ملاحظة
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تسجيل الدخول أو تغيير الدلائل.
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تغيير الدلائل.
Apache Ambari هي واجهة ويب لإدارة ومراقبة مجموعات HDInsight. للحصول على مقدمة حول Ambari Web UI، راجع إدارة مجموعات HDInsight باستخدام واجهة مستخدم الويب Apache Ambari.
تصف الأقسام التالية خيارات التكوين لتحسين أداء Apache Hive الكلي.
- لتعديل معلمات تكوين Apache Hive، حدد Hive من الشريط الجانبي للخدمات.
- انتقل إلى علامة التبويب Configs .
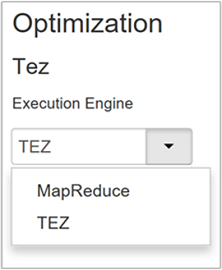
اضبط محرك تنفيذ Hive
يوفر Hive محركي تنفيذ: Apache Hadoop MapReduce وApache TEZ. Tez أسرع من MapReduce. مجموعات HDInsight Linux لها Tez كمحرك تنفيذ افتراضي. لتغيير محرك التنفيذ:
في علامة التبويب Configs في Hive، اكتب execution engine في مربع التصفية.
القيمة الافتراضية لخاصية Optimization هي Tez .
لحن مصممي الخرائط
يحاول Hadoop تقسيم ( تعيين ) ملف واحد إلى ملفات متعددة ومعالجة الملفات الناتجة بالتوازي. يعتمد عدد رسامي الخرائط على عدد الانقسامات. تقود معلمتا التكوين التاليتان عدد الانقسامات لمحرك تنفيذ Tez:
tez.grouping.min-size: الحد الأدنى لحجم الانقسام المجمع بقيمة افتراضية تبلغ 16 ميجابايت (16,777,216 بايت).tez.grouping.max-size: الحد الأعلى لحجم الانقسام المجمع بقيمة افتراضية تبلغ 1 غيغابايت (1,073,741,824 بايت).
كدليل للأداء، قم بخفض هاتين المعلمتين لتحسين وقت الاستجابة وزيادة الإنتاجية.
على سبيل المثال، لتعيين أربع مهام لمخطط الخرائط لحجم بيانات 128 ميغابايت، يمكنك تعيين كلتا المعلمتين على 32 ميغا بايت لكل منهما (33554432 بايت).
لتعديل معلمات الحدود، انتقل إلى علامة التبويب Configs في خدمة Tez. وسع اللوحة General، وحدد موقع المعلمات
tez.grouping.max-sizeوtez.grouping.min-size.قم بتعيين كلتا المعلمتين على 33554432 بايت (32 ميجابايت).

تؤثر هذه التغييرات على كافة وظائف Tez عبر الخادم. للحصول على نتيجة مثالية، اختر قيم المعلمات المناسبة.
ضبط المخفضات
يقدم كل من Apache ORC وSnappy أداءً عالياً. ومع ذلك، قد يكون للـ Hive عدد قليل جداً من مخفضات السرعة بشكل افتراضي، مما يتسبب في حدوث اختناقات.
على سبيل المثال، لنفترض أن لديك حجم بيانات إدخال يبلغ 50 جيجابايت. تلك البيانات بتنسيق ORC مع ضغط Snappy هي 1 غيغابايت. يقدر Apache Hive عدد المخفضات المطلوبة على النحو التالي: (عدد وحدات البايت التي تم إدخالها إلى مصممي الخرائط / hive.exec.reducers.bytes.per.reducer).
مع الإعدادات الافتراضية، هذا المثال هو أربعة مخفضات.
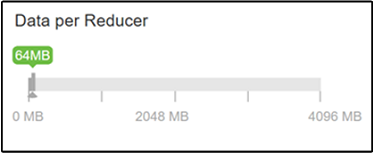
تحدد المعلمة hive.exec.reducers.bytes.per.reducer عدد البايتات التي تمت معالجتها لكل مخفض. القيمة الافتراضية هي 64 ميغا بايت. يؤدي ضبط هذه القيمة لأسفل إلى زيادة التوازي وقد يؤدي إلى تحسين الأداء. قد ينتج عن ضبطه على مستوى منخفض جداً أيضاً الكثير من مخفضات السرعة، مما قد يؤثر سلباً على الأداء. تعتمد هذه المعلمة على متطلبات البيانات الخاصة بك وإعدادات الضغط والعوامل البيئية الأخرى.
لتعديل المعلمة، انتقل إلى علامة التبويب Configs Hive وابحث عن المعلمة Data per Reducer في صفحة الإعدادات.
حدد تحرير لتعديل القيمة إلى 128 ميجا بايت (134.217.728 بايت)، ثم اضغط على Enter للحفظ.
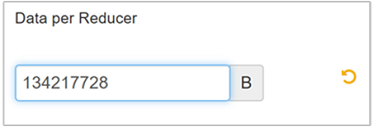
بالنظر إلى حجم الإدخال 1.024 ميجابايت، مع 128 ميجابايت من البيانات لكل مخفض، ثمة ثمانية مخفضات (1024/128).
قد تؤدي القيمة غير الصحيحة لمعلمة البيانات لكل مخفض إلى عدد كبير من أدوات الاختزال، مما يؤثر سلباً على أداء الاستعلام. للحد من الحد الأقصى لعدد المخففات، اضبط
hive.exec.reducers.maxعلى قيمة مناسبة. القيمة الافتراضية هي 1009.
تفعيل التنفيذ المتوازي
يتم تنفيذ استعلام Hive في مرحلة واحدة أو أكثر. إذا كان من الممكن تشغيل المراحل المستقلة بشكل متوازٍ، فسيؤدي ذلك إلى زيادة أداء الاستعلام.
لتمكين تنفيذ الاستعلام الموازي، انتقل إلى علامة التبويب تهيئة Hive وابحث عن الخاصية
hive.exec.parallel. القيمة الافتراضية هي false. غيّر القيمة إلى "صحيح"، ثم اضغط على Enter لحفظ القيمة.للحد من عدد المهام المراد تشغيلها بشكل متوازٍ، قم بتعديل الخاصية
hive.exec.parallel.thread.number. القيمة الافتراضية هي 8.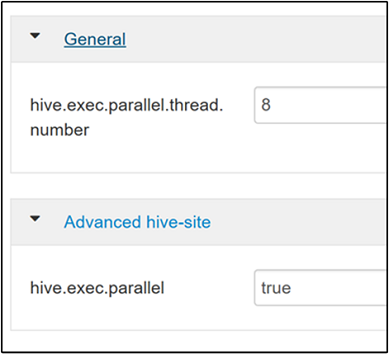
تفعيل التوجيه
تعالج Hive البيانات صفاً تلو الآخر. يوجه Vectorization Hive لمعالجة البيانات في كتل من 1024 صفاً بدلاً من صف واحد في كل مرة. Vectorization قابلة للتطبيق فقط على تنسيق ملف ORC.
لتمكين تنفيذ استعلام متجه، انتقل إلى علامة التبويب Hive Configs وابحث عن المعامل
hive.vectorized.execution.enabled. القيمة الافتراضية هي true لـ Hive 0.13.0 أو ما بعده.لتمكين التنفيذ المتجه للجانب المصغر من الاستعلام، اضبط المعامل
hive.vectorized.execution.reduce.enabledعلى "صواب". القيمة الافتراضية هي false.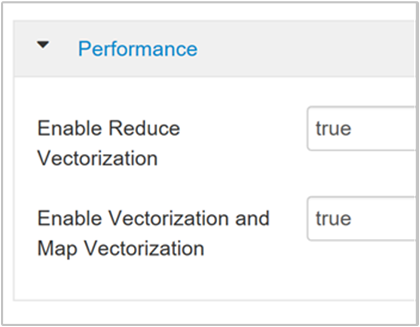
تمكين التحسين القائم على التكلفة (CBO)
بشكل افتراضي، تتبع Hive مجموعة من القواعد للعثور على خطة تنفيذ استعلام أمثل. يعمل التحسين المستند إلى التكلفة (CBO) على تقييم خطط متعددة لتنفيذ استعلام. ويقوم بتعيين تكلفة لكل خطة، ثم يحدد أرخص خطة لتنفيذ استعلام.
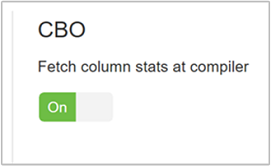
لتمكين CBO، انتقل إلى Hive > Configs > إعدادات وابحث عن Enable Cost Based Optimizer ، ثم بدّل زر التبديل زر تشغيل .

تعمل معلمات التكوين الإضافية التالية على زيادة أداء استعلام Hive عند تمكين CBO:
hive.compute.query.using.statsعند التعيين على "صحيح"، تستخدم Hive الإحصائيات المخزنة في مخزن البيانات الرئيسي الخاص بها للإجابة على استفسارات بسيطة مثل
count(*).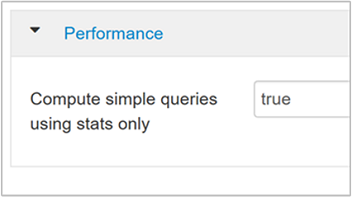
hive.stats.fetch.column.statsيتم إنشاء إحصائيات العمود عندما يتم تمكين CBO. يستخدم Hive إحصائيات العمود، والتي يتم تخزينها في metastore، لتحسين الاستعلامات. يستغرق جلب إحصائيات العمود لكل عمود وقتاً أطول عندما يكون عدد الأعمدة كبيراً. عند التعيين على "خطأ"، فإن هذا الإعداد يعطل جلب إحصائيات العمود من مخزن البيانات الرئيسي.
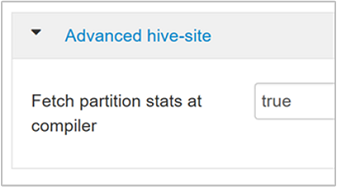
hive.stats.fetch.partition.statsيتم تخزين إحصائيات القسم الأساسية مثل عدد الصفوف وحجم البيانات وحجم الملف في مخزن البيانات الرئيسي. إذا تم التعيين على صحيح، فسيتم جلب إحصائيات القسم من مخزن البيانات الرئيسي. عندما يكون خطأ، يتم جلب حجم الملف من نظام الملفات. ويتم جلب عدد الصفوف من مخطط الصف.
راجع منشور مدونة التحسين المستند إلى التكلفة في Apache Hive في Analytics on Azure Blog لمزيد من القراءة
تفعيل الضغط المتوسط
تُنشئ مهام الخريطة ملفات وسيطة تستخدمها مهام المخفض. يؤدي الضغط المتوسط إلى تقليص حجم الملف المتوسط.
وظائف Hadoop عادة ما تكون مختنق في I / O. يمكن أن يؤدي ضغط البيانات إلى تسريع الإدخال / الإخراج ونقل الشبكة بشكل عام.
أنواع الضغط المتوفرة هي:
| Format | أداة | خوارزمية | امتداد الملف | قابل للتقسيم؟ |
|---|---|---|---|---|
| gzip | gzip | ينكمش | .gz |
لا |
| Bzip2 | Bzip2 | Bzip2 | .bz2 |
نعم |
| LZO | Lzop |
LZO | .lzo |
نعم، إذا تمت فهرستها |
| لاذع | غير متوفر | لاذع | لاذع | لا |
كقاعدة عامة، من المهم وجود طريقة ضغط قابلة للتقسيم، وإلا فسيتم إنشاء عدد قليل من مصممي الخرائط. إذا كانت بيانات الإدخال نصية، فإن bzip2 هو الخيار الأفضل. بالنسبة إلى تنسيق ORC، يعد Snappy هو أسرع خيار ضغط.
لتمكين الضغط المتوسط ، انتقل إلى علامة التبويب Configs Hive، ثم اضبط المعلمة
hive.exec.compress.intermediateعلى true. القيمة الافتراضية هي false.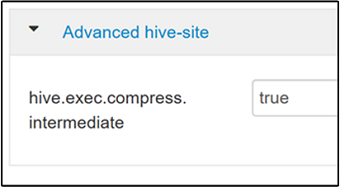
إشعار
لضغط الملفات الوسيطة، اختر برنامج ترميز ضغط بتكلفة أقل لوحدة المعالجة المركزية، حتى إذا لم يكن لبرنامج الترميز ناتج ضغط عالي.
لتعيين برنامج ترميز الضغط المتوسط ، أضف الخاصية المخصصة
mapred.map.output.compression.codecإلى ملفhive-site.xmlأوmapred-site.xml.لإضافة إعداد مخصص:
أ. انتقل إلى Hive > Configs > متقدم > موقع Hive مخصص .
ب. حدد إضافة خاصية ... في الجزء السفلي من جزء موقع Hive المخصص.
جـ. في نافذة إضافة خاصية، أدخل
mapred.map.output.compression.codecكمفتاح وorg.apache.hadoop.io.compress.SnappyCodecكقيمة.د. حدد إضافة.
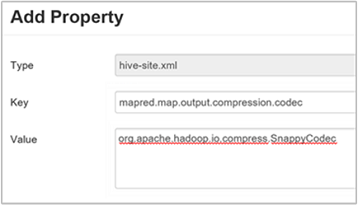
سيقوم هذا الإعداد بضغط الملف الوسيط باستخدام ضغط Snappy. بمجرد إضافة الخاصية، تظهر في جزء موقع Hive المخصص.
إشعار
يقوم هذا الإجراء بتعديل ملف
$HADOOP_HOME/conf/hive-site.xml.
ضغط الناتج النهائي
يمكن أيضاً ضغط إخراج Hive النهائي.
لضغط إخراج Hive النهائي، انتقل إلى علامة التبويب Configs Hive، ثم اضبط المعلمة
hive.exec.compress.outputعلى true. القيمة الافتراضية هي false.لاختيار برنامج ترميز ضغط الإخراج، أضف الخاصية المخصصة
mapred.output.compression.codecإلى جزء موقع Hive المخصص، كما هو موضح في الخطوة 3 من القسم السابق.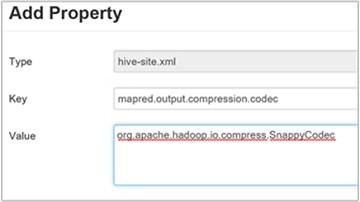
تفعيل تنفيذ المضاربة
يطلق التنفيذ التخميني عدداً معيناً من المهام المكررة لاكتشاف ورفض قائمة متتبع المهام الذي يعمل ببطء. مع تحسين التنفيذ العام للوظيفة من خلال تحسين نتائج المهام الفردية.
لا ينبغي تشغيل التنفيذ التخميني لمهام MapReduce طويلة الأمد مع كميات كبيرة من المدخلات.
لتمكين تنفيذ المضاربة، انتقل إلى علامة التبويب Configs Hive، ثم اضبط المعلمة
hive.mapred.reduce.tasks.speculative.executionعلى true. القيمة الافتراضية هي false.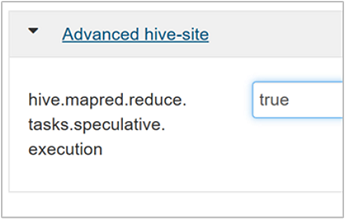
ضبط الأقسام الديناميكية
يسمح Hive بإنشاء أقسام ديناميكية عند إدراج السجلات في جدول، دون تحديد كل قسم مسبقاً. هذه القدرة هي ميزة قوية. على الرغم من أنه قد يؤدي إلى إنشاء عدد كبير من الأقسام. وعدد كبير من الملفات لكل قسم.
لكي تقوم Apache Hive بعمل أقسام ديناميكية، يجب أن تكون قيمة المعلمة
hive.exec.dynamic.partitionصحيحة (القيمة الافتراضية).غيّر وضع القسم الديناميكي إلى صارم . في الوضع المتشدد، يجب أن يكون قسم واحد على الأقل ثابتاً. يمنع هذا الإعداد الاستعلامات التي لا تحتوي على عامل تصفية القسم في جملة WHERE، أي أن صارم يمنع الاستعلامات التي تفحص جميع الأقسام. انتقل إلى علامة التبويب Configs Hive، ثم قم بتعيين
hive.exec.dynamic.partition.modeعلى صارم . القيمة الافتراضية هي غير مقيدة .للحد من عدد الأقسام الديناميكية التي سيتم إنشاؤها، قم بتعديل المعامل
hive.exec.max.dynamic.partitions. القيمة الافتراضية هي 5000.للحد من العدد الإجمالي للأقسام الديناميكية لكل عقدة، قم بتعديل
hive.exec.max.dynamic.partitions.pernode. القيمة الافتراضية هي 2000.
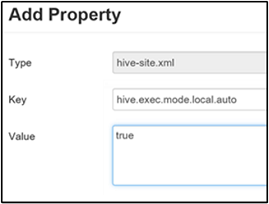
تمكين الوضع المحلي
يمكّن الوضع المحلي Hive من القيام بجميع مهام الوظيفة على جهاز واحد. أو أحياناً في عملية واحدة. يعمل هذا الإعداد على تحسين أداء الاستعلام إذا كانت بيانات الإدخال صغيرة. وتستهلك النفقات العامة لبدء المهام للاستعلامات نسبة كبيرة من تنفيذ الاستعلام الكلي.
لتمكين الوضع المحلي، أضف المعلمة hive.exec.mode.local.auto إلى لوحة موقع Hive المخصص، كما هو موضح في الخطوة 3 من قسم تمكين الضغط المتوسط .
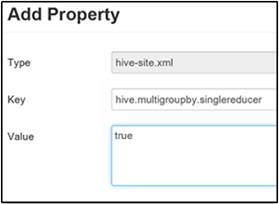
تعيين واحد MapReduce MultiGROUP BY
عند تعيين هذه الخاصية على حقيقي، يقوم استعلام MultiGROUP BY الذي يحتوي على مفاتيح تجميع عامة مشتركة بإنشاء مهمة MapReduce واحدة.
لتمكين هذا السلوك، أضف المعلمة hive.multigroupby.singlereducer إلى جزء موقع Hive المخصص، كما هو موضح في الخطوة 3 من قسم تمكين الضغط المتوسط .
تحسينات Hive إضافية
تصف الأقسام التالية تحسينات إضافية متعلقة بـ Hive يمكنك تعيينها.
الانضمام إلى التحسينات
نوع الصلة الافتراضي في Hive هو ربط عشوائي . في Apache Hive، يقرأ رسامو الخرائط المدخلات ويبعثون زوج مفتاح/قيمة وصل إلى ملف وسيط. يقوم Hadoop بفرز ودمج هذه الأزواج في مرحلة خلط ورق اللعب. هذه المرحلة المراوغة مكلفة. يمكن أن يؤدي تحديد الصلة الصحيحة بناءً على بياناتك إلى تحسين الأداء بشكل ملحوظ.
| نوع الصلة | عندما | كيف | إعدادات Hive | التعليقات |
|---|---|---|---|---|
| ربط عشوائي |
|
|
لا حاجة لإعداد Hive كبيرة | يعمل في كل مرة |
| ربط الخريطة |
|
|
hive.auto.convert.join=true |
سريع ولكن محدود |
| فرز دلو الدمج | إذا كان كلا الجدولين:
|
كل عملية:
|
hive.auto.convert.sortmerge.join=true |
فعالة |
تحسينات محرك التنفيذ
توصيات إضافية لتحسين محرك تنفيذ Hive:
| الإعدادات | مستحسن | HDInsight الافتراضي |
|---|---|---|
hive.mapjoin.hybridgrace.hashtable |
صحيح = أكثر أماناً، أبطأ ؛ خطأ = أسرع | true |
tez.am.resource.memory.mb |
4 جيجا بايت الحد الأعلى لمعظم | السيارات ضبطها |
tez.session.am.dag.submit.timeout.secs |
300 | 300 |
tez.am.container.idle.release-timeout-min.millis |
20000 | 10000 |
tez.am.container.idle.release-timeout-max.millis |
40000 | 20000 |