إشعار
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تسجيل الدخول أو تغيير الدلائل.
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تغيير الدلائل.
ستتعلم في هذا البرنامج التعليمي، كيفية إنشاء تطبيق Apache Spark مكتوباً بلغة Scala باستخدام Apache Maven مع IntelliJ IDEA. يستخدم المقال أداة Apache Maven كنظام بناء. ويبدأ بالنموذج الأصلي Maven القائم لـ Scala المقدمة من IntelliJ IDEA. يشتمل إنشاء تطبيق Scala في IntelliJ IDEA على الخطوات التالية:
- استخدم أداة Maven كنظام البناء.
- حدث ملف نموذج عنصر المشروع (POM) لحل تبعيات الوحدة النمطية Spark.
- اكتب تطبيقك بلغة Scala.
- أنشئ ملف jar الذي يمكن إرساله إلى مجموعات HDInsight Spark.
- شغل التطبيق على مجموعة Spark باستخدام Livy.
في هذا البرنامج التعليمي، تتعلم كيفية:
- ثبت المكون الإضافي Scala لـ IntelliJ IDEA
- استخدام IntelliJ لتطوير تطبيق Scala Maven
- إنشاء مشروع Scala مستقل
المتطلبات الأساسية
مجموعة Apache Spark على HDInsight. للحصول على إرشادات، يرجى مراجعة إنشاء مجموعات Apache Spark في Azure HDInsight.
عدة تطوير Oracle Java. يستخدم هذا البرنامج التعليمي الإصدار8.0.202 من Java.
A Java IDE. تستخدم هذه المقالة IntelliJ IDEA Community 2018.3.4.
Azure Toolkit لـ IntelliJ. يرجى الاطلاع على تثبيت Azure Toolkit لـ IntelliJ.
ثبت المكون الإضافي Scala لـ IntelliJ IDEA
اتبع الخطوات التالية لتثبيت المكون الإضافي Scala:
افتح IntelliJ IDEA.
على شاشة الترحيب، انتقل إلى تكوين>المكونات الإضافية لفتح نافذة المكونات الإضافية.
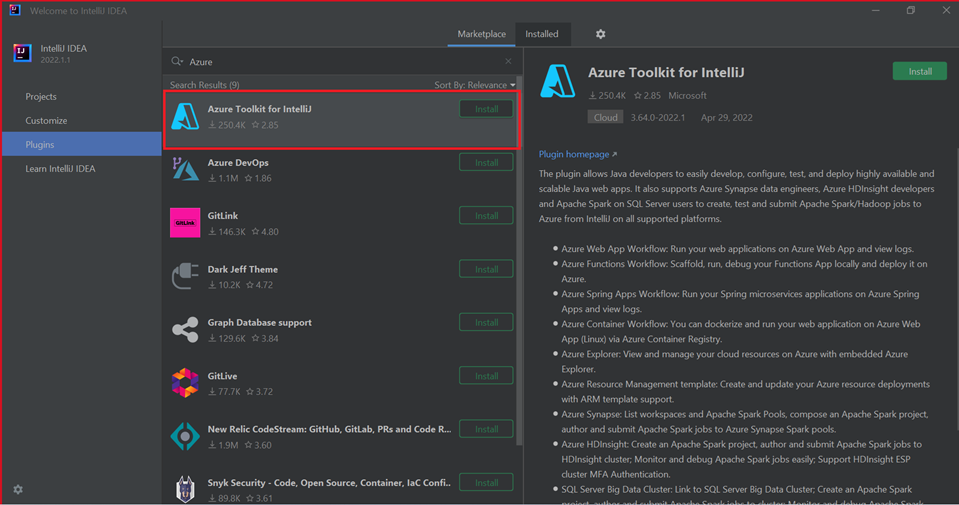
حدد Install لمجموعة أدوات Azure لـ IntelliJ.
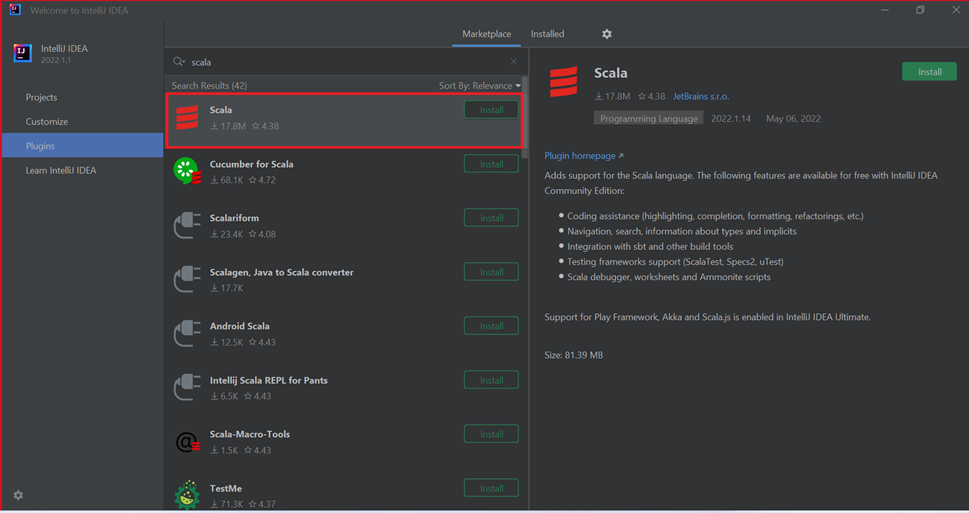
حدد تثبيت المكون الإضافي Scala الذي يظهر في النافذة الجديدة.
عقب تثبيت المكون الإضافي بنجاح، يجب إعادة تشغيل IDE.
استخدم IntelliJ لإنشاء تطبيق
ابدأ تشغيل IntelliJ IDEA، وحدد "Create New Project" لفتح نافذة "New Project".
حدد Apache Spark/HDInsight من الجزء الأيمن.
حدد مشروع Spark (Scala) من النافذة الرئيسية.
من القائمة المنسدلة إنشاء أداة حدد إحدى القيم التالية:
- Maven لدعم معالج إنشاء مشروع Scala.
- SBT لإدارة التبعيات والبناء لمشروع project.
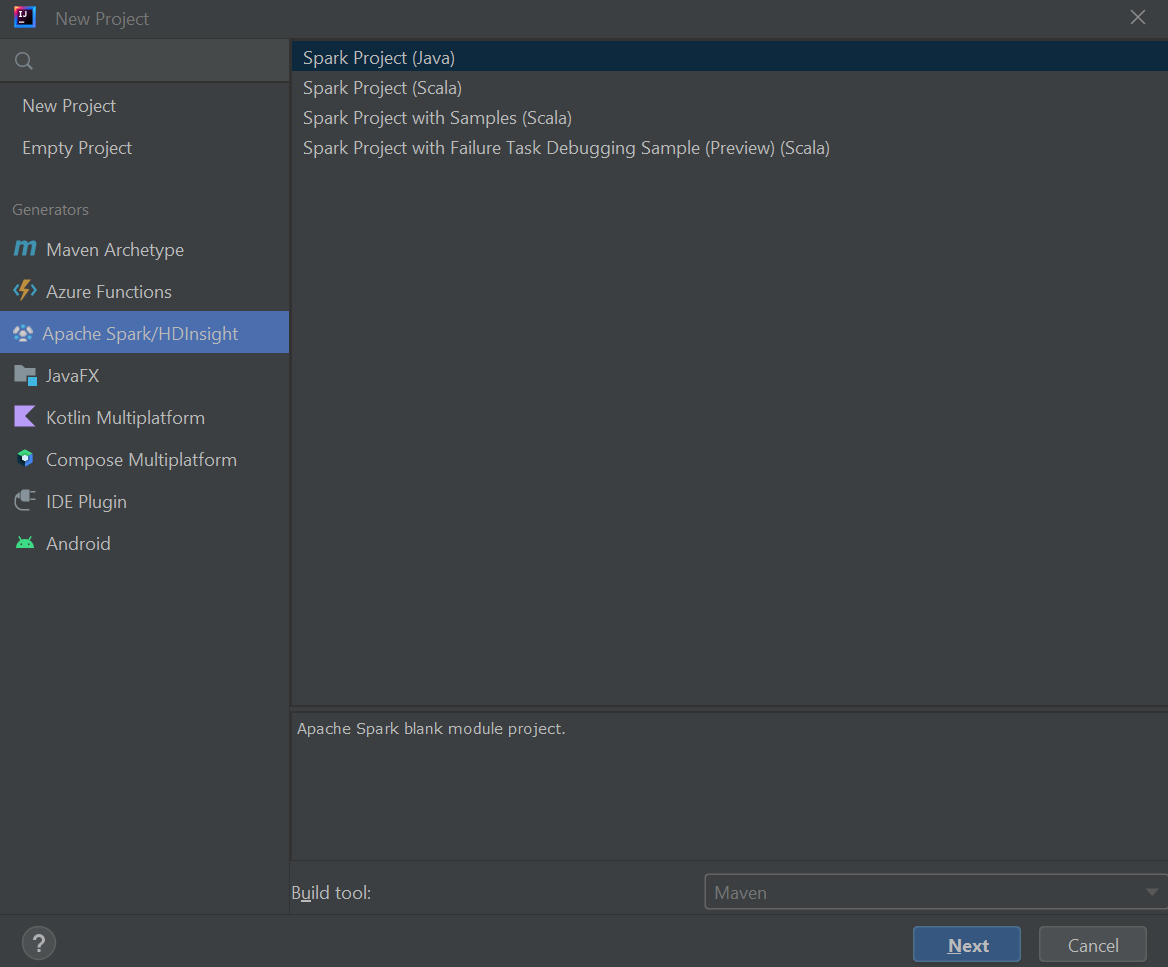
حدد التالي.
في إطار المشروع الجديد وفر المعلومات التالية:
الخاصية الوصف اسم المشروع أدخل اسمًا. موقع المشروع أدخل الموقع لحفظ المشروع. مشروع SDK سيكون هذا الحقل فارغاً في أول استخدام لـ IDEA. حدد جديد... وانتقل إلى JDK. إصدار Spark يدمج معالج الإنشاء الإصدار المناسب لـSpark SDK و Scala SDK. إذا كان إصدار مجموعة Spark أقدم من 2.0، فحدد Spark 1.x. أو حدد Spark2.x. يستخدم هذا المثال Spark 2.3.0 (Scala 2.11.8). 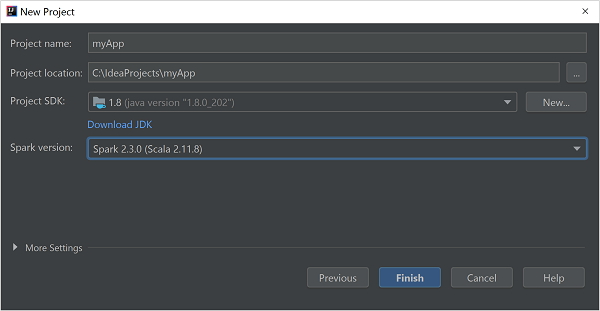
حدد إنهاء.
إنشاء مشروع Scala مستقل
ابدأ تشغيل IntelliJ IDEA، وحدد "Create New Project" لفتح نافذة "New Project".
حدد Maven من الجزء الأيمن.
حدد مشروع SDK. إذا كان فارغاً، فحدد جديد... وانتقل إلى دليل تثبيت Java.
حدد خانة الاختيار إنشاء من النموذج الأصلي.
حدد
org.scala-tools.archetypes:scala-archetype-simpleمن قائمة النماذج الأصلية. ينشئ هذا النموذج الأصلي بنية الدليل الصحيحة و يقوم بتحميل التبعيات الافتراضية المطلوبة لكتابة برنامج Scala.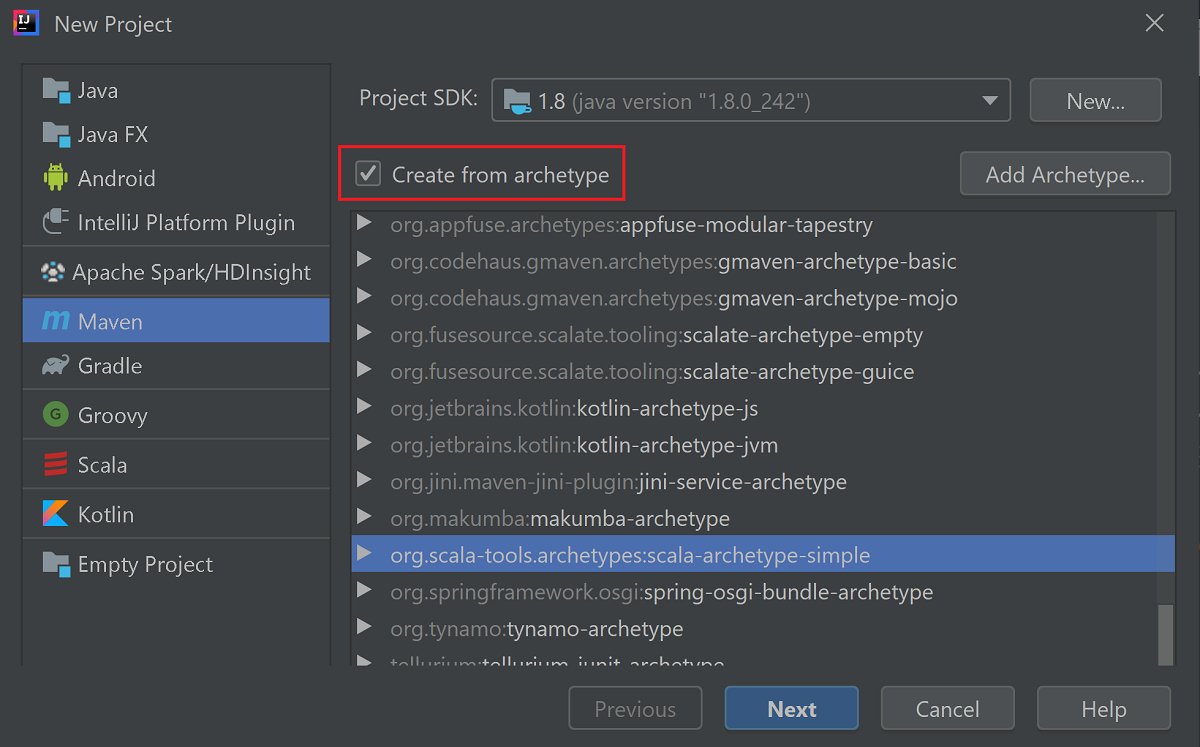
حدد التالي.
توسيع Artifact Coordinate. توفير القيم ذات الصلة لـ GroupId، و ArtifactId. سيتم الملء التلقائي لـ الاسم، والموقع. يتم استخدام القيم التالية في هذا البرنامج التعليمي:
- GroupId: com.microsoft.spark.example
- ArtifactId: SparkSimpleApp
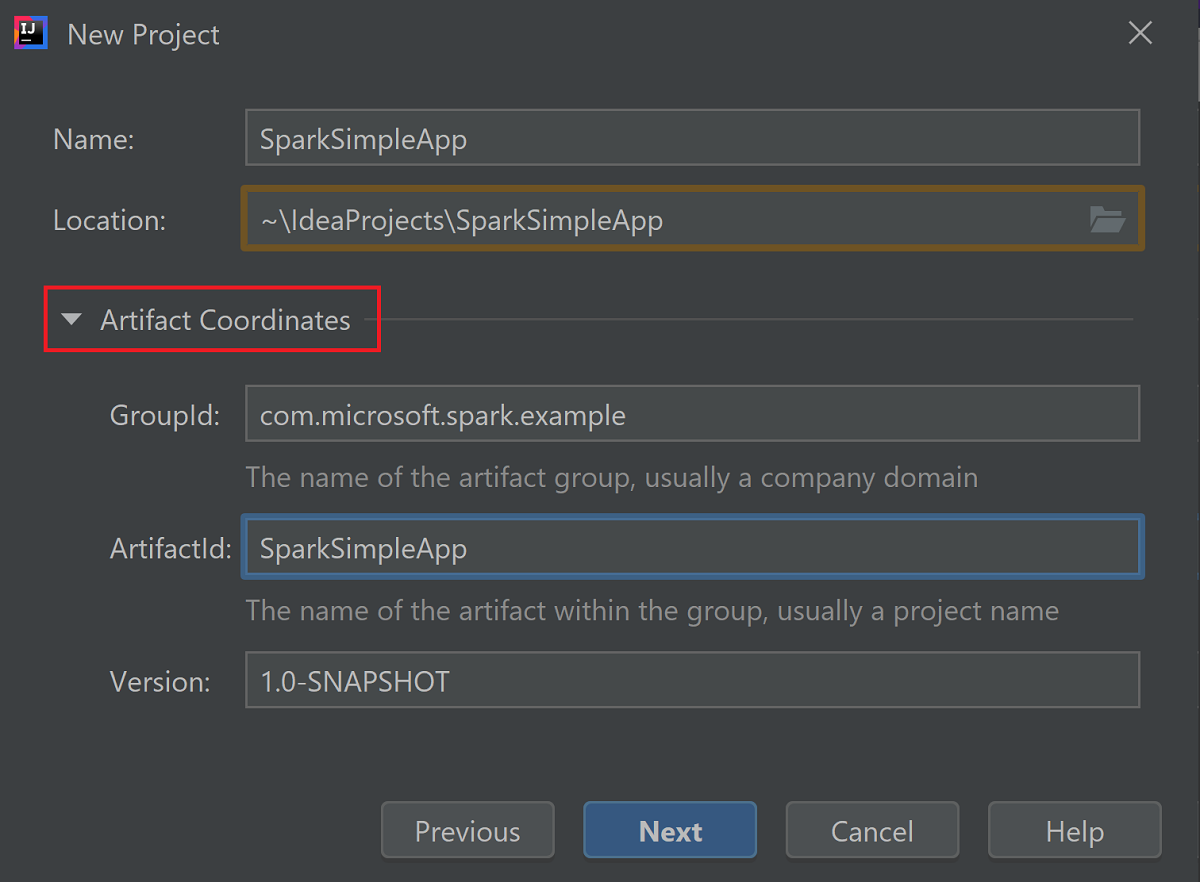
حدد التالي.
تحقق من الإعدادات ثم حدد التالي.
تحقق من اسم المشروع وموقعه، ثم حدد إنهاء. سيستغرق المشروع بضع دقائق لإتمام عملية الاستيراد.
بمجرد استيراد المشروع، من الجزء الأيمن انتقل إلى SparkSimpleApp>src>اختبار>scala>com>مثال>microsoft>spark. انقر بزر الماوس الأيمن فوق MySpec، ثم حدد حذف.... لست بحاجة إلى هذا الملف للتطبيق. في مربع الحوار، حدد موافق.
في الخطوات اللاحقة، يمكنك تحديث pom.xml لتعريف التبعيات لتطبيق Spark Scala. لتحميل هذه التبعيات وحلها تلقائياً، يجب تكوين Maven.
من القائمة ملف، حدد الإعدادات لفتح نافذة الإعدادات.
من نافذة الإعدادات، انتقل إلى إنشاء وتنفيذ ونشراستيراد >Build>Tools>Maven.
حدد خانة الاختيار استيراد مشاريع Maven تلقائياً.
حدد Apply، ثم حدد OK. ثم سيتم إرجاعك إلى نافذة المشروع.
:::image type="content" source="./media/apache-spark-create-standalone-application/configure-maven-download.png" alt-text="Configure Maven for automatic downloads." border="true":::من الجزء الأيمن، انتقل إلى src>الرئيسي>scala>com.microsoft.spark.example،ثم انقر نقراً مزدوجاً فوق التطبيق لفتح App.scala.
استبدل نموذج التعليمات البرمجية الموجودة مع التعليمات البرمجية التالية واحفظ التغييرات. تُقرأ هذه التعليمات البرمجية من HVAC.csv (متوفرة على كافة مجموعات HDInsight Spark). تسترد الصفوف التي تحتوي على رقم واحد فقط في العمود السادس. وتكتب الإخراج إلى /HVACOut تحت حاوية التخزين الافتراضية للمجموعة.
package com.microsoft.spark.example import org.apache.spark.SparkConf import org.apache.spark.SparkContext /** * Test IO to wasb */ object WasbIOTest { def main (arg: Array[String]): Unit = { val conf = new SparkConf().setAppName("WASBIOTest") val sc = new SparkContext(conf) val rdd = sc.textFile("wasb:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv") //find the rows which have only one digit in the 7th column in the CSV val rdd1 = rdd.filter(s => s.split(",")(6).length() == 1) rdd1.saveAsTextFile("wasb:///HVACout") } }في الجزء الأيمن، انقر نقراً مزدوجاً فوق pom.xml.
داخل
<project>\<properties>أضف المقاطع التالية:<scala.version>2.11.8</scala.version> <scala.compat.version>2.11.8</scala.compat.version> <scala.binary.version>2.11</scala.binary.version>داخل
<project>\<dependencies>أضف المقاطع التالية:<dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_${scala.binary.version}</artifactId> <version>2.3.0</version> </dependency>Save changes to pom.xml.أنشئ ملف.jar. تمكن IntelliJ IDEA من إنشاء JAR كبيانات اصطناعية للمشروع. نفذ الخطوات التالية.
من القائمة ملف، حدد بنية المشروع....
من نافذة بنية المشروع، انتقل إلى Artifacts>رمز زائد +>JARمن وحدات >مع تبعيات....
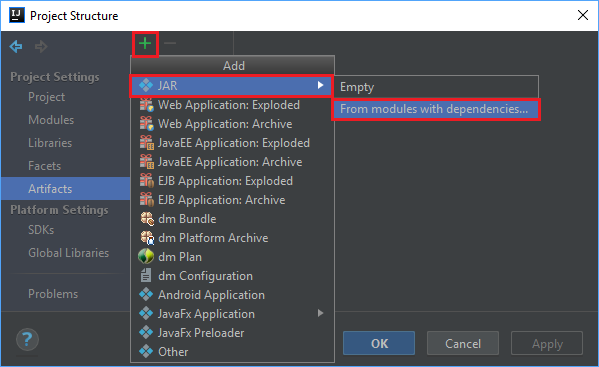
في نافذة إنشاء JAR من الوحدات النمطية حدد رمز المجلد في مربع النص فئة رئيسية.
في نافذة تحديد الفئة الرئيسية، حدد الفئة التي تظهر افتراضياً ثم حدد موافق.
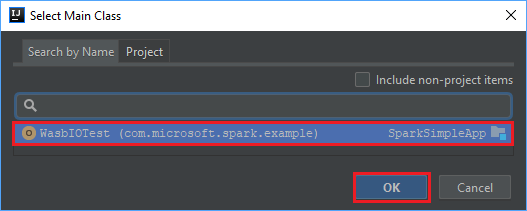
في نافذة إنشاء JAR من الوحدات النمطية، تأكد من تحديد خيارفك الضغط إلى الهدف JAR، ثم حدد موافق. ينشئ هذا الإعداد JAR واحداً مع جميع التبعيات.
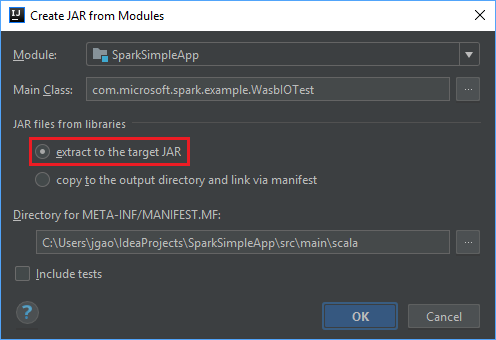
تدرج علامة التبويب تخطيط الإخراج جميع ملفات jar المدرجة كجزء من مشروع Maven. يمكنك تحديد وحذف الملفات التي لا توجد لها تبعية مباشرة لدى تطبيق Scala. بالنسبة إلى التطبيق، الذي تقوم بإنشائه هنا، يمكنك إزالة الجميع باستثناء الأخير ( تجميع إخراج SparkSimpleApp ). حدد الملفات بامتداد jar لحذفها ثم حدد الرمز السالب -.
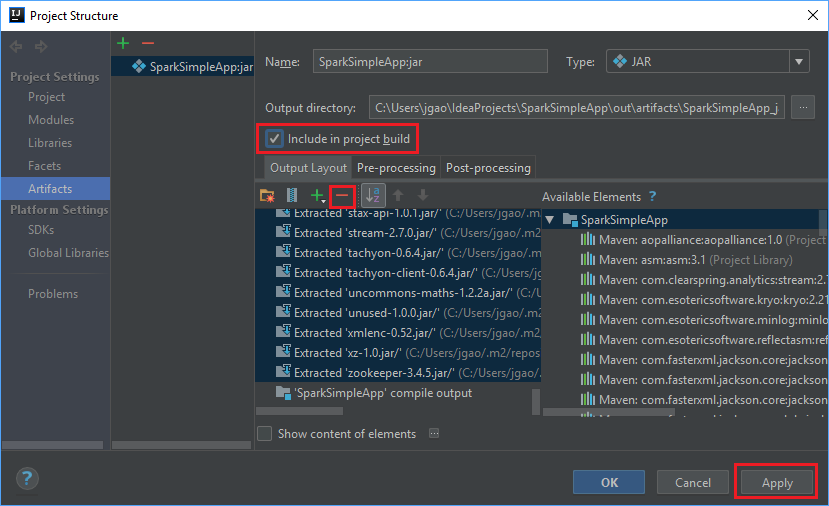
تأكد من تحديد خانة الاختيار إدراج في مشروع البناء. يضمن هذا الخيار إنشاء ملف jar في كل مرة يتم فيها بناء المشروع أو تحديثه. حدد تطبيق ثم موافق.
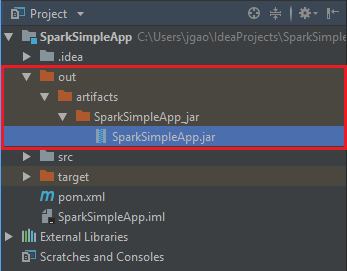
لإنشاء ملف jar، انتقل إلى إنشاء >Build Artifacts>إنشاء. سيستغرق تجميع المشروع حوالي 30 ثانية. يتم إنشاء ملف الإخراج بامتداد jar ضمن \out\artifacts.
تشغيل التطبيق على مجموعة Apache Spark
لتشغيل التطبيق على المجموعة، يمكنك استخدام الطرق التالية:
نسخ ملف jar للتطبيق إلى Azure Storage blob المقترن بالمجموعة. يمكنك استخدام الأداة المساعدة AzCopy، وهي أداة سطر الأوامر، للقيام بذلك. هناك العديد من العملاء الآخرين أيضاً الذين يمكنك استخدامهم لتحميل البيانات. يمكنك العثور على المزيد عنهم في بيانات تحميل وظائف Apache Hadoop في HDInsight.
استخدم Apache Livy لإرسال مهمة طلب عن بعد إلى مجموعة Spark. تتضمن مجموعات Spark على HDInsight Livy التي تعرض نقاط نهاية REST لإرسال وظائف Spark عن بعد. لمزيد من المعلومات، يرجى الاطلاع على إرسال وظائف Apache Spark عن بعد باستخدام Apache Livy مع مجموعات Spark على HDInsight.
تنظيف الموارد
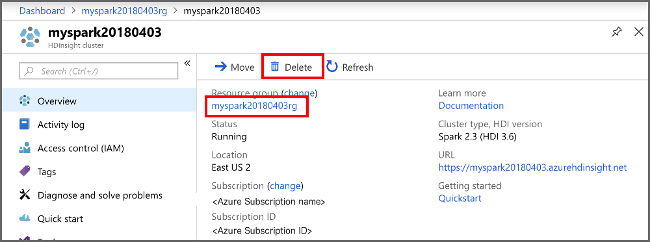
إذا كنت لن تستمر في استخدام هذا التطبيق، فاحذف المجموعة التي قمت بإنشائها عن طريق اتباع الخطوات التالية:
قم بتسجيل الدخول إلى بوابة Azure.
في المربع بحث في الأعلى، اكتب HDInsight.
حدد مجموعات HDInsight ضمن الخدمات.
في قائمة مجموعات HDInsight التي تظهر، حدد ... بجانب المجموعة التي قمت بإنشائها لهذا البرنامج التعليمي.
حدد حذف. حدد نعم.
الخطوة التالية
تعلمت في هذه المقالة كيفية إنشاء تطبيق Apache Spark scala. انتقل إلى المقالة التالية لمعرفة كيفية تشغيل هذا التطبيق على مجموعة HDInsight Spark باستخدام Livy.