ضبط التطبيقات وقواعد البيانات للأداء في قاعدة بيانات Azure SQL ومثيل Azure SQL المُدار
ينطبق على: Azure SQL Database Azure SQL Managed Instance
Azure SQL Database Azure SQL Managed Instance
بمجرد تحديد مشكلة الأداء التي تواجهها مع قاعدة بيانات Azure SQL ومثيل Azure SQL المُدار، تم تصميم هذه المقالة لمساعدتك على:
- اضبط تطبيقك وطبِّق بعض أفضل الممارسات التي يمكنها تحسين الأداء.
- ضبط قاعدة البيانات عن طريق تغيير الفهارس والاستعلامات للعمل بكفاءة أكبر مع البيانات.
تفترض هذه المقالة أنك قد عملت بالفعل من خلال توصيات مستشار قاعدة البيانات في قاعدة بيانات Azure SQL وتوصيات الضبط التلقائي لقاعدة بيانات Azure SQL، إن أمكن. يفترض أيضاً أنك قد راجعت نظرة عامة على المراقبة والضبط والمقالات ذات الصلة المتعلقة باستكشاف مشكلات الأداء وإصلاحها. بالإضافة إلى ذلك، تفترض هذه المقالة أنه ليس لديك موارد وحدة المعالجة المركزية، أو مشكلة الأداء المتعلقة بالتشغيل والتي يمكن حلها عن طريق زيادة حجم الحساب، أو طبقة الخدمة لتوفير المزيد من الموارد لقاعدة البيانات الخاصة بك.
ضبط التطبيق الخاص بك
في SQL Server المحلي التقليدي غالبًا ما يتم فصل عملية التخطيط الأولي للقدرة عن عملية تشغيل تطبيق في الإنتاج. يتم شراء تراخيص الأجهزة والمنتجات أولاً، ويتم ضبط الأداء بعد ذلك. عند استخدام Azure SQL من الأفضل دمج عملية تشغيل تطبيق وضبطه. باستخدام نموذج الدفع مقابل السعة عند الطلب يمكنك ضبط التطبيق الخاص بك لاستخدام الحد الأدنى من الموارد المطلوبة الآن، بدلاً من الإفراط في التزويد بالأجهزة بناءً على تخمينات خطط النمو المستقبلية لأحد التطبيقات، والتي غالبًا ما تكون غير صحيحة. قد يختار بعض العملاء عدم ضبط أحد التطبيقات، وبدلاً من ذلك يختارون الإفراط في توفير موارد الأجهزة. قد تكون هذه الطريقة فكرة جيدة إذا كنت لا ترغب في تغيير أحد التطبيقات الرئيسية خلال فترة الانشغال. ولكن يمكن أن يؤدي ضبط تطبيق ما إلى تقليل متطلبات الموارد وتقليل الفواتير الشهرية عند استخدام طبقات الخدمة في قاعدة بيانات Azure SQL و Azure SQL Managed Instance.
خصائص التطبيق
على الرغم من أن قاعدة بيانات Azure SQL وطبقات خدمة مثيل Azure SQL المُدارة مصممة لتحسين استقرار الأداء والقدرة على التنبؤ لتطبيق ما، ولكن يمكن أن تساعدك بعض أفضل الممارسات في ضبط تطبيقك للاستفادة بشكل أفضل من الموارد بحجم حساب. على الرغم من أن العديد من التطبيقات تتمتع بمكاسب كبيرة في الأداء بمجرد التبديل إلى حجم حوسبة أعلى أو مستوى خدمة أعلى، فإن بعض التطبيقات تحتاج إلى ضبط إضافي للاستفادة من مستوى أعلى من الخدمة. لزيادة الأداء: ضع في اعتبارك ضبط تطبيق إضافي للتطبيقات التي لها هذه الخصائص:
التطبيقات ذات الأداء البطيء بسبب سلوك "الدردشة"
تقوم تطبيقات Chatty بإجراء عمليات مفرطة للوصول إلى البيانات تكون حساسة لزمن انتقال الشبكة. قد تحتاج إلى تعديل هذه الأنواع من التطبيقات لتقليل عدد عمليات الوصول إلى البيانات إلى قاعدة البيانات. على سبيل المثال، يمكنك تحسين أداء التطبيق باستخدام تقنيات مثل تجميع الاستعلامات المخصصة أو نقل الاستعلامات إلى الإجراءات المخزنة. لمزيد من المعلومات راجع استعلامات مجمعة.
قواعد البيانات التي بها أعباء عمل مكثفة لا يمكن أن يدعمها جهاز واحد بالكامل
قد تستفيد قواعد البيانات التي تتجاوز موارد أعلى حجم لحساب Premium من توسيع نطاق حمولة العمل. لمزيد من المعلومات راجع التجزئة عبر قواعد البيانات والتقسيم الوظيفي.
التطبيقات التي تحتوي على استعلامات دون المستوى الأمثل
قد لا تستفيد التطبيقات، خاصة تلك الموجودة في طبقة الوصول إلى البيانات، التي تحتوي على استعلامات مضبوطة بشكل سيئ من حجم حساب أعلى. تتضمن هذا الاستعلامات التي تفتقر إلى عبارة WHERE أو التي تحتوي على فهارس مفقودة أو بها إحصائيات قديمة. تستفيد هذه التطبيقات من تقنيات ضبط أداء الاستعلام القياسي. لمزيد من المعلومات راجع الفهارس المفقودة وضبط الاستعلام والتلميح.
التطبيقات التي تحتوي على تصميم وصول دون المستوى الأمثل إلى البيانات
قد لا تستفيد التطبيقات التي تحتوي على مشكلات متعلقة بالتزامن في الوصول إلى البيانات، مثل حالة الجمود، من زيادة حجم الحوسبة. ضع في اعتبارك تقليل الرحلات ذهابًا وإيابًا مقابل قاعدة البيانات عن طريق تخزين البيانات مؤقتًا على جانب العميل باستخدام خدمة Azure Caching أو تقنية تخزين مؤقت أخرى. راجع التخزين المؤقت لطبقة التطبيق.
لمنع تكرار حدوث حالات التوقف التام في Azure SQL Database، راجع تحليل حالات التوقف التام ومنعها في Azure SQL Database. بالنسبة إلى Azure SQL Managed Instance، راجع Deadlocks في دليل تأمين العمليات وتعيين إصدار الصفوف.
ضبط قاعدة البيانات الخاصة بك
في هذا القسم نلقي نظرة على بعض الأساليب التي يمكنك استخدامها لضبط قاعدة البيانات للحصول على أفضل أداء لتطبيقك، وتشغيلها بأقل حجم ممكن للحوسبة. تتطابق بعض هذه الأساليب مع أفضل ممارسات ضبط SQL Server التقليدية، لكن البعض الآخر خاص بقاعدة بيانات Azure SQL ومثيل Azure SQL المُدار. في بعض الحالات، يمكنك فحص الموارد المستهلكة لقاعدة بيانات للعثور على مناطق لمزيد من ضبط تقنيات SQL Server التقليدية وتوسيع نطاقها للعمل في قاعدة بيانات Azure SQL ومثيل Azure SQL المُدار.
تحديد وإضافة الفهارس المفقودة
هناك مشكلة شائعة في أداء قاعدة بيانات OLTP تتعلق بتصميم قاعدة البيانات الفعلية. في كثير من الأحيان يتم تصميم مخططات قاعدة البيانات وشحنها دون اختبار على نطاق واسع (سواء في التحميل أو في حجم البيانات). لسوء الحظ، قد يكون أداء خطة الاستعلام مقبولاً على نطاق صغير ولكنه يتدهور بشكل كبير في ظل أحجام البيانات على مستوى الإنتاج. المصدر الأكثر شيوعًا لهذه المشكلة هو عدم وجود فهارس مناسبة لتلبية عوامل التصفية أو القيود الأخرى في استعلام. في كثير من الأحيان تظهر الفهارس المفقودة كمسح للجدول عندما يكون البحث عن فهرس كافيًا.
في هذا المثال تستخدم خطة الاستعلام المحددة فحصًا عندما يكون البحث كافيًا:
DROP TABLE dbo.missingindex;
CREATE TABLE dbo.missingindex (col1 INT IDENTITY PRIMARY KEY, col2 INT);
DECLARE @a int = 0;
SET NOCOUNT ON;
BEGIN TRANSACTION
WHILE @a < 20000
BEGIN
INSERT INTO dbo.missingindex(col2) VALUES (@a);
SET @a += 1;
END
COMMIT TRANSACTION;
GO
SELECT m1.col1
FROM dbo.missingindex m1 INNER JOIN dbo.missingindex m2 ON(m1.col1=m2.col1)
WHERE m1.col2 = 4;
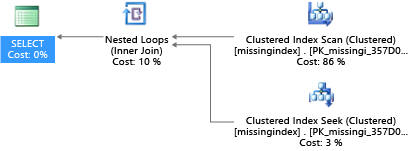
يمكن أن تساعدك قاعدة بيانات Azure SQL ومثيل Azure SQL المُدار في العثور على شروط الفهرس المفقودة الشائعة وإصلاحها. تبحث DMVs المضمنة في قاعدة بيانات Azure SQL ومثيلAzure SQL المُدار في تجميعات الاستعلام التي يؤدي فيها الفهرس إلى تقليل التكلفة المقدرة لتشغيل استعلام بشكل كبير. أثناء تنفيذ الاستعلام يتتبع محرك قاعدة البيانات عدد المرات التي يتم فيها تنفيذ كل خطة استعلام، ويتتبع الفجوة المقدرة بين خطة الاستعلام المنفذة والخطة المتخيلة حيث يوجد هذا الفهرس. يمكنك استخدام DMVs هذه للتخمين بسرعة أي التغييرات التي تطرأ على تصميم قاعدة البيانات الفعلية قد تؤدي إلى تحسين التكلفة الإجمالية لحمل العمل لقاعدة البيانات وحمولة العمل الحقيقي الخاص بها.
يمكنك استخدام هذا الاستعلام لتقييم الفهارس المفقودة المحتملة:
SELECT
CONVERT (varchar, getdate(), 126) AS runtime
, mig.index_group_handle
, mid.index_handle
, CONVERT (decimal (28,1), migs.avg_total_user_cost * migs.avg_user_impact *
(migs.user_seeks + migs.user_scans)) AS improvement_measure
, 'CREATE INDEX missing_index_' + CONVERT (varchar, mig.index_group_handle) + '_' +
CONVERT (varchar, mid.index_handle) + ' ON ' + mid.statement + '
(' + ISNULL (mid.equality_columns,'')
+ CASE WHEN mid.equality_columns IS NOT NULL
AND mid.inequality_columns IS NOT NULL
THEN ',' ELSE '' END + ISNULL (mid.inequality_columns, '') + ')'
+ ISNULL (' INCLUDE (' + mid.included_columns + ')', '') AS create_index_statement
, migs.*
, mid.database_id
, mid.[object_id]
FROM sys.dm_db_missing_index_groups AS mig
INNER JOIN sys.dm_db_missing_index_group_stats AS migs
ON migs.group_handle = mig.index_group_handle
INNER JOIN sys.dm_db_missing_index_details AS mid
ON mig.index_handle = mid.index_handle
ORDER BY migs.avg_total_user_cost * migs.avg_user_impact * (migs.user_seeks + migs.user_scans) DESC
في هذا المثال، نتج عن طلب البحث هذا الاقتراح:
CREATE INDEX missing_index_5006_5005 ON [dbo].[missingindex] ([col2])
بعد إنشائه يختار بيان SELECT نفسه خطة مختلفة تستخدم البحث بدلاً من الفحص، ثم تنفذ الخطة بكفاءة أكبر:
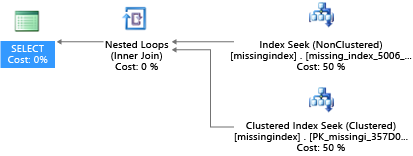
الفكرة الرئيسية هي أن سعة الإدخال / الإخراج (IO) لنظام سلعي مشترك أكثر محدودية من قدرة جهاز خادم مخصص. هناك علاوة على تقليل الإدخال / الإخراج غير الضروري لتحقيق أقصى استفادة من النظام في موارد كل حجم حساب لطبقات الخدمة. يمكن أن تؤدي خيارات تصميم قاعدة البيانات المادية المناسبة إلى تحسين وقت الاستجابة للاستعلامات الفردية بشكل كبير، وتحسين إنتاجية الطلبات المتزامنة التي يتم التعامل معها لكل وحدة مقياس، وتقليل التكاليف المطلوبة لتلبية الاستعلام.
لمزيد من المعلومات عن ضبط الفهارس باستخدام طلبات الفهرس المفقودة، راجع ضبط الفهارس غير متفاوتة المسافات مع اقتراحات الفهرس المفقود.
ضبط الاستعلام والتلميح
مُحسِّن الاستعلام في قاعدة بيانات Azure SQL وAzure SQL المُدار يشبه مُحسِّن استعلام SQL Server التقليدي. تنطبق أيضًا معظم أفضل الممارسات لضبط الاستعلامات وفهم قيود نموذج المنطق لمحسن الاستعلام على قاعدة بيانات Azure SQL ومثيلAzure SQL المُدار. إذا قمت بضبط الاستعلامات في قاعدة بيانات Azure SQL ومثيلAzure SQL المُدار، فقد تحصل على فائدة إضافية تتمثل في تقليل طلبات الموارد الإجمالية. قد يكون التطبيق الخاص بك قادرًا على العمل بتكلفة أقل من المكافئ غير المضبوط لأنه يمكن تشغيله بحجم حساب أقل.
أحد الأمثلة الشائعة في SQL Server والذي ينطبق أيضًا على قاعدة بيانات Azure SQL وAzure SQL المُدار هو كيفية قيام مُحسِّن الاستعلام بـ "شم" المعلمات. أثناء التحويل البرمجي يقوم مُحسِّن الاستعلام بتقييم القيمة الحالية للمعلمة لتحديد ما إذا كان بإمكانها إنشاء خطة استعلام أكثر مثالية. على الرغم من أن هذه الإستراتيجية يمكن أن تؤدي غالبًا إلى خطة استعلام تكون أسرع بشكل ملحوظ من الخطة التي تم تجميعها بدون قيم معلمات معروفة، إلا أنها تعمل حاليًا بشكل غير كامل في كل من SQL Server وقاعدة بيانات Azure SQL ومثيل Azure SQL المُدار. في بعض الأحيان لا يتم استنشاق المعلمة، وأحياناً يتم استنشاق المعلمة ولكن الخطة المُنشأة تكون دون المستوى الأمثل لمجموعة كاملة من قيم المعلمات في حمل العمل. تقوم Microsoft بتضمين تلميحات الاستعلام (التوجيهات) بحيث يمكنك تحديد النية بشكل أكثر تعمدًا وتجاوز السلوك الافتراضي لاستنشاق المعلمات. في كثير من الأحيان، إذا كنت تستخدم التلميحات يمكنك إصلاح الحالات التي يكون فيها سلوك SQL Server الافتراضي وقاعدة بيانات Azure SQL وAzure SQL Managed Instance غير مثالي بالنسبة لأحمال عمل عميل معينة.
يوضح المثال التالي كيف يمكن لمعالج الاستعلام إنشاء خطة دون المستوى الأمثل لمتطلبات الأداء والموارد. يوضح هذا المثال، أيضًا أنه إذا كنت تستخدم تلميح استعلام فيمكنك تقليل وقت تشغيل الاستعلام ومتطلبات الموارد لقاعدة البيانات الخاصة بك:
DROP TABLE psptest1;
CREATE TABLE psptest1(col1 int primary key identity, col2 int, col3 binary(200));
DECLARE @a int = 0;
SET NOCOUNT ON;
BEGIN TRANSACTION
WHILE @a < 20000
BEGIN
INSERT INTO psptest1(col2) values (1);
INSERT INTO psptest1(col2) values (@a);
SET @a += 1;
END
COMMIT TRANSACTION
CREATE INDEX i1 on psptest1(col2);
GO
CREATE PROCEDURE psp1 (@param1 int)
AS
BEGIN
INSERT INTO t1 SELECT * FROM psptest1
WHERE col2 = @param1
ORDER BY col2;
END
GO
CREATE PROCEDURE psp2 (@param2 int)
AS
BEGIN
INSERT INTO t1 SELECT * FROM psptest1 WHERE col2 = @param2
ORDER BY col2
OPTION (OPTIMIZE FOR (@param2 UNKNOWN))
END
GO
CREATE TABLE t1 (col1 int primary key, col2 int, col3 binary(200));
GO
يُنشئ كود الإعداد جدولاً يحتوي على توزيع منحرف للبيانات. تختلف خطة الاستعلام المثلى بناءً على المعلمة المحددة. لسوء الحظ، لا يقوم سلوك التخزين المؤقت للخطة دائمًا بإعادة ترجمة الاستعلام بناءً على قيمة المعلمة الأكثر شيوعًا. لذلك، من الممكن تخزين خطة دون المستوى الأمثل مؤقتاً واستخدامها للعديد من القيم، حتى في حالة كون خطة مختلفة خياراً أفضل في المتوسط. ثم تقوم خطة الاستعلام بإنشاء إجرائين مُخزَّنيْن متطابقين، باستثناء أن أحدهما يحتوي على تلميح استعلام خاص.
-- Prime Procedure Cache with scan plan
EXEC psp1 @param1=1;
TRUNCATE TABLE t1;
-- Iterate multiple times to show the performance difference
DECLARE @i int = 0;
WHILE @i < 1000
BEGIN
EXEC psp1 @param1=2;
TRUNCATE TABLE t1;
SET @i += 1;
END
نوصيك بالانتظار لمدة 10 دقائق على الأقل قبل أن تبدأ الجزء 2 من المثال، بحيث تكون النتائج مميزة في بيانات القياس عن بُعد الناتجة.
EXEC psp2 @param2=1;
TRUNCATE TABLE t1;
DECLARE @i int = 0;
WHILE @i < 1000
BEGIN
EXEC psp2 @param2=2;
TRUNCATE TABLE t1;
SET @i += 1;
END
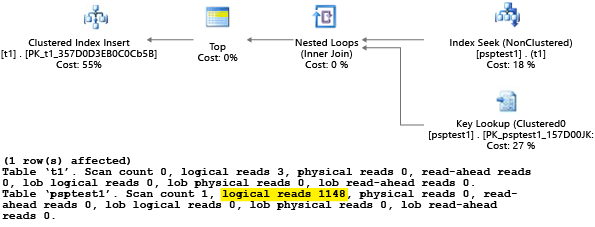
يحاول كل جزء من هذا المثال تشغيل جملة إدراج ذات معلمات 1000 مرة (لتوليد حمولة كافية لاستخدامها كمجموعة بيانات اختبار). عند تنفيذ الإجراءات المخزنة يفحص معالج الاستعلام قيمة المعلمة التي تم تمريرها إلى الإجراء أثناء التجميع الأول له (المعلمة "استنشاق"). يقوم المعالج بتخزين الخطة الناتجة مؤقتًا واستخدامها في الاستدعاءات اللاحقة، حتى إذا كانت قيمة المعلمة مختلفة. قد لا يتم استخدام الخطة المثلى في جميع الحالات. تحتاج أحيانًا إلى إرشاد المُحسِّن لاختيار خطة أفضل للحالة المتوسطة بدلاً من الحالة المحددة من وقت تجميع الاستعلام لأول مرة. في هذا المثال، تنشئ الخطة الأولية خطة "فحص" تقرأ جميع الصفوف للعثور على كل قيمة تطابق المعلمة:

نظراً لأننا نفذنا الإجراء باستخدام القيمة 1، كانت الخطة الناتجة مثالية للقيمة 1 ولكنها كانت دون المستوى الأمثل لجميع القيم الأخرى في الجدول. من المحتمل ألا تكون النتيجة هي ما تريده إذا اخترت كل خطة بشكل عشوائي، لأن الخطة تعمل بشكل أبطأ وتستخدم المزيد من الموارد.
إذا أجريت الاختبار مع ضبط SET STATISTICS IOset toON فسيتم عمل المسح المنطقي في هذا المثال خلف الكواليس. يمكنك أن ترى أن هناك 1148 قراءة تم إجراؤها بواسطة الخطة (وهو أمر غير فعال إذا كان متوسط الحالة هو إرجاع صف واحد فقط):

يستخدم الجزء الثاني من المثال تلميح استعلام لإخبار المُحسِّن باستخدام قيمة محددة أثناء عملية الترجمة. في هذه الحالة، يفرض على معالج الاستعلام تجاهل القيمة التي تم تمريرها كمعامل وبدلاً من ذلك يفترض UNKNOWN. يشير هذا إلى قيمة لها متوسط التردد في الجدول (تجاهل الانحراف). الخطة الناتجة هي خطة قائمة على البحث تكون أسرع وتستخدم موارد أقل، في المتوسط، من الخطة الموجودة في الجزء 1 من هذا المثال:
يمكنك مشاهدة التأثير في الجدول sys.resource_stats (هناك تأخير من وقت تنفيذ الاختبار ووقت ملء البيانات بالجدول). في هذا المثال، تم تنفيذ الجزء 1 أثناء النافذة الزمنية 22:25:00، والجزء الثاني تم تنفيذه في الساعة 22:35:00. استخدمت النافذة الزمنية السابقة موارد أكثر في تلك النافذة الزمنية مقارنة بالنافذة اللاحقة (بسبب تحسينات كفاءة الخطة).
SELECT TOP 1000 *
FROM sys.resource_stats
WHERE database_name = 'resource1'
ORDER BY start_time DESC

ملاحظة
على الرغم من أن الحجم في هذا المثال صغير عن قصد، إلا أن تأثير المعلمات دون المثالية يمكن أن يكون كبيراً، خاصة على قواعد البيانات الأكبر. يمكن أن يكون الفرق، في الحالات القصوى، بين ثوانٍ للحالات السريعة وساعات للحالات البطيئة.
يمكنك فحص sys.resource_stats لتحديد ما إذا كان المورد الخاص بالاختبار يستخدم موارد أكثر أو أقل من اختبار آخر. عند مقارنة البيانات، افصل بين توقيت الاختبارات بحيث لا تكون في نفس نافذة الخمس دقائق في عرض sys.resource_stats . الهدف من التمرين هو تقليل المبلغ الإجمالي للموارد المستخدمة، وليس تقليل موارد الذروة. بشكل عام، يؤدي تحسين جزء من التعليمات البرمجية لوقت الاستجابة أيضًا إلى تقليل استهلاك الموارد. تأكد من أن التغييرات التي تجريها على أحد التطبيقات ضرورية، وأن التغييرات لا تؤثر سلبًا على تجربة العميل لشخص قد يستخدم تلميحات الاستعلام في التطبيق.
إذا كان حمل العمل يحتوي على مجموعة من الاستعلامات المتكررة فغالبًا ما يكون من المنطقي التقاط والتحقق من صحة اختيارات خطتك، لأنها تقود وحدة حجم الموارد الدنيا المطلوبة لاستضافة قاعدة البيانات. بعد التحقق من صحتها أعد فحص الخطط من حين لآخر لمساعدتك على التأكد من أنها لم تتدهور. يمكنك معرفة المزيد حول تلميحات الاستعلام (Transact-SQL).
معماريات قواعد بيانات كبيرة جدًا
قبل إصدار طبقة الخدمة Hyperscale لقواعد البيانات الفردية في قاعدة بيانات Azure SQL، اعتاد العملاء الوصول إلى حدود السعة لقواعد البيانات الفردية. لا تزال حدود السعة هذه موجودة لقواعد البيانات المجمعة في التجمعات المرنة لقاعدة بيانات Azure SQL وقواعد بيانات المثيلات في مثيلات Azure SQL المُدارة. يناقش القسمان التاليان خيارين لحل المشكلات المتعلقة بقواعد البيانات الكبيرة جدًا في قاعدة بيانات Azure SQL ومثيل Azure SQL المُدار عندما لا يمكنك استخدام طبقة خدمة Hyperscale.
تجزئة عبر قاعدة البيانات
نظرًا لأن قاعدة بيانات Azure SQL ومثيل Azure SQL المُدار يعملان على أجهزة سلعة، فإن حدود السعة لقاعدة بيانات فردية أقل من تلك الخاصة بتثبيت خادم SQL محلي تقليدي. يستخدم بعض العملاء تقنيات التجزئة لنشر عمليات قاعدة البيانات عبر قواعد بيانات متعددة عندما لا تتلاءم العمليات مع حدود قاعدة البيانات الفردية في قاعدة بيانات Azure SQL ومثيل Azure SQL المُدار. يقوم معظم العملاء الذين يستخدمون تقنيات التجزئة في قاعدة بياناتAzure SQL وAzure SQL المُدار بتقسيم بياناتهم على بُعد واحد عبر قواعد بيانات متعددة. بالنسبة لهذا الأسلوب، يجب أن تفهم أن تطبيقات OLTP غالبًا ما تقوم بإجراء معاملات تنطبق على صف واحد فقط أو على مجموعة صغيرة من الصفوف في المخطط.
ملاحظة
توفر قاعدة بيانات Azure SQL الآن مكتبة للمساعدة في التجزئة. لمزيد من المعلومات راجع نظرة عامة على مكتبة عميل Elastic Database.
على سبيل المثال، إذا كانت قاعدة البيانات تحتوي على اسم العميل، والطلب، وتفاصيل الطلب (مثل قاعدة بيانات Northwind التقليدية التي تأتي مع SQL Server)، فيمكنك تقسيم هذه البيانات إلى قواعد بيانات متعددة عن طريق تجميع العميل مع معلومات تفاصيل الطلب والطلب ذات الصلة. يمكنك ضمان بقاء بيانات العميل في قاعدة بيانات فردية. سيقوم التطبيق بتقسيم العملاء المختلفين عبر قواعد البيانات، وتوزيع الحمل بشكل فعال عبر قواعد بيانات متعددة. باستخدام التجزئة، لا يمكن للعملاء فقط تجنب الحد الأقصى لحجم قاعدة البيانات، ولكن يمكن أيضًا لقاعدة بيانات Azure SQL وAzure SQL المُدارة معالجة أحمال العمل التي تكون أكبر بكثير من حدود أحجام الحوسبة المختلفة، طالما أن كل قاعدة بيانات فردية تناسب خدمتها حدود الطبقة.
على الرغم من أن تقسيم قاعدة البيانات لا يقلل من سعة الموارد الإجمالية للحل، إلا أنه فعال للغاية في دعم الحلول الكبيرة جدًا التي تنتشر عبر قواعد بيانات متعددة. يمكن تشغيل كل قاعدة بيانات بحجم حساب مختلف لدعم قواعد بيانات كبيرة جدًا "فعالة" ذات متطلبات موارد عالية.
التقسيم الوظيفي
غالبًا ما يجمع المستخدمون العديد من الوظائف في قاعدة بيانات فردية. على سبيل المثال، إذا كان لتطبيق ما منطقًا لإدارة المخزون لمتجر فقد يكون لقاعدة البيانات منطق مرتبط بالمخزون، وتتبع أوامر الشراء، والإجراءات المخزنة، وطرق العرض المفهرسة أو الفعلية التي تدير تقارير نهاية الشهر. تسهل هذه التقنية إدارة قاعدة البيانات لعمليات مثل النسخ الاحتياطي، ولكنها تتطلب أيضًا تحديد حجم الجهاز للتعامل مع الحمل الأقصى عبر جميع وظائف التطبيق.
إذا كنت تستخدم بنية قابلة للتوسيع في قاعدة بيانات Azure SQL وAzure SQL Managed Instance، فمن الأفضل تقسيم الوظائف المختلفة لتطبيق ما إلى قواعد بيانات مختلفة. باستخدام هذه التقنية يتم قياس كل تطبيق بشكل مستقل. عندما يصبح التطبيق أكثر انشغالًا (ويزداد الحمل على قاعدة البيانات)، يمكن للمسؤول اختيار أحجام حساب مستقلة لكل وظيفة في التطبيق. في الحد الأقصى، باستخدام هذه البنية، يمكن أن يكون التطبيق أكبر من قدرة آلة سلعة واحدة على التعامل معها لأن الحمل منتشر عبر أجهزة متعددة.
استفسارات الدُفعات
بالنسبة للتطبيقات التي تصل إلى البيانات باستخدام استعلام مخصص كبير الحجم ومتكرر ومخصص، يتم إنفاق قدر كبير من وقت الاستجابة على اتصال الشبكة بين طبقة التطبيق وطبقة قاعدة البيانات. حتى عندما يكون كل من التطبيق وقاعدة البيانات في نفس مركز البيانات، فقد يتم تضخيم زمن انتقال الشبكة بين الاثنين من خلال عدد كبير من عمليات الوصول إلى البيانات. لتقليل الرحلات ذهابًا وإيابًا على الشبكة لعمليات الوصول إلى البيانات، ضع في اعتبارك استخدام خيار إما تجميع الاستعلامات المخصصة، أو تجميعها كإجراءات مخزنة. إذا قمت بتجميع الاستعلامات المخصصة، فيمكنك إرسال استعلامات متعددة كدفعة واحدة كبيرة في رحلة واحدة إلى قاعدة البيانات. إذا قمت بتجميع استعلامات مخصصة في إجراء مخزن، يمكنك تحقيق نفس النتيجة كما لو قمت بتجميعها. يمنحك استخدام إجراء مُخزَّن أيضًا ميزة زيادة فرص التخزين المؤقت لخطط الاستعلام في قاعدة البيانات حتى تتمكن من استخدام الإجراء المخزن مرة أخرى.
بعض التطبيقات كثيفة الكتابة. في بعض الأحيان، يمكنك تقليل إجمالي تحميل الإدخال / الإخراج على قاعدة بيانات من خلال التفكير في كيفية تجميع عمليات الكتابة معًا. غالبًا ما يكون هذا بسيطًا مثل استخدام المعاملات الصريحة بدلاً من معاملات الالتزام التلقائي في الإجراءات المخزنة والدُفعات المخصصة. لتقييم الأساليب المختلفة التي يمكنك استخدامها، راجع تقنيات التجميع لتطبيقات قواعد البيانات في Azure. جرب حمولة العمل الخاص بك للعثور على النموذج المناسب للتجميع. تأكد من فهم أن النموذج قد يحتوي على ضمانات تناسق معاملات مختلفة قليلاً. يتطلب العثور على حمولة العمل المناسب الذي يقلل من استخدام الموارد إيجاد التركيبة الصحيحة من التناسق ومقايضات الأداء.
التخزين المؤقت على مستوى التطبيق
تحتوي بعض تطبيقات قواعد البيانات على أعباء عمل ثقيلة للقراءة. قد يؤدي التخزين المؤقت للطبقات إلى تقليل الحمل على قاعدة البيانات وربما يقلل من حجم الحساب المطلوب لدعم قاعدة البيانات باستخدام قاعدة بيانات Azure SQL ومثيل Azure SQL المُدار. باستخدام Azure Cache for Redis، إذا كان لديك عبء عمل ثقيل القراءة، فيمكنك قراءة البيانات مرة واحدة (أو ربما مرة واحدة لكل جهاز على مستوى التطبيق، بناءً على كيفية تكوينه)، ثم تخزين هذه البيانات خارج قاعدة البيانات الخاصة بك. هذه طريقة لتقليل تحميل قاعدة البيانات (وحدة المعالجة المركزية وقراءة الإدخال / الإخراج)، ولكن هناك تأثير على اتساق المعاملات لأن البيانات التي تتم قراءتها من ذاكرة التخزين المؤقت قد تكون غير متزامنة مع البيانات الموجودة في قاعدة البيانات. على الرغم من قبول مستوى معين من عدم الاتساق في العديد من التطبيقات، إلا أن هذا ليس صحيحًا بالنسبة لجميع حمولات العمل. يجب أن تفهم تمامًا أي متطلبات للتطبيق قبل تنفيذ استراتيجية التخزين المؤقت لطبقة التطبيق.
احصل على نصائح التكوين والتصميم
إذا كنت تستخدم Azure SQL Database، يمكنك تنفيذ برنامج نصي T-SQL مفتوح المصدر لتحسين تكوين قاعدة البيانات وتصميمها في Azure SQL DB. سيقوم البرنامج النصي بتحليل قاعدة البيانات الخاصة بك عند الطلب وتقديم نصائح لتحسين أداء قاعدة البيانات وصحتها. تقترح بعض التلميحات تغييرات التكوين والتشغيل بناءً على أفضل الممارسات، بينما توصي التلميحات الأخرى بإجراء تغييرات في التصميم تتناسب مع حجم العمل لديك، مثل تمكين ميزات محرك قاعدة البيانات المتقدمة.
لمعرفة المزيد عن البرنامج النصي والبدء، قم بزيارة صفحة Azure SQL Tips wiki.
الخطوات التالية
- تعرف على معلومات عن نموذج الشراء المستند إلى DTU
- تعرف على المزيد عن نموذج الشراء المستند إلى vCore
- اطلع على ما هي مجموعة Azure المرنة؟
- اكتشف متى تفكر في تجمع مرن
- اقرأ حول مراقبة Azure SQL Database وأداء Azure SQL Managed Instance باستخدام طرق عرض الإدارة الديناميكية
- تعرف على تشخيص واستكشاف أخطاء وحدة المعالجة المركزية عالية المستوى في Azure SQL Database وإصلاحها
- ضبط الفهارس غير متفاوتة المسافات مع اقتراحات الفهرس المفقود
- فيديو: Data Loading Best Practices على Azure SQL Database