ملاحظة
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تسجيل الدخول أو تغيير الدلائل.
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تغيير الدلائل.
ينطبق على:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
تلميح
جرب Data Factory في Microsoft Fabric، وهو حل تحليلي متكامل للمؤسسات. يغطي Microsoft Fabric كل شيء بدءا من حركة البيانات إلى علم البيانات والتحليلات في الوقت الحقيقي والمعلومات المهنية وإعداد التقارير. تعرف على كيفية بدء إصدار تجريبي جديد مجانا!
توضح هذه المقالة كيفية نسخ البيانات من وإلى Azure Data Lake Storage Gen1. للتعرف على المزيد، اقرأ المقالة التمهيدية حول Azure Data Factory أو Azure Synapse Analytics.
إشعار
تم إيقاف Azure Data Lake Storage Gen1 في 29 فبراير 2024. يرجى الترحيل إلى موصل Azure Data Lake Storage Gen2. راجع هذه المقالة للحصول على إرشادات ترحيل Azure Data Lake Storage Gen1.
القدرات المدعومة
يتم دعم موصل Azure Data Lake Storage Gen1 للإمكانيات التالية:
| القدرات المدعومة | IR |
|---|---|
| Copy activity (المصدر/المتلق) | (1) (2) |
| تعيين تدفق البيانات (المصدر/ المتلقي) | (1) |
| نشاط البحث | (1) (2) |
| نشاط GetMetadata | (1) (2) |
| حذف النشاط | (1) (2) |
① وقت تشغيل تكامل Azure ② وقت تشغيل التكامل المستضاف ذاتيًا
وبوجه خاص، مع هذا الموصل يمكنك:
- نسخ الملفات باستخدام إحدى الطرق التالية للمصادقة: خدمة أساسية أو الهويات المدارة لموارد Azure.
- نسخ الملفات كما هي أو تحليلها أو إنشائها باستخدام تنسيقات الملفات المدعومة وبرامج ضغط الوسائط وفكها.
- الاحتفاظ بقوائم التحكم في الوصول (ACLs) عند النسخ إلى Azure Data Lake Storage Gen2.
هام
إذا نسختَ البيانات باستخدام وقت تشغيل التكامل المستضاف ذاتياً، فكوِّن جدار حماية الشركة للسماح بحركة المرور الصادرة إلى <ADLS account name>.azuredatalakestore.net وlogin.microsoftonline.com/<tenant>/oauth2/token على المنفذ 443. وهذا الأخير هو خدمة Azure Security Token التي تحتاج وقت تشغيل التكامل للاتصال من أجل الحصول على رمز الوصول المميز.
الشروع في العمل
تلميح
للحصول على طريقة استخدام موصل Azure Data Lake Store، راجع تحميل البيانات في مخزن Azure Data Lake.
لتنفيذ نشاط النسخ باستخدام أحد المسارات، يمكنك استخدام إحدى الأدوات أو عدد تطوير البرامج التالية:
- أداة نسخ البيانات
- مدخل Azure
- The .NET SDK
- عدة تطوير برامج Python
- Azure PowerShell
- واجهة برمجة تطبيقات REST
- قالب Azure Resource Manager
إنشاء خدمة مرتبطة إلى Azure Data Lake Storage Gen1 باستخدام واجهة المستخدم
اتبع الخطوات التالية لإنشاء خدمة مرتبطة إلى Azure Data Lake Storage Gen1 في واجهة مستخدم مدخل Azure.
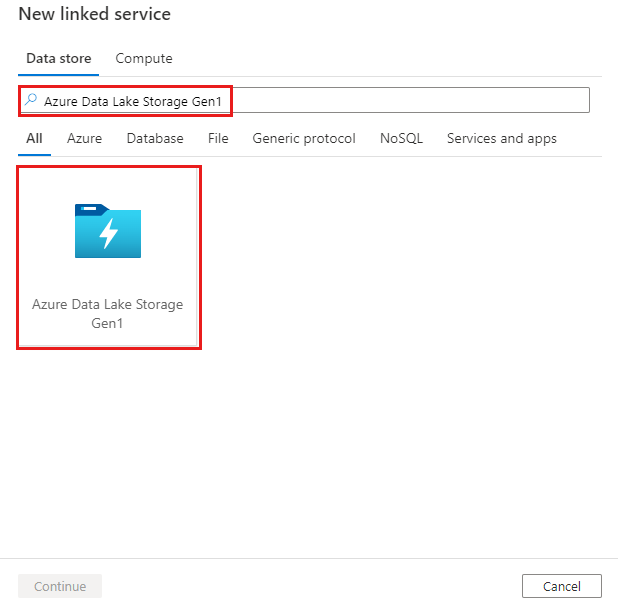
استعرض للوصول إلى علامة تبويب "Manage" في Azure Data Factory أو مساحة عمل Synapse وحدد "Linked Services"، ثم حدد "New":
ابحث عن Azure Data Lake Storage Gen1 وحدد موصل Azure Data Lake Storage Gen1.
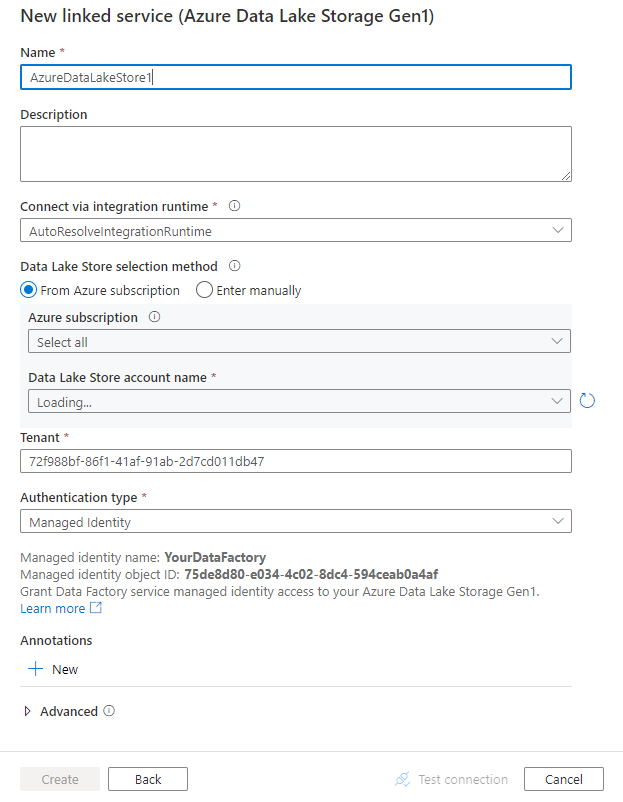
قم بتكوين تفاصيل الخدمة، واختبر الاتصال، وأنشئ الخدمة المرتبطة الجديدة.
تفاصيل تكوين الموصل
توفر المقاطع التالية معلومات حول الخصائص المستخدمة لتعريف الكيانات الخاصة لـ Azure Data Lake Store Gen1.
خصائص الخدمة المرتبطة
الخصائص التالية مدعومة للخدمة المرتبطة لمخزن Azure Data Lake:
| الخاصية | الوصف | مطلوب |
|---|---|---|
| النوع | يجب تعيين الخاصية type إلى AzureDataLakeStore. |
نعم |
| dataLakeStoreUri | معلومات حول حساب مخزن Azure Data Lake. تأخذ هذه المعلومات أحد التنسيقات التالية: https://[accountname].azuredatalakestore.net/webhdfs/v1 أو adl://[accountname].azuredatalakestore.net/. |
نعم |
| subscriptionId | معرف اشتراك Azure الذي ينتمي إليه حساب مخزن Data Lake. | مطلوب للمتلقي |
| resourceGroupName | اسم مجموعة موارد Azure التي ينتمي إليها حساب مخزن Data Lake. | مطلوب للمتلقي |
| connectVia | يُستخدم وقت تشغيل التكامل للاتصال بمخزن البيانات. يمكنك استخدام وقت تشغيل تكامل Azure أو تشغيل تكامل مستضاف ذاتياً إذا كان مخزن البيانات موجوداً في شبكة اتصال خاصة. إذا لم يتم تحديد هذه الخاصية، يتم استخدام Azure Integration Runtime الافتراضي. | لا |
استخدام المصادقة الرئيسية للخدمة
لاستخدام مصادقة كيان الخدمة، اتبع هذه الخطوات.
تسجيل كيان تطبيق في معرف Microsoft Entra ومنحه حق الوصول إلى Data Lake Store. للحصول على خطوات تفصيلية، راجع مصادقة الخدمة إلى الخدمة. دون القيم التالية التي تستخدمها لتعريف الخدمة المرتبطة:
- مُعرّف التطبيق
- مفتاح التطبيق
- معرف المستأجر
امنح الإذن الصحيح الأساسي للخدمة. وراجع أمثلة حول كيفية عمل الإذن في Data Lake Storage Gen1 من خلال التحكم في الوصول في Azure Data Lake Storage Gen1.
- كمصدر: في مستكشف البيانات> وصول، امنح إذن تنفيذ على الأقل لجميع مجلدات المصدر، بما في ذلك الجذر، تزامناً مع إذن قراءة الملفات المقرر نسخها. ويمكنك اختيار إضافة إلى هذا المجلد وجميع الأطفال للتكرار، وإضافة باعتبارها أذونات وصول وإدخال إذن افتراضي. وليس هناك أي متطلبات خاصة بالتحكم في الوصول على مستوى الحساب (IAM).
- كمتلقٍ: في مستكشف البيانات> وصول، امنح إذن تنفيذ على الأقل لجميع مجلدات المصدر، بما في ذلك الجذر، تزامناً مع إذن كتابة لمجلد المتلقي. ويمكنك اختيار إضافة إلى هذا المجلد وجميع الأطفال للتكرار، وإضافة باعتبارها أذونات وصول وإدخال إذن افتراضي.
تدعم الخصائص التالية:
| الخاصية | الوصف | مطلوب |
|---|---|---|
| servicePrincipalId | حدد معرّف عميل التطبيق. | نعم |
| servicePrincipalKey | حدِّد مفتاح التطبيق. وقم بتمييز هذا الحقل باعتباربه SecureString لتخزينه بشكل آمن، أو قم بالإشارة إلى أحد الأسرار المخزنة في Azure Key Vault. |
نعم |
| tenant | حدد معلومات المستأجر، مثل اسم المجال أو معرف المستأجر، التي يوجد التطبيق ضمنها. يمكنك استرداده عن طريق تمرير الماوس في الزاوية العلوية اليمنى من مدخل Microsoft Azure. | نعم |
| azureCloudType | للمصادقة الأساسية للخدمة، حدد نوع بيئة سحابة Azure التي تم تسجيل تطبيق Microsoft Entra إليها. القيم المسموح بها هي AzurePublic، وAzureChina، وAzureUsGovernment، وAzureGermany. يتم استخدام بيئة السحابة للخدمة بشكل افتراضي. |
لا |
مثال:
{
"name": "AzureDataLakeStoreLinkedService",
"properties": {
"type": "AzureDataLakeStore",
"typeProperties": {
"dataLakeStoreUri": "https://<accountname>.azuredatalakestore.net/webhdfs/v1",
"servicePrincipalId": "<service principal id>",
"servicePrincipalKey": {
"type": "SecureString",
"value": "<service principal key>"
},
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>",
"subscriptionId": "<subscription of ADLS>",
"resourceGroupName": "<resource group of ADLS>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
استخدام مصادقة الهوية المدارة المعينة من قبل النظام
يمكن أن يقترن مصنع بيانات أو مساحة عمل Synapse بهوية مدارة معينة من قبل النظام، والتي تمثل خدمة المصادقة. ويمكنك استخدام هذه الهوية المدارة المعينة من قبل النظام مباشرةً لمصادقة مخزن Data Lake، على غرار استخدام أساس الخدمة الخاص بك. ويسمح هذا للمورد المعين بالوصول إلى البيانات ونسخها من أو إلى مخزن Data Lake.
لاستخدام مصادقة الهوية المدارة المعينة من قبل النظام، اتبع الخطوات التالية.
استرداد معلومات الهوية المدارة المعينة من قبل النظام عن طريق نسخ قيمة «معرف تطبيق هوية الخدمة» التي تم إنشاؤها مع المصنع أو مساحة عمل Synapse.
منح الوصول إلى الهوية المدارة المعينة من قبل النظام إلى مخزن Data Lake. وراجع أمثلة حول كيفية عمل الإذن في Data Lake Storage Gen1 من خلال التحكم في الوصول في Azure Data Lake Storage Gen1.
- كمصدر: في مستكشف البيانات> وصول، امنح إذن تنفيذ على الأقل لجميع مجلدات المصدر، بما في ذلك الجذر، تزامناً مع إذن قراءة الملفات المقرر نسخها. ويمكنك اختيار إضافة إلى هذا المجلد وجميع الأطفال للتكرار، وإضافة باعتبارها أذونات وصول وإدخال إذن افتراضي. وليس هناك أي متطلبات خاصة بالتحكم في الوصول على مستوى الحساب (IAM).
- كمتلقٍ: في مستكشف البيانات> وصول، امنح إذن تنفيذ على الأقل لجميع مجلدات المصدر، بما في ذلك الجذر، تزامناً مع إذن كتابة لمجلد المتلقي. ويمكنك اختيار إضافة إلى هذا المجلد وجميع الأطفال للتكرار، وإضافة باعتبارها أذونات وصول وإدخال إذن افتراضي.
لا تحتاج إلى تحديد أي خصائص أخرى غير معلومات مخزن Data Lake في الخدمة المرتبطة.
مثال:
{
"name": "AzureDataLakeStoreLinkedService",
"properties": {
"type": "AzureDataLakeStore",
"typeProperties": {
"dataLakeStoreUri": "https://<accountname>.azuredatalakestore.net/webhdfs/v1",
"subscriptionId": "<subscription of ADLS>",
"resourceGroupName": "<resource group of ADLS>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
استخدام مصادقة الهوية المدارة المعينة من قبل المستخدم
يمكن تعيين مصنع بيانات باستخدام مصادقة هوية مدارة معينة من قبل المستخدم، واحدة أو متعددة. ويمكنك استخدام هذه الهوية المدارة المعينة من قبل المستخدم لمصادقة تخزين Blob، والتي تسمح بالوصول إلى البيانات ونسخها من أو إلى مخزن Data Lake. لمعرفة المزيد حول الهويات المدارة لموارد Azure، راجع الهويات المدارة لموارد Azure
لاستخدام مصادقة الهوية المدارة المعينة من قبل المستخدم اتبع الخطوات التالية:
إنشاء هوية مدارة معينة من قبل المستخدم، واحدة أو متعددة، ومنح حق الوصول إلى Azure Data Lake. وراجع أمثلة حول كيفية عمل الإذن في Data Lake Storage Gen1 من خلال التحكم في الوصول في Azure Data Lake Storage Gen1.
- كمصدر: في مستكشف البيانات> وصول، امنح إذن تنفيذ على الأقل لجميع مجلدات المصدر، بما في ذلك الجذر، تزامناً مع إذن قراءة الملفات المقرر نسخها. ويمكنك اختيار إضافة إلى هذا المجلد وجميع الأطفال للتكرار، وإضافة باعتبارها أذونات وصول وإدخال إذن افتراضي. وليس هناك أي متطلبات خاصة بالتحكم في الوصول على مستوى الحساب (IAM).
- كمتلقٍ: في مستكشف البيانات> وصول، امنح إذن تنفيذ على الأقل لجميع مجلدات المصدر، بما في ذلك الجذر، تزامناً مع إذن كتابة لمجلد المتلقي. ويمكنك اختيار إضافة إلى هذا المجلد وجميع الأطفال للتكرار، وإضافة باعتبارها أذونات وصول وإدخال إذن افتراضي.
تعيين هوية مدارة معينة من قبل المستخدم، واحدة أو متعددة، إلى مصنع البيانات وإنشاء بيانات اعتماد لكل هوية مدارة معينة من قبل المستخدم.
الخاصية التالية مدعومة:
| الخاصية | الوصف | مطلوب |
|---|---|---|
| بيانات الاعتماد | حدد الهوية المدارة المعينة من قبل المستخدم ككائن بيانات الاعتماد. | نعم |
مثال:
{
"name": "AzureDataLakeStoreLinkedService",
"properties": {
"type": "AzureDataLakeStore",
"typeProperties": {
"dataLakeStoreUri": "https://<accountname>.azuredatalakestore.net/webhdfs/v1",
"subscriptionId": "<subscription of ADLS>",
"resourceGroupName": "<resource group of ADLS>",
"credential": {
"referenceName": "credential1",
"type": "CredentialReference"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
خصائص مجموعة البيانات
للحصول على قائمة كاملة بالأقسام والخصائص المتوفرة لتعريف مجموعات البيانات، راجع مقالة مجموعات البيانات.
يدعم Azure Data Factory تنسيقات الملفات التالية. راجع كل مقالة للاطلاع على الإعدادات المستندة إلى التنسيق.
الخصائص التالية مدعومة في Azure Data Lake Store Gen1 ضمن إعدادات location في مجموعة البيانات المستندة إلى تنسيق:
| الخاصية | الوصف | مطلوب |
|---|---|---|
| النوع | يجب تعيين خاصية النوع ضمن location في مجموعة البيانات إلى AzureDataLakeStoreLocation. |
نعم |
| folderPath | المسار إلى مجلد. إذا كنت تريد استخدام حرف بدل لتصفية المجلدات، فتخطَّ هذا الإعداد، وحدده في إعدادات مصدر النشاط. | لا |
| fileName | اسم الملف ضمن folderPath المحدد. إذا كنت تريد استخدام حرف بدل لتصفية الملفات، فتخطَّ هذا الإعداد، وحدده في إعدادات مصدر النشاط. | لا |
مثال:
{
"name": "DelimitedTextDataset",
"properties": {
"type": "DelimitedText",
"linkedServiceName": {
"referenceName": "<ADLS Gen1 linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, auto retrieved during authoring > ],
"typeProperties": {
"location": {
"type": "AzureDataLakeStoreLocation",
"folderPath": "root/folder/subfolder"
},
"columnDelimiter": ",",
"quoteChar": "\"",
"firstRowAsHeader": true,
"compressionCodec": "gzip"
}
}
}
انسخ خصائص النشاط
للحصول على قائمة كاملة بالأقسام والخصائص المتوفرة لتعريف الأنشطة، راجع البنية الأساسية لبرنامج ربط العمليات التجارية. يوفر هذا القسم قائمة بالخصائص المدعومة من قبل مصدر مخزن Azure Data Lake والمتلقي.
متجر Azure Data Lake كمصدر
يدعم Azure Data Factory تنسيقات الملفات التالية. راجع كل مقالة للاطلاع على الإعدادات المستندة إلى التنسيق.
الخصائص التالية مدعومة في Azure Data Lake Store Gen1 ضمن إعدادات storeSettings في مصدر النسخ المستند إلى تنسيق:
| الخاصية | الوصف | مطلوب |
|---|---|---|
| النوع | يجب تعيين خاصية النوع ضمن storeSettings إلى AzureDataLakeStoreReadSettings. |
نعم |
| حدد موقع الملفات المراد نسخها: | ||
| الخيار 1: مسار ثابت |
نسخ من مسار المجلد/الملف المحدد في مجموعة البيانات. إذا كنت تريد نسخ كافة الملفات من مجلد، بالإضافة إلى ذلك حدد wildcardFileName على أنه *. |
|
| الخيار 2: نطاق الاسم - listAfter |
استرداد المجلدات/الملفات التي يقع اسمها أبجدياً (خاص) بعد هذه القيمة. ويستخدم عامل التصفية من جانب الخدمة لـ ADLS Gen1، والذي يوفر أداءً أفضل من عامل تصفية البدل. تطبق الخدمة عامل التصفية هذا على المسار المحدد في مجموعة البيانات، ويتم دعم مستوى كيان واحد فقط. راجع المزيد من الأمثلة في أمثلة على عامل تصفية نطاق الاسم. |
لا |
| الخيار 2: نطاق الاسم - listBefore |
استرداد المجلدات/الملفات التي يقع اسمها أبجدياً (شامل) قبل هذه القيمة. ويستخدم عامل التصفية من جانب الخدمة لـ ADLS Gen1، والذي يوفر أداءً أفضل من عامل تصفية البدل. تطبق الخدمة عامل التصفية هذا على المسار المحدد في مجموعة البيانات، ويتم دعم مستوى كيان واحد فقط. راجع المزيد من الأمثلة في أمثلة على عامل تصفية نطاق الاسم. |
لا |
| الخيار 3: wildcard - wildcardFolderPath |
مسار المجلد مع أحرف البدل لتصفية مجلدات المصدر. حروف البدل المسموح بها هي: * (يطابق صفراً أو المزيد من الأحرف)، و? (يطابق صفراً أو حرفاً واحداً)؛ يمكنك استخدام ^ للإلغاء إذا كان اسم المجلد الفعلي يتضمن حرف بدل أو حرف إلغاء بداخله. راجع المزيد من الأمثلة في أمثلة على تصفية الملفات والمجلدات. |
لا |
| الخيار 3: wildcard - wildcardFileName |
اسم الملف مع حروف البدل ضمن المجلد المحدد / folderPath/wildcardFolderPath المحدد لتصفية الملفات المصدر. حروف البدل المسموح بها هي: * (يطابق صفراً أو المزيد من الأحرف)، و? (يطابق صفراً أو حرفاً واحداً)؛ يمكنك استخدام ^ للإلغاء إذا كان اسم الملف الفعلي يتضمن حرف بدل أو حرف إلغاء بداخله. راجع المزيد من الأمثلة في أمثلة على تصفية الملفات والمجلدات. |
نعم |
| الخيار 4: قائمة الملفات - fileListPath |
يشير إلى نسخ مجموعة ملفات معينة. أشر إلى ملف نصي يتضمن قائمة بالملفات التي تريد نسخها، ملف واحد لكل سطر، وهو المسار النسبي للمسار الذي تم تكوينه في مجموعة البيانات. عند استخدام هذا الخيار، لا تحدد اسم الملف في مجموعة البيانات. شاهد المزيد من الأمثلة في أمثلة قائمة الملفات. |
لا |
| إعدادات إضافية: | ||
| التكرار | يشير إلى ما إذا كانت البيانات ستتم قراءتها بشكل متكرر من المجلدات الفرعية أو من المجلد المحدد فقط. عندما يتم تعيين "recursive" إلى "true" والمتلقي هو مخزن يستند إلى ملف، لا يتم نسخ أو إنشاء مجلد فارغ أو مجلد فرعي في المتلقي. القيم المسموح بها هي true (افتراضية) وfalse. لا تنطبق هذه الخاصية عند تكوين fileListPath. |
لا |
| deleteFilesAfterCompletion | يشير إلى ما إذا كان سيتم حذف الملفات الثنائية من مخزن المصدر بعد الانتقال بنجاح إلى مخزن الوجهة. يتم حذف الملف لكل ملف، لذلك عند فشل نشاط النسخ، سترى أن بعض الملفات قد تم نسخها بالفعل إلى الوجهة وحذفها من المصدر، بينما لا يزال البعض الآخر في مخزن المصدر. هذه الخاصية صالحة فقط في سيناريو نسخ الملفات الثنائية. القيمة الافتراضية: false. |
لا |
| تاريخ البدء المعدل | تصفية الملفات استنادا إلى السمة: "Last Modified". يتم تحديد الملفات إذا كان وقت آخر تعديل لها أكبر من أو يساوي modifiedDatetimeStart وأقل من modifiedDatetimeEnd. ويتم تطبيق الوقت على المنطقة الزمنية UTC بتنسيق «2018-12-01T05:00:00Z». يمكن أن تكون الخصائص ذات «قيمة فارغة»، ما يعني أنه لا يتم تطبيق عامل تصفية سمات الملف على مجموعة البيانات. عندما modifiedDatetimeStart يكون لها قيمة التاريخ والوقت ولكنها modifiedDatetimeEnd NULL، فهذا يعني أن الملفات التي تكون سمتها المعدلة الأخيرة أكبر من قيمة التاريخ والوقت أو مساوية لها محددة. عندما modifiedDatetimeEnd تكون قيمة التاريخ والوقت فارغة modifiedDatetimeStart ، فهذا يعني أن الملفات التي تكون سمتها المعدلة الأخيرة أقل من قيمة التاريخ والوقت محددة.لا تنطبق هذه الخاصية عند تكوين fileListPath. |
لا |
| modifiedDatetimeEnd | مثل أعلاه. | لا |
| enablePartitionDiscovery | بالنسبة للملفات المقسمة، حدد ما إذا كنت تريد تحليل الأقسام من مسار الملف وإضافتها كأعمدة مصدر إضافية. القيم المسموح بها هي false (افتراضية) وtrue. |
لا |
| partitionRootPath | عند تمكين اكتشاف القسم، حدد مسار الجذر المطلق لقراءة المجلدات المقسمة كأعمدة بيانات. إذا لم يتم تحديده، بشكل افتراضي، - عند استخدام مسار الملف في مجموعة البيانات أو قائمة الملفات على المصدر، يكون مسار جذر القسم هو المسار الذي تم تكوينه في مجموعة البيانات. - عند استخدام عامل تصفية مجلد أحرف البدل، يكون مسار جذر القسم هو المسار الفرعي قبل حرف البدل الأول. على سبيل المثال، بافتراض أنك قمت بتكوين المسار في مجموعة البيانات كـ "root/folder/year=2020/month=08/day=27": - إذا حددت مسار جذر القسم على أنه "root/folder/year=2020"، فإن نشاط النسخ ينشئ عمودين month إضافيين والقيمة day "08" و"27" على التوالي، بالإضافة إلى الأعمدة داخل الملفات.- إذا لم يتم تحديد مسار جذر القسم، فلن يتم إنشاء عمود إضافي. |
لا |
| maxConcurrentConnections | الحد الأعلى للاتصالات المتزامنة التي تم إنشاؤها إلى مخزن البيانات أثناء تشغيل النشاط. حدد قيمة فقط عندما تريد تحديد الاتصالات المتزامنة. | لا |
مثال:
"activities":[
{
"name": "CopyFromADLSGen1",
"type": "Copy",
"inputs": [
{
"referenceName": "<Delimited text input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "DelimitedTextSource",
"formatSettings":{
"type": "DelimitedTextReadSettings",
"skipLineCount": 10
},
"storeSettings":{
"type": "AzureDataLakeStoreReadSettings",
"recursive": true,
"wildcardFolderPath": "myfolder*A",
"wildcardFileName": "*.csv"
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
مخزن Azure Data Lake كمتلقٍ
يدعم Azure Data Factory تنسيقات الملفات التالية. راجع كل مقالة للاطلاع على الإعدادات المستندة إلى التنسيق.
الخصائص التالية مدعومة في Azure Data Lake Store Gen1 ضمن إعدادات storeSettings في مصدر النسخ المستند إلى تنسيق:
| الخاصية | الوصف | مطلوب |
|---|---|---|
| النوع | يجب تعيين خاصية النوع ضمن storeSettings إلى AzureDataLakeStoreWriteSettings. |
نعم |
| copyBehavior | تعريف سلوك النسخ عندما يكون المصدر ملفات من مخزن بيانات مستند إلى ملف. القيم المسموح بها هي: - PreserveHierarchy (افتراضي): يحافظ على التسلسل الهرمي للملف في المجلد الهدف. يكون المسار النسبي للملف المصدر إلى المجلد المصدر مطابقاً للمسار النسبي للملف الهدف إلى المجلد الهدف. - FlattenHierarchy: جميع الملفات من المجلد المصدر في المستوى الأول من المجلد الهدف. لملفات الهدف أسماء تم إنشائها تلقائياً. - MergeFiles: دمج جميع الملفات من المجلد المصدر إلى ملف واحد. إذا تم تحديد اسم الملف، فسيكون اسم الملف المدمج هو الاسم المحدد. وإلا، فسيتم إنشاء اسم الملف تلقائياً. |
لا |
| expiryDateTime | تحديد وقت انتهاء صلاحية الملفات المكتوبة. يتم تطبيق الوقت على التوقيت العالمي المنسق في تنسيق «2020-03-01T08:00:00Z». بشكل افتراضي، تكون NULL، مما يعني أن الملفات المكتوبة لا تنتهي صلاحيتها أبدا. | لا |
| maxConcurrentConnections | الحد الأعلى للاتصالات المتزامنة التي تم إنشاؤها إلى مخزن البيانات أثناء تشغيل النشاط. حدد قيمة فقط عندما تريد تحديد الاتصالات المتزامنة. | لا |
مثال:
"activities":[
{
"name": "CopyToADLSGen1",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Parquet output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "ParquetSink",
"storeSettings":{
"type": "AzureDataLakeStoreWriteSettings",
"copyBehavior": "PreserveHierarchy"
}
}
}
}
]
أمثلة على عامل تصفية نطاق الاسم
يصف هذا القسم السلوك الناتج عن عوامل تصفية نطاق الاسم.
| نموذج بنية المصدر | التكوين | نتيجة |
|---|---|---|
| جذر ص file.csv ax file2.csv ax.csv ب file3.csv bx.csv ج file4.csv cx.csv |
في مجموعة البيانات: - مسار المجلد: rootفي مصدر نشاط النسخ: - قائمة بعد: a- قائمة قبل: b |
ثم يتم نسخ الملفات التالية: جذر ax file2.csv ax.csv ب file3.csv |
أمثلة على تصفية الملفات والمجلدات
يصف هذا المقطع السلوك الناتج عن مسار المجلد واسم الملف مع عوامل تصفية البدل.
| folderPath | fileName | التكرار | بنية المجلد المصدر ونتيجة التصفية (يتم استرداد الملفات بخط عريض) |
|---|---|---|---|
Folder* |
(فارغ، استخدم الإعداد الافتراضي) | true | مجلد أ File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
Folder* |
(فارغ، استخدم الإعداد الافتراضي) | صحيح | مجلد أ File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
Folder* |
*.csv |
true | مجلد أ File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
Folder* |
*.csv |
صحيح | مجلد أ File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
أمثلة على قائمة الملفات
يصف هذا القسم السلوك الناتج عن استخدام مسار قائمة الملفات في نسخ مصدر النشاط.
بافتراض أن لديك بنية المجلد المصدر التالية وتريد نسخ الملفات بخط عريض:
| نموذج بنية المصدر | Content in FileListToCopy.txt | التكوين |
|---|---|---|
| جذر مجلد أ File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv بيانات التعريف FileListToCopy.txt |
File1.csv Subfolder1/File3.csv Subfolder1/File5.csv |
في مجموعة البيانات: - مسار المجلد: root/FolderAفي مصدر نشاط النسخ: - مسار ملف القائمة: root/Metadata/FileListToCopy.txt يشير مسار قائمة الملفات إلى ملف نصي في نفس مخزن البيانات يتضمن قائمة بالملفات التي ترغب في نسخها، ملف واحد لكل سطر، مع المسار النسبي للمسار الذي تم تكوينه في مجموعة البيانات. |
أمثلة على سلوك عملية النسخ
يصف هذا القسم السلوك الناتج عن عملية النسخ للمجموعات المختلفة للقيمتين recursive وcopyBehavior.
| التكرار | copyBehavior | بنية المجلد المصدر | الهدف الناتج |
|---|---|---|---|
| صحيح | preserveHierarchy | Folder1 File1 File2 Subfolder1 File3 File4 File5 |
يتم إنشاء Folder1 الهدف ببنية المصدر نفسها: Folder1 File1 File2 Subfolder1 File3 File4 File5. |
| صحيح | flattenHierarchy | Folder1 File1 File2 Subfolder1 File3 File4 File5 |
يتم إنشاء Folder1 الهدف بالبنية التالية: Folder1 الاسم الذي تم إنشائه تلقائياً لملف1 الاسم الذي تم إنشائه تلقائياً للملف2 الاسم الذي تم إنشائه تلقائياً للملف3 الاسم الذي تم إنشائه تلقائياً للملف4 الاسم الذي تم إنشائه تلقائياً للملف5 |
| صحيح | mergeFiles | Folder1 File1 File2 Subfolder1 File3 File4 File5 |
يتم إنشاء Folder1 الهدف بالبنية التالية: Folder1 يتم دمج محتويات File1 + File2 + File3 + File4 + File5 في ملف واحد، باسم ملف مُنشأ تلقائياً. |
| true | preserveHierarchy | Folder1 File1 File2 Subfolder1 File3 File4 File5 |
يتم إنشاء Folder1 الهدف بالبنية التالية: Folder1 File1 File2 لم يتم التقاط المجلد الفرعي1 مع File3 وFile4 وFile5. |
| true | flattenHierarchy | Folder1 File1 File2 Subfolder1 File3 File4 File5 |
يتم إنشاء Folder1 الهدف بالبنية التالية: Folder1 الاسم الذي تم إنشائه تلقائياً لملف1 الاسم الذي تم إنشائه تلقائياً للملف2 لم يتم التقاط المجلد الفرعي1 مع File3 وFile4 وFile5. |
| true | mergeFiles | Folder1 File1 File2 Subfolder1 File3 File4 File5 |
يتم إنشاء Folder1 الهدف بالبنية التالية: Folder1 يتم دمج محتويات File1 + File2 في ملف واحد باسم يتم إنشاؤه تلقائياً. الاسم الذي تم إنشائه تلقائياً لملف1 لم يتم التقاط المجلد الفرعي1 مع File3 وFile4 وFile5. |
الاحتفاظ بقوائم التحكم في الوصول (ACLs) إلى Data Lake Storage Gen2
تلميح
لنسخ البيانات من Azure Data Lake Storage Gen1 إلى Gen2 بوجه عام، راجع نسخ البيانات من Azure Data Lake Storage Gen1 إلى Gen2 للتعرف على المزيد من المعلومات وأفضل الممارسات.
إذا كنت ترغب في نسخ قوائم التحكم في الوصول (ACLs) مع ملفات البيانات عند الترقية من Data Lake Storage Gen1 إلى Data Lake Storage Gen2، فراجع الاحتفاظ بنسخ قوائم التحكم في الوصول (ACLs) من Data Lake Storage Gen1.
تعيين خصائص تدفق البيانات
عند تحويل البيانات في تعيين تدفقات البيانات، يمكنك قراءة الملفات وكتابتها من Azure Data Lake Storage Gen1 بالتنسيقات التالية:
توجد إعدادات خاصة بالتنسيق في وثائق هذا التنسيق. لمزيد من المعلومات، راجع تحويل المصدر في تخطيط تدفق البيانات وتحويل المتلقي في تخطيط تدفق البيانات.
تحويل المصدر
في تحويل المصدر، يمكنك القراءة من حاوية أو مجلد أو ملف فردي في Azure Data Lake Storage Gen1. تتيح لك علامة التبويب خيارات المصدر التحكم في كيفية قراءة الملفات.
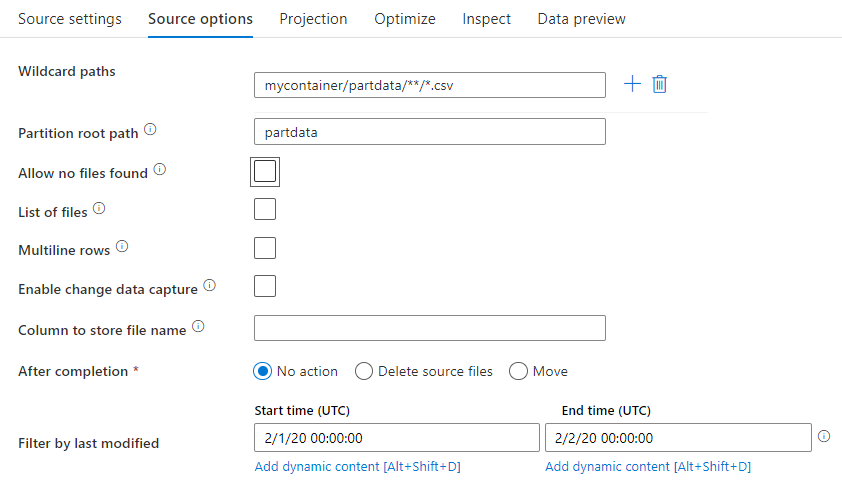
مسار البدل: استخدام نمط البدل سوف يرشد الخدمة إلى حلقة خلال كل مجلد مطابقة وملف في تحويل مصدر واحد. وهذه طريقة فعالة لمعالجة ملفات متعددة داخل تدفق واحد. أضف أنماط مطابقة البدل المتعددة مع علامة + التي تظهر عند التمرير فوق نمط البدل الموجود لديك.
من حاوية المصدر، اختر سلسلة من الملفات التي تطابق نمطاً. يمكن تحديد الحاوية فقط في مجموعة البيانات. ويجب أن يتضمن مسار البدل مسار المجلد من المجلد الجذر.
أمثلة البدل:
*يمثل أي مجموعة من الأحرف**يمثل أي تداخل متكرر للدليل?يستبدل حرفاً واحداً[]يطابق حرفاً واحداً أو أكثر داخل الأقواس/data/sales/**/*.csvيحصل على جميع ملفات csv ضمن /data/sales/data/sales/20??/**/يحصل على جميع الملفات بشكل متكرر داخل جميع مجلدات 20xx المطابقة/data/sales/*/*/*.csvيحصل على ملفات csv، مستويين ضمن /data/sales/data/sales/2004/12/[XY]1?.csvيحصل على جميع ملفات csv من ديسمبر 2004 بدءًا من X أو Y، متبوعًا بـ 1، وأي حرف واحد
Partition Root Path: إذا كان لديك مجلدات مقسمة في مصدر الملف الخاص بك بتنسيق key=value (على سبيل المثال، السنة=2019)، يمكنك حينئذٍ تعيين المستوى الأعلى لشجرة مجلد القسم هذا إلى اسم عمود في تدفق بيانات تدفق البيانات الخاصة بك.
أولاً، قم بتعيين حرف البدل لتضمين جميع المسارات التي هي مجلدات مُقسمة، بالإضافة إلى الملفات الطرفية التي ترغب في قراءتها.
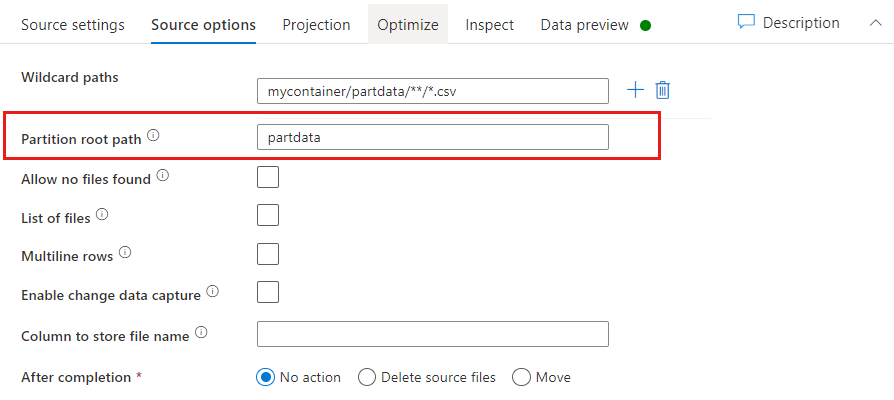
استخدم إعداد مسار جذر القسم لتحديد المستوى الأعلى من بنية المجلد. عند عرض محتويات بياناتك عبر معاينة البيانات، سترى أن الخدمة تضيف الأقسام التي تم حلها الموجودة في كل مستوى من مستويات المجلد.
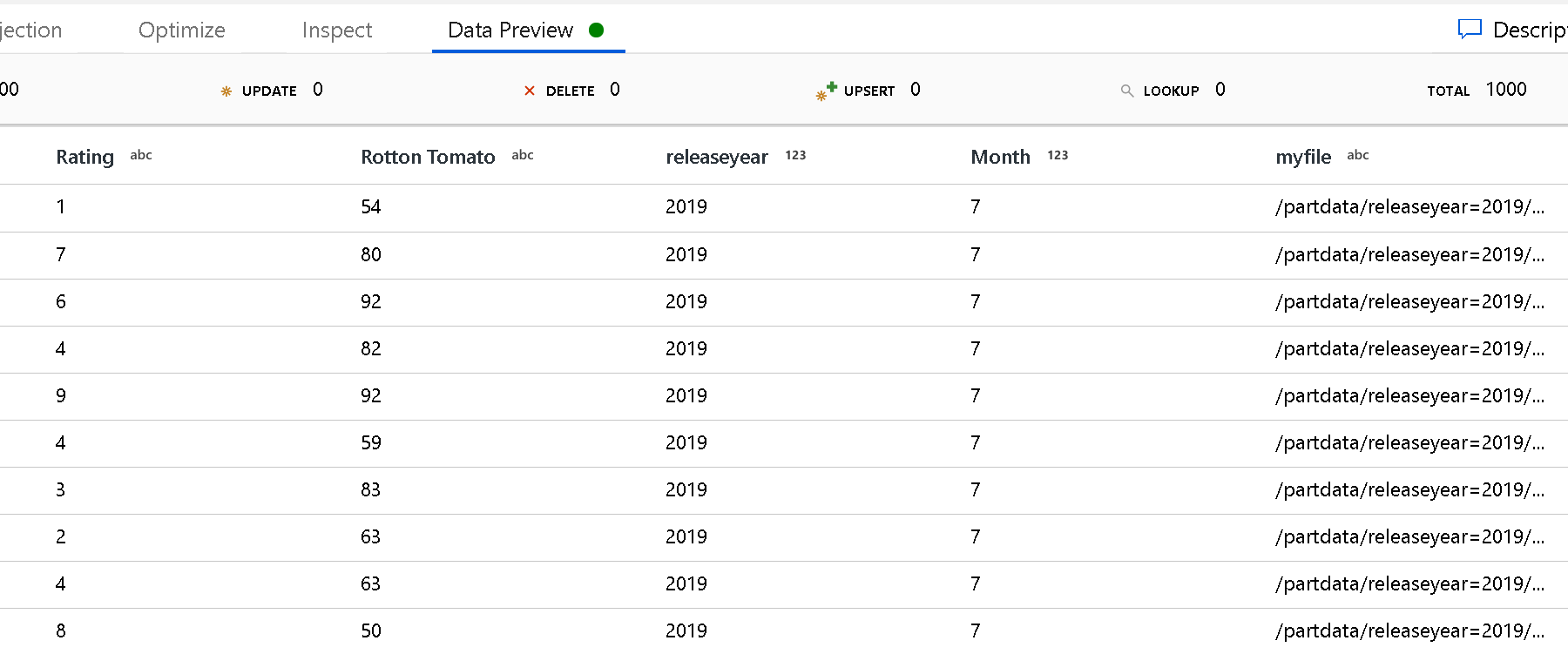
قائمة الملفات: عبارة عن مجموعة ملفات. أنشئ ملف نصي يتضمن قائمة ملفات المسار النسبي لمعالجتها. أشر إلى هذا الملف النصي.
عمود لتخزين اسم الملف: خزّن اسم الملف المصدر في عمود في بياناتك. أدخِل اسم عمود جديد هنا لتخزين سلسلة اسم الملف.
بعد الانتهاء: اختر عدم إجراء أي عملية مع الملف المصدر بعد تشغيل تدفق البيانات أو حذف الملف المصدر أو نقل الملف المصدر. المسارات الخاصة بهذه الخطوة نسبية.
لنقل الملفات المصدر إلى موقع آخر بعد المعالجة، حدد أولاً "Move" لعملية الملف. ثم اضبط الدليل "from". إذا كنت لا تستخدم أي أحرف بدل لمسارك، فإن إعداد "من" هو نفس المجلد مثل المجلد المصدر.
إذا كان لديك مسار مصدر مع حرف بدل، فإن بناء الجملة الخاص بك يبدو كما يلي:
/data/sales/20??/**/*.csv
يمكنك تحديد «من» هكذا
/data/sales
وتحديد «إلى» هكذا
/backup/priorSales
وفي هذه الحالة، يتم نقل جميع الملفات التي تم الحصول عليها تحت /data/sales إلى /backup/priorSales.
إشعار
لا تستخدم تشغيل عمليات الملف إلا عندما تبدأ تدفق البيانات من تشغيل خط الأنابيب (تتبع أخطاء خط الأنابيب أو تشغيل التنفيذ)، والذي يستخدم نشاط تنفيذ تدفق البيانات في خط الأنابيب. لا يتم تشغيل عمليات الملفات في وضع تتبع أخطاء تدفق البيانات.
التصفية حسب آخر تعديل: يمكنك تصفية الملفات التي تعالجها عن طريق تحديد نطاق تاريخ آخر تعديل لها. جميع الأوقات والتواريخ حسب UTC.
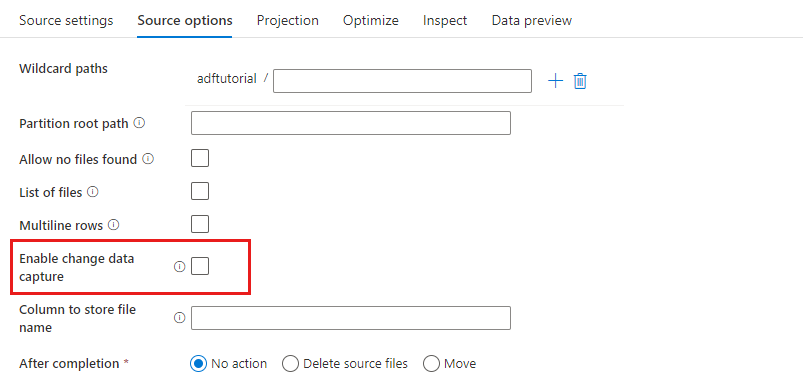
تمكين التقاط بيانات التغيير: إذا كان صحيحا، فستحصل على ملفات جديدة أو تم تغييرها فقط من آخر تشغيل. سيتم دائماً الحصول على التحميل الأولي لبيانات اللقطة الكاملة في التشغيل الأول، متبوعاً بالتقاط ملفات جديدة أو تم تغييرها فقط في عمليات التشغيل التالية. لمزيد من التفاصيل، راجع تغيير تسجيل البيانات.
خصائص المتلقّي
عند تحويل المتلقي، يمكنك الكتابة إما على حاوية أو مجلد في Azure Data Lake Storage Gen1. تتيح لك علامة تبويب الإعدادات التحكم في كيفية كتابة الملفات.
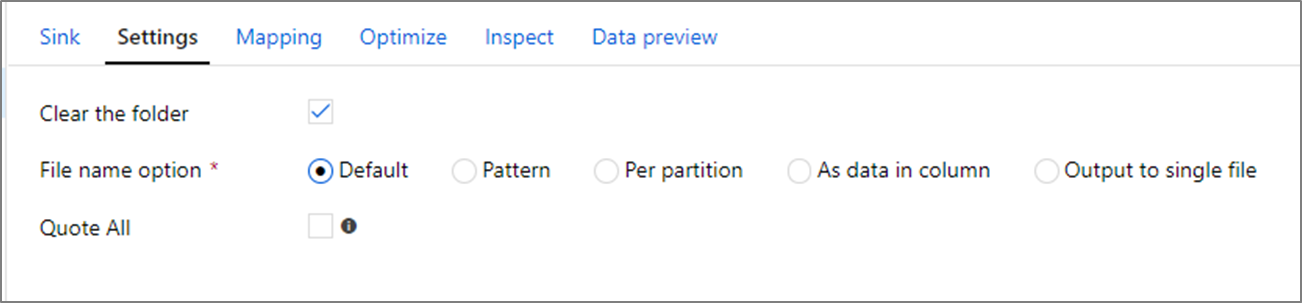
مسح المجلد: لتحديد مسح المجلد الوجهة من عدمه، قبل كتابة البيانات.
خيار اسم الملف: تحديد كيفية تسمية ملفات الوجهة في المجلد الوجهة. خيارات اسم الملف هي:
- الافتراضي: السماح لـ Spark بتسمية الملفات استناداً إلى الإعدادات الافتراضية لـ PART.
- نمط: أدخل نمطاً يُعدد ملفات الإخراج لكل قسم. على سبيل المثال، تنشئ القروض [n].csv loans1.csv loans2.csv وما إلى ذلك.
- لكل قسم: أدخل اسم ملف واحداً لكل قسم.
- كبيانات في العمود: تعيين ملف الإخراج إلى قيمة عمود. يكون المسار منسوباً إلى حاوية مجموعة البيانات، وليس المجلد الوجهة. إذا كان لديك مسار مجلد في مجموعة البيانات، يتم تجاوزه.
- الإخراج إلى ملف واحد: ضم ملفات الإخراج المقسمة إلى ملف مسمى واحد. يكون المسار منسوباً إلى مجلد مجموعة البيانات. يجب أن تدرك أن عملية الدمج قد تفشل بناء على حجم العقدة. لا ينصح بهذا الخيار لمجموعات البيانات الكبيرة.
اقتباس الكل: لتحديد ما إذا كان سيتم إحاطة كل القيم بعلامات اقتباس
بحث عن خصائص النشاط
لمعرفة تفاصيل حول الخصائص، تحقق من نشاط البحث.
خصائص نشاط GetMetadata
لمعرفة تفاصيل حول الخصائص، يرجى التحقق من نشاط GetMetadata
حذف خصائص النشاط
لمعرفة تفاصيل حول الخصائص، يرجى التحقق من نشاط الحذف
النماذج القديمة
إشعار
لا تزال النماذج التالية مدعومة كما هي للتوافق مع الإصدارات السابقة. نقترح عليك استخدام النموذج الجديد المذكور في الأقسام أعلاه للمضي قدماً، وقد تحولت واجهة مستخدم التأليف إلى إنشاء النموذج الجديد.
نموذج مجموعة البيانات القديم
| الخاصية | الوصف | مطلوب |
|---|---|---|
| النوع | يجب تعيين خاصية نوع مجموعة البيانات إلى AzureDataLakeStoreFile. | نعم |
| folderPath | المسار إلى المجلد في مخزن Data Lake. في حالة عدم التحديد، يشير إلى الجذر. عامل تصفية البدل مدعوم. أحرف البدل المسموح بها هي * (تطابق صفراً أو أكثر من الأحرف) و? (تطابق صفراً أو حرفاً واحداً). استخدم ^ للإلغاء، إذا كان اسم المجلد الفعلي يتضمن حرف بدل، أو إذا كان حرف الإلغاء هذا موجود بداخله. على سبيل المثال: rootfolder/subfolder/. راجع المزيد من الأمثلة في أمثلة على تصفية الملفات والمجلدات. |
لا |
| fileName | عامل تصفية حرف البدل أو الاسم للملفات ضمن «folderPath» المحدد. إذا لم تحدد قيمة لهذه الخاصية، فإن مجموعة البيانات تشير إلى جميع الملفات الموجودة في المجلد. للتصفية، أحرف البدل المسموح بها هي * (تطابق صفراً أو أكثر من الأحرف) و? (تطابق صفراً أو حرفاً واحداً).- مثال 1: "fileName": "*.csv"- مثال 2: "fileName": "???20180427.txt"استخدم ^ للإلغاء، إذا كان اسم الملف الفعلي يتضمن حرف بدل، أو إذا كان حرف الإلغاء هذا موجود بداخله.في حالة عدم تحديد fileName لمجموعة بيانات الإخراج، وpreserveHierarchy غير محدد في متلقي النشاط، فإن نشاط النسخ يُنشئ تلقائياً اسم الملف باستخدام النمط التالي: «Data. [المعرّف الفريد لمعرف تشغيل النشاط]. [المعرف الفريد في حالة FlattenHierarchy].[التنسيق في حال تكوينه]. [الضغط المكوّن]» مثال: "Data.0a405f8a-93ff-4c6f-b3be-f69616f1df7a.txt.gz". إذا نسخت من مصدر جدولي مستخدماً اسم الجدول، بدلاً من الاستعلام، يكون اسم النمط كالآتي «[اسم الجدول].[التنسيق].[الضغط إذا تم تكوينه]»، مثال: «MyTable.csv». |
لا |
| تاريخ البدء المعدل | تصفية الملفات وفقاً لآخر تعديل للسمة. يتم تحديد الملفات إذا كان وقت آخر تعديل لها أكبر من أو يساوي modifiedDatetimeStart وأقل من modifiedDatetimeEnd. يتم تطبيق الوقت على المنطقة الزمنية UTC بتنسيق "2018-12-01T05:00:00Z". يتأثر الأداء الكلي لحركة البيانات بتمكين هذا الإعداد، عندما تريد استخدام عامل تصفية الملفات مع كمية كبيرة من الملفات. يمكن أن تكون الخصائص ذات «قيمة فارغة»، ما يعني أنه لا يتم تطبيق عامل تصفية سمات الملف على مجموعة البيانات. وعندما يكون modifiedDatetimeStart له قيمة محددة للوقت والتاريخ، ولكن modifiedDatetimeEnd له «قيمة خالية»، فإن هذا يعني أن الملفات، التي قيمة سمة تاريخ آخر تعديل لها أكبر من قيمة التاريخ والوقت أو تساويها، هي التي سيتم تحديدها. وعندما يكون modifiedDatetimeEnd له قيمة محددة للوقت والتاريخ، ولكن modifiedDatetimeStart له «قيمة خالية»، فإن هذا يعني أن الملفات، التي قيمة سمة تاريخ آخر تعديل لها أقل من قيمة التاريخ والوقت، هي التي سيتم تحديدها. |
لا |
| modifiedDatetimeEnd | تصفية الملفات وفقاً لآخر تعديل للسمة. يتم تحديد الملفات إذا كان وقت آخر تعديل لها أكبر من أو يساوي modifiedDatetimeStart وأقل من modifiedDatetimeEnd. يتم تطبيق الوقت على المنطقة الزمنية UTC بتنسيق "2018-12-01T05:00:00Z". يتأثر الأداء الكلي لحركة البيانات بتمكين هذا الإعداد، عندما تريد استخدام عامل تصفية الملفات مع كمية كبيرة من الملفات. يمكن أن تكون الخصائص ذات «قيمة فارغة»، ما يعني أنه لا يتم تطبيق عامل تصفية سمات الملف على مجموعة البيانات. وعندما يكون modifiedDatetimeStart له قيمة محددة للوقت والتاريخ، ولكن modifiedDatetimeEnd له «قيمة خالية»، فإن هذا يعني أن الملفات، التي قيمة سمة تاريخ آخر تعديل لها أكبر من قيمة التاريخ والوقت أو تساويها، هي التي سيتم تحديدها. وعندما يكون modifiedDatetimeEnd له قيمة محددة للوقت والتاريخ، ولكن modifiedDatetimeStart له «قيمة خالية»، فإن هذا يعني أن الملفات، التي قيمة سمة تاريخ آخر تعديل لها أقل من قيمة التاريخ والوقت، هي التي سيتم تحديدها. |
لا |
| format | إذا كنت تريد نسخ الملفات كما هو الحال بين مخازن مستندة إلى ملف (نسخة ثنائية)، فتخطَّ قسم التنسيق في كل من التعريفات مجموعة بيانات الإدخال والإخراج. إذا كنت تريد توزيع الملفات أو إنشاءها بتنسيق معين، فإن أنواع تنسيق الملف التالية معتمدة: TextFormat، وJsonFormat، وAvroFormat، وOrcFormat، وParquetFormat. قم بتعيين خاصية النوع الموجودة ضمن التنسيق إلى إحدى هذه القيم. للحصول على مزيدٍ من المعلومات، راجع أقسام تنسيق Text، وتنسيقJSON، وتنسيقAvro، وتنسيقORC، وتنسيق Parquet. |
لا (فقط لسيناريو النسخ الثنائي) |
| ضغط | حدد نوع ضغط البيانات ومستواه. للحصول على مزيدٍ من المعلومات، راجع تنسيقات الملفات المدعومة وبرامج ضغط الوسائط وفكها. الأنواع المدعومة هي GZipو Deflateو BZip2، وZipDeflate. المستويات المعتمدة هي الأمثل والأسرع. |
لا |
تلميح
لنسخ جميع الملفات المضمنة في مجلد، حدد folderPath فقط.
لنسخ ملف واحد باسم معين، حدد folderPath مع جزء المجلد، وfileName مع اسم الملف.
لنسخ مجموعة فرعية من الملفات ضمن مجلد ما، حدد folderPath مع جزء المجلد، وfileName مع عامل تصفية حرف البدل.
مثال:
{
"name": "ADLSDataset",
"properties": {
"type": "AzureDataLakeStoreFile",
"linkedServiceName":{
"referenceName": "<ADLS linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"folderPath": "datalake/myfolder/",
"fileName": "*",
"modifiedDatetimeStart": "2018-12-01T05:00:00Z",
"modifiedDatetimeEnd": "2018-12-01T06:00:00Z",
"format": {
"type": "TextFormat",
"columnDelimiter": ",",
"rowDelimiter": "\n"
},
"compression": {
"type": "GZip",
"level": "Optimal"
}
}
}
}
نموذج مصدر نشاط النسخ القديم
| الخاصية | الوصف | مطلوب |
|---|---|---|
| النوع | يجب تعيين الخاصية type لمصدر نشاط النسخ إلى AzureDataLakeStoreSource. |
نعم |
| التكرار | يشير إلى ما إذا كانت البيانات ستتم قراءتها بشكل متكرر من المجلدات الفرعية أو من المجلد المحدد فقط. عندما يتم تعيين recursive إلى «صواب» والمتلقي هو مخزن يستند إلى ملف، لا يتم نسخ أو إنشاء مجلد فارغ أو مجلد فرعي في المتلقي. القيم المسموح بها هي true (افتراضية) وfalse. |
لا |
| maxConcurrentConnections | الحد الأعلى للاتصالات المتزامنة التي تم إنشاؤها إلى مخزن البيانات أثناء تشغيل النشاط. حدد قيمة فقط عندما تريد تحديد الاتصالات المتزامنة. | لا |
مثال:
"activities":[
{
"name": "CopyFromADLSGen1",
"type": "Copy",
"inputs": [
{
"referenceName": "<ADLS Gen1 input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AzureDataLakeStoreSource",
"recursive": true
},
"sink": {
"type": "<sink type>"
}
}
}
]
نموذج متلقي نشاط النسخ القديم
| الخاصية | الوصف | مطلوب |
|---|---|---|
| النوع | يجب تعيين خاصية type لمتلقي نشاط النسخ إلى AzureDataLakeStoreSink. |
نعم |
| copyBehavior | تعريف سلوك النسخ عندما يكون المصدر ملفات من مخزن بيانات مستند إلى ملف. القيم المسموح بها هي: - PreserveHierarchy (افتراضي): يحافظ على التسلسل الهرمي للملف في المجلد الهدف. يكون المسار النسبي للملف المصدر إلى المجلد المصدر مطابقاً للمسار النسبي للملف الهدف إلى المجلد الهدف. - FlattenHierarchy: جميع الملفات من المجلد المصدر في المستوى الأول من المجلد الهدف. لملفات الهدف أسماء تم إنشائها تلقائياً. - MergeFiles: دمج جميع الملفات من المجلد المصدر إلى ملف واحد. إذا تم تحديد اسم الملف، فسيكون اسم الملف المدمج هو الاسم المحدد. وإلا، يتم إنشاء اسم الملف تلقائياً. |
لا |
| maxConcurrentConnections | الحد الأعلى للاتصالات المتزامنة التي تم إنشاؤها إلى مخزن البيانات أثناء تشغيل النشاط. حدد قيمة فقط عندما تريد تحديد الاتصالات المتزامنة. | لا |
مثال:
"activities":[
{
"name": "CopyToADLSGen1",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<ADLS Gen1 output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzureDataLakeStoreSink",
"copyBehavior": "PreserveHierarchy"
}
}
}
]
تغيير التوفر العام لتسجيل البيانات (إصدار أولي)
يمكن لـ Azure Data Factory الحصول على الملفات الجديدة أو التي تم تغييرها فقط من Azure Data Lake Storage Gen1 عن طريق تمكين Enable change data capture (إصدار أولي) في تحويل مصدر تدفق بيانات التعيين. باستخدام خيار الموصل، بإمكانك قراءة الملفات الجديدة أو المحدثة فقط وتطبيق التحويلات قبل تحميل البيانات المحولة إلى مجموعات بيانات الوجهة التي تختارها.
تأكد من الاحتفاظ بمسار التدفق واسم النشاط دون تغيير، بحيث يمكن دائماً تسجيل نقطة التحقق من التشغيل الأخير للحصول على التغييرات من هناك. إذا قمت بتغيير اسم المسار أو اسم النشاط، إعادة تعيين نقطة التحقق، وستبدأ من البداية في التشغيل التالي.
عند تصحيح أخطاء مسار التدفق، يعمل Enable change data capture (إصدار أولي) أيضاً. تتم إعادة تعيين نقطة التحقق عند تحديث المستعرض أثناء تشغيل تتبع الأخطاء. بعد أن تكون راضيا عن النتيجة من تشغيل تتبع الأخطاء، يمكنك نشر وتشغيل البنية الأساسية لبرنامج ربط العمليات التجارية. سيبدأ دائماً من البداية بغض النظر عن نقطة التحقق السابقة المسجلة بواسطة تشغيل التصحيح.
في قسم المراقبة، دائمًا لديك فرصة لإعادة تشغيل المسار. عند القيام بذلك، يتم دائما تلقي التغييرات من سجل نقطة التحقق في تشغيل المسار المحدد.
المحتوى ذو الصلة
للحصول على قائمة بمخازن البيانات المدعومة من نشاط النسخ كمصادر ومواضع تلقي، راجع مخازن البيانات المدعومة.