إشعار
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تسجيل الدخول أو تغيير الدلائل.
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تغيير الدلائل.
نموذج MLflow هو تنسيق قياسي لتغليف نماذج التعلم الآلي التي يمكن استخدامها في مجموعة متنوعة من أدوات انتقال البيانات من الخادم - على سبيل المثال، الاستدلال الدفعي على Apache Spark أو الخدمة في الوقت الحقيقي من خلال واجهة برمجة تطبيقات REST. يحدد التنسيق اصطلاحا يتيح لك حفظ نموذج بنكهات مختلفة (python-function وpytorch وsklearn وما إلى ذلك)، والتي يمكن فهمها من خلال أنظمة أساسية مختلفة لخدمة النموذج والاستدلال.
لمعرفة كيفية تسجيل نموذج تدفق وتسجيله، راجع كيفية حفظ نموذج تدفق وتحميله.
نماذج السجل والتحميل
عند تسجيل نموذج، يقوم MLflow تلقائيا بتسجيل والملفات requirements.txt conda.yaml . يمكنك استخدام هذه الملفات لإعادة إنشاء بيئة تطوير النموذج وإعادة تثبيت التبعيات باستخدام virtualenv (مستحسن) أو conda.
هام
تحديث Anaconda Inc. لشروط الخدمة الخاصة بهم لقنوات anaconda.org. بناء على شروط الخدمة الجديدة، قد تحتاج إلى ترخيص تجاري إذا كنت تعتمد على حزم وتوزيع Anaconda. راجع الأسئلة المتداولة حول Anaconda Commercial Edition لمزيد من المعلومات. يخضع استخدامك لأي قنوات Anaconda لشروط الخدمة الخاصة بها.
تم تسجيل نماذج MLflow التي تم تسجيلها قبل الإصدار 1.18 (Databricks Runtime 8.3 ML أو إصدار سابق) بشكل افتراضي باستخدام قناة conda defaults (https://repo.anaconda.com/pkgs/) كتبعية. وبسبب تغيير الترخيص هذا، أوقف Databricks استخدام القناة defaults للنماذج التي تم تسجيلها باستخدام MLflow v1.18 وما فوق. القناة الافتراضية المسجلة هي الآن conda-forge، والتي تشير إلى المجتمع المدار https://conda-forge.org/.
إذا قمت بتسجيل نموذج قبل MLflow v1.18 دون استبعاد defaults القناة من بيئة conda للنموذج، فقد يكون لهذا النموذج تبعية على القناة defaults التي قد لا تكون قد قصدتها.
لتأكيد ما إذا كان النموذج يحتوي على هذه التبعية يدويا، يمكنك فحص channel القيمة في conda.yaml الملف الذي تم حزمه مع النموذج المسجل. على سبيل المثال، قد يبدو النموذج conda.yaml مع defaults تبعية القناة كما يلي:
channels:
- defaults
dependencies:
- python=3.8.8
- pip
- pip:
- mlflow
- scikit-learn==0.23.2
- cloudpickle==1.6.0
name: mlflow-env
نظرا لأن Databricks لا يمكنها تحديد ما إذا كان استخدامك لمستودع Anaconda للتفاعل مع نماذجك مسموحا به في إطار علاقتك ب Anaconda، فإن Databricks لا يجبر عملائها على إجراء أي تغييرات. إذا كان استخدامك Anaconda.com repo من خلال استخدام Databricks مسموحا به بموجب شروط Anaconda، فلن تحتاج إلى اتخاذ أي إجراء.
إذا كنت ترغب في تغيير القناة المستخدمة في بيئة النموذج، يمكنك إعادة تسجيل النموذج في سجل النموذج باستخدام جديد conda.yaml. يمكنك القيام بذلك عن طريق تحديد القناة في معلمة conda_env log_model().
لمزيد من المعلومات حول log_model() واجهة برمجة التطبيقات، راجع وثائق MLflow لنكهة النموذج التي تعمل معها، على سبيل المثال، log_model ل scikit-learn.
لمزيد من المعلومات حول conda.yaml الملفات، راجع وثائق MLflow.
أوامر واجهة برمجة التطبيقات
لتسجيل نموذج إلى خادم تتبع MLflow، استخدم mlflow.<model-type>.log_model(model, ...).
لتحميل نموذج مسجل مسبقا للاستدلال أو مزيد من التطوير، استخدم mlflow.<model-type>.load_model(modelpath)، حيث modelpath يكون أحد الإجراءات التالية:
- مسار تشغيل نسبي (مثل
runs:/{run_id}/{model-path}) - مسار وحدات تخزين كتالوج Unity (مثل
dbfs:/Volumes/catalog_name/schema_name/volume_name/{path_to_artifact_root}/{model_path}) - مسار تخزين البيانات الاصطناعية المدارة بواسطة MLflow بدءا من
dbfs:/databricks/mlflow-tracking/ - مسار نموذج مسجل (مثل
models:/{model_name}/{model_stage}).
للحصول على قائمة كاملة بالخيارات لتحميل نماذج MLflow، راجع الرجوع إلى البيانات الاصطناعية في وثائق MLflow.
بالنسبة لنماذج Python MLflow، هناك خيار إضافي وهو استخدام mlflow.pyfunc.load_model() لتحميل النموذج كدالة Python عامة.
يمكنك استخدام القصاصة البرمجية التالية لتحميل النموذج وتسجيل نقاط البيانات.
model = mlflow.pyfunc.load_model(model_path)
model.predict(model_input)
كبديل، يمكنك تصدير النموذج ك Apache Spark UDF لاستخدامه في التسجيل على مجموعة Spark، إما كوظيفة دفعية أو كمهمة Spark Streaming في الوقت الفعلي.
# load input data table as a Spark DataFrame
input_data = spark.table(input_table_name)
model_udf = mlflow.pyfunc.spark_udf(spark, model_path)
df = input_data.withColumn("prediction", model_udf())
تبعيات نموذج السجل
لتحميل نموذج بدقة، يجب التأكد من تحميل تبعيات النموذج بالإصدارات الصحيحة في بيئة دفتر الملاحظات. في Databricks Runtime 10.5 ML وما فوق، يحذرك MLflow إذا تم الكشف عن عدم تطابق بين البيئة الحالية وتبعيات النموذج.
يتم تضمين وظائف إضافية لتبسيط استعادة تبعيات النموذج في Databricks Runtime 11.0 ML وما فوق. في Databricks Runtime 11.0 ML وما فوق، بالنسبة لنماذج pyfunc النكهة، يمكنك استدعاء mlflow.pyfunc.get_model_dependencies لاسترداد وتنزيل تبعيات النموذج. ترجع هذه الدالة مسارا إلى ملف التبعيات الذي يمكنك تثبيته بعد ذلك باستخدام %pip install <file-path>. عند تحميل نموذج ك PySpark UDF، حدد env_manager="virtualenv" في mlflow.pyfunc.spark_udf المكالمة. يؤدي هذا إلى استعادة تبعيات النموذج في سياق PySpark UDF ولا يؤثر على البيئة الخارجية.
يمكنك أيضا استخدام هذه الوظيفة في Databricks Runtime 10.5 أو أقل عن طريق تثبيت MLflow الإصدار 1.25.0 أو أحدث يدويا:
%pip install "mlflow>=1.25.0"
للحصول على معلومات إضافية حول كيفية تسجيل تبعيات النموذج (Python وغير Python) والبيانات الاصطناعية، راجع تبعيات نموذج السجل.
تعرف على كيفية تسجيل تبعيات النموذج والبيانات الاصطناعية المخصصة لخدمة النموذج:
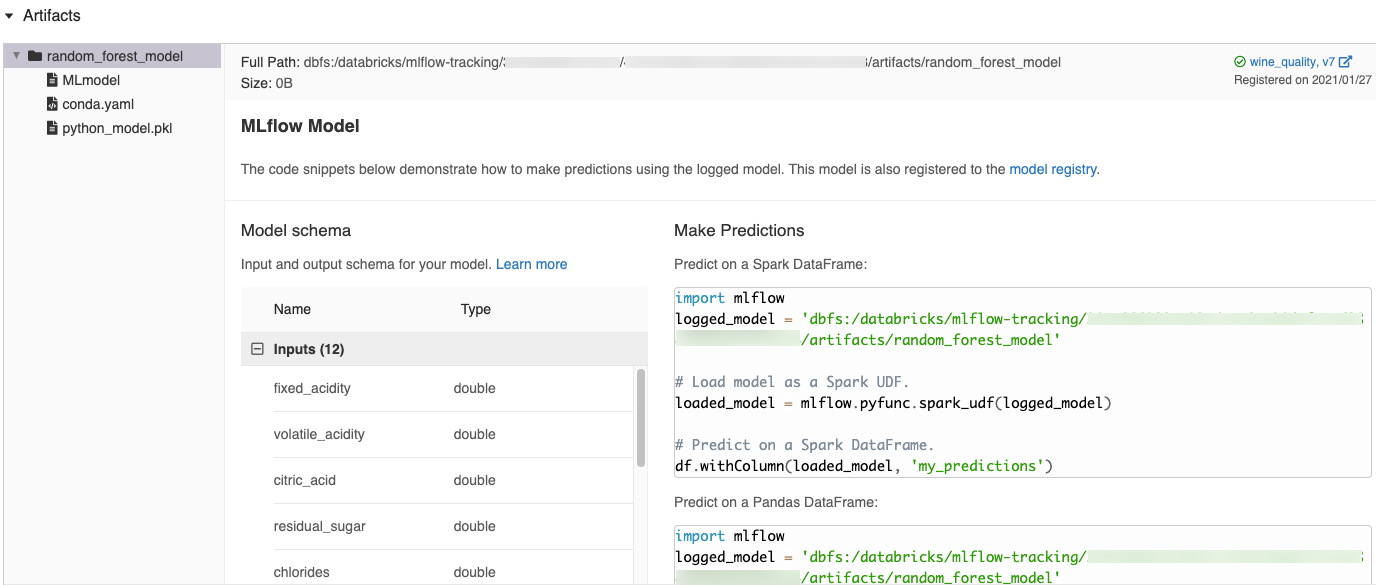
مقتطفات التعليمات البرمجية التي تم إنشاؤها تلقائيا في واجهة مستخدم MLflow
عند تسجيل نموذج في دفتر ملاحظات Azure Databricks، يقوم Azure Databricks تلقائيا بإنشاء قصاصات برمجية يمكنك نسخها واستخدامها لتحميل النموذج وتشغيله. لعرض قصاصات التعليمات البرمجية هذه:
- انتقل إلى شاشة Runs للتشغيل الذي أنشأ النموذج. (راجع عرض تجربة دفتر الملاحظات لمعرفة كيفية عرض شاشة "التشغيل".)
- قم بالتمرير إلى قسم Artifacts .
- انقر فوق اسم النموذج المسجل. تفتح لوحة على اليمين تظهر التعليمات البرمجية التي يمكنك استخدامها لتحميل النموذج المسجل وإجراء تنبؤات على Spark أو pandas DataFrames.
الأمثلة
للحصول على أمثلة لنماذج التسجيل، راجع الأمثلة في تتبع التدريب على التعلم الآلي أمثلة تشغيل. للحصول على مثال لتحميل نموذج مسجل للاستدلال، راجع مثال استنتاج النموذج.
تسجيل النماذج في Model Registry
يمكنك تسجيل النماذج في سجل نموذج MLflow، وهو مخزن نماذج مركزي يوفر واجهة مستخدم ومجموعة من واجهات برمجة التطبيقات لإدارة دورة الحياة الكاملة لنماذج MLflow. للحصول على إرشادات حول كيفية استخدام Model Registry لإدارة النماذج في كتالوج Databricks Unity، راجع إدارة دورة حياة النموذج في كتالوج Unity. لاستخدام Workspace Model Registry، راجع إدارة دورة حياة النموذج باستخدام Workspace Model Registry (قديم) .
لتسجيل نموذج باستخدام واجهة برمجة التطبيقات، استخدم mlflow.register_model("runs:/{run_id}/{model-path}", "{registered-model-name}").
حفظ النماذج في وحدات تخزين كتالوج Unity
لحفظ نموذج محليا، استخدم mlflow.<model-type>.save_model(model, modelpath). modelpath يجب أن يكون مسار وحدات تخزين كتالوج Unity. على سبيل المثال، إذا كنت تستخدم موقع dbfs:/Volumes/catalog_name/schema_name/volume_name/my_project_models وحدات تخزين كتالوج Unity لتخزين عمل المشروع الخاص بك، يجب استخدام مسار /dbfs/Volumes/catalog_name/schema_name/volume_name/my_project_modelsالنموذج :
modelpath = "/dbfs/Volumes/catalog_name/schema_name/volume_name/my_project_models/model-%f-%f" % (alpha, l1_ratio)
mlflow.sklearn.save_model(lr, modelpath)
بالنسبة لنماذج MLlib، استخدم ML Pipelines.
تنزيل البيانات الاصطناعية للنموذج
يمكنك تنزيل البيانات الاصطناعية للنموذج المسجل (مثل ملفات النموذج والمخططات والمقاييس) لنموذج مسجل بواجهات برمجة تطبيقات مختلفة.
مثال على واجهة برمجة تطبيقات Python:
from mlflow.store.artifact.models_artifact_repo import ModelsArtifactRepository
model_uri = MlflowClient.get_model_version_download_uri(model_name, model_version)
ModelsArtifactRepository(model_uri).download_artifacts(artifact_path="")
مثال على واجهة برمجة تطبيقات Java:
MlflowClient mlflowClient = new MlflowClient();
// Get the model URI for a registered model version.
String modelURI = mlflowClient.getModelVersionDownloadUri(modelName, modelVersion);
// Or download the model artifacts directly.
File modelFile = mlflowClient.downloadModelVersion(modelName, modelVersion);
مثال على أمر CLI:
mlflow artifacts download --artifact-uri models:/<name>/<version|stage>
توزيع نماذج لخدمة عبر الإنترنت
يمكنك استخدام موزاييك الذكاء الاصطناعي Model Serving لاستضافة نماذج التعلم الآلي المسجلة في سجل نموذج كتالوج Unity كنقاط نهاية REST. يتم تحديث نقاط النهاية هذه تلقائيا استنادا إلى توفر إصدارات النموذج ومراحلها.
يمكنك أيضا نشر نموذج إلى أطر عمل خدمة تابعة لجهة خارجية باستخدام أدوات النشر المضمنة في MLflow.