إشعار
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تسجيل الدخول أو تغيير الدلائل.
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تغيير الدلائل.
مستودع البيانات هو نظام إدارة البيانات الذي يجمع بين فوائد مستودعات البيانات ومستودعات البيانات. توضح هذه المقالة النمط المعماري للبحيرة وما يمكنك القيام به به على Azure Databricks.
ما هو مستودع البيانات المستخدم؟
يوفر مستودع البيانات قدرات تخزين ومعالجة قابلة للتطوير للمؤسسات الحديثة التي ترغب في تجنب الأنظمة المعزولة لمعالجة أحمال العمل المختلفة، مثل التعلم الآلي (ML) والمعلومات المهنية (BI). يمكن أن يساعد مستودع البيانات في إنشاء مصدر واحد للحقيقة، والقضاء على التكاليف الزائدة عن الحاجة، وضمان حداثة البيانات.
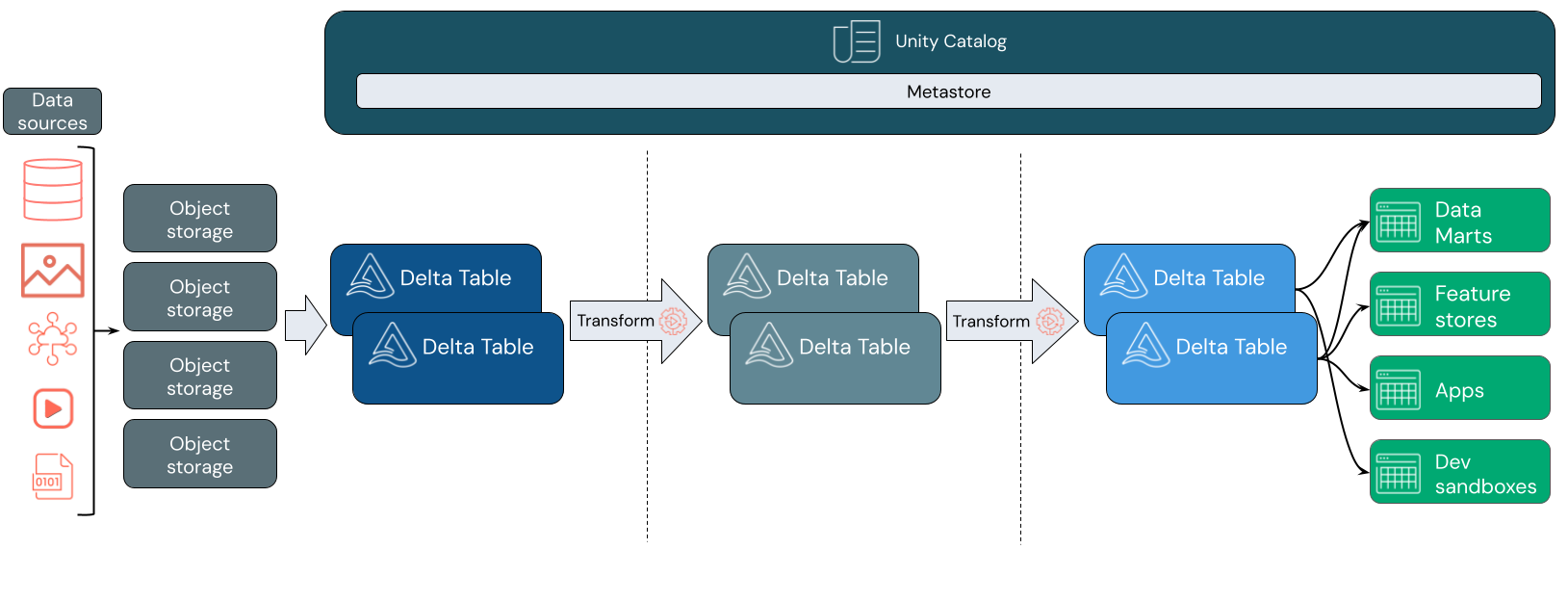
غالبا ما تستخدم بحيرات البيانات نمط تصميم البيانات الذي يحسن البيانات ويثريها ويحسنها بشكل متزايد أثناء انتقالها عبر طبقات من التقسيم المرحلي والتحويل. يمكن أن تتضمن كل طبقة من طبقة البحيرة طبقة واحدة أو أكثر. يشار إلى هذا النمط بشكل متكرر باسم بنية الميدالية. لمزيد من المعلومات، راجع ما هو تصميم بحيرة الميدالية؟
كيف يعمل مستودع Databricks؟
تم إنشاء Databricks على Apache Spark. يتيح Apache Spark محركا قابلا للتطوير بشكل كبير يعمل على موارد الحوسبة المنفصلة عن التخزين. لمزيد من المعلومات، راجع Apache Spark على Azure Databricks
يستخدم مستودع Databricks اثنين من التقنيات الرئيسية الإضافية:
- Delta Lake: طبقة تخزين محسنة تدعم معاملات ACID وفرض المخطط.
- كتالوج Unity: حل حوكمة موحد دقيق للبيانات الذكاء الاصطناعي.
استيعاب البيانات
في طبقة الاستيعاب، تصل البيانات الدفعية أو المتدفقة من مجموعة متنوعة من المصادر وبأشكال متنوعة. توفر هذه الطبقة المنطقية الأولى مكانا لتلك البيانات لتهبط بتنسيقها الخام. أثناء تحويل هذه الملفات إلى جداول Delta، يمكنك استخدام قدرات فرض المخطط في Delta Lake للتحقق من وجود بيانات مفقودة أو غير متوقعة. يمكنك استخدام كتالوج Unity لتسجيل الجداول وفقا لنموذج إدارة البيانات وحدود عزل البيانات المطلوبة. يسمح لك كتالوج Unity بتعقب دورة حياة بياناتك أثناء تحويلها وتحسينها، بالإضافة إلى تطبيق نموذج حوكمة موحد للحفاظ على خصوصية البيانات الحساسة وأمانها.
معالجة البيانات، والمعالجة، والتكامل
بمجرد التحقق من ذلك، يمكنك البدء في تنسيق بياناتك وتحسينها. يعمل علماء البيانات وممارسو التعلم الآلي بشكل متكرر مع البيانات في هذه المرحلة لبدء الجمع بين ميزات جديدة أو إنشائها وتنقية البيانات بالكامل. بمجرد تنظيف بياناتك بدقة، يمكن دمجها وإعادة تنظيمها في جداول مصممة لتلبية احتياجات عملك الخاصة.
يعني نهج المخطط عند الكتابة، جنبا إلى جنب مع قدرات تطور مخطط دلتا، أنه يمكنك إجراء تغييرات على هذه الطبقة دون الحاجة بالضرورة إلى إعادة كتابة منطق انتقال البيانات من الخادم الذي يخدم البيانات للمستخدمين النهائيين.
خدمة البيانات
تخدم الطبقة النهائية البيانات النظيفة والمثرية للمستخدمين النهائيين. يجب تصميم الجداول النهائية لخدمة البيانات لجميع حالات الاستخدام الخاصة بك. يعني نموذج الحوكمة الموحد أنه يمكنك تتبع دورة حياة البيانات مرة أخرى إلى مصدرك الوحيد للحقيقة. تسمح تخطيطات البيانات، المحسنة لمهام مختلفة، للمستخدمين النهائيين بالوصول إلى البيانات لتطبيقات التعلم الآلي وهندسة البيانات والمعلومات المهنية وإعداد التقارير.
لمعرفة المزيد حول Delta Lake، راجع ما هو Delta Lake؟ لمعرفة المزيد حول كتالوج Unity، راجع ما هو كتالوج Unity؟
قدرات مستودع Databricks
يحل مستودع مبني على Databricks محل الاعتماد الحالي على مستودعات البيانات ومستودعات البيانات لشركات البيانات الحديثة. تتضمن بعض المهام الرئيسية التي يمكنك تنفيذها ما يلي:
- معالجة البيانات في الوقت الحقيقي: معالجة البيانات المتدفقة في الوقت الفعلي للتحليل الفوري والعمل.
- تكامل البيانات: توحيد بياناتك في نظام واحد لتمكين التعاون وإنشاء مصدر واحد للحقيقة لمؤسستك.
- تطور المخطط: تعديل مخطط البيانات بمرور الوقت للتكيف مع احتياجات الأعمال المتغيرة دون تعطيل مسارات البيانات الحالية.
- تحويلات البيانات: يؤدي استخدام Apache Spark وData Lake إلى جلب السرعة وقابلية التوسع والموثوقية لبياناتك.
- تحليل البيانات وإعداد التقارير: قم بتشغيل الاستعلامات التحليلية المعقدة باستخدام محرك محسن لأحمال عمل تخزين البيانات.
- التعلم الآلي الذكاء الاصطناعي: تطبيق تقنيات التحليلات المتقدمة على جميع بياناتك. استخدم التعلم الآلي لإثراء بياناتك ودعم أحمال العمل الأخرى.
- تعيين إصدار البيانات و دورة حياة البيانات: الاحتفاظ بمحفوظات الإصدار لمجموعات البيانات وتتبع دورة حياة البيانات لضمان مصدر البيانات وإمكانية التتبع.
- إدارة البيانات: استخدم نظاما واحدا وموحدا للتحكم في الوصول إلى بياناتك وإجراء عمليات التدقيق.
- مشاركة البيانات: تسهيل التعاون من خلال السماح بمشاركة مجموعات البيانات المنسقة والتقارير والرؤى عبر الفرق.
- التحليلات التشغيلية: مراقبة مقاييس جودة البيانات ومقاييس جودة النموذج والانجراف من خلال تطبيق التعلم الآلي على بيانات مراقبة lakehouse.
Lakehouse مقابل Data Lake مقابل Data Warehouse
تمتلك مستودعات البيانات قرارات ذكاء الأعمال (BI) لمدة 30 عاما تقريبا، بعد أن تطورت باعتبارها مجموعة من إرشادات التصميم للأنظمة التي تتحكم في تدفق البيانات. تعمل مستودعات بيانات المؤسسة على تحسين الاستعلامات لتقارير BI، ولكن يمكن أن تستغرق دقائق أو حتى ساعات لإنشاء النتائج. مصممة للبيانات التي من غير المحتمل أن تتغير بتردد عال، تسعى مستودعات البيانات إلى منع التعارضات بين الاستعلامات قيد التشغيل المتزامن. تعتمد العديد من مستودعات البيانات على التنسيقات الخاصة، والتي غالبا ما تحد من دعم التعلم الآلي. يستفيد تخزين البيانات على Azure Databricks من قدرات مستودع Databricks وDatabricks SQL. لمزيد من المعلومات، راجع ما هو تخزين البيانات على Azure Databricks؟.
وقد أصبحت مستودعات البيانات مستخدمة على نطاق واسع على مدى العقد الماضي بفضل التقدم التكنولوجي في تخزين البيانات مدفوعا بزيادات هائلة في أنواع البيانات وحجمها. تخزن مستودعات البيانات البيانات وتعالجها بتكلفة زهيدة وفعالة. غالبا ما يتم تعريف مستودعات البيانات بشكل معارض لمستودعات البيانات: يوفر مستودع البيانات بيانات نظيفة ومنظمة لتحليلات المعلومات المهنية، بينما يخزن مستودع البيانات البيانات بشكل دائم ورخيص بأي شكل من الأشكال. تستخدم العديد من المؤسسات مستودعات البيانات لعلوم البيانات والتعلم الآلي، ولكن ليس لإعداد تقارير المعلومات المهنية بسبب طبيعتها غير المصدقة.
تجمع مستودع البيانات بين فوائد مستودعات البيانات ومستودعات البيانات وتوفر:
- الوصول المفتوح والمباشر إلى البيانات المخزنة بتنسيقات البيانات القياسية.
- بروتوكولات الفهرسة المحسنة للتعلم الآلي وعلوم البيانات.
- زمن انتقال استعلام منخفض وموثوقية عالية ل BI والتحليلات المتقدمة.
من خلال الجمع بين طبقة بيانات التعريف المحسنة والبيانات التي تم التحقق من صحتها المخزنة في تنسيقات قياسية في تخزين الكائنات السحابية، يسمح مستودع البيانات لعلماء البيانات ومهندسي التعلم الآلي ببناء نماذج من نفس تقارير المعلومات المهنية المستندة إلى البيانات.
الخطوة التالية
لمعرفة المزيد حول المبادئ وأفضل الممارسات لتنفيذ وتشغيل مستودع باستخدام Databricks، راجع مقدمة إلى مستودع البيانات المصمم جيدا