تجسن المصادر
لكل مصدر باستثناء قاعدة بيانات Azure SQL، يوصى بالاحتفاظ باستخدام التقسيم الحالي كقيمة محددة. عند القراءة من جميع أنظمة المصدر الأخرى، تقسم تدفقات البيانات تلقائيا البيانات بالتساوي بناء على حجم البيانات. يتم إنشاء قسم جديد لكل 128 ميغا بايت من البيانات. كلما زاد حجم بياناتك، زاد عدد الأقسام.
يحدث أي تقسيم مخصص بعد قراءة Spark للبيانات والتأثير سلبا على أداء تدفق البيانات. نظرا لأن البيانات مقسمة بالتساوي عند القراءة، فلا يوصى بها ما لم تفهم شكل بياناتك وعلاقة أساسية بها أولا.
إشعار
يمكن أن تكون سرعات القراءة محدودة من خلال إنتاجية نظام المصدر الخاص بك.
مصادر قاعدة بيانات Azure SQL
تحتوي قاعدة بيانات Azure SQL على خيار تقسيم فريد يسمى تقسيم "المصدر". يمكن أن يؤدي تمكين تقسيم المصدر إلى تحسين أوقات القراءة من قاعدة بيانات Azure SQL عن طريق تمكين الاتصالات المتوازية على النظام المصدر. حدد عدد الأقسام وكيفية تقسيم بياناتك. استخدم عمود قسم به عدد أساسيات عالية. يمكنك أيضاً إدخال استعلام يطابق مخطط التقسيم لجدول المصدر.
تلميح
بالنسبة لتقسيم المصدر، فإن الإدخال / الإخراج لخادم SQL هو أمر مقيد. قد تؤدي إضافة عدد كبير جداً من الأقسام إلى تشبع قاعدة بيانات المصدر. بشكل عام أربعة أو خمسة أقسام مثالية عند استخدام هذا الخيار.
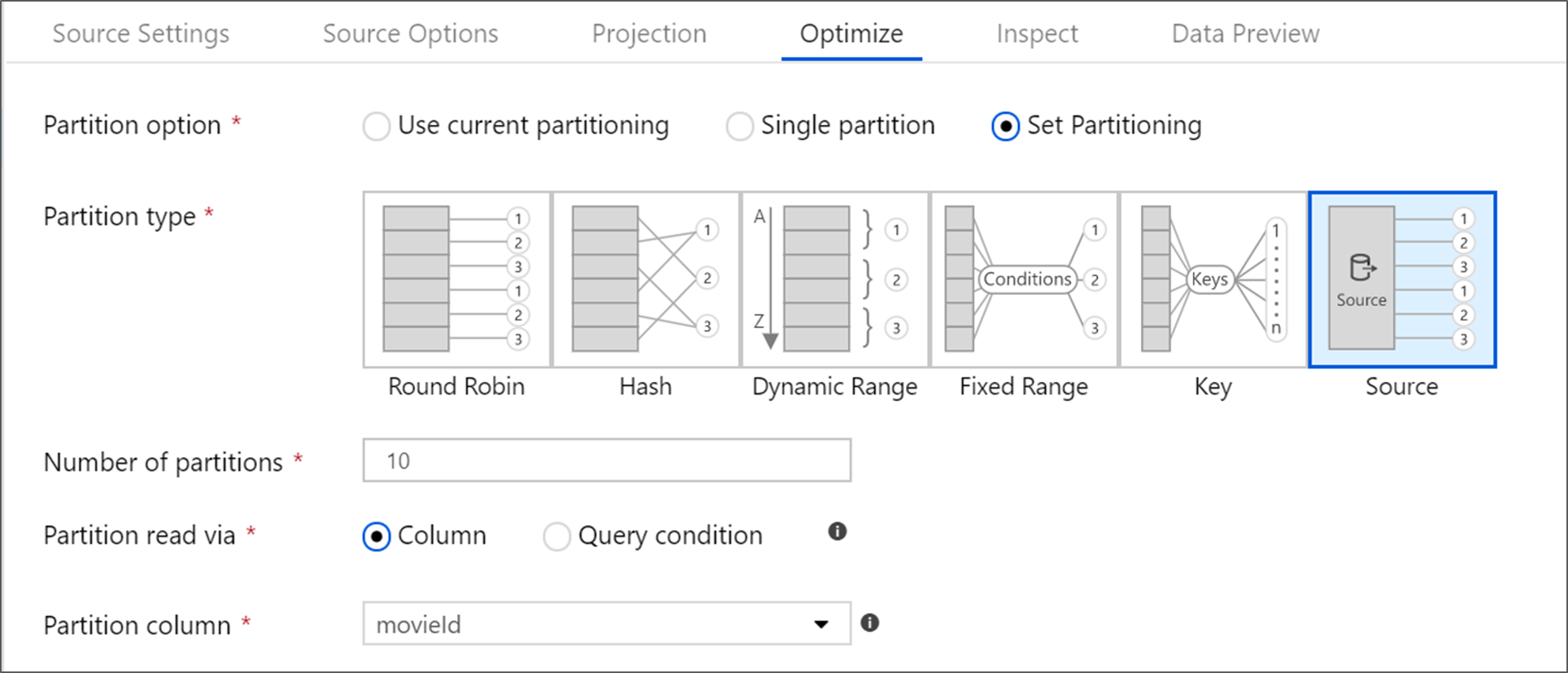
مستوى العزلة
يؤثر مستوى عزل القراءة على نظام مصدر Azure SQL على الأداء. يوفر اختيار "قراءة غير ملتزمة" أسرع أداء ويمنع أي تأمين لقاعدة البيانات. لمعرفة المزيد حول مستويات عزل SQL، راجع فهم مستويات العزل.
اقرأ باستخدام الاستعلام
يمكنك القراءة من قاعدة بيانات Azure SQL باستخدام جدول أو استعلام SQL. إذا كنت تقوم بتنفيذ استعلام SQL، يجب أن يكتمل الاستعلام قبل بدء التحويل. يمكن أن تكون استعلامات SQL مفيدة لدفع العمليات التي قد تنفذ بشكل أسرع وتقليل كمية البيانات المقروءة من SQL Server مثل عبارات SELECT و WHERE و JOIN. عند الضغط على العمليات، تفقد القدرة على تتبع النسب وأداء التحويلات قبل أن تدخل البيانات في تدفق البيانات.
مصادر تحليلات Azure Synapse
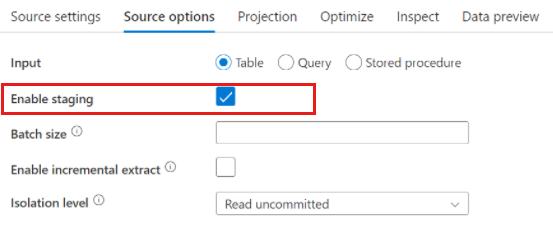
عند استخدام Azure Synapse Analytics، يوجد إعداد يسمى Enable staging في خيارات المصدر. يسمح هذا للخدمة بالقراءة من Synapse باستخدام Staging، ما يحسن أداء القراءة بشكل كبير باستخدام إمكانية التحميل المجمع الأكثر أداء مثل الأمر CETAS و COPY. يتطلب التمكين Staging تحديد موقع التقسيم المرحلي Azure Blob Storage أو Azure Data Lake Storage gen2 في إعدادات نشاط تدفق البيانات.
المصادر المستندة إلى الملفات
Parquet مقابل النص المحدد
بينما تدعم تدفقات البيانات أنواع ملفات مختلفة، يوصى بتنسيق Spark-native Parquet لأوقات القراءة والكتابة المثلى.
إذا كنت تقوم بتشغيل نفس تدفق البيانات على مجموعة من الملفات، فإننا نوصي بالقراءة من مجلد، باستخدام مسارات أحرف البدل أو القراءة من قائمة الملفات. يمكن أن يقوم تشغيل نشاط تدفق بيانات واحد بمعالجة جميع ملفاتك دفعة واحدة. يمكن العثور على مزيد من المعلومات حول كيفية تكوين هذه الإعدادات في قسم تحويل المصدر في وثائق موصل Azure Blob Storage.
إذا أمكن، تجنب استخدام نشاط For-Each لتشغيل تدفقات البيانات عبر مجموعة من الملفات. يؤدي هذا كل تكرار لكل منهما إلى تدوير مجموعة Spark الخاصة به، والتي غالبا ما تكون غير ضرورية ويمكن أن تكون مكلفة.
مجموعات البيانات المضمنة مقابل مجموعات البيانات المشتركة
مجموعات بيانات ADF وSynapse هي موارد مشتركة في المصانع ومساحات العمل الخاصة بك. ومع ذلك، عند قراءة أعداد كبيرة من المجلدات المصدر والملفات ذات النص المحدد ومصادر JSON، يمكنك تحسين أداء اكتشاف ملف تدفق البيانات عن طريق تعيين الخيار "مخطط المستخدم المتوقع" داخل الإسقاط | مربع حوار خيارات المخطط. يؤدي هذا الخيار إلى إيقاف تشغيل الاكتشاف التلقائي للمخطط الافتراضي ل ADF وتحسين أداء اكتشاف الملفات بشكل كبير. قبل تعيين هذا الخيار، تأكد من استيراد الإسقاط بحيث يحتوي ADF على مخطط موجود للإسقاط. لا يعمل هذا الخيار مع انحراف المخطط.
المحتوى ذو الصلة
راجع مقالات تدفق البيانات الأخرى المتعلقة بالأداء:
الملاحظات
قريبًا: خلال عام 2024، سنتخلص تدريجيًا من GitHub Issues بوصفها آلية إرسال ملاحظات للمحتوى ونستبدلها بنظام ملاحظات جديد. لمزيد من المعلومات، راجع https://aka.ms/ContentUserFeedback.
إرسال الملاحظات وعرضها المتعلقة بـ