التكامل والتسليم المستمر على Azure Databricks باستخدام Azure DevOps
إشعار
تتناول هذه المقالة Azure DevOps، والتي لا يتم توفيرها أو دعمها من قبل Databricks. للاتصال بالموفر، راجع دعم خدمات Azure DevOps.
ترشدك هذه المقالة خلال تكوين أتمتة Azure DevOps للتعليمات البرمجية والبيانات الاصطناعية التي تعمل مع Azure Databricks. على وجه التحديد، ستقوم بتكوين سير عمل تكامل وتسليم مستمر (CI/CD) للاتصال بمستودع Git، وتشغيل المهام باستخدام Azure Pipelines لإنشاء وحدة واختبار عجلة Python (*.whl)، ونشرها للاستخدام في دفاتر ملاحظات Databricks.
سير عمل تطوير CI/CD
يقترح Databricks سير العمل التالي لتطوير CI/CD باستخدام Azure DevOps:
- إنشاء مستودع، أو استخدام مستودع موجود، مع موفر Git التابع لجهة خارجية.
- قم بتوصيل جهاز التطوير المحلي الخاص بك بنفس مستودع الجهات الخارجية. للحصول على الإرشادات، راجع وثائق موفر Git التابع لجهة خارجية.
- اسحب أي بيانات اصطناعية محدثة موجودة (مثل دفاتر الملاحظات وملفات التعليمات البرمجية والبرامج النصية للبناء) وصولا إلى جهاز التطوير المحلي من مستودع الجهات الخارجية.
- عند الضرورة، قم بإنشاء البيانات الاصطناعية وتحديثها واختبارها على جهاز التطوير المحلي. ثم، ادفع أي بيانات اصطناعية جديدة ومتغيرة من جهاز التطوير المحلي إلى مستودع الجهات الخارجية. للحصول على الإرشادات، راجع وثائق موفر Git التابع لجهة خارجية.
- كرر الخطوين 3 و4 حسب الحاجة.
- استخدم Azure DevOps بشكل دوري كنهج متكامل لسحب البيانات الاصطناعية تلقائيا من مستودع الجهات الخارجية الخاص بك، وبناء التعليمات البرمجية واختبارها وتشغيلها على مساحة عمل Azure Databricks، والإبلاغ عن نتائج الاختبار والتشغيل. بينما يمكنك تشغيل Azure DevOps يدويا، في عمليات التنفيذ في العالم الحقيقي، يمكنك توجيه موفر Git التابع لجهة خارجية لتشغيل Azure DevOps في كل مرة يحدث فيها حدث معين، مثل طلب سحب المستودع.
هناك العديد من أدوات CI/CD التي يمكنك استخدامها لإدارة البنية الأساسية لبرنامج ربط العمليات التجارية وتنفيذها. توضح هذه المقالة كيفية استخدام Azure DevOps. CI/CD هو نمط تصميم، لذلك يجب نقل الخطوات والمراحل الموضحة في مثال هذه المقالة مع بعض التغييرات على لغة تعريف المسار في كل أداة. علاوة على ذلك، فإن الكثير من التعليمات البرمجية في مسار المثال هذا هو تعليمة Python البرمجية القياسية التي يمكن استدعاؤها في أدوات أخرى.
تلميح
للحصول على معلومات حول استخدام Jenkins مع Azure Databricks بدلا من Azure DevOps، راجع CI/CD مع Jenkins على Azure Databricks.
تصف بقية هذه المقالة زوجا من أمثلة المسارات في Azure DevOps التي يمكنك تكييفها مع احتياجاتك الخاصة ل Azure Databricks.
حول المثال
يستخدم مثال هذه المقالة مسارين لجمع التعليمات البرمجية ل Python ودفاتر ملاحظات Python المخزنة في مستودع Git بعيد ونشرها وتشغيلها.
البنية الأساسية لبرنامج ربط العمليات التجارية الأولى، والمعروفة باسم البنية الأساسية لبرنامج ربط العمليات التجارية للبناء ، تقوم بإعداد البيانات الاصطناعية للبنية الأساسية لبرنامج ربط العمليات التجارية الثانية، والمعروفة باسم البنية الأساسية لبرنامج ربط العمليات التجارية للإصدار . يسمح لك فصل البنية الأساسية لبرنامج ربط العمليات التجارية للبناء عن البنية الأساسية لبرنامج ربط العمليات التجارية للإصدار بإنشاء أداة بناء دون نشرها أو نشر البيانات الاصطناعية في نفس الوقت من بنيات متعددة. لإنشاء البنية الأساسية لبرنامج ربط العمليات التجارية للإنشاء والإصدار:
- إنشاء جهاز ظاهري Azure للبنية الأساسية لبرنامج ربط العمليات التجارية للبناء.
- انسخ الملفات من مستودع Git الخاص بك إلى الجهاز الظاهري.
- إنشاء ملف gzip'ed tar يحتوي على التعليمات البرمجية ل Python ودفاتر ملاحظات Python وملفات الإعدادات ذات الصلة.
- انسخ ملف gzip'ed tar كملف مضغوط في موقع لمسار الإصدار للوصول إليه.
- إنشاء جهاز ظاهري Azure آخر لمسار الإصدار.
- احصل على الملف المضغوط من موقع البنية الأساسية لبرنامج ربط العمليات التجارية ثم قم بفك حزم الملف المضغوط للحصول على التعليمات البرمجية ل Python ودفاتر ملاحظات Python وملفات الإعدادات ذات الصلة.
- نشر التعليمات البرمجية ل Python ودفاتر ملاحظات Python وملفات الإعدادات ذات الصلة إلى مساحة عمل Azure Databricks البعيدة ونشرها وتشغيلها.
- بناء ملفات التعليمات البرمجية لمكون مكتبة عجلة Python في ملف عجلة Python.
- قم بإجراء اختبارات الوحدة على التعليمات البرمجية للمكون للتحقق من المنطق في ملف عجلة Python.
- قم بتشغيل دفاتر ملاحظات Python، والتي يستدعي أحدها وظيفة ملف عجلة Python.
حول Databricks CLI
يوضح مثال هذه المقالة كيفية استخدام Databricks CLI في وضع غير تفاعلي داخل البنية الأساسية لبرنامج ربط العمليات التجارية. يوزع مثال البنية الأساسية لبرنامج ربط العمليات التجارية لهذه المقالة التعليمات البرمجية، وينشئ مكتبة، ويشغل دفاتر الملاحظات في مساحة عمل Azure Databricks.
إذا كنت تستخدم Databricks CLI في البنية الأساسية لبرنامج ربط العمليات التجارية الخاصة بك دون تنفيذ مثال التعليمات البرمجية والمكتبة ودفاتر الملاحظات من هذه المقالة، فاتبع الخطوات التالية:
قم بإعداد مساحة عمل Azure Databricks لاستخدام مصادقة OAuth من جهاز إلى جهاز (M2M) لمصادقة كيان الخدمة. قبل البدء، تأكد من أن لديك كيان خدمة معرف Microsoft Entra مع سر Azure Databricks OAuth. راجع مصادقة الوصول إلى Azure Databricks باستخدام كيان خدمة باستخدام OAuth (OAuth M2M).
تثبيت Databricks CLI في البنية الأساسية لبرنامج ربط العمليات التجارية الخاصة بك. للقيام بذلك، أضف مهمة Bash Script إلى البنية الأساسية لبرنامج ربط العمليات التجارية التي تقوم بتشغيل البرنامج النصي التالي:
curl -fsSL https://raw.githubusercontent.com/databricks/setup-cli/main/install.sh | shلإضافة مهمة Bash Script إلى البنية الأساسية لبرنامج ربط العمليات التجارية الخاصة بك، راجع الخطوة 3.6. تثبيت أدوات بناء عجلة Databricks CLI وPython.
تكوين البنية الأساسية لبرنامج ربط العمليات التجارية لتمكين Databricks CLI المثبت لمصادقة كيان الخدمة مع مساحة العمل الخاصة بك. للقيام بذلك، راجع الخطوة 3.1: تحديد متغيرات البيئة لمسار الإصدار.
أضف المزيد من مهام Bash Script إلى البنية الأساسية لبرنامج ربط العمليات التجارية الخاصة بك حسب الحاجة لتشغيل أوامر Databricks CLI. راجع أوامر Databricks CLI.
قبل البدء
لاستخدام مثال هذه المقالة، يجب أن يكون لديك:
- مشروع Azure DevOps موجود. إذا لم يكن لديك مشروع بعد، فقم بإنشاء مشروع في Azure DevOps.
- مستودع موجود مع موفر Git يدعمه Azure DevOps. ستضيف التعليمة البرمجية لمثال Python، ومثال دفتر ملاحظات Python، وملفات إعدادات الإصدار ذات الصلة إلى هذا المستودع. إذا لم يكن لديك مستودع بعد، فقم بإنشاء مستودع باتباع إرشادات موفر Git. ثم قم بتوصيل مشروع Azure DevOps بهذا المستودع إذا لم تكن قد فعلت ذلك بالفعل. للحصول على إرشادات، اتبع الارتباطات الموجودة في مستودعات المصدر المدعومة.
- يستخدم مثال هذه المقالة مصادقة OAuth من جهاز إلى جهاز (M2M) لمصادقة أساس خدمة معرف Microsoft Entra إلى مساحة عمل Azure Databricks. يجب أن يكون لديك كيان خدمة معرف Microsoft Entra مع سر Azure Databricks OAuth لكيان الخدمة هذا. راجع مصادقة الوصول إلى Azure Databricks باستخدام كيان خدمة باستخدام OAuth (OAuth M2M).
الخطوة 1: إضافة ملفات المثال إلى المستودع الخاص بك
في هذه الخطوة، في المستودع مع موفر Git التابع لجهة خارجية، يمكنك إضافة جميع ملفات الأمثلة لهذه المقالة التي تنشئها خطوط أنابيب Azure DevOps وتنشرها وتشغلها على مساحة عمل Azure Databricks البعيدة.
الخطوة 1.1: إضافة ملفات مكون عجلة Python
في مثال هذه المقالة، تقوم البنية الأساسية لبرنامج ربط العمليات التجارية Azure DevOps بإنشاء وحدة واختبار ملف عجلة Python. ثم يستدعي دفتر ملاحظات Azure Databricks وظيفة ملف عجلة Python المضمن.
لتعريف المنطق واختبارات الوحدة لملف عجلة Python الذي تعمل عليه دفاتر الملاحظات، في جذر المستودع الخاص بك قم بإنشاء ملفين باسم addcol.py و test_addcol.py، وإضافتهما إلى بنية مجلد مسمى python/dabdemo/dabdemo Libraries في مجلد، يتم تصورهما على النحو التالي:
└── Libraries
└── python
└── dabdemo
└── dabdemo
├── addcol.py
└── test_addcol.py
addcol.py يحتوي الملف على وظيفة مكتبة تم إنشاؤها لاحقا في ملف عجلة Python ثم تثبيتها على مجموعات Azure Databricks. إنها دالة بسيطة تضيف عمودا جديدا، يتم ملؤه بالحرف الحرفي، إلى Apache Spark DataFrame:
# Filename: addcol.py
import pyspark.sql.functions as F
def with_status(df):
return df.withColumn("status", F.lit("checked"))
test_addcol.py يحتوي الملف على اختبارات لتمرير كائن DataFrame وهمية with_status إلى الوظيفة، المعرفة في addcol.py. ثم تتم مقارنة النتيجة بعنصر DataFrame يحتوي على القيم المتوقعة. إذا تطابقت القيم، يجتاز الاختبار:
# Filename: test_addcol.py
import pytest
from pyspark.sql import SparkSession
from dabdemo.addcol import *
class TestAppendCol(object):
def test_with_status(self):
spark = SparkSession.builder.getOrCreate()
source_data = [
("paula", "white", "paula.white@example.com"),
("john", "baer", "john.baer@example.com")
]
source_df = spark.createDataFrame(
source_data,
["first_name", "last_name", "email"]
)
actual_df = with_status(source_df)
expected_data = [
("paula", "white", "paula.white@example.com", "checked"),
("john", "baer", "john.baer@example.com", "checked")
]
expected_df = spark.createDataFrame(
expected_data,
["first_name", "last_name", "email", "status"]
)
assert(expected_df.collect() == actual_df.collect())
لتمكين Databricks CLI من حزم التعليمات البرمجية لهذه المكتبة بشكل صحيح في ملف عجلة Python، قم بإنشاء ملفين باسم __init__.py وفي __main__.py نفس المجلد مثل الملفين السابقين. أيضا، قم بإنشاء ملف باسم setup.py في python/dabdemo المجلد، تم تصوره كما يلي:
└── Libraries
└── python
└── dabdemo
├── dabdemo
│ ├── __init__.py
│ ├── __main__.py
│ ├── addcol.py
│ └── test_addcol.py
└── setup.py
__init__.py يحتوي الملف على رقم إصدار المكتبة والكاتب. استبدل <my-author-name> باسمك:
# Filename: __init__.py
__version__ = '0.0.1'
__author__ = '<my-author-name>'
import sys, os
sys.path.append(os.path.join(os.path.dirname(__file__), "..", ".."))
__main__.py يحتوي الملف على نقطة إدخال المكتبة:
# Filename: __main__.py
import sys, os
sys.path.append(os.path.join(os.path.dirname(__file__), "..", ".."))
from addcol import *
def main():
pass
if __name__ == "__main__":
main()
setup.py يحتوي الملف على إعدادات إضافية لبناء المكتبة في ملف عجلة Python. استبدل <my-url>و <my-author-name>@<my-organization>و <my-package-description> بقيم صالحة:
# Filename: setup.py
from setuptools import setup, find_packages
import dabdemo
setup(
name = "dabdemo",
version = dabdemo.__version__,
author = dabdemo.__author__,
url = "https://<my-url>",
author_email = "<my-author-name>@<my-organization>",
description = "<my-package-description>",
packages = find_packages(include = ["dabdemo"]),
entry_points={"group_1": "run=dabdemo.__main__:main"},
install_requires = ["setuptools"]
)
الخطوة 1.2: إضافة دفتر ملاحظات اختبار وحدة لملف عجلة Python
في وقت لاحق، يقوم Databricks CLI بتشغيل مهمة دفتر ملاحظات. تقوم هذه المهمة بتشغيل دفتر ملاحظات Python باسم run_unit_tests.pyملف . يعمل pytest دفتر الملاحظات هذا مقابل منطق مكتبة عجلة Python.
لتشغيل اختبارات الوحدة لمثال هذه المقالة، أضف إلى جذر المستودع ملف دفتر ملاحظات باسم run_unit_tests.py بالمحتويات التالية:
# Databricks notebook source
# COMMAND ----------
# MAGIC %sh
# MAGIC
# MAGIC mkdir -p "/Workspace${WORKSPACEBUNDLEPATH}/Validation/reports/junit/test-reports"
# COMMAND ----------
# Prepare to run pytest.
import sys, pytest, os
# Skip writing pyc files on a readonly filesystem.
sys.dont_write_bytecode = True
# Run pytest.
retcode = pytest.main(["--junit-xml", f"/Workspace{os.getenv('WORKSPACEBUNDLEPATH')}/Validation/reports/junit/test-reports/TEST-libout.xml",
f"/Workspace{os.getenv('WORKSPACEBUNDLEPATH')}/files/Libraries/python/dabdemo/dabdemo/"])
# Fail the cell execution if there are any test failures.
assert retcode == 0, "The pytest invocation failed. See the log for details."
الخطوة 1.3: إضافة دفتر ملاحظات يستدعي ملف عجلة Python
في وقت لاحق، يقوم Databricks CLI بتشغيل مهمة دفتر ملاحظات أخرى. يقوم دفتر الملاحظات هذا بإنشاء كائن DataFrame، وتمريره إلى وظيفة مكتبة with_status عجلة Python، وطباعة النتيجة، والإبلاغ عن نتائج تشغيل المهمة. أنشئ جذر المستودع الخاص بك ملف دفتر ملاحظات باسم dabdemo_notebook.py بالمحتويات التالية:
# Databricks notebook source
# COMMAND ----------
# Restart Python after installing the Python wheel.
dbutils.library.restartPython()
# COMMAND ----------
from dabdemo.addcol import with_status
df = (spark.createDataFrame(
schema = ["first_name", "last_name", "email"],
data = [
("paula", "white", "paula.white@example.com"),
("john", "baer", "john.baer@example.com")
]
))
new_df = with_status(df)
display(new_df)
# Expected output:
#
# +------------+-----------+-------------------------+---------+
# │ first_name │ last_name │ email │ status │
# +============+===========+=========================+=========+
# │ paula │ white │ paula.white@example.com │ checked │
# +------------+-----------+-------------------------+---------+
# │ john │ baer │ john.baer@example.com │ checked │
# +------------+-----------+-------------------------+---------+
الخطوة 1.4: إنشاء تكوين المجموعة
يستخدم مثال هذه المقالة حزم أصول Databricks لتحديد الإعدادات والسلوكيات لإنشاء ملف عجلة Python ودفتر الملاحظات وملف التعليمات البرمجية Python ونشره وتشغيله. تجعل حزم أصول Databricks، والمعروفة ببساطة باسم الحزم، من الممكن التعبير عن البيانات الكاملة والتحليلات ومشاريع التعلم الآلي كمجموعة من الملفات المصدر. راجع ما هي حزم أصول Databricks؟.
لتكوين الحزمة لمثال هذه المقالة، قم بإنشاء ملف باسم databricks.ymlفي جذر المستودع الخاص بك. في ملف المثال databricks.yml هذا، استبدل العناصر النائبة التالية:
- استبدل
<bundle-name>باسم برمجي فريد للحزمة. على سبيل المثال،azure-devops-demo - استبدل
<job-prefix-name>ببعض السلسلة للمساعدة في تحديد المهام التي تم إنشاؤها في مساحة عمل Azure Databricks بشكل فريد لهذا المثال. على سبيل المثال،azure-devops-demo - استبدل
<spark-version-id>بمعرف إصدار Databricks Runtime لمجموعات الوظائف، على سبيل المثال13.3.x-scala2.12. - استبدل
<cluster-node-type-id>بمعرف نوع عقدة نظام المجموعة لمجموعات الوظائف، على سبيل المثالStandard_DS3_v2. - لاحظ أنه
devفيtargetsالتعيين يحدد المضيف وسلوكيات التوزيع ذات الصلة. في تطبيقات العالم الحقيقي، يمكنك إعطاء هذا الهدف اسما مختلفا في مجموعاتك الخاصة.
فيما يلي محتويات ملف هذا المثال databricks.yml :
# Filename: databricks.yml
bundle:
name: <bundle-name>
variables:
job_prefix:
description: A unifying prefix for this bundle's job and task names.
default: <job-prefix-name>
spark_version:
description: The cluster's Spark version ID.
default: <spark-version-id>
node_type_id:
description: The cluster's node type ID.
default: <cluster-node-type-id>
artifacts:
dabdemo-wheel:
type: whl
path: ./Libraries/python/dabdemo
resources:
jobs:
run-unit-tests:
name: ${var.job_prefix}-run-unit-tests
tasks:
- task_key: ${var.job_prefix}-run-unit-tests-task
new_cluster:
spark_version: ${var.spark_version}
node_type_id: ${var.node_type_id}
num_workers: 1
spark_env_vars:
WORKSPACEBUNDLEPATH: ${workspace.root_path}
notebook_task:
notebook_path: ./run_unit_tests.py
source: WORKSPACE
libraries:
- pypi:
package: pytest
run-dabdemo-notebook:
name: ${var.job_prefix}-run-dabdemo-notebook
tasks:
- task_key: ${var.job_prefix}-run-dabdemo-notebook-task
new_cluster:
spark_version: ${var.spark_version}
node_type_id: ${var.node_type_id}
num_workers: 1
spark_env_vars:
WORKSPACEBUNDLEPATH: ${workspace.root_path}
notebook_task:
notebook_path: ./dabdemo_notebook.py
source: WORKSPACE
libraries:
- whl: "/Workspace${workspace.root_path}/files/Libraries/python/dabdemo/dist/dabdemo-0.0.1-py3-none-any.whl"
targets:
dev:
mode: development
لمزيد من المعلومات حول databricks.yml بناء جملة الملف، راجع تكوين مجموعة أصول Databricks.
الخطوة 2: تحديد البنية الأساسية لبرنامج ربط العمليات التجارية للبناء
يوفر Azure DevOps واجهة مستخدم مستضافة على السحابة لتحديد مراحل البنية الأساسية لبرنامج ربط العمليات التجارية CI/CD باستخدام YAML. لمزيد من المعلومات حول Azure DevOps والتدفقات، راجع وثائق Azure DevOps.
في هذه الخطوة، يمكنك استخدام علامات YAML لتعريف البنية الأساسية لبرنامج ربط العمليات التجارية للبناء، والتي تنشئ أداة توزيع. لنشر التعليمات البرمجية إلى مساحة عمل Azure Databricks، يمكنك تحديد أداة بناء البنية الأساسية لبرنامج ربط العمليات التجارية هذه كإدخل في مسار الإصدار. يمكنك تعريف مسار الإصدار هذا لاحقا.
لتشغيل البنية الأساسية لبرنامج ربط العمليات التجارية للبناء، يوفر Azure DevOps عوامل تنفيذ مستضافة على السحابة عند الطلب تدعم عمليات النشر إلى Kubernetes والأجهزة الظاهرية وAzure Functions وAzure Web Apps والعديد من الأهداف الأخرى. في هذا المثال، يمكنك استخدام عامل عند الطلب لأتمتة إنشاء البيانات الاصطناعية للتوزيع.
حدد مثال البنية الأساسية لبرنامج ربط العمليات التجارية للبناء في هذه المقالة كما يلي:
سجل الدخول إلى Azure DevOps ثم انقر فوق الارتباط تسجيل الدخول لفتح مشروع Azure DevOps.
إشعار
إذا كان مدخل Azure يعرض بدلا من مشروع Azure DevOps الخاص بك، فانقر فوق المزيد من الخدمات > مؤسسات Azure DevOps > مؤسسات My Azure DevOps ثم افتح مشروع Azure DevOps.
انقر فوق Pipelines في الشريط الجانبي، ثم انقر فوق Pipelines في قائمة Pipelines.
انقر فوق الزر New Pipeline واتبع الإرشادات التي تظهر على الشاشة. (إذا كان لديك مسارات بالفعل، فانقر فوق إنشاء البنية الأساسية لبرنامج ربط العمليات التجارية بدلا من ذلك.) في نهاية هذه الإرشادات، يفتح محرر البنية الأساسية لبرنامج ربط العمليات التجارية. هنا يمكنك تعريف البرنامج النصي للبنية الأساسية لبرنامج ربط العمليات التجارية في
azure-pipelines.ymlالملف الذي يظهر. إذا لم يكن محرر البنية الأساسية لبرنامج ربط العمليات التجارية مرئيا في نهاية الإرشادات، فحدد اسم البنية الأساسية لبرنامج ربط العمليات التجارية ثم انقر فوق تحرير.يمكنك استخدام محدد
 فرع Git لتخصيص عملية الإنشاء لكل فرع في مستودع Git الخاص بك. من أفضل الممارسات CI/CD عدم القيام بأعمال الإنتاج مباشرة في فرع المستودع
فرع Git لتخصيص عملية الإنشاء لكل فرع في مستودع Git الخاص بك. من أفضل الممارسات CI/CD عدم القيام بأعمال الإنتاج مباشرة في فرع المستودع mainالخاص بك. يفترض هذا المثال وجود فرع مسمىreleaseفي المستودع لاستخدامه بدلا منmain.
azure-pipelines.ymlيتم تخزين البرنامج النصي للبنية الأساسية لبرنامج ربط العمليات التجارية بشكل افتراضي في جذر مستودع Git البعيد الذي تقوم بإقرانه بالبنية الأساسية لبرنامج ربط العمليات التجارية.قم بالكتابة فوق محتويات بداية ملف البنية
azure-pipelines.ymlالأساسية لبرنامج ربط العمليات التجارية باستخدام التعريف التالي، ثم انقر فوق حفظ.# Specify the trigger event to start the build pipeline. # In this case, new code merged into the release branch initiates a new build. trigger: - release # Specify the operating system for the agent that runs on the Azure virtual # machine for the build pipeline (known as the build agent). The virtual # machine image in this example uses the Ubuntu 22.04 virtual machine # image in the Azure Pipeline agent pool. See # https://learn.microsoft.com/azure/devops/pipelines/agents/hosted#software pool: vmImage: ubuntu-22.04 # Download the files from the designated branch in the remote Git repository # onto the build agent. steps: - checkout: self persistCredentials: true clean: true # Generate the deployment artifact. To do this, the build agent gathers # all the new or updated code to be given to the release pipeline, # including the sample Python code, the Python notebooks, # the Python wheel library component files, and the related Databricks asset # bundle settings. # Use git diff to flag files that were added in the most recent Git merge. # Then add the files to be used by the release pipeline. # The implementation in your pipeline will likely be different. # The objective here is to add all files intended for the current release. - script: | git diff --name-only --diff-filter=AMR HEAD^1 HEAD | xargs -I '{}' cp --parents -r '{}' $(Build.BinariesDirectory) mkdir -p $(Build.BinariesDirectory)/Libraries/python/dabdemo/dabdemo cp $(Build.Repository.LocalPath)/Libraries/python/dabdemo/dabdemo/*.* $(Build.BinariesDirectory)/Libraries/python/dabdemo/dabdemo cp $(Build.Repository.LocalPath)/Libraries/python/dabdemo/setup.py $(Build.BinariesDirectory)/Libraries/python/dabdemo cp $(Build.Repository.LocalPath)/*.* $(Build.BinariesDirectory) displayName: 'Get Changes' # Create the deployment artifact and then publish it to the # artifact repository. - task: ArchiveFiles@2 inputs: rootFolderOrFile: '$(Build.BinariesDirectory)' includeRootFolder: false archiveType: 'zip' archiveFile: '$(Build.ArtifactStagingDirectory)/$(Build.BuildId).zip' replaceExistingArchive: true - task: PublishBuildArtifacts@1 inputs: ArtifactName: 'DatabricksBuild'
الخطوة 3: تحديد البنية الأساسية لبرنامج ربط العمليات التجارية للإصدار
يوزع مسار الإصدار البيانات الاصطناعية للبناء من البنية الأساسية لبرنامج ربط العمليات التجارية للبناء إلى بيئة Azure Databricks. يسمح لك فصل مسار الإصدار في هذه الخطوة عن البنية الأساسية لبرنامج ربط العمليات التجارية للبناء في الخطوات السابقة بإنشاء بنية دون نشرها أو توزيع البيانات الاصطناعية من بنيات متعددة في وقت واحد.
في مشروع Azure DevOps، في قائمة Pipelines في الشريط الجانبي، انقر فوق Releases.
انقر فوق New > New release pipeline. (إذا كان لديك مسارات بالفعل، فانقر فوق البنية الأساسية لبرنامج ربط العمليات التجارية الجديدة بدلا من ذلك.)
على جانب الشاشة توجد قائمة بالقوالب المميزة لأنماط التوزيع الشائعة. في هذا المثال، انقر فوق
 البنية الأساسية لبرنامج ربط العمليات التجارية لإصدار .
البنية الأساسية لبرنامج ربط العمليات التجارية لإصدار .
في المربع Artifacts على جانب الشاشة، انقر فوق
 . في جزء Add an artifact ، بالنسبة للمصدر (البنية الأساسية لبرنامج ربط العمليات التجارية للبناء)، حدد البنية الأساسية لبرنامج ربط العمليات التجارية التي قمت بإنشائها مسبقا. ثم انقر فوق Add.
. في جزء Add an artifact ، بالنسبة للمصدر (البنية الأساسية لبرنامج ربط العمليات التجارية للبناء)، حدد البنية الأساسية لبرنامج ربط العمليات التجارية التي قمت بإنشائها مسبقا. ثم انقر فوق Add.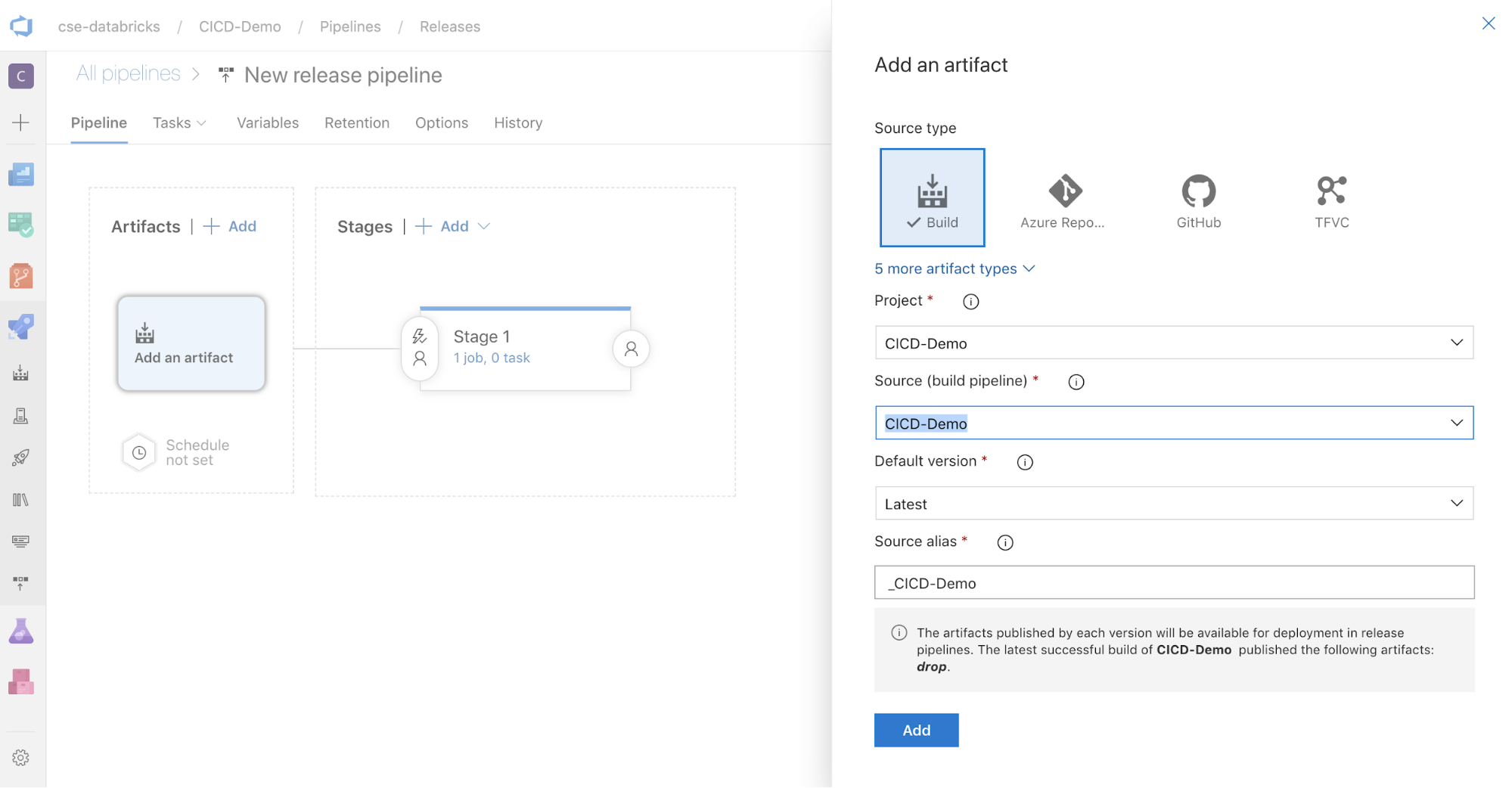
يمكنك تكوين كيفية تشغيل البنية الأساسية لبرنامج ربط العمليات التجارية بالنقر
 لعرض خيارات التشغيل على جانب الشاشة. إذا كنت تريد بدء إصدار تلقائيا استنادا إلى توفر البيانات الاصطناعية للبناء أو بعد سير عمل طلب السحب، فمكن المشغل المناسب. في الوقت الحالي، في هذا المثال، في الخطوة الأخيرة من هذه المقالة، يمكنك تشغيل البنية الأساسية لبرنامج ربط العمليات التجارية للبناء يدويا ثم البنية الأساسية لبرنامج ربط العمليات التجارية للإصدار.
لعرض خيارات التشغيل على جانب الشاشة. إذا كنت تريد بدء إصدار تلقائيا استنادا إلى توفر البيانات الاصطناعية للبناء أو بعد سير عمل طلب السحب، فمكن المشغل المناسب. في الوقت الحالي، في هذا المثال، في الخطوة الأخيرة من هذه المقالة، يمكنك تشغيل البنية الأساسية لبرنامج ربط العمليات التجارية للبناء يدويا ثم البنية الأساسية لبرنامج ربط العمليات التجارية للإصدار.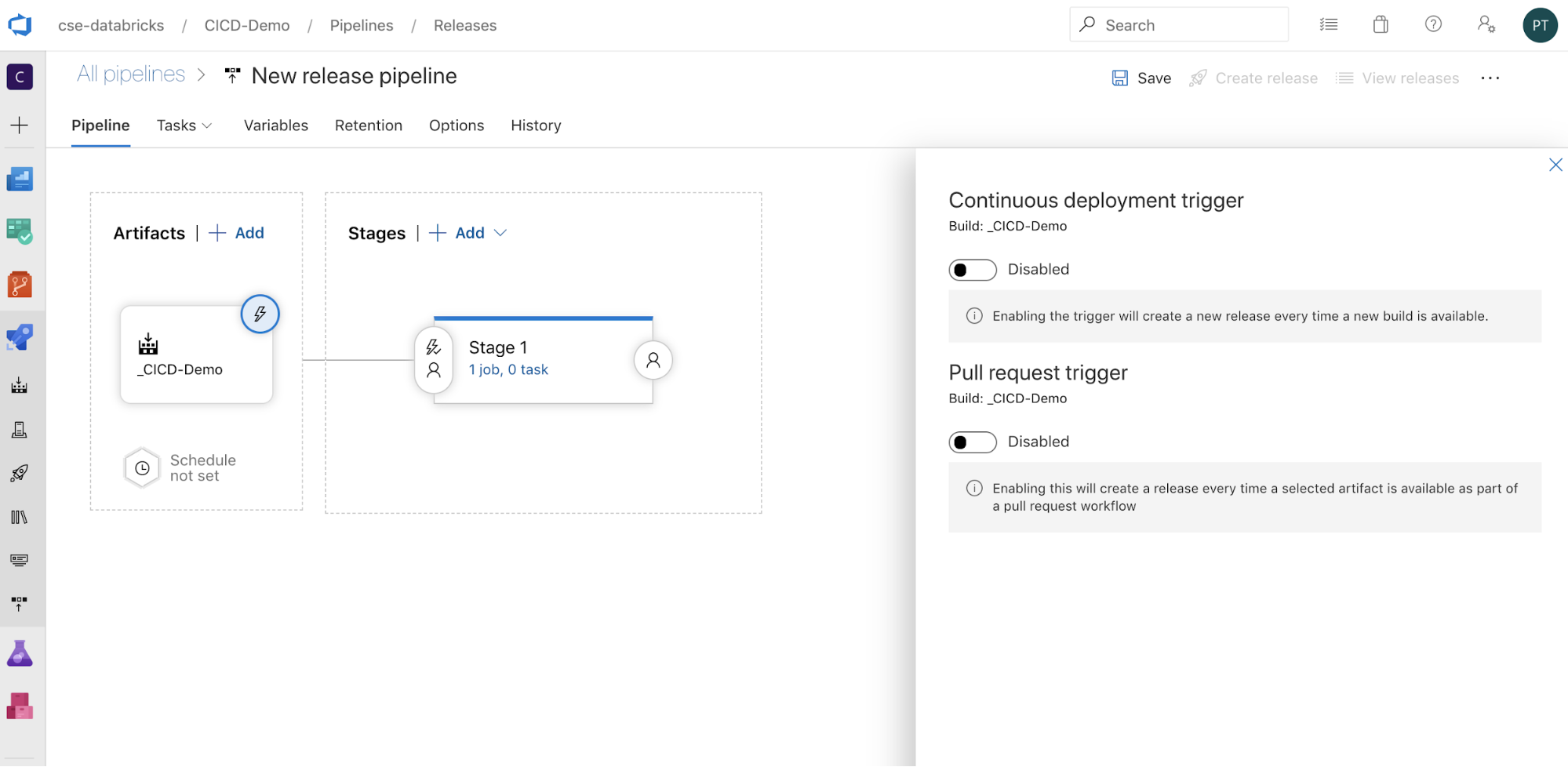
انقر فوق حفظ > موافق.
الخطوة 3.1: تحديد متغيرات البيئة لمسار الإصدار
يعتمد مسار إصدار هذا المثال على متغيرات البيئة التالية، والتي يمكنك إضافتها بالنقر فوق Add في قسم Pipeline variables في علامة التبويب Variables، مع نطاق المرحلة 1:
BUNDLE_TARGET، والتي يجب أن تتطابق معtargetالاسم في الملف الخاص بكdatabricks.yml. في مثال هذه المقالة، هذا هوdev.DATABRICKS_HOST، الذي يمثل عنوان URL لكل مساحة عمل لمساحة عمل Azure Databricks، بدءا منhttps://، على سبيل المثالhttps://adb-<workspace-id>.<random-number>.azuredatabricks.net. لا تقم بتضمين اللاحقة/بعد.net.DATABRICKS_CLIENT_ID، الذي يمثل معرف التطبيق لمدير خدمة معرف Microsoft Entra.DATABRICKS_CLIENT_SECRET، الذي يمثل سر Azure Databricks OAuth لمدير خدمة معرف Microsoft Entra.
الخطوة 3.2: تكوين عامل الإصدار لمسار الإصدار
انقر فوق ارتباط المهمة 1، 0 ضمن كائن المرحلة 1.
على علامة التبويب المهام ، انقر فوق وظيفة العامل.
في قسم Agent selection ، ل Agent pool، حدد Azure Pipelines.
بالنسبة لمواصفات العامل، حدد نفس العامل الذي حددته لعامل البناء سابقا، في هذا المثال ubuntu-22.04.
انقر فوق حفظ > موافق.
الخطوة 3.3: تعيين إصدار Python لعامل الإصدار
انقر فوق علامة الجمع في قسم وظيفة العامل، المشار إليها بواسطة السهم الأحمر في الشكل التالي. تظهر قائمة بالمهام المتوفرة القابلة للبحث. هناك أيضا علامة تبويب Marketplace للمكونات الإضافية التابعة لجهات خارجية التي يمكن استخدامها لتكملة مهام Azure DevOps القياسية. ستضيف عدة مهام إلى عامل الإصدار خلال الخطوات العديدة التالية.
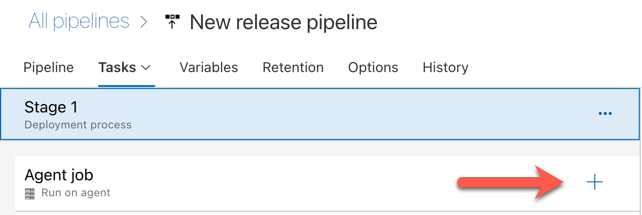
المهمة الأولى التي تضيفها هي استخدام إصدار Python، الموجود في علامة التبويب أداة . إذا لم تتمكن من العثور على هذه المهمة، فاستخدم مربع البحث للبحث عنها. عند العثور عليه، حدده ثم انقر فوق الزر Add بجوار مهمة Use Python version .
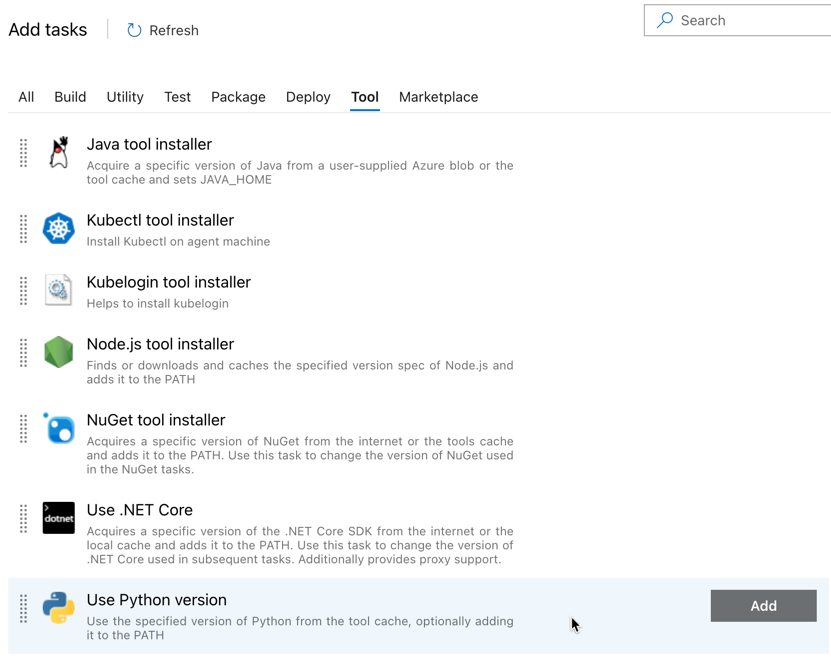
كما هو الحال مع البنية الأساسية لبرنامج ربط العمليات التجارية للبناء، تريد التأكد من أن إصدار Python متوافق مع البرامج النصية التي تم استدعاؤها في المهام اللاحقة. في هذه الحالة، انقر فوق المهمة Use Python 3.x بجوار Agent job، ثم قم بتعيين مواصفات الإصدار إلى
3.10. قم أيضا بتعيين اسم العرض إلىUse Python 3.10. يفترض هذا المسار أنك تستخدم Databricks Runtime 13.3 LTS على المجموعات التي تم تثبيت Python 3.10.12 عليها.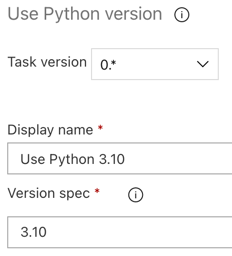
انقر فوق حفظ > موافق.
الخطوة 3.4: فك حزمة البيانات الاصطناعية للبناء من البنية الأساسية لبرنامج ربط العمليات التجارية للبناء
بعد ذلك، يجب على عامل الإصدار استخراج ملف عجلة Python، وملفات إعدادات الإصدار ذات الصلة، ودفاتر الملاحظات، وملف التعليمات البرمجية Python من الملف المضغوط باستخدام مهمة استخراج الملفات : انقر فوق علامة الجمع في قسم وظيفة العامل، وحدد مهمة استخراج الملفات في علامة التبويب الأداة المساعدة ، ثم انقر فوق إضافة.
انقر فوق مهمة استخراج الملفات بجوار مهمة العامل، واضبط أنماط ملفات الأرشيف على
**/*.zip، ثم قم بتعيين مجلد الوجهة إلى متغير$(Release.PrimaryArtifactSourceAlias)/Databricksالنظام . قم أيضا بتعيين اسم العرض إلىExtract build pipeline artifact.إشعار
$(Release.PrimaryArtifactSourceAlias)يمثل اسما مستعارا تم إنشاؤه بواسطة Azure DevOps لتحديد موقع مصدر البيانات الاصطناعية الأساسي على عامل الإصدار، على سبيل المثال_<your-github-alias>.<your-github-repo-name>. يعين مسار الإصدار هذه القيمة كمتغيرRELEASE_PRIMARYARTIFACTSOURCEALIASالبيئة في مرحلة تهيئة الوظيفة لعامل الإصدار. راجع متغيرات الإصدار والبيانات الاصطناعية الكلاسيكية.تعيين اسم العرض إلى
Extract build pipeline artifact.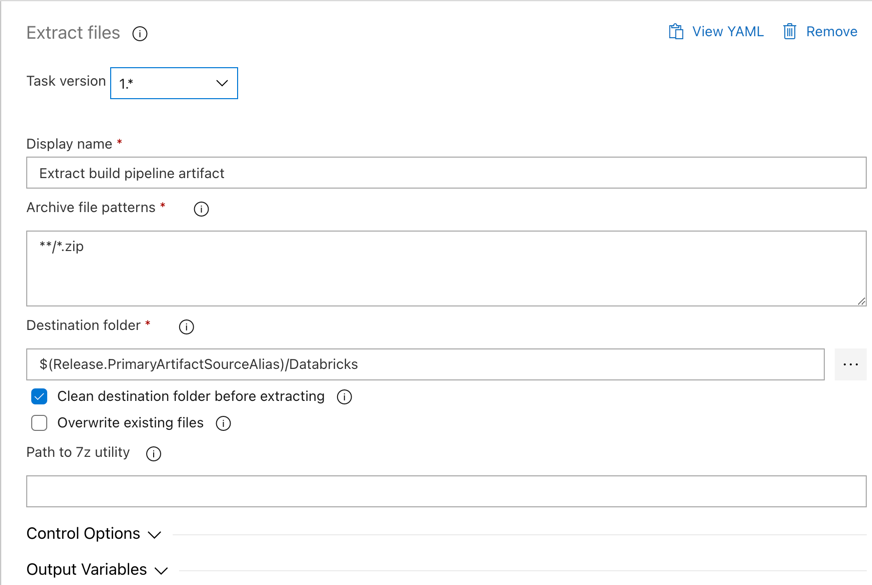
انقر فوق حفظ > موافق.
الخطوة 3.5: تعيين متغير البيئة BUNDLE_ROOT
لكي يعمل مثال هذه المقالة كما هو متوقع، يجب تعيين متغير بيئة مسمى BUNDLE_ROOT في مسار الإصدار. تستخدم حزم أصول Databricks متغير البيئة هذا لتحديد مكان databricks.yml وجود الملف. لتعيين متغير البيئة هذا:
استخدم مهمة متغيرات البيئة: انقر فوق علامة الجمع مرة أخرى في قسم وظيفة العامل، وحدد مهمة متغيرات البيئة في علامة التبويب الأداة المساعدة، ثم انقر فوق إضافة.
إشعار
إذا لم تكن مهمة متغيرات البيئة مرئية في علامة التبويب الأداة المساعدة، أدخل
Environment Variablesفي مربع البحث واتبع الإرشادات التي تظهر على الشاشة لإضافة المهمة إلى علامة التبويب الأداة المساعدة. قد يتطلب ذلك مغادرة Azure DevOps ثم العودة إلى هذا الموقع حيث توقفت.بالنسبة إلى متغيرات البيئة (مفصولة بفواصل)، أدخل التعريف التالي:
BUNDLE_ROOT=$(Agent.ReleaseDirectory)/$(Release.PrimaryArtifactSourceAlias)/Databricks.إشعار
$(Agent.ReleaseDirectory)يمثل اسما مستعارا تم إنشاؤه بواسطة Azure DevOps لتحديد موقع دليل الإصدار على عامل الإصدار، على سبيل المثال/home/vsts/work/r1/a. يعين مسار الإصدار هذه القيمة كمتغيرAGENT_RELEASEDIRECTORYالبيئة في مرحلة تهيئة الوظيفة لعامل الإصدار. راجع متغيرات الإصدار والبيانات الاصطناعية الكلاسيكية. للحصول على معلومات حول$(Release.PrimaryArtifactSourceAlias)، راجع الملاحظة في الخطوة السابقة.تعيين اسم العرض إلى
Set BUNDLE_ROOT environment variable.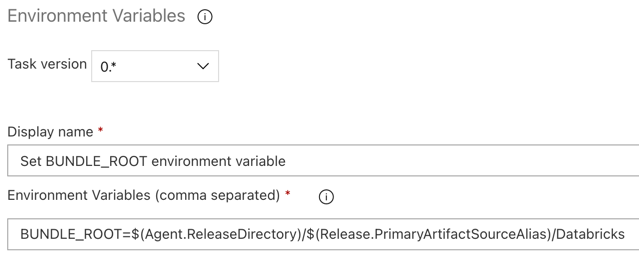
انقر فوق حفظ > موافق.
الخطوة 3.6. تثبيت أدوات بناء عجلة Databricks CLI وPython
بعد ذلك، قم بتثبيت أدوات بناء عجلة Databricks CLI وPython على عامل الإصدار. سيقوم عامل الإصدار باستدعاء أدوات بناء عجلة Databricks CLI وPython في المهام القليلة التالية. للقيام بذلك، استخدم مهمة Bash : انقر فوق علامة الجمع مرة أخرى في قسم وظيفة العامل، وحدد مهمة Bash في علامة التبويب الأداة المساعدة ، ثم انقر فوق إضافة.
انقر فوق مهمة Bash Script بجوار مهمة العامل.
بالنسبة إلى Type، حدد Inline.
استبدل محتويات البرنامج النصي بالأمر التالي، الذي يقوم بتثبيت أدوات بناء Databricks CLI وعجلة Python:
curl -fsSL https://raw.githubusercontent.com/databricks/setup-cli/main/install.sh | sh pip install wheelتعيين اسم العرض إلى
Install Databricks CLI and Python wheel build tools.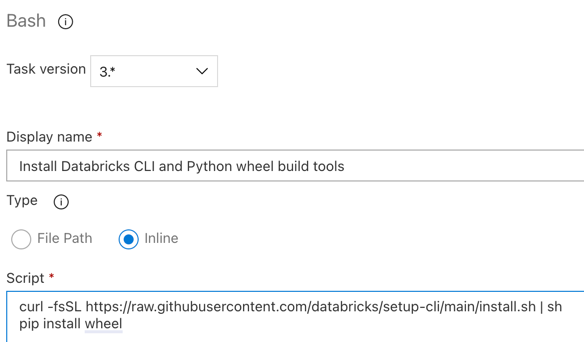
انقر فوق حفظ > موافق.
الخطوة 3.7: التحقق من صحة مجموعة أصول Databricks
في هذه الخطوة، تأكد من أن databricks.yml الملف صحيح من الناحية التركيبية.
استخدم مهمة Bash: انقر فوق علامة الجمع مرة أخرى في قسم وظيفة العامل، وحدد مهمة Bash في علامة التبويب الأداة المساعدة، ثم انقر فوق إضافة.
انقر فوق مهمة Bash Script بجوار مهمة العامل.
بالنسبة إلى Type، حدد Inline.
استبدل محتويات البرنامج النصي بالأمر التالي، والذي يستخدم Databricks CLI للتحقق مما إذا كان
databricks.ymlالملف صحيحا من الناحية التركيبية:databricks bundle validate -t $(BUNDLE_TARGET)تعيين اسم العرض إلى
Validate bundle.انقر فوق حفظ > موافق.
الخطوة 3.8: نشر الحزمة
في هذه الخطوة، يمكنك إنشاء ملف عجلة Python ونشر ملف عجلة Python المضمن، ودفتر ملاحظات Python، وملف Python من مسار الإصدار إلى مساحة عمل Azure Databricks.
استخدم مهمة Bash: انقر فوق علامة الجمع مرة أخرى في قسم وظيفة العامل، وحدد مهمة Bash في علامة التبويب الأداة المساعدة، ثم انقر فوق إضافة.
انقر فوق مهمة Bash Script بجوار مهمة العامل.
بالنسبة إلى Type، حدد Inline.
استبدل محتويات البرنامج النصي بالأمر التالي، الذي يستخدم Databricks CLI لإنشاء ملف عجلة Python ونشر ملفات المثال لهذه المقالة من مسار الإصدار إلى مساحة عمل Azure Databricks:
databricks bundle deploy -t $(BUNDLE_TARGET)تعيين اسم العرض إلى
Deploy bundle.انقر فوق حفظ > موافق.
الخطوة 3.9: تشغيل دفتر ملاحظات اختبار الوحدة لعجلة Python
في هذه الخطوة، يمكنك تشغيل مهمة تقوم بتشغيل دفتر ملاحظات اختبار الوحدة في مساحة عمل Azure Databricks. يقوم دفتر الملاحظات هذا بتشغيل اختبارات الوحدة مقابل منطق مكتبة عجلة Python.
استخدم مهمة Bash: انقر فوق علامة الجمع مرة أخرى في قسم وظيفة العامل، وحدد مهمة Bash في علامة التبويب الأداة المساعدة، ثم انقر فوق إضافة.
انقر فوق مهمة Bash Script بجوار مهمة العامل.
بالنسبة إلى Type، حدد Inline.
استبدل محتويات البرنامج النصي بالأمر التالي، والذي يستخدم Databricks CLI لتشغيل المهمة في مساحة عمل Azure Databricks:
databricks bundle run -t $(BUNDLE_TARGET) run-unit-testsتعيين اسم العرض إلى
Run unit tests.انقر فوق حفظ > موافق.
الخطوة 3.10: تشغيل دفتر الملاحظات الذي يستدعي عجلة Python
في هذه الخطوة، يمكنك تشغيل مهمة تقوم بتشغيل دفتر ملاحظات آخر في مساحة عمل Azure Databricks. يستدعي دفتر الملاحظات هذا مكتبة عجلة Python.
استخدم مهمة Bash: انقر فوق علامة الجمع مرة أخرى في قسم وظيفة العامل، وحدد مهمة Bash في علامة التبويب الأداة المساعدة، ثم انقر فوق إضافة.
انقر فوق مهمة Bash Script بجوار مهمة العامل.
بالنسبة إلى Type، حدد Inline.
استبدل محتويات البرنامج النصي بالأمر التالي، والذي يستخدم Databricks CLI لتشغيل المهمة في مساحة عمل Azure Databricks:
databricks bundle run -t $(BUNDLE_TARGET) run-dabdemo-notebookتعيين اسم العرض إلى
Run notebook.انقر فوق حفظ > موافق.
لقد أكملت الآن تكوين البنية الأساسية لبرنامج ربط العمليات التجارية للإصدار. يجب أن يبدو كما يلي:
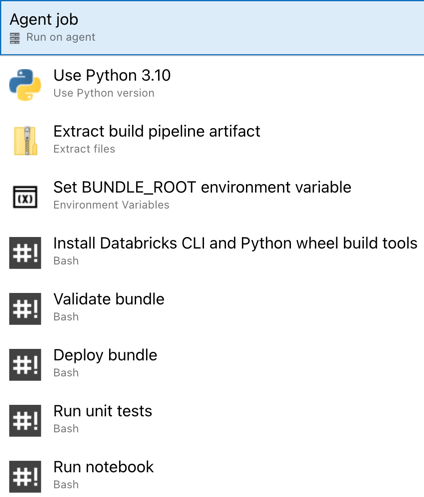
الخطوة 4: تشغيل البنية الأساسية لبرنامج ربط العمليات التجارية للإنشاء والإصدار
في هذه الخطوة، يمكنك تشغيل البنية الأساسية لبرنامج ربط العمليات التجارية يدويا. لمعرفة كيفية تشغيل البنية الأساسية لبرنامج ربط العمليات التجارية تلقائيا، راجع تحديد الأحداث التي تؤدي إلى تشغيل المسارات ومشغلات الإصدار.
لتشغيل البنية الأساسية لبرنامج ربط العمليات التجارية للبناء يدويا:
- في قائمة Pipelines في الشريط الجانبي، انقر فوق Pipelines.
- انقر فوق اسم البنية الأساسية لبرنامج ربط العمليات التجارية للبناء، ثم انقر فوق تشغيل البنية الأساسية لبرنامج ربط العمليات التجارية.
- بالنسبة إلى Branch/tag، حدد اسم الفرع في مستودع Git الذي يحتوي على جميع التعليمات البرمجية المصدر التي أضفتها. يفترض هذا المثال أن هذا في
releaseالفرع. - انقر فوق تشغيل. تظهر صفحة تشغيل البنية الأساسية لبرنامج ربط العمليات التجارية للبناء.
- لمشاهدة تقدم البنية الأساسية لبرنامج ربط العمليات التجارية للبناء ولعرض السجلات ذات الصلة، انقر فوق الأيقونة الدوارة بجوار Job.
- بعد أن تتحول أيقونة الوظيفة إلى علامة اختيار خضراء، تابع لتشغيل البنية الأساسية لبرنامج ربط العمليات التجارية للإصدار.
لتشغيل البنية الأساسية لبرنامج ربط العمليات التجارية للإصدار يدويا:
- بعد تشغيل البنية الأساسية لبرنامج ربط العمليات التجارية بنجاح، في قائمة Pipelines في الشريط الجانبي، انقر فوق Releases.
- انقر فوق اسم مسار الإصدار، ثم انقر فوق إنشاء إصدار.
- انقر فوق Create.
- للاطلاع على تقدم مسار الإصدار، في قائمة الإصدارات، انقر فوق اسم أحدث إصدار.
- في المربع مراحل ، انقر فوق المرحلة 1، ثم انقر فوق سجلات.