إشعار
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تسجيل الدخول أو تغيير الدلائل.
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تغيير الدلائل.
ينطبق على: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
تلميح
Data Factory في Microsoft Fabric هو الجيل التالي من Azure Data Factory، مع بنية أبسط وذكاء الاصطناعي المدمج وميزات جديدة. إذا كنت جديدا على تكامل البيانات، فابدأ ب Fabric Data Factory. يمكن ترقية أحمال عمل ADF الحالية إلى Fabric للوصول إلى قدرات جديدة عبر علوم البيانات والتحليلات في الوقت الحقيقي وإعداد التقارير.
اتبع هذه المقالة عندما تريد تحليل ملفات JSON أو كتابة البيانات بتنسيق JSON.
يتم اعتماد تنسيق JSON للموصلات التالية:
- أمازون S3
- التخزين المتوافق مع Amazon S3،
- Azure Blob
- Azure Data Lake Storage Gen1
- Azure Data Lake Storage Gen2
- ملفات Azure
- نظام الملفات
- بروتوكول نقل الملفات
- التخزين السحابي من Google
- HDFS
- HTTP
- أوراكل كلاود سترجينج
- SFTP
خصائص مجموعة البيانات
للحصول على قائمة كاملة بالأقسام والخصائص المتوفرة لتعريف مجموعات البيانات، راجع مقالة مجموعات البيانات. يوفر هذا القسم قائمة بالخصائص المعتمدة من قبل مجموعة بيانات JSON.
| الخاصية | الوصف | مطلوب |
|---|---|---|
| النوع | يجب تعيين خاصية نوع مجموعة البيانات إلى JSON. | نعم |
| مكان | إعدادات الموقع للملف (الملفات). يحتوي كل موصل يستند إلى ملف على نوع الموقع الخاص به وخصائص مدعومة ضمن location.
راجع التفاصيل الواردة في مقالة الموصل -> قسم خصائص مجموعة البيانات. |
نعم |
| encodingName | نوع الترميز المُستخدم لقراءة/ كتابة ملفات الاختبار. فيما يلي القيم المسموح بها: "UTF-8","UTF-8 without BOM", "UTF-16", "UTF-16BE", "UTF-32", "UTF-32BE", "US-ASCII", "UTF-7", "BIG5", "EUC-JP", "EUC-KR", "GB2312", "GB18030", "JOHAB", "SHIFT-JIS", "CP875", "CP866", "IBM00858", "IBM037", "IBM273", "IBM437", "IBM500", "IBM737", "IBM775", "IBM850", "IBM852", "IBM855", "IBM857", "IBM860", "IBM861", "IBM863", "IBM864", "IBM865", "IBM869", "IBM870", "IBM01140", "IBM01141", "IBM01142", "IBM01143", "IBM01144", "IBM01145", "IBM01146", "IBM01147", "IBM01148", "IBM01149", "ISO-2022-JP", "ISO-2022-KR", "ISO-8859-1", "ISO-8859-2", "ISO-8859-3", "ISO-8859-4", "ISO-8859-5", "ISO-8859-6", "ISO-8859-7", "ISO-8859-8", "ISO-8859-9", "ISO-8859-13", "ISO-8859-15", "WINDOWS-874", "WINDOWS-1250", "WINDOWS-1251", "WINDOWS-1252", "WINDOWS-1253", "WINDOWS-1254", "WINDOWS-1255", "WINDOWS-1256", "WINDOWS-1257", "WINDOWS-1258". |
لا |
| ضغط | مجموعة من الخصائص لتكوين ضغط الملف. قم بتكوين هذا القسم عندما تريد الضغط / فك الضغط أثناء تنفيذ النشاط. | لا |
| النوع (أسفل compression) |
برنامج ترميز الضغط المستخدم لقراءة / كتابة ملفات JSON. القيم المسموح بها هي bzip2، أو gzip، أو deflate، أو ZipDeflate، أو TarGzip، أو Tar، أو snappy، أو lz4. لا يتم ضغط الافتراضي. لا يدعم Note حاليا Copy activity "snappy" و"lz4"، ولا يدعم تعيين تدفق البيانات "ZipDeflate" و"TarGzip" و"Tar". ملاحظة عند استخدام نشاط النسخ لفك ضغط ملف (ملفات) ZipDeflate/TarGzip /Tar والكتابة إلى ملف مستند إلى مخزن بيانات التخزين، يتم استخراج الملفات افتراضياً إلى المجلد: <path specified in dataset>/<folder named as source compressed file>/، استخدم preserveZipFileNameAsFolder/preserveCompressionFileNameAsFolder في مصدر نشاط النسخ للتحكم في الاحتفاظ باسم الملف (الملفات) المضغوطة كهيكل مجلد. |
لا. |
| المستوى (أسفل compression) |
نسبة الضغط. القيم المسموح بها هي Optimal أو Fastest. - الأسرع: يجب أن تكتمل عملية الضغط بأسرع وقت ممكن، حتى إذا لم يتم ضغط الملف الناتج بشكل أمثل. - الأمثل : يجب ضغط عملية الضغط على النحو الأمثل، حتى لو استغرقت العملية وقتاً أطول حتى تكتمل. لمزيد من المعلومات، يمكنك الاطلاع على موضوع مستوى الضغط. |
لا |
فيما يلي مثال على مجموعة بيانات JSON على مساحة تخزين Azure Blob:
{
"name": "JSONDataset",
"properties": {
"type": "Json",
"linkedServiceName": {
"referenceName": "<Azure Blob Storage linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"location": {
"type": "AzureBlobStorageLocation",
"container": "containername",
"folderPath": "folder/subfolder",
},
"compression": {
"type": "gzip"
}
}
}
}
خصائص Copy activity
للحصول على قائمة كاملة بالأقسام والخصائص المتوفرة لتعريف الأنشطة، راجع مقالة التدفقات. يوفر هذا المقطع قائمة الخصائص المعتمدة من قبل مصدر بيانات JSON والمتلقي.
تعرف على كيفية استخراج البيانات من ملفات JSON وخريطة متلقي مخزن البيانات/ تنسيقها أو العكس بالعكس من تعيين المخطط.
JSON كمصدر
يتم دعم الخصائص التالية في جزء نسخ النشاط *Source*.
| الخاصية | الوصف | مطلوب |
|---|---|---|
| النوع | يجب تعيين خاصية نوع مصدر نشاط النسخ إلى JSONSource. | نعم |
| إعدادات التنسيقات | مجموعة من الخصائص. راجع جدول إعدادات قراءة JSON أدناه. | لا |
| إعدادات المخزن | lمجموعة من الخصائص حول كيفية قراءة البيانات من مخزن بيانات. يحتوي كل موصل يستند إلى ملف إعدادات القراءة المدعومة الخاصة به ضمن storeSettings.
انظر التفاصيل في مقالة الموصل -قسم خصائص > Copy activity. |
لا |
إعدادات قراءة JSON المعتمدة الواردة أدناه formatSettings:
| الخاصية | الوصف | مطلوب |
|---|---|---|
| النوع | يجب تعيين نوع formatSettings إلى JsonReadSettings. | نعم |
| compressionProperties | مجموعة من الخصائص حول كيفية إلغاء ضغط البيانات من أجل برنامج ترميز ضغط معين. | لا |
| preserveZipFileNameAsFolder (ضمن compressionProperties->type كـ ZipDeflateReadSettings) |
ينطبق عند تكوين مجموعة بيانات الإدخال بضغط ZipDeflate. يشير إلى ما إذا كان يجب الاحتفاظ باسم الملف البريدي المصدر كبنية مجلد أثناء النسخ. - عند التعيين على "True" (افتراضي)، تكتب الخدمة الملفات التي تم فك ضغطها إلى <path specified in dataset>/<folder named as source zip file>/.- عند التعيين على False، تقوم الخدمة بكتابة الملفات التي تم إلغاء ضغطها مباشرة إلى <path specified in dataset>. تأكد من عدم تكرار أسماء الملفات في مصدر ملفات zip المختلفة لتجنب السباق أو السلوك غير المتوقع. |
لا |
| preserveCompressionFileNameAsFolder ( ضمن compressionProperties->type كـ TarGZipReadSettings أو TarReadSettings) |
ينطبق عندما يتم تكوين مجموعة بيانات الإدخال بضغط TarGzip/Tar. يشير إلى ما إذا كان سيتم الاحتفاظ باسم الملف المضغوط المصدر كبنية مجلد أثناء النسخ. - عند تعيين إلى "true" (افتراضي)، تكتب الخدمة الملفات التي تم فك ضغطها إلى <path specified in dataset>/<folder named as source compressed file>/. - عند التعيين إلى "false"، تكتب الخدمة الملفات الغير مضغوطة مباشرة إلى <path specified in dataset>. تأكد من عدم تكرار أسماء الملفات في ملفات مصدر مختلفة لتجنب السباق أو السلوك غير المتوقع. |
لا |
JSON كمتلقي
الخصائص التالية مدعومة في نشاط النسخ * lمتلقي * القسم.
| الخاصية | الوصف | مطلوب |
|---|---|---|
| النوع | يجب تعيين خاصية نوع مصدر نشاط النسخ إلى JSONSink. | نعم |
| إعدادات التنسيقات | مجموعة من الخصائص. راجع جدول إعدادات كتابة JSON أدناه. | لا |
| إعدادات المخزن | مجموعة من الخصائص حول كيفية كتابة البيانات إلى مخزن بيانات. يحتوي كل موصل يستند إلى ملف إعدادات الكتابة المعتمدة الخاصة به ضمن storeSettings.
انظر التفاصيل في مقالة الموصل -قسم خصائص > Copy activity. |
لا |
إعدادات كتابة JSON المعتمدة الواردة أدناه formatSettings:
| الخاصية | الوصف | مطلوب |
|---|---|---|
| النوع | يجب تعيين نوع formatSettings إلى JsonWriteSettings. | نعم |
| filePattern | يشير إلى نمط البيانات المخزنة في كل ملف JSON. القيم المسموح بها هي: setOfObjects (خطوط JSON) وarrayOfObjects. القيمة الافتراضية هي setOfObjects. يمكنك الاطلاع على قسم أنماط ملفات JSON للحصول على تفاصيل أكثر حول هذه الأنماط. | لا |
أنماط ملفات JSON
عند نسخ البيانات من ملفات JSON يمكن لنشاط النسخ اكتشاف الأنماط التالية لملفات JSON وتحليلها تلقائياً. عند كتابة البيانات إلى ملفات JSON، يمكنك تكوين نمط الملف على مصدر نشاط النسخ.
الفئة الأولى: setOfObjects
يحتوي كل ملف على كائن واحد أو خطوط JSON أو عناصر متصلة.
مثال نموذج JSON كائن واحد
{ "time": "2015-04-29T07:12:20.9100000Z", "callingimsi": "466920403025604", "callingnum1": "678948008", "callingnum2": "567834760", "switch1": "China", "switch2": "Germany" }خطوط JSON (افتراضي للمتلقي)
{"time":"2015-04-29T07:12:20.9100000Z","callingimsi":"466920403025604","callingnum1":"678948008","callingnum2":"567834760","switch1":"China","switch2":"Germany"} {"time":"2015-04-29T07:13:21.0220000Z","callingimsi":"466922202613463","callingnum1":"123436380","callingnum2":"789037573","switch1":"US","switch2":"UK"} {"time":"2015-04-29T07:13:21.4370000Z","callingimsi":"466923101048691","callingnum1":"678901578","callingnum2":"345626404","switch1":"Germany","switch2":"UK"}مثال JSON المتصل
{ "time": "2015-04-29T07:12:20.9100000Z", "callingimsi": "466920403025604", "callingnum1": "678948008", "callingnum2": "567834760", "switch1": "China", "switch2": "Germany" } { "time": "2015-04-29T07:13:21.0220000Z", "callingimsi": "466922202613463", "callingnum1": "123436380", "callingnum2": "789037573", "switch1": "US", "switch2": "UK" } { "time": "2015-04-29T07:13:21.4370000Z", "callingimsi": "466923101048691", "callingnum1": "678901578", "callingnum2": "345626404", "switch1": "Germany", "switch2": "UK" }
الفئة الثانية: arrayOfObjects
يحتوي كل ملف على صفيف من العناصر.
[ { "time": "2015-04-29T07:12:20.9100000Z", "callingimsi": "466920403025604", "callingnum1": "678948008", "callingnum2": "567834760", "switch1": "China", "switch2": "Germany" }, { "time": "2015-04-29T07:13:21.0220000Z", "callingimsi": "466922202613463", "callingnum1": "123436380", "callingnum2": "789037573", "switch1": "US", "switch2": "UK" }, { "time": "2015-04-29T07:13:21.4370000Z", "callingimsi": "466923101048691", "callingnum1": "678901578", "callingnum2": "345626404", "switch1": "Germany", "switch2": "UK" } ]
تعيين خصائص تدفق البيانات
في تعيين تدفقات البيانات، يمكنك القراءة والكتابة بتنسيق JSON في مخازن البيانات التالية: مساحة تخزين Azure Blob، Azure Data Lake Storage Gen1، Azure Data Lake Storage Gen2 و SFTP، ويمكنك قراءة تنسيق JSON في Amazon S3.
خصائص المصدر
يسرد الجدول أدناه الخصائص المعتمدة من مصدر json. يمكنك تحرير هذه الخصائص في علامة التبويب "Source options".
| Name | الوصف | مطلوب | القيم المسموح بها | خاصية البرنامج النصي لتدفق البيانات |
|---|---|---|---|---|
| مسارات محرف البدل | ستتم معالجة جميع الملفات المطابقة لمسار محرف البدل. يتجاوز المجلد ومسار الملف المحددين في مجموعة البيانات. | no | سلسلة[] | wildcardPaths |
| مسار جذر التقسيم | بالنسبة لبيانات الملف المقسمة، يمكنك إدخال مسار جذر القسم لقراءة المجلدات المقسمة كأعمدة | no | السلسلة | partitionRootPath |
| قائمة الملفات | ما إذا كان المصدر يشير إلى ملف نصي يسرد الملفات المراد معالجتها | no |
true أو false |
قائمة الملفات |
| عمود لتخزين اسم الملف | إنشاء عمود جديد باسم الملف المصدر ومساره | no | السلسلة | rowUrlColumn |
| بعد الانتهاء | احذف أو انقل الملفات بعد المعالجة. مسار الملف يبدأ من جذر الحاوية | no | حذف: true أو false نقل: ['<from>', '<to>'] |
إزالة الملفات نقل الملفات |
| التصفية حسب آخر تعديل | اختيار تصفية الملفات استناداً إلى آخر مرة تم تبديلها | no | طابع زمني | تم التعديل بعد ذلك modifiedBefore |
| مستند واحد | تعيين تدفقات بيانات قراءة مستند JSON واحد من كل ملف | no |
true أو false |
singleDocument |
| أسماء أعمدة غير مقتبسة | إذا تم تحديد "Unquoted column names" فإن تعيين تدفقات البيانات يقرأ أعمدة JSON غير محاطة بعروض الأسعار. | no |
true أو false |
unquotedColumnNames |
| لديه تعليقات | حدد يحتوي على تعليقات إذا كان بيانات JSON لديها تعليق على نمط C أو C++ | no |
true أو false |
asComments |
| واحد نقلت | قراءة أعمدة JSON غير المحاطة بعروض الأسعار | no |
true أو false |
singleQuoted |
| تجاوز الخط المائل العكسي | تحديد "Backslash escaped" إذا تم استخدام الخطوط المائلة العكسية لحروف الإلغاء في بيانات JSON | no |
true أو false |
backslashEscape |
| السماح بعدم العثور على أي ملفات | إذا كان هذا صحيحاً، فلن يتم طرح خطأ إذا لم يتم العثور على ملفات | no |
true أو false |
ignoreNoFilesFound |
مجموعة بيانات مضمنة
يدعم تعيين تدفقات البيانات "مجموعات البيانات المضمنة" كخيار لتعريف المصدر والمتلقي. يتم تعريف مجموعة بيانات JSON المضمنة مباشرة داخل تحويلات المصدر والمتلقي ولا تتم مشاركتها خارج تدفق البيانات المحدد. من المفيد تحديد معلمات خصائص مجموعة البيانات مباشرة داخل تدفق البيانات الخاص بك ويمكن أن تستفيد من الأداء المحسن عبر مجموعات بيانات ADF المشتركة.
عند قراءة أعداد كبيرة من المجلدات والملفات المصدر، يمكنك تحسين أداء اكتشاف ملف تدفق البيانات عن طريق تعيين الخيار "مخطط المستخدم المتوقع" داخل العرض | مربع حوار خيارات المخطط. يؤدي هذا الخيار إلى إيقاف تشغيل الاكتشاف التلقائي للمخطط الافتراضي ل ADF وسيحسن أداء اكتشاف الملفات بشكل كبير. قبل تعيين هذا الخيار، تأكد من استيراد إسقاط JSON بحيث يحتوي ADF على مخطط موجود للإسقاط. لا يعمل هذا الخيار مع انحراف المخطط.
خيارات تنسيق مصدر البيانات
يتيح لك استخدام مجموعة بيانات JSON كمصدر في تدفق البيانات تعيين خمسة إعدادات إضافية. يمكن العثور على هذه الإعدادات ضمن إعدادات JSON تحت علامة التبويب خيارات المصدر. بالنسبة لإعداد نموذج المستند، يمكنك تحديد أحد الأنواع المستند الواحد و المستند لكل سطر و مجموعة المستندات.

الإعداد الافتراضي
بشكل افتراضي، تتم قراءة بيانات JSON بالتنسيق التالي.
{ "json": "record 1" }
{ "json": "record 2" }
{ "json": "record 3" }
مستند واحد
إذا تم تحديد "Single document" فإن تعيين تدفقات البيانات يقرأ مستند JSON واحد من كل ملف.
File1.json
{
"json": "record 1"
}
File2.json
{
"json": "record 2"
}
File3.json
{
"json": "record 3"
}
إذا تم تحديد "Document per line" فإن تعيين تدفقات البيانات يقرأ مستند JSON واحد من كل سطر في ملف.
File1.json
{"json": "record 1"}
File2.json
{"time":"2015-04-29T07:12:20.9100000Z","callingimsi":"466920403025604","callingnum1":"678948008","callingnum2":"567834760","switch1":"China","switch2":"Germany"}
{"time":"2015-04-29T07:13:21.0220000Z","callingimsi":"466922202613463","callingnum1":"123436380","callingnum2":"789037573","switch1":"US","switch2":"UK"}
File3.json
{"time":"2015-04-29T07:12:20.9100000Z","callingimsi":"466920403025604","callingnum1":"678948008","callingnum2":"567834760","switch1":"China","switch2":"Germany"}
{"time":"2015-04-29T07:13:21.0220000Z","callingimsi":"466922202613463","callingnum1":"123436380","callingnum2":"789037573","switch1":"US","switch2":"UK"}
{"time":"2015-04-29T07:13:21.4370000Z","callingimsi":"466923101048691","callingnum1":"678901578","callingnum2":"345626404","switch1":"Germany","switch2":"UK"}
إذا تم تحديد "Array of documents" فإن تعيين تدفقات البيانات يقرأ صفيفاً واحداً من المستند من ملف.
File.json
[
{
"time": "2015-04-29T07:12:20.9100000Z",
"callingimsi": "466920403025604",
"callingnum1": "678948008",
"callingnum2": "567834760",
"switch1": "China",
"switch2": "Germany"
},
{
"time": "2015-04-29T07:13:21.0220000Z",
"callingimsi": "466922202613463",
"callingnum1": "123436380",
"callingnum2": "789037573",
"switch1": "US",
"switch2": "UK"
},
{
"time": "2015-04-29T07:13:21.4370000Z",
"callingimsi": "466923101048691",
"callingnum1": "678901578",
"callingnum2": "345626404",
"switch1": "Germany",
"switch2": "UK"
}
]
إشعار
إذا كانت تدفقات البيانات تطرح خطأ يفيد "corrupt_record" عند معاينة بيانات JSON، فمن المحتمل أن تحتوي بياناتك على مستند واحد في ملف JSON. يجب أن يؤدي تعيين "single document" إلى مسح هذا الخطأ.
أسماء أعمدة غير مقتبسة
إذا تم تحديد "Unquoted column names" فإن تعيين تدفقات البيانات يقرأ أعمدة JSON غير محاطة بعروض الأسعار.
{ json: "record 1" }
{ json: "record 2" }
{ json: "record 3" }
لديه تعليقات
حدد "Has comments" إذا كان لدى بيانات JSON تعليق على نمط C أو C++.
{ "json": /** comment **/ "record 1" }
{ "json": "record 2" }
{ /** comment **/ "json": "record 3" }
واحد نقلت
حدد "Single quoted" إذا استخدمت حقول وقيم JSON علامات اقتباس مفردة بدلاً من علامات الاقتباس المزدوجة.
{ 'json': 'record 1' }
{ 'json': 'record 2' }
{ 'json': 'record 3' }
تجاوز الخط المائل العكسي
تحديد "Backslash escaped" إذا تم استخدام الخطوط المائلة العكسية لحروف الإلغاء في بيانات JSON.
{ "json": "record 1" }
{ "json": "\} \" \' \\ \n \\n record 2" }
{ "json": "record 3" }
خصائص المتلقي
يسرد الجدول أدناه الخصائص المعتمدة بواسطة متلقي json. يمكنك تحرير هذه الخصائص في علامة التبويب "Settings".
| Name | الوصف | مطلوب | القيم المسموح بها | خاصية البرنامج النصي لتدفق البيانات |
|---|---|---|---|---|
| مسح المجلد | إذا تم مسح المجلد الوجهة قبل الكتابة | no |
true أو false |
اقتطاع |
| خيار اسم الملف | تنسيق تسمية البيانات المكتوبة. بشكل افتراضي، ملف واحد لكل قسم بالتنسيق part-#####-tid-<guid> |
no | النمط: سلسلة لكل قسم: سلسلة[] كبيانات في العمود: سلسلة الإخراج إلى ملف واحد: ['<fileName>'] |
filePattern partitionFileNames rowUrlColumn partitionFileNames |
إنشاء بنيات JSON في عمود مشتق
يمكنك إضافة عمود معقد إلى تدفق البيانات عبر منشئ التعبيرات المشتقة. في تحويل العمود المشتقة، إضافة عمود جديد وفتح منشئ التعبير عن طريق النقر على المربع الأزرق. لجعل عمود معقد، يمكنك إدخال بنية JSON يدوياً أو استخدام UX لإضافة الأعمدة الفرعية بشكل تفاعلي.
استخدام منشئ التعبير UX
في الجزء الجانبي لمخطط الإخراج، مرر مؤشر الماوس فوق عمود وانقر فوق رمز الجمع. حدد "Add subcolumn" لجعل العمود نوعاً معقداً.
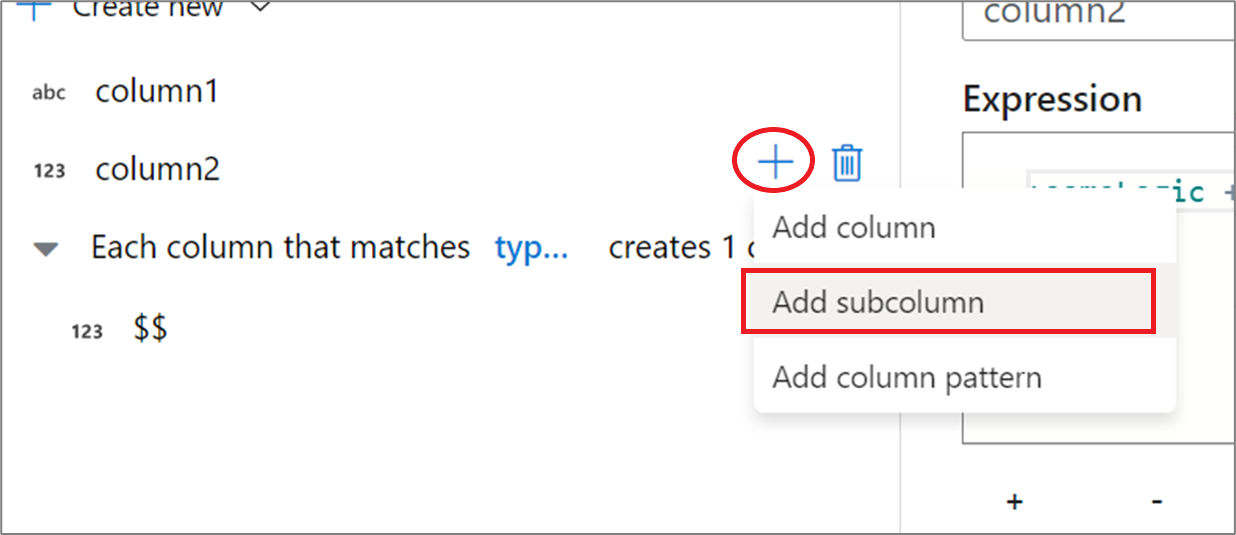
يمكنك إضافة أعمدة إضافية ومصفوفات فرعية بنفس الطريقة. لكل حقل غير معقد، يمكن إضافة تعبير في محرر التعبير إلى اليمين.
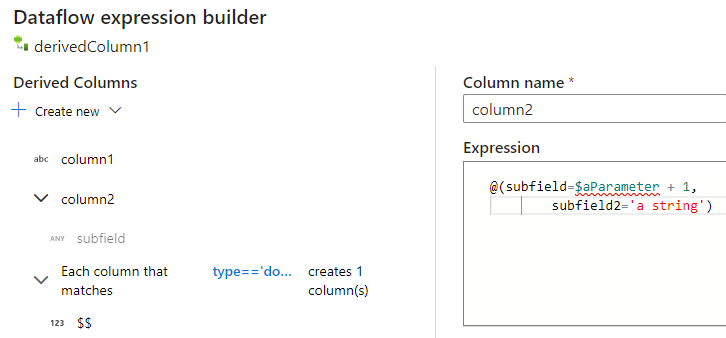
إدخال بنية JSON يدوياً
لإضافة بنية JSON يدوياً، أضف عمود جديد وأدخل التعبير في المحرر. يتبع التعبير التنسيق العام التالي:
@(
field1=0,
field2=@(
field1=0
)
)
إذا تم إدخال هذا التعبير لعمود يسمى "complexColumn"، ثم فإنه سيتم كتابة إلى مصدر كـ JSON التالية:
{
"complexColumn": {
"field1": 0,
"field2": {
"field1": 0
}
}
}
نموذج البرنامج النصي اليدوي لتعريف التسلسل الهرمي الكامل
@(
title=Title,
firstName=FirstName,
middleName=MiddleName,
lastName=LastName,
suffix=Suffix,
contactDetails=@(
email=EmailAddress,
phone=Phone
),
address=@(
line1=AddressLine1,
line2=AddressLine2,
city=City,
state=StateProvince,
country=CountryRegion,
postCode=PostalCode
),
ids=[
toString(CustomerID), toString(AddressID), rowguid
]
)
الموصلات والتنسيقات ذات الصلة
فيما يلي بعض الموصلات والتنسيقات الشائعة المتعلقة بتنسيق JSON:
المحتوى ذو الصلة
- نظرة عامة على Copy activity
- تعيين تدفق البيانات
- نشاط البحث
- نشاط GetMetadata