إشعار
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تسجيل الدخول أو تغيير الدلائل.
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تغيير الدلائل.
ينطبق على: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
تلميح
Data Factory في Microsoft Fabric هو الجيل القادم من Azure Data Factory، مع بنية أبسط، وذكاء اصطناعي مدمج، وميزات جديدة. إذا كنت جديدا في تكامل البيانات، ابدأ مع Fabric Data Factory. يمكن لأعباء عمل ADF الحالية الترقية إلى Fabric للوصول إلى قدرات جديدة في علوم البيانات، والتحليلات اللحظية، والتقارير.
في هذا الدرس، تستخدم واجهة المستخدم Azure Data Factory (UX) لإنشاء خط أنابيب ينسخ ويحول البيانات من مصدر Azure Data Lake Storage (ADLS) Gen2 إلى مصرف ADLS Gen2 باستخدام تدفق البيانات المخصص. يمكن توسيع نمط التكوين في هذا البرنامج التعليمي عند تحويل البيانات باستخدام تعيين تدفق البيانات
يهدف هذا البرنامج التعليمي لرسم خرائط تدفقات البيانات بشكل عام. تتوفر تدفقات البيانات في كل من Azure Data Factory وSynapse Pipelines. إذا كنت جديدا على تدفقات البيانات في خطوط أنابيب Azure Synapse، اتبع Data Flow باستخدام Azure Synapse Pipelines.
في هذا البرنامج التعليمي، يمكنك القيام بالخطوات التالية:
- إنشاء data factory.
- أنشئ خط أنابيب مع نشاط Data Flow.
- إنشاء تعيين تدفق البيانات مع أربعة تحويلات.
- اختبار تشغيل التدفقات.
- مراقبة نشاط Data Flow
المتطلبات الأساسية
- Azure اشتراك. إذا لم يكن لديك اشتراك Azure، أنشئ حساب Azure مجاني قبل أن تبدأ.
- Azure Data Lake Storage Gen2 حساب. يمكنك استخدام تخزين ADLS كمصدر ومتلقي لمخازن البيانات. إذا لم يكن لديك حساب تخزين، راجع إنشاء حساب تخزين Azure لخطوات إنشاء واحد.
- قم بتنزيل MoviesDB.csv هنا. لاسترجاع الملف من GitHub، انسخ المحتوى إلى محرر نصوص من اختيارك لحفظه محليا كملف .csv. قم بتحميل الملف إلى حساب التخزين الخاص بك في حاوية تسمى "sample-data".
إنشاء مصدرًا للبيانات
يمكنك في هذه الخطوة إنشاء Data Factory وفتح تجربة مستخدم Data Factory لإنشاء تدفق في Data Factory.
افتح Microsoft Edge أو جوجل كروم. حاليا، يدعم واجهة مصنع البيانات فقط في متصفحات الويب Microsoft Edge وGoogle Chrome.
في القائمة العلوية، حدد Create a resource>Analytics>Data Factory :
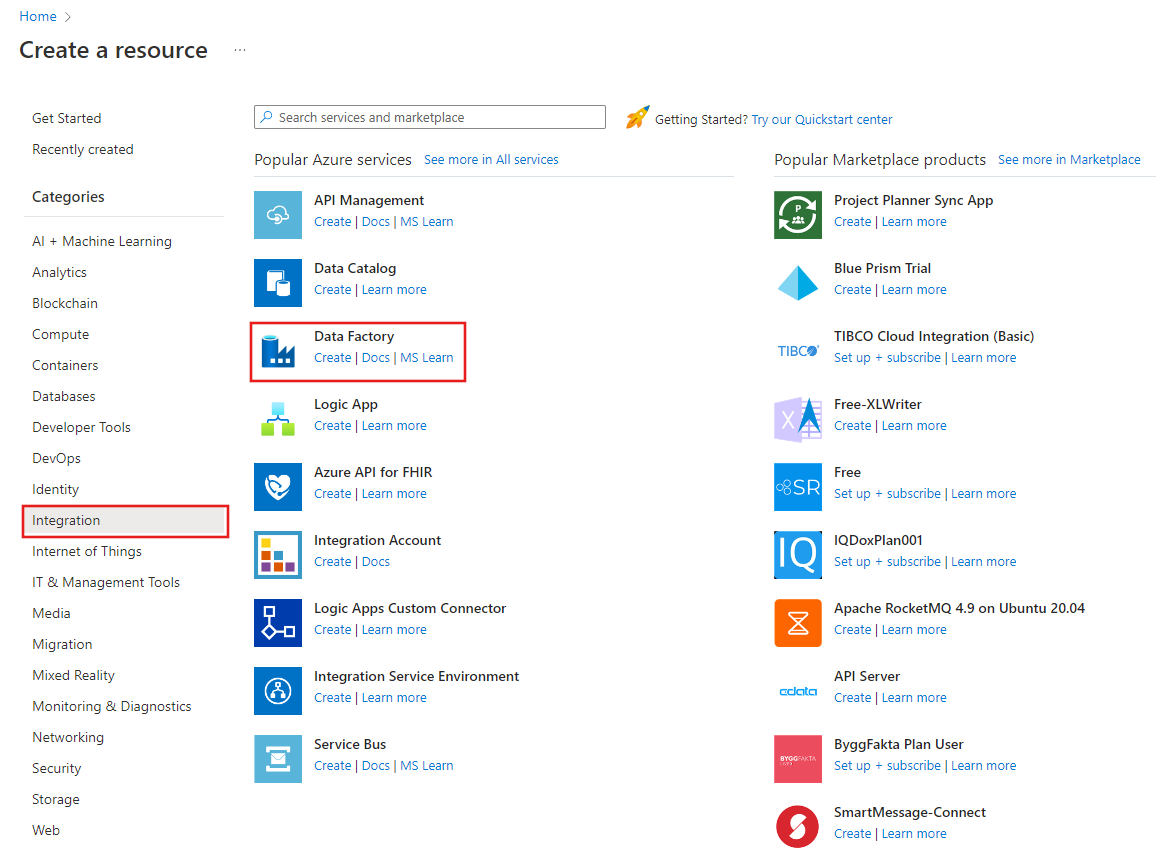
في صفحة New data factory، أدخِل ADFTutorialDataFactory في خانة Name.
يجب أن يكون اسم مصنع البيانات Azure global unique. إذا تلقيت رسالة خطأ حول قيمة الاسم، فأدخل اسماً مختلفاً لمصنع البيانات. (على سبيل المثال، yournameADFTutorialDataFactory). للحصول على قواعد التسمية للبيانات الاصطناعية على Data Factory، راجع قواعد تسمية Data Factory.
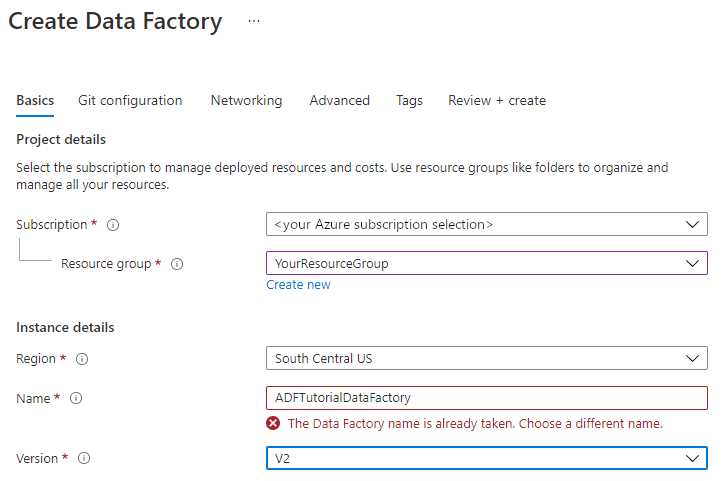
اختر Azure subscription الذي تريد إنشاء مصنع البيانات فيه.
بالنسبة إلى مجموعة الموارد، نفِّذ إحدى الخطوات التالية:
حدد Use existing واختر مجموعة موارد موجودة من القائمة المنسدلة.
حدد Create new وأدخل اسم مجموعة الموارد.
للتعرف على مجموعات الموارد، راجع Use Resource groups لإدارة موارد Azure الخاصة بك.
ضمن Version، حدد V2.
ضمن Region، حدد موقعا لمصنع البيانات. لن تظهر القائمة المنسدلة إلا على المواقع المعتمدة فقط. يمكن أن تكون مخازن البيانات (مثل تخزين Azure و SQL Database) والحوسبات (مثل Azure HDInsight) المستخدمة في مصنع البيانات في مناطق أخرى.
حدد «Review + Create»، ثم حدد «Create».
بعد الانتهاء من الإنشاء، سترى الإعلام في مركز الإعلامات. حدد Go to resource للانتقال إلى صفحة Data factory.
حدد Launch studio لبدء تشغيل Data Factory studio في علامة تبويب منفصلة.
إنشاء خط أنابيب مع نشاط Data Flow
في هذه الخطوة، تنشئ خط أنابيب يحتوي على نشاط Data Flow.
في الصفحة الرئيسية ل Azure Data Factory، اختر Orchestrate.
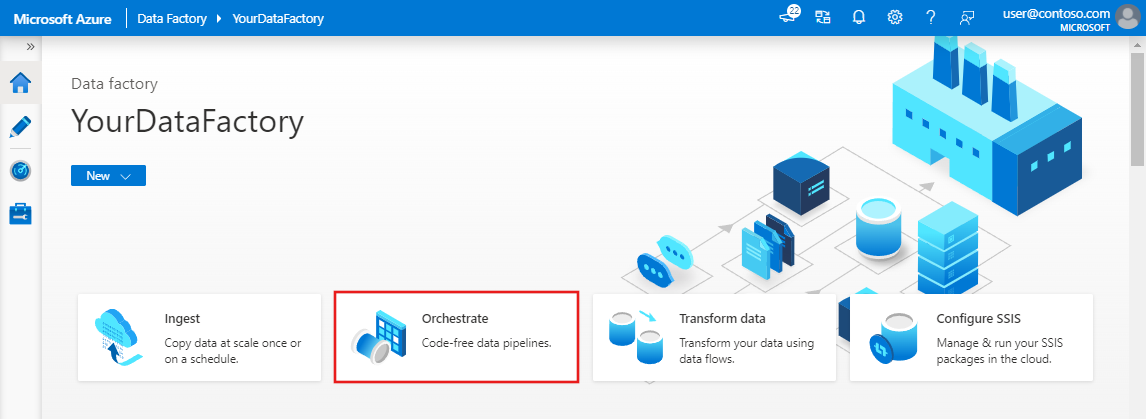
الآن نافذة مفتوحة لمسار جديد. في علامة التبويب General لخصائص البنية الأساسية لبرنامج ربط العمليات التجارية، أدخل TransformMovies ل Name of the pipeline.
في جزء "الأنشطة"، وسّع أكورديون "النقل والتحويل". قم بسحب وإفلات نشاط Data Flow من اللوحة إلى لوحة خط الأنابيب.
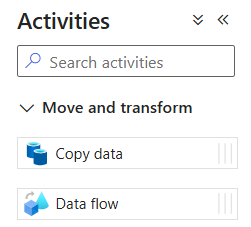
قم بتسمية نشاط تدفق البيانات DataFlow1.
في الشريط العلوي من لوحة خط الأنابيب، قم بتمرير شريط Data Flow debug إلى الوضع. يسمح وضع التصحيح بالاختبار التفاعلي لمنطق التحويل مقابل نظام مجموعة Spark مباشرة. تستغرق مجموعات Data Flow من 5 إلى 7 دقائق للتسخين، وينصح المستخدمون بتفعيل تصحيح الأخطاء أولا إذا كانوا يخططون لتطوير Data Flow. لمزيد من المعلومات، راجع وضع التصحيح.

إنشاء منطق التحويل في لوحة تدفق البيانات
في هذه الخطوة، يمكنك إنشاء تدفق بيانات يأخذ moviesDB.csv في تخزين ADLS وتجميع متوسط تصنيف الكوميديا من 1910 إلى 2000. ثم تكتب هذا الملف مرة أخرى إلى تخزين ADLS.
في اللوحة أسفل اللوحة، انتقل إلى إعدادات نشاط تدفق البيانات وحدد جديد، الموجود بجانب حقل تدفق البيانات. يؤدي ذلك إلى فتح لوحة تدفق البيانات.
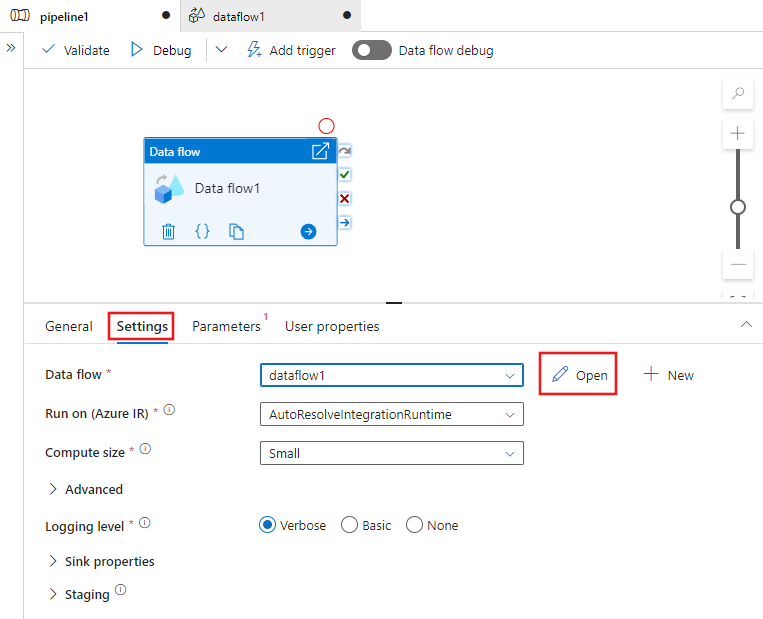
في جزء Properties ضمن General، قم بتسمية تدفق البيانات الخاص بك: TransformMovies.
في لوحة تدفق البيانات، أضف مصدر عن طريق تحديد المربع إضافة مصدر .
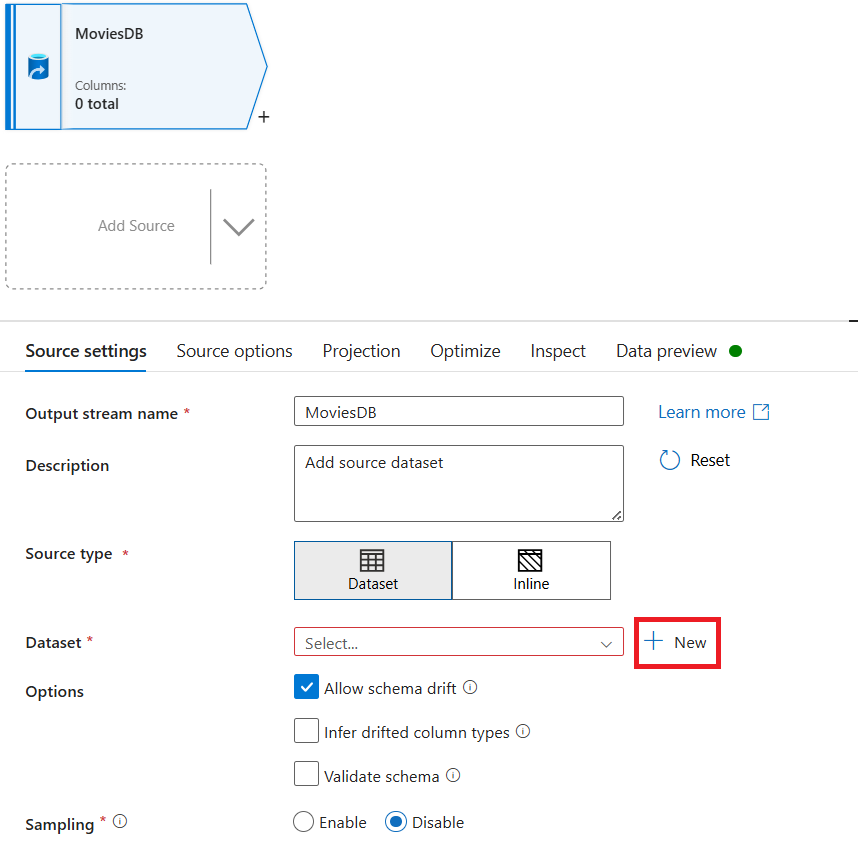
سمِّ مصدرك MoviesDB. حدد "جديد" لإنشاء مجموعة بيانات مصدر جديدة.
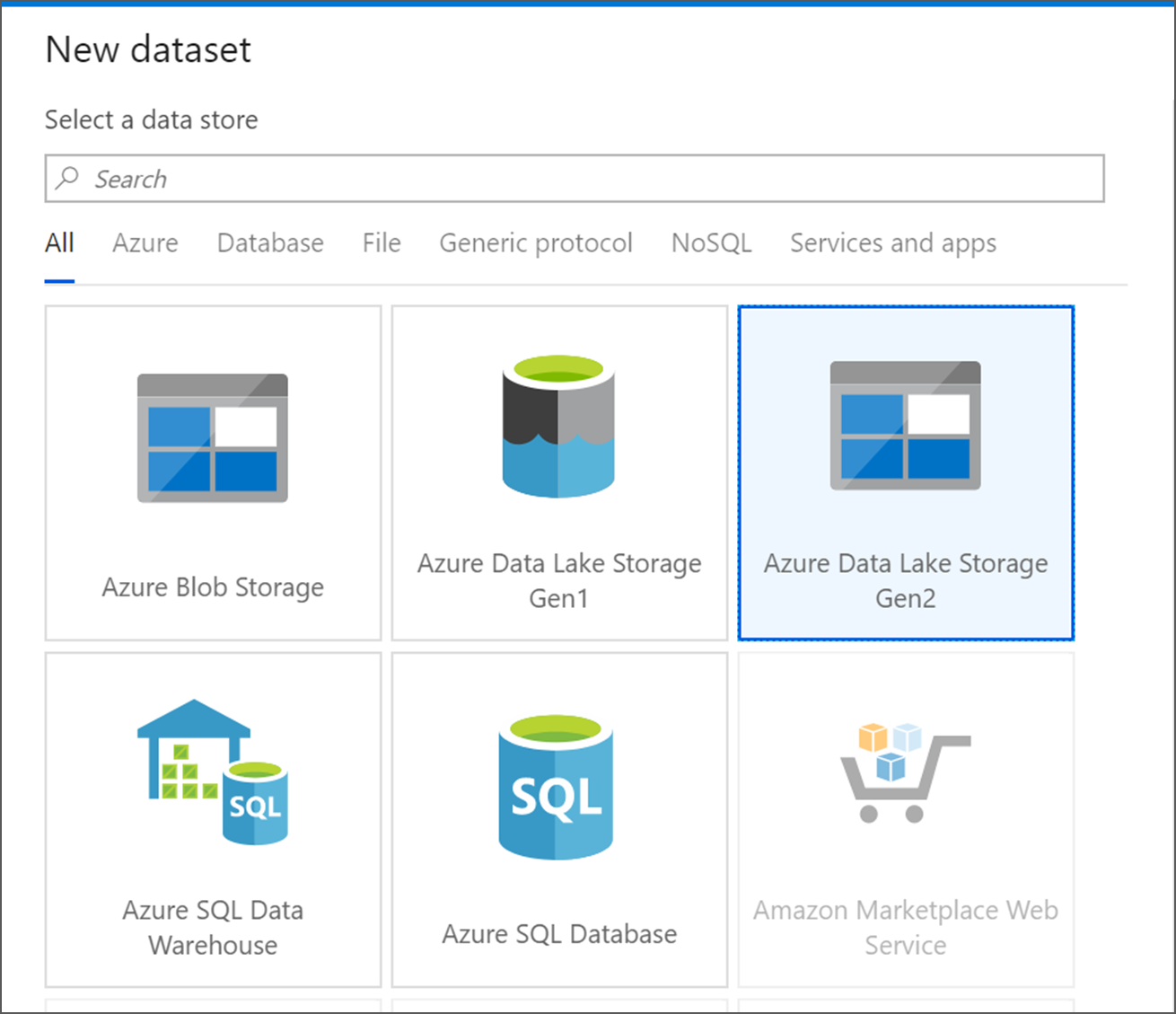
اختر Azure Data Lake Storage Gen2. حدد متابعة.
اختر DelimitedText. حدد متابعة.
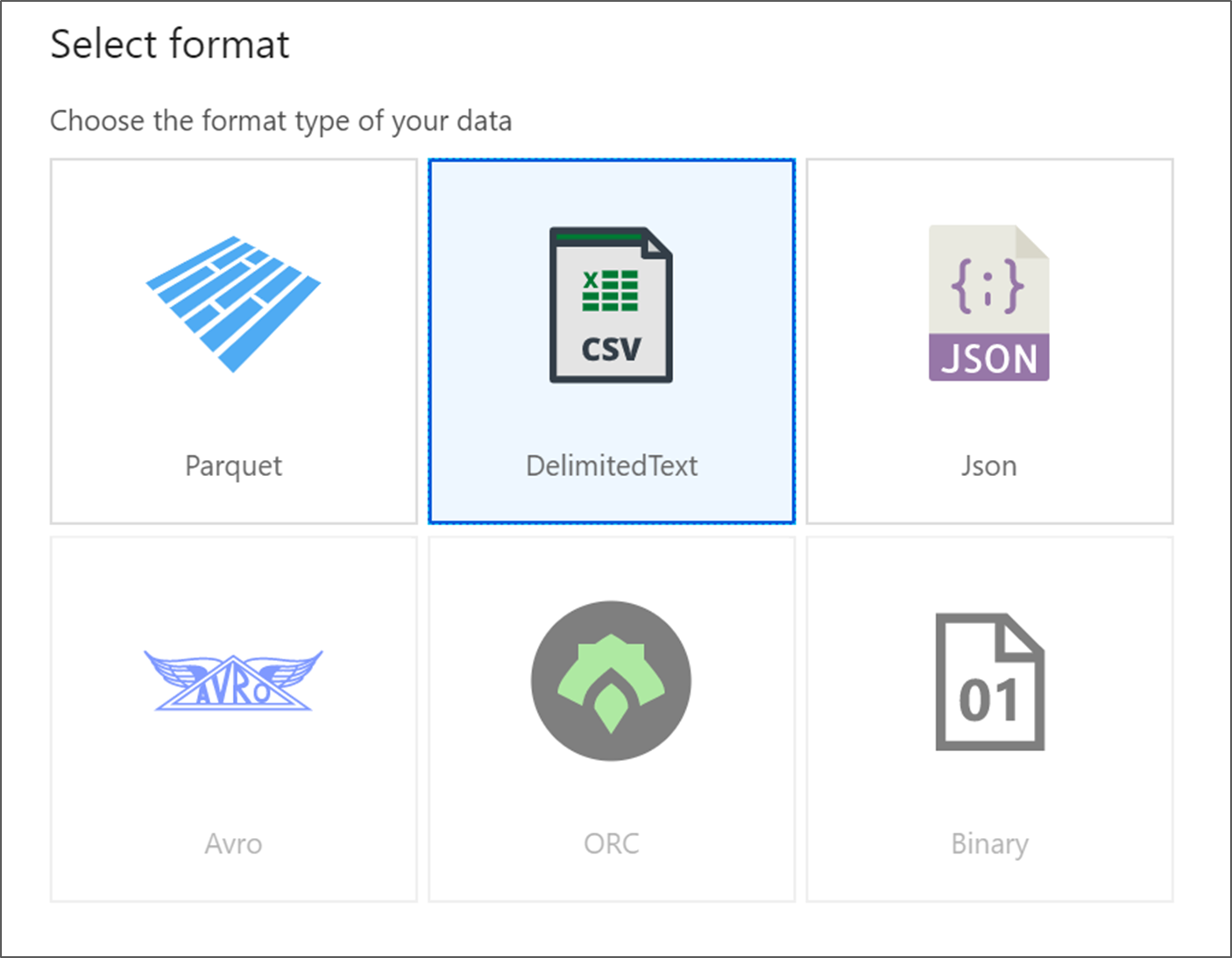
سمِّ مجموعة البيانات MoviesDB. في القائمة المنسدلة للخدمة المرتبطة، اختر "جديد".
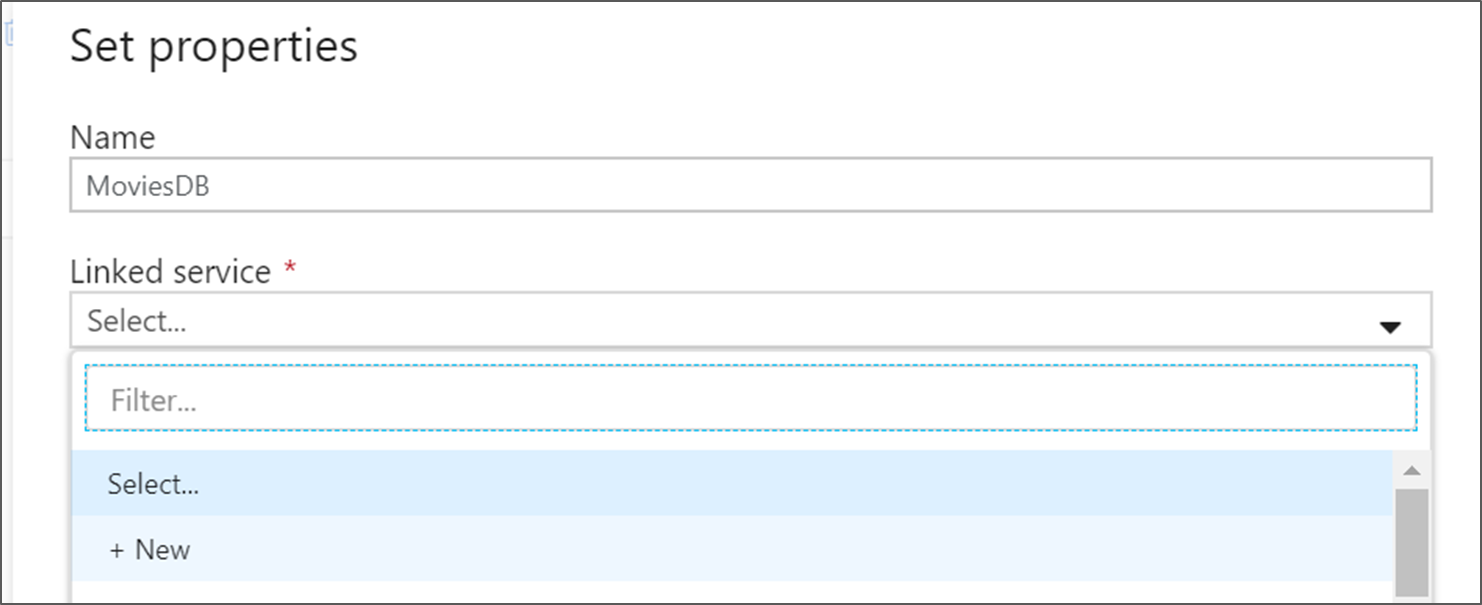
في شاشة إنشاء خدمة مرتبطة، قم بتسمية الخدمة المرتبطة ADLS gen2 ADLSGen2 وحدد أسلوب المصادقة. ثم أدخل بيانات اعتماد الاتصال. في هذا البرنامج التعليمي، نحن نستخدم مفتاح الحساب للاتصال بحساب التخزين الخاص بنا. يمكنك تحديد اختبار الاتصال للتحقق من إدخال بيانات الاعتماد بشكل صحيح. حدد إنشاء عند الانتهاء.
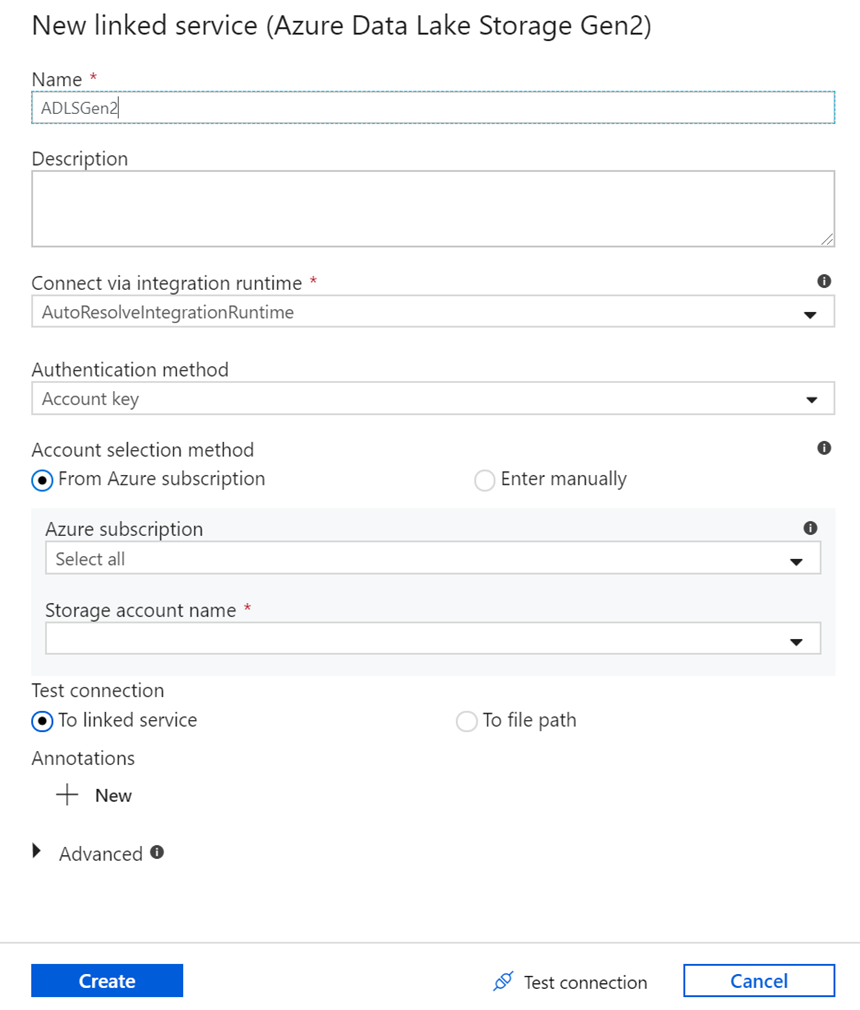
على شاشة إنشاء مجموعة البيانات، أدخل مكان الملف ضمن حقل "مسار الملف". في هذا البرنامج التعليمي، يقع الملف moviesDB.csv في حاوية عينة البيانات. حيث إن الملف يحتوي على عناوين تحقق الصف الأول كعنوان. حدد من اتصال/تخزين لاستيراد مخطط العنوان مباشرة من الملف داخل موقع التخزين. حدد موافق عند الانتهاء.
إذا بدأ تشغيل كتلة تتبع الأخطاء، انتقل إلى علامة التبويب "معاينة البيانات" من تحويل المصدر وحدد "تحديث" للحصول على لقطة من البيانات. يمكنك استخدام معاينة البيانات للتحقق من تكوين التحويل بشكل صحيح.
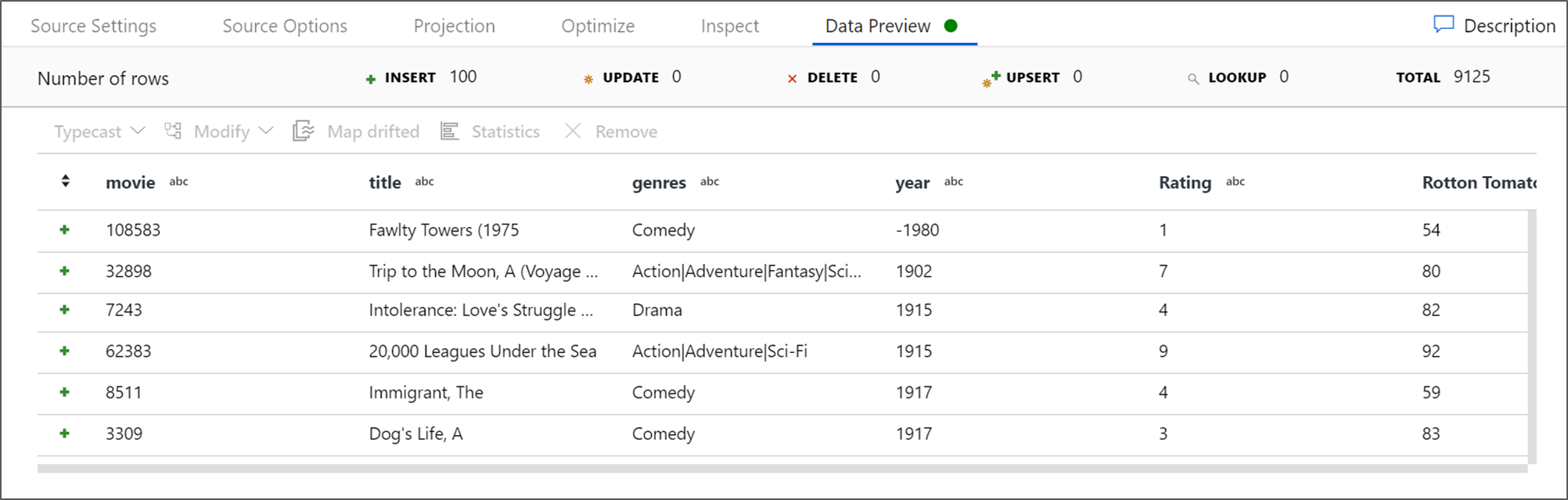
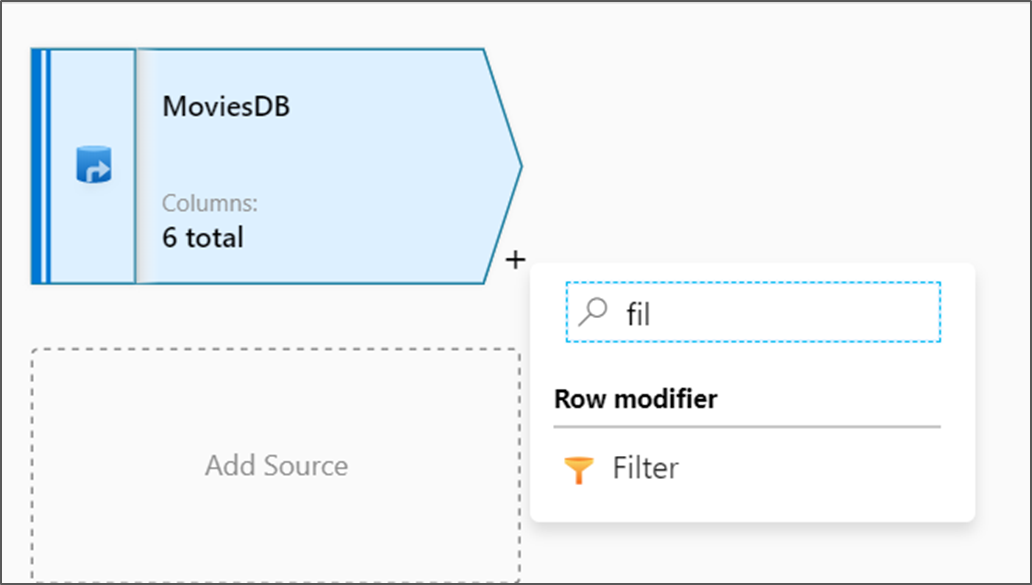
بجوار عقدة المصدر على لوحة تدفق البيانات، حدد رمز الجمع لإضافة تحويل جديد. أول تحويل تضيفه هو "عامل تصفية".
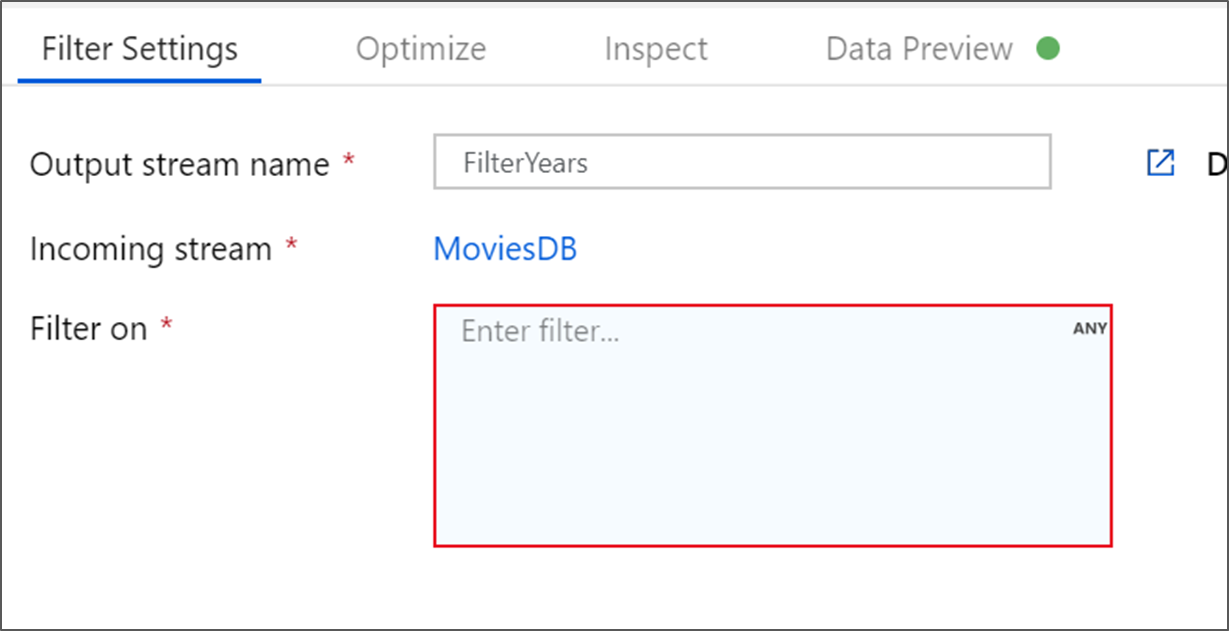
تسمية عامل التصفية تحويل FilterYears. حدد مربع التعبير بجوار Filter on ثم Open expression builder. هنا يمكنك تحديد شرط التصفية الخاص بك.
يتيح لك منشئ تعبير تدفق البيانات إنشاء تعبيرات بشكل تفاعلي لاستخدامها في تحويلات مختلفة. يمكن أن تتضمن التعبيرات دالات مضمنة وأعمدة من مخطط الإدخال ومعلمات معرفة من قبل المستخدم. لمزيد من المعلومات حول كيفية بناء التعبيرات، راجع Data Flow expression builder.
في هذا البرنامج التعليمي، فإنك ترغب في تصفية أفلام الكوميديا النوع الذي خرج بين عامي 1910 و2000. حيث إن السنة حالياً هي سلسلة، تحتاج إلى تحويلها إلى عدد صحيح باستخدام
toInteger()الدالة. استخدم عامل التشغيل الأكبر من أو يساوي (> =) وأقل من أو يساوي (< =) للمقارنة بقيم السنة الحرفية 1910 و 2000. توحيد هذه التعبيرات مع عامل التشغيل و(&&). التعبير يخرج على النحو التالي:toInteger(year) >= 1910 && toInteger(year) <= 2000للعثور على الأفلام الكوميدية، يمكنك استخدام
rlike()الوظيفة للعثور على نمط "كوميديا" في أنواع الأعمدة. توحيدrlikeالتعبير مع مقارنة السنة للحصول على:toInteger(year) >= 1910 && toInteger(year) <= 2000 && rlike(genres, 'Comedy')إذا كان لديك مجموعة تصحيح نشطة، يمكنك التحقق من المنطق الخاص بك عن طريق تحديد Refresh لمشاهدة إخراج التعبير مقارنة بالمدخلات المستخدمة. هناك أكثر من إجابة صحيحة حول كيفية إنجاز هذا المنطق باستخدام لغة التعبير عن تدفق البيانات.
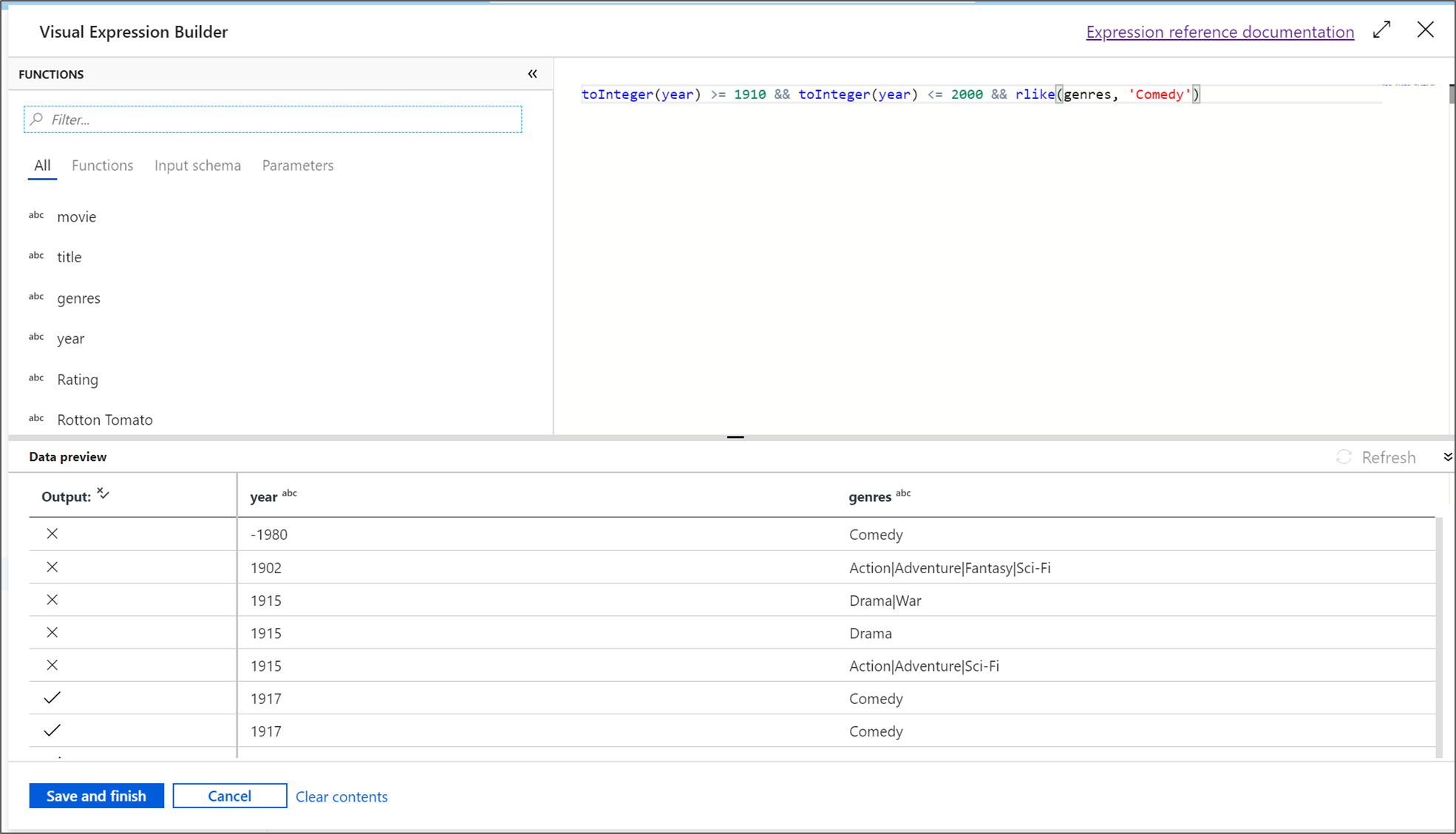
حدد حفظ وإنهاء بمجرد الانتهاء من التعبير الخاص بك.
إحضار "معاينة البيانات" للتحقق من أن عامل التصفية يعمل بشكل صحيح.
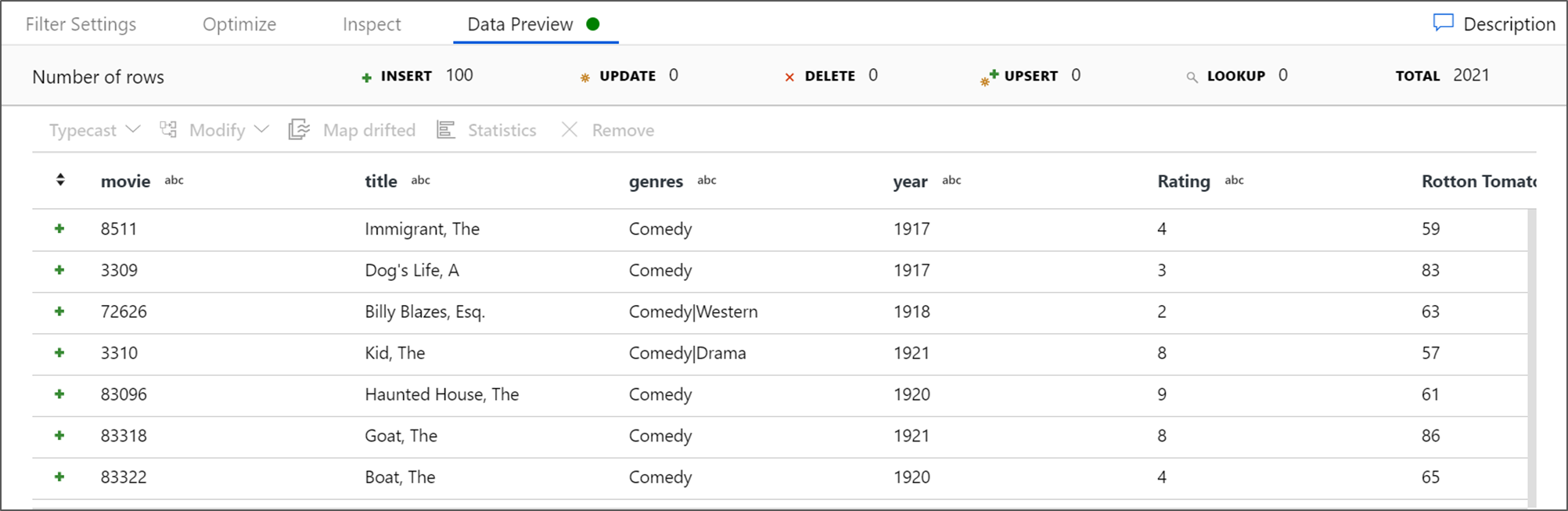
التحويل التالي الذي ستقوم بإضافته هو تحويل "تجميعي" ضمن "معدل المخطط".
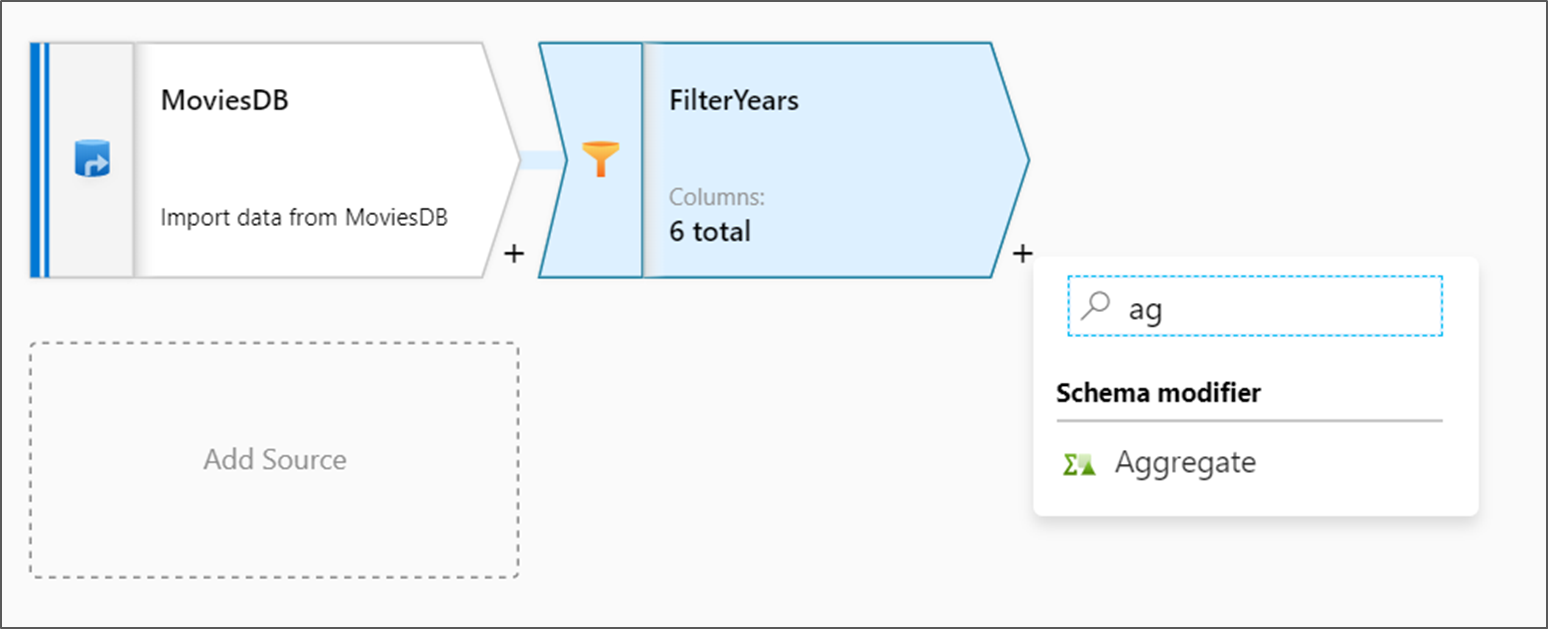
تسمية التحويل التجميعي AggregateComedyRating. في علامة التبويب تجميع حسب، حدد السنة من القائمة المنسدلة لجمع التجميعات حسب السنة التي صدر فيها الفيلم.
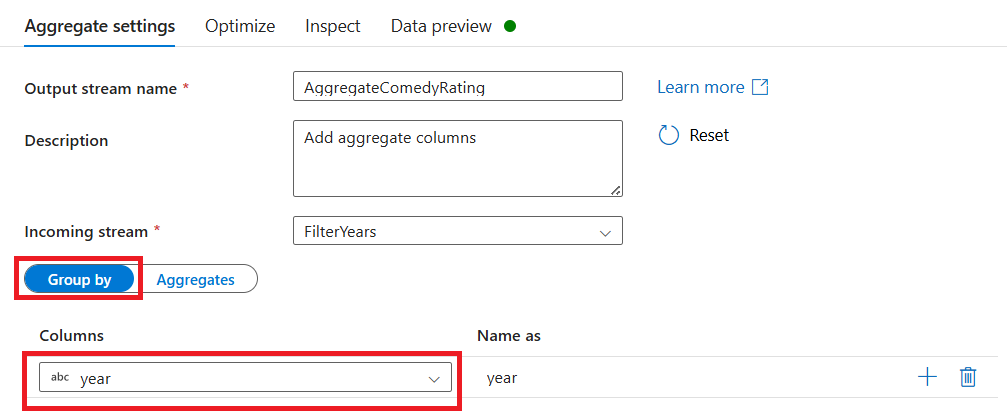
انتقل إلى علامة التبويب تجميعات. في مربع النص الأيمن، ثم تسمية العمود التجميعي AverageComedyRating. حدد مربع التعبير الصحيح لإدخال التعبير التجميعي عبر منشئ التعبير.
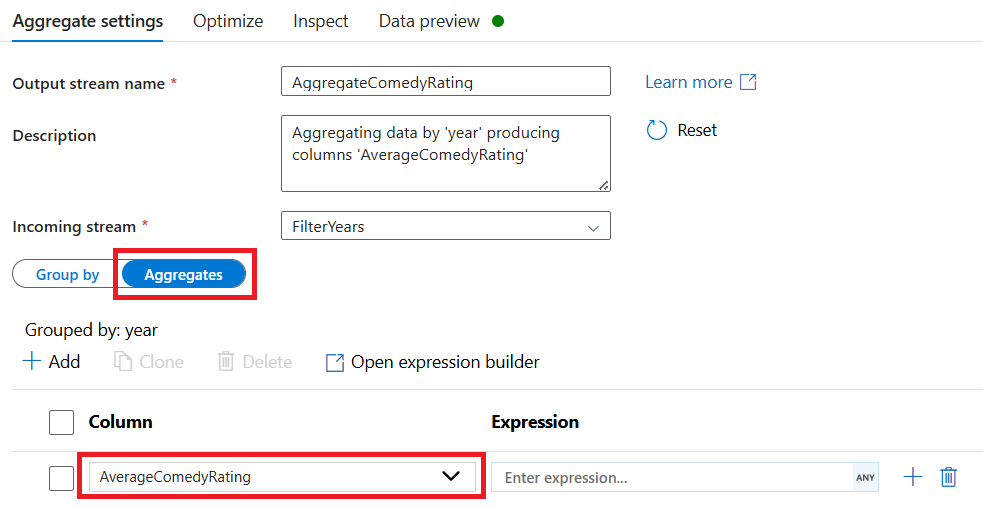
للحصول على متوسط "تصنيف"العمود، استخدم الدالة
avg()التجميعية. لأن "التصنيف" هو سلسلةavg()ويقبل الإدخال الرقمي، يجب علينا تحويل القيمة إلى رقم عن طريقtoInteger()الدالة. يبدو التعبير هكذا:avg(toInteger(Rating))حدد حفظ وإنهاء عند الانتهاء.

انتقل إلى علامة التبويب "معاينة البيانات" لعرض إخراج التحويل. لاحظ وجود عمودين فقط هناك، السنة وAverageComedyRating.
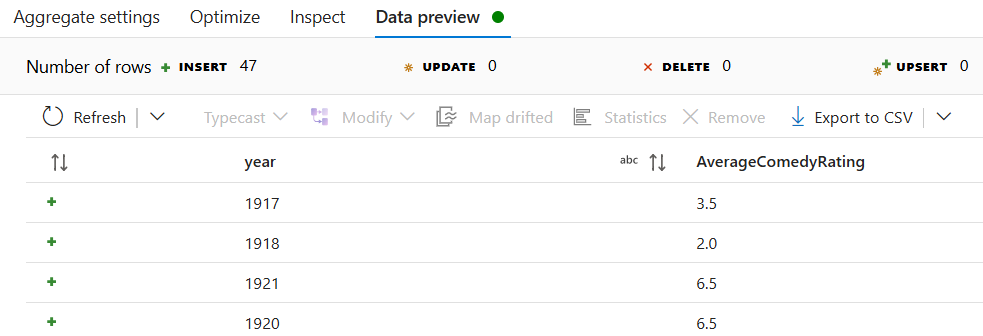
أضف تحويل "متلقٍ" ضمن قسم "الوجهة".
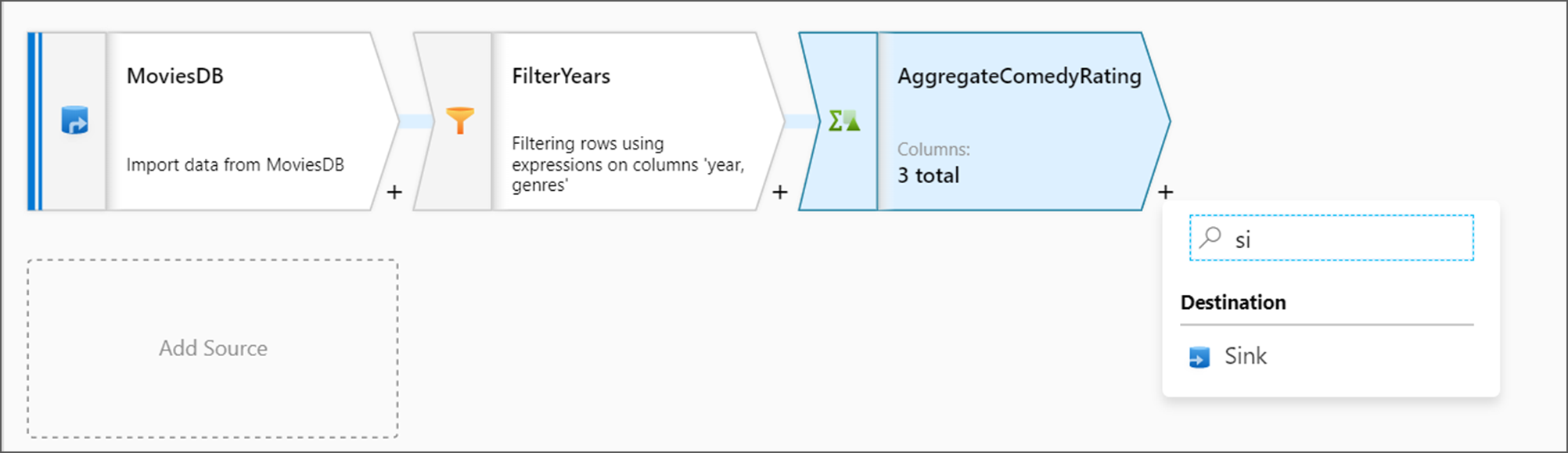
سَمِّ المتلقي Sink. حدد "جديد" لإنشاء مجموعة بيانات الملتقي.
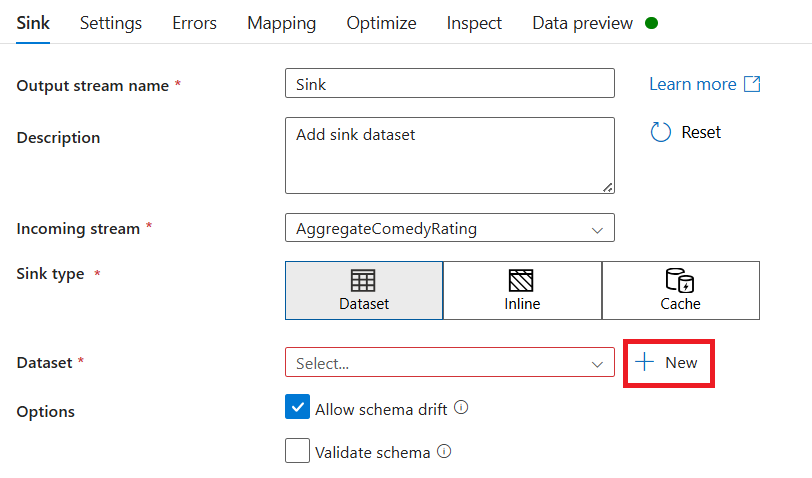
اختر Azure Data Lake Storage Gen2. حدد متابعة.
اختر DelimitedText. حدد متابعة.
تسمية مجموعة بيانات المتلقي MoviesSink. بالنسبة للخدمة المرتبطة، اختر الخدمة المرتبطة ADLS gen2 التي أنشأتها في الخطوة 6. أدخل مجلد إخراج لكتابة البيانات إليه. في هذا البرنامج التعليمي، سنكتب إلى مجلد 'الإخراج' في حاوية 'عينة البيانات'. لا يحتاج المجلد إلى الوجود مسبقاً ويمكن إنشاؤه ديناميكياً. حدد خانة الاختيار الصف الأول كعنوان، وحدد دونلمخطط الاستيراد. حدد إنهاء.
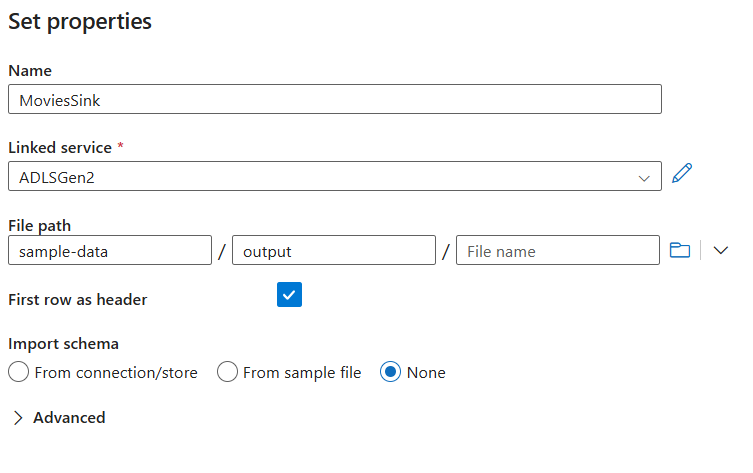
الآن انتهيت من بناء تدفق البيانات. أنت مستعد لتشغيله في مسارك.
تشغيل ومراقبة Data Flow
يمكنك تتبع أخطاء المسار قبل نشره. في هذه الخطوة، ستقوم بتشغيل تتبع أخطاء مسار تدفق البيانات. بينما لا تكتب معاينة البيانات البيانات، يقوم تشغيل تتبع الأخطاء بكتابة البيانات إلى وجهة المتلقي.
انتقل إلى لوحة المسار. حدد "تتبع الأخطاء" لتشغيل تتبع الأخطاء.
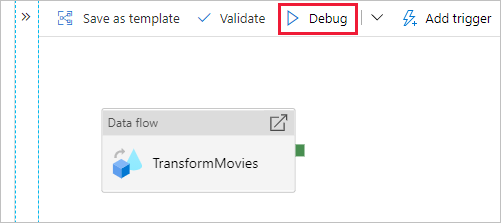
تصحيح خطوط الأنابيب لأنشطة Data Flow يستخدم مجموعة التصحيح النشط لكنه لا يزال يستغرق دقيقة على الأقل للتهيئة. يمكنك تعقب التقدم عبر علامة التبويب Output . بمجرد نجاح التشغيل، مرر مؤشر الماوس فوق التشغيل وحدد أيقونة النظارات لفتح جزء المراقبة.
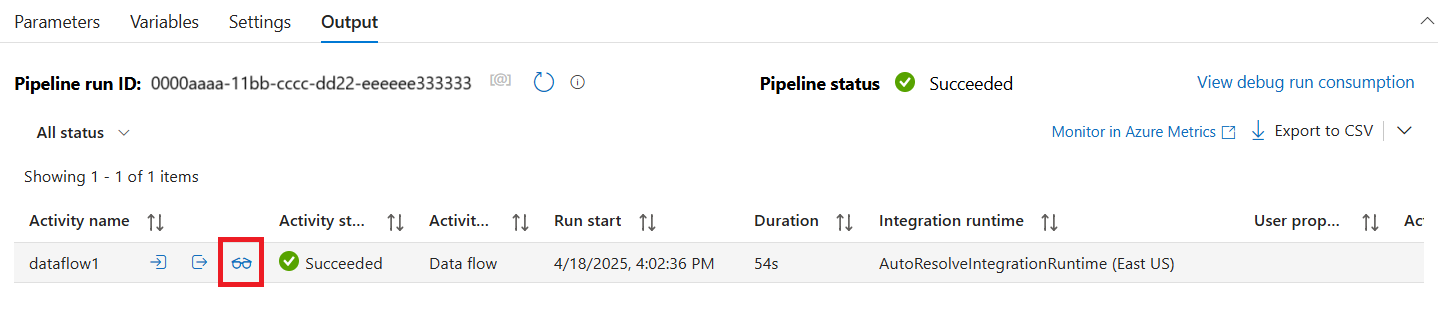
في جزء المراقبة، حدد الزر مراحل لمعرفة عدد الصفوف والوقت المستغرق في كل خطوة تحويل.
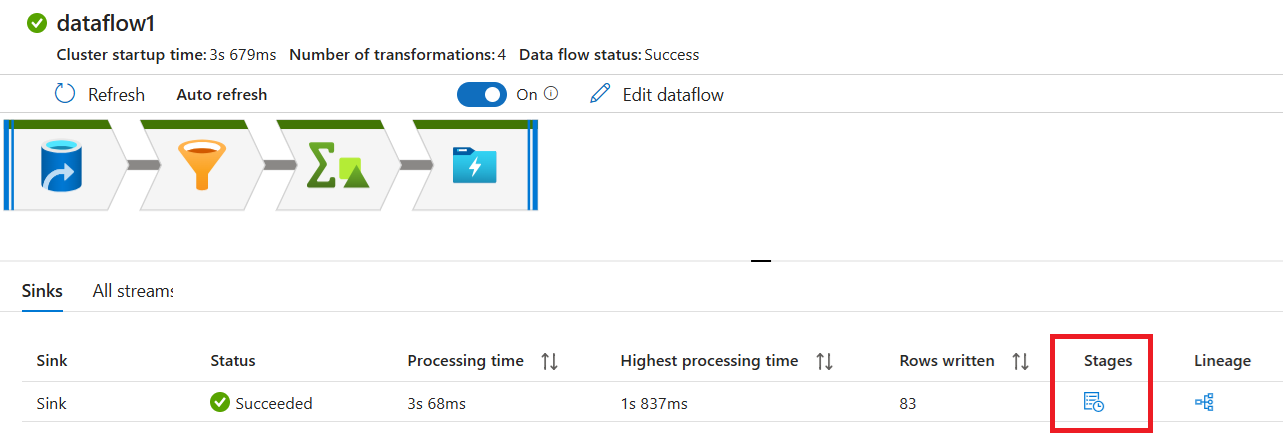
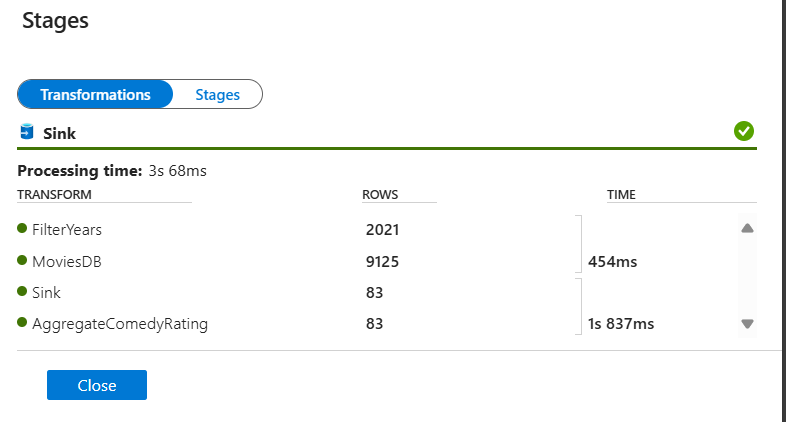
حدد تحويلاً للحصول على معلومات مفصلة حول أعمدة البيانات وتقسيمها.
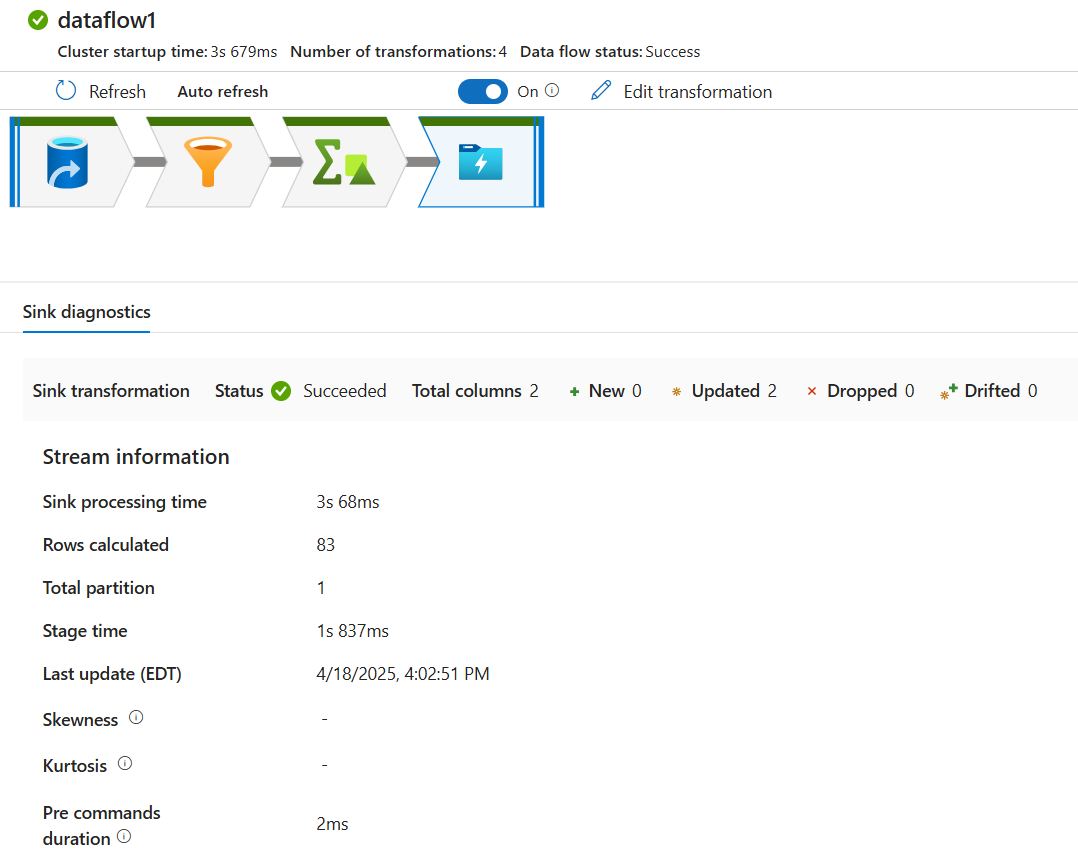
إذا كنت اتبعت هذا البرنامج التعليمي بشكل صحيح، يجب أن تكون قد كتبت 83 صفاً وعمودين في مجلد المتلقي الخاص بك. يمكنك التحقق من صحة البيانات عن طريق التحقق من تخزين الكائن الثنائي كبير الحجم.
المحتوى ذو الصلة
المسار في هذا البرنامج التعليمي يدير تدفق البيانات التي تجمع متوسط تصنيف أفلام الكوميديا من 1910 إلى 2000 ويكتب البيانات إلى ADLS. لقد تعرفت على كيفية:
- إنشاء data factory.
- أنشئ خط أنابيب مع نشاط Data Flow.
- إنشاء تعيين تدفق البيانات مع أربعة تحويلات.
- اختبار تشغيل التدفقات.
- مراقبة نشاط Data Flow
تعرف على المزيد حول لغة تعبير تدفق البيانات.