إشعار
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تسجيل الدخول أو تغيير الدلائل.
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تغيير الدلائل.
ينطبق على: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
تلميح
Data Factory في Microsoft Fabric هو الجيل القادم من Azure Data Factory، مع بنية أبسط، وذكاء اصطناعي مدمج، وميزات جديدة. إذا كنت جديدا في تكامل البيانات، ابدأ مع Fabric Data Factory. يمكن لأعباء عمل ADF الحالية الترقية إلى Fabric للوصول إلى قدرات جديدة في علوم البيانات، والتحليلات اللحظية، والتقارير.
ينفذ نشاط Spark في مصنع بيانات و البنية الأساسية لبرنامج ربط العمليات التجارية بـ Synapse برنامج Spark على نظام مجموعة HDInsight الخاصة بك أو عند الطلب . تعتمد هذه المقالة على مقالة أنشطة تحويل البيانات، والتي تقدم نظرة عامة على تحويل البيانات وأنشطة التحويل المدعومة. عند استخدام خدمة Spark المرتبطة عند الطلب، تقوم الخدمة تلقائياً بإنشاء نظام مجموعة Spark لك في الوقت المناسب لمعالجة البيانات ثم تحذف نظام المجموعة بمجرد اكتمال المعالجة.
إضافة نشاط Spark إلى البنية الأساسية باستخدام واجهة المستخدم
لاستخدام نشاط Spark في البنية الأساسية، أكمل الخطوات التالية:
ابحث عن Spark في جزء أنشطة البنية الأساسية، واسحب نشاط Spark إلى لوحة البنية الأساسية.
حدد نشاط Spark الجديد على اللوحة إذا لم يكن محددًا بالفعل.
حدد علامة التبويب HDI Cluster لتحديد أو إنشاء خدمة مرتبطة جديدة إلى مجموعة HDInsight التي سيتم استخدامها لتنفيذ نشاط Spark.
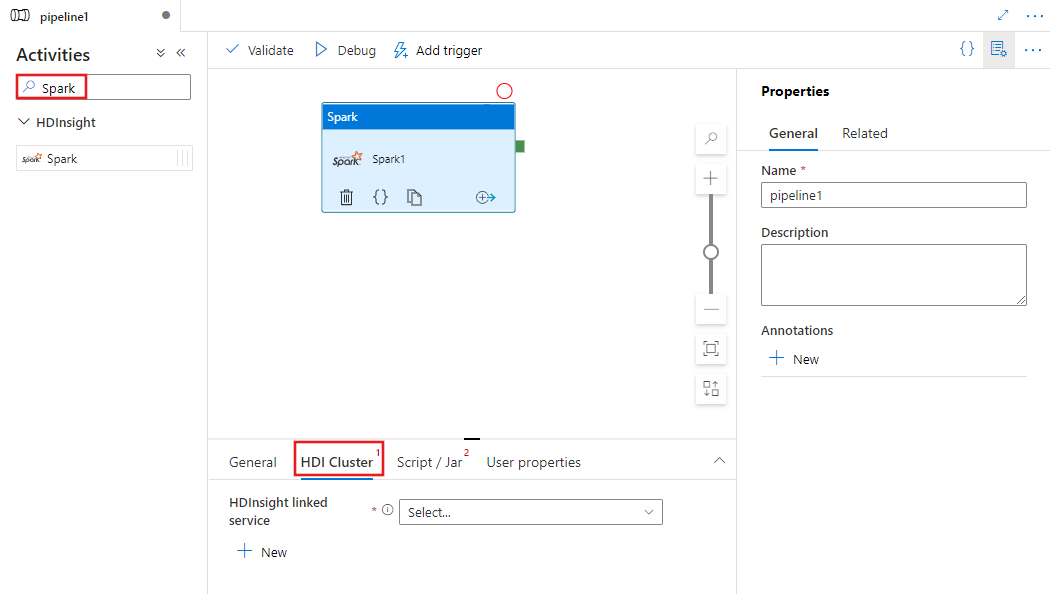
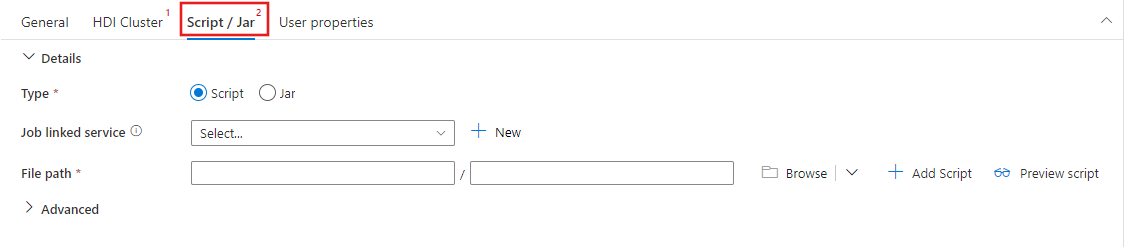
اختر تبويب Script / Jar لاختيار أو إنشاء خدمة مرتبطة بالوظائف جديدة إلى حساب تخزين Azure الذي سيستضيف السكريبت الخاص بك. حدد مسارًا إلى الملف الذي سيتم تنفيذه هناك. يمكنك أيضًا تكوين التفاصيل المتقدمة بما في ذلك مستخدم وكيل وتكوين تصحيح الأخطاء والوسيطات ومعلمات تكوين Spark ليتم تمريرها إلى البرنامج النصي.
خصائص نشاط Spark
هذا هو تعريف JSON عينة من نشاط Spark:
{
"name": "Spark Activity",
"description": "Description",
"type": "HDInsightSpark",
"linkedServiceName": {
"referenceName": "MyHDInsightLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"sparkJobLinkedService": {
"referenceName": "MyAzureStorageLinkedService",
"type": "LinkedServiceReference"
},
"rootPath": "adfspark",
"entryFilePath": "test.py",
"sparkConfig": {
"ConfigItem1": "Value"
},
"getDebugInfo": "Failure",
"arguments": [
"SampleHadoopJobArgument1"
]
}
}
يصف الجدول التالي خصائص JSON المستخدمة في تعريف JSON:
| الخاصية | الوصف | مطلوب |
|---|---|---|
| الاسم | اسم النشاط في التدفق. | نعم |
| الوصف | نص يصف ما يفعله النشاط. | لا |
| النوع | بالنسبة لنشاط Spark، يكون نوع النشاط HDInsightSpark. | نعم |
| linkedServiceName | اسم خدمة HDInsight Spark Linked التي يعمل عليها برنامج Spark. للتعرف على هذه الخدمة المرتبطة، راجع مقالة خدمات الحوسبة المرتبطة. | نعم |
| SparkJobLinkedService | الخدمة المرتبطة ب تخزين Azure التي تحتفظ بملف وظيفة Spark، والتبعيات، والسجلات. تدعم هنا فقط الخدمات المرتبطة مساحة تخزين Azure Blob وADLS Gen2 المرتبطة. إذا لم تقم بتحديد قيمة لهذه الخاصية، يتم استخدام التخزين المقترنة مع نظام المجموعة HDInsight. قيمة هذه الخاصية لا يمكن أن تكون إلا خدمة مرتبطة ب تخزين Azure. | لا |
| rootPath | الحاوية والمجلد في Azure Blob الذي يحتوي على ملف Spark. اسم الملف حساس لحالة الأحرف. راجع قسم بنية المجلد (القسم التالي) للحصول على تفاصيل حول بنية هذا المجلد. | نعم |
| entryFilePath | المسار النسبي للمجلد جذر رمز/حزمة Spark. يجب أن يكون ملف الإدخال إما ملف Python أو ملف .jar. | نعم |
| className | الفئة الرئيسية ل Java/Spark في التطبيق | لا |
| الحجج | قائمة وسيطات سطر الأوامر إلى برنامج Spark. | لا |
| proxyUser | حساب المستخدم للانتحال لتنفيذ برنامج Spark | لا |
| sparkConfig | حدد قيم خصائص Spark configuration المدرجة في الموضوع: Spark Configuration - خصائص التطبيق . | لا |
| getDebugInfo | يحدد متى يتم نسخ ملفات سجل Spark إلى مخزن Azure المستخدم في عنقود HDInsight (أو) المحدد بواسطة sparkJobLinkedService. القيم المسموح بها: بلا، دوماً، أو فشل. القيمة الافتراضية: بلا. | لا |
بنية المجلد
تعد وظائف Spark أكثر قابلية للتوسع من وظائف Pig/Apache Hive. بالنسبة لوظائف Spark، يمكنك توفير عدة تبعيات مثل حزم jar (الموضوعة في مسار Java CLASSPATH)، وملفات Python (الموضوعة على PYTHONPATH)، وأي ملفات أخرى.
أنشئ هيكل المجلدات التالي في تخزين Azure Blob المشار إليه من قبل الخدمة المرتبطة ب HDInsight. بعد ذلك، قم بتحميل الملفات التابعة إلى المجلدات الفرعية المناسبة في المجلد الجذر الذي يمثله entryFilePath. على سبيل المثال، رفع ملفات Python إلى مجلد pyFiles الفرعي وملفات jar إلى مجلد jars الفرعي في المجلد الجذر. عند وقت التشغيل، تتوقع الخدمة هيكل المجلدات التالي في تخزين Azure Blob:
| المسار | الوصف | مطلوب | نوع |
|---|---|---|---|
. (جذر) |
المسار الجذر لوظيفة Spark في خدمة التخزين المرتبطة | نعم | مجلد |
| <معرّف المستخدم> | المسار الذي يشير إلى ملف إدخال وظيفة Spark | نعم | الملف |
| ./jars | جميع الملفات الموجودة في هذا المجلد يتم رفعها ووضعها على مسار Java classpath الخاص بالمجموعة | لا | مجلد |
| ملفات ./pyFiles | يتم تحميل جميع الملفات الموجودة ضمن هذا المجلد ووضعها في PYTHONPATH الخاص بنظام المجموعة | لا | مجلد |
| ./files | يتم تحميل جميع الملفات الموجودة ضمن هذا المجلد ووضعها على دليل المشغَّل | لا | مجلد |
| ./archives | جميع الملفات الموجودة تحت هذا المجلد غير مضغوطة | لا | مجلد |
| ./logs | المجلد الذي يحتوي على سجلات من نظام المجموعة Spark. | لا | مجلد |
إليك مثالا على تخزين يحتوي على ملفي وظائف Spark في مساحة تخزين Azure Blob المشار إليهما بواسطة خدمة HDInsight المرتبطة به.
SparkJob1
main.jar
files
input1.txt
input2.txt
jars
package1.jar
package2.jar
logs
archives
pyFiles
SparkJob2
main.py
pyFiles
scrip1.py
script2.py
logs
archives
jars
files
المحتوى ذو الصلة
راجع المقالات التالية التي تشرح كيفية تحويل البيانات بطرق أخرى: