إشعار
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تسجيل الدخول أو تغيير الدلائل.
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تغيير الدلائل.
إشعار
توصي Databricks Connect باستخدام Databricks Connect ل Databricks Runtime 13.0 والإصدارات الأحدث بدلا من ذلك.
لا تخطط Databricks أي عمل ميزة جديد ل Databricks Connect ل Databricks Runtime 12.2 LTS والإصدارات أدناه.
يسمح لك Databricks Connect بتوصيل IDEs الشائعة مثل Visual Studio Code وPyCharm وخوادم دفتر الملاحظات والتطبيقات المخصصة الأخرى إلى مجموعات Azure Databricks.
تشرح هذه المقالة كيفية عمل Databricks Connect، وترشدك خلال خطوات بدء استخدام Databricks Connect، وتشرح كيفية استكشاف المشكلات التي قد تنشأ عند استخدام Databricks Connect وإصلاحها، والاختلافات بين التشغيل باستخدام Databricks Connect مقابل التشغيل في دفتر ملاحظات Azure Databricks.
نظرة عامة
Databricks Connect هي مكتبة عميل لوقت تشغيل Databricks. يسمح لك بكتابة المهام باستخدام واجهات برمجة تطبيقات Spark وتشغيلها عن بعد على مجموعة Azure Databricks بدلا من جلسة Spark المحلية.
على سبيل المثال، عند تشغيل الأمر spark.read.format(...).load(...).groupBy(...).agg(...).show() DataFrame باستخدام Databricks Connect، يتم إرسال التمثيل المنطقي للأمر إلى خادم Spark الذي يعمل في Azure Databricks للتنفيذ على نظام المجموعة البعيد.
باستخدام Databricks Connect، يمكنك:
- تشغيل مهام Spark واسعة النطاق من أي تطبيق Python أو R أو Scala أو Java. في أي مكان يمكنك
import pyspark،require(SparkR)أوimport org.apache.spark، يمكنك الآن تشغيل وظائف Spark مباشرة من التطبيق الخاص بك، دون الحاجة إلى تثبيت أي مكونات إضافية ل IDE أو استخدام البرامج النصية لإرسال Spark. - التنقل وتصحيح التعليمات البرمجية في IDE الخاص بك حتى عند العمل مع نظام مجموعة بعيد.
- التكرار بسرعة عند تطوير المكتبات. لا تحتاج إلى إعادة تشغيل نظام المجموعة بعد تغيير تبعيات مكتبة Python أو Java في Databricks Connect، لأن كل جلسة عمل عميل معزولة عن بعضها البعض في نظام المجموعة.
- إيقاف تشغيل أنظمة المجموعات الخاملة دون فقدان العمل. نظرا لأن تطبيق العميل منفصل عن نظام المجموعة، فإنه لا يتأثر بإعادة تشغيل نظام المجموعة أو ترقياته، مما قد يتسبب عادة في فقدان جميع المتغيرات ومجموعات البيانات الموزعة المرنة وعناصر DataFrame المعرفة في دفتر ملاحظات.
إشعار
لتطوير Python باستخدام استعلامات SQL، توصي Databricks باستخدام Databricks SQL Connector ل Python بدلا من Databricks Connect. يعد Databricks SQL Connector ل Python أسهل في الإعداد من Databricks Connect. أيضا، تعمل وظائف توزيع وخطط Databricks Connect على جهازك المحلي، بينما تعمل المهام على موارد الحوسبة عن بعد. يمكن أن يجعل هذا من الصعب بشكل خاص تصحيح أخطاء وقت التشغيل. يرسل Databricks SQL Connector ل Python استعلامات SQL مباشرة إلى موارد الحوسبة عن بعد ويجلب النتائج.
المتطلبات
يسرد هذا القسم متطلبات Databricks Connect.
يتم دعم إصدارات وقت تشغيل Databricks التالية فقط:
- Databricks Runtime 12.2 LTS ML, Databricks Runtime 12.2 LTS
- Databricks Runtime 11.3 LTS ML, Databricks Runtime 11.3 LTS
- Databricks Runtime 10.4 LTS ML, Databricks Runtime 10.4 LTS
- Databricks Runtime 9.1 LTS ML, Databricks Runtime 9.1 LTS
- Databricks Runtime 7.3 LTS
يجب تثبيت Python 3 على جهاز التطوير الخاص بك، ويجب أن يكون الإصدار الثانوي من تثبيت العميل Python هو نفسه إصدار Python الثانوي من نظام مجموعة Azure Databricks. يعرض الجدول التالي إصدار Python المثبت مع كل وقت تشغيل Databricks.
إصدار وقت تشغيل Databricks إصدار Python 12.2 LTS ML، 12.2 LTS 3.9 11.3 LTS ML، 11.3 LTS 3.9 10.4 LTS ML، 10.4 LTS 3.8 9.1 LTS ML، 9.1 LTS 3.8 7.3 LTS 3.7 توصي Databricks بشدة بتنشيط بيئة Python الظاهرية لكل إصدار Python تستخدمه مع Databricks Connect. تساعد بيئات Python الظاهرية على التأكد من أنك تستخدم الإصدارات الصحيحة من Python وDatabricks Connect معا. يمكن أن يساعد هذا في تقليل الوقت المستغرق في حل المشكلات التقنية ذات الصلة.
على سبيل المثال، إذا كنت تستخدم venv على جهاز التطوير الخاص بك وكان نظام مجموعتك يقوم بتشغيل Python 3.9، فيجب عليك إنشاء
venvبيئة بهذا الإصدار. ينشئ الأمر المثال التالي البرامج النصية لتنشيطvenvبيئة باستخدام Python 3.9، ثم يضع هذا الأمر هذه البرامج النصية داخل مجلد مخفي يسمى.venvداخل دليل العمل الحالي:# Linux and macOS python3.9 -m venv ./.venv # Windows python3.9 -m venv .\.venvلاستخدام هذه البرامج النصية لتنشيط هذه
venvالبيئة، راجع كيفية عمل venvs.كمثال آخر، إذا كنت تستخدم Conda على جهاز التطوير الخاص بك وكان نظام مجموعتك يقوم بتشغيل Python 3.9، يجب عليك إنشاء بيئة Conda بهذا الإصدار، على سبيل المثال:
conda create --name dbconnect python=3.9لتنشيط بيئة Conda باسم البيئة هذا، قم بتشغيل
conda activate dbconnect.يجب أن يتطابق إصدار الحزمة الرئيسية والثانوية ل Databricks Connect دائما مع إصدار Databricks Runtime. توصي Databricks باستخدام أحدث حزمة من Databricks Connect التي تطابق إصدار Databricks Runtime الخاص بك. على سبيل المثال، عند استخدام نظام مجموعة Databricks Runtime 12.2 LTS، يجب عليك أيضا استخدام الحزمة
databricks-connect==12.2.*.إشعار
راجع ملاحظات إصدار Databricks Connect للحصول على قائمة بإصدارات Databricks Connect المتوفرة وتحديثات الصيانة.
Java Runtime Environment (JRE) 8. تم اختبار العميل باستخدام OpenJDK 8 JRE. لا يدعم العميل Java 11.
إشعار
في Windows، إذا رأيت خطأ تعذر على Databricks Connect العثور عليه winutils.exe، فشاهد يتعذر العثور على winutils.exe على Windows.
إعداد العميل
أكمل الخطوات التالية لإعداد العميل المحلي ل Databricks Connect.
إشعار
قبل البدء في إعداد عميل Databricks Connect المحلي، يجب أن تفي بمتطلبات Databricks Connect.
الخطوة 1: تثبيت عميل Databricks Connect
مع تنشيط بيئتك الظاهرية، قم بإلغاء تثبيت PySpark، إذا كان مثبتا بالفعل، عن طريق تشغيل
uninstallالأمر . هذا مطلوب لأن الحزمةdatabricks-connectتتعارض مع PySpark. للحصول على التفاصيل، راجع عمليات تثبيت PySpark المتعارضة. للتحقق مما إذا كان PySpark مثبتا بالفعل، قم بتشغيلshowالأمر .# Is PySpark already installed? pip3 show pyspark # Uninstall PySpark pip3 uninstall pysparkمع استمرار تنشيط بيئتك الظاهرية، قم بتثبيت عميل Databricks Connect عن طريق تشغيل
installالأمر .--upgradeاستخدم الخيار لترقية أي تثبيت عميل موجود إلى الإصدار المحدد.pip3 install --upgrade "databricks-connect==12.2.*" # Or X.Y.* to match your cluster version.إشعار
توصي Databricks بإلحاق رمز "dot-asterisk" لتحديد
databricks-connect==X.Y.*بدلا منdatabricks-connect=X.Y، للتأكد من تثبيت أحدث حزمة.
الخطوة 2: تكوين خصائص الاتصال
جمع خصائص التكوين التالية.
عنوان URL الخاص ب Azure Databricks لكل مساحة عمل. هذا هو أيضا نفس ما
https://يليه قيمة اسم مضيف الخادم للمجموعة الخاصة بك؛ راجع الحصول على تفاصيل الاتصال لمورد حساب Azure Databricks.رمز الوصول الشخصي الخاص بك في Azure Databricks أو الرمز المميز لمعرف Microsoft Entra (المعروف سابقا ب Azure Active Directory).
- بالنسبة لتمرير بيانات اعتماد Azure Data Lake Storage (ADLS)، يجب استخدام رمز مميز لمعرف Microsoft Entra. يتم دعم تمرير بيانات اعتماد معرف Microsoft Entra فقط على أنظمة المجموعات القياسية التي تقوم بتشغيل Databricks Runtime 7.3 LTS وما فوق، وهي غير متوافقة مع المصادقة الأساسية للخدمة.
- لمزيد من المعلومات حول المصادقة باستخدام الرموز المميزة لمعرف Microsoft Entra، راجع المصادقة باستخدام الرموز المميزة لمعرف Microsoft Entra.
معرف نظام المجموعة الخاص بك. يمكنك الحصول على معرف نظام المجموعة من عنوان URL. هنا معرف نظام المجموعة هو
1108-201635-xxxxxxxx. راجع أيضا عنوان URL للمجموعة والمعرف.
معرف المؤسسة الفريد لمساحة العمل الخاصة بك. راجع الحصول على معرفات لكائنات مساحة العمل.
المنفذ الذي يتصل به Databricks Connect على نظام المجموعة. المنفذ الافتراضي هو
15001. إذا تم تكوين نظام المجموعة لاستخدام منفذ مختلف، مثل8787الذي تم تقديمه في الإرشادات السابقة ل Azure Databricks، فاستخدم رقم المنفذ المكون.
تكوين الاتصال كما يلي.
يمكنك استخدام CLI أو تكوينات SQL أو متغيرات البيئة. أسبقية أساليب التكوين من الأعلى إلى الأدنى هي: مفاتيح تكوين SQL وCLI ومتغيرات البيئة.
CLI
شغّل
databricks-connect.databricks-connect configureيعرض الترخيص:
Copyright (2018) Databricks, Inc. This library (the "Software") may not be used except in connection with the Licensee's use of the Databricks Platform Services pursuant to an Agreement ...قبول قيم تكوين الترخيص والإمداد. بالنسبة إلى Databricks Host وDatabricks Token، أدخل عنوان URL لمساحة العمل ورمز الوصول الشخصي الذي لاحظته في الخطوة 1.
Do you accept the above agreement? [y/N] y Set new config values (leave input empty to accept default): Databricks Host [no current value, must start with https://]: <databricks-url> Databricks Token [no current value]: <databricks-token> Cluster ID (e.g., 0921-001415-jelly628) [no current value]: <cluster-id> Org ID (Azure-only, see ?o=orgId in URL) [0]: <org-id> Port [15001]: <port>إذا تلقيت رسالة تفيد بأن الرمز المميز لمعرف Microsoft Entra طويل جدا، يمكنك ترك حقل Databricks Token فارغا وإدخال الرمز المميز يدويا في
~/.databricks-connect.
تكوينات SQL أو متغيرات البيئة. يعرض الجدول التالي مفاتيح تكوين SQL ومتغيرات البيئة التي تتوافق مع خصائص التكوين التي لاحظتها في الخطوة 1. لتعيين مفتاح تكوين SQL، استخدم
sql("set config=value"). على سبيل المثال:sql("set spark.databricks.service.clusterId=0304-201045-abcdefgh").المعلمة مفتاح تكوين SQL اسم متغير البيئة مضيف Databricks spark.databricks.service.address DATABRICKS_ADDRESS رمز Databricks المميز spark.databricks.service.token DATABRICKS_API_TOKEN معرف نظام المجموعة spark.databricks.service.clusterId DATABRICKS_CLUSTER_ID معرف المؤسسة spark.databricks.service.orgId DATABRICKS_ORG_ID المنفذ spark.databricks.service.port DATABRICKS_PORT
مع استمرار تنشيط بيئتك الظاهرية، اختبر الاتصال ب Azure Databricks كما يلي.
databricks-connect testإذا لم يكن نظام المجموعة الذي قمت بتكوينه قيد التشغيل، يبدأ الاختبار نظام المجموعة الذي سيبقى قيد التشغيل حتى وقت تحديد تلقائي تم تكوينه. يجب أن يبدو الإخراج مشابهًا لما يلي:
* PySpark is installed at /.../.../pyspark * Checking java version java version "1.8..." Java(TM) SE Runtime Environment (build 1.8...) Java HotSpot(TM) 64-Bit Server VM (build 25..., mixed mode) * Testing scala command ../../.. ..:..:.. WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). ../../.. ..:..:.. WARN MetricsSystem: Using default name SparkStatusTracker for source because neither spark.metrics.namespace nor spark.app.id is set. ../../.. ..:..:.. WARN SparkServiceRPCClient: Now tracking server state for 5ab..., invalidating prev state ../../.. ..:..:.. WARN SparkServiceRPCClient: Syncing 129 files (176036 bytes) took 3003 ms Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /___/ .__/\_,_/_/ /_/\_\ version 2... /_/ Using Scala version 2.... (Java HotSpot(TM) 64-Bit Server VM, Java 1.8...) Type in expressions to have them evaluated. Type :help for more information. scala> spark.range(100).reduce(_ + _) Spark context Web UI available at https://... Spark context available as 'sc' (master = local[*], app id = local-...). Spark session available as 'spark'. View job details at <databricks-url>/?o=0#/setting/clusters/<cluster-id>/sparkUi View job details at <databricks-url>?o=0#/setting/clusters/<cluster-id>/sparkUi res0: Long = 4950 scala> :quit * Testing python command ../../.. ..:..:.. WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). ../../.. ..:..:.. WARN MetricsSystem: Using default name SparkStatusTracker for source because neither spark.metrics.namespace nor spark.app.id is set. ../../.. ..:..:.. WARN SparkServiceRPCClient: Now tracking server state for 5ab.., invalidating prev state View job details at <databricks-url>/?o=0#/setting/clusters/<cluster-id>/sparkUiإذا لم يتم عرض أي أخطاء متعلقة بالاتصال (
WARNالرسائل على ما يرام)، ثم قمت بالاتصال بنجاح.
استخدام Databricks Connect
يصف القسم كيفية تكوين IDE المفضل لديك أو خادم دفتر الملاحظات لاستخدام العميل ل Databricks Connect.
في هذا القسم:
- JupyterLab
- دفتر ملاحظات Jupyter الكلاسيكي
- PyCharm
- SparkR وRStudio Desktop
- sparklyr وRStudio Desktop
- IntelliJ (Scala أو Java)
- PyDev مع Eclipse
- كسوف
- SBT
- Spark shell
JupyterLab
إشعار
قبل البدء في استخدام Databricks Connect، يجب عليك تلبية المتطلبات وإعداد العميل ل Databricks Connect.
لاستخدام Databricks Connect مع JupyterLab وPython، اتبع هذه الإرشادات.
لتثبيت JupyterLab، مع تنشيط بيئة Python الظاهرية، قم بتشغيل الأمر التالي من المحطة الطرفية أو موجه الأوامر:
pip3 install jupyterlabلبدء JupyterLab في مستعرض الويب الخاص بك، قم بتشغيل الأمر التالي من بيئة Python الظاهرية التي تم تنشيطها:
jupyter labإذا لم يظهر JupyterLab في مستعرض الويب الخاص بك، فانسخ عنوان URL الذي يبدأ بالبيئة
localhostالظاهرية أو127.0.0.1منها، وأدخله في شريط عناوين مستعرض الويب الخاص بك.إنشاء دفتر ملاحظات جديد: في JupyterLab، انقر فوق File New Notebook في القائمة الرئيسية، وحدد Python 3 (ipykernel) وانقر فوق Select. > >
في الخلية الأولى لدفتر الملاحظات، أدخل التعليمات البرمجية المثال أو التعليمات البرمجية الخاصة بك. إذا كنت تستخدم التعليمات البرمجية الخاصة بك، على الأقل يجب إنشاء مثيل ل
SparkSession.builder.getOrCreate()، كما هو موضح في مثال التعليمات البرمجية.لتشغيل دفتر الملاحظات، انقر فوق تشغيل تشغيل > كافة الخلايا.
لتصحيح أخطاء دفتر الملاحظات، انقر فوق أيقونة الخطأ (تمكين مصحح الأخطاء) بجوار Python 3 (ipykernel) في شريط أدوات دفتر الملاحظات. قم بتعيين نقطة توقف واحدة أو أكثر، ثم انقر فوق تشغيل > كافة الخلايا.
لإيقاف تشغيل JupyterLab، انقر فوق إيقاف تشغيل الملف>. إذا كانت عملية JupyterLab لا تزال قيد التشغيل في المحطة الطرفية أو موجه الأوامر، فتوقف عن هذه العملية بالضغط
Ctrl + cثم الدخولyللتأكيد.
للحصول على إرشادات تصحيح أكثر تحديدا، راجع مصحح الأخطاء.
دفتر ملاحظات Jupyter الكلاسيكي
إشعار
قبل البدء في استخدام Databricks Connect، يجب عليك تلبية المتطلبات وإعداد العميل ل Databricks Connect.
يضيف البرنامج النصي للتكوين ل Databricks Connect الحزمة تلقائيا إلى تكوين مشروعك. للبدء في نواة Python، قم بتشغيل:
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
لتمكين الاختصار %sql لتشغيل استعلامات SQL وتصورها، استخدم القصاصة البرمجية التالية:
from IPython.core.magic import line_magic, line_cell_magic, Magics, magics_class
@magics_class
class DatabricksConnectMagics(Magics):
@line_cell_magic
def sql(self, line, cell=None):
if cell and line:
raise ValueError("Line must be empty for cell magic", line)
try:
from autovizwidget.widget.utils import display_dataframe
except ImportError:
print("Please run `pip install autovizwidget` to enable the visualization widget.")
display_dataframe = lambda x: x
return display_dataframe(self.get_spark().sql(cell or line).toPandas())
def get_spark(self):
user_ns = get_ipython().user_ns
if "spark" in user_ns:
return user_ns["spark"]
else:
from pyspark.sql import SparkSession
user_ns["spark"] = SparkSession.builder.getOrCreate()
return user_ns["spark"]
ip = get_ipython()
ip.register_magics(DatabricksConnectMagics)
تعليمة Visual Studio برمجية
إشعار
قبل البدء في استخدام Databricks Connect، يجب عليك تلبية المتطلبات وإعداد العميل ل Databricks Connect.
لاستخدام Databricks Connect مع Visual Studio Code، قم بما يلي:
تحقق من تثبيت ملحق Python.
افتح لوحة الأوامر (Command+Shift+P على macOS وCtrl +Shift+P على Windows/Linux).
حدد مترجم Python. انتقل إلى إعدادات تفضيلات التعليمات >البرمجية>، واختر إعدادات python.
شغّل
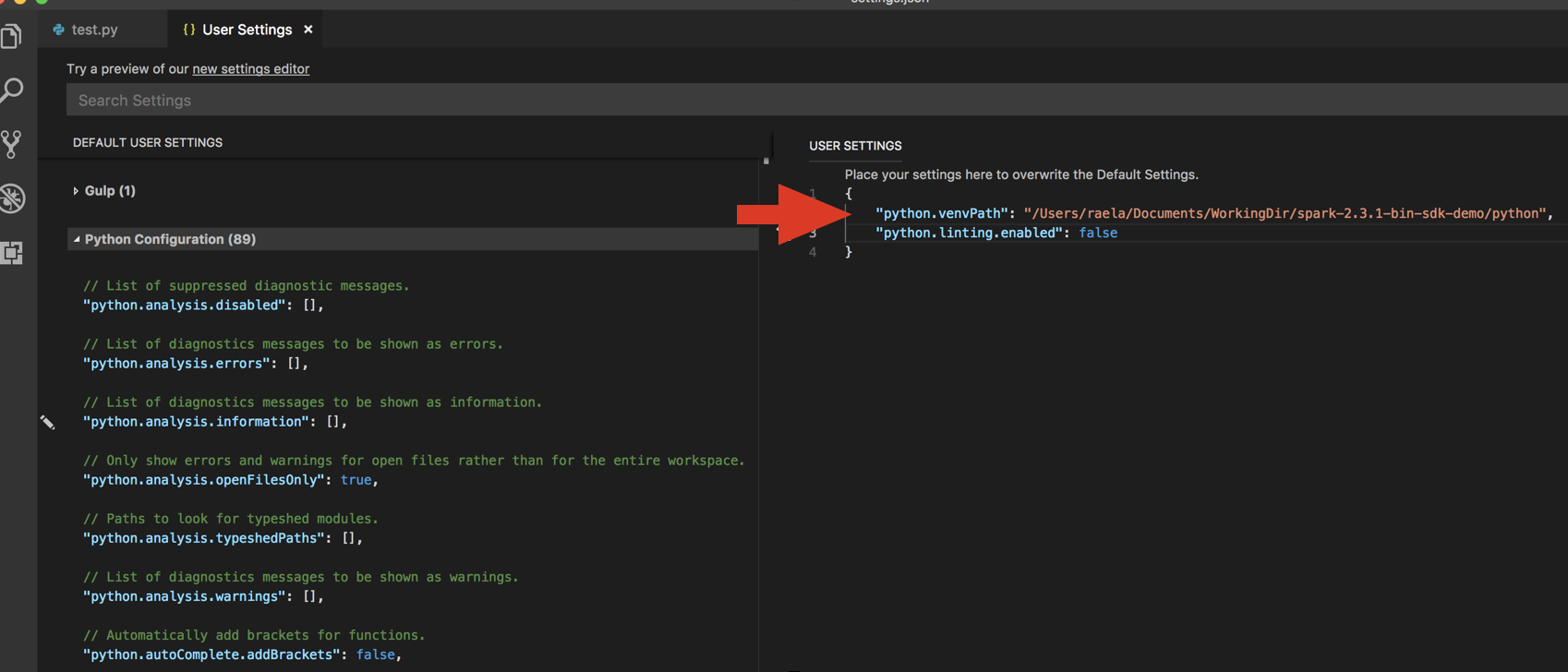
databricks-connect get-jar-dir.أضف الدليل الذي تم إرجاعه من الأمر إلى User Settings JSON ضمن
python.venvPath. يجب إضافة هذا إلى تكوين Python.تعطيل أداة التحليل. انقر فوق ... على الجانب الأيسر وقم بتحرير إعدادات json. الإعدادات المعدلة هي كما يلي:
إذا كان يعمل مع بيئة ظاهرية، وهي الطريقة الموصى بها لتطوير Python في VS Code، في نوع
select python interpreterلوحة الأوامر وأشر إلى بيئتك التي تطابق إصدار Python لنظام المجموعة.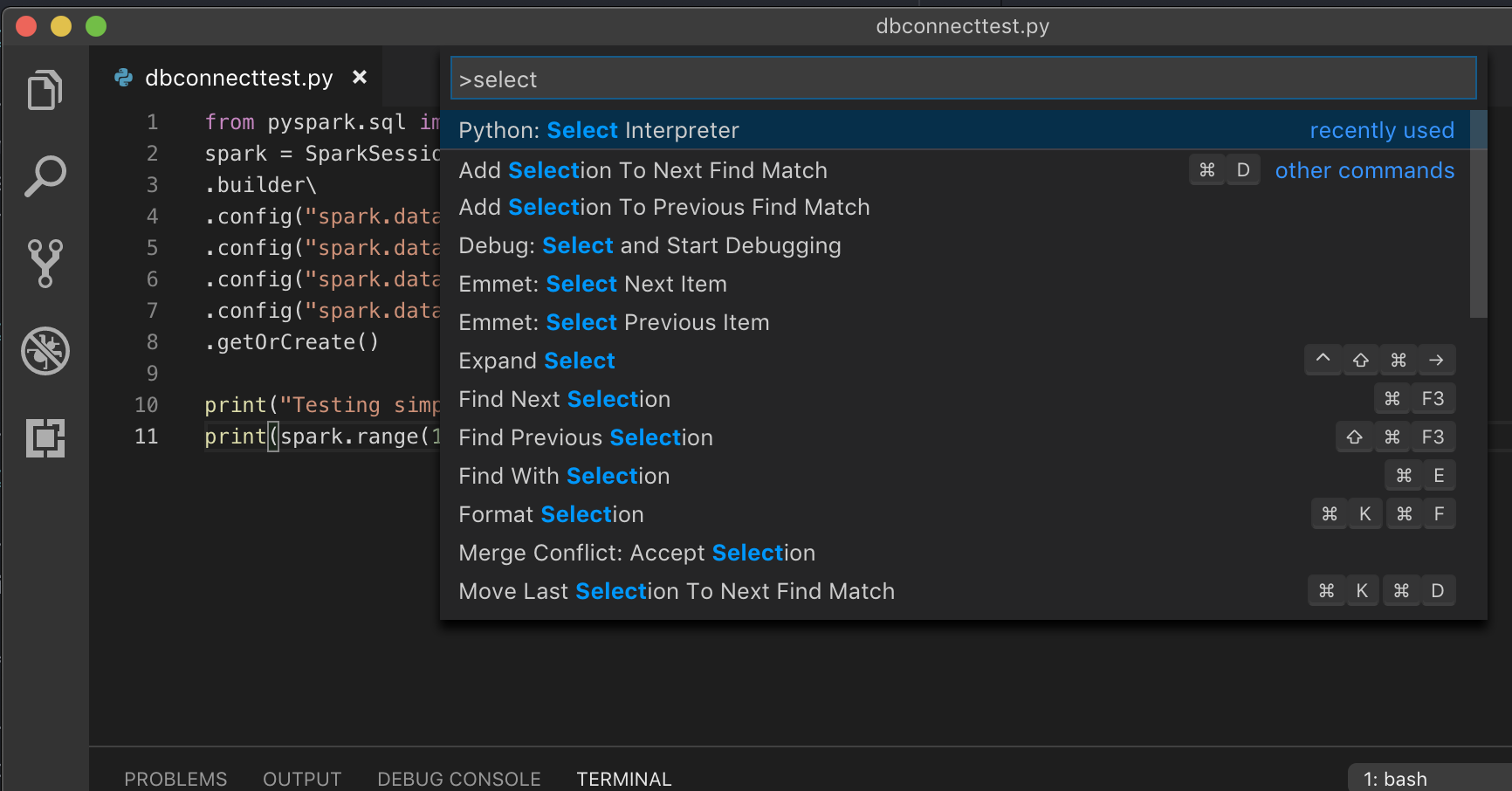
على سبيل المثال، إذا كانت مجموعتك Python 3.9، يجب أن تكون بيئة التطوير الخاصة بك Python 3.9.
PyCharm
إشعار
قبل البدء في استخدام Databricks Connect، يجب عليك تلبية المتطلبات وإعداد العميل ل Databricks Connect.
يضيف البرنامج النصي للتكوين ل Databricks Connect الحزمة تلقائيا إلى تكوين مشروعك.
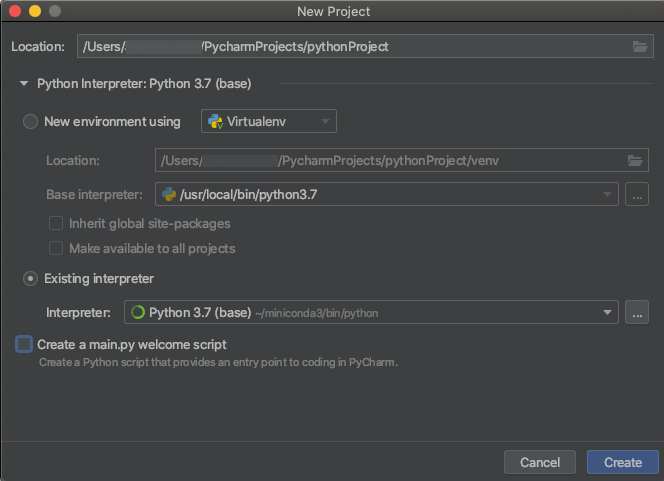
مجموعات Python 3
عند إنشاء مشروع PyCharm، حدد المترجم الموجود. من القائمة المنسدلة، حدد بيئة Conda التي أنشأتها (راجع المتطلبات).
انتقل إلى تشغيل > تكوينات التحرير.
إضافة
PYSPARK_PYTHON=python3كمتغير بيئة.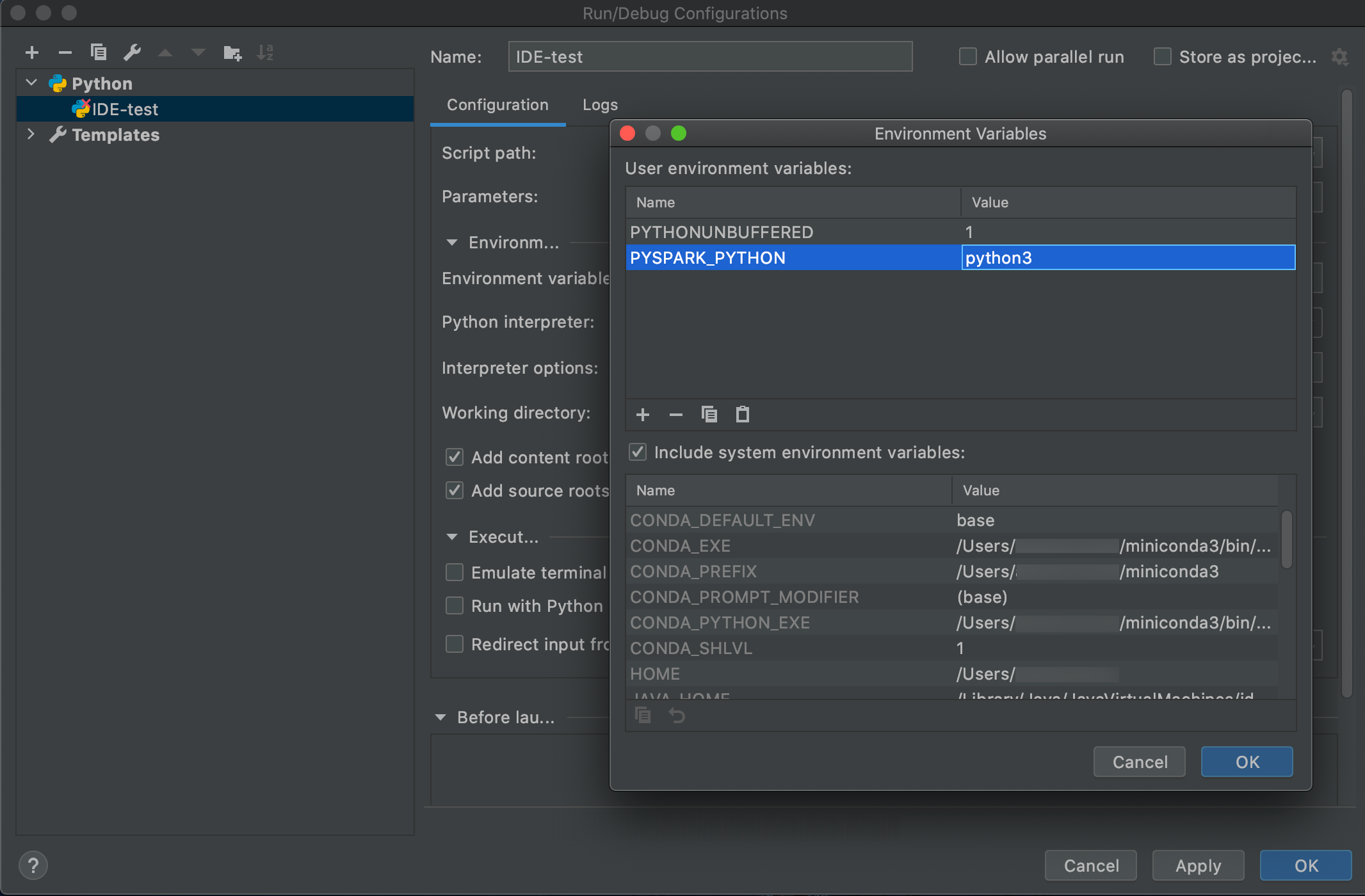
SparkR وRStudio Desktop
إشعار
قبل البدء في استخدام Databricks Connect، يجب عليك تلبية المتطلبات وإعداد العميل ل Databricks Connect.
لاستخدام Databricks Connect مع SparkR وRStudio Desktop، قم بما يلي:
قم بتنزيل توزيع مصدر مفتوح Spark وفكه على جهاز التطوير الخاص بك. اختر نفس الإصدار كما هو الحال في مجموعة Azure Databricks (Hadoop 2.7).
شغّل
databricks-connect get-jar-dir. يقوم هذا الأمر بإرجاع مسار مثل/usr/local/lib/python3.5/dist-packages/pyspark/jars. انسخ مسار ملف دليل واحد أعلى مسار ملف دليل JAR، على سبيل المثال،/usr/local/lib/python3.5/dist-packages/pyspark، وهوSPARK_HOMEالدليل.قم بتكوين مسار Spark lib وSpark home عن طريق إضافتهم إلى الجزء العلوي من البرنامج النصي R. اضبط
<spark-lib-path>على الدليل حيث قمت بفك حزمة مصدر مفتوح Spark في الخطوة 1. تعيين<spark-home-path>إلى دليل Databricks Connect من الخطوة 2.# Point to the OSS package path, e.g., /path/to/.../spark-2.4.0-bin-hadoop2.7 library(SparkR, lib.loc = .libPaths(c(file.path('<spark-lib-path>', 'R', 'lib'), .libPaths()))) # Point to the Databricks Connect PySpark installation, e.g., /path/to/.../pyspark Sys.setenv(SPARK_HOME = "<spark-home-path>")بدء جلسة Spark وبدء تشغيل أوامر SparkR.
sparkR.session() df <- as.DataFrame(faithful) head(df) df1 <- dapply(df, function(x) { x }, schema(df)) collect(df1)
sparklyr وRStudio Desktop
إشعار
قبل البدء في استخدام Databricks Connect، يجب عليك تلبية المتطلبات وإعداد العميل ل Databricks Connect.
يمكنك نسخ التعليمات البرمجية المعتمدة على sparklyr التي قمت بتطويرها محليا باستخدام Databricks Connect وتشغيلها في دفتر ملاحظات Azure Databricks أو خادم RStudio المستضاف في مساحة عمل Azure Databricks مع الحد الأدنى من تغييرات التعليمات البرمجية أو بدونها.
في هذا القسم:
المتطلبات
- sparklyr 1.2 أو أعلى.
- Databricks Runtime 7.3 LTS أو أعلى مع الإصدار المطابق من Databricks Connect.
تثبيت sparklyr وتكوينه واستخدامه
في RStudio Desktop، قم بتثبيت sparklyr 1.2 أو أعلى من CRAN أو قم بتثبيت أحدث إصدار رئيسي من GitHub.
# Install from CRAN install.packages("sparklyr") # Or install the latest master version from GitHub install.packages("devtools") devtools::install_github("sparklyr/sparklyr")قم بتنشيط بيئة Python مع تثبيت الإصدار الصحيح من Databricks Connect وتشغيل الأمر التالي في المحطة الطرفية للحصول على
<spark-home-path>:databricks-connect get-spark-homeبدء جلسة Spark وبدء تشغيل أوامر sparklyr.
library(sparklyr) sc <- spark_connect(method = "databricks", spark_home = "<spark-home-path>") iris_tbl <- copy_to(sc, iris, overwrite = TRUE) library(dplyr) src_tbls(sc) iris_tbl %>% countأغلق الاتصال.
spark_disconnect(sc)
الموارد
لمزيد من المعلومات، راجع sparklyr GitHub README.
للحصول على أمثلة التعليمات البرمجية، راجع sparklyr.
قيود sparklyr وRStudio Desktop
الميزات التالية غير مدعومة:
- واجهات برمجة تطبيقات دفق sparklyr
- واجهات برمجة تطبيقات sparklyr ML
- واجهات برمجة تطبيقات المكنسة
- وضع التسلسل csv_file
- إرسال spark
IntelliJ (Scala أو Java)
إشعار
قبل البدء في استخدام Databricks Connect، يجب عليك تلبية المتطلبات وإعداد العميل ل Databricks Connect.
لاستخدام Databricks Connect مع IntelliJ (Scala أو Java)، قم بما يلي:
شغّل
databricks-connect get-jar-dir.أشر إلى التبعيات إلى الدليل الذي تم إرجاعه من الأمر . انتقل إلى File > Project Structure > Modules > Dependencies > '+' sign > JARs أو Directories.
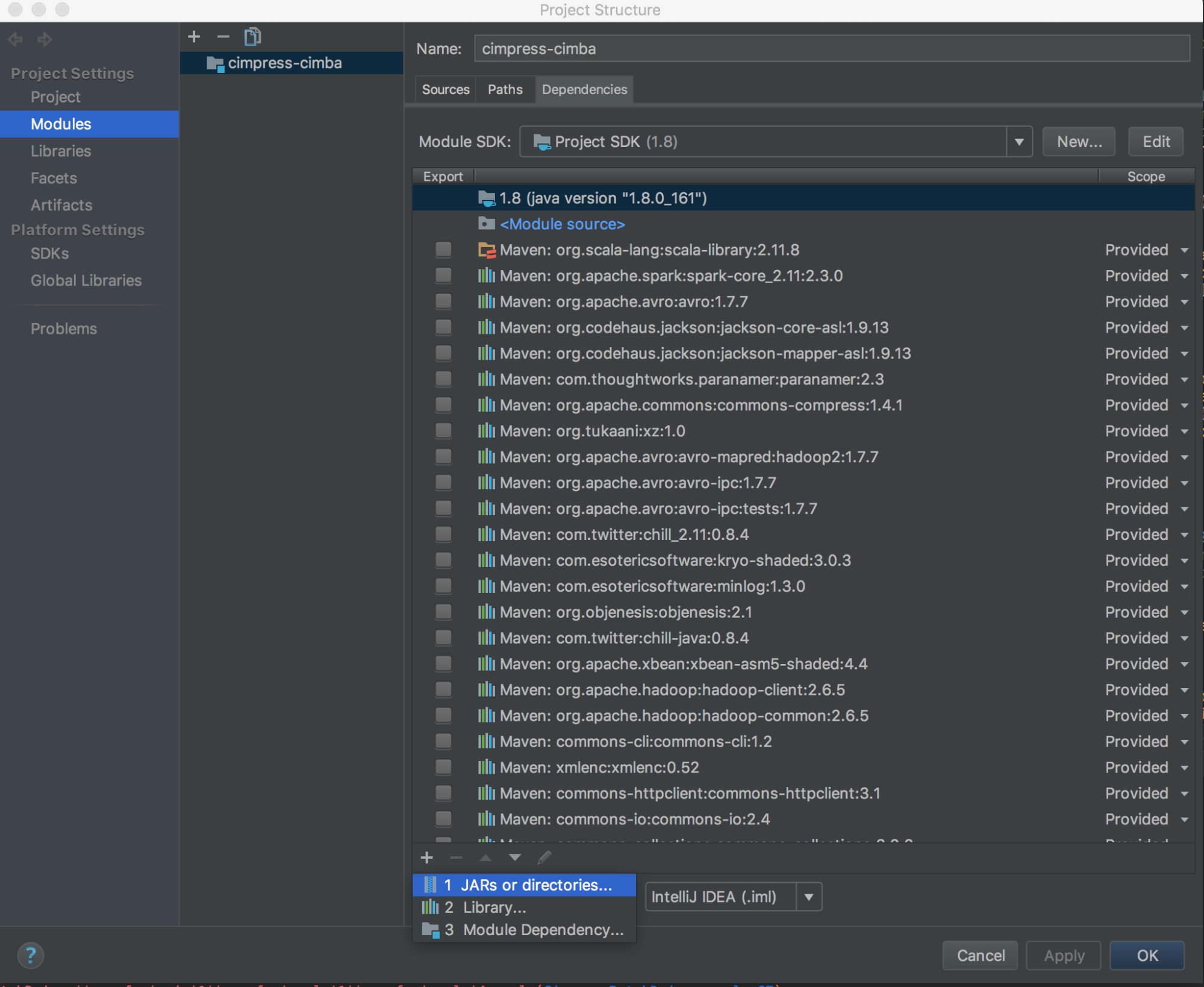
لتجنب التعارضات، نوصي بشدة بإزالة أي عمليات تثبيت Spark أخرى من مسار الفصل الخاص بك. إذا لم يكن ذلك ممكنا، فتأكد من أن JARs التي تضيفها موجودة في مقدمة مسار الفئة. على وجه الخصوص، يجب أن تكون متقدمة على أي إصدار مثبت آخر من Spark (وإلا ستستخدم إما أحد إصدارات Spark الأخرى هذه وتشغيلها محليا أو طرح
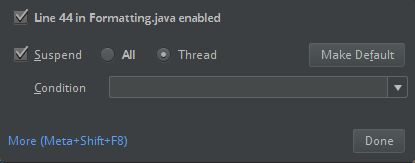
ClassDefNotFoundError).تحقق من إعداد خيار التقسيم في IntelliJ. الإعداد الافتراضي هو الكل وسيتسبب في مهلات الشبكة إذا قمت بتعيين نقاط توقف لتصحيح الأخطاء. قم بتعيينه إلى مؤشر الترابط لتجنب إيقاف مؤشرات ترابط الشبكة الخلفية.
PyDev مع Eclipse
إشعار
قبل البدء في استخدام Databricks Connect، يجب عليك تلبية المتطلبات وإعداد العميل ل Databricks Connect.
لاستخدام Databricks Connect وPyDev مع Eclipse، اتبع هذه الإرشادات.
- تشغيل Eclipse.
- إنشاء مشروع: انقر فوق ملف مشروع جديد PyDev > PyDev Project، ثم انقر فوق التالي.> > >
- حدد اسم المشروع.
- بالنسبة لمحتويات Project، حدد المسار إلى بيئة Python الظاهرية.
- انقر فوق الرجاء تكوين مترجم قبل المتابعة.
- انقر فوق التكوين اليدوي.
- انقر فوق استعراض جديد > ل python/pypy exe.
- استعرض وصولا إلى وحدد المسار الكامل إلى مترجم Python المشار إليه من البيئة الظاهرية، ثم انقر فوق فتح.
- في مربع الحوار تحديد مترجم ، انقر فوق موافق.
- في مربع الحوار التحديد المطلوب ، انقر فوق موافق.
- في مربع الحوار تفضيلات ، انقر فوق تطبيق وإغلاق.
- في مربع الحوار مشروع PyDev، انقر فوق إنهاء.
- انقر فوق فتح منظور.
- أضف إلى المشروع ملف تعليمة Python البرمجية (
.py) الذي يحتوي على التعليمات البرمجية المثال أو التعليمات البرمجية الخاصة بك. إذا كنت تستخدم التعليمات البرمجية الخاصة بك، على الأقل يجب إنشاء مثيل لSparkSession.builder.getOrCreate()، كما هو موضح في مثال التعليمات البرمجية. - مع فتح ملف التعليمات البرمجية Python، قم بتعيين أي نقاط توقف حيث تريد أن تتوقف التعليمات البرمجية الخاصة بك مؤقتا أثناء التشغيل.
- انقر فوق تشغيل > أو تشغيل > تصحيح الأخطاء.
للحصول على إرشادات تشغيل وتصحيح أكثر تحديدا، راجع تشغيل برنامج.
Eclipse
إشعار
قبل البدء في استخدام Databricks Connect، يجب عليك تلبية المتطلبات وإعداد العميل ل Databricks Connect.
لاستخدام Databricks Connect وEclipse، قم بما يلي:
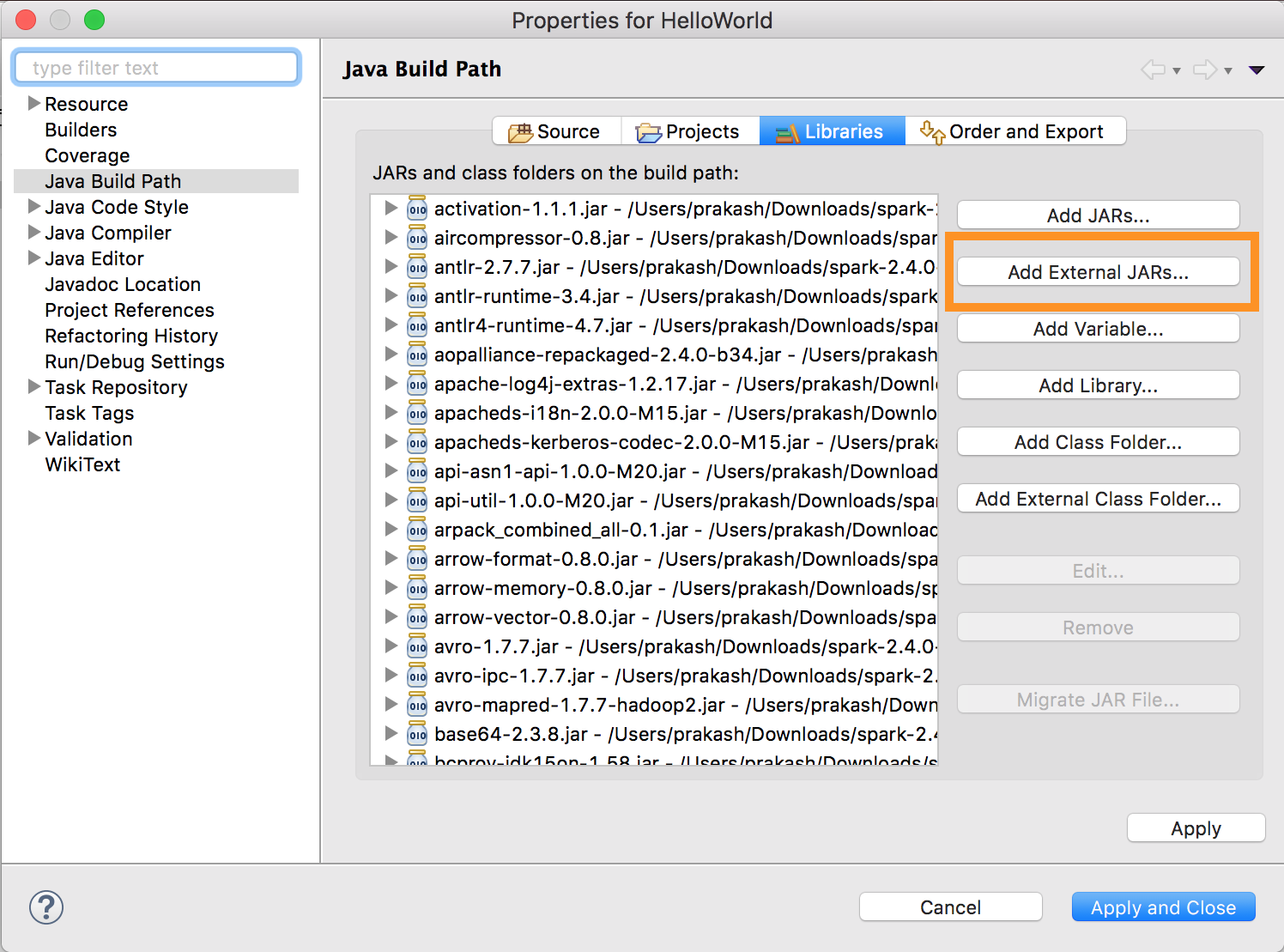
شغّل
databricks-connect get-jar-dir.توجيه تكوين JARs الخارجي إلى الدليل الذي تم إرجاعه من الأمر . انتقل إلى قائمة Project Properties > Java Build Path > Libraries > Add External Jars>.
لتجنب التعارضات، نوصي بشدة بإزالة أي عمليات تثبيت Spark أخرى من مسار الفصل الخاص بك. إذا لم يكن ذلك ممكنا، فتأكد من أن JARs التي تضيفها موجودة في مقدمة مسار الفئة. على وجه الخصوص، يجب أن تكون متقدمة على أي إصدار مثبت آخر من Spark (وإلا ستستخدم إما أحد إصدارات Spark الأخرى هذه وتشغيلها محليا أو طرح
ClassDefNotFoundError).
SBT
إشعار
قبل البدء في استخدام Databricks Connect، يجب عليك تلبية المتطلبات وإعداد العميل ل Databricks Connect.
لاستخدام Databricks Connect مع SBT، يجب تكوين الملف الخاص بك build.sbt للارتباط مقابل Databricks Connect JARs بدلا من تبعية مكتبة Spark المعتادة. يمكنك القيام بذلك مع unmanagedBase التوجيه في ملف البناء المثال التالي، والذي يفترض تطبيق Scala الذي يحتوي على كائن com.example.Test رئيسي:
build.sbt
name := "hello-world"
version := "1.0"
scalaVersion := "2.11.6"
// this should be set to the path returned by ``databricks-connect get-jar-dir``
unmanagedBase := new java.io.File("/usr/local/lib/python2.7/dist-packages/pyspark/jars")
mainClass := Some("com.example.Test")
Spark shell
إشعار
قبل البدء في استخدام Databricks Connect، يجب عليك تلبية المتطلبات وإعداد العميل ل Databricks Connect.
لاستخدام Databricks Connect مع Spark shell وPython أو Scala، اتبع هذه الإرشادات.
مع تنشيط البيئة الظاهرية، تأكد من تشغيل
databricks-connect testالأمر بنجاح في إعداد العميل.مع تنشيط بيئتك الظاهرية، ابدأ تشغيل Spark shell. بالنسبة إلى Python، قم بتشغيل
pysparkالأمر . بالنسبة إلى Scala، قم بتشغيلspark-shellالأمر .# For Python: pyspark# For Scala: spark-shellيظهر Spark shell، على سبيل المثال ل Python:
Python 3... (v3...) [Clang 6... (clang-6...)] on darwin Type "help", "copyright", "credits" or "license" for more information. Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). ../../.. ..:..:.. WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /__ / .__/\_,_/_/ /_/\_\ version 3.... /_/ Using Python version 3... (v3...) Spark context Web UI available at http://...:... Spark context available as 'sc' (master = local[*], app id = local-...). SparkSession available as 'spark'. >>>بالنسبة إلى Scala:
Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). ../../.. ..:..:.. WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Spark context Web UI available at http://... Spark context available as 'sc' (master = local[*], app id = local-...). Spark session available as 'spark'. Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /___/ .__/\_,_/_/ /_/\_\ version 3... /_/ Using Scala version 2... (OpenJDK 64-Bit Server VM, Java 1.8...) Type in expressions to have them evaluated. Type :help for more information. scala>راجع التحليل التفاعلي باستخدام Spark Shell للحصول على معلومات حول كيفية استخدام Spark shell مع Python أو Scala لتشغيل الأوامر على مجموعتك.
استخدم المتغير المضمن
sparkلتمثيل علىSparkSessionنظام المجموعة قيد التشغيل، على سبيل المثال ل Python:>>> df = spark.read.table("samples.nyctaxi.trips") >>> df.show(5) +--------------------+---------------------+-------------+-----------+----------+-----------+ |tpep_pickup_datetime|tpep_dropoff_datetime|trip_distance|fare_amount|pickup_zip|dropoff_zip| +--------------------+---------------------+-------------+-----------+----------+-----------+ | 2016-02-14 16:52:13| 2016-02-14 17:16:04| 4.94| 19.0| 10282| 10171| | 2016-02-04 18:44:19| 2016-02-04 18:46:00| 0.28| 3.5| 10110| 10110| | 2016-02-17 17:13:57| 2016-02-17 17:17:55| 0.7| 5.0| 10103| 10023| | 2016-02-18 10:36:07| 2016-02-18 10:41:45| 0.8| 6.0| 10022| 10017| | 2016-02-22 14:14:41| 2016-02-22 14:31:52| 4.51| 17.0| 10110| 10282| +--------------------+---------------------+-------------+-----------+----------+-----------+ only showing top 5 rowsبالنسبة إلى Scala:
>>> val df = spark.read.table("samples.nyctaxi.trips") >>> df.show(5) +--------------------+---------------------+-------------+-----------+----------+-----------+ |tpep_pickup_datetime|tpep_dropoff_datetime|trip_distance|fare_amount|pickup_zip|dropoff_zip| +--------------------+---------------------+-------------+-----------+----------+-----------+ | 2016-02-14 16:52:13| 2016-02-14 17:16:04| 4.94| 19.0| 10282| 10171| | 2016-02-04 18:44:19| 2016-02-04 18:46:00| 0.28| 3.5| 10110| 10110| | 2016-02-17 17:13:57| 2016-02-17 17:17:55| 0.7| 5.0| 10103| 10023| | 2016-02-18 10:36:07| 2016-02-18 10:41:45| 0.8| 6.0| 10022| 10017| | 2016-02-22 14:14:41| 2016-02-22 14:31:52| 4.51| 17.0| 10110| 10282| +--------------------+---------------------+-------------+-----------+----------+-----------+ only showing top 5 rowsلإيقاف Spark shell، اضغط
Ctrl + dأو ، أوCtrl + zقم بتشغيل الأمرquit()أوexit()ل Python أو:q:quitل Scala.
أمثلة التعليمات البرمجية
يستعلم مثال التعليمات البرمجية البسيط هذا عن الجدول المحدد ثم يعرض أول 5 صفوف للجدول المحدد. لاستخدام جدول مختلف، اضبط الاستدعاء إلى spark.read.table.
from pyspark.sql.session import SparkSession
spark = SparkSession.builder.getOrCreate()
df = spark.read.table("samples.nyctaxi.trips")
df.show(5)
يقوم مثال التعليمات البرمجية الأطول هذا بالآتي:
- إنشاء DataFrame في الذاكرة.
- إنشاء جدول بالاسم
zzz_demo_temps_tableداخلdefaultالمخطط. إذا كان الجدول بهذا الاسم موجودا بالفعل، يتم حذف الجدول أولا. لاستخدام مخطط أو جدول مختلف، اضبط الاستدعاءات إلىspark.sqlأوtemps.write.saveAsTableأو كليهما. - يحفظ محتويات DataFrame في الجدول.
SELECTتشغيل استعلام على محتويات الجدول.- إظهار نتيجة الاستعلام.
- حذف الجدول.
Python
from pyspark.sql import SparkSession
from pyspark.sql.types import *
from datetime import date
spark = SparkSession.builder.appName('temps-demo').getOrCreate()
# Create a Spark DataFrame consisting of high and low temperatures
# by airport code and date.
schema = StructType([
StructField('AirportCode', StringType(), False),
StructField('Date', DateType(), False),
StructField('TempHighF', IntegerType(), False),
StructField('TempLowF', IntegerType(), False)
])
data = [
[ 'BLI', date(2021, 4, 3), 52, 43],
[ 'BLI', date(2021, 4, 2), 50, 38],
[ 'BLI', date(2021, 4, 1), 52, 41],
[ 'PDX', date(2021, 4, 3), 64, 45],
[ 'PDX', date(2021, 4, 2), 61, 41],
[ 'PDX', date(2021, 4, 1), 66, 39],
[ 'SEA', date(2021, 4, 3), 57, 43],
[ 'SEA', date(2021, 4, 2), 54, 39],
[ 'SEA', date(2021, 4, 1), 56, 41]
]
temps = spark.createDataFrame(data, schema)
# Create a table on the Databricks cluster and then fill
# the table with the DataFrame's contents.
# If the table already exists from a previous run,
# delete it first.
spark.sql('USE default')
spark.sql('DROP TABLE IF EXISTS zzz_demo_temps_table')
temps.write.saveAsTable('zzz_demo_temps_table')
# Query the table on the Databricks cluster, returning rows
# where the airport code is not BLI and the date is later
# than 2021-04-01. Group the results and order by high
# temperature in descending order.
df_temps = spark.sql("SELECT * FROM zzz_demo_temps_table " \
"WHERE AirportCode != 'BLI' AND Date > '2021-04-01' " \
"GROUP BY AirportCode, Date, TempHighF, TempLowF " \
"ORDER BY TempHighF DESC")
df_temps.show()
# Results:
#
# +-----------+----------+---------+--------+
# |AirportCode| Date|TempHighF|TempLowF|
# +-----------+----------+---------+--------+
# | PDX|2021-04-03| 64| 45|
# | PDX|2021-04-02| 61| 41|
# | SEA|2021-04-03| 57| 43|
# | SEA|2021-04-02| 54| 39|
# +-----------+----------+---------+--------+
# Clean up by deleting the table from the Databricks cluster.
spark.sql('DROP TABLE zzz_demo_temps_table')
Scala
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.types._
import org.apache.spark.sql.Row
import java.sql.Date
object Demo {
def main(args: Array[String]) {
val spark = SparkSession.builder.master("local").getOrCreate()
// Create a Spark DataFrame consisting of high and low temperatures
// by airport code and date.
val schema = StructType(Array(
StructField("AirportCode", StringType, false),
StructField("Date", DateType, false),
StructField("TempHighF", IntegerType, false),
StructField("TempLowF", IntegerType, false)
))
val data = List(
Row("BLI", Date.valueOf("2021-04-03"), 52, 43),
Row("BLI", Date.valueOf("2021-04-02"), 50, 38),
Row("BLI", Date.valueOf("2021-04-01"), 52, 41),
Row("PDX", Date.valueOf("2021-04-03"), 64, 45),
Row("PDX", Date.valueOf("2021-04-02"), 61, 41),
Row("PDX", Date.valueOf("2021-04-01"), 66, 39),
Row("SEA", Date.valueOf("2021-04-03"), 57, 43),
Row("SEA", Date.valueOf("2021-04-02"), 54, 39),
Row("SEA", Date.valueOf("2021-04-01"), 56, 41)
)
val rdd = spark.sparkContext.makeRDD(data)
val temps = spark.createDataFrame(rdd, schema)
// Create a table on the Databricks cluster and then fill
// the table with the DataFrame's contents.
// If the table already exists from a previous run,
// delete it first.
spark.sql("USE default")
spark.sql("DROP TABLE IF EXISTS zzz_demo_temps_table")
temps.write.saveAsTable("zzz_demo_temps_table")
// Query the table on the Databricks cluster, returning rows
// where the airport code is not BLI and the date is later
// than 2021-04-01. Group the results and order by high
// temperature in descending order.
val df_temps = spark.sql("SELECT * FROM zzz_demo_temps_table " +
"WHERE AirportCode != 'BLI' AND Date > '2021-04-01' " +
"GROUP BY AirportCode, Date, TempHighF, TempLowF " +
"ORDER BY TempHighF DESC")
df_temps.show()
// Results:
//
// +-----------+----------+---------+--------+
// |AirportCode| Date|TempHighF|TempLowF|
// +-----------+----------+---------+--------+
// | PDX|2021-04-03| 64| 45|
// | PDX|2021-04-02| 61| 41|
// | SEA|2021-04-03| 57| 43|
// | SEA|2021-04-02| 54| 39|
// +-----------+----------+---------+--------+
// Clean up by deleting the table from the Databricks cluster.
spark.sql("DROP TABLE zzz_demo_temps_table")
}
}
Java
import java.util.ArrayList;
import java.util.List;
import java.sql.Date;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.types.*;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.RowFactory;
import org.apache.spark.sql.Dataset;
public class App {
public static void main(String[] args) throws Exception {
SparkSession spark = SparkSession
.builder()
.appName("Temps Demo")
.config("spark.master", "local")
.getOrCreate();
// Create a Spark DataFrame consisting of high and low temperatures
// by airport code and date.
StructType schema = new StructType(new StructField[] {
new StructField("AirportCode", DataTypes.StringType, false, Metadata.empty()),
new StructField("Date", DataTypes.DateType, false, Metadata.empty()),
new StructField("TempHighF", DataTypes.IntegerType, false, Metadata.empty()),
new StructField("TempLowF", DataTypes.IntegerType, false, Metadata.empty()),
});
List<Row> dataList = new ArrayList<Row>();
dataList.add(RowFactory.create("BLI", Date.valueOf("2021-04-03"), 52, 43));
dataList.add(RowFactory.create("BLI", Date.valueOf("2021-04-02"), 50, 38));
dataList.add(RowFactory.create("BLI", Date.valueOf("2021-04-01"), 52, 41));
dataList.add(RowFactory.create("PDX", Date.valueOf("2021-04-03"), 64, 45));
dataList.add(RowFactory.create("PDX", Date.valueOf("2021-04-02"), 61, 41));
dataList.add(RowFactory.create("PDX", Date.valueOf("2021-04-01"), 66, 39));
dataList.add(RowFactory.create("SEA", Date.valueOf("2021-04-03"), 57, 43));
dataList.add(RowFactory.create("SEA", Date.valueOf("2021-04-02"), 54, 39));
dataList.add(RowFactory.create("SEA", Date.valueOf("2021-04-01"), 56, 41));
Dataset<Row> temps = spark.createDataFrame(dataList, schema);
// Create a table on the Databricks cluster and then fill
// the table with the DataFrame's contents.
// If the table already exists from a previous run,
// delete it first.
spark.sql("USE default");
spark.sql("DROP TABLE IF EXISTS zzz_demo_temps_table");
temps.write().saveAsTable("zzz_demo_temps_table");
// Query the table on the Databricks cluster, returning rows
// where the airport code is not BLI and the date is later
// than 2021-04-01. Group the results and order by high
// temperature in descending order.
Dataset<Row> df_temps = spark.sql("SELECT * FROM zzz_demo_temps_table " +
"WHERE AirportCode != 'BLI' AND Date > '2021-04-01' " +
"GROUP BY AirportCode, Date, TempHighF, TempLowF " +
"ORDER BY TempHighF DESC");
df_temps.show();
// Results:
//
// +-----------+----------+---------+--------+
// |AirportCode| Date|TempHighF|TempLowF|
// +-----------+----------+---------+--------+
// | PDX|2021-04-03| 64| 45|
// | PDX|2021-04-02| 61| 41|
// | SEA|2021-04-03| 57| 43|
// | SEA|2021-04-02| 54| 39|
// +-----------+----------+---------+--------+
// Clean up by deleting the table from the Databricks cluster.
spark.sql("DROP TABLE zzz_demo_temps_table");
}
}
العمل مع التبعيات
عادة ما يكون للفئة الرئيسية أو ملف Python ملفات وملفات تبعية أخرى. يمكنك إضافة مثل هذه التبعية JARs والملفات عن طريق الاتصال sparkContext.addJar("path-to-the-jar") أو sparkContext.addPyFile("path-to-the-file"). يمكنك أيضا إضافة ملفات البيض وملفات zip مع الواجهة addPyFile() . في كل مرة تقوم فيها بتشغيل التعليمات البرمجية في IDE الخاص بك، يتم تثبيت التبعية JARs والملفات على نظام المجموعة.
Python
from lib import Foo
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
sc = spark.sparkContext
#sc.setLogLevel("INFO")
print("Testing simple count")
print(spark.range(100).count())
print("Testing addPyFile isolation")
sc.addPyFile("lib.py")
print(sc.parallelize(range(10)).map(lambda i: Foo(2)).collect())
class Foo(object):
def __init__(self, x):
self.x = x
Python + Java UDFs
from pyspark.sql import SparkSession
from pyspark.sql.column import _to_java_column, _to_seq, Column
## In this example, udf.jar contains compiled Java / Scala UDFs:
#package com.example
#
#import org.apache.spark.sql._
#import org.apache.spark.sql.expressions._
#import org.apache.spark.sql.functions.udf
#
#object Test {
# val plusOne: UserDefinedFunction = udf((i: Long) => i + 1)
#}
spark = SparkSession.builder \
.config("spark.jars", "/path/to/udf.jar") \
.getOrCreate()
sc = spark.sparkContext
def plus_one_udf(col):
f = sc._jvm.com.example.Test.plusOne()
return Column(f.apply(_to_seq(sc, [col], _to_java_column)))
sc._jsc.addJar("/path/to/udf.jar")
spark.range(100).withColumn("plusOne", plus_one_udf("id")).show()
Scala
package com.example
import org.apache.spark.sql.SparkSession
case class Foo(x: String)
object Test {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
...
.getOrCreate();
spark.sparkContext.setLogLevel("INFO")
println("Running simple show query...")
spark.read.format("parquet").load("/tmp/x").show()
println("Running simple UDF query...")
spark.sparkContext.addJar("./target/scala-2.11/hello-world_2.11-1.0.jar")
spark.udf.register("f", (x: Int) => x + 1)
spark.range(10).selectExpr("f(id)").show()
println("Running custom objects query...")
val objs = spark.sparkContext.parallelize(Seq(Foo("bye"), Foo("hi"))).collect()
println(objs.toSeq)
}
}
الوصول إلى أدوات Databricks المساعدة
يصف هذا القسم كيفية استخدام Databricks Connect للوصول إلى Databricks Utilities.
يمكنك استخدام dbutils.fs والأدوات dbutils.secrets المساعدة للوحدة المرجعية Databricks Utilities (dbutils).
الأوامر المدعومة هي dbutils.fs.cp، dbutils.fs.head، dbutils.fs.ls، dbutils.fs.mkdirs، dbutils.fs.mv، dbutils.fs.put، dbutils.fs.rm، dbutils.secrets.get، ، dbutils.secrets.getBytes، dbutils.secrets.list. dbutils.secrets.listScopes
راجع الأداة المساعدة لنظام الملفات (dbutils.fs) أو أداة التشغيل dbutils.fs.help() والبيانات السرية (dbutils.secrets) أو قم بتشغيل dbutils.secrets.help().
Python
from pyspark.sql import SparkSession
from pyspark.dbutils import DBUtils
spark = SparkSession.builder.getOrCreate()
dbutils = DBUtils(spark)
print(dbutils.fs.ls("dbfs:/"))
print(dbutils.secrets.listScopes())
عند استخدام Databricks Runtime 7.3 LTS أو أعلى، للوصول إلى الوحدة النمطية DBUtils بطريقة تعمل محليا وفي مجموعات Azure Databricks، استخدم ما يلي get_dbutils():
def get_dbutils(spark):
from pyspark.dbutils import DBUtils
return DBUtils(spark)
وإلا، استخدم ما يلي get_dbutils():
def get_dbutils(spark):
if spark.conf.get("spark.databricks.service.client.enabled") == "true":
from pyspark.dbutils import DBUtils
return DBUtils(spark)
else:
import IPython
return IPython.get_ipython().user_ns["dbutils"]
Scala
val dbutils = com.databricks.service.DBUtils
println(dbutils.fs.ls("dbfs:/"))
println(dbutils.secrets.listScopes())
نسخ الملفات بين أنظمة الملفات المحلية والنائية
يمكنك استخدام dbutils.fs لنسخ الملفات بين العميل الخاص بك ونظام الملفات البعيد. يشير المخطط file:/ إلى نظام الملفات المحلي على العميل.
from pyspark.dbutils import DBUtils
dbutils = DBUtils(spark)
dbutils.fs.cp('file:/home/user/data.csv', 'dbfs:/uploads')
dbutils.fs.cp('dbfs:/output/results.csv', 'file:/home/user/downloads/')
الحد الأقصى لحجم الملف الذي يمكن نقله بهذه الطريقة هو 250 ميغابايت.
تمكين dbutils.secrets.get
بسبب قيود الأمان، يتم تعطيل القدرة على الاتصال dbutils.secrets.get بشكل افتراضي. اتصل بدعم Azure Databricks لتمكين هذه الميزة لمساحة العمل الخاصة بك.
تعيين تكوينات Hadoop
على العميل يمكنك تعيين تكوينات Hadoop باستخدام spark.conf.set واجهة برمجة التطبيقات، والتي تنطبق على عمليات SQL وDataFrame. يجب تعيين تكوينات Hadoop المعينة sparkContext على في تكوين نظام المجموعة أو باستخدام دفتر ملاحظات. وذلك لأن التكوينات التي تم تعيينها على sparkContext غير مرتبطة بجلسات عمل المستخدم ولكنها تنطبق على المجموعة بأكملها.
استكشاف الأخطاء وإصلاحها
قم بتشغيل databricks-connect test للتحقق من وجود مشكلات في الاتصال. يصف هذا القسم بعض المشكلات الشائعة التي قد تواجهها مع Databricks Connect وكيفية حلها.
في هذا القسم:
- عدم تطابق إصدار Python
- الخادم غير ممكن
- عمليات تثبيت PySpark المتعارضة
- المتعارضه
SPARK_HOME - إدخال متعارض أو مفقود
PATHللثنائيات - إعدادات التسلسل المتعارضة على نظام المجموعة
- يتعذر العثور
winutils.exeعلى Windows - اسم الملف أو اسم الدليل أو بناء جملة تسمية وحدة التخزين غير صحيح على Windows
عدم تطابق إصدار Python
تحقق من أن إصدار Python الذي تستخدمه محليا يحتوي على نفس الإصدار الثانوي على الأقل مثل الإصدار على نظام المجموعة (على سبيل المثال، 3.9.16 مقابل 3.9.15 موافق، 3.9 مقابل 3.8 ليس كذلك).
إذا كان لديك إصدارات Python متعددة مثبتة محليا، فتأكد من أن Databricks Connect يستخدم الإصدار الصحيح عن طريق تعيين PYSPARK_PYTHON متغير البيئة (على سبيل المثال، PYSPARK_PYTHON=python3).
الخادم غير ممكن
تأكد من تمكين خادم Spark لنظام المجموعة باستخدام spark.databricks.service.server.enabled true. يجب أن تشاهد الأسطر التالية في سجل برنامج التشغيل إذا كان:
../../.. ..:..:.. INFO SparkConfUtils$: Set spark config:
spark.databricks.service.server.enabled -> true
...
../../.. ..:..:.. INFO SparkContext: Loading Spark Service RPC Server
../../.. ..:..:.. INFO SparkServiceRPCServer:
Starting Spark Service RPC Server
../../.. ..:..:.. INFO Server: jetty-9...
../../.. ..:..:.. INFO AbstractConnector: Started ServerConnector@6a6c7f42
{HTTP/1.1,[http/1.1]}{0.0.0.0:15001}
../../.. ..:..:.. INFO Server: Started @5879ms
عمليات تثبيت PySpark المتعارضة
databricks-connect تتعارض الحزمة مع PySpark. سيؤدي تثبيت كليهما إلى حدوث أخطاء عند تهيئة سياق Spark في Python. يمكن أن يظهر هذا بعدة طرق، بما في ذلك أخطاء "البث التالفة" أو "لم يتم العثور على الفئة". إذا كان لديك PySpark مثبت في بيئة Python الخاصة بك، فتأكد من إلغاء تثبيته قبل تثبيت databricks-connect. بعد إلغاء تثبيت PySpark، تأكد من إعادة تثبيت حزمة Databricks Connect بشكل كامل:
pip3 uninstall pyspark
pip3 uninstall databricks-connect
pip3 install --upgrade "databricks-connect==12.2.*" # or X.Y.* to match your specific cluster version.
المتعارضه SPARK_HOME
إذا كنت قد استخدمت Spark مسبقا على جهازك، فقد يتم تكوين IDE الخاص بك لاستخدام أحد هذه الإصدارات الأخرى من Spark بدلا من Databricks Connect Spark. يمكن أن يظهر هذا بعدة طرق، بما في ذلك أخطاء "البث التالفة" أو "لم يتم العثور على الفئة". يمكنك معرفة إصدار Spark الذي يتم استخدامه عن طريق التحقق من SPARK_HOME قيمة متغير البيئة:
Python
import os
print(os.environ['SPARK_HOME'])
Scala
println(sys.env.get("SPARK_HOME"))
Java
System.out.println(System.getenv("SPARK_HOME"));
نوع الحل
إذا SPARK_HOME تم تعيين إلى إصدار Spark غير الإصدار الموجود في العميل، يجب إلغاء تعيين SPARK_HOME المتغير والمحاولة مرة أخرى.
تحقق من إعدادات متغير بيئة IDE، أو ملف ، .bashrc.zshrcأو .bash_profile ، وأي مكان آخر قد يتم تعيين متغيرات البيئة فيه. سيتعين عليك على الأرجح إنهاء IDE وإعادة تشغيله لإزالة الحالة القديمة، وقد تحتاج حتى إلى إنشاء مشروع جديد إذا استمرت المشكلة.
يجب ألا تحتاج إلى تعيين SPARK_HOME إلى قيمة جديدة؛ يجب أن يكون إلغاء تحديدها كافيا.
إدخال متعارض أو مفقود PATH للثنائيات
من الممكن تكوين PATH الخاص بك بحيث تقوم الأوامر مثل spark-shell بتشغيل بعض الأوامر الثنائية الأخرى المثبتة مسبقا بدلا من تلك المتوفرة مع Databricks Connect. يمكن أن يؤدي databricks-connect test هذا إلى الفشل. يجب التأكد من أن ثنائيات Databricks Connect لها الأسبقية، أو إزالة الثنائيات المثبتة مسبقا.
إذا لم تتمكن من تشغيل أوامر مثل spark-shell، فمن المحتمل أيضا أنه لم يتم إعداد PATH تلقائيا بواسطة pip3 install وستحتاج إلى إضافة وقت التثبيت bin إلى PATH يدويا. من الممكن استخدام Databricks Connect مع IDEs حتى إذا لم يتم إعداد هذا. ومع ذلك، databricks-connect test لن يعمل الأمر.
إعدادات التسلسل المتعارضة على نظام المجموعة
إذا رأيت أخطاء "دفق تالف" عند تشغيل databricks-connect test، فقد يكون هذا بسبب تكوينات تسلسل نظام المجموعة غير المتوافقة. على سبيل المثال، يمكن أن يؤدي تعيين التكوين إلى spark.io.compression.codec هذه المشكلة. لحل هذه المشكلة، ضع في اعتبارك إزالة هذه التكوينات من إعدادات نظام المجموعة، أو تعيين التكوين في عميل Databricks Connect.
يتعذر العثور winutils.exe على Windows
إذا كنت تستخدم Databricks Connect على Windows وشاهد:
ERROR Shell: Failed to locate the winutils binary in the hadoop binary path
java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
اتبع الإرشادات لتكوين مسار Hadoop على Windows.
اسم الملف أو اسم الدليل أو بناء جملة تسمية وحدة التخزين غير صحيح على Windows
إذا كنت تستخدم Windows وDatabricks Connect وشاهد:
The filename, directory name, or volume label syntax is incorrect.
تم تثبيت إما Java أو Databricks Connect في دليل به مسافة في المسار الخاص بك. يمكنك حل هذه المشكلة إما عن طريق التثبيت في مسار دليل بدون مسافات، أو تكوين المسار باستخدام نموذج الاسم القصير.
المصادقة باستخدام الرموز المميزة لمعرف Microsoft Entra
إشعار
تنطبق المعلومات التالية على إصدارات Databricks Connect من 7.3.5 إلى 12.2.x فقط.
لا يدعم Databricks Connect ل Databricks Runtime 13.3 LTS والإصدارات الأحدث حاليا الرموز المميزة لمعرف Microsoft Entra.
عند استخدام إصدارات Databricks Connect من 7.3.5 إلى 12.2.x، يمكنك المصادقة باستخدام رمز مميز لمعرف Microsoft Entra بدلا من رمز وصول شخصي. الرموز المميزة لمعرف Microsoft Entra لها عمر محدود. عند انتهاء صلاحية الرمز المميز لمعرف Microsoft Entra، يفشل Databricks Connect مع حدوث Invalid Token خطأ.
بالنسبة لإصدارات Databricks Connect من 7.3.5 إلى 12.2.x، يمكنك توفير الرمز المميز لمعرف Microsoft Entra في تطبيق Databricks Connect قيد التشغيل. يحتاج التطبيق الخاص بك إلى الحصول على رمز الوصول الجديد، وتعيينه إلى spark.databricks.service.token مفتاح تكوين SQL.
Python
spark.conf.set("spark.databricks.service.token", new_aad_token)
Scala
spark.conf.set("spark.databricks.service.token", newAADToken)
بعد تحديث الرمز المميز، يمكن للتطبيق الاستمرار في استخدام نفس وأي SparkSession كائنات وحالة تم إنشاؤها في سياق جلسة العمل. لتجنب الأخطاء المتقطعة، توصي Databricks بتوفير رمز مميز جديد قبل انتهاء صلاحية الرمز المميز القديم.
يمكنك تمديد عمر الرمز المميز لمعرف Microsoft Entra للاستمرار أثناء تنفيذ التطبيق الخاص بك. للقيام بذلك، قم بإرفاق TokenLifetimePolicy بمدة بقاء طويلة بشكل مناسب إلى تطبيق تخويل معرف Microsoft Entra الذي استخدمته للحصول على الرمز المميز للوصول.
إشعار
يستخدم رمز مرور معرف Microsoft Entra رمزين مميزين: الرمز المميز للوصول إلى معرف Microsoft Entra الذي تم وصفه مسبقا الذي قمت بتكوينه في إصدارات Databricks Connect من 7.3.5 إلى 12.2.x، والرمز المميز لتمرير ADLS للمورد المحدد الذي ينشئه Databricks أثناء معالجة Databricks للطلب. لا يمكنك تمديد مدة بقاء رموز ADLS المميزة باستخدام نهج مدة بقاء الرمز المميز لمعرف Microsoft Entra. إذا أرسلت أمرا إلى نظام المجموعة يستغرق أكثر من ساعة، فسيفشل إذا كان الأمر يصل إلى مورد ADLS بعد علامة ساعة واحدة.
القيود
كتالوج Unity.
دفق منظم.
تشغيل التعليمات البرمجية العشوائية التي ليست جزءا من مهمة Spark على نظام المجموعة البعيد.
لا يتم دعم واجهات برمجة تطبيقات Scala وPython وR الأصلية لعمليات جدول Delta (على سبيل المثال).
DeltaTable.forPathومع ذلك، يتم دعم كل من SQL API (spark.sql(...)) مع عمليات Delta Lake وSpark API (على سبيل المثال،spark.read.load) في جداول Delta.انسخ إلى.
باستخدام وظائف SQL، Python أو Scala UDFs التي تعد جزءا من كتالوج الخادم. ومع ذلك، تم تقديم Scala وPython UDFs محليا.
Apache Zeppelin 0.7.x وما دونه.
الاتصال بالمجموعة باستخدام التحكم في الوصول إلى الجدول.
الاتصال بالمجموعة مع تمكين عزل العملية (بمعنى آخر، حيث
spark.databricks.pyspark.enableProcessIsolationيتم تعيين إلىtrue).أمر Delta
CLONESQL.طرق العرض المؤقتة العمومية.
Koalas و
pyspark.pandas.CREATE TABLE table AS SELECT ...لا تعمل أوامر SQL دائما. بدلاً من ذلك، استخدمspark.sql("SELECT ...").write.saveAsTable("table").يتم دعم تمرير بيانات اعتماد معرف Microsoft Entra فقط على المجموعات القياسية التي تقوم بتشغيل Databricks Runtime 7.3 LTS وما فوق، وهي غير متوافقة مع المصادقة الأساسية للخدمة.