ملاحظة
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تسجيل الدخول أو تغيير الدلائل.
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تغيير الدلائل.
توضح هذه المقالة بعض تحسينات الأداء الأكثر شيوعًا التي يمكنك استخدامها لتحسين أداء استعلامات Apache Hive.
تحديد نوع نظام المجموعة
في Azure HDInsight، يمكنك تشغيل استعلامات Apache Hive على عدة أنواع مختلفة من أنظمة المجموعات.
اختر نوع نظام المجموعة المناسب للمساعدة في تحسين الأداء لتلبية احتياجات حمل العمل:
- اختر نوع نظام المجموعة Interactive Query لتحسين الاستعلامات التفاعلية
ad hoc. - اختر نوع نظام مجموعة Apache Hadoop لتحسين استعلامات Hive المستخدمة كمعالجة دُفعة.
- يمكن أيضا أن تقوم أنواع مجموعات Spark وHBase بتشغيل استعلامات Apache Hive، وقد تكون مناسبة إذا كنت تقوم بتشغيل أحمال العمل هذه.
لمزيد من المعلومات حول تشغيل استعلامات Hive على أنواع مختلفة من أنظمة مجموعات HDInsight، راجع ما هي Apache Hive وHiveQL في Azure HDInsight؟.
توسيع العقد العاملة
تسمح زيادة عدد العقد العاملة في مجموعة HDInsight بالعمل على استخدام المزيد من المعينات والمخفضات ليتم تشغيلها بالتوازي. هناك طريقتان يمكنك من خلالهما زيادة السعة في HDInsight:
عند إنشاء نظام مجموعة، يمكنك تحديد عدد العقد العاملة باستخدام مدخل Azure، أو Azure PowerShell، أو واجهة سطر الأوامر. لمزيد من المعلومات، راجع إنشاء أنظمة مجموعات HDInsight. تُظهر لقطة الشاشة التالية تكوين العقد العاملة في مدخل Azure:
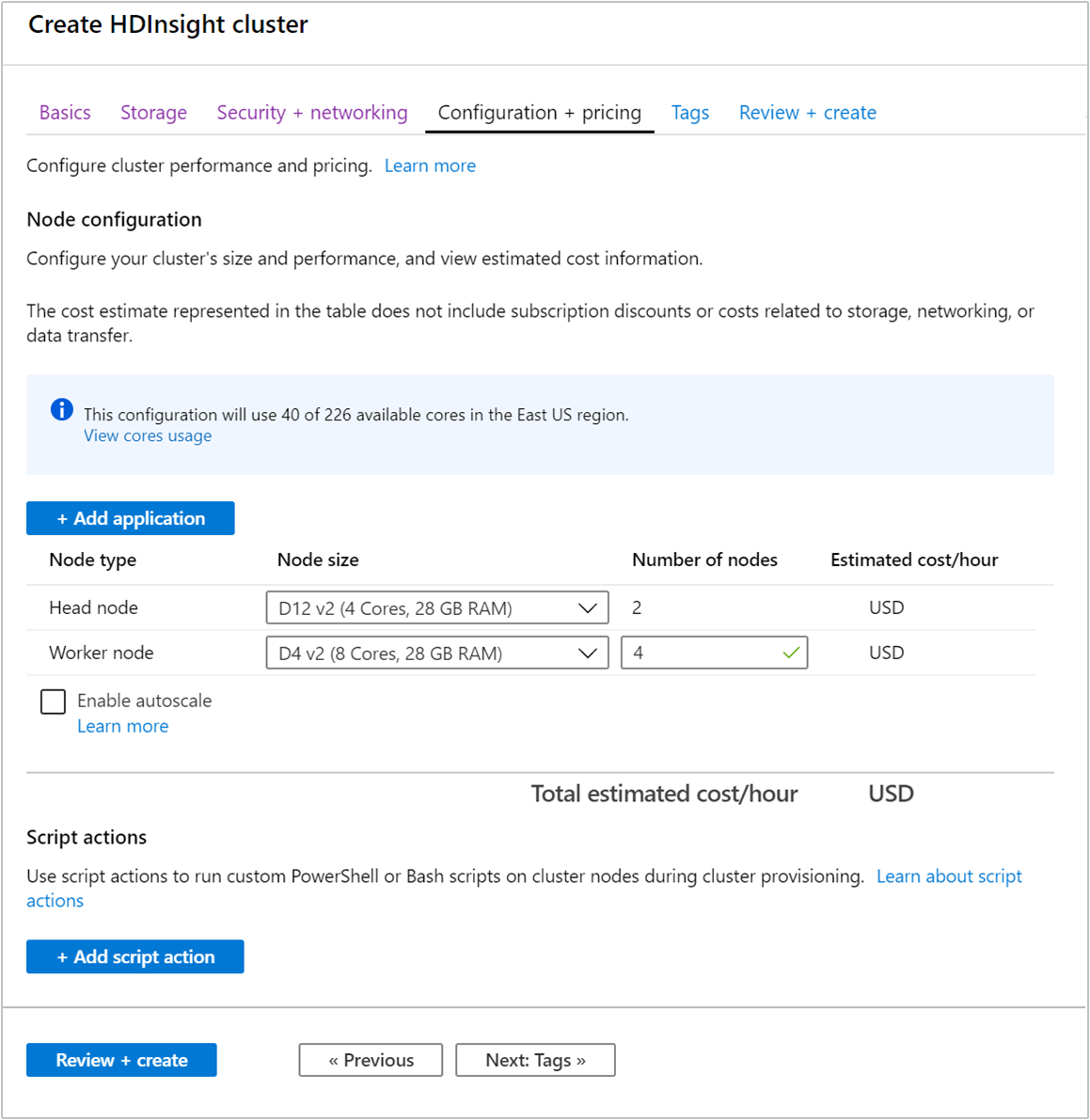
بعد الإنشاء، يمكنك أيضًا تحرير عدد العقد العاملة لتوسيع نظام المجموعة بشكل أكبر دون إعادة إنشاء واحد:
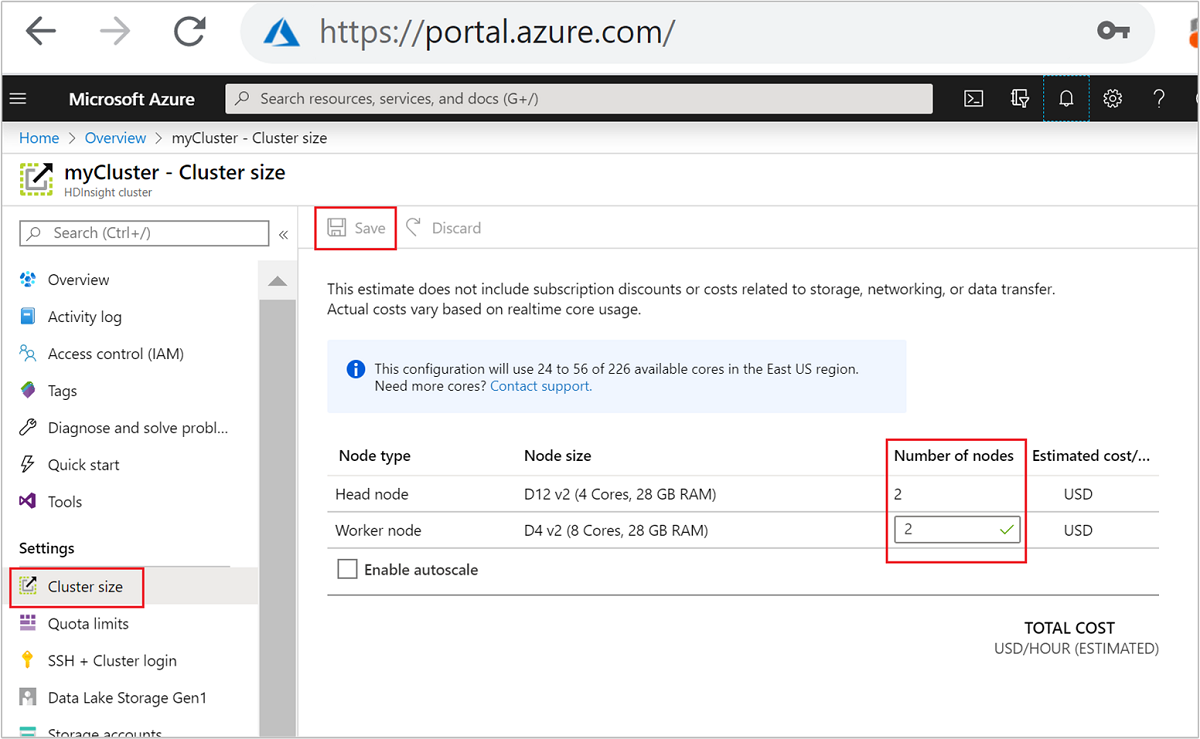
لمزيد من المعلومات حول تغيير حجم HDInsight، راجع تغيير حجم أنظمة مجموعات HDInsight
استخدام Apache Tez بدلاً من Map Reduce
Apache Tez هو محرك تنفيذ بديل لمحرك MapReduce. تعمل أنظمة مجموعات HDInsight المستندة إلى Linux على تمكين Tez بشكل افتراضي.
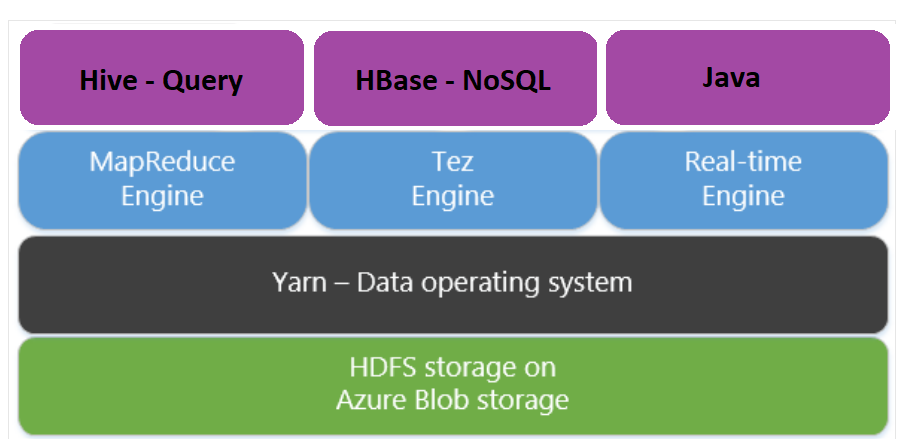
Tez أسرع للأسباب التالية:
- تنفيذ الرسم البياني الموجّه اللاحلقي (DAG) كمهمة واحدة في محرك MapReduce. يتطلب الرسم البياني الموجّه اللاحلقي (DAG) أن تتبع كل مجموعة من المُعينات بمجموعة واحدة من المخفضات. يؤدي هذا المطلب إلى تفرع مهام MapReduce متعددة لكل استعلام Hive. لا يوجد لدى Tez مثل هذا القيد ويمكنه معالجة الرسم البياني الموجّه اللاحلقي (DAG) المعقد كمهمة واحدة لتقليل عبء بدء تشغيل المهام الزائد عن الحد.
- تجنب عمليات الكتابة غير الضرورية. تُستخدم مهام متعددة لمعالجة نفس استعلام Hive في محرك MapReduce. تتم كتابة إخراج كل مهمة من مهام MapReduce إلى HDFS للحصول على بيانات وسيطة. نظرًا لأن Tez يقلل عدد المهام لكل استعلام Hive، فإنه قادر على تجنب عمليات الكتابة غير الضرورية.
- تقليل تأخير بدء التشغيل. يتمتع Tez بقدرة أفضل على تقليل تأخير بدء التشغيل من خلال تقليل عدد المُعينات التي يحتاجها للبدء وكذلك زيادة فعالية التحسين طوال الوقت.
- إعادة استخدام الحاويات. كلما أمكن إعادة استخدام حاويات Tez لضمان تقليل زمن الانتقال من بدء تشغيل الحاويات.
- تقنيات التحسين المستمر. جرت العادة على إجراء التحسين أثناء مرحلة التحويل البرمجي. ومع ذلك، يتوفر المزيد من المعلومات حول الإدخالات التي تسمح بتحسين أفضل أثناء وقت التشغيل. يستخدم Tez تقنيات التحسين المستمر التي تسمح له بتحسين الخطة بشكل أكبر في مرحلة وقت التشغيل.
لمزيد من المعلومات حول هذه المفاهيم، راجع Apache TEZ.
يمكنك جعل أي استعلام Hive في Tez ممكّنًا عن طريق بدء الاستعلام باستخدام الأمر set التالي:
set hive.execution.engine=tez;
تقسيم Hive
عمليات الإدخال/الإخراج هي عقبة الأداء الرئيسية لتشغيل استعلامات Hive. يمكن تحسين الأداء إذا كان من الممكن تقليل كمية البيانات التي يجب قراءتها. بشكل افتراضي، تقوم استعلامات Hive بمسح جداول Hive بأكملها ضوئيًا. ومع ذلك، بالنسبة للاستعلامات التي تحتاج فقط إلى مسح كمية صغيرة من البيانات ضوئيًا (على سبيل المثال، الاستعلامات ذات عوامل التصفية)، ينشأ عن هذا السلوك عبء غير ضروري. يسمح تقسيم Hive لاستعلامات Hive بالوصول فقط إلى كمية البيانات الضرورية في جداول Hive.
يتم تنفيذ تقسيم Hive عن طريق إعادة تنظيم البيانات الأولية إلى دلائل جديدة. كل قسم له دليل الملفات الخاص به. يحدد المستخدم التقسيم. يوضح الرسم التخطيطي التالي تقسيم جدول Hive حسب عمود السنة. يتم إنشاء دليل جديد لكل سنة.
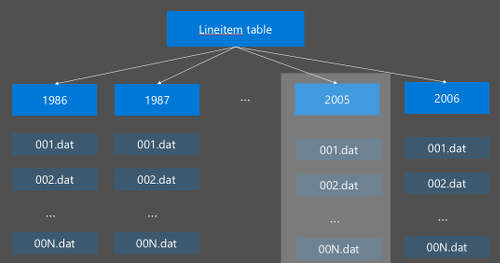
بعض اعتبارات التقسيم:
- عدم تقليل التقسيم - يمكن أن يؤدي التقسيم على أعمدة ذات قيم قليلة فقط إلى وجود أقسام قليلة. على سبيل المثال، يؤدي التقسيم على نوع الجنس إلى إنشاء قسمين فقط (ذكر وأنثى)، لذا قم بتقليل زمن الانتقال بمقدار النصف كحد أقصى.
- عدم الإفراط في التقسيم - على الطرف الآخر، يؤدي إنشاء تقسيم على عمود بقيمة فريدة (على سبيل المثال، معرف المستخدم) إلى وجود أقسام متعددة. يتسبب الإفراط في التقسيم في حدوث ضغط كبير على عقدة اسم نظام المجموعة حيث يتعين عليها معالجة عدد كبير من الدلائل.
- تجنب انحراف البيانات - اختر مفتاح التقسيم بحكمة بحيث تكون جميع الأقسام متساوية الحجم. على سبيل المثال، قد يؤدي التقسيم على عمود الولاية إلى انحراف توزيع البيانات. بما أن ولاية كاليفورنيا تضم حوالي 30 أضعاف عدد سكان ولاية فيرمونت، فمن المحتمل أن يكون حجم القسم منحرفا، وقد يختلف الأداء بشكل كبير.
لإنشاء جدول تقسبم، استخدم عبارة مقسم حسب:
CREATE TABLE lineitem_part
(L_ORDERKEY INT, L_PARTKEY INT, L_SUPPKEY INT,L_LINENUMBER INT,
L_QUANTITY DOUBLE, L_EXTENDEDPRICE DOUBLE, L_DISCOUNT DOUBLE,
L_TAX DOUBLE, L_RETURNFLAG STRING, L_LINESTATUS STRING,
L_SHIPDATE_PS STRING, L_COMMITDATE STRING, L_RECEIPTDATE STRING,
L_SHIPINSTRUCT STRING, L_SHIPMODE STRING, L_COMMENT STRING)
PARTITIONED BY(L_SHIPDATE STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS TEXTFILE;
بمجرد إنشاء الجدول المقسم، يمكنك إما إنشاء تقسيم ثابت أو تقسيم ديناميكي.
تقسيم ثابت يعني أنك قمت بالفعل بتقسيم البيانات في الدلائل المناسبة. باستخدام التقسيم الثابت، يمكنك إضافة أقسام Hive يدويًا استنادًا إلى موقع الدليل. تعتبر القصاصة البرمجية التالية مثالاً:
INSERT OVERWRITE TABLE lineitem_part PARTITION (L_SHIPDATE = '5/23/1996 12:00:00 AM') SELECT * FROM lineitem WHERE lineitem.L_SHIPDATE = '5/23/1996 12:00:00 AM' ALTER TABLE lineitem_part ADD PARTITION (L_SHIPDATE = '5/23/1996 12:00:00 AM') LOCATION 'wasb://sampledata@ignitedemo.blob.core.windows.net/partitions/5_23_1996/'تقسيم ديناميكي يعني أنك تريد من Hive إنشاء أقسام لك تلقائيًا. نظرًا لأنك قمت بالفعل بإنشاء جدول التقسيم من الجدول المرحلي، فكل ما عليك فعله هو إدراج البيانات في الجدول المقسم:
SET hive.exec.dynamic.partition = true; SET hive.exec.dynamic.partition.mode = nonstrict; INSERT INTO TABLE lineitem_part PARTITION (L_SHIPDATE) SELECT L_ORDERKEY as L_ORDERKEY, L_PARTKEY as L_PARTKEY, L_SUPPKEY as L_SUPPKEY, L_LINENUMBER as L_LINENUMBER, L_QUANTITY as L_QUANTITY, L_EXTENDEDPRICE as L_EXTENDEDPRICE, L_DISCOUNT as L_DISCOUNT, L_TAX as L_TAX, L_RETURNFLAG as L_RETURNFLAG, L_LINESTATUS as L_LINESTATUS, L_SHIPDATE as L_SHIPDATE_PS, L_COMMITDATE as L_COMMITDATE, L_RECEIPTDATE as L_RECEIPTDATE, L_SHIPINSTRUCT as L_SHIPINSTRUCT, L_SHIPMODE as L_SHIPMODE, L_COMMENT as L_COMMENT, L_SHIPDATE as L_SHIPDATE FROM lineitem;
لمزيد من المعلومات، راجع الجداول المقسمة.
استخدام تنسيق ORCFile
يدعم Hive تنسيقات ملفات مختلفة. على سبيل المثال:
- Text: تنسيق الملف الافتراضي ويعمل مع معظم السيناريوهات.
- Avro: يعمل بشكل جيد مع سيناريوهات إمكانية التشغيل التفاعلي.
- ORC/Parquet: الأنسب للأداء.
يعد تنسيق ORC (Optimized Row Columnar) طريقة فعالة للغاية لتخزين بيانات Hive. بالمقارنة مع التنسيقات الأخرى، يتمتع ORC بالمزايا التالية:
- دعم الأنواع المعقدة بما في ذلك "التاريخ والوقت" والأنواع المعقدة والمركبة جزئيًا.
- ضغط يصل إلى 70%.
- يقوم بفهرسة كل 10000 صف، مما يسمح بتخطي الصفوف.
- انخفاض كبير في تنفيذ وقت التشغيل.
لتمكين تنسيق ORC، عليك أولاً إنشاء جدول باستخدام العبارة Stored as ORC:
CREATE TABLE lineitem_orc_part
(L_ORDERKEY INT, L_PARTKEY INT,L_SUPPKEY INT, L_LINENUMBER INT,
L_QUANTITY DOUBLE, L_EXTENDEDPRICE DOUBLE, L_DISCOUNT DOUBLE,
L_TAX DOUBLE, L_RETURNFLAG STRING, L_LINESTATUS STRING,
L_SHIPDATE_PS STRING, L_COMMITDATE STRING, L_RECEIPTDATE STRING,
L_SHIPINSTRUCT STRING, L_SHIPMODE STRING, L_COMMENT STRING)
PARTITIONED BY(L_SHIPDATE STRING)
STORED AS ORC;
بعد ذلك، يمكنك إدراج البيانات في جدول ORC من الجدول المرحلي. على سبيل المثال:
INSERT INTO TABLE lineitem_orc
SELECT L_ORDERKEY as L_ORDERKEY,
L_PARTKEY as L_PARTKEY ,
L_SUPPKEY as L_SUPPKEY,
L_LINENUMBER as L_LINENUMBER,
L_QUANTITY as L_QUANTITY,
L_EXTENDEDPRICE as L_EXTENDEDPRICE,
L_DISCOUNT as L_DISCOUNT,
L_TAX as L_TAX,
L_RETURNFLAG as L_RETURNFLAG,
L_LINESTATUS as L_LINESTATUS,
L_SHIPDATE as L_SHIPDATE,
L_COMMITDATE as L_COMMITDATE,
L_RECEIPTDATE as L_RECEIPTDATE,
L_SHIPINSTRUCT as L_SHIPINSTRUCT,
L_SHIPMODE as L_SHIPMODE,
L_COMMENT as L_COMMENT
FROM lineitem;
يمكنك قراءة المزيد عن تنسيق ORC في دليل لغة Apache Hive.
التحويل إلى متجه
يسمح التحويل إلى متجه (Vectorization) لـ Hive بمعالجة دُفعة من 1024 صفًا معًا بدلاً من معالجة صف واحد في كل مرة. هذا يعني أن العمليات البسيطة تتم بشكل أسرع لأن عدد أقل من التعليمات البرمجية الداخلية يحتاج إلى تشغيل.
لتمكين التحويل إلى متجه (Vectorization)، قم ببدء استعلام Hive الخاص بك باستخدام الإعداد التالي:
set hive.vectorized.execution.enabled = true;
لمزيد من المعلومات، راجع تنفيذ استعلام متجه.
أساليب التحسين الأخرى
هناك المزيد من أساليب التحسين التي يمكنك أخذها في الاعتبار، على سبيل المثال:
- استخدام مستودع Hive: أسلوب يسمح بتجميع مجموعات كبيرة من البيانات أو تقسيمها لتحسين أداء الاستعلام.
- تحسين عمليات الربط: تحسين تخطيط تنفيذ استعلام Hive لتحسين كفاءة عمليات الربط وتقليل الحاجة إلى تلميحات المستخدم. لمزيد من المعلومات، راجع تحسين عمليات الربط.
- زيادة المخفضات.
الخطوات التالية
في هذه المقالة، تعرفت على العديد من أساليب تحسين استعلام Hive الشائعة. لمعرفة المزيد، راجع المقالات التالية: