ملاحظة
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تسجيل الدخول أو تغيير الدلائل.
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تغيير الدلائل.
ينطبق على: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
تلميح
جرب Data Factory في Microsoft Fabric، وهو حل تحليلي متكامل للمؤسسات. يغطي Microsoft Fabric كل شيء بدءا من حركة البيانات إلى علم البيانات والتحليلات في الوقت الحقيقي والمعلومات المهنية وإعداد التقارير. تعرف على كيفية بدء إصدار تجريبي جديد مجانا!
إذا كنت جديداً في استخدام Azure Data Factory، فراجع مقدمة لـ Azure Data Factory.
في هذا البرنامج التعليمي، ستتعلم أفضل الممارسات التي يمكن تطبيقها عند كتابة الملفات إلى Data Lake Storage Gen2 أو تخزين كائن ثنائي كبير الحجم من Azure باستخدام تدفق البيانات. ستحتاج إلى الوصول إلى حساب تخزين كائن ثنائي كبير الحجم من Azure أو حساب Azure Data Lake Store Gen2 لقراءة ملف باركيه ثم تخزين النتائج في المجلدات.
المتطلبات الأساسية
- اشتراك Azure. إذا لم تكن مشتركًا في Azure، فيمكنك إنشاء حساب مجاني على Azure قبل البدء.
- حساب Azure Storage. يمكنك استخدام تخزين ADLS كمصدر ومتلقي لمخازن البيانات. إذا لم يكن لديك حساب تخزين، فشاهد إنشاء حساب تخزين Azure للحصول على خطوات لإنشاء حساب.
الخطوات في هذا البرنامج التعليمي سوف نفترض أن لديك
إنشاء مصدرًا للبيانات
يمكنك في هذه الخطوة إنشاء Data Factory وفتح تجربة مستخدم Data Factory لإنشاء تدفق في Data Factory.
افتح Microsoft Edge أو Google Chrome. حالياً، تُدعم واجهة مستخدم مصنع البيانات فقط في متصفحات الويب Microsoft Edge وGoogle Chrome.
في القائمة اليسرى، حدد Create a resource>Integration>Data Factory
في صفحة New data factory، أدخِل ADFTutorialDataFactory في خانة Name
حدد subscription على Azure الذي تريد إنشاء مصنع البيانات فيه.
بالنسبة إلى مجموعة الموارد، نفِّذ إحدى الخطوات التالية:
أ. حدد Use existing واختر مجموعة موارد موجودة من القائمة المنسدلة.
ب. حدد Create new وأدخل اسم مجموعة الموارد. للتعرف على مجموعات الموارد، راجع استخدام مجموعات الموارد لإدارة موارد Azure التابعة لك.
ضمن Version، حدد V2.
ضمن الموقع، حدد موقعا لمصنع البيانات. لن تظهر القائمة المنسدلة إلا على المواقع المعتمدة فقط. يمكن أن تكون مخازن البيانات (على سبيل المثال، Azure Storage وSQL Database) والحوسبة (على سبيل المثال، Azure HDInsight) المستخدمة من قبل مصنع البيانات في مناطق أخرى.
حدد إنشاء.
بعد الانتهاء من الإنشاء، سترى الإعلام في مركز الإعلامات. حدد Go to resource للانتقال إلى صفحة Data factory.
حددAuthor & Monitor لإطلاق واجهة مستخدم Data Factory في علامة تبويب منفصلة.
إنشاء مسار بنشاط تدفق البيانات
في هذه الخطوة، ستقوم بإنشاء تدفق يحتوي على نشاط سير عمل البيانات.
في صفحة Azure Data Factory الرئيسية، حدد Orchestrate.
في علامة التبويب عام للتدفق، أدخل DeltaLake في خانة اسم التدفق.
في الشريط العلوي للمصنع، شغّل شريط تمرير تتبع أخطاء تدفق البيانات. يسمح وضع التصحيح بالاختبار التفاعلي لمنطق التحويل مقابل نظام مجموعة Spark مباشرة. نوصي المستخدمين بتشغيل تتبع الأخطاء أولاً إذا كانوا يخططون لتطوير تدفق البيانات حيث إن نُظمها تستغرق 5-7 دقائق للاستعداد. لمزيد من المعلومات، راجع وضع التصحيح.
في جزء "الأنشطة"، وسّع أكورديون "النقل والتحويل". اسحب نشاط "تدفق البيانات" وأسقطه في جزء من لوحة المسار.
إنشاء منطق التحويل في لوحة تدفق البيانات
ستأخذ أي بيانات مصدر (في هذا البرنامج التعليمي، سنستخدم مصدر ملف باركيه) ونستخدم تحويل المتلقي لتهبط البيانات بتنسيق باركيه باستخدام الآليات الأكثر فاعلية لمستودع بيانات ETL.

أهداف البرنامج التعليمي
- اختر أيًا من مجموعات البيانات المصدر في تدفق بيانات جديد 1. استخدم تدفقات البيانات لتقسيم مجموعة بيانات الحوض بشكل فعال
- ضع بياناتك المقسمة في مجلدات مستودع ADLS Gen2
أبدء بلوحة سير عمل بيانات فارغة
أولاً، يتم إعداد بيئة تدفق البيانات لكل آلية من الآليات الموضحة أدناه للبيانات المنتَقل إليها في ADLS Gen2
- انقر فوق تحويل المصدر.
- انقر فوق الزر الجديد بجوار مجموعة البيانات في اللوحة السفلية.
- اختر مجموعة بيانات أو أنشئ مجموعة جديدة. لهذا العرض التوضيحي، سنستخدم مجموعة بيانات باركيه تسمى بيانات المستخدم.
- إضافة تحويل عمود مشتق. سنستخدم هذا كطريقة لتعيين أسماء المجلدات المطلوبة بشكل ديناميكي.
- إضافة تحويل متلقي.
إخراج المجلد الهرمي
من الشائع جدا استخدام قيم فريدة في البيانات لإنشاء التسلسلات الهرمية للمجلدات لتقسيم البيانات في المستودع. هذه هي الطريقة المثلى جدا لتنظيم ومعالجة البيانات في المستودع وفي Spark (محرك حساب وراء تدفق البيانات). ومع ذلك، سيكون هناك تكلفة أداء صغيرة لتنظيم الإخراج الخاص بك بهذه الطريقة. توقع أن ترى انخفاض صغير في الأداء الإجمالي للمسار باستخدام هذه الآلية في المفرغ.
- ارجع إلى مصمم تدفق البيانات وقم بتحرير تدفق البيانات الذي تم إنشاؤه أعلاه. انقر على تحويل مفرغ.
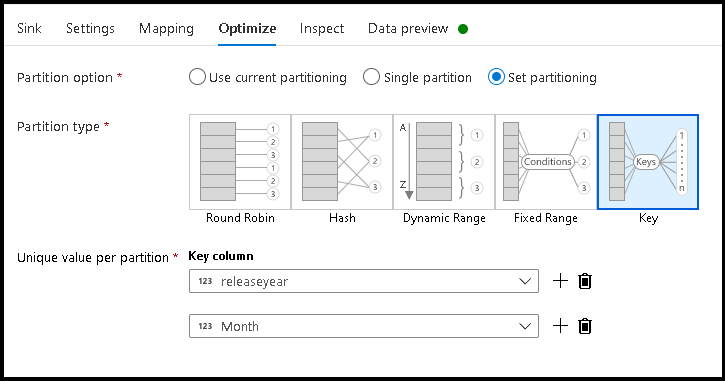
- انقر فوق تحسين > تعيين تقسيم > مفتاح
- اختر العمود (الأعمدة) الذي ترغب في استخدامه لتعيين بنية المجلد الهرمية.
- لاحظ المثال أدناه يستخدم السنة والشهر كأعمدة لتسمية المجلد. ستكون النتائج مجلدات النموذج
releaseyear=1990/month=8. - عند الوصول إلى أقسام البيانات في مصدر تدفق البيانات، سوف تشير إلى المجلد الأعلى مستوى أعلاه فقط
releaseyearوتستخدم نمط حرف بدل لكل مجلد لاحق، على سبيل المثال:**/**/*.parquet - لمعالجة قيم البيانات، أو حتى إذا كنت بحاجة إلى إنشاء قيم تركيبية لأسماء المجلدات، استخدم تحويل العمود المشتق لإنشاء القيم التي ترغب في استخدامها في أسماء المجلدات الخاصة بك.
اسم المجلد كقيم بيانات
تقنية المفرغ ذات الأداء الأفضل قليلاً لبيانات المستودع باستخدام ADLS Gen2 والتي لا تقدم نفس فائدة تقسيم المفتاح/القيمة، هي Name folder as column data. في حين أن نمط تقسيم المفتاح للبنية الهرمية سيسمح لك بمعالجة شرائح البيانات بشكل أسهل، فإن هذه التقنية هي بنية مجلد مبسطة يمكنها كتابة البيانات بشكل أسرع.
- ارجع إلى مصمم تدفق البيانات وقم بتحرير تدفق البيانات الذي تم إنشاؤه أعلاه. انقر على تحويل مفرغ.
- انقر فوق تحسين > تعيين التقسيم > استخدام التقسيم الحالي.
- انقر فوق الإعدادات > اسم المجلد كبيانات عمود.
- اختر العمود الذي ترغب في استخدامه لإنشاء أسماء المجلدات.
- لمعالجة قيم البيانات، أو حتى إذا كنت بحاجة إلى إنشاء قيم تركيبية لأسماء المجلدات، استخدم تحويل العمود المشتق لإنشاء القيم التي ترغب في استخدامها في أسماء المجلدات الخاصة بك.
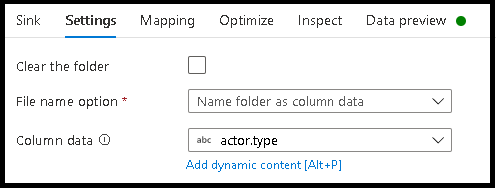
اسم الملف كقيم بيانات
التقنيات المذكورة في البرامج التعليمية المذكورة أعلاه هي حالات الاستخدام الجيد لإنشاء فئات المجلد في مستودع البيانات الخاصة بك. نظام تسمية الملف الافتراضي المستخدمة بواسطة هذه التقنيات هو استخدام معرف المهمة المنفذ Spark. في بعض الأحيان قد ترغب في تعيين اسم ملف الإخراج في مصدر نص تدفق البيانات. يتم اقتراح هذه التقنية فقط للاستخدام مع الملفات الصغيرة. تعد عملية دمج ملفات الأقسام في ملف إخراج واحد عملية طويلة الأمد.
- ارجع إلى مصمم تدفق البيانات وقم بتحرير تدفق البيانات الذي تم إنشاؤه أعلاه. انقر على تحويل مفرغ.
- انقر فوق تحسين > تعيين تقسيم > تقسيم فردي. هذا القسم الفردي هو الذي يخلق ازدحام في عملية التنفيذ حيث يتم دمج الملفات. يوصى بهذا الخيار فقط للملفات الصغيرة.
- انقر فوق الإعدادات > اسم الملف كبيانات عمود.
- اختر العمود الذي ترغب في استخدامه لإنشاء أسماء الملف.
- لمعالجة قيم البيانات، أو حتى إذا كنت بحاجة إلى إنشاء قيم تركيبية لأسماء الملف، استخدم تحويل العمود المشتق لإنشاء القيم التي ترغب في استخدامها في أسماء الملف الخاصة بك.
المحتوى ذو الصلة
تعرف على المزيد حول متلقي تدفق البيانات.