إشعار
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تسجيل الدخول أو تغيير الدلائل.
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تغيير الدلائل.
توضح هذه المقالة كيف يمكنك استخدام MLOps على النظام الأساسي Databricks لتحسين أداء أنظمة التعلم الآلي (ML) وكفاءتها على المدى الطويل. يتضمن توصيات عامة لبنية MLOps ويصف سير عمل معمم باستخدام النظام الأساسي Databricks الذي يمكنك استخدامه كنموذج لعملية تطوير التعلم الآلي إلى الإنتاج. للحصول على تعديلات على سير العمل هذا لتطبيقات LLMOps، راجع مهام سير عمل LLMOps.
لمزيد من التفاصيل، راجع الكتاب الكبير من MLOps.
ما هو MLOps؟
MLOps هي مجموعة من العمليات والخطوات التلقائية لإدارة التعليمات البرمجية والبيانات والنماذج لتحسين الأداء والاستقرار والكفاءة طويلة الأجل لأنظمة التعلم الآلي. فهو يجمع بين DevOps وDataOps و ModelOps.
يتم تطوير أصول التعلم الآلي مثل التعليمات البرمجية والبيانات والنماذج على مراحل تتقدم من مراحل التطوير المبكرة التي لا تحتوي على قيود وصول صارمة ولا يتم اختبارها بدقة، من خلال مرحلة اختبار وسيطة، إلى مرحلة إنتاج نهائية يتم التحكم فيها بإحكام. يتيح لك النظام الأساسي Databricks إدارة هذه الأصول على نظام أساسي واحد مع التحكم الموحد في الوصول. يمكنك تطوير تطبيقات البيانات وتطبيقات التعلم الآلي على نفس النظام الأساسي، ما يقلل من المخاطر والتأخيرات المرتبطة بنقل البيانات.
توصيات عامة ل MLOps
يتضمن هذا القسم بعض التوصيات العامة ل MLOps على Databricks مع ارتباطات لمزيد من المعلومات.
إنشاء بيئة منفصلة لكل مرحلة
بيئة التنفيذ هي المكان الذي يتم فيه إنشاء النماذج والبيانات أو استهلاكها بواسطة التعليمات البرمجية. تتكون كل بيئة تنفيذ من مثيلات الحوسبة وأوقات التشغيل والمكتبات الخاصة بها والمهام التلقائية.
توصي Databricks بإنشاء بيئات منفصلة للمراحل المختلفة من التعليمات البرمجية ML وتطوير النموذج مع انتقالات محددة بوضوح بين المراحل. يتبع سير العمل الموضح في هذه المقالة هذه العملية، باستخدام الأسماء الشائعة للمراحر:
يمكن أيضا استخدام تكوينات أخرى لتلبية الاحتياجات المحددة لمؤسستك.
التحكم في الوصول وتعيين الإصدار
التحكم في الوصول وتعيين الإصدار هما مكونان رئيسيان لأي عملية عمليات برامج. توصي Databricks بما يلي:
- استخدم Git للتحكم في الإصدار. يجب تخزين المسارات والرمز في Git للتحكم في الإصدار. يمكن تفسير نقل منطق التعلم الآلي بين المراحل على أنه نقل التعليمات البرمجية من فرع التطوير، إلى الفرع المرحلي، إلى فرع الإصدار. استخدم مجلدات Databricks Git للتكامل مع موفر Git ومزامنة دفاتر الملاحظات ورمز المصدر مع مساحات عمل Databricks. يوفر Databricks أيضا أدوات إضافية لتكامل Git والتحكم في الإصدار؛ راجع أدوات المطور.
- تخزين البيانات في بنية مستودع باستخدام جداول Delta. يجب تخزين البيانات في بنية مستودع في حساب السحابة الخاص بك. يجب تخزين كل من البيانات الأولية وجداول الميزات كجداول Delta مع عناصر التحكم في الوصول لتحديد من يمكنه قراءتها وتعديلها.
- إدارة تطوير النموذج باستخدام MLflow. يمكنك استخدام MLflow لتتبع عملية تطوير النموذج وحفظ لقطات التعليمات البرمجية ومعلمات النموذج والمقاييس وبيانات التعريف الأخرى.
- استخدم النماذج في كتالوج Unity لإدارة دورة حياة النموذج. استخدم النماذج في كتالوج Unity لإدارة تعيين إصدار النموذج والحوكمة وحالة النشر.
نشر التعليمات البرمجية، وليس النماذج
في معظم الحالات، توصي Databricks بأنه أثناء عملية تطوير التعلم الآلي، تقوم بترقية التعليمات البرمجية، بدلا من النماذج، من بيئة إلى أخرى. يضمن نقل أصول المشروع بهذه الطريقة أن جميع التعليمات البرمجية في عملية تطوير التعلم الآلي تمر بنفس عمليات مراجعة التعليمات البرمجية واختبار التكامل. كما يضمن أن يتم تدريب إصدار الإنتاج من النموذج على التعليمات البرمجية للإنتاج. للحصول على مناقشة أكثر تفصيلا للخيارات والمفاضلات، راجع أنماط توزيع النموذج.
سير عمل MLOps الموصى به
تصف الأقسام التالية سير عمل MLOps نموذجيا، يغطي كل من المراحل الثلاث: التطوير والتقسيم المرحلي والإنتاج.
يستخدم هذا القسم مصطلحي "عالم البيانات" و"مهندس التعلم الآلي" كأشخاص أصليين؛ ستختلف الأدوار والمسؤوليات المحددة في سير عمل MLOps بين الفرق والمؤسسات.
مرحلة التطوير
ينصب تركيز مرحلة التطوير على التجريب. يقوم علماء البيانات بتطوير الميزات والنماذج وتشغيل التجارب لتحسين أداء النموذج. إخراج عملية التطوير هو التعليمات البرمجية لمسار التعلم الآلي التي يمكن أن تتضمن حساب الميزة وتدريب النموذج والاستدلال والمراقبة.
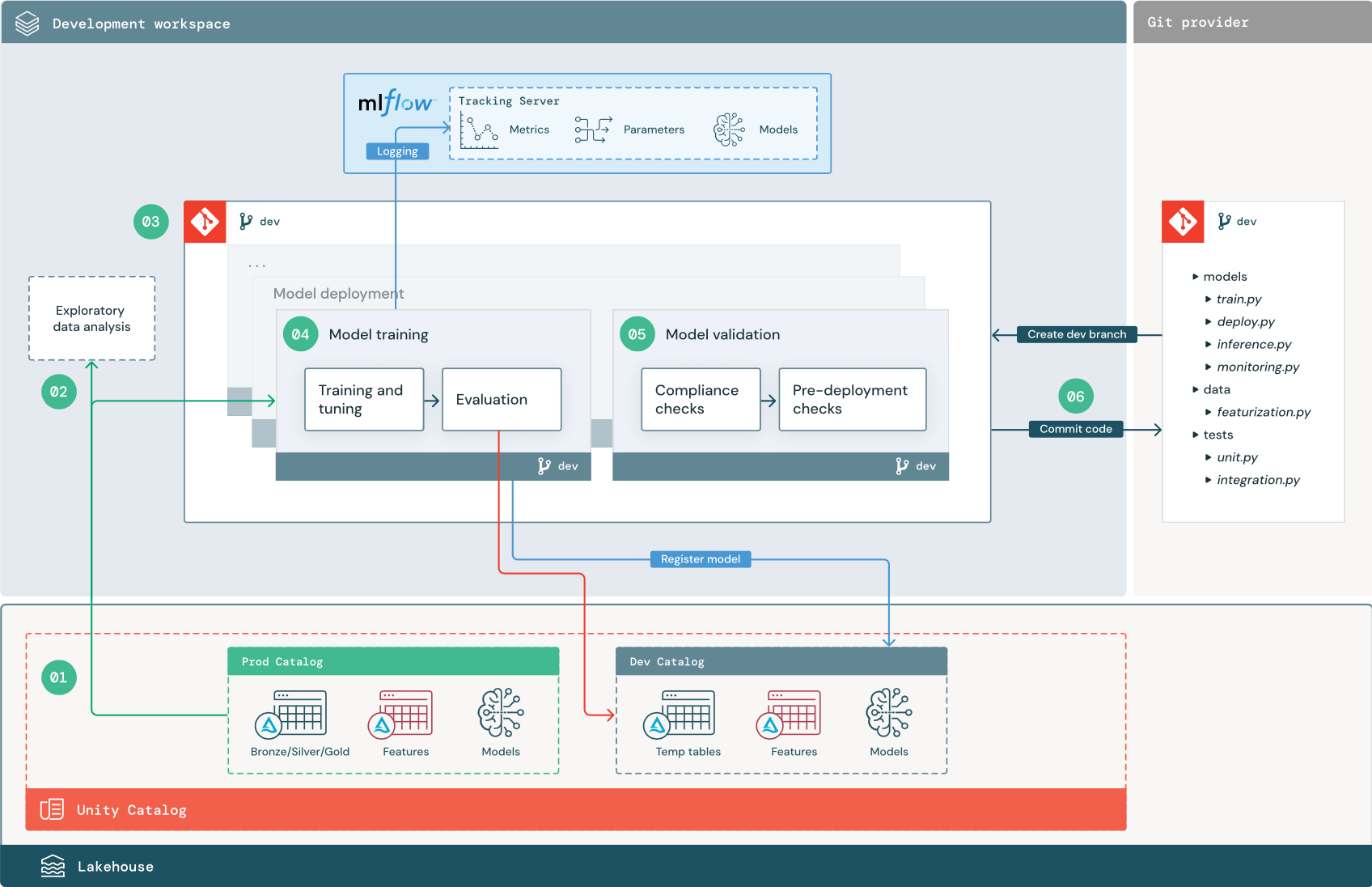
تتوافق الخطوات الرقمية مع الأرقام المعروضة في الرسم التخطيطي.
1. مصادر البيانات
يتم تمثيل بيئة التطوير بواسطة كتالوج التطوير في كتالوج Unity. يتمتع علماء البيانات بإمكانية الوصول للقراءة والكتابة إلى كتالوج التطوير أثناء إنشاء بيانات مؤقتة وجداول ميزات في مساحة عمل التطوير. يتم تسجيل النماذج التي تم إنشاؤها في مرحلة التطوير في كتالوج التطوير.
من الناحية المثالية، يتمتع علماء البيانات الذين يعملون في مساحة عمل التطوير أيضا بإمكانية الوصول للقراءة فقط إلى بيانات الإنتاج في كتالوج prod. السماح لعلماء البيانات بقراءة الوصول إلى بيانات الإنتاج وجداول الاستدلال وجداول القياس في كتالوج prod يمكنهم من تحليل تنبؤات نموذج الإنتاج الحالي وأدائه. يجب أن يكون علماء البيانات أيضا قادرين على تحميل نماذج الإنتاج للتجريب والتحليل.
إذا لم يكن من الممكن منح حق الوصول للقراءة فقط إلى كتالوج prod، يمكن كتابة لقطة من بيانات الإنتاج إلى كتالوج التطوير لتمكين علماء البيانات من تطوير التعليمات البرمجية للمشروع وتقييمها.
2. تحليل البيانات الاستكشافية (EDA)
يستكشف علماء البيانات البيانات ويحللونها في عملية تفاعلية متكررة باستخدام دفاتر الملاحظات. والهدف هو تقييم ما إذا كانت البيانات المتاحة لديها القدرة على حل مشكلة الأعمال. في هذه الخطوة، يبدأ عالم البيانات في تحديد خطوات إعداد البيانات والتميز لتدريب النموذج. هذه العملية المخصصة بشكل عام ليست جزءا من البنية الأساسية لبرنامج ربط العمليات التجارية التي سيتم نشرها في بيئات التنفيذ الأخرى.
يعمل AutoML على تسريع هذه العملية عن طريق إنشاء نماذج أساسية لمجموعة بيانات. ينفذ AutoML مجموعة من الإصدارات التجريبية ويسجلها ويوفر دفتر ملاحظات Python مع التعليمات البرمجية المصدر لكل تشغيل تجريبي، حتى تتمكن من مراجعة التعليمات البرمجية وإعادة إنتاجها وتعديلها. يحسب AutoML أيضا إحصائيات الملخص على مجموعة البيانات الخاصة بك ويحفظ هذه المعلومات في دفتر ملاحظات يمكنك مراجعته.
3. التعليمات البرمجية
يحتوي مستودع التعليمات البرمجية على كافة المسارات والوحدات النمطية وملفات المشروع الأخرى لمشروع التعلم الآلي. ينشئ علماء البيانات مسارات جديدة أو محدثة في فرع تطوير ("dev") لمستودع المشروع. بدءا من EDA والمراحل الأولية للمشروع، يجب أن يعمل علماء البيانات في مستودع لمشاركة التعليمات البرمجية وتتبع التغييرات.
4. نموذج التدريب (التطوير)
يقوم علماء البيانات بتطوير مسار تدريب النموذج في بيئة التطوير باستخدام جداول من كتالوجات التطوير أو prod.
يتضمن هذا المسار مهمتين:
التدريب والضبط. تسجل عملية التدريب معلمات النموذج والمقاييس والبيانات الاصطناعية إلى خادم MLflow Tracking. بعد تدريب المعلمات الفائقة وضبطها، يتم تسجيل البيانات الاصطناعية النهائية للنموذج إلى خادم التعقب لتسجيل ارتباط بين النموذج وبيانات الإدخال التي تم تدريبه عليها والتعليمات البرمجية المستخدمة لإنشائه.
التقييم. تقييم جودة النموذج عن طريق اختبار البيانات المحتفظ بها. يتم تسجيل نتائج هذه الاختبارات إلى خادم MLflow Tracking. الغرض من التقييم هو تحديد ما إذا كان أداء النموذج المطور حديثا أفضل من نموذج الإنتاج الحالي. بالنظر إلى الأذونات الكافية، يمكن تحميل أي نموذج إنتاج مسجل في كتالوج prod في مساحة عمل التطوير ومقارنتها بنموذج مدرب حديثا.
إذا كانت متطلبات الحوكمة الخاصة بمؤسستك تتضمن معلومات إضافية حول النموذج، يمكنك حفظه باستخدام تتبع MLflow. البيانات الاصطناعية النموذجية هي أوصاف النص العادي وتفسيرات النموذج مثل المخططات التي تنتجها SHAP. قد تأتي متطلبات الحوكمة المحددة من مسؤول إدارة البيانات أو أصحاب المصلحة في الأعمال.
إخراج مسار تدريب النموذج هو أداة نموذج التعلم الآلي المخزنة في خادم MLflow Tracking لبيئة التطوير. إذا تم تنفيذ البنية الأساسية لبرنامج ربط العمليات التجارية في مساحة عمل التقسيم المرحلي أو الإنتاج، يتم تخزين البيانات الاصطناعية للنموذج في خادم تتبع MLflow لمساحة العمل هذه.
عند اكتمال تدريب النموذج، قم بتسجيل النموذج في كتالوج Unity. قم بإعداد التعليمات البرمجية للبنية الأساسية لبرنامج ربط العمليات التجارية الخاصة بك لتسجيل النموذج في الكتالوج المقابل للبيئة التي تم تنفيذ مسار النموذج فيها؛ في هذا المثال، كتالوج التطوير.
باستخدام البنية الموصى بها، يمكنك نشر سير عمل Databricks متعدد المهام حيث تكون المهمة الأولى هي مسار تدريب النموذج، متبوعا بمهام التحقق من صحة النموذج ونشر النموذج. ينتج عن مهمة تدريب النموذج URI نموذج يمكن أن تستخدمه مهمة التحقق من صحة النموذج. يمكنك استخدام قيم المهام لتمرير URI هذا إلى النموذج.
5. التحقق من صحة النموذج ونشره (التطوير)
بالإضافة إلى مسار تدريب النموذج، يتم تطوير مسارات أخرى مثل التحقق من صحة النموذج وتدفقات نشر النموذج في بيئة التطوير.
التحقق من صحة النموذج. يأخذ مسار التحقق من صحة النموذج URI النموذج من مسار تدريب النموذج، ويحمل النموذج من كتالوج Unity، ويشغل عمليات التحقق من الصحة.
تعتمد عمليات التحقق من الصحة على السياق. يمكن أن تتضمن عمليات التحقق الأساسية مثل تأكيد التنسيق وبيانات التعريف المطلوبة، والفحوصات الأكثر تعقيدا التي قد تكون مطلوبة للصناعات عالية التنظيم، مثل فحوصات التوافق المعرفة مسبقا وتأكيد أداء النموذج على شرائح بيانات محددة.
الوظيفة الأساسية لمسار التحقق من صحة النموذج هي تحديد ما إذا كان يجب أن ينتقل النموذج إلى خطوة النشر. إذا مر النموذج بعمليات التحقق قبل التوزيع، يمكن تعيين الاسم المستعار "Challenger" في كتالوج Unity. إذا فشلت عمليات التحقق، تنتهي العملية. يمكنك تكوين سير العمل لإعلام المستخدمين بفشل التحقق من الصحة. راجع إضافة إعلامات البريد الإلكتروني والنظام لأحداث الوظيفة.
توزيع النموذج. عادة ما يقوم مسار توزيع النموذج إما بشكل مباشر بترقية نموذج "Challenger" المدرب حديثا إلى حالة "البطل" باستخدام تحديث الاسم المستعار، أو يسهل المقارنة بين نموذج "البطل" الحالي ونموذج "Challenger" الجديد. يمكن لهذا المسار أيضا إعداد أي بنية أساسية للاستدلال المطلوبة، مثل نقاط نهاية خدمة النموذج. للحصول على مناقشة مفصلة للخطوات المتضمنة في مسار توزيع النموذج، راجع الإنتاج.
6. تنفيذ التعليمات البرمجية
بعد تطوير التعليمات البرمجية للتدريب والتحقق من الصحة والنشر وغيرها من المسارات، يلتزم عالم البيانات أو مهندس التعلم الآلي بتغييرات فرع التطوير في التحكم بالمصادر.
مرحلة التقسيم المرحلي
ينصب تركيز هذه المرحلة على اختبار التعليمات البرمجية لمسار التعلم الآلي للتأكد من أنها جاهزة للإنتاج. يتم اختبار جميع التعليمات البرمجية لمسار التعلم الآلي في هذه المرحلة، بما في ذلك التعليمات البرمجية لتدريب النموذج بالإضافة إلى خطوط أنابيب هندسة الميزات ورمز الاستدلال وما إلى ذلك.
يقوم مهندسو التعلم الآلي بإنشاء مسار CI لتنفيذ الوحدة وتشغيل اختبارات التكامل في هذه المرحلة. إخراج عملية التقسيم المرحلي هو فرع إصدار يقوم بتشغيل نظام CI/CD لبدء مرحلة الإنتاج.
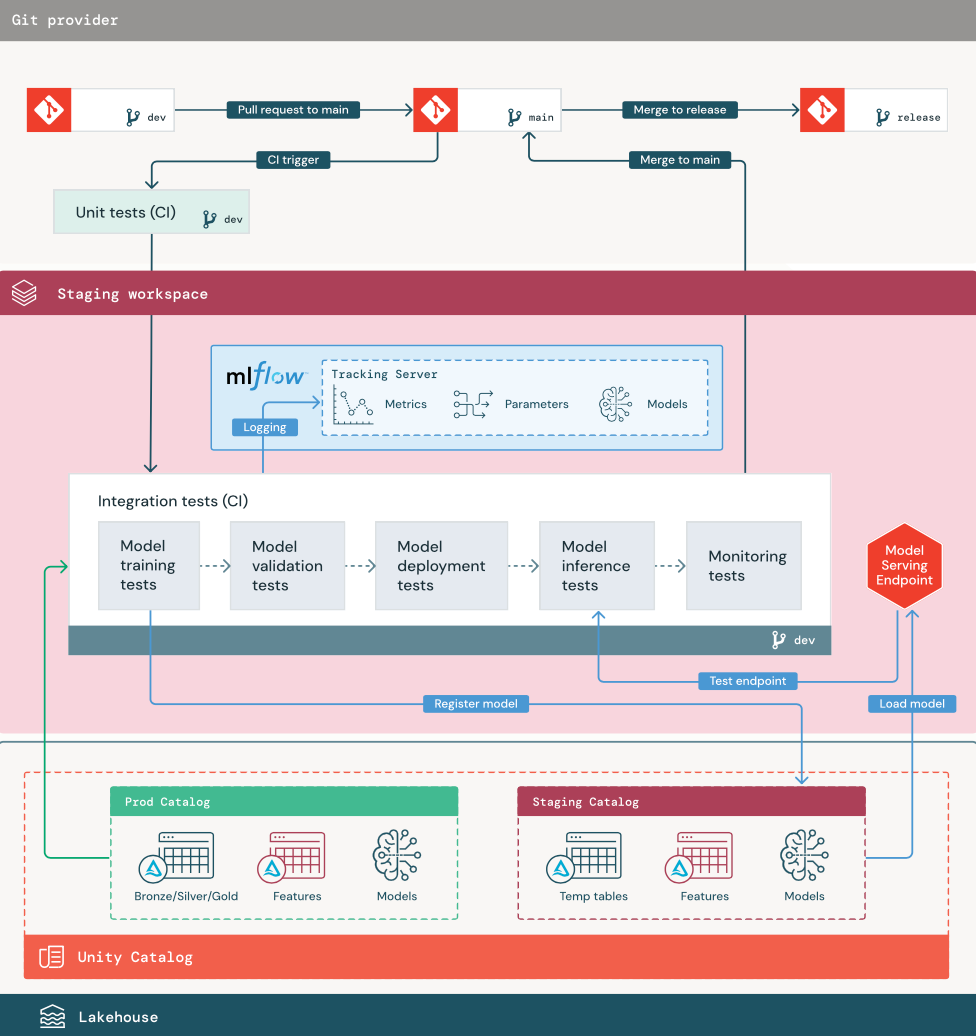
1. البيانات
يجب أن يكون لبيئة التقسيم المرحلي كتالوج خاص بها في كتالوج Unity لاختبار مسارات التعلم الآلي وتسجيل النماذج في كتالوج Unity. يظهر هذا الكتالوج ككتالوج "مرحلي" في الرسم التخطيطي. تكون الأصول المكتوبة في هذا الكتالوج مؤقتة بشكل عام ولا يتم الاحتفاظ بها إلا حتى اكتمال الاختبار. قد تتطلب بيئة التطوير أيضا الوصول إلى كتالوج التقسيم المرحلي لأغراض تصحيح الأخطاء.
2. دمج التعليمات البرمجية
يقوم علماء البيانات بتطوير مسار التدريب النموذجي في بيئة التطوير باستخدام جداول من كتالوجات التطوير أو الإنتاج.
سحب الطلب. تبدأ عملية النشر عند إنشاء طلب سحب مقابل الفرع الرئيسي للمشروع في التحكم بالمصادر.
اختبارات الوحدة (CI). ينشئ طلب السحب التعليمات البرمجية المصدر تلقائيا ويشغل اختبارات الوحدة. إذا فشلت اختبارات الوحدة، يتم رفض طلب السحب.
اختبارات الوحدة هي جزء من عملية تطوير البرامج ويتم تنفيذها باستمرار وإضافتها إلى قاعدة التعليمات البرمجية أثناء تطوير أي تعليمة برمجية. يضمن تشغيل اختبارات الوحدة كجزء من البنية الأساسية لبرنامج ربط العمليات التجارية CI أن التغييرات التي تم إجراؤها في فرع التطوير لا تكسر الوظائف الموجودة.
3. اختبارات التكامل (CI)
ثم تقوم عملية CI بتشغيل اختبارات التكامل. تعمل اختبارات التكامل على تشغيل جميع المسارات (بما في ذلك هندسة الميزات وتدريب النموذج والاستدلال والمراقبة) للتأكد من أنها تعمل معا بشكل صحيح. يجب أن تتطابق بيئة التقسيم المرحلي مع بيئة الإنتاج بقدر ما هي معقولة.
إذا كنت تقوم بنشر تطبيق التعلم الآلي مع الاستدلال في الوقت الحقيقي، يجب عليك إنشاء واختبار خدمة البنية الأساسية في بيئة التقسيم المرحلي. يتضمن ذلك تشغيل مسار توزيع النموذج، والذي ينشئ نقطة نهاية خدمة في بيئة التشغيل المرحلي ويحمل نموذجا.
لتقليل الوقت المطلوب لتشغيل اختبارات التكامل، يمكن لبعض الخطوات المقايضة بين دقة الاختبار والسرعة أو التكلفة. على سبيل المثال، إذا كانت النماذج مكلفة أو تستغرق وقتا طويلا للتدريب، فقد تستخدم مجموعات فرعية صغيرة من البيانات أو تشغيل تكرارات تدريب أقل. بالنسبة لخدمة النموذج، اعتمادا على متطلبات الإنتاج، قد تقوم بإجراء اختبار تحميل كامل النطاق في اختبارات التكامل، أو قد تختبر فقط وظائف دفعية صغيرة أو طلبات إلى نقطة نهاية مؤقتة.
4. الدمج إلى فرع التقسيم المرحلي
إذا اجتزت جميع الاختبارات، يتم دمج التعليمات البرمجية الجديدة في الفرع الرئيسي للمشروع. إذا فشلت الاختبارات، يجب أن يقوم نظام CI/CD بإعلام المستخدمين ونشر النتائج على طلب السحب.
يمكنك جدولة اختبارات التكامل الدورية على الفرع الرئيسي. هذه فكرة جيدة إذا كان الفرع يتم تحديثه بشكل متكرر مع طلبات سحب متزامنة من عدة مستخدمين.
5. إنشاء فرع إصدار
بعد اجتياز اختبارات التكامل المستمر ودمج فرع التطوير في الفرع الرئيسي، ينشئ مهندس التعلم الآلي فرع إصدار، مما يؤدي إلى تشغيل نظام CI/CD لتحديث مهام الإنتاج.
مرحلة الإنتاج
يمتلك مهندسو التعلم الآلي بيئة الإنتاج حيث يتم نشر البنية الأساسية لبرنامج ربط العمليات التجارية ML وتنفيذها. تؤدي هذه المسارات إلى تشغيل تدريب النموذج، والتحقق من صحة إصدارات النموذج الجديدة ونشرها، ونشر التنبؤات إلى جداول أو تطبيقات انتقال البيانات من الخادم، ومراقبة العملية بأكملها لتجنب تدهور الأداء وعدم الاستقرار.
عادة ما لا يكون لدى علماء البيانات حق الوصول للكتابة أو الحساب في بيئة الإنتاج. ومع ذلك، من المهم أن يكون لديهم رؤية لاختبار النتائج والسجلات والبيانات الاصطناعية للنموذج وحالة مسار الإنتاج وجداول المراقبة. تسمح لهم هذه الرؤية بتحديد المشاكل وتشخيصها في الإنتاج ومقارنة أداء النماذج الجديدة بالنماذج قيد الإنتاج حاليا. يمكنك منح علماء البيانات حق الوصول للقراءة فقط إلى الأصول في كتالوج الإنتاج لهذه الأغراض.
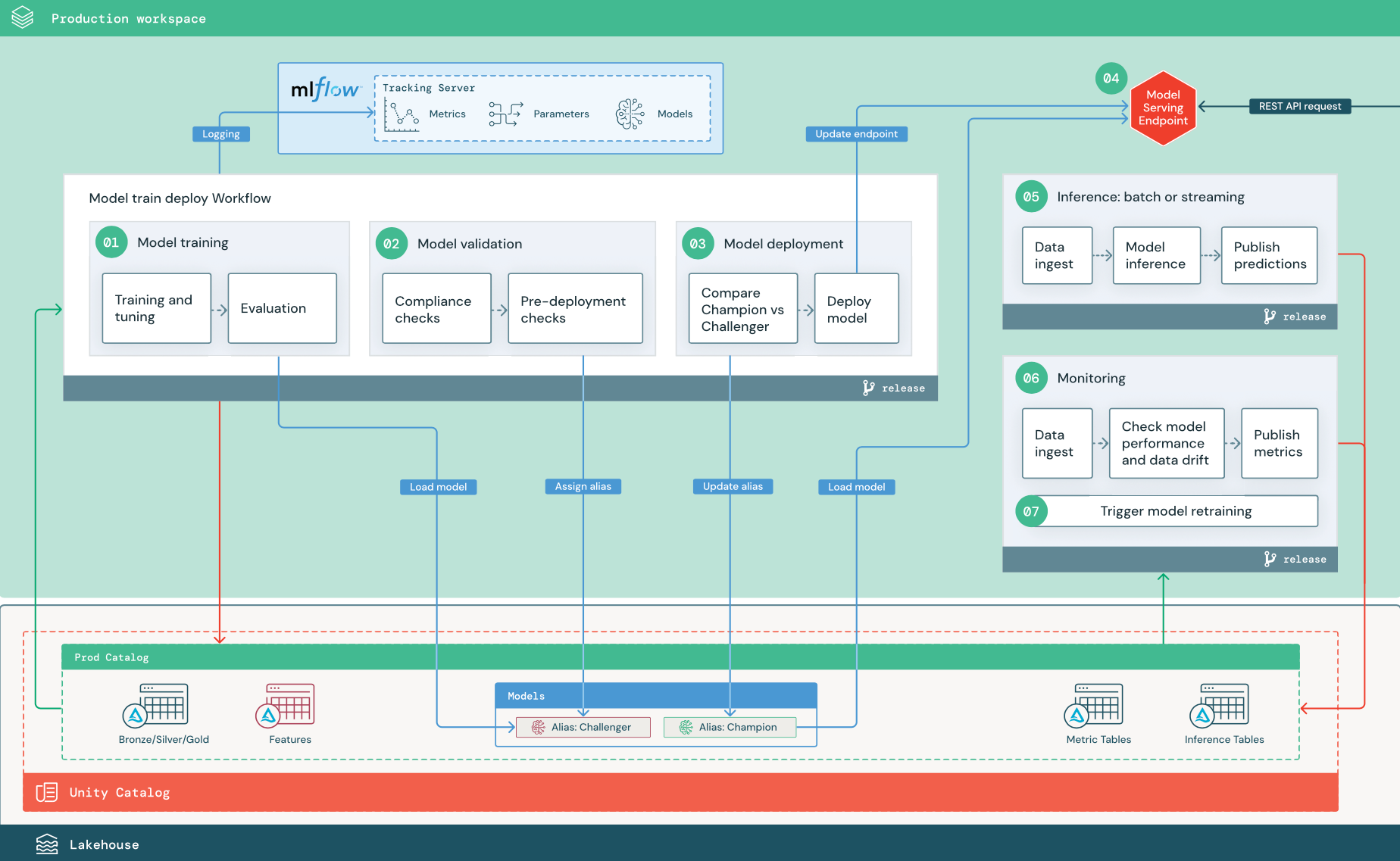
تتوافق الخطوات الرقمية مع الأرقام المعروضة في الرسم التخطيطي.
1. تدريب النموذج
يمكن تشغيل هذا المسار عن طريق تغييرات التعليمات البرمجية أو عن طريق مهام إعادة التدريب التلقائية. في هذه الخطوة، يتم استخدام الجداول من كتالوج الإنتاج للخطوات التالية.
التدريب والضبط. أثناء عملية التدريب، يتم تسجيل السجلات إلى بيئة الإنتاج خادم تتبع MLflow. تتضمن هذه السجلات مقاييس النموذج والمعلمات والعلامات والنموذج نفسه. إذا كنت تستخدم جداول الميزات، يتم تسجيل النموذج إلى MLflow باستخدام عميل Databricks Feature Store، الذي يحزم النموذج بمعلومات البحث عن الميزات المستخدمة في وقت الاستدلال.
أثناء التطوير، قد يختبر علماء البيانات العديد من الخوارزميات والمقاييس الفائقة. في التعليمات البرمجية للتدريب على الإنتاج، من الشائع مراعاة الخيارات الأعلى أداء فقط. الحد من الضبط بهذه الطريقة يوفر الوقت ويمكن أن يقلل من التباين من الضبط في إعادة التدريب التلقائي.
إذا كان لدى علماء البيانات حق الوصول للقراءة فقط إلى كتالوج الإنتاج، فقد يتمكنوا من تحديد المجموعة المثلى من المعلمات الفائقة للنموذج. في هذه الحالة، يمكن تنفيذ مسار تدريب النموذج المنشور في الإنتاج باستخدام مجموعة محددة من المعلمات الفائقة، المضمنة عادة في البنية الأساسية لبرنامج ربط العمليات التجارية كملف تكوين.
التقييم. يتم تقييم جودة النموذج عن طريق اختبار بيانات الإنتاج المحتفظ بها. يتم تسجيل نتائج هذه الاختبارات إلى خادم تتبع MLflow. تستخدم هذه الخطوة مقاييس التقييم المحددة من قبل علماء البيانات في مرحلة التطوير. قد تتضمن هذه المقاييس تعليمة برمجية مخصصة.
تسجيل النموذج. عند اكتمال تدريب النموذج، يتم حفظ البيانات الاصطناعية للنموذج كإصدار نموذج مسجل في مسار النموذج المحدد في كتالوج الإنتاج في كتالوج Unity. ينتج عن مهمة تدريب النموذج URI نموذج يمكن أن تستخدمه مهمة التحقق من صحة النموذج. يمكنك استخدام قيم المهام لتمرير URI هذا إلى النموذج.
2. التحقق من صحة النموذج
يستخدم هذا المسار URI النموذج من الخطوة 1 ويحمل النموذج من كتالوج Unity. ثم ينفذ سلسلة من عمليات التحقق من الصحة. تعتمد عمليات التحقق هذه على مؤسستك وحالة الاستخدام، ويمكن أن تتضمن أشياء مثل التنسيق الأساسي والتحقق من صحة بيانات التعريف، وتقييمات الأداء على شرائح البيانات المحددة، والامتثال للمتطلبات التنظيمية مثل عمليات التحقق من التوافق للعلامات أو الوثائق.
إذا نجح النموذج في اجتياز جميع عمليات التحقق من الصحة، يمكنك تعيين الاسم المستعار "Challenger" لإصدار النموذج في كتالوج Unity. إذا لم يجتاز النموذج جميع عمليات التحقق من الصحة، يتم إنهاء العملية ويمكن إعلام المستخدمين تلقائيا. يمكنك استخدام العلامات لإضافة سمات قيمة المفتاح اعتمادا على نتيجة عمليات التحقق من الصحة هذه. على سبيل المثال، يمكنك إنشاء علامة "model_validation_status" وتعيين القيمة إلى "معلق" أثناء تنفيذ الاختبارات، ثم تحديثها إلى "PASSED" أو "FAILED" عند اكتمال البنية الأساسية لبرنامج ربط العمليات التجارية.
نظرا لأن النموذج مسجل في كتالوج Unity، يمكن لعلماء البيانات الذين يعملون في بيئة التطوير تحميل إصدار النموذج هذا من كتالوج الإنتاج للتحقيق في ما إذا فشل النموذج في التحقق من الصحة. بغض النظر عن النتيجة، يتم تسجيل النتائج إلى النموذج المسجل في كتالوج الإنتاج باستخدام تعليقات توضيحية على إصدار النموذج.
3. توزيع النموذج
مثل مسار التحقق من الصحة، يعتمد مسار توزيع النموذج على مؤسستك وحالة الاستخدام. يفترض هذا القسم أنك عينت النموذج الذي تم التحقق من صحته حديثا الاسم المستعار "Challenger"، وأن نموذج الإنتاج الحالي قد تم تعيين الاسم المستعار "البطل". الخطوة الأولى قبل نشر النموذج الجديد هي التأكد من أنه يعمل على الأقل بالإضافة إلى نموذج الإنتاج الحالي.
مقارنة "CHALLENGER" بنموذج "CHAMPION". يمكنك إجراء هذه المقارنة دون اتصال أو عبر الإنترنت. تقيم المقارنة دون اتصال كلا النموذجين مقابل مجموعة بيانات محتفظ بها وتتعقب النتائج باستخدام خادم MLflow Tracking. بالنسبة لخدمة النموذج في الوقت الحقيقي، قد ترغب في إجراء مقارنات أطول قيد التشغيل عبر الإنترنت، مثل اختبارات A/B أو الإطلاق التدريجي للنموذج الجديد. إذا كان أداء إصدار نموذج "Challenger" أفضل في المقارنة، فإنه يحل محل الاسم المستعار الحالي "البطل".
تسمح لك الفسيفساء الذكاء الاصطناعي Model Serving وDatabricks Lakehouse Monitoring بجمع جداول الاستدلال التي تحتوي على بيانات الطلب والاستجابة لنقطة نهاية ومراقبتها تلقائيا.
إذا لم يكن هناك نموذج "بطل" موجود، فقد تقارن نموذج "Challenger" بنموذج الأعمال أو العتبة الأخرى كأساس.
العملية الموضحة هنا مؤتمتة بالكامل. إذا كانت خطوات الموافقة اليدوية مطلوبة، يمكنك إعداد تلك الخطوات باستخدام إشعارات سير العمل أو عمليات رد اتصال CI/CD من مسار توزيع النموذج.
توزيع النموذج. يمكن إعداد مسارات الاستدلال الدفعية أو المتدفقة لاستخدام النموذج مع الاسم المستعار "البطل". بالنسبة لحالات الاستخدام في الوقت الحقيقي، يجب إعداد البنية الأساسية لنشر النموذج كنقطة نهاية REST API. يمكنك إنشاء نقطة النهاية هذه وإدارتها باستخدام الفسيفساء الذكاء الاصطناعي Model Serving. إذا كانت نقطة النهاية قيد الاستخدام بالفعل للنموذج الحالي، يمكنك تحديث نقطة النهاية بالنموذج الجديد. تنفذ خدمة نموذج الفسيفساء الذكاء الاصطناعي تحديث وقت التعطل الصفري عن طريق الحفاظ على التكوين الحالي قيد التشغيل حتى يكون التكوين الجديد جاهزا.
4. خدمة النموذج
عند تكوين نقطة نهاية خدمة النموذج، يمكنك تحديد اسم النموذج في كتالوج Unity والإصدار الذي تريد خدمته. إذا تم تدريب إصدار النموذج باستخدام ميزات من جداول في كتالوج Unity، يخزن النموذج التبعيات للميزات والوظائف. يستخدم Model Serving تلقائيا هذا الرسم البياني للتبعية للبحث عن الميزات من المتاجر المناسبة عبر الإنترنت في وقت الاستدلال. يمكن أيضا استخدام هذا النهج لتطبيق وظائف للمعالجة المسبقة للبيانات أو لحساب الميزات عند الطلب أثناء تسجيل النموذج.
يمكنك إنشاء نقطة نهاية واحدة بنماذج متعددة وتحديد تقسيم نسبة استخدام الشبكة لنقطة النهاية بين هذه النماذج، ما يسمح لك بإجراء مقارنات "البطل" عبر الإنترنت مقابل مقارنات "Challenger".
5. الاستدلال: الدفعة أو الدفق
يقرأ مسار الاستدلال أحدث البيانات من كتالوج الإنتاج، وينفذ الوظائف لحساب الميزات عند الطلب، ويحمل نموذج "البطل"، ويسجل البيانات، ويعيد التنبؤات. الاستدلال الدفعي أو الدفق هو بشكل عام الخيار الأكثر فعالية من حيث التكلفة لحالات استخدام أعلى من حيث الإنتاجية وزمن انتقال أعلى. بالنسبة للسيناريوهات التي تكون فيها التنبؤات ذات زمن الانتقال المنخفض مطلوبة، ولكن يمكن حساب التنبؤات دون اتصال بالإنترنت، يمكن نشر تنبؤات الدفعات هذه إلى مخزن قيم المفاتيح عبر الإنترنت مثل DynamoDB أو Cosmos DB.
تتم الإشارة إلى النموذج المسجل في كتالوج Unity بواسطة الاسم المستعار الخاص به. يتم تكوين مسار الاستدلال لتحميل وتطبيق إصدار نموذج "البطل". إذا تم تحديث إصدار "البطل" إلى إصدار نموذج جديد، فإن مسار الاستدلال يستخدم تلقائيا الإصدار الجديد لتنفيذه التالي. بهذه الطريقة يتم فصل خطوة نشر النموذج عن مسارات الاستدلال.
عادة ما تنشر وظائف الدفعات التنبؤات إلى الجداول في كتالوج الإنتاج أو إلى الملفات المسطحة أو عبر اتصال JDBC. عادة ما تنشر مهام الدفق التنبؤات إما إلى جداول كتالوج Unity أو إلى قوائم انتظار الرسائل مثل Apache Kafka.
6. مراقبة Lakehouse
تراقب Lakehouse Monitoring الخصائص الإحصائية، مثل انحراف البيانات وأداء النموذج، لبيانات الإدخال وتوقعات النموذج. يمكنك إنشاء تنبيهات استنادا إلى هذه المقاييس أو نشرها في لوحات المعلومات.
- استيعاب البيانات. يقرأ هذا المسار في السجلات من الدفعة أو الدفق أو الاستدلال عبر الإنترنت.
- تحقق من الدقة وانحراف البيانات. يحسب المسار مقاييس حول بيانات الإدخال وتوقعات النموذج وأداء البنية الأساسية. يحدد علماء البيانات البيانات ومقاييس النموذج أثناء التطوير، ويحدد مهندسو التعلم الآلي مقاييس البنية الأساسية. يمكنك أيضا تحديد مقاييس مخصصة باستخدام Lakehouse Monitoring.
- نشر المقاييس وإعداد التنبيهات. يكتب المسار إلى الجداول في كتالوج الإنتاج للتحليل وإعداد التقارير. يجب عليك تكوين هذه الجداول لتكون قابلة للقراءة من بيئة التطوير حتى يتمكن علماء البيانات من الوصول للتحليل. يمكنك استخدام Databricks SQL لإنشاء لوحات معلومات مراقبة لتتبع أداء النموذج، وإعداد مهمة المراقبة أو أداة لوحة المعلومات لإصدار إشعار عندما يتجاوز المقياس حدا محددا.
- تشغيل إعادة تدريب النموذج. عندما تشير مقاييس المراقبة إلى مشكلات الأداء أو التغييرات في بيانات الإدخال، قد يحتاج عالم البيانات إلى تطوير إصدار نموذج جديد. يمكنك إعداد تنبيهات SQL لإعلام علماء البيانات عند حدوث ذلك.
7. إعادة التدريب
تدعم هذه البنية إعادة التدريب التلقائي باستخدام نفس مسار تدريب النموذج أعلاه. توصي Databricks بالبدء بإعادة التدريب الدوري المجدول والانتقال إلى إعادة التدريب التي تم تشغيلها عند الحاجة.
- المقرر. إذا كانت البيانات الجديدة متوفرة بشكل منتظم، يمكنك إنشاء مهمة مجدولة لتشغيل التعليمات البرمجية للتدريب النموذجي على أحدث البيانات المتاحة. راجع أنواع المشغلات لوظائف Databricks
- مشغِّلة. إذا كان مسار المراقبة يمكنه تحديد مشكلات أداء النموذج وإرسال التنبيهات، فيمكنه أيضا تشغيل إعادة التدريب. على سبيل المثال، إذا تغير توزيع البيانات الواردة بشكل كبير أو إذا انخفض أداء النموذج، فإن إعادة التدريب التلقائي وإعادة التوزيع يمكن أن تعزز أداء النموذج بأقل تدخل بشري. يمكن تحقيق ذلك من خلال تنبيه SQL للتحقق مما إذا كان المقياس شاذا (على سبيل المثال، تحقق من الانجراف أو جودة النموذج مقابل الحد). يمكن تكوين التنبيه لاستخدام وجهة إخطار على الويب، والتي يمكن أن تؤدي لاحقا إلى تشغيل سير عمل التدريب.
إذا أظهرت البنية الأساسية لبرنامج ربط العمليات التجارية إعادة التدريب أو المسارات الأخرى مشكلات في الأداء، فقد يحتاج عالم البيانات إلى العودة إلى بيئة التطوير لإجراء تجارب إضافية لمعالجة المشكلات.