إشعار
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تسجيل الدخول أو تغيير الدلائل.
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تغيير الدلائل.
Azure Cosmos DB هي قاعدة بيانات قابلة للتطوير وموزعة عالمياً ومدارة بالكامل. فهي توفر وصولاً مضموناً بزمن انتقال منخفض إلى بياناتك. لمعرفة المزيد حول Azure Cosmos DB، راجع مقالة نظرة عامة. ترشد هذه المقالة كيفية ترحيل بياناتك من HBase إلى Azure Cosmos DB لحساب NoSQL.
الاختلافات بين Azure Cosmos DB وHBase
قبل الترحيل، يجب أن تفهم الاختلافات بين Azure Cosmos DB وHBase.
نموذج الموارد
يحتوي Azure Cosmos DB على نموذج المورد التالي: 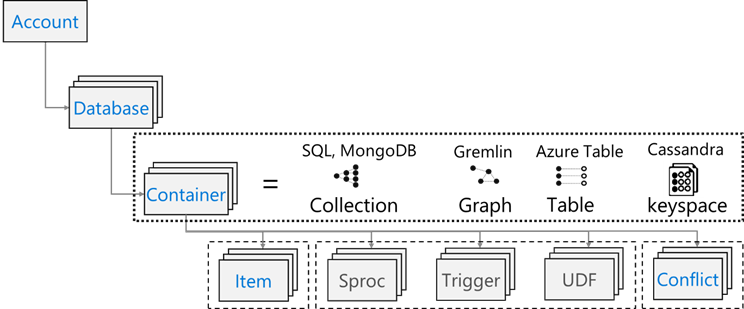
يحتوي HBase على نموذج المورد التالي: 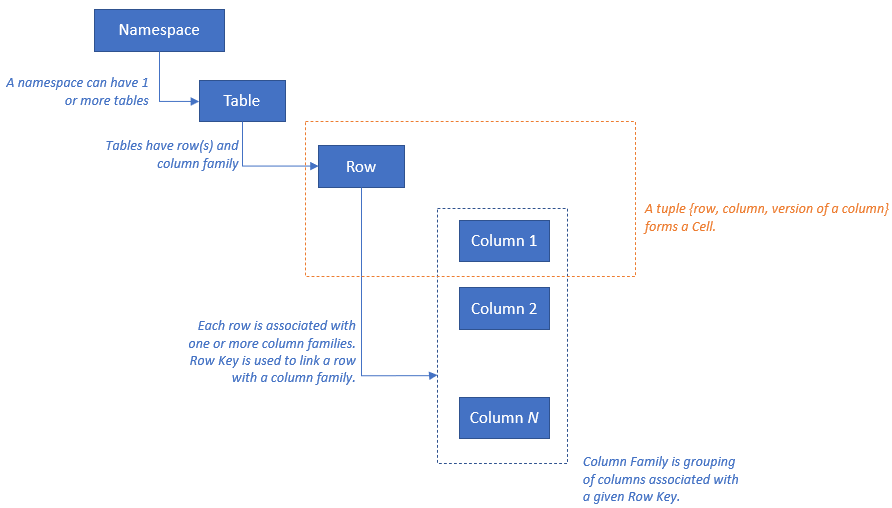
تخطيط الموارد
يعرض الجدول التالي مخططًا مفاهيميًا بين Apache HBase وApache Phoenix وAzure Cosmos DB.
| HBase | Phoenix | Azure Cosmos DB |
|---|---|---|
| نظام المجموعة | نظام المجموعة | عميل |
| مساحة الاسم | المخطط (إذا تم تمكينه) | قاعدة البيانات |
| الجدول | الجدول | الحاوية/المجموعة |
| عائلة العمود | عائلة العمود | غير متوفر |
| الصف | الصف | العنصر/المستند |
| الإصدار (الطابع الزمني) | الإصدار (الطابع الزمني) | غير متوفر |
| غير متوفر | المفتاح الأساسي | مفتاح القسم |
| غير متوفر | Index | Index |
| غير متوفر | الفهرس الثانوي | الفهرس الثانوي |
| غير متوفر | العرض | غير متوفر |
| غير متوفر | Sequence | غير متوفر |
مقارنة هيكل البيانات والاختلافات
فيما يلي الاختلافات الرئيسية بين بنية بيانات Azure Cosmos DB وHBase:
مفتاح الصف
في HBase، يتم تخزين البيانات من قِبل RowKey ويتم تقسيمها أفقيًا إلى مناطق حسب نطاق RowKey المحدد أثناء إنشاء الجدول.
يقوم Azure Cosmos DB على الجانب الآخر بتوزيع البيانات في أقسام بناءً على قيمة التجزئة الخاصة بمفتاح القسم المحدد.
عائلة العمود
في HBase، يتم تجميع الأعمدة داخل عائلة الأعمدة (CF).
يخزن Azure Cosmos DB (API for NoSQL) البيانات كمستند JSON . ومن ثم، تنطبق جميع الخصائص المرتبطة بهيكل بيانات JSON.
Timestamp
يستخدم HBase الطابع الزمني لإصدار مثيلات متعددة لخلية معينة. يمكنك الاستعلام عن إصدارات مختلفة من الخلية باستخدام الطابع الزمني.
يأتي Azure Cosmos DB مزودًا بميزة تغيير الخلاصة التي تتعقب السجل الدائم للتغييرات في الحاوية بالترتيب الذي تحدث به. ثم تقوم بإخراج قائمة المستندات التي تم فرزها والتي تم تغييرها بترتيب حدوث التغييرات.
تنسيق البيانات
يتكون تنسيق بيانات HBase من RowKey، عائلة العمود: اسم العمود، الطابع الزمني، القيمة. فيما يلي مثال على صف جدول HBase:
ROW COLUMN+CELL 1000 column=Office:Address, timestamp=1611408732448, value=1111 San Gabriel Dr. 1000 column=Office:Phone, timestamp=1611408732418, value=1-425-000-0002 1000 column=Personal:Name, timestamp=1611408732340, value=John Dole 1000 column=Personal:Phone, timestamp=1611408732385, value=1-425-000-0001في Azure Cosmos DB ل NoSQL، يمثل كائن JSON تنسيق البيانات. يوجد مفتاح القسم في حقل في المستند ويحدد الحقل الذي يمثل مفتاح القسم للمجموعة. لا يحتوي Azure Cosmos DB على مفهوم الطابع الزمني المستخدم لعائلة الأعمدة أو الإصدار. كما تم إبرازه سابقًا، فقد تم تغيير دعم التغذية الذي يمكن من خلاله تتبع/تسجيل التغييرات التي تم إجراؤها على الحاوية. ما يلي هو مثال على وثيقة.
{ "RowId": "1000", "OfficeAddress": "1111 San Gabriel Dr.", "OfficePhone": "1-425-000-0002", "PersonalName": "John Dole", "PersonalPhone": "1-425-000-0001", }
تلميح
يخزن HBase البيانات في صفيف بايت، لذلك إذا كنت تريد ترحيل البيانات التي تحتوي على أحرف مزدوجة البايت إلى Azure Cosmos DB، فيجب أن تكون البيانات بترميز UTF-8.
نموذج الاتساق
يقدم HBase عمليات قراءة وكتابة متسقة بدقة.
تقدم Azure Cosmos DB خمسة مستويات تناسق محددة جيدًا. يوفر كل مستوى مفاضلات التوافر والأداء. من الأقوى إلى الأضعف، مستويات الاتساق المدعومة هي:
- Strong
- الجمود المحدود
- جلسة
- بادئة متناسقة
- نهايه المطاف
ضبط الحجم
HBase
لتوزيع HBase، Master على مستوى المؤسسة؛ خوادم المنطقة؛ وZooKeeper يقودان الجزء الأكبر من الحجم. مثل أي تطبيق موزع، تم تصميم HBase لتوسيع نطاقه. يعتمد أداء HBase بشكل أساسي على حجم HBase RegionServers. يعتمد التحجيم بشكل أساسي على متطلبين رئيسيين - معدل النقل وحجم مجموعة البيانات التي يجب تخزينها على HBase.
Azure Cosmos DB
Azure Cosmos DB عبارة عن عرض PaaS من Microsoft ويتم استخراج تفاصيل نشر البنية الأساسية من المستخدمين النهائيين. عند توفير حاوية Azure Cosmos DB، يقوم نظام Azure الأساسي تلقائيا بتوفير البنية الأساسية (الحوسبة والتخزين والذاكرة ومكدس الشبكات) لدعم متطلبات الأداء لحمل عمل معين. يتم تسوية تكلفة جميع عمليات قاعدة البيانات عن طريق قاعدة بيانات Azure Cosmos ويتم التعبير عنها عن طريق وحدات الطلب (أو وحدات البحث السريع، باختصار).
لتقدير حدات الطلب التي يستهلكها عبء العمل لديك، ضع في اعتبارك العوامل التالية:
هناك حاسبة سعة متاحة للمساعدة في تمرين تغيير الحجم لوحدات الطلب.
يمكنك أيضًا استخدام قياس معدل النقل التلقائي للتوفير في Azure Cosmos DB لتوسيع نطاق قاعدة البيانات أو سعة نقل الحاوية تلقائيًا وفوريًا (وحدة طلب/ثانية). يتم قياس معدل النقل استنادًا إلى الاستخدام دون التأثير على توفر عبء العمل أو زمن الانتقال أو الإنتاجية أو الأداء.
توزيع البيانات
HBase يقوم HBase بفرز البيانات وفقًا لـ RowKey. ثم يتم تقسيم البيانات إلى مناطق وتخزينها في RegionServers. يقسم التقسيم التلقائي المناطق أفقياً وفقًا لنهج التقسيم. يتم التحكم في ذلك من خلال القيمة المعينة لمعامل HBase hbase.hregion.max.filesize(القيمة الافتراضية هي 10 جيجابايت). دائمًا ما ينتمي الصف الموجود في HBase باستخدام RowKey المحدد إلى منطقة واحدة. بالإضافة إلى ذلك، يتم فصل البيانات على القرص لكل عائلة عمود. يتيح ذلك التصفية في وقت القراءة وعزل الإدخال/الإخراج على HFile.
Azure Cosmos DB يستخدم Azure Cosmos DB تقسيم الأقسام لتوسيع الحاويات الفردية. للحصول على تفاصيل شاملة حول التقسيمات المنطقية، والتقسيمات الفيزيائية، واختيار مفاتيح الأقسام، راجع نظرة عامة على التقسيمات.
الفروقات الرئيسية في الهجرة:
- آلية توزيع البيانات: يقوم نظام RowKey من HBase بفرز البيانات وتخزينها باستمرار، بينما يقوم مفتاح التقسيم في Azure Cosmos DB بتوزيع البيانات بشكل تجزئي. استخدام نفس RowKey لمفتاح التقسيم عادة لا يعطي نتائج أداء مثالية.
- الفهارس المركبة للاستعلامات المرتبة: نظرا لأن البيانات مرتبة على HBase، قد يكون فهرس Azure Cosmos DB المركب مفيدا. هذا مطلوب إذا أردت استخدام بند ORDER BY في عدة حقول. يمكنك أيضا تحسين أداء العديد من استعلامات المساواة والمدى من خلال تعريف مؤشر مركب.
Availability
HBase يتكون HBase من Master؛ خادم المنطقة؛ وZooKeeper. يمكن تحقيق التوافر العالي في مجموعة واحدة من خلال جعل كل مكون فائض عن الحاجة. عند تكوين التكرار الجغرافي، يمكن للمرء نشر مجموعات HBase عبر مراكز بيانات فعلية مختلفة واستخدام النسخ المتماثل للحفاظ على تزامن مجموعات متعددة.
لا يتطلب Azure Cosmos DB Azure Cosmos DB أي تكوين مثل تكرار مكون نظام المجموعة. يوفر اتفاقية مستوى الخدمة (SLA) شاملة للإتاحة والاتساق ووقت الاستجابة العالي. راجع اتفاقية مستوى الخدمة ل Azure Cosmos DB لمزيد من التفاصيل.
موثوقية البيانات
HBase تم إنشاء HBase على نظام الملفات الموزعة Hadoop (HDFS) ويتم نسخ البيانات المخزنة على HDFS ثلاث مرات.
Azure Cosmos DB يوفر Azure Cosmos DB بشكل أساسي توفرًا عاليًا بطريقتين. أولا، يقوم Azure Cosmos DB بنسخ البيانات نسخا متماثلا بين المناطق التي تم تكوينها داخل حساب Azure Cosmos DB الخاص بك. ثانيًا، يحتفظ Azure Cosmos DB بأربع نسخ متماثلة من البيانات في المنطقة.
اعتبارات قبل الهجرة
تبعيات النظام
يركز هذا الجانب من التخطيط على فهم تبعيات المنبع والمصب لمثيل HBase، والذي يتم ترحيله إلى Azure Cosmos DB.
يمكن أن تكون التطبيقات التي تقرأ البيانات من HBase مثالاً على التبعيات النهائية. يجب إعادة تصميمها لتتم قراءتها من Azure Cosmos DB. يجب اعتبار هذه النقاط التالية جزءًا من الترحيل:
أسئلة لتقييم التبعيات - هل نظام HBase الحالي مكون مستقل؟ أم أنها تستدعي عملية على نظام آخر، أم أنها تسمى بعملية على نظام آخر، أم يتم الوصول إليها باستخدام خدمة دليل؟ هل هناك عمليات مهمة أخرى تعمل في مجموعة HBase الخاصة بك؟ تحتاج تبعيات النظام هذه إلى توضيح لتحديد تأثير الهجرة.
RPO وRTO لنشر HBase في أماكن العمل.
الترحيل دون اتصال أو عبر الإنترنت
لترحيل البيانات بنجاح، من المهم فهم خصائص الأعمال التي تستخدم قاعدة البيانات وتحديد كيفية القيام بذلك. حدد الترحيل دون اتصال بالإنترنت إذا كان بإمكانك إيقاف تشغيل النظام تمامًا وإجراء ترحيل البيانات وإعادة تشغيل النظام في الوجهة. أيضًا، إذا كانت قاعدة البيانات الخاصة بك مشغولة دائمًا ولا يمكنك تحمل انقطاع طويل، ففكر في الترحيل عبر الإنترنت.
إشعار
يغطي هذا المستند الترحيل في وضع عدم الاتصال فقط.
عند إجراء ترحيل البيانات دون اتصال، يعتمد ذلك على إصدار HBase الذي تقوم بتشغيله حاليا والأدوات المتوفرة. راجع قسم ترحيل البيانات لمزيد من التفاصيل.
الاعتبارات الخاصة بالأداء
هذا الجانب من التخطيط هو فهم أهداف الأداء لـ HBase ثم ترجمتها عبر دلالات Azure Cosmos DB. على سبيل المثال - للضغط على "X" IOPS على HBase، كم عدد وحدات الطلب (وحدة طلب/ثانية) التي ستكون مطلوبة في Azure Cosmos DB. توجد اختلافات بين HBase وAzure Cosmos DB، يركز هذا التمرين على بناء عرض لكيفية ترجمة أهداف الأداء من HBase إلى Azure Cosmos DB. هذا سوف يقود تمرين التحجيم.
أسئلة يجب طرحها:
- هل نشر HBase ثقيل القراءة أم كثيف الكتابة؟
- ما هو الفصل بين يقرأ ويكتب؟
- ما هو الهدف الذي يعبر عنه IOPS كنسبة مئوية؟
- كيف/ما هي التطبيقات المستخدمة لتحميل البيانات في HBase؟
- كيف/ما هي التطبيقات المستخدمة لقراءة البيانات من HBase؟
عند تنفيذ الاستعلامات التي تطلب البيانات المصنفة، سيعيد HBase النتيجة بسرعة لأن البيانات يتم فرزها من قِبل RowKey. ومع ذلك، فإن Azure Cosmos DB ليس لديه مثل هذا المفهوم. لتحسين الأداء، يمكنك استخدام الفهارس المركبة حسب الحاجة.
اعتبارات النشر
يمكنك استخدام مدخل Azure أو Azure CLI لنشر Azure Cosmos DB ل NoSQL. نظرا لأن وجهة الترحيل هي Azure Cosmos DB ل NoSQL، حدد "NoSQL" لواجهة برمجة التطبيقات كمعلمة عند النشر. بالإضافة إلى ذلك، قم بتعيين التكرار الجغرافي، وعمليات الكتابة متعددة المناطق، ومناطق التوفر وفقًا لمتطلبات التوفر الخاصة بك.
اعتبار الشبكة
يحتوي Azure Cosmos DB على ثلاثة خيارات شبكة رئيسية. الأول هو التكوين الذي يستخدم عنوان IP العام ويتحكم في الوصول باستخدام جدار حماية IP (افتراضي). والثاني هو تكوين يستخدم عنوان IP عام ويسمح بالوصول فقط من شبكة فرعية محددة لشبكة ظاهرية معينة (نقطة نهاية الخدمة). الثالث هو تكوين (نقطة نهاية خاصة) ينضم إلى شبكة خاصة باستخدام عنوان IP خاص.
راجع المستندات التالية للحصول على مزيد من المعلومات حول خيارات الشبكة الثلاثة:
تقييم البيانات الموجودة لديك
اكتشاف البيانات
اجمع المعلومات مسبقًا من مجموعة HBase الحالية لتحديد البيانات التي تريد ترحيلها. يمكن أن يساعدك ذلك في تحديد كيفية الترحيل، وتحديد الجداول المراد ترحيلها، وفهم البنية الموجودة في تلك الجداول، وتحديد كيفية إنشاء نموذج البيانات الخاص بك. على سبيل المثال، اجمع تفاصيل مثل ما يلي:
- نسخة HBase
- أهداف الترحيل الجداول
- معلومات عائلة العمود
- حالة الجدول
توضح الأوامر التالية كيفية جمع التفاصيل المذكورة أعلاه باستخدام برنامج نصي لقشرة hbase وتخزينها في نظام الملفات المحلي لجهاز التشغيل.
احصل على نسخة HBase
hbase version -n > hbase-version.txt
الناتج:
cat hbase-version.txt
HBase 2.1.8.4.1.2.5
احصل على قائمة الجداول
يمكنك الحصول على قائمة الجداول المخزنة في HBase. إذا قمت بإنشاء مساحة اسم غير الافتراضية، فسيتم إخراجها بتنسيق "Namespace: Table".
echo "list" | hbase shell -n > table-list.txt
HBase 2.1.8.4.1.2.5
الناتج:
echo "list" | hbase shell -n > table-list.txt
cat table-list.txt
TABLE
COMPANY
Contacts
ns1:t1
3 row(s)
Took 0.4261 seconds
COMPANY
Contacts
ns1:t1
تحديد الجداول المراد ترحيلها
احصل على تفاصيل مجموعات الأعمدة في الجدول عن طريق تحديد اسم الجدول الذي سيتم ترحيله.
echo "describe '({Namespace}:){Table name}'" | hbase shell -n > {Table name} -schema.txt
الناتج:
cat {Table name} -schema.txt
Table {Table name} is ENABLED
{Table name}
COLUMN FAMILIES DESCRIPTION
{NAME => 'cf1', VERSIONS => '1', EVICT_BLOCKS_ON_CLOSE => 'false', NEW_VERSION_BEHAVIOR => 'false', KEEP_DELETED_CELLS => 'FALSE', CACHE_DATA_ON_WRITE => 'false', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', MIN_VERSIONS => '0', REPLICATION_SCOPE => '0', BLOOMFILTER => 'ROW', CACHE_INDEX_ON_WRITE => 'false', IN_MEMORY => 'false', CACHE_BLOOMS_ON_WRITE => 'false', PREFETCH_BLOCKS_ON_OPEN => 'false', COMPRESSION => 'NONE', BLOCKCACHE => 'true', BLOCKSIZE => '65536'}
{NAME => 'cf2', VERSIONS => '1', EVICT_BLOCKS_ON_CLOSE => 'false', NEW_VERSION_BEHAVIOR => 'false', KEEP_DELETED_CELLS => 'FALSE', CACHE_DATA_ON_WRITE => 'false', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', MIN_VERSIONS => '0', REPLICATION_SCOPE => '0', BLOOMFILTER => 'ROW', CACHE_INDEX_ON_WRITE => 'false', IN_MEMORY => 'false', CACHE_BLOOMS_ON_WRITE => 'false', PREFETCH_BLOCKS_ON_OPEN => 'false', COMPRESSION => 'NONE', BLOCKCACHE => 'true', BLOCKSIZE => '65536'}
2 row(s)
Took 0.5775 seconds
احصل على عائلات الأعمدة في الجدول وإعداداتها
echo "status 'detailed'" | hbase shell -n > hbase-status.txt
الناتج:
{HBase version}
0 regionsInTransition
active master: {Server:Port number}
2 backup masters
{Server:Port number}
{Server:Port number}
master coprocessors: []
# live servers
{Server:Port number}
requestsPerSecond=0.0, numberOfOnlineRegions=44, usedHeapMB=1420, maxHeapMB=15680, numberOfStores=49, numberOfStorefiles=14, storefileUncompressedSizeMB=7, storefileSizeMB=7, compressionRatio=1.0000, memstoreSizeMB=0, storefileIndexSizeKB=15, readRequestsCount=36210, filteredReadRequestsCount=415729, writeRequestsCount=439, rootIndexSizeKB=15, totalStaticIndexSizeKB=5, totalStaticBloomSizeKB=16, totalCompactingKVs=464, currentCompactedKVs=464, compactionProgressPct=1.0, coprocessors=[GroupedAggregateRegionObserver, Indexer, MetaDataEndpointImpl, MetaDataRegionObserver, MultiRowMutationEndpoint, ScanRegionObserver, SecureBulkLoadEndpoint, SequenceRegionObserver, ServerCachingEndpointImpl, UngroupedAggregateRegionObserver]
[...]
"Contacts,,1611126188216.14a597a0964383a3d923b2613524e0bd."
numberOfStores=2, numberOfStorefiles=2, storefileUncompressedSizeMB=7168, lastMajorCompactionTimestamp=0, storefileSizeMB=7, compressionRatio=0.0010, memstoreSizeMB=0, readRequestsCount=4393, writeRequestsCount=0, rootIndexSizeKB=14, totalStaticIndexSizeKB=5, totalStaticBloomSizeKB=16, totalCompactingKVs=0, currentCompactedKVs=0, compactionProgressPct=NaN, completeSequenceId=-1, dataLocality=0.0
[...]
يمكنك الحصول على معلومات تحجيم مفيدة مثل حجم ذاكرة الكومة، وعدد المناطق، وعدد الطلبات كحالة الكتلة، وحجم البيانات في مضغوطة/غير مضغوطة كحالة الجدول.
إذا كنت تستخدم Apache Phoenix على مجموعة HBase، فأنت بحاجة إلى جمع البيانات من Phoenix أيضا.
- جدول هدف الترحيل
- مخططات الجدول
- Indexes
- المفتاح الأساسي
اتصل بـ Apache Phoenix على مجموعتك
sqlline.py ZOOKEEPER/hbase-unsecure
احصل على قائمة الجدول
!tables
احصل على تفاصيل الجدول
!describe <Table Name>
احصل على تفاصيل الفهرس
!indexes <Table Name>
احصل على تفاصيل المفتاح الأساسي
!primarykeys <Table Name>
ترحيل بياناتك
خيارات الترحيل
هناك طرق مختلفة لترحيل البيانات دون اتصال، ولكن هنا سنقدم كيفية استخدام Azure Data Factory.
| حل | نسخة المصدر | Considerations |
|---|---|---|
| Azure Data Factory | HBase < 2 | سهل الإعداد. مناسب لمجموعات البيانات الكبيرة. لا يدعم HBase 2 أو أحدث. |
| Apache Spark | جميع الإصدارات | دعم جميع إصدارات HBase. مناسب لمجموعات البيانات الكبيرة. مطلوب إعداد شرارة. |
| أداة مخصصة مع مكتبة المنفذ المجمع ل Azure Cosmos DB | جميع الإصدارات | الأكثر مرونة لإنشاء أدوات ترحيل البيانات المخصصة باستخدام المكتبات. يتطلب المزيد من الجهد للإعداد. |
يستخدم المخطط الانسيابي التالي بعض الشروط للوصول إلى طرق ترحيل البيانات المتاحة.
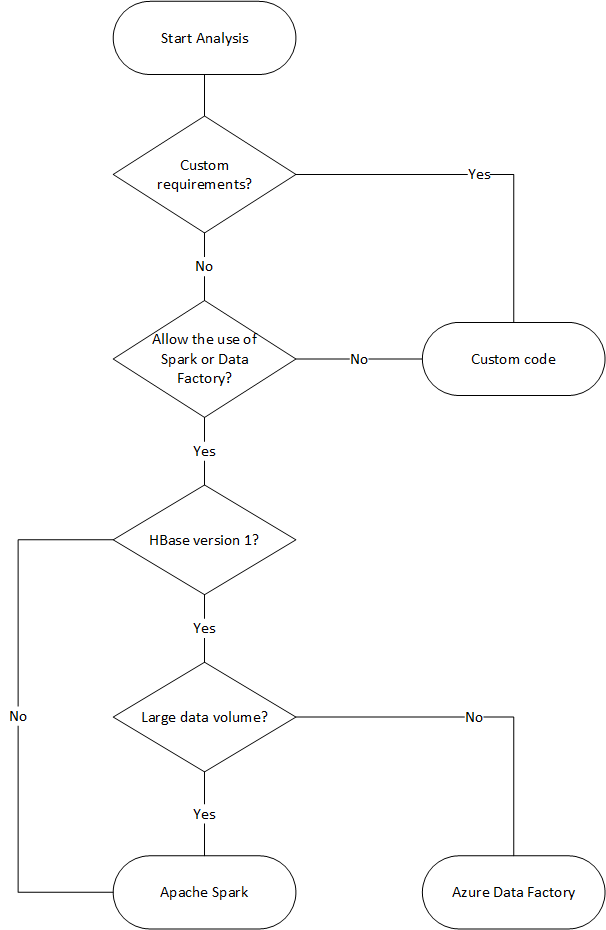
الترحيل باستخدام Data Factory
هذا الخيار مناسب لمجموعات البيانات الكبيرة. يتم استخدام مكتبة Azure Cosmos DB Bulk Executor. لا توجد نقاط تفتيش، لذلك إذا واجهت أي مشاكل أثناء الترحيل، فسيتعين عليك إعادة تشغيل عملية الترحيل من البداية. يمكنك أيضًا استخدام وقت تشغيل التكامل المستضاف ذاتيًا في Data Factory للاتصال بقاعدة HBase المحلية الخاصة بك، أو نشر Data Factory على VNET مُدار والاتصال بشبكتك المحلية عبر VPN أو ExpressRoute.
يدعم نشاط النسخ في Data Factory HBase كمصدر بيانات. راجع مقالة نسخ البيانات من HBase باستخدام Azure Data Factory للحصول على مزيد من التفاصيل.
يمكنك تحديد Azure Cosmos DB (API for NoSQL) كوجهة لبياناتك. راجع مقالة نسخ البيانات وتحويلها في Azure Cosmos DB (API for NoSQL) باستخدام Azure Data Factory لمزيد من التفاصيل.

الترحيل باستخدام Apache Spark - موصل Apache HBase وموصل Azure Cosmos DB Spark
فيما يلي مثال لترحيل بياناتك إلى Azure Cosmos DB. يفترض أن HBase 2.1.0 وSpark 2.4.0 يعملان في نفس المجموعة.
يمكن العثور على مستودع Apache Spark - Apache HBase Connector في Apache Spark - موصل Apache HBase
بالنسبة إلى موصل Azure Cosmos DB Spark، راجع دليل البدء السريع وقم بتنزيل المكتبة المناسبة لإصدار Spark الخاص بك.
انسخ hbase-site.xml إلى دليل تكوين Spark.
cp /etc/hbase/conf/hbase-site.xml /etc/spark2/conf/قم بتشغيل قشرة شرارة باستخدام موصل Spark HBase وموصل Azure Cosmos DB Spark.
spark-shell --packages com.hortonworks.shc:shc-core:1.1.0.3.1.2.2-1 --repositories http://repo.hortonworcontent/groups/public/ --jars azure-cosmosdb-spark_2.4.0_2.11-3.6.8-uber.jarبعد بدء تشغيل Spark shell، قم بتنفيذ رمز Scala على النحو التالي. استيراد المكتبات المطلوبة لتحميل البيانات من HBase.
// Import libraries import org.apache.spark.sql.{SQLContext, _} import org.apache.spark.sql.execution.datasources.hbase._ import org.apache.spark.{SparkConf, SparkContext} import spark.sqlContext.implicits._حدد مخطط كتالوج Spark لجداول HBase. هنا Namespace "افتراضي" واسم الجدول هو "Contacts". يتم تحديد مفتاح الصف كمفتاح. يتم تعيين الأعمدة ومجموعة العمود والعمود إلى كتالوج Spark.
// define a catalog for the Contacts table you created in HBase def catalog = s"""{ |"table":{"namespace":"default", "name":"Contacts"}, |"rowkey":"key", |"columns":{ |"rowkey":{"cf":"rowkey", "col":"key", "type":"string"}, |"officeAddress":{"cf":"Office", "col":"Address", "type":"string"}, |"officePhone":{"cf":"Office", "col":"Phone", "type":"string"}, |"personalName":{"cf":"Personal", "col":"Name", "type":"string"}, |"personalPhone":{"cf":"Personal", "col":"Phone", "type":"string"} |} |}""".stripMarginبعد ذلك، حدد طريقة للحصول على البيانات من جدول جهات اتصال HBase كإطار بيانات.
def withCatalog(cat: String): DataFrame = { spark.sqlContext .read .options(Map(HBaseTableCatalog.tableCatalog->cat)) .format("org.apache.spark.sql.execution.datasources.hbase") .load() }قم بإنشاء DataFrame باستخدام الطريقة المحددة.
val df = withCatalog(catalog)ثم قم باستيراد المكتبات اللازمة لاستخدام موصل Azure Cosmos DB Spark.
import com.microsoft.azure.cosmosdb.spark.schema._ import com.microsoft.azure.cosmosdb.spark._ import com.microsoft.azure.cosmosdb.spark.config.Configقم بإعدادات لكتابة البيانات إلى Azure Cosmos DB.
val writeConfig = Config(Map( "Endpoint" -> "https://<cosmos-db-account-name>.documents.azure.com:443/", "Masterkey" -> "<comsmos-db-master-key>", "Database" -> "<database-name>", "Collection" -> "<collection-name>", "Upsert" -> "true" ))اكتب بيانات DataFrame إلى Azure Cosmos DB.
import org.apache.spark.sql.SaveMode df.write.mode(SaveMode.Overwrite).cosmosDB(writeConfig)
يكتب بالتوازي بسرعة عالية، وأداؤه مرتفع. من ناحيةٍ أخرى، لاحظ أنه قد تستهلك وحدة الطلب/ثانية على جانب Azure Cosmos DB.
فينكس
يتم دعم Phoenix كمصدر بيانات Data Factory. الرجوع إلى الوثائق التالية للحصول على خطوات مفصلة.
- انسخ البيانات من Phoenix باستخدام Azure Data Factory
- انسخ البيانات من HBase باستخدام Azure Data Factory
قم بترحيل التعليمات البرمجية الخاصة بك
يصف هذا القسم الاختلافات بين إنشاء التطبيقات في Azure Cosmos DB ل NoSQLs وHBase. تستخدم الأمثلة هنا واجهات برمجة تطبيقات Apache HBase 2.x وAzure Cosmos DB Java SDK v4.
تعتمد نماذج رموز HBase هذه على تلك الموضحة في الوثائق الرسمية لـ HBase.
يتم عرض تعيينات ترحيل التعليمات البرمجية هنا، ولكن مفاتيح أقسام HBase RowKeys وAzure Cosmos DB المستخدمة في هذه الأمثلة ليست مصممة دائما بشكل جيد. تصميم وفقًا لنموذج البيانات الفعلي لمصدر الترحيل.
إنشاء اتصال
HBase
Configuration config = HBaseConfiguration.create();
config.set("hbase.zookeeper.quorum","zookeepernode0,zookeepernode1,zookeepernode2");
config.set("hbase.zookeeper.property.clientPort", "2181");
config.set("hbase.cluster.distributed", "true");
Connection connection = ConnectionFactory.createConnection(config)
Phoenix
//Use JDBC to get a connection to an HBase cluster
Connection conn = DriverManager.getConnection("jdbc:phoenix:server1,server2:3333",props);
Azure Cosmos DB
// Create sync client
client = new CosmosClientBuilder()
.endpoint(AccountSettings.HOST)
.key(AccountSettings.MASTER_KEY)
.consistencyLevel(ConsistencyLevel.{ConsistencyLevel})
.contentResponseOnWriteEnabled(true)
.buildClient();
إنشاء قاعدة بيانات/جدول/مجموعة
HBase
// create an admin object using the config
HBaseAdmin admin = new HBaseAdmin(config);
// create the table...
HTableDescriptor tableDescriptor = new HTableDescriptor(TableName.valueOf("FamilyTable"));
// ... with single column families
tableDescriptor.addFamily(new HColumnDescriptor("ColFam"));
admin.createTable(tableDescriptor);
Phoenix
CREATE IF NOT EXISTS FamilyTable ("id" BIGINT not null primary key, "ColFam"."lastName" VARCHAR(50));
Azure Cosmos DB
// Create database if not exists
CosmosDatabaseResponse databaseResponse = client.createDatabaseIfNotExists(databaseName);
database = client.getDatabase(databaseResponse.getProperties().getId());
// Create container if not exists
CosmosContainerProperties containerProperties = new CosmosContainerProperties("FamilyContainer", "/lastName");
// Provision throughput
ThroughputProperties throughputProperties = ThroughputProperties.createManualThroughput(400);
// Create container with 400 RU/s
CosmosContainerResponse databaseResponse = database.createContainerIfNotExists(containerProperties, throughputProperties);
container = database.getContainer(databaseResponse.getProperties().getId());
إنشاء صف/مستند
HBase
HTable table = new HTable(config, "FamilyTable");
Put put = new Put(Bytes.toBytes(RowKey));
put.add(Bytes.toBytes("ColFam"), Bytes.toBytes("id"), Bytes.toBytes("1"));
put.add(Bytes.toBytes("ColFam"), Bytes.toBytes("lastName"), Bytes.toBytes("Witherspoon"));
table.put(put)
Phoenix
UPSERT INTO FamilyTable (id, lastName) VALUES (1, ‘Witherspoon’);
Azure Cosmos DB
يوفر Azure Cosmos DB أمان النوع عبر نموذج البيانات. نستخدم نموذج البيانات المسمى "العائلة".
public class Family {
public Family() {
}
public void setId(String id) {
this.id = id;
}
public void setLastName(String lastName) {
this.lastName = lastName;
}
private String id="";
private String lastName="";
}
ما ورد أعلاه جزء من الرمز. راجع مثال الرمز الكامل.
استخدم فئة "العائلة" لتعريف المستند وإدراج العنصر.
Family family = new Family();
family.setLastName("Witherspoon");
family.setId("1");
// Insert this item as a document
// Explicitly specifying the /pk value improves performance.
container.createItem(family,new PartitionKey(family.getLastName()),new CosmosItemRequestOptions());
قراءة الصف/المستند
HBase
HTable table = new HTable(config, "FamilyTable");
Get get = new Get(Bytes.toBytes(RowKey));
get.addColumn(Bytes.toBytes("ColFam"), Bytes.toBytes("lastName"));
Result result = table.get(get);
byte[] col = result.getValue(Bytes.toBytes("ColFam"), Bytes.toBytes("lastName"));
Phoenix
SELECT lastName FROM FamilyTable;
Azure Cosmos DB
// Read document by ID
Family family = container.readItem(documentId,new PartitionKey(documentLastName),Family.class).getItem();
String sql = "SELECT lastName FROM c";
CosmosPagedIterable<Family> filteredFamilies = container.queryItems(sql, new CosmosQueryRequestOptions(), Family.class);
تحديث البيانات
HBase
بالنسبة لـ HBase، استخدم طريقة الإلحاق وطريقة checkAndPut لتحديث القيمة. الإلحاق هو عملية إلحاق قيمة بشكل ذري بنهاية القيمة الحالية، ويقارن checkAndPut القيمة الحالية بالقيمة المتوقعة والتحديثات فقط إذا كانت متطابقة.
// append
HTable table = new HTable(config, "FamilyTable");
Append append = new Append(Bytes.toBytes(RowKey));
Append.add(Bytes.toBytes("ColFam"), Bytes.toBytes("id"), Bytes.toBytes(2));
Append.add(Bytes.toBytes("ColFam"), Bytes.toBytes("lastName"), Bytes.toBytes("Harris"));
Result result = table.append(append)
// checkAndPut
byte[] row = Bytes.toBytes(RowKey);
byte[] colfam = Bytes.toBytes("ColFam");
byte[] col = Bytes.toBytes("lastName");
Put put = new Put(row);
put.add(colfam, col, Bytes.toBytes("Patrick"));
boolearn result = table.checkAndPut(row, colfam, col, Bytes.toBytes("Witherspoon"), put);
Phoenix
UPSERT INTO FamilyTable (id, lastName) VALUES (1, ‘Brown’)
ON DUPLICATE KEY UPDATE id = "1", lastName = "Whiterspoon";
Azure Cosmos DB
في Azure Cosmos DB، يتم التعامل مع التحديثات على أنها عمليات Upsert. أي إذا لم يكن المستند موجودا، إدراجه.
// Replace existing document with new modified document (contingent on modification).
Family family = new Family();
family.setLastName("Brown");
family.setId("1");
CosmosItemResponse<Family> famResp = container.upsertItem(family, new CosmosItemRequestOptions());
حذف الصف/الوثيقة
HBase
في Hbase، لا توجد طريقة حذف مباشر لاختيار الصف حسب القيمة. ربما تكون قد نفذت عملية الحذف بالاشتراك مع ValueFilter وما إلى ذلك. في هذا المثال، يتم تحديد الصف المراد حذفه من قِبل RowKey.
HTable table = new HTable(config, "FamilyTable");
Delete delete = new Delete(Bytes.toBytes(RowKey));
delete.deleteColumn(Bytes.toBytes("ColFam"), Bytes.toBytes("id"));
delete.deleteColumn(Bytes.toBytes("ColFam"), Bytes.toBytes("lastName"));
table.dalate(delete)
Phoenix
DELETE FROM TableName WHERE id = "xxx";
Azure Cosmos DB
طريقة الحذف من قِبل معرّف المستند موضحة أدناه.
container.deleteItem(documentId, new PartitionKey(documentLastName), new CosmosItemRequestOptions());
صفوف/مستندات الاستعلام
HBase يسمح لك HBase باسترداد عدة صفوف باستخدام المسح. يمكنك استخدام عامل التصفية لتحديد شروط الفحص التفصيلية. راجع عوامل تصفية طلب العميل لمعرفة أنواع عوامل التصفية المضمنة في HBase.
HTable table = new HTable(config, "FamilyTable");
Scan scan = new Scan();
SingleColumnValueFilter filter = new SingleColumnValueFilter(Bytes.toBytes("ColFam"),
Bytes.toBytes("lastName"), CompareOp.EQUAL, New BinaryComparator(Bytes.toBytes("Witherspoon")));
filter.setFilterIfMissing(true);
filter.setLatestVersionOnly(true);
scan.setFilter(filter);
ResultScanner scanner = table.getScanner(scan);
Phoenix
SELECT * FROM FamilyTable WHERE lastName = "Witherspoon"
Azure Cosmos DB
عملية التصفية
String sql = "SELECT * FROM c WHERE c.lastName = 'Witherspoon'";
CosmosPagedIterable<Family> filteredFamilies = container.queryItems(sql, new CosmosQueryRequestOptions(), Family.class);
حذف الجدول/المجموعة
HBase
HBaseAdmin admin = new HBaseAdmin(config);
admin.deleteTable("FamilyTable")
Phoenix
DROP TABLE IF EXISTS FamilyTable;
Azure Cosmos DB
CosmosContainerResponse containerResp = database.getContainer("FamilyContainer").delete(new CosmosContainerRequestOptions());
اعتبارات أخرى
يمكن استخدام مجموعات HBase مع أحمال عمل HBase وMapReduce وHive وSpark وغير ذلك الكثير. إذا كان لديك أعباء عمل أخرى مع HBase الحالي، فيجب أيضًا ترحيلها. للحصول على تفاصيل، راجع كل دليل ترحيل.
- MapReduce
- HBase
- Spark
البرمجة من جانب الخادم
يقدم HBase العديد من ميزات البرمجة من جانب الخادم. إذا كنت تستخدم هذه الميزات، فستحتاج أيضا إلى ترحيل معالجتها.
HBase
-
تتوفر العديد من المرشحات بشكل افتراضي في HBase، ولكن يمكنك أيضًا تنفيذ عوامل التصفية المخصصة الخاصة بك. يمكن تنفيذ عوامل التصفية المخصصة إذا كانت المرشحات المتاحة افتراضيًا على HBase لا تلبي متطلباتك.
-
المعالج الثانوي هو إطار عمل يسمح لك بتشغيل التعليمات البرمجية الخاصة بك على خادم المنطقة. باستخدام المعالج الثانوي، من الممكن إجراء المعالجة التي تم تنفيذها على جانب العميل من جانب الخادم، واعتمادًا على المعالجة، يمكن جعلها أكثر كفاءة. هناك نوعان من المعالجات المشتركة، المراقب ونقطة النهاية.
المراقب
- المراقب يربط عمليات وأحداث محددة. هذه وظيفة لإضافة معالجة عشوائية. هذه ميزة مشابهة مشغلات RDBMS.
Endpoint
- نقطة النهاية هي ميزة لتمديد HBase RPC. إنها دالة مشابهة لإجراء RDBMS المخزن.
Azure Cosmos DB
-
- تتم كتابة الإجراءات المخزنة في Azure Cosmos DB بلغة JavaScript ويمكن تنفيذ عمليات مثل إنشاء العناصر وتحديثها وقراءتها والاستعلام فيها وحذفها في حاويات Azure Cosmos DB.
مشغل
- يمكن تحديد المشغلات للعمليات في قاعدة البيانات. هناك طريقتان متوفرتان: مشغل مسبق يتم تشغيله قبل تغيير عنصر قاعدة البيانات ومشغل لاحق يتم تشغيله بعد تغيير عنصر قاعدة البيانات.
-
- يسمح لك Azure Cosmos DB بتعريف الوظائف المعرفة من قبل المستخدم (UDFs). يمكن أيضًا كتابة UDFs بلغة JavaScript.
تستهلك الإجراءات والمشغلات المخزنة وحدات الطلب بناءً على مدى تعقيد العمليات التي يتم إجراؤها. عند تطوير المعالجة من جانب الخادم، تحقق من الاستخدام المطلوب للحصول على فهم أفضل لمقدار RU الذي تستهلكه كل عملية. راجع طلب الوحدات في Azure Cosmos DB وتحسين تكلفة الطلب في Azure Cosmos DB للحصول على التفاصيل.
تعيينات البرمجة من جانب الخادم
| HBase | Azure Cosmos DB | الوصف |
|---|---|---|
| عوامل تصفية مخصصة | عبارة WHERE | إذا تعذر تحقيق المعالجة التي تم تنفيذها من قِبل عامل التصفية المخصص من قِبل عبارة WHERE في Azure Cosmos DB، فاستخدم UDF معًا. |
| معالج مساعد (مراقب) | المشغِّل | المراقب هو الزناد الذي يتم تنفيذه قبل وبعد حدث معين. تماما كما يدعم المراقب المكالمات المسبقة واللاحقة، يدعم مشغل Azure Cosmos DB أيضا المشغلات السابقة واللاحقة. |
| معالج مساعد (نقطة نهاية) | الإجراء المخزَّن | نقطة النهاية هي آلية معالجة بيانات من جانب الخادم يتم تنفيذها لكل منطقة. هذا مشابه لإجراء RDBMS المخزن. تتم كتابة الإجراءات المخزنة في Azure Cosmos DB باستخدام JavaScript. يوفر الوصول إلى جميع العمليات التي يمكنك تنفيذها على Azure Cosmos DB من خلال الإجراءات المخزنة. |
إشعار
قد تكون هناك حاجة إلى تعيينات وتنفيذات مختلفة في Azure Cosmos DB اعتمادا على المعالجة المنفذة على HBase.
الأمان
أمن البيانات مسؤولية مشتركة للعميل ومزود قاعدة البيانات. بالنسبة للحلول المحلية، يتعين على العملاء توفير كل شيء بدءًا من حماية نقطة النهاية وحتى أمان الأجهزة المادية، وهي ليست مهمة سهلة. إذا اخترت موفر قاعدة بيانات سحابة PaaS مثل Azure Cosmos DB، فسيتم تقليل مشاركة العميل. يعمل Azure Cosmos DB على النظام الأساسي ل Azure، بحيث يمكن تحسينه بطريقة مختلفة عن HBase. لا يتطلب Azure Cosmos DB أي مكونات إضافية ليتم تثبيتها للأمان. نوصي بأن تفكر في ترحيل تطبيق أمان نظام قاعدة البيانات الخاص بك باستخدام قائمة التحقق التالية:
| التحكم في الأمان | HBase | Azure Cosmos DB |
|---|---|---|
| إعداد أمان الشبكة وجدار الحماية | التحكم في حركة المرور باستخدام وظائف الأمان مثل أجهزة الشبكة. | يدعم التحكم في الوصول المستند إلى بروتوكول الإنترنت على جدار الحماية الداخلي. |
| مصادقة المستخدم وعناصر تحكم المستخدم الدقيقة | تحكم دقيق في الوصول من خلال الجمع بين LDAP ومكونات الأمان مثل Apache Ranger. | يمكنك استخدام المفتاح الأساسي للحساب لإنشاء موارد المستخدمين والأذونات لكل قاعدة بيانات. يمكنك أيضا استخدام معرف Microsoft Entra لمصادقة طلبات البيانات. يتيح لك هذا التصريح بطلبات البيانات باستخدام نموذج RBAC دقيق الحبيبات. |
| القدرة على تكرار البيانات على مستوى العالم للإخفاقات الإقليمية | قم بعمل نسخة طبق الأصل من قاعدة البيانات في مركز بيانات بعيد باستخدام النسخ المتماثل لـ HBase. | ينفذ Azure Cosmos DB توزيعا عالميا خاليا من التكوين ويسمح لك بنسخ البيانات نسخا متماثلا إلى مراكز البيانات في جميع أنحاء العالم في Azure مع تحديد زر. من حيث الأمان، يضمن النسخ العالمي حماية بياناتك من الأعطال المحلية. |
| القدرة على الفشل من مركز بيانات إلى آخر | أنت بحاجة إلى تنفيذ تجاوز الفشل بنفسك. | إذا كنت تقوم بنسخ البيانات إلى عدة مراكز بيانات وكان مركز بيانات المنطقة في وضع عدم الاتصال، فإن Azure Cosmos DB يمرر العملية تلقائيًا. |
| تكرار البيانات المحلية داخل مركز البيانات | تتيح لك آلية HDFS الحصول على نسخ متماثلة متعددة عبر العقد داخل نظام ملفات واحد. | يقوم Azure Cosmos DB تلقائيا بنسخ البيانات نسخا متماثلا للحفاظ على قابلية الوصول العالية، حتى داخل مركز بيانات واحد. يمكنك اختيار مستوى التناسق بنفسك. |
| النسخ الاحتياطي التلقائي للبيانات | لا توجد وظيفة نسخ احتياطي تلقائي. أنت بحاجة إلى تنفيذ النسخ الاحتياطي للبيانات بنفسك. | يتم نسخ Azure Cosmos DB احتياطيا بانتظام وتخزينه في التخزين المتكرر جغرافيا. |
| حماية البيانات الحساسة وعزلها | على سبيل المثال، إذا كنت تستخدم Apache Ranger، يمكنك استخدام نهج Ranger لتطبيق النهج على الجدول. | يمكنك فصل البيانات الشخصية والبيانات الحساسة الأخرى في حاويات محددة والقراءة/الكتابة، أو تقييد الوصول للقراءة فقط إلى مستخدمين محددين. |
| رصد الهجمات | يجب أن يتم تنفيذه باستخدام منتجات الجهة الأخرى. | باستخدام تسجيل التدقيق وسجلات النشاط، يمكنك مراقبة حسابك بحثاً عن نشاط عادي وغير طبيعي. |
| الرد على الهجمات | يجب أن يتم تنفيذه باستخدام منتجات الجهة الأخرى. | عند الاتصال بدعم Azure والإبلاغ عن هجوم محتمل، تبدأ عملية الاستجابة للحوادث المكونة من خمس خطوات. |
| القدرة على تطويق البيانات جغرافياً للالتزام بقيود إدارة البيانات | تحتاج إلى التحقق من قيود كل بلد/منطقة وتنفيذها بنفسك. | يضمن حوكمة البيانات للمناطق ذات السيادة (ألمانيا والصين وحكومة الولايات المتحدة وما إلى ذلك). |
| الحماية المادية للخوادم في مراكز البيانات المحمية | يعتمد ذلك على مركز البيانات حيث يوجد النظام. | للحصول على قائمة بأحدث الشهادات، راجع موقع التوافق مع Azure. |
| الشهادات | يعتمد على توزيع Hadoop. | راجع وثائق التوافق مع Azure |
مراقبة
عادةً ما يراقب HBase الكتلة باستخدام واجهة مستخدم ويب الكتلة المترية أو باستخدام Ambari أو Cloudera Manager أو أدوات المراقبة الأخرى. يسمح لك Azure Cosmos DB باستخدام آلية المراقبة المضمنة في النظام الأساسي Azure. للحصول على مزيدٍ من المعلومات عن مراقبة Azure Cosmos DB، راجع مراقبة Azure Cosmos DB.
إذا كانت بيئتك تنفذ مراقبة نظام HBase لإرسال التنبيهات، على سبيل المثال عبر البريد الإلكتروني، فقد تتمكن من استبدالها بتنبيهات Azure Monitor. يمكنك تلقي التنبيهات بناءً على المقاييس أو أحداث سجل النشاط لحساب Azure Cosmos DB الخاص بك.
للحصول على مزيدٍ من المعلومات حول التنبيهات في Azure Monitor، يرجى الرجوع إلى إنشاء تنبيهات لـ Azure Cosmos DB باستخدام Azure Monitor
راجع أيضا مقاييس Azure Cosmos DB وأنواع السجلات التي يمكن جمعها بواسطة Azure Monitor.
النسخ الاحتياطي والتعافي من الكوارث
Backup
هناك عدة طرق للحصول على نسخة احتياطية من HBase. على سبيل المثال، Snapshot، Export، CopyTable، النسخ الاحتياطي دون اتصال لبيانات HDFS، والنسخ الاحتياطية المخصصة الأخرى.
يقوم Azure Cosmos DB تلقائيا بنسخ البيانات احتياطيا على فترات دورية، مما لا يؤثر على أداء عمليات قاعدة البيانات أو توفرها. يتم تخزين النسخ الاحتياطية في تخزين Azure ويمكن استخدامها لاستعادة البيانات إذا لزم الأمر. هناك نوعان من النسخ الاحتياطية ل Azure Cosmos DB:
التعافي من الكوارث
HBase هو نظام موزع يتسامح مع الأخطاء، ولكن يجب عليك تنفيذ التعافي من الكوارث باستخدام Snapshot، والنسخ المتماثل، وما إلى ذلك عندما يكون تجاوز الفشل مطلوبًا في موقع النسخ الاحتياطي في حالة فشل مستوى مركز البيانات. يمكن إعداد النسخ المتماثل HBase بثلاثة نماذج للنسخ المتماثل: قائد - تابع، قائد - قائد، والدوري. إذا كان المصدر HBase ينفذ التعافي من الكوارث، فأنت بحاجة إلى فهم كيفية تكوين التعافي من الكوارث في Azure Cosmos DB وتلبية متطلبات النظام.
Azure Cosmos DB عبارة عن قاعدة بيانات موزعة عالميًا مع إمكانات مضمنة لاستعادة القدرة على العمل بعد الكوارث. يمكنك نسخ بيانات قاعدة البيانات الخاصة بك إلى أي منطقة Azure. يحافظ Azure Cosmos DB على إتاحة قاعدة البيانات بشكل كبير في حالة حدوث فشل غير محتمل في بعض المناطق.
قد يفقد حساب Azure Cosmos DB الذي يستخدم منطقة واحدة فقط الإتاحة في حالة فشل المنطقة. نوصي بتكوين منطقتين على الأقل لضمان الإتاحة العالية دائمًا. يمكنك أيضًا ضمان التوفر العالي لكل من عمليات الكتابة والقراءة عن طريق تكوين حساب Azure Cosmos DB الخاص بك ليشمل منطقتين على الأقل مع مناطق كتابة متعددة لضمان التوفر العالي لعمليات الكتابة والقراءة. بالنسبة للحسابات متعددة المناطق التي تتكون من مناطق كتابة متعددة، يتم اكتشاف تجاوز الفشل بين المناطق ومعالجته من قِبل عميل Azure Cosmos DB. هذه عملية لحظية ولا تتطلب أي تغييرات من التطبيق. بهذه الطريقة، يمكنك تحقيق تكوين التوفر الذي يتضمن استرداد الكوارث لـ Azure Cosmos DB. كما ذكرنا سابقا، يمكن إعداد النسخ المتماثل HBase بثلاثة نماذج، ولكن يمكن إعداد Azure Cosmos DB مع التوفر المستند إلى اتفاقية مستوى الخدمة عن طريق تكوين مناطق الكتابة المفردة والكتابة المتعددة.
للحصول على مزيدٍ من المعلومات عن الإتاحة العالية، يرجى الرجوع إلى كيف يوفر Azure Cosmos DB توفرًا عاليًا
الأسئلة المتداولة
لماذا الترحيل إلى واجهة برمجة التطبيقات ل NoSQL بدلا من واجهات برمجة التطبيقات الأخرى في Azure Cosmos DB؟
توفر واجهة برمجة التطبيقات ل NoSQL أفضل تجربة شاملة من حيث الواجهة ومكتبة عميل SDK للخدمة. ستتوفر الميزات الجديدة التي تم طرحها في Azure Cosmos DB أولا في واجهة برمجة التطبيقات لحساب NoSQL. بالإضافة إلى ذلك، تدعم واجهة برمجة التطبيقات ل NoSQL التحليلات وتوفر فصل الأداء بين أحمال عمل الإنتاج والتحليلات. إذا كنت ترغب في استخدام التقنيات الحديثة لإنشاء تطبيقاتك، فإن واجهة برمجة التطبيقات ل NoSQL هي الخيار الموصى به.
هل يمكنني تعيين HBase RowKey لمفتاح قسم Azure Cosmos DB؟
قد لا يتم تحسينها كما هي. في HBase، يتم فرز البيانات حسب RowKey المحددة، وتخزينها في المنطقة، وتقسيمها إلى أحجام ثابتة. يعمل هذا بشكل مختلف عن التقسيم في Azure Cosmos DB. لذلك، يجب إعادة تصميم المفاتيح لتوزيع البيانات بشكل أفضل وفقًا لخصائص عبء العمل. راجع قسم التوزيع لمزيد من التفاصيل.
يتم فرز البيانات حسب RowKey في HBase، ولكن التقسيم حسب المفتاح في Azure Cosmos DB. كيف يمكن ل Azure Cosmos DB تحقيق الفرز والتكوين؟
في Azure Cosmos DB، يمكنك إضافة فهرس مركب لفرز بياناتك بترتيب تصاعدي أو تنازلي لتحسين أداء استعلامات المساواة والنطاق. راجع قسم التوزيع والمؤشر المُركَّب في وثائق المنتج.
يتم تنفيذ المعالجة التحليلية على بيانات HBase باستخدام Hive أو Spark. كيف يمكنني تحديثها في Azure Cosmos DB؟
يمكنك استخدام Azure Cosmos DB Mirroring إلى Microsoft Fabric لمزامنة بيانات التشغيل تلقائيا مع مخزن أعمدة آخر. يتيح لك العكس بناء حل HTAP خال من ETL على OneLake في Microsoft Fabric. يتيح لك ذلك إجراء تحليل واسع النطاق وشبه في الوقت الفعلي للبيانات التشغيلية. يدعم Microsoft Fabric تجمعات Apache Spark وSQL بدون خوادم. يمكنك الاستفادة من هذه الميزة لترحيل المعالجة التحليلية الخاصة بك. راجع Azure Cosmos DB Mirroring لمزيد من المعلومات.
كيف يمكن للمستخدمين استخدام استعلام الطابع الزمني في HBase إلى Azure Cosmos DB؟
لا يحتوي Azure Cosmos DB على نفس ميزة تعيين إصدار الطابع الزمني مثل HBase. ولكن يوفر Azure Cosmos DB القدرة على الوصول إلى موجز التغيير ويمكنك استخدامه لتعيين الإصدار.
قم بتخزين كل إصدار/تغيير كعنصر منفصل.
اقرأ موجز التغيير لدمج/دمج التغييرات وبدء الإجراءات المناسبة بعد ذلك عن طريق التصفية باستخدام الحقل "_ts". بالإضافة إلى ذلك، بالنسبة للإصدار القديم من البيانات، يمكنك إنهاء صلاحية الإصدارات القديمة باستخدام TTL.
الخطوات التالية
لإجراء اختبار الأداء، راجع مقالة اختبار الأداء والقياس باستخدام Azure Cosmos DB.
لتحسين التعليمات البرمجية، راجع مقالة تلميحات الأداء لـAzure Cosmos DB.
استكشاف Java Async V3 SDK، ومرجع SDK GitHub repo.