إشعار
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تسجيل الدخول أو تغيير الدلائل.
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تغيير الدلائل.
في هذا التشغيل السريع، يمكنك استخدام قالب Azure Resource Manager (قالب ARM) لإنشاء كتلة Apache Spark في Azure HDInsight. ثم إنشاء ملف دفتر ملاحظات Jupyter واستخدامها لتشغيل الاستعلامات Spark SQL مقابل جداول Apache Hive. Azure HDInsight هي خدمة تحليلات مدارة كاملة الطيف ومفتوحة المصدر للمؤسسات. يتيح إطار عمل Apache Spark لـ HDInsight تحليلات البيانات السريعة والحوسبة العنقودية باستخدام المعالجة داخل الذاكرة. دفتر ملاحظات Jupyter يسمح لك بالتفاعل مع بياناتك، ودمج الرمز مع نص من مرجع markdown، والقيام بتصور بسيط.
إذا كنت تستخدم نظام مجموعات متعددة معاً، فستحتاج إلى إنشاء شبكة ظاهرية، وإذا كنت تستخدم نظام مجموعة Spark، فستحتاج أيضاً إلى استخدام موصل Apache Hive Warehouse Connector. لمزيد من المعلومات، راجع تخطيط شبكة ظاهرية لـ Azure HDInsightوتكامل Apache Spark وApache Hive مع Apache Hive Warehouse Connector.
قالب Azure Resource Manager هو ملف JavaScript Object Notation (JSON) الذي يحدد البنية الأساسية والتكوين لمشروعك. يستخدم القالب عبارات توضيحية. يمكنك وصف النشر المقصود دون كتابة تسلسل أوامر البرمجة لإنشاء النشر.
إذا كانت بيئتك تلبي المتطلبات الأساسية وكنت معتاداً على استخدام قوالب "ARM"، فحدد زر "Deploy to Azure". سيتم فتح القالب في مدخل Azure.

المتطلبات الأساسية
في حال لم يكن لديك اشتراك Azure، فأنشئ حساباً مجانيّاً قبل البدء.
مراجعة القالب
يُعدّ النموذج المستخدم في هذا التشغيل السريع مأخوذاً من قوالب التشغيل السريع من Azure.
{
"$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#",
"contentVersion": "1.0.0.0",
"metadata": {
"_generator": {
"name": "bicep",
"version": "0.5.6.12127",
"templateHash": "4742950082151195489"
}
},
"parameters": {
"clusterName": {
"type": "string",
"metadata": {
"description": "The name of the HDInsight cluster to create."
}
},
"clusterLoginUserName": {
"type": "string",
"maxLength": 20,
"minLength": 2,
"metadata": {
"description": "These credentials can be used to submit jobs to the cluster and to log into cluster dashboards. The username must consist of digits, upper or lowercase letters, and/or the following special characters: (!#$%&'()-^_`{}~)."
}
},
"clusterLoginPassword": {
"type": "secureString",
"minLength": 10,
"metadata": {
"description": "The password must be at least 10 characters in length and must contain at least one digit, one upper case letter, one lower case letter, and one non-alphanumeric character except (single-quote, double-quote, backslash, right-bracket, full-stop). Also, the password must not contain 3 consecutive characters from the cluster username or SSH username."
}
},
"sshUserName": {
"type": "string",
"minLength": 2,
"metadata": {
"description": "These credentials can be used to remotely access the cluster. The sshUserName can only consit of digits, upper or lowercase letters, and/or the following special characters (%&'^_`{}~). Also, it cannot be the same as the cluster login username or a reserved word"
}
},
"sshPassword": {
"type": "secureString",
"maxLength": 72,
"minLength": 6,
"metadata": {
"description": "SSH password must be 6-72 characters long and must contain at least one digit, one upper case letter, and one lower case letter. It must not contain any 3 consecutive characters from the cluster login name"
}
},
"location": {
"type": "string",
"defaultValue": "[resourceGroup().location]",
"metadata": {
"description": "Location for all resources."
}
},
"headNodeVirtualMachineSize": {
"type": "string",
"defaultValue": "Standard_E8_v3",
"allowedValues": [
"Standard_A4_v2",
"Standard_A8_v2",
"Standard_E2_v3",
"Standard_E4_v3",
"Standard_E8_v3",
"Standard_E16_v3",
"Standard_E20_v3",
"Standard_E32_v3",
"Standard_E48_v3"
],
"metadata": {
"description": "This is the headnode Azure Virtual Machine size, and will affect the cost. If you don't know, just leave the default value."
}
},
"workerNodeVirtualMachineSize": {
"type": "string",
"defaultValue": "Standard_E8_v3",
"allowedValues": [
"Standard_A4_v2",
"Standard_A8_v2",
"Standard_E2_v3",
"Standard_E4_v3",
"Standard_E8_v3",
"Standard_E16_v3",
"Standard_E20_v3",
"Standard_E32_v3",
"Standard_E48_v3"
],
"metadata": {
"description": "This is the workernode Azure Virtual Machine size, and will affect the cost. If you don't know, just leave the default value."
}
}
},
"resources": [
{
"type": "Microsoft.Storage/storageAccounts",
"apiVersion": "2021-08-01",
"name": "[format('storage{0}', uniqueString(resourceGroup().id))]",
"location": "[parameters('location')]",
"sku": {
"name": "Standard_LRS"
},
"kind": "StorageV2"
},
{
"type": "Microsoft.HDInsight/clusters",
"apiVersion": "2021-06-01",
"name": "[parameters('clusterName')]",
"location": "[parameters('location')]",
"properties": {
"clusterVersion": "4.0",
"osType": "Linux",
"tier": "Standard",
"clusterDefinition": {
"kind": "spark",
"configurations": {
"gateway": {
"restAuthCredential.isEnabled": true,
"restAuthCredential.username": "[parameters('clusterLoginUserName')]",
"restAuthCredential.password": "[parameters('clusterLoginPassword')]"
}
}
},
"storageProfile": {
"storageaccounts": [
{
"name": "[replace(replace(reference(resourceId('Microsoft.Storage/storageAccounts', format('storage{0}', uniqueString(resourceGroup().id)))).primaryEndpoints.blob, 'https://', ''), '/', '')]",
"isDefault": true,
"container": "[parameters('clusterName')]",
"key": "[listKeys(resourceId('Microsoft.Storage/storageAccounts', format('storage{0}', uniqueString(resourceGroup().id))), '2021-08-01').keys[0].value]"
}
]
},
"computeProfile": {
"roles": [
{
"name": "headnode",
"targetInstanceCount": 2,
"hardwareProfile": {
"vmSize": "[parameters('headNodeVirtualMachineSize')]"
},
"osProfile": {
"linuxOperatingSystemProfile": {
"username": "[parameters('sshUserName')]",
"password": "[parameters('sshPassword')]"
}
}
},
{
"name": "workernode",
"targetInstanceCount": 2,
"hardwareProfile": {
"vmSize": "[parameters('workerNodeVirtualMachineSize')]"
},
"osProfile": {
"linuxOperatingSystemProfile": {
"username": "[parameters('sshUserName')]",
"password": "[parameters('sshPassword')]"
}
}
}
]
}
},
"dependsOn": [
"[resourceId('Microsoft.Storage/storageAccounts', format('storage{0}', uniqueString(resourceGroup().id)))]"
]
}
],
"outputs": {
"storage": {
"type": "object",
"value": "[reference(resourceId('Microsoft.Storage/storageAccounts', format('storage{0}', uniqueString(resourceGroup().id))))]"
},
"cluster": {
"type": "object",
"value": "[reference(resourceId('Microsoft.HDInsight/clusters', parameters('clusterName')))]"
}
}
}
يتم تعريف موردين لـ Azure في القالب:
- Microsoft.Storage/storageAccounts: أنشئ حساب تخزين في Azure.
- Microsoft.HDInsight/cluster: إنشاء نظام مجموعة HDInsight.
نشر القالب
حدد زر النشر إلى Azure أدناه لتسجيل الدخول إلى Azure وافتح قالب ARM.
أدخل أو حدد القيم التالية:
الخاصية الوصف الاشتراك من القائمة المنسدلة، قم بتحديد اشتراك Azure المستخدم في نظام المجموعة. مجموعة الموارد من القائمة المنسدلة، حدد مجموعة الموارد الموجودة، أو تحديد إنشاء جديد. الموقع سيتم ملء القيمة تلقائيًا بالموقع المستخدم لمجموعة الموارد. اسم المجموعة أدخل اسمًا فريدًا عالميًا. بالنسبة إلى هذا القالب، استخدم الأحرف الصغيرة والأرقام فقط. اسم مستخدم تسجيل الدخول إلى نظام المجموعة أدخل اسم المستخدم، الافتراضي هو admin.كلمة مرور تسجيل الدخول إلى نظام المجموعة أدخل كلمة مرور. يجب أن يكون طول كلمة المرور 10 أحرف على الأقل ويجب أن تحتوي على رقم واحد على الأقل، وأحرف كبيرة واحدة، وحرف صغير واحد، وحرف واحد غير أبجدي رقمي (باستثناء الأحرف ' ` ").اسم مستخدم Ssh أدخل اسم المستخدم، الافتراضي هو sshuser.كلمة مرور Ssh أدخل كلمة المرور. 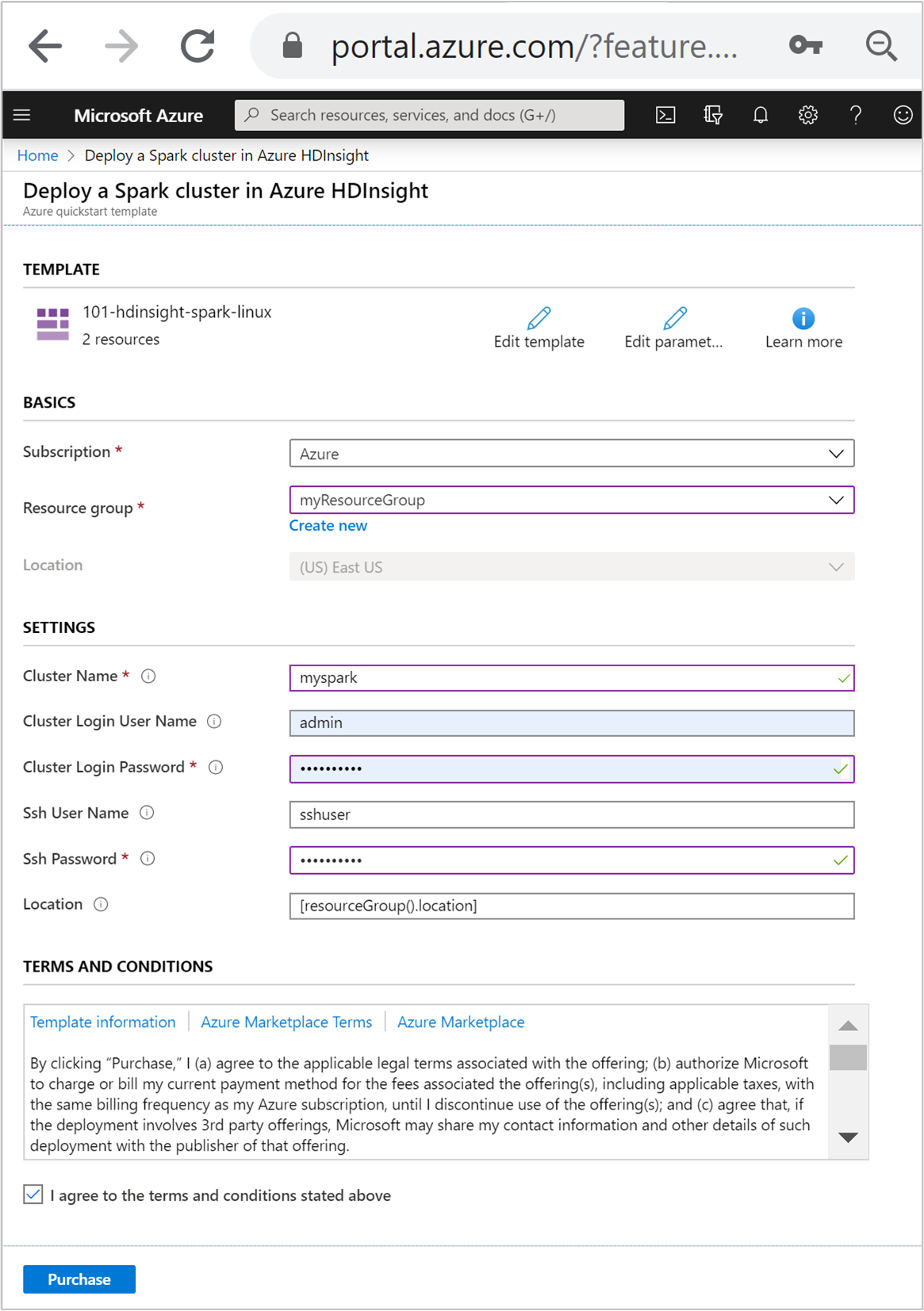
قم بمراجعة الشروط والأحكام. ثم حدد أوافق على الشروط والأحكام المذكورة أعلاه، وحدد شراء. ستتلقى إشعارًا بأن عملية النشر قيد التقدم. يستغرق إنشاء نظام المجموعة نحو 20 دقيقة.
إذا واجهت مشكلة في إنشاء نظام مجموعات HDInsight، فقد يكون السبب أنك لا تملك الأذونات والصلاحيات المناسبة للقيام بذلك. لمزيد من المعلومات، راجع متطلبات التحكم في الوصول.
مراجعة الموارد الموزعة
بمجرد إنشاء نظام المجموعة، ستتلقى إشعارًا تم التوزيع بنجاح مع رابط الانتقال إلى المورد. ستسرد صفحة مجموعة الموارد مجموعة HDInsight الجديدة والتخزين الافتراضي المقترن بالمجموعة. تحتوي كل مجموعة على Azure Storage أو Azure Data Lake Storage Gen2 تبعية. يشار إليه باسم حساب التخزين الافتراضي. ويجب أن تكون مجموعة HDInsight وحساب التخزين الافتراضي الخاص بها ملونة في نفس منطقة Azure. حذف الكتل لا يؤدي إلى حذف تبعية حساب التخزين. يشار إليه باسم حساب التخزين الافتراضي. يجب أن يتم وضع مجموعة HDInsight وحساب التخزين الافتراضي المخصص لها في نفس منطقة Azure. حذف الكتل لا يؤدي إلى حذف حساب التخزين.
إنشاء ملف دفتر ملاحظات Jupyter
Jupyter Notebook هي بيئة تفاعلية لدفتر الملاحظات تدعم لغات البرمجة المختلفة. يمكنك استخدام ملف Jupyter Notebook للتفاعل مع بياناتك، ودمج التعليمات البرمجية مع نص markdown، وتنفيذ مرئيات بسيطة.
افتح مدخل Azure.
حدد كتل HDInsight، ثم حدد الكتلة التي قمت بإنشائها.
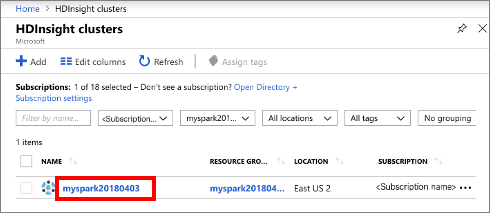
من المدخل، في قسم لوحات معلومات الكتلة، حدد Jupyter Notebook. في حالة المطالبة بإدخال بيانات تسجيل الدخول في شبكة نظام المجموعة لشبكة نظام المجموعة.
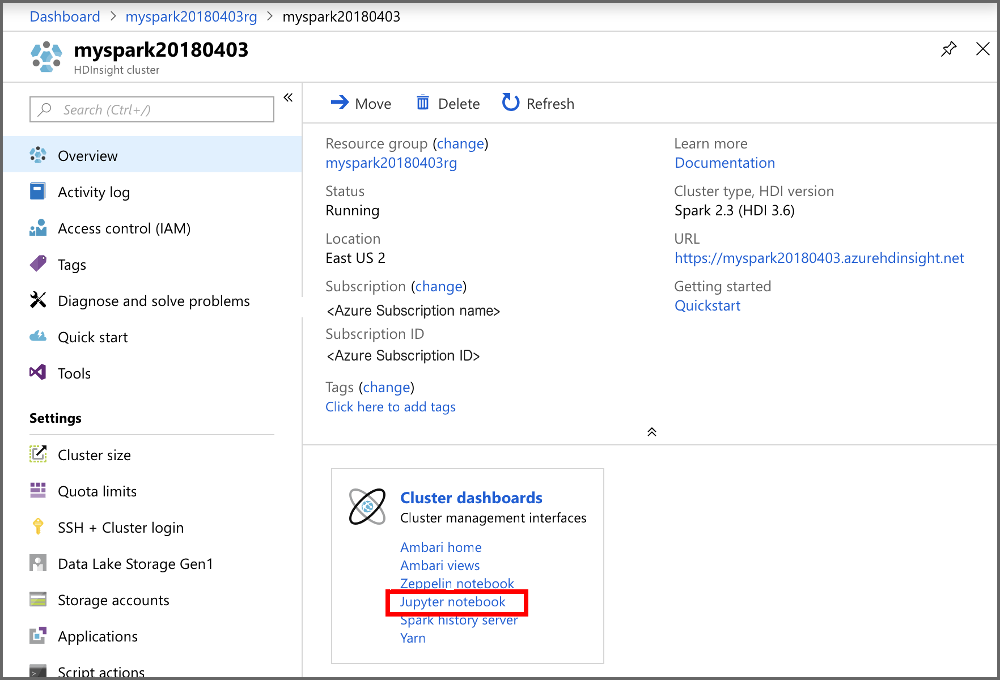
حدد جديد>PySparkلإنشاء دفتر ملاحظات.
يتم إنشاء دفتر ملاحظات جديد وفتحه باسم بدون عنوان (بدون عنوان.ipynb).
قم بتشغيل جمل Apache Spark SQL
SQL (Structured Query Language) هي اللغة الأكثر شيوعًا والأكثر استخدامًا للاستعلام عن البيانات وتحويلها. تعمل عوامل Spark SQL كامتداد لـ Apache Spark لمعالجة البيانات المنظمة، باستخدام بناء الجملة SQL المألوف.
تحقق من أن مركز kernel جاهز. يكون مركز kernel جاهزاً عندما ترى دائرة مجوفة بجانب اسم kernel في دفتر الملاحظات. تشير الدائرة الصلبة إلى أن المركز مشغول.
 alt-text="حالة Kernel." border="true":::
alt-text="حالة Kernel." border="true":::عند بدء تشغيل دفتر الملاحظات للمرة الأولى، يقوم مركز kernel بتنفيذ بعض المهام في الخلفية. انتظر حتى يكون مركز Kernel جاهزاً.
الصق الرمز التالي في خلية فارغة، ثم قم بالضغط SHIFT + ENTER لتقوم بتشغيل الرمز. يسرد الأمر جداول Hive على الكتلة:
%%sql SHOW TABLESعند استخدام ملف Jupyter Notebook مع نظام مجموعة HDInsight، ستحصل على جلسة عمل محددة مسبقًا
sparkيمكنك استخدامها لتشغيل استعلامات Hive باستخدام Spark SQL.%%sqlتخبر Jupyter Notebook باستخدام جلسة العمل المعدة مسبقًاsparkلتشغيل استعلام Hive. يسترد الاستعلام أعلى 10 صفوف من جدول خلية (hivesampletable) الذي يأتي مع جميع مجموعات HDInsight بشكل افتراضي. في المرة الأولى التي تقوم فيها بإرسال الاستعلام، سيقوم Jupyter بإنشاء تطبيق Spark لدفتر الملاحظات. يستغرق حوالي 30 ثانية لإكماله. بمجرد أن يكون التطبيق Spark جاهزًا، يتم تنفيذ الاستعلام في حوالي ثانية واحدة ثم ينتج النتائج. يبدو الإخراج مثل: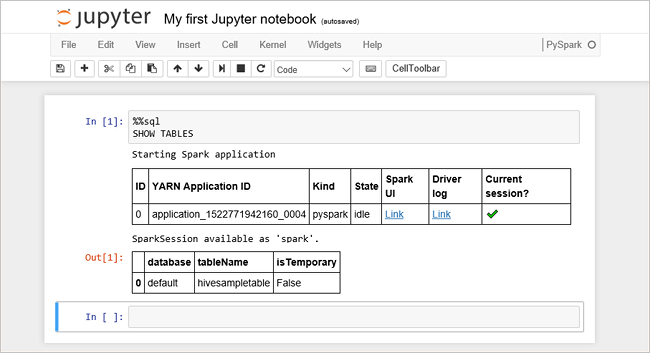 y in HDInsight" border="true":::
y in HDInsight" border="true":::في كل مرة تقوم فيها بتشغيل استعلام في Jupyter، يظهر عنوان نافذة مستعرض الويب حالة (Busy) مع عنوان دفتر الملاحظات. وستتمكن بعدها برؤية دائرة صلبة بجوار نص PySpark في الزاوية العلوية اليمنى.
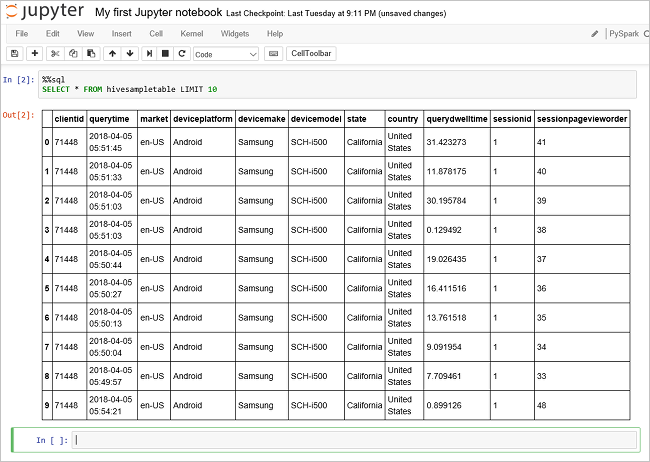
تشغيل استعلام آخر لمشاهدة البيانات في
hivesampletable.%%sql SELECT * FROM hivesampletable LIMIT 10يجب تحديث الشاشة لإظهار إخراج الاستعلام.
 Insight" border="true":::
Insight" border="true":::من القائمة حدد File في دفتر الملاحظات، ثم حدد lose and Halt. إيقاف تشغيل دفتر الملاحظات يطلق موارد الكتلة، بما في ذلك تطبيق Spark.
تنظيف الموارد
بعد إكمال التشغيل السريع، قد تحتاج إلى حذف المجموعة. من خلال HDInsight، يتم تخزين البيانات الخاصة بك في Azure Storage؛ لذا يمكنك حذف المجموعة بأمان عندما لا تكون قيد الاستخدام. كما يتم تحصيل رسوم منك مقابل مجموعة HDInsight، حتى عندما لا تكون قيد الاستخدام. نظراً لأن رسوم نظام المجموعة تزيد عدة مرات عن رسوم التخزين، فمن المنطقي اقتصادياً حذف أنظمة المجموعات عندما لا تكون قيد الاستخدام.
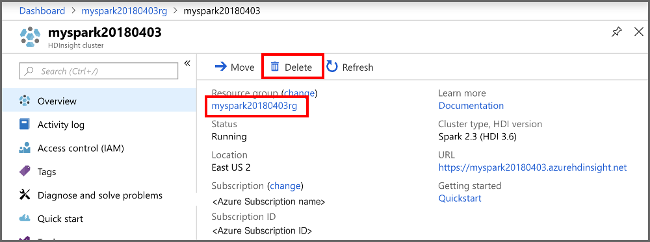
من مدخل Azure، انتقل إلى نظام المجموعة، وحدد حذف.
 نظام مجموعة الرؤية" border="true":::
نظام مجموعة الرؤية" border="true":::
يمكنك أيضًا تحديد اسم مجموعة الموارد لفتح صفحة مجموعة الموارد، ثم حدد حذف مجموعة الموارد. إذا قمت بحذف مجموعة الموارد، سيتم حذف كل من نظام المجموعة HDInsight وحساب التخزين الافتراضي.
الخطوات التالية
في هذا البدء السريع، تعلمت كيفية إنشاء مجموعة Apache Spark في HDInsight وتشغيل استعلام Spark SQL الأساسي. تقدم إلى البرنامج التعليمي التالي لمعرفة كيفية استخدام مجموعة HDInsight لتشغيل الاستعلامات التفاعلية على عينة البيانات.