استخدام مجموعة أدوات Azure لـ IntelliJ لإنشاء تطبيقات Apache Spark للمجموعة HDInsight
توضح هذه المقالة كيفية تطوير تطبيقات Apache Spark على Azure HDInsight باستخدام الأداة الإضافية مجموعة أدوات Azure لـ IntelliJ IDE. Azure HDInsight هي خدمة تحليلات مُدارة ومفتوحة المصدر على السحابة. تتيح لك الخدمة استخدام أطر مفتوحة المصدر مثل Hadoop وApache Spark وApache Hive وApache Kafka.
يمكنك استخدام الأداة الإضافية مجموعة أدوات Azure بعدة طرق:
- تطوير وتقديم تطبيق Scala Spark على نظام مجموعة HDInsight Spark.
- الوصول إلى موارد نظام مجموعة Azure HDInsight Spark.
- قم بتطوير وتشغيل تطبيق Scala Spark محليًا.
في هذه المقالة، ستتعرف على كيفية:
- استخدام Azure Toolkit للمكون الإضافي IntelliJ
- تطوير تطبيقات Apache Spark
- إرسال تطبيق إلى مجموعة Azure HDInsight
المتطلبات الأساسية
مجموعة Apache Spark على HDInsight. للحصول على إرشادات، يرجى مراجعة إنشاء مجموعات Apache Spark في Azure HDInsight. يتم دعم مجموعات HDInsight فقط في السحابة العامة، بينما لا يتم دعم أنواع السحابة الآمنة الأخرى (مثل السحب الحكومية).
عدة تطوير Oracle Java. تستخدم هذه المقالة الإصدار8.0.202 من Java.
IntelliJ IDEA. تستخدم هذه المقالة IntelliJ IDEA Community 2018.3.4.
Azure Toolkit لـ IntelliJ. يرجى الاطلاع على تثبيت Azure Toolkit لـ IntelliJ.
ثبت المكون الإضافي Scala لـ IntelliJ IDEA
خطوات تثبيت المكون الإضافي Scala:
افتح IntelliJ IDEA.
على شاشة الترحيب، انتقل إلى تكوين>المكونات الإضافية لفتح نافذة المكونات الإضافية.
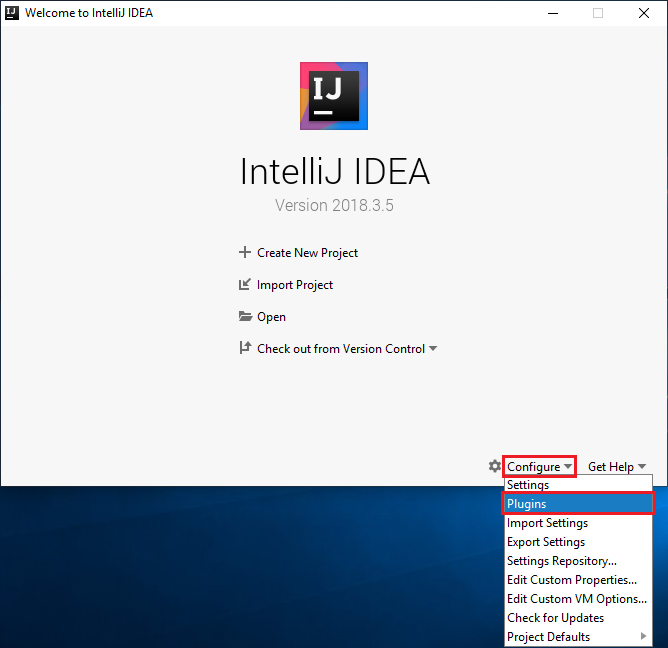
حدد تثبيت المكون الإضافي Scala الذي يظهر في النافذة الجديدة.
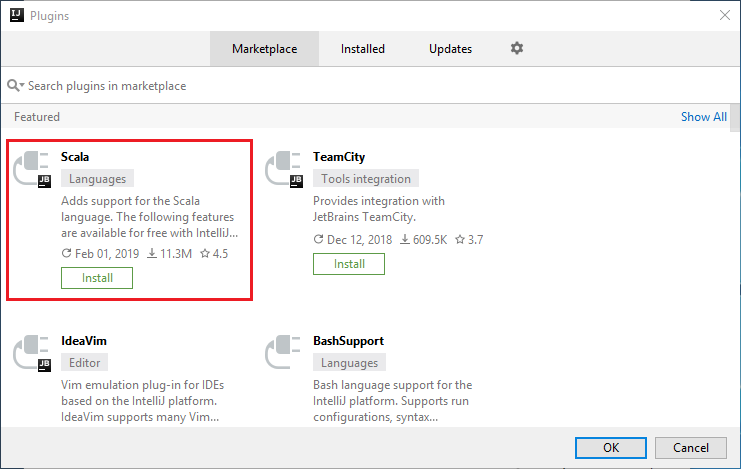
عقب تثبيت المكون الإضافي بنجاح، يجب إعادة تشغيل IDE.
إنشاء تطبيق Spark Scala لمجموعة HDInsight Spark
ابدأ تشغيل IntelliJ IDEA، وحدد "Create New Project" لفتح نافذة "New Project".
حدد Apache Spark/HDInsight من الجزء الأيسر.
حدد مشروع Spark (Scala) من النافذة الرئيسية.
من القائمة المنسدلة أداة الإنشاء حدد أحد الأنواع التالية:
Maven لدعم معالج إنشاء مشروع Scala.
SBT لإدارة التبعيات والبناء لمشروع project.
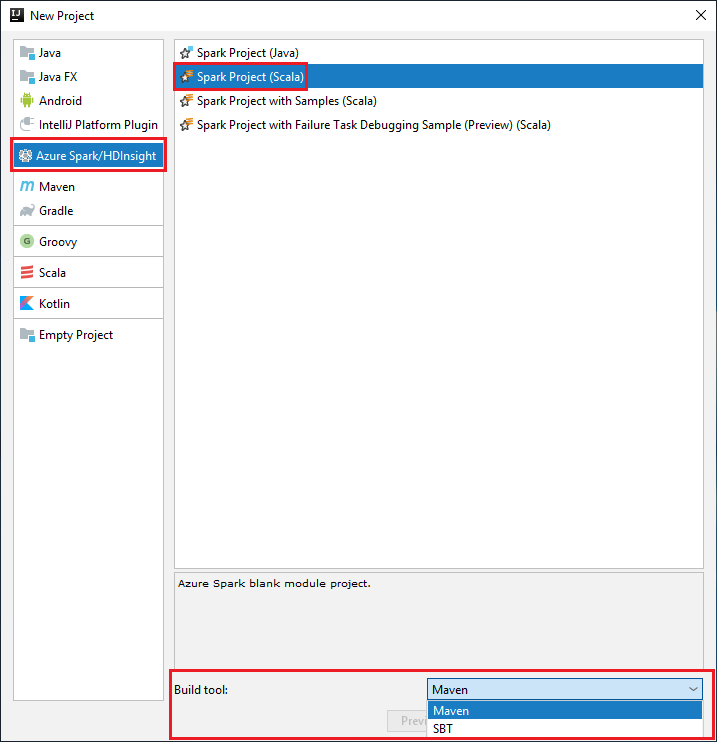
حدد التالي.
في إطار المشروع الجديد وفر المعلومات التالية:
الخاصية الوصف اسم المشروع أدخل اسمًا. يستخدم هذا المقال myApp.موقع المشروع أدخل الموقع لحفظ المشروع. مشروع SDK قد يكون هذا الحقل فارغاً في أول استخدام لـ IDEA. حدد جديد... وانتقل إلى JDK. إصدار Spark يدمج معالج الإنشاء الإصدار المناسب لـSpark SDK و Scala SDK. إذا كان إصدار مجموعة Spark أقدم من 2.0، فحدد Spark 1.x. أو حدد Spark2.x. يستخدم هذا المثال Spark 2.3.0 (Scala 2.11.8). 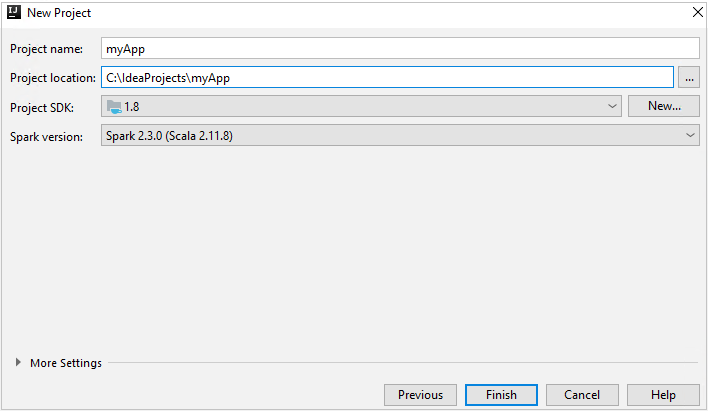
حدد إنهاء. قد يستغرق الأمر بضع دقائق قبل أن يصبح المشروع متاحًا.
يقوم مشروع Spark تلقائيًا بإنشاء أداة لك. لعرض الأداة، نفذ الخطوات التالية:
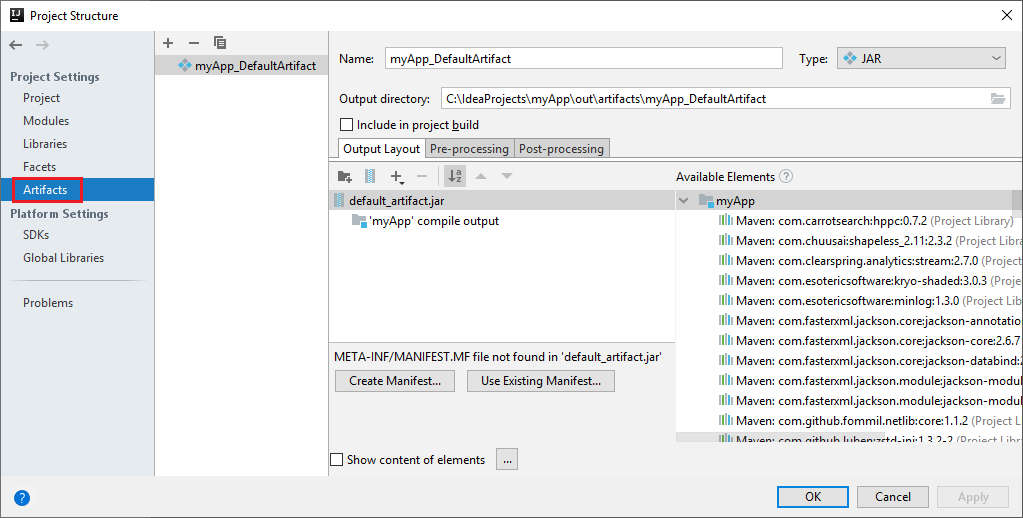
أ. من شريط القائمة، انتقل إلى >Project Structure....
ب. من نافذة Project Structure، حدد Artifacts.
جـ. حدد Cancel بعد عرض الأداة.
أضف التعليمات البرمجية المصدر للتطبيق الخاص بك عن طريق تنفيذ الخطوات التالية:
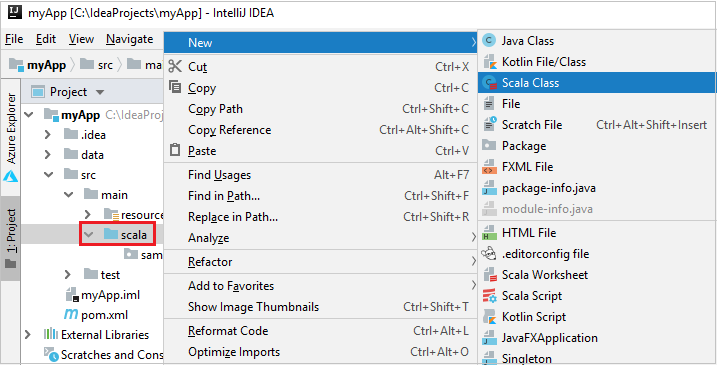
أ. من Project، انتقل إلى myApp>src>main>scala.
ب. انقر بزر الماوس الأيمن فوق scala، ثم انتقل إلى New>Scala Class.
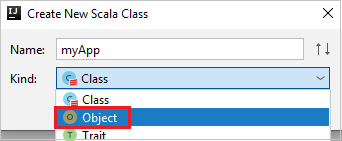
جـ. في مربع الحوار Create New Scala Class، أدخل اسماً، وحدد Object في القائمة المنسدلة Kind، ثم حدد OK.
د. ثم يفتح الملف myApp.scala في طريقة العرض الرئيسية. استبدال التعليمات البرمجية الافتراضية بالتعليمات البرمجية الموجودة أدناه:
import org.apache.spark.SparkConf import org.apache.spark.SparkContext object myApp{ def main (arg: Array[String]): Unit = { val conf = new SparkConf().setAppName("myApp") val sc = new SparkContext(conf) val rdd = sc.textFile("wasbs:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv") //find the rows that have only one digit in the seventh column in the CSV file val rdd1 = rdd.filter(s => s.split(",")(6).length() == 1) rdd1.saveAsTextFile("wasbs:///HVACOut") } }تقرأ التعليمات البرمجية البيانات من HVAC.csv (المتوفر على جميع مجموعات Spark HDInsight)، وتسترد الصفوف التي تحتوي على رقم واحد فقط في العمود السابع في ملف CSV ثم تكتب الإخراج إلى
/HVACOutضمن حاوية التخزين الافتراضية للمجموعة.
الاتصال بمجموعة HDInsight لديك
يمكن للمستخدم إما تسجيل الدخول إلى اشتراك Azure الخاص بك، أو ربط مجموعة HDInsight. استخدم اسم مستخدم/كلمة مرور Ambari أو بيانات الاعتماد المنضمة إلى المجال للاتصال بمجموعة HDInsight الخاصة بك.
تسجيل الدخول إلى اشتراك Azure الخاص بك
من شريط القوائم، انتقل إلى View>Tool Windows >Azure Explorer.
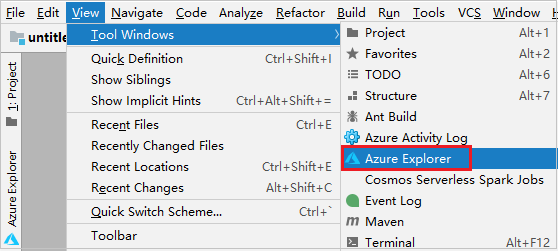
من مستكشف Azure، انقر بزر الماوس الأيمن فوق عقدة Azure، ثم حدد Sign In.
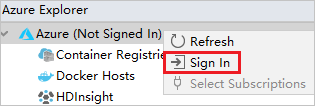
في مربع الحوار Azure Sign In، اختر Device Login،ثم حدد Sign in.

في مربع الحوار Azure Device Login، انقر فوق Copy&Open.

في واجهة المستعرض، قم بلصق التعليمات البرمجية، ثم انقر فوق Next.

أدخل بيانات اعتماد Azure، ثم أغلق المستعرض.

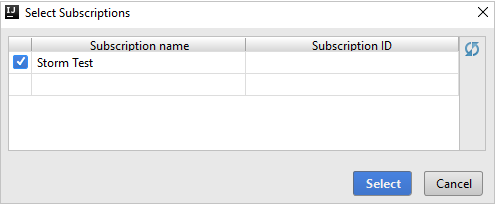
بعد تسجيل الدخول، يسرد مربع الحوار Select Subscriptions كافة اشتراكات Azure المقترنة ببيانات الاعتماد. حدد اشتراكك، ثم حدد الزر Select.
من Azure Explorer، قم بتوسيع HDInsight لعرض مجموعات HDInsight Spark الموجودة في اشتراكاتك.
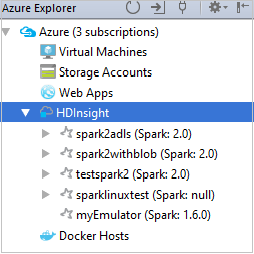
لعرض الموارد (على سبيل المثال، حسابات التخزين) المقترنة مع المجموعة، يمكنك توسيع عقدة اسم المجموعة.

ربط النظام
يمكنك ربط نظام HDInsight باستخدام اسم مستخدم Apache Ambari المُدار. وبالمثل، بالنسبة لنظام مجموعة HDInsight المُنضم إلى المجال، يمكنك الربط باستخدام المجال واسم المستخدم، مثل user1@contoso.com. كما يمكنك ربط مجموعة Livy Service.
من شريط القوائم، انتقل إلى View>Tool Windows >Azure Explorer.
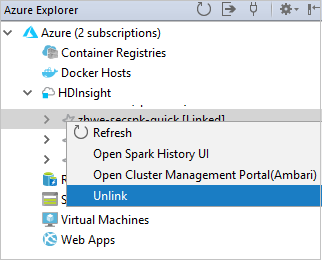
من مستكشف Azure، انقر بزر الماوس الأيمن فوق عقدة HDInsight، ثم حدد Link A Cluster.

تختلف الخيارات المتاحة في نافذة ارتباط مجموعة باختلاف القيمة التي تحددها من القائمة المنسدلة نوع مورد الارتباط. أدخل قيمك ثم حدد OK.
مجموعة HDInsight
الخاصية القيمة نوع مورد الارتباط حدد HDInsight Cluster من القائمة المنسدلة. اسم المجموعة/عنوان URL أدخل اسم المجموعة. نوع المصادقة ترك كـ مصادقة أساسية اسم المستخدم أدخل اسم مستخدم المجموعة، حيث إن الافتراضي هو المسؤول. كلمة المرور أدخل كلمة المرور الخاصة باسم المستخدم. 
خدمة Livy
الخاصية القيمة نوع مورد الارتباط حدد Livy Service من القائمة المنسدلة. نقطة نهاية Livy أدخل نقطة نهاية Livy اسم المجموعة أدخل اسم المجموعة. نقطة نهاية Yarn اختياري. نوع المصادقة ترك كـ مصادقة أساسية اسم المستخدم أدخل اسم مستخدم المجموعة، حيث إن الافتراضي هو المسؤول. كلمة المرور أدخل كلمة المرور الخاصة باسم المستخدم. 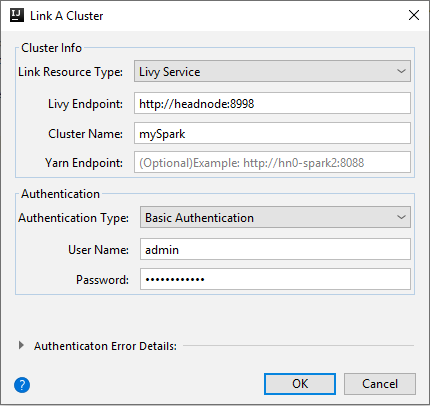
يمكنك مشاهدة المجموعة المرتبطة من عقدة HDInsight.
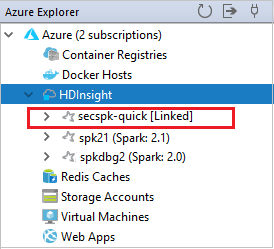
يمكنك أيضاً إلغاء ارتباط نظام من مستكشف Azure.
تشغيل تطبيق Spark Scala على مجموعة HDInsight Spark
بعد إنشاء تطبيق Scala، يمكنك إرساله إلى المجموعة.
من Project، انتقل إلى myApp>src>الرئيسية>scala>myApp. انقر بزر الماوس الأيمن فوق myApp، وحدد Submit Spark Application (من المحتمل أن يكون موجوداً أسفل القائمة).
في نافذة الحوار Submit Spark Application، حدد 1. Spark on HDInsight.
في نافذة Edit configuration، قم بتوفير القيم التالية ثم حدد OK:
الخاصية القيمة مجموعات Spark (Linux فقط) حدد نظام مجموعة HDInsight Spark الذي تريد تشغيل تطبيقك عليه. تحديد أداة للتقديم اترك الإعداد الافتراضي. اسم الفئة الرئيسية القيمة الافتراضية هي الفئة الرئيسية من الملف المحدد. يمكنك تغيير الفئة عن طريق تحديد القطع الناقص(...) واختيار فئة أخرى. تكوينات الوظيفة يمكنك تغيير المفاتيح و/أو القيم الافتراضية. لمزيد من المعلومات، راجع Apache Livy REST API. وسيطات سطر الأوامر يمكنك إدخال وسيطات مفصولة بمسافة للفئة الرئيسية إذا لزم الأمر. الجرار والملفات المشار إليها يمكنك إدخال مسارات الجرار المشار إليها والملفات إن وجدت. يمكنك أيضاً استعراض الملفات في نظام الملفات الظاهري Azure الذي يدعم حالياً فقط نظام المجموعة ADLS Gen 2. لمزيدٍ من المعلومات: انظر تكوين Apache Spark. انظر كذلك، كيفية تحميل الموارد إلى المجموعة. تخزين تحميل الوظيفة قم بالتوسيع للكشف عن خيارات إضافية. نوع التخزين حدد Use Azure Blob to upload من القائمة المنسدلة. حساب التخزين أدخل حساب التخزين الخاص بك. مفتاح التخزين أدخل مفتاح التخزين. حاوية التخزين حدد حاوية التخزين من القائمة المنسدلة بمجرد إدخال حساب التخزينومفتاح التخزين. 
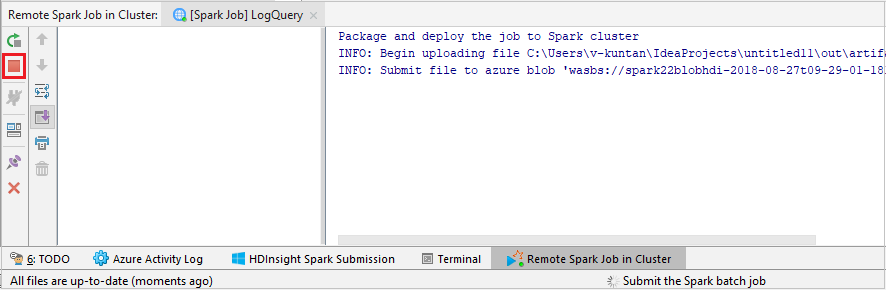
حدد SparkJobRun لإرسال المشروع إلى المجموعة المحددة. تعرض علامة التبويب Remote Spark Job in Cluster تقدم تنفيذ المهمة في الأسفل. يمكنك إيقاف التطبيق بالنقر فوق الزر الأحمر.
تصحيح أخطاء تطبيقات Apache Spark محلياً أو عن بُعد على مجموعة HDInsight
نوصي أيضاً بطريقة أخرى لإرسال تطبيق Spark إلى المجموعة. يمكنك القيام بذلك عن طريق تعيين المعلمات في تكوينات تشغيل/تصحيح الأخطاء لـ IDE. انظر تتبع أخطاء تطبيقات Apache Spark محلياً أو عن بُعد على نظام مجموعة HDInsight باستخدام مجموعة أدوات Azure لـ Intelj عبر SSH.
الوصول إلى مجموعات HDInsight Spark وإدارتها باستخدام مجموعة أدوات Azure لـ IntelliJ
يمكنك إجراء عمليات مختلفة باستخدام مجموعة أدوات Azure لـ IntelliJ. يتم تشغيل معظم العمليات من مستكشف Azure. من شريط القوائم، انتقل إلى View>Tool Windows >Azure Explorer.
الوصول إلى طريقة عرض المهمة
من Azure Explorer، انتقل إلى HDInsight><نظام مجموعتك>>الوظائف.
في الجزء الأيسر، تعرض علامة التبويب عرض مهمة Spark جميع التطبيقات التي تم تشغيلها في نظام المجموعة. حدد اسم التطبيق الذي تريد الاطلاع على مزيد من التفاصيل عنه.
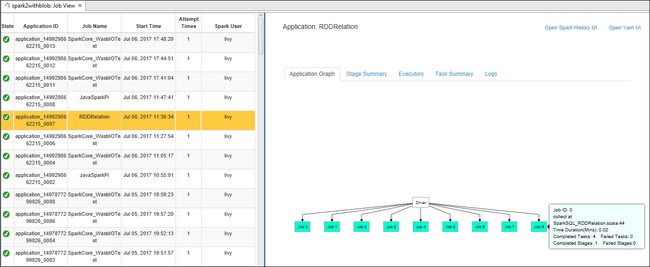
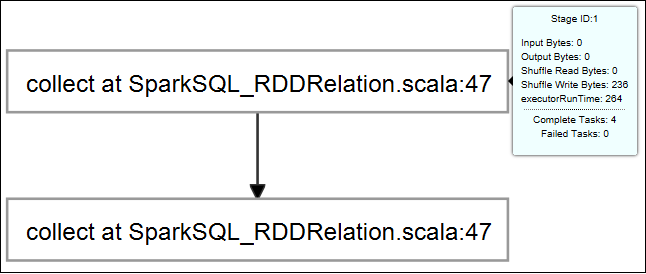
لعرض معلومات مهمة التشغيل الأساسية، مرر الماوس فوق الرسم البياني للوظيفة. لعرض الرسم البياني للمراحل والمعلومات التي تولدها كل مهمة، حدد عقدة في الرسم البياني للمهمة.
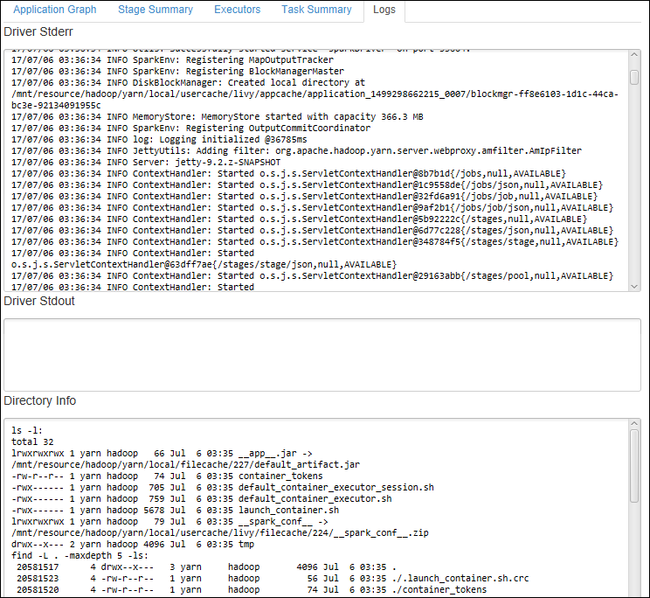
لعرض السجلات المستخدمة بشكل متكرر، مثل Driver Stderr وDriver Stdout وDirectory Info، حدد علامة التبويب Log.
يمكنك عرض واجهة مستخدم محفوظات Spark وواجهة مستخدم YARN (على مستوى التطبيق). حدد ارتباطاً أعلى النافذة.
الوصول إلى خادم محفوظات Spark
من مستكشف Azure، وسّع HDInsight، وانقر بزر الماوس الأيمن فوق اسم مجموعة Spark، ثم حدد Open Spark History UI.
عند مطالبتك، أدخل بيانات اعتماد مسؤول المجموعة التي حددتها عند إعداد المجموعة.
من لوحة معلومات خادم محفوظات Spark، يمكنك استخدام اسم التطبيق للبحث عن التطبيق الذي انتهيت للتو من تشغيله. في التعليمات البرمجية السابقة، قمت بتعيين اسم التطبيق باستخدام
val conf = new SparkConf().setAppName("myApp"). اسم تطبيق Spark الخاص بك هو myApp.
بدء تشغيل مدخل Ambari
من مستكشف Azure، قم بتوسيع HDInsight، وانقر بزر الماوس الأيمن فوق اسم مجموعة Spark، ثم حدد Open Cluster Management Portal (Ambari).
أدخل بيانات اعتماد المسؤول لنظام المجموعة عند مطالبتك بذلك. لقد حددت بيانات الاعتماد هذه أثناء عملية إعداد المجموعة.
إدارة اشتراكات Azure
بشكلٍ افتراضي، تسرد مجموعة أدوات Azure الخاصة بـ IntelliJ مجموعات Spark من جميع اشتراكات Azure. إذا لزم الأمر، يمكنك تحديد الاشتراكات التي تريد الوصول إليها.
من مستكشف Azure، انقر بزر الماوس الأيمن فوق عقدة جذر Azure، ثم حدد Select Subscriptions.
من نافذة Select Subscriptions، قم بإلغاء تحديد خانات الاختيار المجاورة للاشتراكات التي لا تريد الوصول إليها، ثم حدد Close.
وحدة تحكم Spark
يمكنك تشغيل وحدة التحكم المحلية Spark (Scala) أو تشغيل وحدة تحكم جلسة العمل التفاعلية Spark Livy (Scala).
وحدة التحكم المحلية لـ Spark (Scala)
تأكد من استيفاء شرط WINUTILS.EXE الأساسي.
من شريط القوائم، انتقل إلى Run>Edit Configurations....
من نافذة Run/Debug Configurations في الجزء الأيسر، انتقل إلى Apache Spark on HDInsight>[Spark on HDInsight] myApp.
من النافذة الرئيسية، حدد علامة التبويب
Locally Run.قم بتوفير القيم التالية، ثم حدد OK:
الخاصية القيمة الفئة الرئيسية للمهمة القيمة الافتراضية هي الفئة الرئيسية من الملف المحدد. يمكنك تغيير الفئة عن طريق تحديد القطع الناقص(...) واختيار فئة أخرى. متغيرات البيئة تأكد من صحة قيمة HADOOP_HOME. موقع WINUTILS.exe تأكد من صحة المسار. 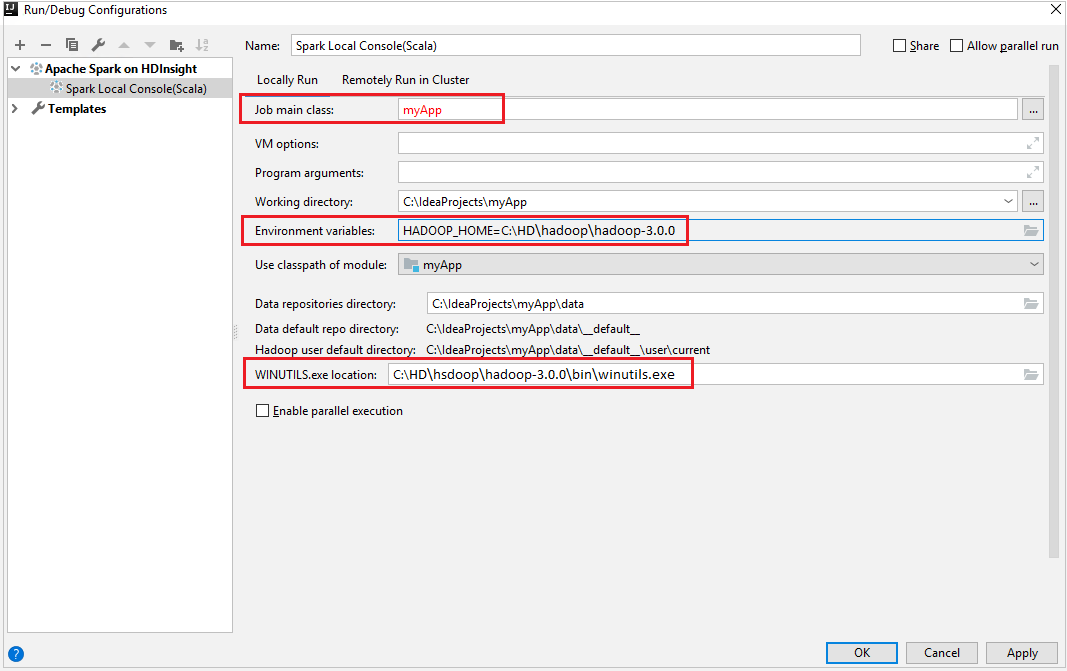
من Project، انتقل إلى myApp>src>الرئيسية>scala>myApp.
من شريط القوائم، انتقل إلى Tools>Spark Console>Run Spark Local Console(Scala).
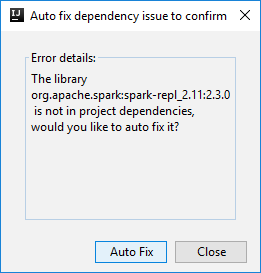
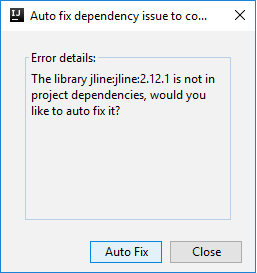
ثم قد يتم عرض مربعي حوار لسؤالك عما إذا كنت تريد إصلاح التبعيات تلقائيًا. إذا كان الأمر كذلك، حدد Auto Fix.
يجب أن تبدو وحدة التحكم مشابهة للصورة أدناه. في نوع إطار وحدة التحكم
sc.appName، ثم اضغط ctrl+Enter. سيتم عرض النتيجة. يمكنك إنهاء وحدة التحكم المحلية بالنقر فوق الزر الأحمر.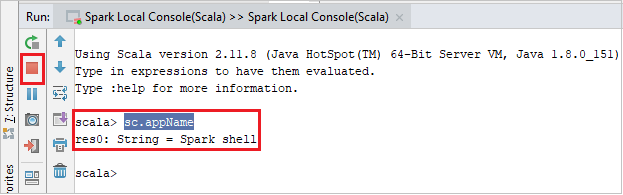
وحدة التحكم في الجلسة التفاعلية Spark Livy (Scala)
من شريط القوائم، انتقل إلى Run>Edit Configurations....
من نافذة Run/Debug Configurations في الجزء الأيسر، انتقل إلى Apache Spark on HDInsight>[Spark on HDInsight] myApp.
من النافذة الرئيسية، حدد علامة التبويب
Remotely Run in Cluster.قم بتوفير القيم التالية، ثم حدد OK:
الخاصية القيمة مجموعات Spark (Linux فقط) حدد نظام مجموعة HDInsight Spark الذي تريد تشغيل تطبيقك عليه. اسم الفئة الرئيسية القيمة الافتراضية هي الفئة الرئيسية من الملف المحدد. يمكنك تغيير الفئة عن طريق تحديد القطع الناقص(...) واختيار فئة أخرى. 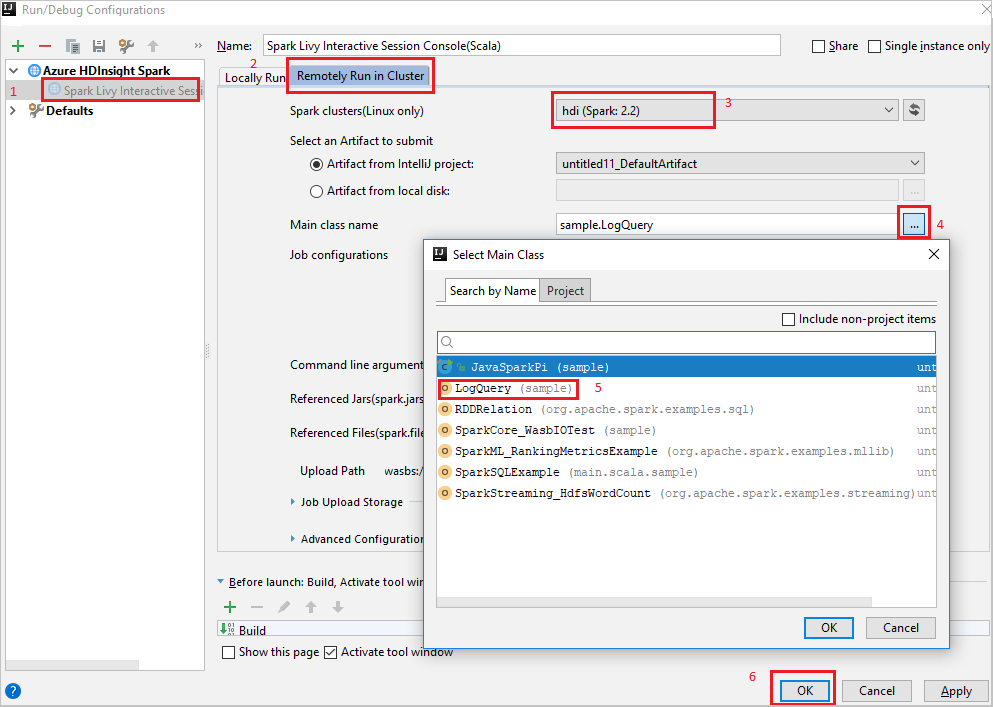
من Project، انتقل إلى myApp>src>الرئيسية>scala>myApp.
من شريط القوائم، انتقل إلى Tools>Spark console>Run Spark Livy Interactive Session Console(Scala).
يجب أن تبدو وحدة التحكم مشابهة للصورة أدناه. في نوع إطار وحدة التحكم
sc.appName، ثم اضغط ctrl+Enter. سيتم عرض النتيجة. يمكنك إنهاء وحدة التحكم المحلية بالنقر فوق الزر الأحمر.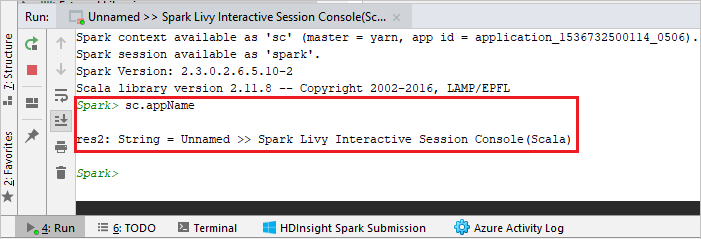
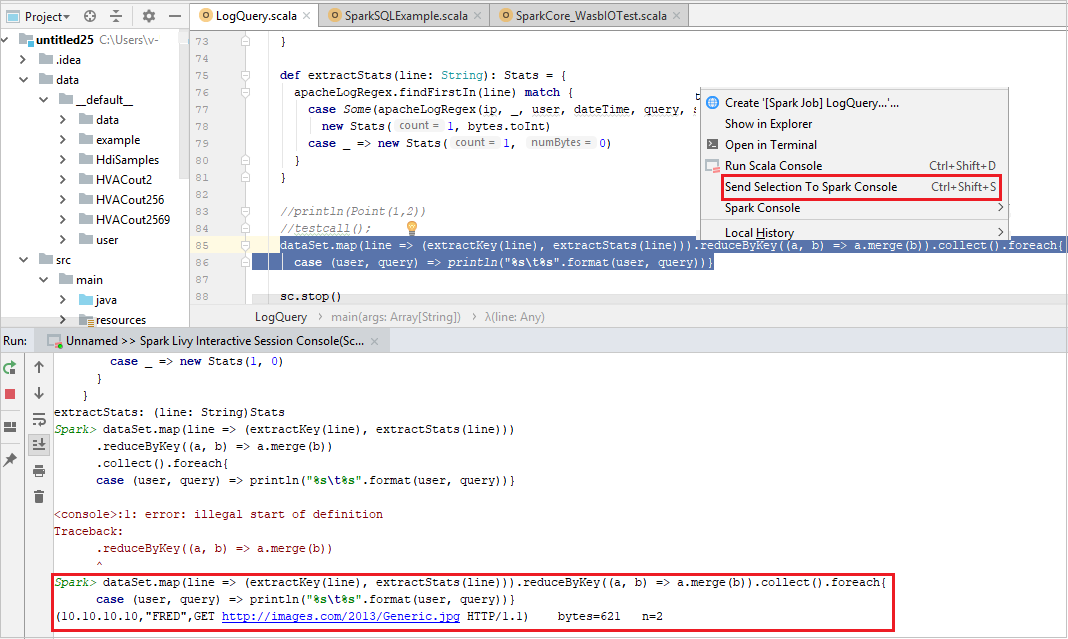
إرسال التحديد إلى وحدة تحكم Spark
من الملائم لك توقع نتيجة البرنامج النصي عن طريق إرسال بعض التعليمات البرمجية إلى وحدة التحكم المحلية أو وحدة التحكم Livy Interactive Session Console(Scala). يمكنك تمييز بعض التعليمات البرمجية في ملف Scala، ثم النقر بزر الماوس الأيمن فوق Send Selection To Spark Console. سيتم إرسال التعليمات البرمجية المحددة إلى وحدة التحكم. سيتم عرض النتيجة بعد التعليمات البرمجية في وحدة التحكم. تتحقق وحدة التحكم من الأخطاء إذا كانت موجودة.
التكامل مع HDInsight Identity Broker (HIB)
اتصل بمجموعة HDInsight ESP الخاصة بك باستخدام ID Broker (HIB)
يمكنك اتباع الخطوات العادية لتسجيل الدخول إلى اشتراك Azure للاتصال بمجموعة HDInsight ESP باستخدام ID Broker (HIB). بعد تسجيل الدخول، سترى قائمة المجموعة في مستكشف Azure. لمزيد من الإرشادات، راجع الاتصال بمجموعة HDInsight.
تشغيل تطبيق Spark Scala على مجموعة HDInsight ESP باستخدام ID Broker (HIB)
يمكنك اتباع الخطوات العادية لإرسال المهمة إلى مجموعة HDInsight ESP باستخدام ID Broker (HIB). راجع تشغيل تطبيق Spark Scala على مجموعة HDInsight Spark للحصول على مزيد من الإرشادات.
نقوم بتحميل الملفات الضرورية إلى مجلد مسمى بحساب تسجيل الدخول الخاص بك، ويمكنك رؤية مسار التحميل في ملف التكوين.

وحدة تحكم Spark على مجموعة HDInsight ESP باستخدام ID Broker (HIB)
يمكنك تشغيل وحدة التحكم المحلية لـ Spark (Scala) أو تشغيل وحدة تحكم جلسة العمل التفاعلية لـ Spark Livy (Scala) على نظام مجموعة HDInsight ESP باستخدام ID Broker (HIB). راجع وحدة تحكم Spark للحصول على مزيدٍ من الإرشادات.
إشعار
بالنسبة إلى نظام المجموعة HDInsight ESP باستخدام Id Broker (HIB)، لا يتم حالياً دعم ربط نظام مجموعة وتصحيح أخطاء تطبيقات Apache Spark عن بعد.
دور القارئ فقط
عندما يرسل المستخدمون مهمة إلى نظام مجموعة بإذن دور «قارئ فقط»، تكون بيانات اعتماد Ambari مطلوبة.
ربط نظام مجموعة من قائمة السياق
قم بتسجيل الدخول بحساب دور «قارئ فقط».
من Azure Explorer، قم بتوسيع HDInsight لعرض أنظمة مجموعات HDInsight الموجودة في اشتراكك. أنظمة المجموعات المميزة بعلامة "دور:قارئ" لها إذن دور للقارئ فقط.

انقر بزر الماوس الأيمن فوق نظام المجموعة الذي له إذن دور قارئ فقط. حدد ربط نظام المجموعة هذا من قائمة السياق لربط نظام المجموعة. أدخل اسم المستخدم وكلمة المرور لـ Ambari.
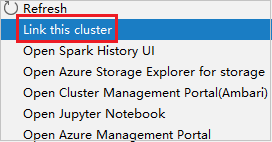
إذا تم ربط نظام المجموعة بنجاح، فسيتم تحديث HDInsight. وستصبح مرحلة نظام المجموعة مرتبطة.
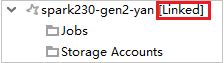
ربط نظام المجموعة عن طريق توسيع عقدة المهام
انقر فوق عقدة Jobs، تنبثق نافذة رفض الوصول إلى مهمة نظام المجموعة.
انقر فوق Link this cluster لربط نظام المجموعة.

ارتباط مجموعة النظام من نافذة تكوينات التشغيل/التصحيح
إنشاء تكوين HDInsight. ثم حدد Remotely Run in Cluster.
حدد مجموعة النظام، التي لديها إذن دور القارئ فقط لمجموعات Spark (Linux فقط). تظهر رسالة تحذير. يمكنك النقر فوق ربط نظام المجموعة هذا لربط نظام المجموعة.
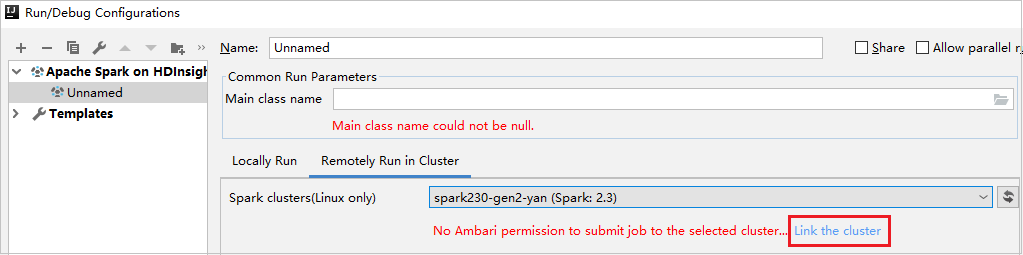
عرض حسابات التخزين
بالنسبة لأنظمة المجموعات التي لها إذن دور قارئ فقط، انقر فوق عقدة Storage Accounts، وستنبثق نافذة رفض الوصول إلى التخزين. يمكنك النقر فوق Open Azure Storage Explorer لفتح مستكشف التخزين.


بالنسبة لأنظمة المجموعات المرتبطة، انقر فوق عقدة Storage Accounts، وستنبثق نافذة رفض الوصول إلى التخزين. يمكنك النقر فوق Open Azure Storage لفتح مستكشف التخزين.

تحويل تطبيقات IntelliJ IDEA الحالية لاستخدام مجموعة أدوات Azure لـ IntelliJ
يمكنك تحويل تطبيقات Spark Scala الموجودة التي قمت بإنشائها في IntelliJ IDEA لتكون متوافقة مع مجموعة أدوات Azure لـ IntelliJ. يمكنك بعد ذلك استخدام المكون الإضافي لإرسال التطبيقات إلى مجموعة HDInsight Spark.
بالنسبة لتطبيق Spark Scala الحالي الذي تم إنشاؤه من خلال IntelliJ IDEA، افتح ملف
.imlالمرتبط.على مستوى الجذر، يوجد عنصر وحدة مثل النص التالي:
<module org.jetbrains.idea.maven.project.MavenProjectsManager.isMavenModule="true" type="JAVA_MODULE" version="4">تحرير العنصر المراد إضافته
UniqueKey="HDInsightTool"بحيث يبدو عنصر الوحدة مشابهاً للنص التالي:<module org.jetbrains.idea.maven.project.MavenProjectsManager.isMavenModule="true" type="JAVA_MODULE" version="4" UniqueKey="HDInsightTool">احفظ التغييرات. يجب أن يكون تطبيقك الآن متوافقاً مع مجموعة أدوات Azure لـ IntelliJ. يمكنك اختباره بالنقر بزر الماوس الأيمن فوق اسم المشروع في المشروع. تحتوي القائمة المنبثقة الآن على الخيار إرسال تطبيق Spark إلى HDInsight.
تنظيف الموارد
إذا كنت لن تستمر في استخدام هذا التطبيق، فاحذف المجموعة التي قمت بإنشائها عن طريق اتباع الخطوات التالية:
قم بتسجيل الدخول إلى بوابة Azure.
في المربع بحث في الأعلى، اكتب HDInsight.
حدد مجموعات HDInsight ضمن الخدمات.
في قائمة مجموعات HDInsight التي تظهر، حدد ... بجانب المجموعة التي قمت بإنشائها لهذه المقالة.
حدد حذف. حدد نعم.

الأخطاء والحل
قم بإلغاء وضع علامة على المجلد src كمصادر إذا تلقيت أخطاء فشل الإنشاء كما يلي:

قم بإلغاء وضع علامة على المجلد src كمصادر لحل هذه المشكلة:
انتقل إلى ملف وحدد بنية المشروع.
حدد الوحدات ضمن الإعدادات Project.
حدد ملف src وقم بإلغاء تحديده كمصادر.
انقر فوق الزر تطبيق ثم انقر فوق الزر موافق لإغلاق مربع الحوار.

الخطوات التالية
في هذه المقالة، تعلمت كيفية استخدام مجموعة أدوات Azure للمكون الإضافي IntelliJ لتطوير تطبيقات Apache Spark المكتوبة بلغة Scala. ثم أرسلها إلى مجموعة HDInsight Spark مباشرة من بيئة التطوير المتكاملة IntelliJ (IDE). انتقل إلى المقالة التالية لمعرفة طريقة التمكن منسحب البيانات التي قمت بتسجيلها في Apache Spark في أداة تحليلات BI، مثل Power BI.