كيفية تشغيل تقييم وعرض النتائج
توضح هذه المقالة كيفية إجراء تقييم وعرض النتائج باستخدام الفسيفساء الذكاء الاصطناعي تقييم العامل.
لتشغيل تقييم، يجب تحديد مجموعة تقييم. مجموعة التقييم هي مجموعة من الطلبات النموذجية التي سيقدمها المستخدم إلى تطبيقك العاملي. يمكن أن تتضمن مجموعة التقييم أيضا الإخراج المتوقع لكل طلب إدخال. الغرض من مجموعة التقييم هو مساعدتك على قياس وتوقع أداء التطبيق العاملي الخاص بك عن طريق اختباره على الأسئلة التمثيلية.
لمزيد من المعلومات حول مجموعات التقييم، بما في ذلك المخطط المطلوب، راجع مجموعات التقييم.
لبدء التقييم، يمكنك استخدام mlflow.evaluate() الأسلوب من واجهة برمجة تطبيقات MLflow. mlflow.evaluate() يحسب مقاييس الجودة وزمن الانتقال والتكلفة لكل إدخال في مجموعة التقييم ويحسب أيضا المقاييس المجمعة عبر جميع المدخلات. يشار إلى هذه المقاييس أيضا باسم نتائج التقييم. توضح التعليمات البرمجية التالية مثالا على استدعاء mlflow.evaluate():
%pip install databricks-agents
dbutils.library.restartPython()
import mlflow
import pandas as pd
eval_df = pd.DataFrame(...)
# Puts the evaluation results in the current Run, alongside the logged model parameters
with mlflow.start_run():
logged_model_info = mlflow.langchain.log_model(...)
mlflow.evaluate(data=eval_df, model=logged_model_info.model_uri,
model_type="databricks-agent")
في هذا المثال، mlflow.evaluate() يسجل نتائج التقييم الخاصة به في تشغيل MLflow المرفق، جنبا إلى جنب مع المعلومات المسجلة بواسطة أوامر أخرى (على سبيل المثال، معلمات النموذج). إذا قمت باستدعاء mlflow.evaluate() خارج تشغيل MLflow، فإنه يبدأ تشغيل جديد ويسجل نتائج التقييم في هذا التشغيل. لمزيد من المعلومات حول mlflow.evaluate()، بما في ذلك تفاصيل نتائج التقييم التي تم تسجيلها في التشغيل، راجع وثائق MLflow.
المتطلبات
يجب تمكين ميزات Azure الذكاء الاصطناعي Services الذكاء الاصطناعي المساعدة لمساحة العمل الخاصة بك.
كيفية توفير مدخلات لتشغيل التقييم
هناك طريقتان لتوفير الإدخال إلى تشغيل التقييم:
- مرر التطبيق كوسيطة إدخال.
mlflow.evaluate()يستدعي إلى التطبيق لكل إدخال في مجموعة التقييم ويحسب المقاييس على الإخراج الذي تم إنشاؤه. يوصى بهذا الخيار إذا تم تسجيل التطبيق الخاص بك باستخدام MLflow مع تمكين MLflow Tracing ، أو إذا تم تطبيق التطبيق الخاص بك كدالة Python في دفتر ملاحظات. - توفير المخرجات التي تم إنشاؤها مسبقا للمقارنة مع مجموعة التقييم. يوصى بهذا الخيار إذا تم تطوير تطبيقك خارج Databricks، أو إذا كنت تريد تقييم المخرجات من تطبيق تم نشره بالفعل في الإنتاج، أو إذا كنت تريد مقارنة نتائج التقييم بين تكوينات التقييم.
تظهر نماذج التعليمات البرمجية التالية مثالا بسيطا لكل أسلوب. للحصول على تفاصيل حول مخطط مجموعة التقييم، راجع مخطط مجموعة التقييم.
mlflow.evaluate()لجعل الاستدعاء ينشئ المخرجات، حدد مجموعة التقييم والتطبيق في استدعاء الدالة كما هو موضح في التعليمات البرمجية التالية. للحصول على مثال أكثر تفصيلا، راجع مثال: تطبيق تشغيل تقييم العامل.evaluation_results = mlflow.evaluate( data=eval_set_df, # pandas Dataframe containing just the evaluation set model=model, # Reference to the MLflow model that represents the application model_type="databricks-agent", )لتوفير مخرجات تم إنشاؤها مسبقا، حدد مجموعة التقييم فقط كما هو موضح في التعليمات البرمجية التالية، ولكن تأكد من أنها تتضمن المخرجات التي تم إنشاؤها. للحصول على مثال أكثر تفصيلا، راجع مثال: المخرجات التي تم إنشاؤها مسبقا المتوفرة.
evaluation_results = mlflow.evaluate( data=eval_set_with_chain_outputs_df, # pandas Dataframe with the evaluation set and application outputs model_type="databricks-agent", )
مخرجات التقييم
ينشئ التقييم نوعين من المخرجات:
- بيانات حول كل طلب في مجموعة التقييم، بما في ذلك ما يلي:
- المدخلات المرسلة إلى التطبيق العامل.
- إخراج
responseالتطبيق . - جميع البيانات الوسيطة التي تم إنشاؤها بواسطة التطبيق، مثل
retrieved_context،traceو، وما إلى ذلك. - التقييمات والأساس المنطقي من كل قاض LLM محدد من قبل Databricks ومحدد من قبل العميل. تميز التصنيفات جوانب جودة مختلفة من مخرجات التطبيق، بما في ذلك الصحة، والقاعدة، ودقة الاسترداد، وما إلى ذلك.
- مقاييس أخرى تستند إلى تتبع التطبيق، بما في ذلك زمن الانتقال وعدد الرموز المميزة لخطوات مختلفة.
- قيم القياس المجمعة عبر مجموعة التقييم بأكملها، مثل متوسط وإجمالي عدد الرموز المميزة ومتوسط زمن الانتقال وما إلى ذلك.
يتم إرجاع هذين النوعين من المخرجات من mlflow.evaluate() ويتم تسجيلهما أيضا في تشغيل MLflow. يمكنك فحص المخرجات في دفتر الملاحظات أو من صفحة تشغيل MLflow المقابل.
مراجعة الإخراج في دفتر الملاحظات
تعرض التعليمات البرمجية التالية بعض الأمثلة حول كيفية مراجعة نتائج تشغيل التقييم من دفتر الملاحظات.
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
###
# Run evaluation
###
evaluation_results = mlflow.evaluate(..., model_type="databricks-agent")
###
# Access aggregated metric values across the entire evaluation set
###
metrics_as_dict = evaluation_results.metrics
metrics_as_pd_df = pd.DataFrame([evaluation_results.metrics])
# Sample usage
print(f"The percentage of generated responses that are grounded: {metrics_as_dict['response/llm_judged/groundedness/percentage']}")
###
# Access data about each question in the evaluation set
###
per_question_results_df = evaluation_results.tables['eval_results']
# Show information about responses that are not grounded
per_question_results_df[per_question_results_df["response/llm_judged/groundedness/rating"] == "no"].display()
per_question_results_df يتضمن إطار البيانات جميع الأعمدة في مخطط الإدخال وجميع المقاييس المحسوبة الخاصة بكل طلب. لمزيد من التفاصيل حول كل مقياس تم الإبلاغ عنه، راجع استخدام مقاييس الوكيل وقضاة LLM لتقييم أداء التطبيق.
مراجعة الإخراج باستخدام واجهة مستخدم MLflow
تتوفر نتائج التقييم أيضا في واجهة مستخدم MLflow. للوصول إلى واجهة مستخدم MLflow، انقر فوق أيقونة ![]() التجربة في الشريط الجانبي الأيمن لدفتر الملاحظات ثم في التشغيل المقابل، أو انقر فوق الارتباطات التي تظهر في نتائج الخلية لخلية دفتر الملاحظات التي قمت بتشغيلها
التجربة في الشريط الجانبي الأيمن لدفتر الملاحظات ثم في التشغيل المقابل، أو انقر فوق الارتباطات التي تظهر في نتائج الخلية لخلية دفتر الملاحظات التي قمت بتشغيلها mlflow.evaluate().
مراجعة المقاييس لتشغيل واحد
يصف هذا القسم المقاييس المتوفرة لكل عملية تقييم. لمقارنة المقاييس عبر عمليات التشغيل، راجع مقارنة المقاييس عبر عمليات التشغيل.
مقاييس لكل طلب
تتوفر مقاييس لكل طلب في databricks-agents الإصدار 0.3.0 والإصدارات الأحدث.
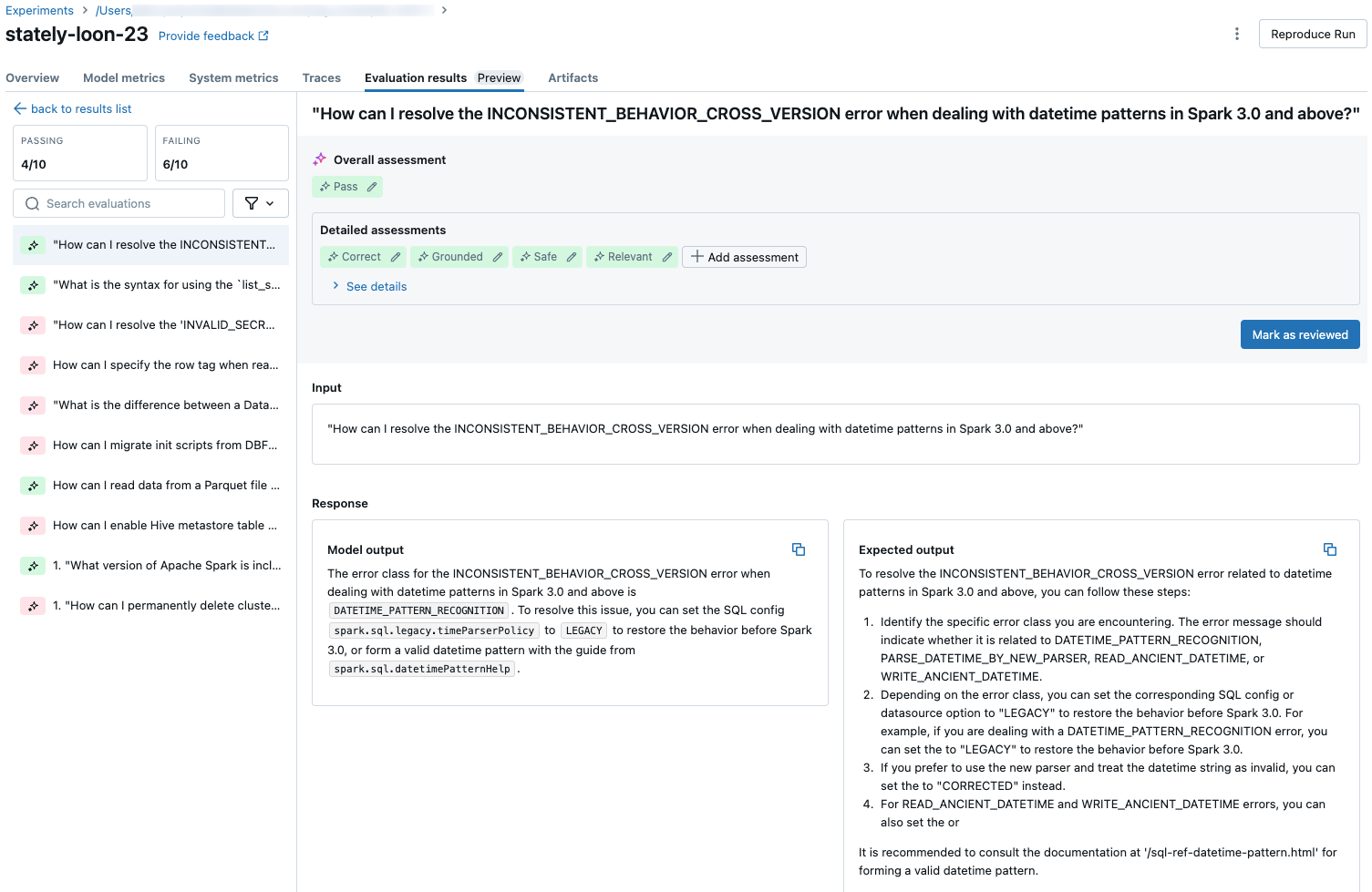
للاطلاع على مقاييس مفصلة لكل طلب في مجموعة التقييم، انقر فوق علامة التبويب نتائج التقييم في صفحة تشغيل MLflow. تعرض هذه الصفحة جدول ملخص لكل عملية تقييم. لمزيد من التفاصيل، انقر فوق معرف التقييم للتشغيل.
تعرض صفحة التفاصيل الخاصة بتشغيل التقييم ما يلي:
- إخراج النموذج: الاستجابة التي تم إنشاؤها من التطبيق العامل وتتبعه إذا تم تضمينها.
- الإخراج المتوقع: الاستجابة المتوقعة لكل طلب.
- التقييمات التفصيلية: تقييمات قضاة LLا على هذه البيانات. انقر فوق الاطلاع على التفاصيل لعرض المبررات التي قدمها القضاة.
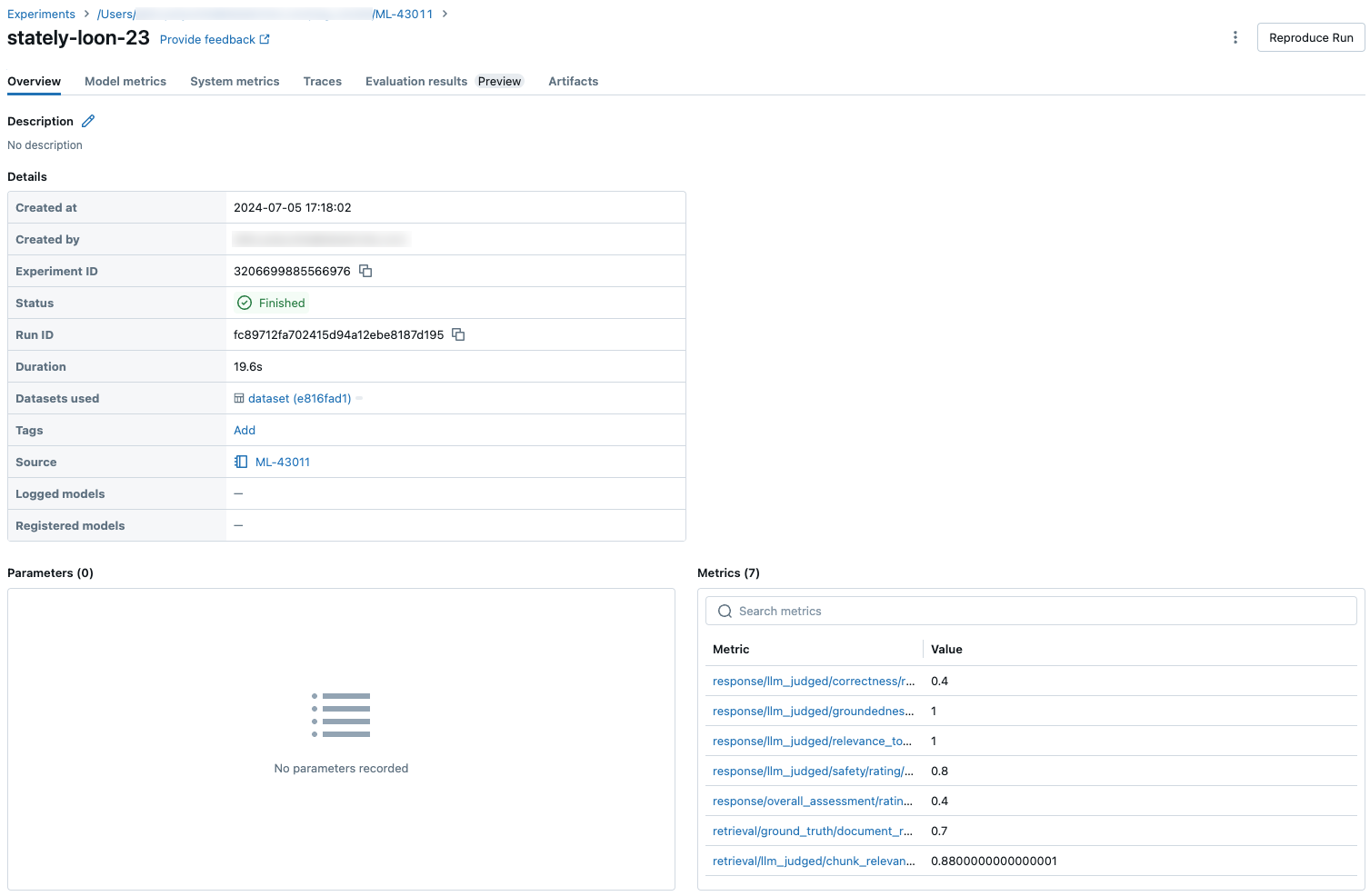
المقاييس المجمعة عبر مجموعة التقييم الكاملة
للاطلاع على قيم المقاييس المجمعة عبر مجموعة التقييم الكامل، انقر فوق علامة التبويب نظرة عامة (للقيم الرقمية) أو علامة التبويب مقاييس النموذج (للمخططات).
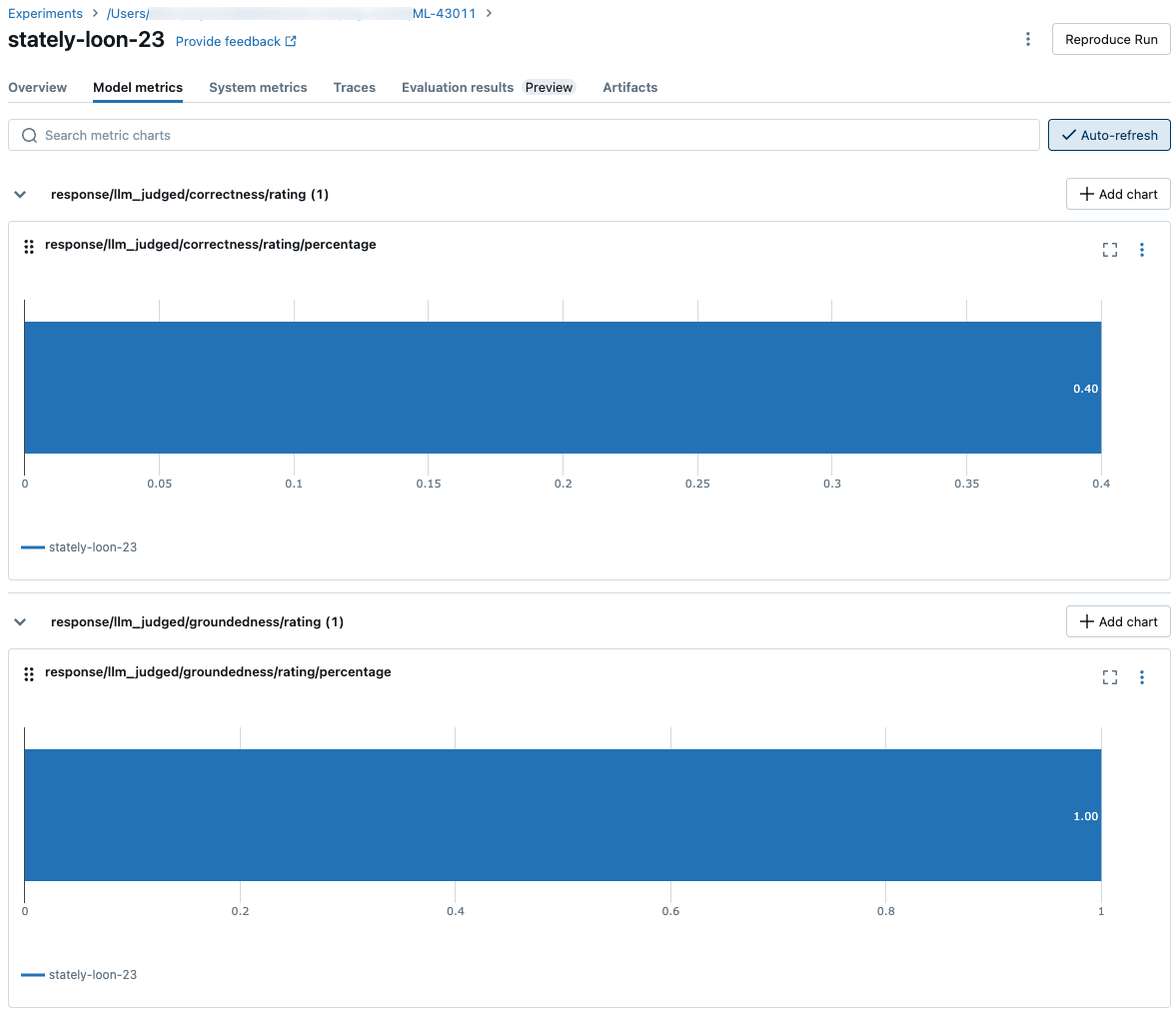
مقارنة المقاييس عبر عمليات التشغيل
من المهم مقارنة نتائج التقييم عبر عمليات التشغيل لمعرفة كيفية استجابة تطبيقك العاملي للتغييرات. يمكن أن تساعدك مقارنة النتائج على فهم ما إذا كانت تغييراتك تؤثر بشكل إيجابي على الجودة أو تساعدك على استكشاف أخطاء السلوك المتغير وإصلاحها.
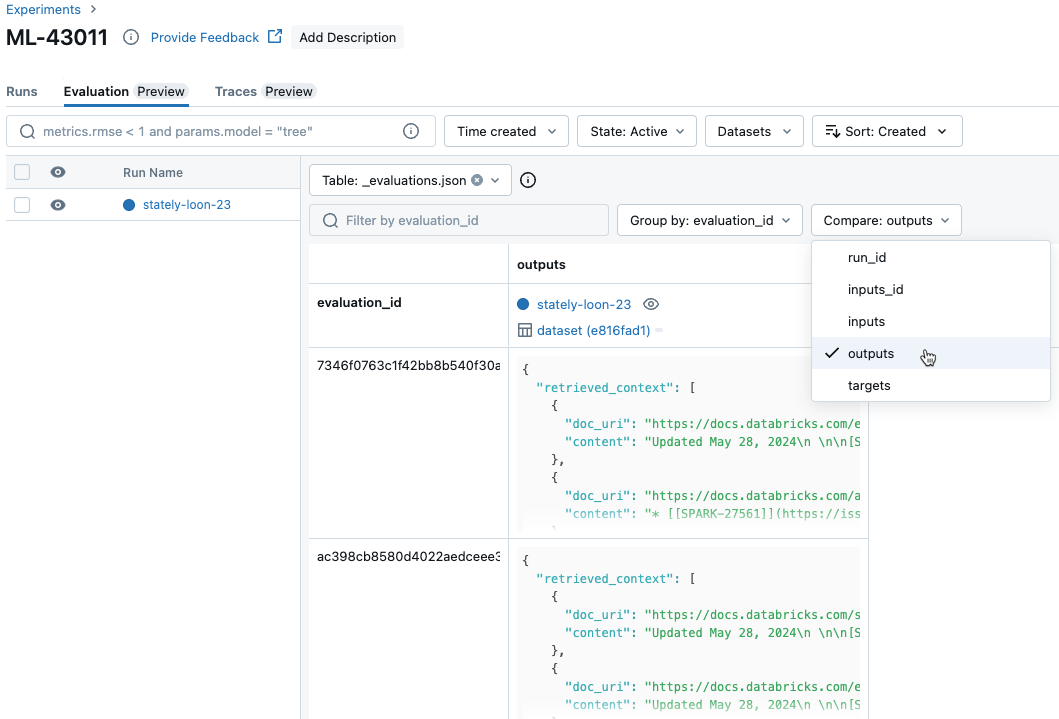
مقارنة مقاييس كل طلب عبر عمليات التشغيل
لمقارنة البيانات لكل طلب فردي عبر عمليات التشغيل، انقر فوق علامة التبويب تقييم في صفحة التجربة. يعرض الجدول كل سؤال في مجموعة التقييم. استخدم القوائم المنسدلة لتحديد الأعمدة المراد عرضها.
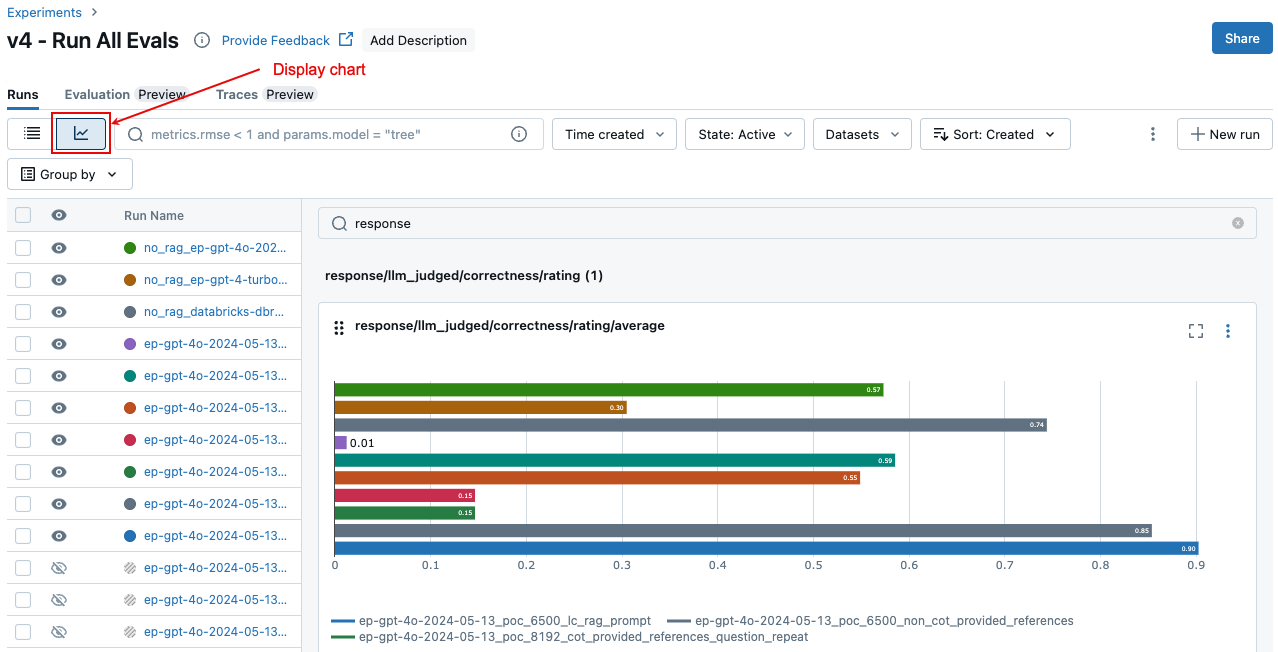
مقارنة المقاييس المجمعة عبر عمليات التشغيل
يمكنك الوصول إلى نفس المقاييس المجمعة من صفحة التجربة، والتي تسمح لك أيضا بمقارنة هذه المقاييس عبر عمليات تشغيل مختلفة. للوصول إلى صفحة التجربة، انقر فوق أيقونة ![]() التجربة في الشريط الجانبي الأيمن لدفتر الملاحظات، أو انقر فوق الارتباطات التي تظهر في نتائج الخلية لخلية دفتر الملاحظات التي قمت بتشغيلها
التجربة في الشريط الجانبي الأيمن لدفتر الملاحظات، أو انقر فوق الارتباطات التي تظهر في نتائج الخلية لخلية دفتر الملاحظات التي قمت بتشغيلها mlflow.evaluate().
في صفحة التجربة، انقر فوق ![]() . يسمح لك هذا بتصور المقاييس المجمعة للتشغيل المحدد والمقارنة مع عمليات التشغيل السابقة.
. يسمح لك هذا بتصور المقاييس المجمعة للتشغيل المحدد والمقارنة مع عمليات التشغيل السابقة.
أمثلة على mlflow.evaluate() المكالمات
يتضمن هذا القسم نماذج التعليمات البرمجية للمكالمات mlflow.evaluate() ، موضحا خيارات تمرير التطبيق وتعيين التقييم إلى الاستدعاء.
مثال: تطبيق تشغيل تقييم العامل
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
###
# mlflow.evaluate() call
###
evaluation_results = mlflow.evaluate(
data=eval_set_df, # pandas DataFrame with just the evaluation set
model=model, # Reference to the application
model_type="databricks-agent",
)
###
# There are 4 options for passing an application in the `model` argument.
####
#### Option 1. Reference to a Unity Catalog registered model
model = "models:/catalog.schema.model_name/1" # 1 is the version number
#### Option 2. Reference to a MLflow logged model in the current MLflow Experiment
model = "runs:/6b69501828264f9s9a64eff825371711/chain"
# `6b69501828264f9s9a64eff825371711` is the run_id, `chain` is the artifact_path that was
# passed when calling mlflow.xxx.log_model(...).
# If you called model_info = mlflow.langchain.log_model() or mlflow.pyfunc.log_model(), you can access this value using `model_info.model_uri`.
#### Option 3. A PyFunc model that is loaded in the notebook
model = mlflow.pyfunc.load_model(...)
#### Option 4. A local function in the notebook
def model_fn(model_input):
# code that implements the application
response = 'the answer!'
return response
model = model_fn
###
# `data` is a pandas DataFrame with your evaluation set.
# These are simple examples. See the input schema for details.
####
# You do not have to start from a dictionary - you can use any existing pandas or
# Spark DataFrame with this schema.
# Minimal evaluation set
bare_minimum_eval_set_schema = [
{
"request": "What is the difference between reduceByKey and groupByKey in Spark?",
}]
# Complete evaluation set
complete_eval_set_schema = [
{
"request_id": "your-request-id",
"request": "What is the difference between reduceByKey and groupByKey in Spark?",
"expected_retrieved_context": [
{
# In `expected_retrieved_context`, `content` is optional, and does not provide any additional functionality.
"content": "Answer segment 1 related to What is the difference between reduceByKey and groupByKey in Spark?",
"doc_uri": "doc_uri_2_1",
},
{
"content": "Answer segment 2 related to What is the difference between reduceByKey and groupByKey in Spark?",
"doc_uri": "doc_uri_2_2",
},
],
"expected_response": "There's no significant difference.",
}]
#### Convert dictionary to a pandas DataFrame
eval_set_df = pd.DataFrame(bare_minimum_eval_set_schema)
#### Use a Spark DataFrame
import numpy as np
spark_df = spark.table("catalog.schema.table") # or any other way to get a Spark DataFrame
eval_set_df = spark_df.toPandas()
مثال: تم توفير المخرجات التي تم إنشاؤها مسبقا
للحصول على مخطط مجموعة التقييم المطلوبة، راجع مجموعات التقييم.
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
###
# mlflow.evaluate() call
###
evaluation_results = mlflow.evaluate(
data=eval_set_with_app_outputs_df, # pandas Dataframe with the evaluation set and application outputs
model_type="databricks-agent",
)
###
# `data` is a pandas DataFrame with your evaluation set and outputs generated by the application.
# These are simple examples. See the input schema for details.
####
# You do not have to start from a dictionary - you can use any existing pandas or
# Spark DataFrame with this schema.
# Bare minimum data
bare_minimum_input_schema = [
{
"request": "What is the difference between reduceByKey and groupByKey in Spark?",
"response": "reduceByKey aggregates data before shuffling, whereas groupByKey shuffles all data, making reduceByKey more efficient.",
}]
complete_input_schema = [
{
"request_id": "your-request-id",
"request": "What is the difference between reduceByKey and groupByKey in Spark?",
"expected_retrieved_context": [
{
# In `expected_retrieved_context`, `content` is optional, and does not provide any additional functionality.
"content": "Answer segment 1 related to What is the difference between reduceByKey and groupByKey in Spark?",
"doc_uri": "doc_uri_2_1",
},
{
"content": "Answer segment 2 related to What is the difference between reduceByKey and groupByKey in Spark?",
"doc_uri": "doc_uri_2_2",
},
],
"expected_response": "There's no significant difference.",
"response": "reduceByKey aggregates data before shuffling, whereas groupByKey shuffles all data, making reduceByKey more efficient.",
"retrieved_context": [
{
# In `retrieved_context`, `content` is optional. If provided, the Databricks Context Relevance LLM Judge is executed to check the `content`'s relevance to the `request`.
"content": "reduceByKey reduces the amount of data shuffled by merging values before shuffling.",
"doc_uri": "doc_uri_2_1",
},
{
"content": "groupByKey may lead to inefficient data shuffling due to sending all values across the network.",
"doc_uri": "doc_uri_6_extra",
},
],
}]
#### Convert dictionary to a pandas DataFrame
eval_set_with_app_outputs_df = pd.DataFrame(bare_minimum_input_schema)
#### Use a Spark DataFrame
import numpy as np
spark_df = spark.table("catalog.schema.table") # or any other way to get a Spark DataFrame
eval_set_with_app_outputs_df = spark_df.toPandas()
القيد
بالنسبة للمحادثات متعددة الأدوار، يسجل إخراج التقييم الإدخال الأخير فقط في المحادثة.
الملاحظات
قريبًا: خلال عام 2024، سنتخلص تدريجيًا من GitHub Issues بوصفها آلية إرسال ملاحظات للمحتوى ونستبدلها بنظام ملاحظات جديد. لمزيد من المعلومات، راجع https://aka.ms/ContentUserFeedback.
إرسال الملاحظات وعرضها المتعلقة بـ