ملاحظة
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تسجيل الدخول أو تغيير الدلائل.
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تغيير الدلائل.
ينطبق على: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
تلميح
جرب Data Factory في Microsoft Fabric، وهو حل تحليلي متكامل للمؤسسات. يغطي Microsoft Fabric كل شيء بدءا من حركة البيانات إلى علم البيانات والتحليلات في الوقت الحقيقي والمعلومات المهنية وإعداد التقارير. تعرف على كيفية بدء إصدار تجريبي جديد مجانا!
تتوفر تدفقات البيانات في كل من مسارات Azure Data Factory وخطوط أنابيب Azure Synapse Analytics. تنطبق هذه المقالة على تعيين تدفقات البيانات. إذا كنت جديدا على التحويلات، فراجع المقالة التمهيدية تحويل البيانات باستخدام تعيين تدفقات البيانات.
بعد الانتهاء من تحويل بياناتك، اكتبها في مخزن وجهة باستخدام تحويل المتلقي. يتطلب كل تدفق بيانات تحويل متلقي واحد على الأقل، ولكن يمكنك الكتابة إلى أكبر عدد ممكن من المتلقين حسب الضرورة لإكمال تدفق التحويل الخاص بك. للكتابة إلى متلقين إضافيين، قم بإنشاء عمليات دفق بيانات جديدة عبر الفروع الجديدة والتقسيمات المشروطة.
يرتبط كل تحويل للمتلقي بعنصر مجموعة بيانات واحد أو خدمة مرتبطة. يحدد تحويل الملتقى شكل وموقع البيانات التي تريد الكتابة إليها.
مجموعات البيانات المضمنة
عندما تقوم بإنشاء تحويل المتلقي، اختر ما إذا كانت معلومات المتلقي الخاصة بك محددة داخل عنصر مجموعة بيانات أو ضمن تحويل المتلقي. تتوفر معظم التنسيقات في تنسيق واحد فقط أو الآخر. لمعرفة كيفية استخدام موصل محدد، راجع مستند الموصل المناسب.
عندما يتم اعتماد تنسيق لكل من العناصر المضمنة وفي عنصر مجموعة البيانات، يكون هناك فوائد لكليهما. عناصر مجموعة البيانات هي عناصر قابلة لإعادة الاستخدام يمكن استخدامها في تدفقات البيانات والأنشطة الأخرى مثل النسخ "Copy". هذه الكيانات القابلة لإعادة الاستخدام مفيدة بشكل خاص عند استخدام مخطط محصَّن. لا تستند مجموعات البيانات إلى "Spark". في بعض الأحيان، قد تحتاج إلى تجاوز إعدادات معينة أو إسقاط مخطط في تحويل المتلقي.
يوصى بمجموعات البيانات المضمنة عند استخدام مخططات مرنة أو مثيلات متلقي غير متكررة أو متلقين ذات معلمات. إذا كان المتلقي الخاص بك ذا معلمات كبيرة، فإن مجموعات البيانات المضمنة لن تسمح لك بإنشاء عنصر "وهمي". تستند مجموعات البيانات المضمنة في "Spark" وخصائصها الأصلية لتدفق البيانات.
لاستخدام مجموعة بيانات مضمنة، حدد التنسيق الذي تريده في محدد نوع المتلقي. بدلاً من تحديد مجموعة بيانات المتلقي، يمكنك تحديد الخدمة المرتبطة التي تريد الاتصال بها.
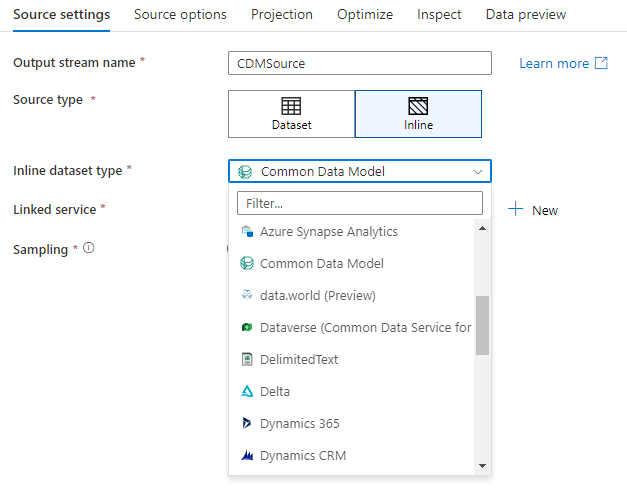
مساحة عمل قاعدة البيانات (مساحات عمل Synapse فقط)
عند استخدام تدفقات البيانات في مساحات عمل Azure Synapse، سيكون لديك خيار إضافي لتخزين بياناتك مباشرةً في نوع قاعدة البيانات الموجود داخل مساحة عمل Synapse الخاصة بك. سيؤدي ذلك إلى تقليل الحاجة إلى إضافة خدمات أو مجموعات بيانات مرتبطة لقواعد البيانات هذه. يمكن أيضا الوصول إلى قواعد البيانات التي تم إنشاؤها من خلال قوالب قاعدة بيانات Azure Synapse عند تحديد Workspace DB.
إشعار
موصل قاعدة بيانات مساحة عمل Azure Synapse قيد المعاينة العامة حالياً ويمكنه العمل فقط مع قواعد بيانات Spark Lake في الوقت الحالي
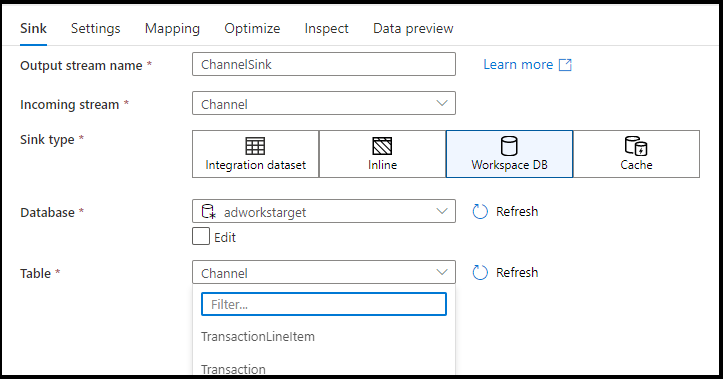
أنواع المتلقي المدعومة
يتبع تعيين تدفق البيانات نهج استخراج وتحميل وتحويل (ELT) ويعمل مع مجموعات بيانات التقسيم المرحلي الموجودة جميعها في Azure. حاليا، يمكن استخدام مجموعات البيانات التالية في تحويل المتلقي.
تلميح
يمكن أن يكون المتلقي الخاص بك تنسيقا مختلفا عن مصدرك. هذه خطوة واحدة من كيفية التحويل من تنسيق إلى آخر. على سبيل المثال، من CSV إلى متلقي Parquet. قد تحتاج إلى إجراء بعض التحويلات في تدفق البيانات بين المصدر والمتلقي حتى يعمل هذا بشكل صحيح. (على سبيل المثال، يحتوي Parquet على متطلبات رأس أكثر تحديدا من CSV.)
| الموصل | تنسيق | مجموعة البيانات/ المضمنة |
|---|---|---|
| مخزن البيانات الثنائية كبيرة الحجم لـ Azure |
أفرو نص Delimited الدلتا JSON ORC باركيه |
✓/✓ ✓/✓ -/✓ ✓/✓ ✓/✓ ✓/✓ |
| قاعدة بيانات Azure Cosmos لـ NoSQL | ✓/- | |
| Azure Data Lake Storage الجيل الأول |
أفرو نص Delimited JSON ORC باركيه |
✓/- ✓/- ✓/- ✓/✓ ✓/- |
| Azure Data Lake Storage Gen2 |
أفرو نموذج البيانات العامة نص Delimited الدلتا JSON ORC باركيه |
✓/✓ -/✓ ✓/✓ -/✓ ✓/✓ ✓/✓ ✓/✓ |
| قاعدة بيانات Azure ل MySQL | ✓/✓ | |
| قاعدة بيانات Azure ل PostgreSQL | ✓/✓ | |
| Azure Data Explorer | ✓/✓ | |
| قاعدة بيانات Azure SQL | ✓/✓ | |
| مثيل Azure SQL المدار | ✓/- | |
| Azure Synapse Analytics | ✓/- | |
| Dataverse | ✓/✓ | |
| Dynamics 365 | ✓/✓ | |
| Dynamics CRM | ✓/✓ | |
| نسيج ليكهاوس | ✓/✓ | |
| SFTP |
أفرو نص Delimited JSON ORC باركيه |
✓/✓ ✓/✓ ✓/✓ ✓/✓ ✓/✓ |
| البلورة الثلجية | ✓/✓ | |
| SQL Server | ✓/✓ |
الإعدادات الخاصة بهذه الموصلات موجودة في علامة التبويب الإعدادات. توجد أمثلة على نصوص تدفق البيانات والمعلومات حول هذه الإعدادات في وثائق الموصلات.
يمكن للخدمة الوصول إلى أكثر من 90 موصلاً أصلياً . لكتابة البيانات إلى تلك المصادر الأخرى من تدفق البيانات الخاص بك، استخدم نشاط النسخ "Copy Activity" لتحميل تلك البيانات من متلقي معتمد.
إعدادات Sink
بعد إضافة المتلقي، قم بالتكوين عبر علامة التبويب المتلقي "Sink". ويمكنك هنا اختيار أو إنشاء مجموعة البيانات التي يكتب المتلقي الخاص بك إليها. يمكن تكوين قيم التطوير لمعلمات مجموعة البيانات في إعدادات تتبع الأخطاء "Debug settings". (يجب تشغيل وضع تتبع الأخطاء.)
يوضح الفيديو التالي عدداً من خيارات المتلقي المختلفة لأنواع الملفات المحددة بالنص.
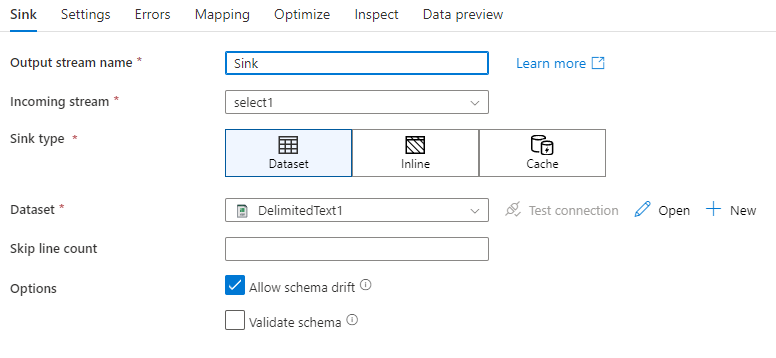
انحراف المخطط: انحراف المخطط هو قدرة الخدمة على التعامل بشكل أصلي مع المخططات المرنة في تدفقات البيانات الخاصة بك دون الحاجة إلى تحديد تغيير حالة العمود بشكل صريح. قم بتمكين السماح بانحراف المخطط لكتابة أعمدة إضافية فوق ما تم تعريفه في مخطط بيانات المتلقي.
التحقق من صحة المخطط: إذا تم تحديد "التحقق من صحة المخطط"، فسيفشل تدفق البيانات إذا لم يتم العثور على أي عمود في إسقاط المتلقي في مخزن المتلقي أو إذا لم تتطابق أنواع البيانات. استخدم هذا الإعداد لفرض توافق مخطط المتلقي مع اتفاق الإسقاط المحدد الخاص بك. من المفيد في سيناريوهات متلقي قاعدة البيانات الإشارة إلى تغيير أسماء الأعمدة أو أنواعها.
متلقي ذاكرة التخزين المؤقت
يحدث متلقي ذاكرة التخزين المؤقت عندما يقوم تدفق البيانات بإدخال البيانات في ذاكرة التخزين المؤقت لـ Spark بدلاً من مخزن البيانات. عند تعيين تدفقات البيانات، يمكنك الرجوع إلى هذه البيانات في نفس التدفق عدة مرات باستخدام البحث في ذاكرة التخزين المؤقت. يكون هذا مفيداً عندما تريد الإشارة إلى البيانات كجزء من تعبير ولكن لا تريد ضم الأعمدة إليه بشكل صريح. من الأمثلة الشائعة التي قد يكون فيها متلقي ذاكرة التخزين المؤقت مفيداً هي البحث عن قيمة قصوى في مخزن بيانات ومطابقة رموز الخطأ بقاعدة بيانات رسائل الخطأ.
للكتابة إلى متلقي ذاكرة التخزين المؤقت، أضف تحويل متلقي وحدد ذاكرة التخزين المؤقت "Cache" كنوع المتلقي. وبخلاف أنواع المتلقي الأخرى، لا تحتاج إلى تحديد مجموعة بيانات أو خدمة مرتبطة لأنك لا تكتب إلى مخزن خارجي.
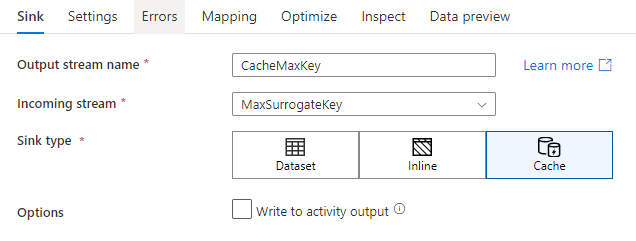
في إعدادات المتلقي، يمكنك اختيارياً تحديد الأعمدة الرئيسية لمتلقي ذاكرة التخزين المؤقت. حيث يتم استخدامها كشروط مطابقة عند استخدام الدالة lookup() عند البحث في ذاكرة التخزين المؤقت. إذا قمت بتحديد الأعمدة الرئيسية، فلا يمكنك استخدام الدالة outputs() عند البحث في ذاكرة التخزين المؤقت. لمعرفة المزيد حول بنية البحث في ذاكرة التخزين المؤقت، راجع عمليات البحث المخزنة مؤقتاً.
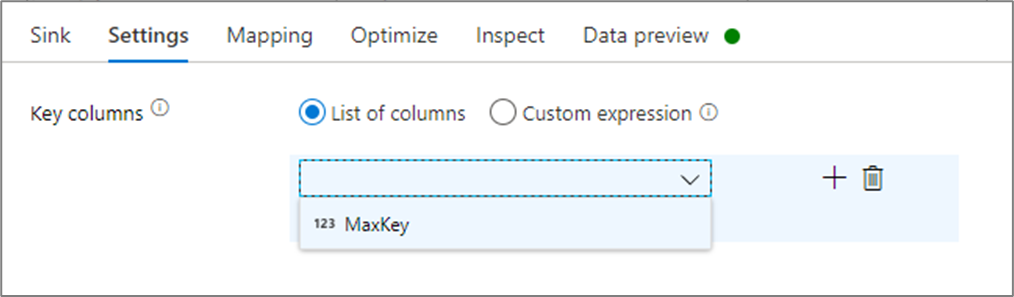
على سبيل المثال، إذا قمت بتحديد عمود رئيسي واحد لـ column1 في متلقي ذاكرة التخزين المؤقت يسمى cacheExample، فإن الاتصال بـ cacheExample#lookup() ستكون له معلمة واحدة تحدد أي صف في متلقي ذاكرة التخزين المؤقت سيتم التطابق معه. تقوم الدالة بإخراج عمود واحد معقد مع أعمدة فرعية لكل عمود يتم تعيينه.
إشعار
يجب أن يكون متلقي ذاكرة التخزين المؤقت في دفق بيانات مستقل تماماً عن أي تحويل يشير إليه عبر أي بحث في ذاكرة التخزين المؤقت. يجب أن يكون متلقي التخزين المؤقت هو أول متلقي مكتوب.
الكتابة إلى إخراج النشاط
يمكن لمتلقي ذاكرة التخزين المؤقت كتابة بياناته اختياريا إلى إخراج نشاط تدفق البيانات الذي يمكن استخدامه بعد ذلك كمدخل لنشاط آخر في البنية الأساسية لبرنامج ربط العمليات التجارية. سيسمح لك ذلك بتمرير البيانات بسرعة وسهولة من نشاط تدفق البيانات الخاص بك دون الحاجة إلى الاحتفاظ بالبيانات في مخزن البيانات.
لاحظ أن الإخراج من تدفق البيانات الذي يتم إدخاله مباشرة في البنية الأساسية لبرنامج ربط العمليات التجارية الخاصة بك يقتصر على 2 ميغابايت. وبالتالي، سيحاول تدفق البيانات إضافة إلى إخراج أكبر عدد ممكن من الصفوف أثناء البقاء ضمن الحد الأقصى 2 ميغابايت، وبالتالي قد لا ترى في بعض الأحيان جميع الصفوف في إخراج النشاط. يساعدك تعيين "الصف الأول فقط" على مستوى نشاط تدفق البيانات أيضا على الحد من إخراج البيانات من تدفق البيانات إذا لزم الأمر.
أسلوب التحديث
بالنسبة إلى أنواع متلقي قاعدة البيانات، ستتضمن علامة التبويب الإعدادات خاصية "أسلوب التحديث". الإعداد الافتراضي هو إدراج ولكنه يتضمن أيضا خيارات خانة الاختيار للتحديث و upsert وحذف. للاستفادة من هذه الخيارات الإضافية، ستحتاج إلى إضافة تحويل Alter Row قبل المتلقي. سيسمح لك Alter Row بتحديد شروط كل إجراء من إجراءات قاعدة البيانات. إذا كان المصدر الخاص بك هو مصدر تمكين CDC أصلي، فيمكنك تعيين أساليب التحديث دون Alter Row لأن ADF على دراية بالفعل بعلامات الصفوف لإدراجها وتحديثها وتصغيرها وحذفها.
تعيين الحقول
على غرار تحويل التحديد، في علامة التبويب تعيين "Mapping" في المتلقي، يمكنك أن تحدد الأعمدة الواردة التي ستتم كتابتها. بشكل افتراضي، يتم تعيين جميع أعمدة الإدخال، بما في ذلك الأعمدة المنحرفة. يُعرف هذا السلوك باسم التعيين التلقائي (automapping).
عند إيقاف تشغيل التعيين التلقائي، يمكنك إضافة التعيينات المستندة إلى الأعمدة الثابتة أو التعيينات المستندة إلى القواعد. باستخدام التعيينات المستندة إلى القواعد، يمكنك كتابة تعبيرات بمطابقة النمط. يعين التعيين الثابت أسماء الأعمدة المنطقية والفعلية. لمزيد من المعلومات حول التعيين المستند إلى القواعد، راجع أنماط الأعمدة في تعيين تدفق البيانات.
ترتيب المتلقين المخصصين
بشكل افتراضي، تتم كتابة البيانات إلى عدة متلقين بترتيب غير محدد. يكتب محرك التنفيذ البيانات بالتزامن مع اكتمال منطق التحويل، وقد يختلف ترتيب المتلقين في كل عملية تشغيل. لتحديد ترتيب دقيق للمتلقين، قم بتمكين ترتيب المتلقين المخصصين في علامة التبويب عام (General) الخاصة بتدفق البيانات. عند التمكين، تتم كتابة المتلقين بشكل تسلسلي بترتيب تصاعدي.
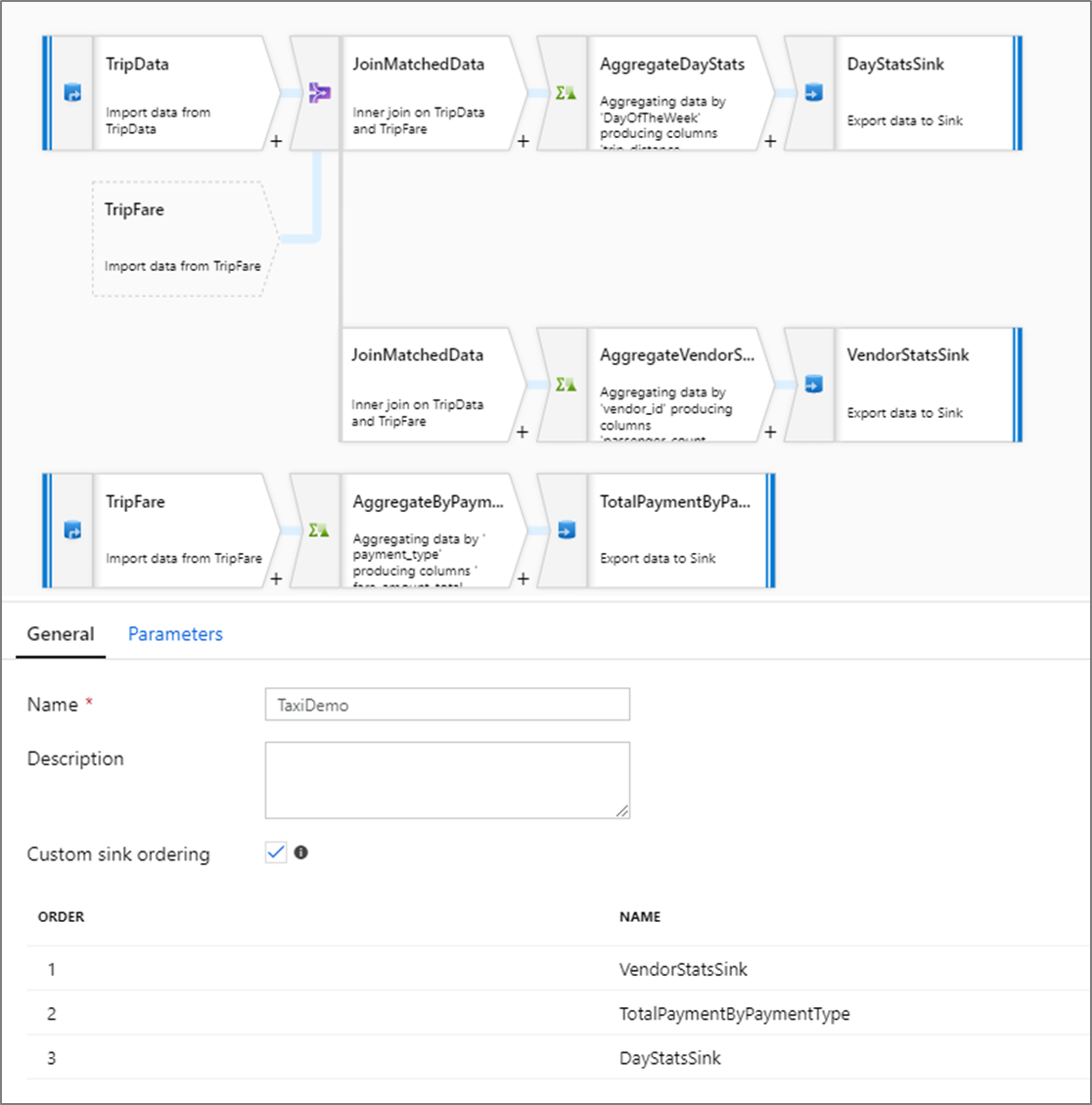
إشعار
عند استخدام عمليات البحث المخزنة مؤقتاً، تأكد من تعيين المتلقين المخزنين مؤقتاً في ترتيب المتلقين الخاصين بك على 1، أدنى رقم (أو أول رقم) في الترتيب.
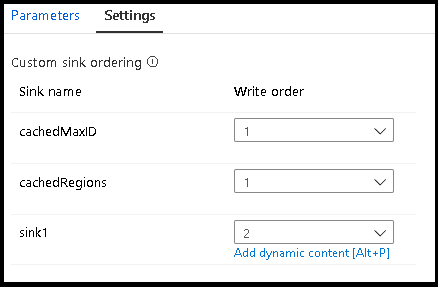
مجموعات المتلقين
يمكنك تجميع المتلقين معاً عن طريق تطبيق نفس رقم الطلب لسلسلة من المتلقين. ستتعامل الخدمة مع أولئك المتلقين على أنهم مجموعات يمكن أن تُنفَّذ بالتزامن. ستظهر خيارات التنفيذ المتزامن في نشاط تدفق بيانات التدفقات.
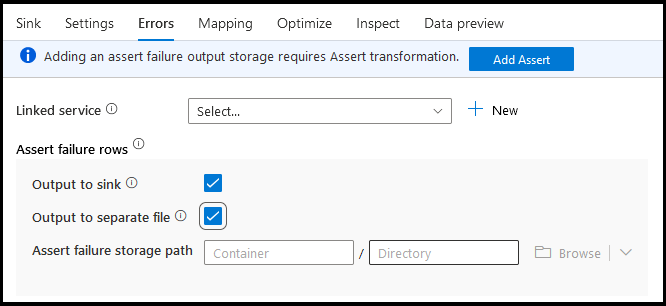
اخطاء
في علامة التبويب أخطاء المتلقي يمكنك تكوين معالجة صف الخطأ لالتقاط إخراج وإعادة توجيهه لأخطاء برنامج تشغيل قاعدة البيانات والتأكيدات الفاشلة.
عند الكتابة إلى قواعد البيانات، قد تفشل صفوف معينة من البيانات بسبب القيود التي تضعها الوجهة. بشكل افتراضي، سيفشل تشغيل تدفق البيانات عند حدوث أول خطأ. في بعض الموصلات، يمكنك اختيار المتابعة مع وجود الخطأ وسيسمح ذلك بتدفق البيانات حتى إذا كانت هناك أخطاء في صفوف فردية. في الوقت الحالي، لا تتوفر هذه الإمكانية إلا في قاعدة بيانات Azure SQL وAzure Synapse. لمزيد من المعلومات، راجع معالجة صف الخطأ في Azure SQL DB.
يوجد أدناه فيديو تعليمي حول كيفية استخدام معالجة صف خطأ قاعدة البيانات تلقائياً في تحويل المتلقي.
بالنسبة لتأكيد صفوف الفشل، يمكنك استخدام تأكيد التحويل المصدر في تدفق البيانات ثم إعادة توجيه التأكيدات الفاشلة إلى ملف الإخراج هنا في علامة تبويب أخطاء المتلقي. لديك أيضًا خيار هنا لتجاهل الصفوف التي بها فشل التأكيد وعدم إخراج هذه الصفوف على الإطلاق إلى مخزن بيانات وجهة المتلقي.
معاينة البيانات في المتلقي
عند إحضار معاينة البيانات في وضع تتبع الأخطاء، لن تتم كتابة أي بيانات في المتلقي الخاص بك. سيتم إرجاع لقطة للشكل الذي تبدو عليه البيانات، ولكن لن تتم كتابة أي شيء في وجهتك. لاختبار كتابة البيانات في المتلقي الخاص بك، قم بتشغيل تتبع أخطاء التدفقات من لوحة التدفقات.
البرنامج النصي لتدفق البيانات
مثال
يوجد أدناه مثال على تحويل المتلقي ونص تدفق البيانات الخاص به:
sink(input(
movie as integer,
title as string,
genres as string,
year as integer,
Rating as integer
),
allowSchemaDrift: true,
validateSchema: false,
deletable:false,
insertable:false,
updateable:true,
upsertable:false,
keys:['movie'],
format: 'table',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true,
saveOrder: 1,
errorHandlingOption: 'stopOnFirstError') ~> sink1
المحتوى ذو الصلة
الآن بعد أن أنشأت تدفق البيانات الخاص بك، أضف نشاط تدفق البيانات إلى التدفقات الخاصة بك.