رسم خرائط تدفقات البيانات ودليل الضبط
ينطبق على: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
تلميح
جرب Data Factory في Microsoft Fabric، وهو حل تحليلي متكامل للمؤسسات. يغطي Microsoft Fabric كل شيء بدءا من حركة البيانات إلى علم البيانات والتحليلات في الوقت الحقيقي والمعلومات المهنية وإعداد التقارير. تعرف على كيفية بدء إصدار تجريبي جديد مجانا!
تعيين تدفق البيانات في Azure Data Factory ومسارات Synapse توفر واجهة خالية من التعليمات البرمجية لتصميم عمليات تحويل البيانات وتشغيلها على نطاق واسع. إذا لم تكن على دراية بتعيين تدفقات البيانات، فشاهد نظرة عامة على تعيين تدفق البيانات. تسلط هذه المقالة الضوء على طرق مختلفة لضبط تدفقات البيانات وتحسينها بحيث تلبي معايير الأداء الخاصة بك.
شاهد الفيديو التالي لمشاهدته يعرض بعض عينات التوقيتات التي تحول البيانات باستخدام تدفقات البيانات.
مراقبة أداء تدفق البيانات
بمجرد التحقق من منطق التحويل الخاص بك باستخدام وضع التصحيح، قم بتشغيل تدفق البيانات من طرف إلى طرف كنشاط في خط أنابيب. يتم تشغيل تدفقات البيانات في البنية الأساسية لبرنامج ربط العمليات التجارية باستخدام نشاط تنفيذ تدفق البيانات. يتمتع نشاط تدفق البيانات بتجربة مراقبة فريدة مقارنة بالأنشطة الأخرى التي تعرض خطة تنفيذ مفصلة وملف تعريف أداء لمنطق التحويل. لعرض معلومات المراقبة التفصيلية لتدفق البيانات، حدد أيقونة النظارات في إخراج تشغيل النشاط للبنية الأساسية لبرنامج ربط العمليات التجارية. لمزيد من المعلومات، راجع مراقبة تدفقات بيانات التعيين.

عند مراقبة أداء تدفق البيانات، هناك أربعة اختناقات محتملة للبحث عنها:
- وقت بدء الكتلة
- القراءة من المصدر
- وقت التحول
- الكتابة في المجموعة
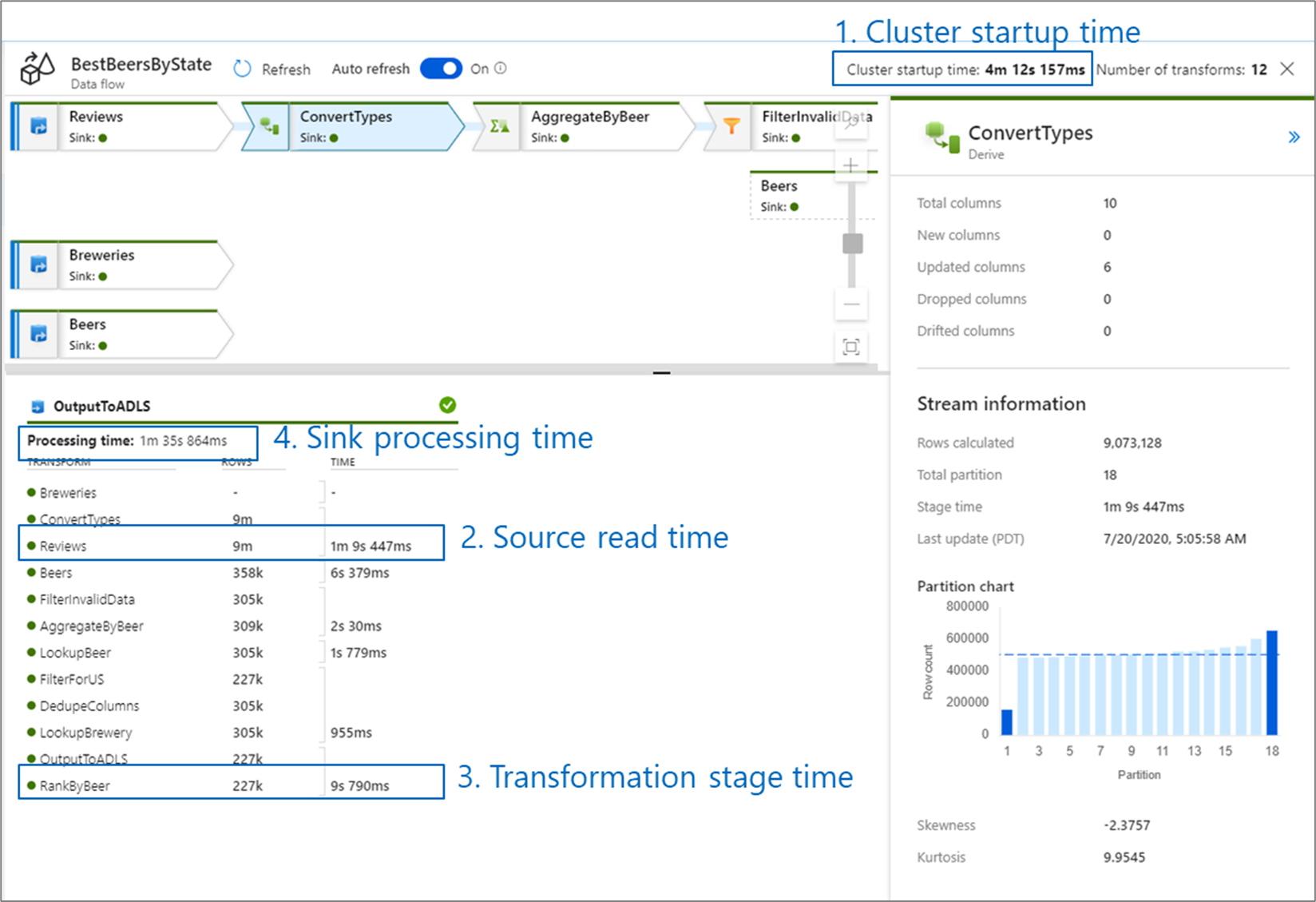
وقت بدء تشغيل الكتلة هو الوقت الذي يستغرقه تدوير مجموعة Apache Spark. توجد هذه القيمة في الزاوية العلوية اليمنى من شاشة المراقبة. تعمل تدفقات البيانات على نموذج في الوقت المناسب حيث تستخدم كل وظيفة مجموعة معزولة. يستغرق وقت بدء التشغيل هذا عادة من 3 إلى 5 دقائق. بالنسبة للوظائف المتتالية، يمكن تقليل وقت بدء التشغيل عن طريق تمكين قيمة مدة البقاء. لمزيد من المعلومات، راجع قسم مدة البقاء في أداء وقت تشغيل التكامل.
تستخدم تدفقات البيانات مُحسِّن Spark الذي يعيد ترتيب وتشغيل منطق عملك في "مراحل" لأداء أسرع وقت ممكن. لكل مجموعة تتدفق لها البيانات، تسرد مخرجات المراقبة مدة كل مرحلة تحويل، جنباً إلى جنب مع الوقت المستغرق لتدوين البيانات في المجموعة. من المحتمل أن يتم استهلاك الوقت الأكبر في توقف تدفق البيانات. إذا كانت مرحلة التحويل التي تأخذ الأكبر تحتوي على مصدر، فقد تحتاج إلى النظر في تحسين وقت القراءة بشكل أكبر. إذا استغرق التحويل وقتا طويلا، فقد تحتاج إلى إعادة تقسيم أو زيادة حجم وقت تشغيل التكامل. إذا كان وقت معالجة المتلقي كبيرا، فقد تحتاج إلى توسيع نطاق قاعدة البيانات أو التحقق من عدم الإخراج إلى ملف واحد.
بمجرد تحديد عنق الزجاجة لتدفق البيانات الخاصة بك، استخدم إستراتيجيات التحسين أدناه لتحسين الأداء.
اختبار منطق تدفق البيانات
عند تصميم تدفقات البيانات واختبارها من واجهة المستخدم، يسمح لك وضع تتبع الأخطاء بالاختبار بشكل تفاعلي مقابل نظام مجموعة Spark مباشر، مما يسمح لك بمعاينة البيانات وتنفيذ تدفقات البيانات الخاصة بك دون انتظار إعداد نظام مجموعة. لمزيد من المعلومات، راجع وضع التصحيح.
علامة التبويب تحسين
تحتوي علامة التبويب Optimize على إعدادات لتكوين نظام التقسيم لمجموعة Spark. توجد علامة التبويب هذه في كل تحويل لتدفق البيانات وتحدد ما إذا كنت تريد إعادة تقسيم البيانات بعد اكتمال التحويل. يوفر ضبط التقسيم التحكم في توزيع بياناتك عبر عقد الحوسبة وتحسينات منطقة البيانات التي يمكن أن يكون لها تأثيرات إيجابية وسلبية على أداء تدفق البيانات الإجمالي.
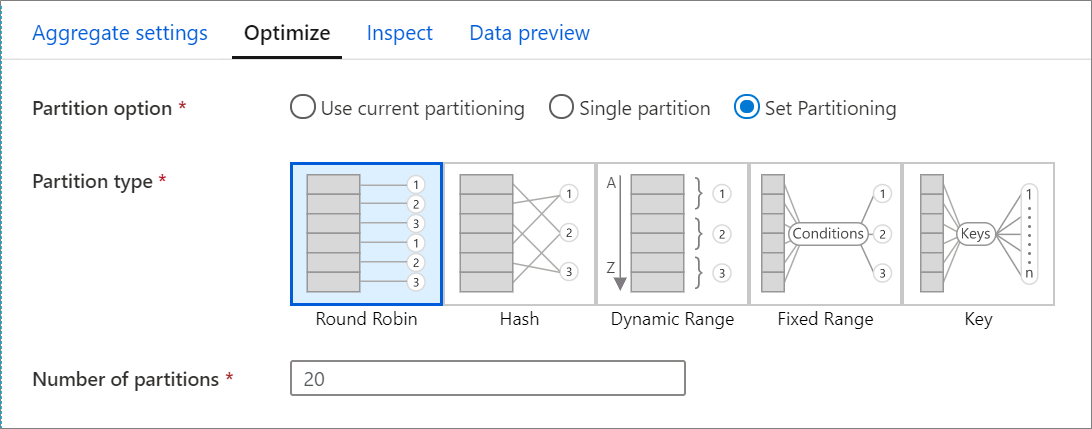
بشكل افتراضي، يتم تحديد استخدام التقسيم الحالي الذي يوجه الخدمة للحفاظ على تقسيم الإخراج الحالي للتحويل. نظرا لأن إعادة تقسيم البيانات تستغرق وقتا، يوصى باستخدام التقسيم الحالي في معظم السيناريوهات. تتضمن السيناريوهات التي قد ترغب في إعادة تقسيم بياناتك فيها بعد التجميعات والصلات التي تنحرف بياناتك بشكل كبير أو عند استخدام تقسيم المصدر على قاعدة بيانات SQL.
لتغيير التقسيم على أي تحويل، حدد علامة التبويب تحسين وحدد الزر التبادلي تعيين التقسيم . يتم تقديم سلسلة من الخيارات للتقسيم. تختلف أفضل طريقة للتقسيم بناءً على أحجام البيانات والمفاتيح المرشحة والقيم الفارغة والعلاقة الأساسية.
هام
يجمع قسم واحد كل البيانات الموزعة في قسم واحد. هذه عملية بطيئة للغاية تؤثر أيضاً بشكل كبير على جميع عمليات التحويل في الاتجاه والكتابة. لا يُنصح بشدة بهذا الخيار ما لم يكن هناك سبب تجاري واضح لاستخدامه.
تتوفر خيارات التقسيم التالية في كل تحويل:
ترتيب دوري
يوزع Round robin البيانات بالتساوي عبر الأقسام. استخدم round-robin عندما لا يكون لديك مرشحون أساسيون مميزون لتنفيذ إستراتيجية تقسيم ذكية وقوية. يمكنك ضبط عدد الأقسام المادية.
Hash
تنتج الخدمة تجزئة من الأعمدة لإنتاج أقسام موحدة بحيث تقع الصفوف ذات القيم المماثلة في نفس القسم. عند استخدام خيار Hash، اختبر انحراف القسم المحتمل. يمكنك ضبط عدد الأقسام المادية.
النطاق الديناميكي
يستخدم النطاق الديناميكي نطاقات Spark الديناميكية بناءً على الأعمدة أو التعبيرات التي توفرها. يمكنك ضبط عدد الأقسام المادية.
النطاق الثابت
أنشئ تعبيراً يوفر نطاقاً ثابتاً للقيم داخل أعمدة البيانات المقسمة. لتجنب انحراف التقسيم، يجب أن يكون لديك فهم جيد لبياناتك قبل استخدام هذا الخيار. يتم استخدام القيم التي تدخلها للتعبير كجزء من دالة القسم. يمكنك ضبط عدد الأقسام المادية.
مفتاح
إذا كان لديك فهم جيد للعناصر الأساسية لبياناتك، فقد يكون تقسيم المفاتيح إستراتيجية جيدة. يُنشئ التقسيم الرئيسي أقساماً لكل قيمة فريدة في العمود الخاص بك. لا يمكنك تعيين عدد الأقسام لأن الرقم يعتمد على قيم فريدة في البيانات.
تلميح
يؤدي تعيين مخطط التقسيم يدوياً إلى إعادة ترتيب البيانات ويمكن أن يعوض فوائد مُحسِّن Spark. أفضل ممارسة هي عدم تعيين التقسيم يدوياً إلا إذا كنت بحاجة إلى ذلك.
مستوى التسجيل
إذا كنت لا تتطلب كل تنفيذ البنية الأساسية لبرنامج ربط العمليات التجارية لأنشطة تدفق البيانات لتسجيل جميع سجلات بيانات تتبع الاستخدام المطولة بالكامل، يمكنك اختياريا تعيين مستوى التسجيل إلى "أساسي" أو "بلا". عند تنفيذ تدفقات البيانات في وضع "مطول" (افتراضي)، فأنت تطلب من الخدمة تسجيل النشاط بالكامل على كل مستوى قسم فردي أثناء تحويل البيانات. قد تكون هذه عملية مكلفة، لذا فإن التمكين المطول فقط عند استكشاف الأخطاء وإصلاحها يمكن أن يحسّن من تدفق البيانات الكلي وأداء البنية الأساسية لبرنامج ربط العمليات التجارية. يقوم الوضع "الأساسي" بتسجيل مدد التحويل فقط بينما يوفر "بلا" ملخصا للمدد فقط.

المحتوى ذو الصلة
راجع مقالات تدفق البيانات الأخرى المتعلقة بالأداء: