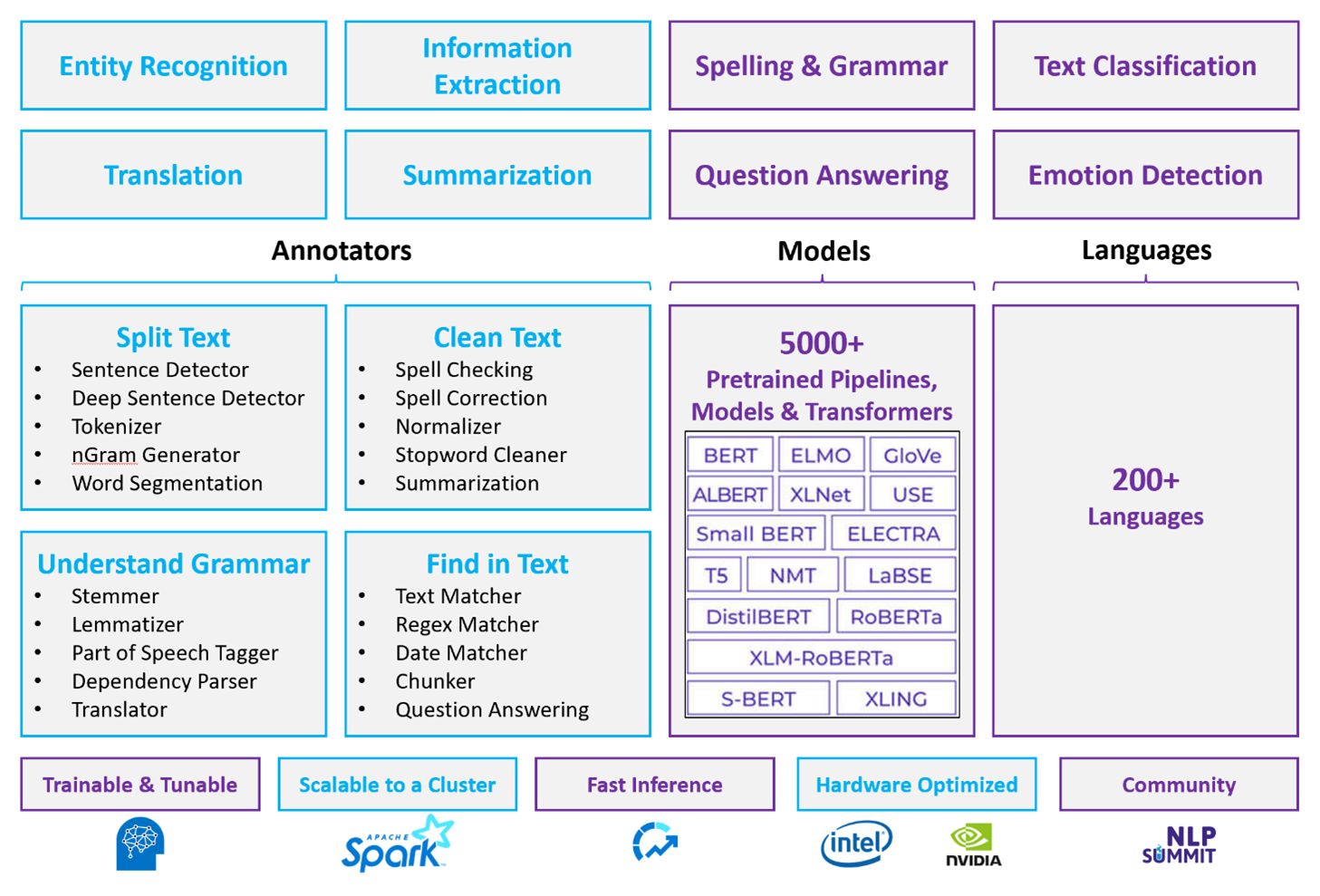
Apache Spark with Spark NLP is a distributed, open-source approach to natural language processing that operates at cluster scale. The Spark NLP platform architecture, performance, and prebuilt model ecosystem make it a strong option for large-scale, customizable natural language processing workloads on Azure Databricks or Fabric.
Understand platform and architecture
We recommend that you use Fabric or Azure Databricks for Apache Spark-based natural language processing workloads.
Apache Spark provides parallel, in-memory processing for big-data analytics. Fabric and Azure Databricks give you access to Apache Spark processing capabilities for large-scale natural language processing workloads.
Spark NLP operates as a native extension of Spark ML on data frames. This integration enables unified natural language processing and machine learning pipelines with improved performance on distributed clusters.
Spark NLP is an open-source library with Python, Java, and Scala support. The library provides functionality comparable to spaCy and Natural Language Toolkit (NLTK), including spell check, sentiment analysis, and document classification.

Apache®, Apache Spark, and the flame logo are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries. No endorsement by The Apache Software Foundation is implied by the use of these marks.
Assess performance and scalability
Public benchmarks show significant speed improvements over other natural language processing libraries. Compared to frameworks like spaCy and NLTK, Spark NLP demonstrates faster training and inference on distributed clusters. Custom models that Spark NLP trains reach accuracy levels that match those of other natural language processing frameworks, which makes it suitable for production workloads that require speed and precision.
Optimized builds for CPUs, GPUs, and Intel Xeon chips fully use Apache Spark clusters. These builds enable training and inference to scale efficiently across cluster nodes.
MPNet embeddings and ONNX support enable precise, context-aware processing. MPNet produces dense vector representations that capture semantic meaning, and ONNX support lets you import and run optimized models for inference.
Use prebuilt models and pipelines
Prebuilt deep learning models handle NER, document classification, and sentiment detection. The library comes with prebuilt deep learning models.
Pretrained language models support word, chunk, sentence, and document embeddings. The library includes pretrained language models that support word, chunk, sentence, and document embedding levels. These embeddings provide dense vector representations that enable downstream tasks like similarity search and classification.
Unified natural language processing and machine learning pipelines support document classification and risk prediction. The integration with Spark ML supports unified natural language processing and machine learning pipelines for tasks like document classification and risk prediction. With this unified approach, you can combine text processing with traditional machine learning models in a single pipeline, which reduces architectural complexity.
Address common natural language processing challenges
Both Azure Language and Apache Spark with Spark NLP face common challenges in natural language processing at scale. If you understand these challenges, you can plan resources, design pipelines, and set accuracy expectations before you commit to either option.
Resource processing
Processing free-form text requires significant computational resources and time. Free-form text documents are computationally expensive and time intensive to analyze. Every document requires tokenization, normalization, and model inference before it produces usable results.
Spark NLP workloads often require GPU compute deployment. For large-scale Spark NLP pipelines, GPU-accelerated clusters on Azure Databricks or Fabric provide the parallel processing power needed for training and inference. Optimizations like Llama 3.x model quantization help reduce memory footprint and improve throughput for these intensive tasks.
Azure Language requires throughput planning and quota management. The service handles resource management, but high-volume API calls require careful throughput planning. Monitor your request rates against service limits and rate limits to avoid throttling and ensure consistent processing performance.
Document standardization
Real-world documents rarely follow a consistent structure. This inconsistency creates challenges for extraction pipelines and requires deliberate strategies to maintain accuracy across sources.
Inconsistent formats: Without a standardized document format, extracting specific facts from free-form text can be difficult. For example, it can be a challenge to extract invoice numbers and dates from different vendors because field layouts, labels, and formatting vary across sources.
Custom model training: When you train custom models in Spark NLP and Azure Language, you can adapt to domain-specific document formats. When you train on representative samples of your actual documents, you can improve extraction accuracy for fields, entities, and patterns that prebuilt models don't handle well.
Data variety and complexity
Diverse document structures and linguistic nuances add complexity. Real-world text data comes in many formats, writing styles, and languages. Addressing these variations requires models that can handle ambiguity, slang, abbreviations, and domain-specific terminology while maintaining accuracy.
MPNet embeddings in Spark NLP provide enhanced contextual understanding. MPNet embeddings capture contextual relationships between words and phrases, which helps Spark NLP pipelines handle nuanced text more effectively. These embeddings produce dense vector representations that preserve semantic meaning across different document formats.
Custom models in Azure Language adapt to domain-specific text patterns. With CNER you can train models on your own labeled data to recognize patterns specific to your domain. This approach improves reliability by teaching the model to recognize entities and categories that prebuilt models miss.
Apply key selection criteria
Use the following criteria to determine which Azure natural language processing option best fits your requirements. Each criterion describes a workload characteristic and identifies the service that addresses it.
Managed natural language processing capabilities: Use Azure Language APIs for entity recognition, intent identification, topic detection, or sentiment analysis. These capabilities are available as managed services with minimal setup, and you don't need to provision or manage any infrastructure.
Prebuilt or pretrained models: Use Azure Language if you plan to use prebuilt or pretrained models without managing infrastructure. This approach suits small to medium datasets and standard natural language processing tasks where prebuilt models deliver sufficient accuracy. It provides automatic scaling, built-in security, and pay-per-call pricing without cluster management overhead.
Custom model training on large text datasets: Use Azure Databricks or Fabric with Spark NLP. These platforms provide the computational power and flexibility that you need for extensive model training on large text datasets. You can also download models through Spark NLP, including Llama 3.x and MPNet.
Low-level natural language processing primitives: Use Azure Databricks or Fabric with Spark NLP for tokenization, stemming, lemmatization, and TF-IDF. Alternatively, use an open-source library like spaCy or NLTK. Azure Language in Foundry Tools uses tokenization internally as part of its model pipeline, but it doesn't expose these steps as standalone, controllable APIs.
Build natural language processing pipelines by using Spark NLP
Spark NLP follows the same development pattern as traditional Spark ML models when you run a natural language processing pipeline. You manage trained models by using MLflow for experiment tracking and production deployment.

Assemble core pipeline components
A Spark NLP pipeline chains annotators in sequence. Each annotator transforms the output of the previous stage and builds from raw text to semantic vectors.
DocumentAssembler is the entry point for every Spark NLP pipeline. Use
setCleanupModeto apply optional text preprocessing, like HTML tag removal or whitespace normalization, before downstream annotators run.SentenceDetector identifies sentence boundaries in the assembled document. It returns detected sentences either as an
Arraywithin a single row or as separate rows, depending on your pipeline configuration. Accurate sentence detection is important because many downstream annotators operate at the sentence level.Tokenizer divides raw text into discrete tokens like words, numbers, and symbols. If the default rules are insufficient for your domain, add custom rules to handle specialized vocabulary, hyphenated terms, or domain-specific patterns.
Normalizer refines tokens by applying regular expressions and dictionary transformations. It cleans text to reduce noise before embedding. For example, you can strip accents, convert to lowercase, or apply custom dictionary mappings to standardize terminology.
WordEmbeddings maps tokens to semantic vectors for contextual processing. Each token is represented as a dense vector that captures its meaning relative to other tokens. Unresolved tokens that don't appear in the embeddings vocabulary default to zero vectors.
Manage models by using MLflow
Spark NLP uses Spark MLlib pipelines with native MLflow support. You don't need to write custom serialization or integration code.
MLflow manages experiment tracking, model versioning, and deployment. You can log pipeline parameters, metrics, and artifacts during training runs. MLflow tracks each experiment, so you can compare results across iterations and reproduce successful configurations.
MLflow integrates directly with Azure Databricks and Fabric. On Azure Databricks, MLflow comes preinstalled and integrates tightly with the workspace. Fabric also provides a built-in MLflow experience with native experiment tracking and autologging, so you don't need to install MLflow separately. If you run Spark NLP on another Apache Spark-based environment, you can install MLflow separately and configure it to track experiments against a remote tracking server.
Use the MLflow Model Registry to promote models to production and maintain governance. The Model Registry provides a central repository to manage model versions across your natural language processing pipelines. In classic deployments, transition models through stages like staging, production, and archived. On Azure Databricks, newer deployments use Models in Unity Catalog, which replaces fixed stages with custom aliases and tags for more flexible life cycle management. On Fabric, the workspace provides its own MLflow-based model registry.
Capability matrix
The following tables summarize the key differences in capabilities between Spark NLP on Azure Databricks or Fabric and Azure Language.
General capabilities
| Capability | Spark NLP (Azure Databricks or Fabric) | Azure Language |
|---|---|---|
| Pretrained models as a service | Yes | Yes |
| REST API | Yes | Yes |
| Programmability | Python, Scala | See Supported programming languages. |
| Supports processing of large datasets and large documents | Yes | Limited 1 |
1. Azure Language has per-request document size limits that vary by mode. Synchronous requests support up to 5,120 characters per document, and asynchronous requests support up to 125,000 characters per document. Both modes support up to 25 documents per API call. You can process large dataset volumes through batching and pagination, but individual documents that exceed the character limit for your chosen mode require chunking. For more information, see Data and rate limits for Azure Language.
Annotator capabilities
| Capability | Spark NLP (Azure Databricks or Fabric) | Azure Language |
|---|---|---|
| Sentence detector | Yes | No |
| Deep sentence detector | Yes | No |
| Tokenizer | Yes | Internal only (not exposed as a standalone API) |
| N-gram generator | Yes | No |
| Word segmentation | Yes | Yes |
| Stemmer | Yes | No |
| Lemmatizer | Yes | No |
| Part-of-speech tagging | Yes | No |
| Dependency parser | Yes | No |
| Translation | Yes | No |
| Stopword cleaner | Yes | No |
| Spell correction | Yes | No |
| Normalizer | Yes | Yes |
| Text matcher | Yes | No |
| TF-IDF | Yes | No |
| Regular expression matcher | Yes | Limited |
| Date matcher | Yes | Limited |
| Chunker | Yes | No |
High-level natural language processing capabilities
| Capability | Spark NLP (Azure Databricks or Fabric) | Azure Language |
|---|---|---|
| Spell check | Yes | No |
| Summarization | Yes | Yes |
| Question answering | Yes | Yes |
| Sentiment detection | Yes | Yes |
| Emotion detection | Yes | Limited 2 |
| Token classification | Yes | Limited 3 |
| Text classification | Yes | Limited 3 |
| Text representation | Yes | No |
| NER | Yes | Yes (prebuilt). CNER is available through custom models. 3 |
| Language detection | Yes | Yes |
| Supports languages other than English | Yes. See Spark NLP supported languages. | Yes. See Azure Language supported languages. |
2. Azure Language supports opinion mining, which identifies sentiments linked to specific aspects of text but doesn't provide dedicated emotion detection (like joy, anger, or sadness classification).
3. Available through custom models. You train CNER or custom entity recognition models on your own labeled data.
Contributors
Microsoft maintains this article. The following contributors wrote this article.
Principal authors:
- Ananya Ghosh Chowdhury | Principal Cloud Solution Architect
- Kranthi Manchikanti | Senior AI Solutions Engineer
Other contributors:
- Freddy Ayala | Cloud Solution Architect
- Tincy Elias | Senior Cloud Solution Architect
- Moritz Steller | Senior Cloud Solution Architect
To see nonpublic LinkedIn profiles, sign in to LinkedIn.
Next steps
Related resources
Azure Language documentation:
Spark NLP documentation:
Azure components:
Learn resources: