نموذج MLflow القديم الذي يخدم على Azure Databricks
هام
- تم إيقاف هذه الوثائق وقد لا يتم تحديثها. لم تعد المنتجات أو الخدمات أو التقنيات المذكورة في هذا المحتوى مدعومة.
- الإرشادات الواردة في هذه المقالة مخصصة لخدمة نموذج MLflow القديمة. توصي Databricks بترحيل مهام سير عمل خدمة النموذج إلى خدمة النموذج لنشر نقطة نهاية النموذج المحسنة وقابلية التوسع. لمزيد من المعلومات، راجع خدمة النموذج مع Azure Databricks.
تتيح لك خدمة نموذج MLflow القديم استضافة نماذج التعلم الآلي من Model Registry كنقاط نهاية REST يتم تحديثها تلقائيا استنادا إلى توفر إصدارات النموذج ومراحلها. يستخدم نظام مجموعة عقدة واحدة يعمل ضمن حسابك الخاص ضمن ما يسمى الآن بوحدة الحوسبة الكلاسيكية. تتضمن وحدة الحوسبة هذه الشبكة الظاهرية وموارد الحوسبة المرتبطة بها مثل مجموعات دفاتر الملاحظات والوظائف ومستودعات SQL الاحترافية والكلاسيكية والنموذج القديم الذي يخدم نقاط النهاية.
عند تمكين خدمة النموذج لنموذج مسجل معين، يقوم Azure Databricks تلقائيا بإنشاء مجموعة فريدة للنموذج ونشر جميع الإصدارات غير المؤرشفة من النموذج على تلك المجموعة. يعيد Azure Databricks تشغيل نظام المجموعة إذا حدث خطأ وينهي المجموعة عند تعطيل خدمة النموذج للنموذج. تتم مزامنة خدمة النموذج تلقائيا مع Model Registry وتنشر أي إصدارات نموذج مسجلة جديدة. يمكن الاستعلام عن إصدارات النموذج المنشورة بطلب REST API قياسي. يقوم Azure Databricks بمصادقة الطلبات إلى النموذج باستخدام المصادقة القياسية الخاصة به.
بينما تكون هذه الخدمة قيد المعاينة، توصي Databricks باستخدامها للتطبيقات منخفضة الإنتاجية وغير الحرجة. معدل النقل المستهدف هو 200 qps والتوافر المستهدف هو 99.5٪، على الرغم من عدم تقديم أي ضمان لأي منهما. بالإضافة إلى ذلك، هناك حد لحجم الحمولة يبلغ 16 ميغابايت لكل طلب.
يتم نشر كل إصدار نموذج باستخدام نشر نموذج MLflow ويتم تشغيله في بيئة Conda المحددة بواسطة تبعياته.
إشعار
- يتم الاحتفاظ بالمجموعة طالما تم تمكين الخدمة، حتى إذا لم يكن هناك إصدار نموذج نشط. لإنهاء مجموعة الخدمة، قم بتعطيل خدمة النموذج للنموذج المسجل.
- يعتبر نظام المجموعة مجموعة لجميع الأغراض، تخضع لتسعير حمل العمل لجميع الأغراض.
- لا يتم تشغيل البرامج النصية العالمية init على مجموعات خدمة النموذج.
هام
تحديث Anaconda Inc. لشروط الخدمة الخاصة بهم لقنوات anaconda.org. بناء على شروط الخدمة الجديدة، قد تحتاج إلى ترخيص تجاري إذا كنت تعتمد على حزم وتوزيع Anaconda. راجع الأسئلة المتداولة حول Anaconda Commercial Edition لمزيد من المعلومات. يخضع استخدامك لأي قنوات Anaconda لشروط الخدمة الخاصة بها.
تم تسجيل نماذج MLflow التي تم تسجيلها قبل الإصدار 1.18 (Databricks Runtime 8.3 ML أو إصدار سابق) بشكل افتراضي باستخدام قناة conda defaults (https://repo.anaconda.com/pkgs/) كتبعية. وبسبب تغيير الترخيص هذا، أوقف Databricks استخدام القناة defaults للنماذج التي تم تسجيلها باستخدام MLflow v1.18 وما فوق. القناة الافتراضية المسجلة هي الآن conda-forge، والتي تشير إلى المجتمع المدار https://conda-forge.org/.
إذا قمت بتسجيل نموذج قبل MLflow v1.18 دون استبعاد defaults القناة من بيئة conda للنموذج، فقد يكون لهذا النموذج تبعية على القناة defaults التي قد لا تكون قد قصدتها.
لتأكيد ما إذا كان النموذج يحتوي على هذه التبعية يدويا، يمكنك فحص channel القيمة في conda.yaml الملف الذي تم حزمه مع النموذج المسجل. على سبيل المثال، قد يبدو النموذج conda.yaml مع defaults تبعية القناة كما يلي:
channels:
- defaults
dependencies:
- python=3.8.8
- pip
- pip:
- mlflow
- scikit-learn==0.23.2
- cloudpickle==1.6.0
name: mlflow-env
نظرا لأن Databricks لا يمكنها تحديد ما إذا كان استخدامك لمستودع Anaconda للتفاعل مع نماذجك مسموحا به في إطار علاقتك ب Anaconda، فإن Databricks لا يجبر عملائها على إجراء أي تغييرات. إذا كان استخدامك Anaconda.com repo من خلال استخدام Databricks مسموحا به بموجب شروط Anaconda، فلن تحتاج إلى اتخاذ أي إجراء.
إذا كنت ترغب في تغيير القناة المستخدمة في بيئة النموذج، يمكنك إعادة تسجيل النموذج في سجل النموذج باستخدام جديد conda.yaml. يمكنك القيام بذلك عن طريق تحديد القناة في معلمة conda_envlog_model().
لمزيد من المعلومات حول log_model() واجهة برمجة التطبيقات، راجع وثائق MLflow لنكهة النموذج التي تعمل معها، على سبيل المثال، log_model ل scikit-learn.
لمزيد من المعلومات حول conda.yaml الملفات، راجع وثائق MLflow.
المتطلبات
- تتوفر خدمة نموذج MLflow القديمة لنماذج Python MLflow. يجب الإعلان عن كافة تبعيات النموذج في بيئة conda. راجع تبعيات نموذج السجل.
- لتمكين خدمة النموذج، يجب أن يكون لديك إذن إنشاء نظام المجموعة.
خدمة النموذج من Model Registry
تتوفر خدمة النموذج في Azure Databricks من Model Registry.
تمكين خدمة النموذج وتعطيلها
يمكنك تمكين نموذج لخدمة من صفحة النموذج المسجل.
انقر فوق علامة التبويب تقديم. إذا لم يتم تمكين النموذج بالفعل للتقم، يظهر الزر Enable Serving.
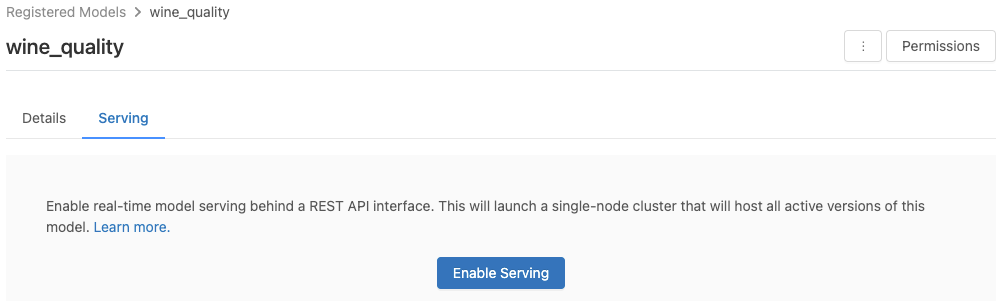
انقر فوق تمكين التقديم. تظهر علامة التبويب تقديم مع الحالة المعروضة على أنها معلق. بعد بضع دقائق، تتغير الحالة إلى جاهز.
لتعطيل نموذج لخدمة، انقر فوق إيقاف.
التحقق من صحة خدمة النموذج
من علامة التبويب تقديم، يمكنك إرسال طلب إلى النموذج المقدم وعرض الاستجابة.
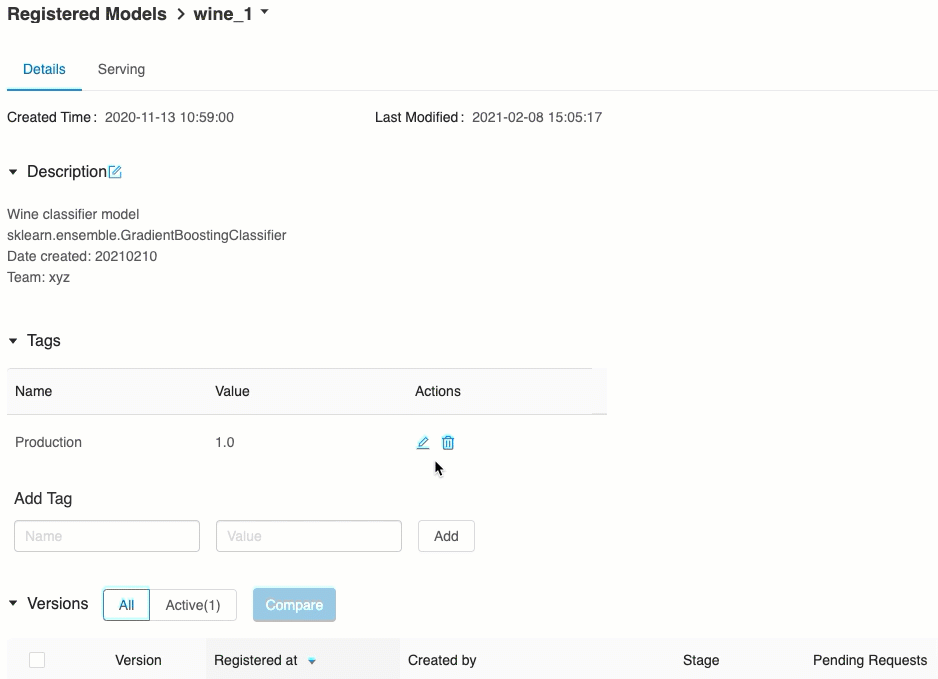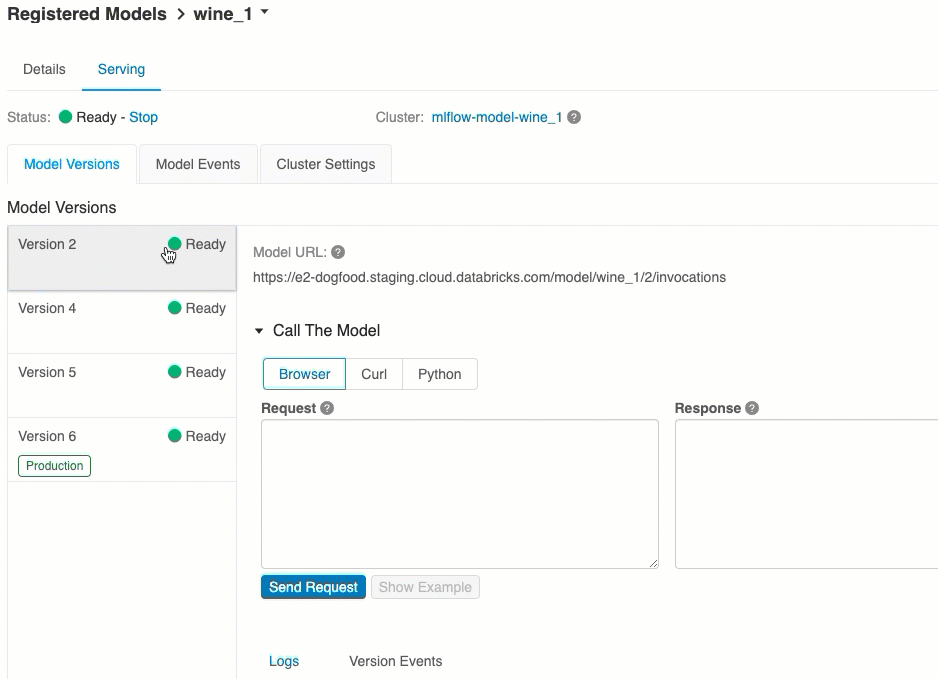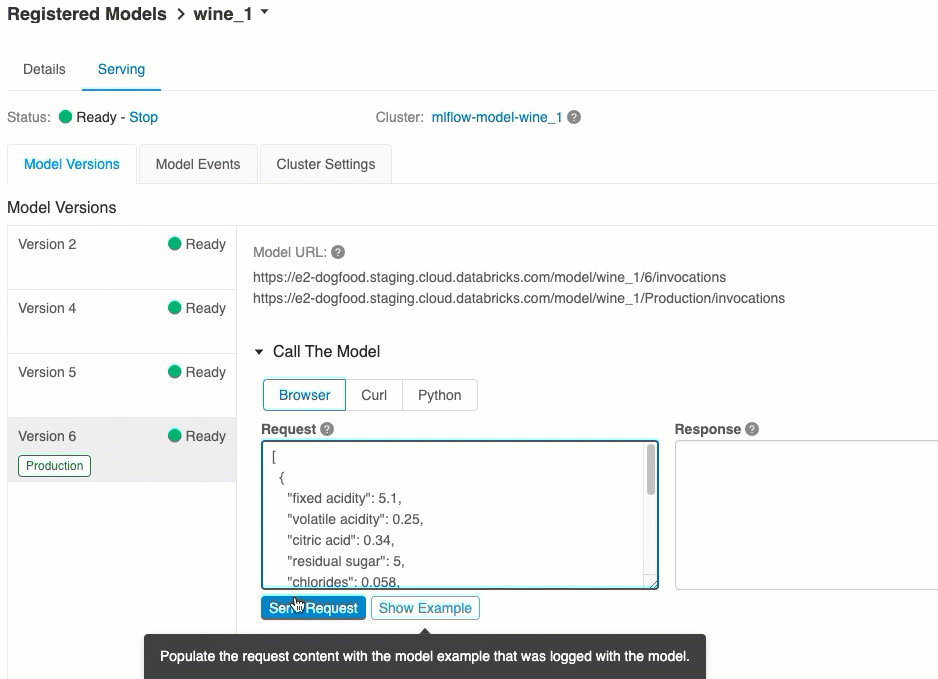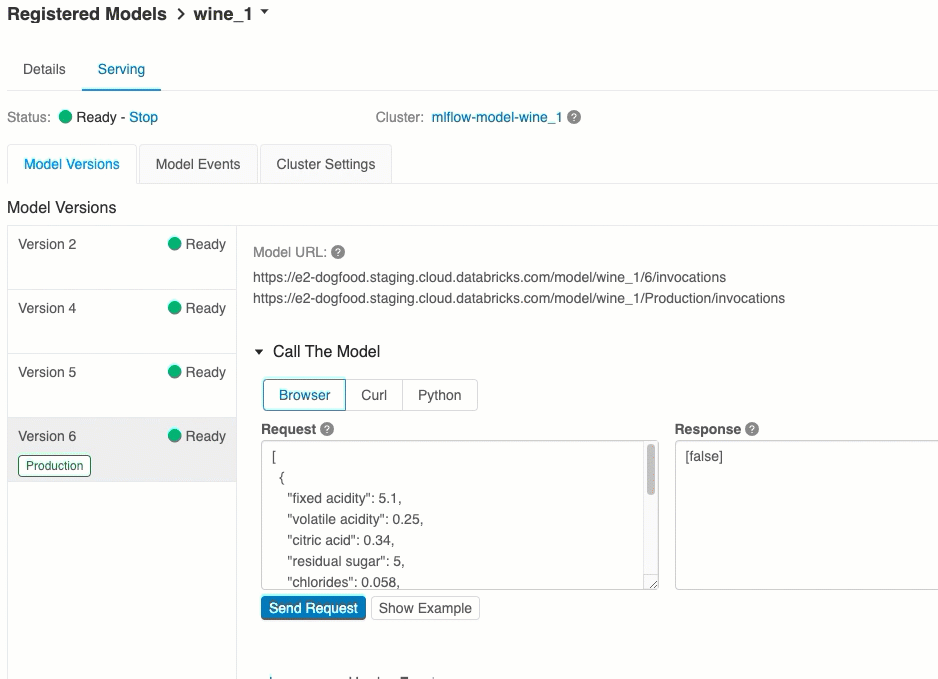
معرفات URI لإصدار النموذج
يتم تعيين واحد أو عدة عناوين URL فريدة لكل إصدار من إصدارات النموذج المنشور. كحد أدنى، يتم تعيين URI لكل إصدار نموذج تم إنشاؤه على النحو التالي:
<databricks-instance>/model/<registered-model-name>/<model-version>/invocations
على سبيل المثال، لاستدعاء الإصدار 1 من نموذج مسجل ك iris-classifier، استخدم URI هذا:
https://<databricks-instance>/model/iris-classifier/1/invocations
يمكنك أيضا استدعاء إصدار نموذج حسب مرحلته. على سبيل المثال، إذا كان الإصدار 1 في مرحلة الإنتاج ، يمكن أيضا تسجيله باستخدام URI هذا:
https://<databricks-instance>/model/iris-classifier/Production/invocations
تظهر قائمة معرفات URI للنموذج المتوفرة في أعلى علامة التبويب Model Versions في صفحة العرض.
إدارة الإصدارات المقدمة
يتم نشر جميع إصدارات النموذج النشطة (غير المؤرشفة)، ويمكنك الاستعلام عنها باستخدام معرفات URI. ينشر Azure Databricks إصدارات نموذج جديدة تلقائيا عند تسجيلها، ويزيل تلقائيا الإصدارات القديمة عند أرشفتها.
إشعار
تشترك جميع الإصدارات المنشورة من نموذج مسجل في نفس المجموعة.
إدارة حقوق الوصول إلى النموذج
يتم توريث حقوق الوصول إلى النموذج من تسجيل النموذج. يتطلب تمكين ميزة الخدمة أو تعطيلها إذن "إدارة" على النموذج المسجل. يمكن لأي شخص لديه حقوق قراءة تسجيل أي من الإصدارات المنشورة.
تسجيل إصدارات النموذج المنشورة
لتسجيل نموذج تم نشره، يمكنك استخدام واجهة المستخدم أو إرسال طلب واجهة برمجة تطبيقات REST إلى عنوان URI للنموذج.
النتيجة عبر واجهة المستخدم
هذه هي أسهل وأسرع طريقة لاختبار النموذج. يمكنك إدراج بيانات إدخال النموذج بتنسيق JSON والنقر فوق إرسال طلب. إذا تم تسجيل النموذج باستخدام مثال إدخال (كما هو موضح في الرسم أعلاه)، فانقر فوق تحميل مثال لتحميل مثال الإدخال.
النتيجة عبر طلب واجهة برمجة تطبيقات REST
يمكنك إرسال طلب تسجيل من خلال واجهة برمجة تطبيقات REST باستخدام مصادقة Databricks القياسية. توضح الأمثلة أدناه المصادقة باستخدام رمز مميز للوصول الشخصي مع MLflow 1.x.
إشعار
كأفضل ممارسة أمان، عند المصادقة باستخدام الأدوات والأنظمة والبرامج النصية والتطبيقات التلقائية، توصي Databricks باستخدام رموز الوصول الشخصية التي تنتمي إلى كيانات الخدمة بدلا من مستخدمي مساحة العمل. لإنشاء رموز مميزة لكيانات الخدمة، راجع إدارة الرموز المميزة لكيان الخدمة.
بالنظر إلى MODEL_VERSION_URI مثل https://<databricks-instance>/model/iris-classifier/Production/invocations (حيث <databricks-instance> هو اسم مثيل Databricks الخاص بك) ورمز Databricks REST API المميز المسمى DATABRICKS_API_TOKEN، توضح الأمثلة التالية كيفية الاستعلام عن نموذج تم تقديمه:
تعكس الأمثلة التالية تنسيق تسجيل النقاط للنماذج التي تم إنشاؤها باستخدام MLflow 1.x. إذا كنت تفضل استخدام MLflow 2.0، فستحتاج إلى تحديث تنسيق حمولة الطلب.
Bash
قصاصة برمجية للاستعلام عن نموذج يقبل مدخلات إطار البيانات.
curl -X POST -u token:$DATABRICKS_API_TOKEN $MODEL_VERSION_URI \
-H 'Content-Type: application/json' \
-d '[
{
"sepal_length": 5.1,
"sepal_width": 3.5,
"petal_length": 1.4,
"petal_width": 0.2
}
]'
قصاصة برمجية للاستعلام عن نموذج يقبل مدخلات tensor. يجب تنسيق مدخلات Tensor كما هو موضح في مستندات واجهة برمجة تطبيقات TensorFlow Serving.
curl -X POST -u token:$DATABRICKS_API_TOKEN $MODEL_VERSION_URI \
-H 'Content-Type: application/json' \
-d '{"inputs": [[5.1, 3.5, 1.4, 0.2]]}'
Python
import numpy as np
import pandas as pd
import requests
def create_tf_serving_json(data):
return {'inputs': {name: data[name].tolist() for name in data.keys()} if isinstance(data, dict) else data.tolist()}
def score_model(model_uri, databricks_token, data):
headers = {
"Authorization": f"Bearer {databricks_token}",
"Content-Type": "application/json",
}
data_json = data.to_dict(orient='records') if isinstance(data, pd.DataFrame) else create_tf_serving_json(data)
response = requests.request(method='POST', headers=headers, url=model_uri, json=data_json)
if response.status_code != 200:
raise Exception(f"Request failed with status {response.status_code}, {response.text}")
return response.json()
# Scoring a model that accepts pandas DataFrames
data = pd.DataFrame([{
"sepal_length": 5.1,
"sepal_width": 3.5,
"petal_length": 1.4,
"petal_width": 0.2
}])
score_model(MODEL_VERSION_URI, DATABRICKS_API_TOKEN, data)
# Scoring a model that accepts tensors
data = np.asarray([[5.1, 3.5, 1.4, 0.2]])
score_model(MODEL_VERSION_URI, DATABRICKS_API_TOKEN, data)
Powerbi
يمكنك تسجيل مجموعة بيانات في Power BI Desktop باستخدام الخطوات التالية:
افتح مجموعة البيانات التي تريد تسجيلها.
انتقل إلى Transform Data.
انقر بزر الماوس الأيمن في اللوحة اليسرى وحدد إنشاء استعلام جديد.
انتقل إلى عرض > المحرر المتقدم.
استبدل نص الاستعلام بمقتطف التعليمات البرمجية أدناه، بعد ملء مناسب
DATABRICKS_API_TOKENوMODEL_VERSION_URI.(dataset as table ) as table => let call_predict = (dataset as table ) as list => let apiToken = DATABRICKS_API_TOKEN, modelUri = MODEL_VERSION_URI, responseList = Json.Document(Web.Contents(modelUri, [ Headers = [ #"Content-Type" = "application/json", #"Authorization" = Text.Format("Bearer #{0}", {apiToken}) ], Content = Json.FromValue(dataset) ] )) in responseList, predictionList = List.Combine(List.Transform(Table.Split(dataset, 256), (x) => call_predict(x))), predictionsTable = Table.FromList(predictionList, (x) => {x}, {"Prediction"}), datasetWithPrediction = Table.Join( Table.AddIndexColumn(predictionsTable, "index"), "index", Table.AddIndexColumn(dataset, "index"), "index") in datasetWithPredictionقم بتسمية الاستعلام باسم النموذج المطلوب.
افتح محرر الاستعلام المتقدم لمجموعة البيانات الخاصة بك وقم بتطبيق دالة النموذج.
مراقبة النماذج المقدمة
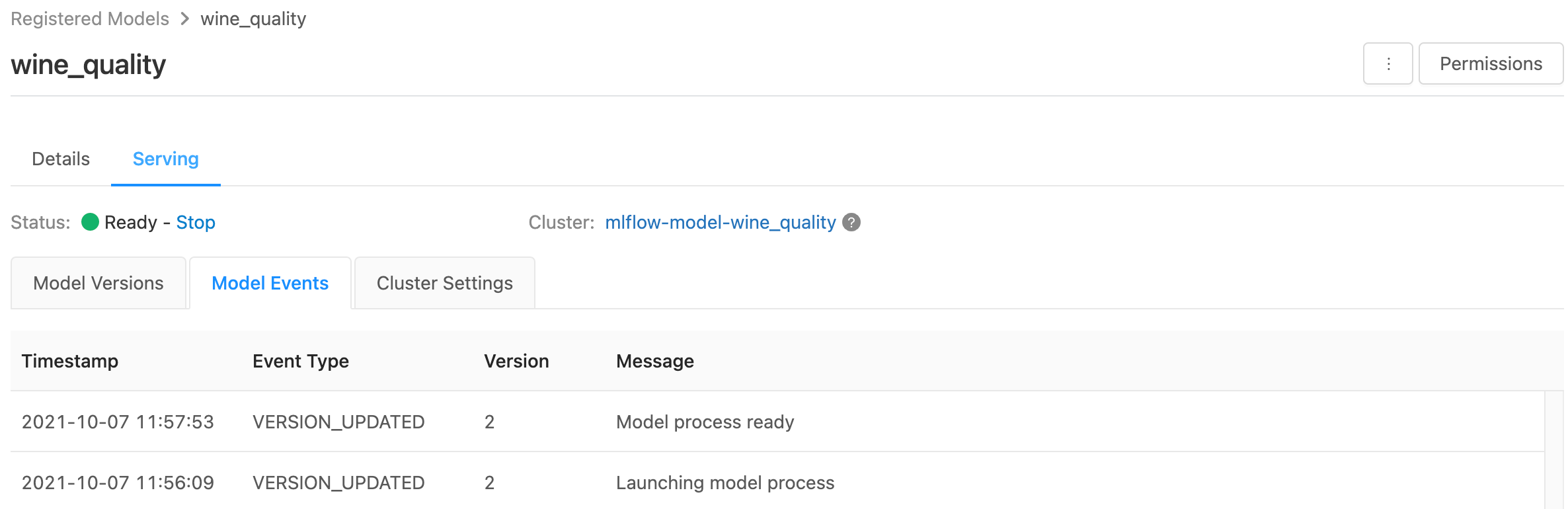
تعرض صفحة العرض مؤشرات الحالة لنظام مجموعة العرض بالإضافة إلى إصدارات النموذج الفردية.
- لفحص حالة نظام مجموعة العرض، استخدم علامة التبويب Model Events ، التي تعرض قائمة بجميع أحداث العرض لهذا النموذج.
- لفحص حالة إصدار نموذج واحد، انقر فوق علامة التبويب Model Versions وقم بالتمرير لعرض علامتي التبويب Logs أو Version Events .
تخصيص نظام مجموعة الخدمة
لتخصيص نظام مجموعة العرض، استخدم علامة التبويب cluster الإعدادات في علامة التبويب تقديم .
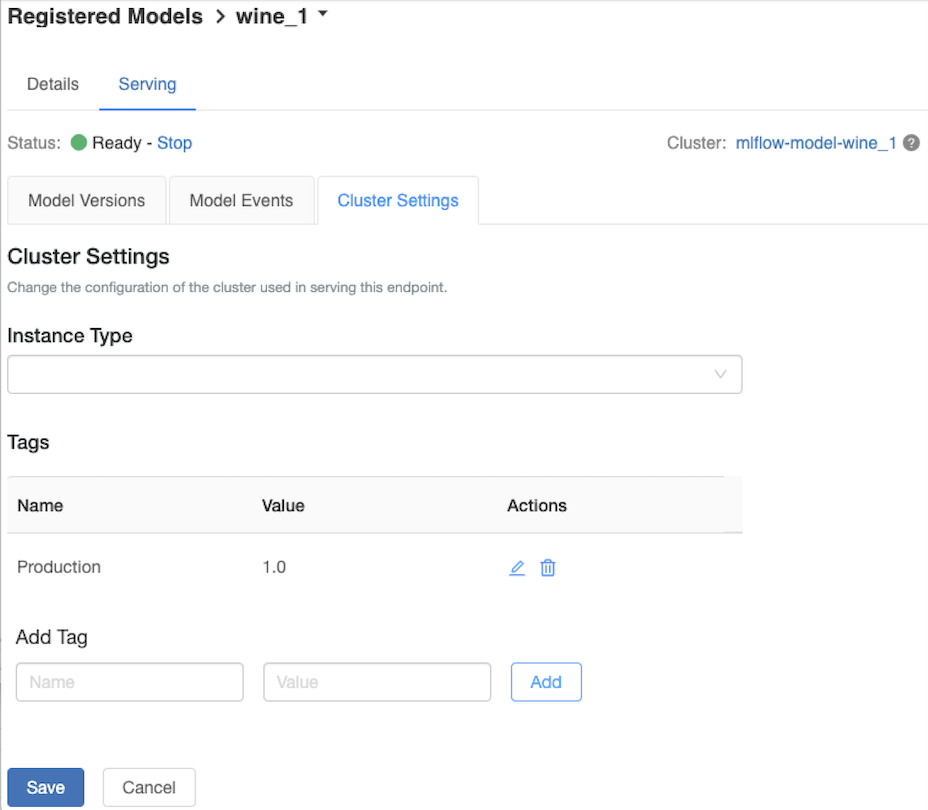
- لتعديل حجم الذاكرة وعدد الذاكرات الأساسية لنظام مجموعة خدمة، استخدم القائمة المنسدلة نوع المثيل لتحديد تكوين نظام المجموعة المطلوب. عند النقر فوق حفظ، يتم إنهاء المجموعة الموجودة ويتم إنشاء مجموعة جديدة بالإعدادات المحددة.
- لإضافة علامة، اكتب الاسم والقيمة في حقول إضافة علامة وانقر فوق إضافة.
- لتحرير علامة موجودة أو حذفها، انقر فوق أحد الأيقونات في عمود الإجراءات في جدول العلامات.
تكامل مخزن الميزات
يمكن لخدمة النموذج القديم البحث تلقائيا عن قيم الميزات من المتاجر المنشورة عبر الإنترنت.
.. اوس:
Databricks Legacy MLflow Model Serving supports automatic feature lookup from these online stores:
- Amazon DynamoDB (v0.3.8 and above)
- Amazon Aurora (MySQL-compatible)
- Amazon RDS MySQL
.. azure::
Databricks Legacy MLflow Model Serving supports automatic feature lookup from these online stores:
- Azure Cosmos DB (v0.5.0 and above)
- Azure Database for MySQL
الأخطاء المعروفة
ResolvePackageNotFound: pyspark=3.1.0
يمكن أن يحدث هذا الخطأ إذا كان النموذج يعتمد على pyspark ويتم تسجيله باستخدام Databricks Runtime 8.x.
إذا رأيت هذا الخطأ، فحدد pyspark الإصدار بشكل صريح عند تسجيل النموذج، باستخدام المعلمةconda_env.
Unrecognized content type parameters: format
يمكن أن يحدث هذا الخطأ نتيجة لتنسيق بروتوكول تسجيل MLflow 2.0 الجديد. إذا كنت ترى هذا الخطأ، من المحتمل أنك تستخدم تنسيق طلب تسجيل قديم. لحل الخطأ، يمكنك:
تحديث تنسيق طلب تسجيل النقاط إلى أحدث بروتوكول.
إشعار
تعكس الأمثلة التالية تنسيق تسجيل النقاط المقدم في MLflow 2.0. إذا كنت تفضل استخدام MLflow 1.x، يمكنك تعديل
log_model()استدعاءات واجهة برمجة التطبيقات لتضمين تبعية إصدار MLflow المطلوبة في المعلمةextra_pip_requirements. يضمن القيام بذلك استخدام تنسيق تسجيل النقاط المناسب.mlflow.<flavor>.log_model(..., extra_pip_requirements=["mlflow==1.*"])Bash
الاستعلام عن نموذج يقبل مدخلات إطار بيانات pandas.
curl -X POST -u token:$DATABRICKS_API_TOKEN $MODEL_VERSION_URI \ -H 'Content-Type: application/json' \ -d '{ "dataframe_records": [{"sepal_length (cm)": 5.1, "sepal_width (cm)": 3.5, "petal_length (cm)": 1.4, "petal_width": 0.2}, {"sepal_length (cm)": 4.2, "sepal_width (cm)": 5.0, "petal_length (cm)": 0.8, "petal_width": 0.5}] }'الاستعلام عن نموذج يقبل مدخلات tensor. يجب تنسيق مدخلات Tensor كما هو موضح في مستندات واجهة برمجة تطبيقات TensorFlow Serving.
curl -X POST -u token:$DATABRICKS_API_TOKEN $MODEL_VERSION_URI \ -H 'Content-Type: application/json' \ -d '{"inputs": [[5.1, 3.5, 1.4, 0.2]]}'Python
import numpy as np import pandas as pd import requests def create_tf_serving_json(data): return {'inputs': {name: data[name].tolist() for name in data.keys()} if isinstance(data, dict) else data.tolist()} def score_model(model_uri, databricks_token, data): headers = { "Authorization": f"Bearer {databricks_token}", "Content-Type": "application/json", } data_dict = {'dataframe_split': data.to_dict(orient='split')} if isinstance(data, pd.DataFrame) else create_tf_serving_json(data) data_json = json.dumps(data_dict) response = requests.request(method='POST', headers=headers, url=model_uri, json=data_json) if response.status_code != 200: raise Exception(f"Request failed with status {response.status_code}, {response.text}") return response.json() # Scoring a model that accepts pandas DataFrames data = pd.DataFrame([{ "sepal_length": 5.1, "sepal_width": 3.5, "petal_length": 1.4, "petal_width": 0.2 }]) score_model(MODEL_VERSION_URI, DATABRICKS_API_TOKEN, data) # Scoring a model that accepts tensors data = np.asarray([[5.1, 3.5, 1.4, 0.2]]) score_model(MODEL_VERSION_URI, DATABRICKS_API_TOKEN, data)Powerbi
يمكنك تسجيل مجموعة بيانات في Power BI Desktop باستخدام الخطوات التالية:
افتح مجموعة البيانات التي تريد تسجيلها.
انتقل إلى Transform Data.
انقر بزر الماوس الأيمن في اللوحة اليسرى وحدد إنشاء استعلام جديد.
انتقل إلى عرض > المحرر المتقدم.
استبدل نص الاستعلام بمقتطف التعليمات البرمجية أدناه، بعد ملء مناسب
DATABRICKS_API_TOKENوMODEL_VERSION_URI.(dataset as table ) as table => let call_predict = (dataset as table ) as list => let apiToken = DATABRICKS_API_TOKEN, modelUri = MODEL_VERSION_URI, responseList = Json.Document(Web.Contents(modelUri, [ Headers = [ #"Content-Type" = "application/json", #"Authorization" = Text.Format("Bearer #{0}", {apiToken}) ], Content = Json.FromValue(dataset) ] )) in responseList, predictionList = List.Combine(List.Transform(Table.Split(dataset, 256), (x) => call_predict(x))), predictionsTable = Table.FromList(predictionList, (x) => {x}, {"Prediction"}), datasetWithPrediction = Table.Join( Table.AddIndexColumn(predictionsTable, "index"), "index", Table.AddIndexColumn(dataset, "index"), "index") in datasetWithPredictionقم بتسمية الاستعلام باسم النموذج المطلوب.
افتح محرر الاستعلام المتقدم لمجموعة البيانات الخاصة بك وقم بتطبيق دالة النموذج.
إذا كان طلب التسجيل يستخدم عميل MLflow، مثل
mlflow.pyfunc.spark_udf()، فبادر بترقية عميل MLflow إلى الإصدار 2.0 أو أعلى لاستخدام أحدث تنسيق. تعرف على المزيد حول بروتوكول تسجيل نموذج MLflow المحدث في MLflow 2.0.
لمزيد من المعلومات حول تنسيقات بيانات الإدخال التي يقبلها الخادم (على سبيل المثال، تنسيق pandas split-oriented)، راجع وثائق MLflow.
الملاحظات
قريبًا: خلال عام 2024، سنتخلص تدريجيًا من GitHub Issues بوصفها آلية إرسال ملاحظات للمحتوى ونستبدلها بنظام ملاحظات جديد. لمزيد من المعلومات، راجع https://aka.ms/ContentUserFeedback.
إرسال الملاحظات وعرضها المتعلقة بـ