إشعار
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تسجيل الدخول أو تغيير الدلائل.
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تغيير الدلائل.
في هذا التشغيل السريع، يمكنك استخدام مدخل Microsoft Azure لإنشاء مجموعة Apache Spark في Azure HDInsight. يمكنك بعد ذلك إنشاء Jupyter Notebook، واستخدامه لتشغيل استعلامات Spark SQL مقابل جداول Apache Hive. Azure HDInsight هي خدمة تحليلات مدارة كاملة الطيف ومفتوحة المصدر للمؤسسات. يتيح إطار عمل Apache Spark لـ HDInsight تحليلات البيانات السريعة والحوسبة العنقودية باستخدام المعالجة داخل الذاكرة. يتيح لك Jupyter Notebook التفاعل مع بياناتك ، ودمج التعليمات البرمجية مع نص تخفيض السعر ، والقيام بتصورات بسيطة.
للحصول على تفسيرات متعمقة للتكوينات المتوفرة، راجع إعداد المجموعات في HDInsight. لمزيد من المعلومات حول استخدام المدخل لإنشاء المجموعات، راجع إنشاء مجموعات في المدخل.
إذا كنت تستخدم مجموعات متعددة معا ، فقد ترغب في إنشاء شبكة ظاهرية. إذا كنت تستخدم نظام مجموعة Spark، فقد ترغب أيضا في استخدام Hive Warehouse Connector. لمزيد من المعلومات، راجع تخطيط شبكة ظاهرية لـ Azure HDInsightوتكامل Apache Spark وApache Hive مع Apache Hive Warehouse Connector.
هام
يتم تقسيم الفوترة لمجموعات HDInsight بالتناسب في الدقيقة، سواء كنت تستخدمها أم لا. تأكد من حذف نظام المجموعة الخاص بك بعد الانتهاء من استخدامه. لمزيد من المعلومات، راجع قسم تنظيف الموارد في هذه المقالة.
المتطلبات الأساسية
حساب Azure مع اشتراك نشط. أنشئ حساباً مجاناً.
إنشاء مجموعة Apache Spark في HDInsight
يمكنك استخدام مدخل Microsoft Azure لإنشاء مجموعة HDInsight التي تستخدم Azure Storage Blobs كتخزين نظام المجموعة. لمزيد من المعلومات حول استخدام Data Lake Storage Gen2، راجع التشغيل السريع: إعداد المجموعات في HDInsight.
قم بتسجيل الدخول إلى بوابة Azure.
من القائمة العلوية، حدد + إنشاء مورد.
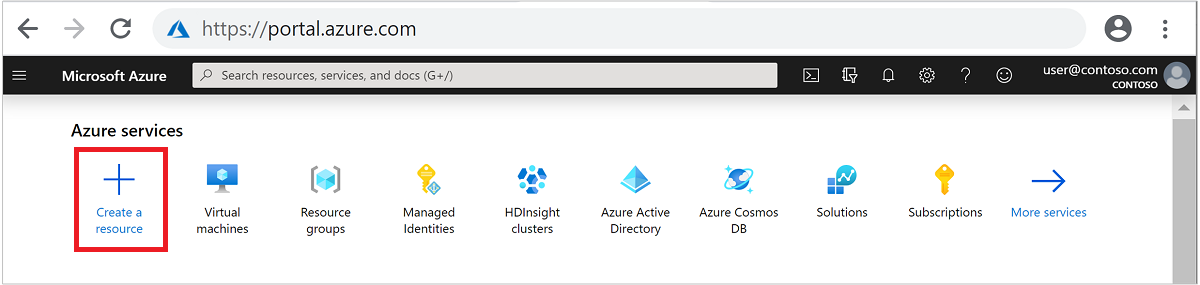
حدد Analytics>Azure HDInsight للانتقال إلى صفحة إنشاء نظام مجموعة HDInsight .
من علامة التبويب الأساسيات ، قم بتوفير المعلومات التالية:
الخاصية وصف الاشتراك من القائمة المنسدلة، حدد اشتراك Azure المستخدم لنظام المجموعة. مجموعة الموارد من القائمة المنسدلة، حدد مجموعة الموارد الحالية، أو حدد إنشاء جديد. اسم شبكة نظام المجموعة أدخل اسمًا فريدًا عالميًا. المنطقة من القائمة المنسدلة، حدد منطقة يتم إنشاء نظام المجموعة فيها. مناطق التوفّر اختياري - حدد منطقة إتاحة لنشر نظام المجموعة الخاص بك نوع شبكة نظام المجموعة حدد نوع نظام المجموعة لفتح قائمة. من القائمة، حدد Spark. إصدار شبكة نظام المجموعة سيتم ملء هذا الحقل تلقائيًا بالإصدار الافتراضي بمجرد تحديد نوع شبكة نظام المجموعة. اسم مستخدم تسجيل الدخول إلى نظام المجموعة أدخل اسم مستخدم تسجيل الدخول إلى نظام المجموعة. الاسم الافتراضي هو admin. يمكنك استخدام هذا الحساب لتسجيل الدخول إلى دفتر ملاحظات Jupyter لاحقا في التشغيل السريع. كلمة مرور تسجيل الدخول إلى نظام المجموعة أدخل كلمة مرور تسجيل الدخول إلى نظام المجموعة. اسم مستخدم Shell (SSH) الآمن. أدخل اسم المستخدم SSH. اسم مستخدم SSH المستخدم لهذا التشغيل السريع هو sshuser. بشكل افتراضي، يشترك هذا الحساب في نفس كلمة المرور مثل حساب اسم مستخدم تسجيل الدخول إلى نظام المجموعة . 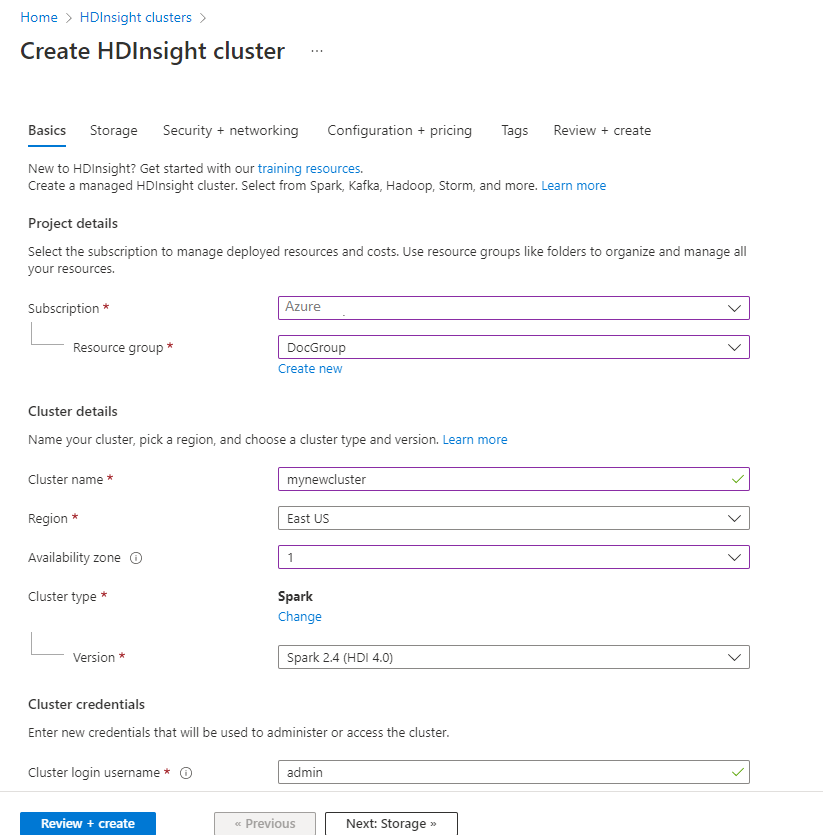
حدد التالي: التخزين >> للمتابعة إلى صفحة التخزين .
ضمن»التخزين»، توفير القيم التالية:
الخاصية وصف نوع التخزين الأساسي استخدم القيمة الافتراضية Azure Storage. أسلوب التحديد استخدم القيمة الافتراضية حدد من. حساب التخزين الأساسي استخدم القيمة التي يتم ملؤها تلقائيًا. حاوية استخدم القيمة التي يتم ملؤها تلقائيًا. 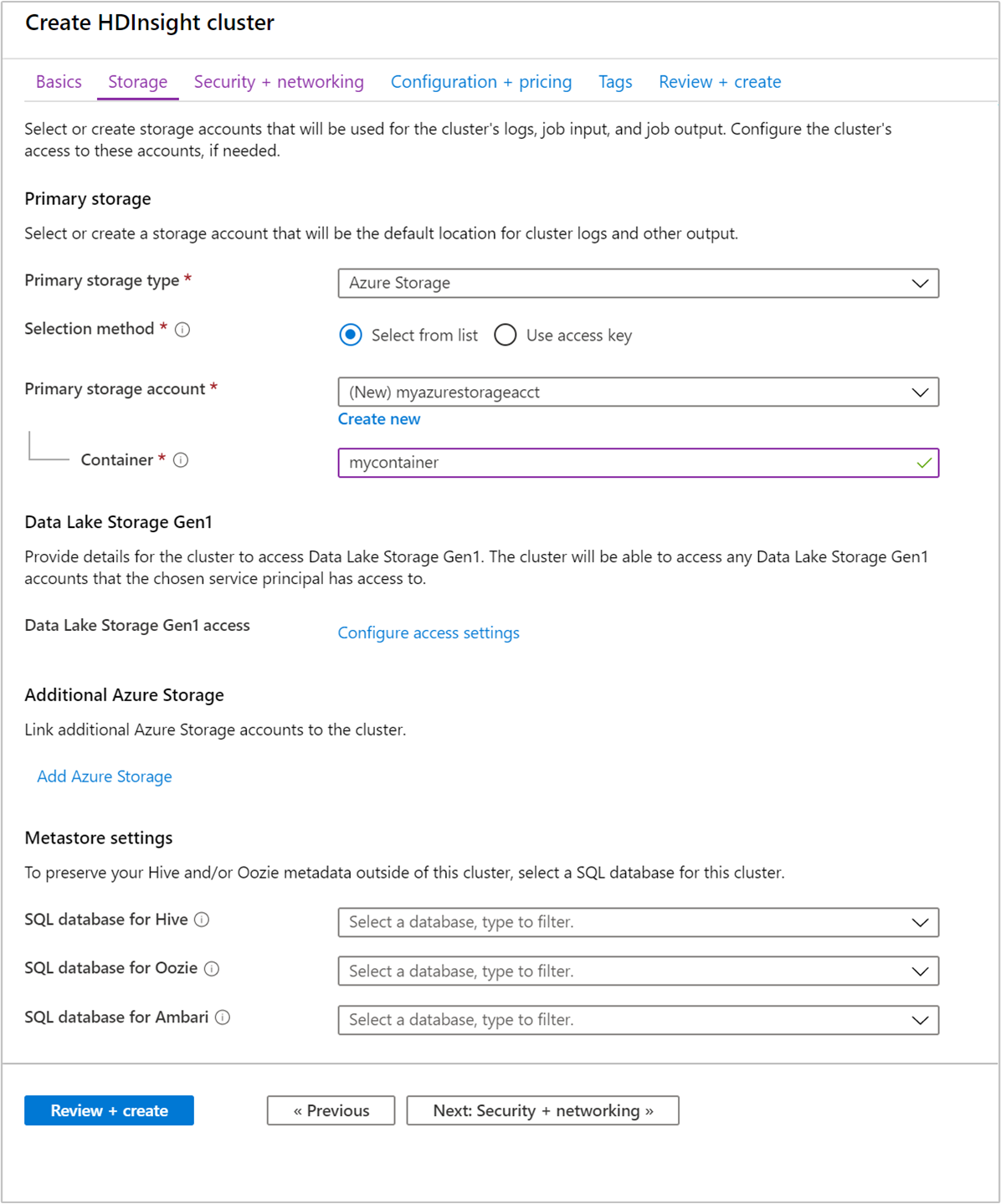
حدد «مراجعة + إنشاء» للمتابعة.
ضمن «مراجعة + إنشاء»، حدد «إنشاء». يستغرق إنشاء شبكة نظام المجموعة حوالي 20 دقيقة. يجب إنشاء شبكة نظام المجموعة قبل أن تتمكن من المتابعة إلى جلسة العمل التالية.
إذا واجهت مشكلة في إنشاء مجموعات HDInsight، فقد يكون ذلك بسبب عدم امتلاكك الأذونات الصحيحة للقيام بذلك. لمزيد من المعلومات، راجع متطلبات التحكم في الوصول.
إنشاء دفتر ملاحظات Jupyter
Jupyter Notebook هي بيئة كمبيوتر محمول تفاعلية تدعم لغات البرمجة المختلفة. يتيح لك دفتر الملاحظات التفاعل مع بياناتك ودمج التعليمات البرمجية مع نص التخفيض وإجراء تصورات بسيطة.
من مستعرض ويب، انتقل إلى
https://CLUSTERNAME.azurehdinsight.net/jupyter، حيثCLUSTERNAMEيوجد اسم نظام المجموعة الخاص بك. إذا طلب منك ذلك، أدخل بيانات اعتماد تسجيل الدخول إلى نظام المجموعة لنظام المجموعة.حدد New>PySpark لإنشاء دفتر ملاحظات.
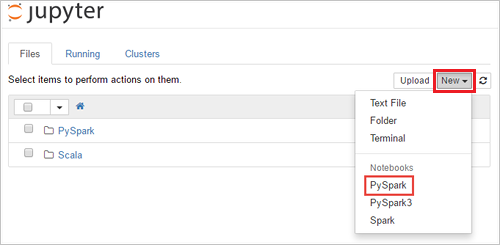
يتم إنشاء دفتر ملاحظات جديد وفتحه باسم Untitled(Untitled.pynb).
تشغيل عبارات Apache Spark SQL
SQL (لغة الاستعلام المنظمة) هي اللغة الأكثر شيوعا والأكثر استخداما للاستعلام عن البيانات وتعريفها. يعمل Spark SQL كملحق ل Apache Spark لمعالجة البيانات المنظمة، باستخدام بناء جملة SQL المألوف.
تحقق من أن kernel جاهزة. تكون النواة جاهزة عندما ترى دائرة مجوفة بجوار اسم kernel في دفتر الملاحظات. تشير الدائرة الصلبة إلى أن النواة مشغولة.

عند بدء تشغيل دفتر الملاحظات لأول مرة، تقوم النواة بتنفيذ بعض المهام في الخلفية. انتظر حتى تصبح النواة جاهزة.
الصق التعليمات البرمجية التالية في خلية فارغة، ثم اضغط على SHIFT + ENTER لتشغيل التعليمات البرمجية. يسرد الأمر جداول الخلية على نظام المجموعة:
%%sql SHOW TABLESعند استخدام Jupyter Notebook مع نظام مجموعة HDInsight الخاص بك، تحصل على إعداد
sqlContextمسبق يمكنك استخدامه لتشغيل استعلامات Hive باستخدام Spark SQL.%%sqlيخبر Jupyter Notebook باستخدام الإعدادsqlContextالمسبق لتشغيل استعلام Hive. يسترد الاستعلام أعلى 10 صفوف من جدول Hive (hivesampletable) الذي يأتي مع جميع مجموعات HDInsight افتراضيا. يستغرق الحصول على النتائج حوالي 30 ثانية. يبدو الإخراج مثل: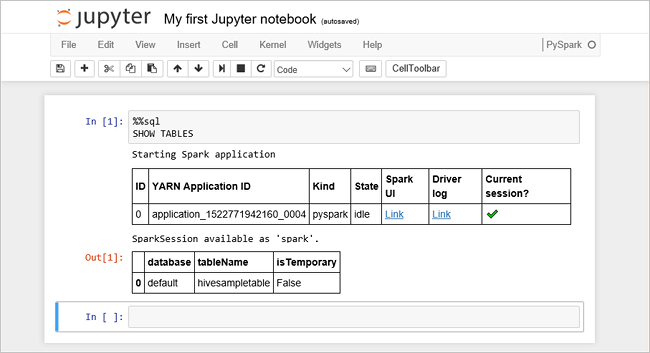 هو التشغيل السريع." border="true":::
هو التشغيل السريع." border="true":::في كل مرة تقوم فيها بتشغيل استعلام في Jupyter، يعرض عنوان نافذة مستعرض الويب حالة (مشغول) مع عنوان دفتر الملاحظات. سترى أيضا دائرة صلبة بجوار نص PySpark في الزاوية العلوية اليمنى.
قم بتشغيل استعلام آخر لرؤية البيانات في
hivesampletable.%%sql SELECT * FROM hivesampletable LIMIT 10يجب تحديث الشاشة لإظهار إخراج الاستعلام.
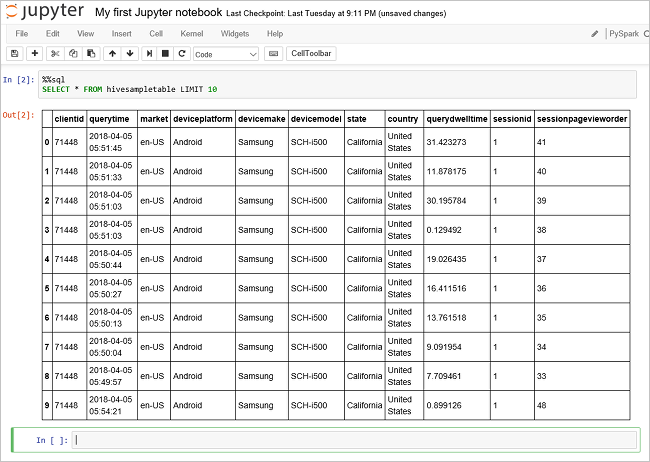 البصيرة" الحدود = "true":::
البصيرة" الحدود = "true":::من القائمة ملف في دفتر الملاحظات، حدد إغلاق وإيقاف تشغيل. يؤدي إيقاف تشغيل دفتر الملاحظات إلى تحرير موارد نظام المجموعة.
تنظيف الموارد
يحفظ HDInsight بياناتك في Azure Storage أو Azure Data Lake Storage، بحيث يمكنك حذف نظام مجموعة بأمان عندما لا يكون قيد الاستخدام. كما يتم تحصيل رسوم منك مقابل مجموعة HDInsight، حتى عندما لا تكون قيد الاستخدام. نظراً لأن رسوم نظام المجموعة تزيد عدة مرات عن رسوم التخزين، فمن المنطقي اقتصادياً حذف أنظمة المجموعات عندما لا تكون قيد الاستخدام. إذا كنت تخطط للعمل على البرنامج التعليمي المدرج في الخطوات التالية على الفور، فقد ترغب في الاحتفاظ بنظام المجموعة.
عد إلى مدخل Microsoft Azure، وحدد حذف.
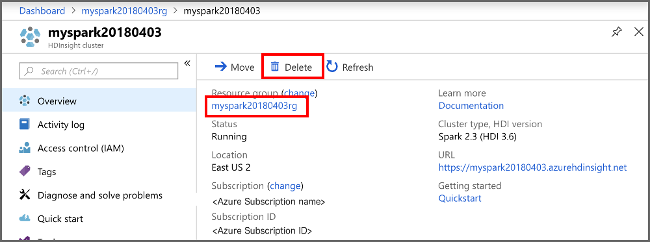 مجموعة الرؤية" الحدود = "true":::
مجموعة الرؤية" الحدود = "true":::
يمكنك أيضا تحديد اسم مجموعة الموارد لفتح صفحة مجموعة الموارد، ثم تحديد حذف مجموعة الموارد. عن طريق حذف مجموعة الموارد، يمكنك حذف كل من نظام مجموعة HDInsight وحساب التخزين الافتراضي.
الخطوات التالية
في هذا التشغيل السريع، تعلمت كيفية إنشاء مجموعة Apache Spark في HDInsight وتشغيل استعلام Spark SQL أساسي. تقدم إلى البرنامج التعليمي التالي لمعرفة كيفية استخدام مجموعة HDInsight لتشغيل الاستعلامات التفاعلية على عينة البيانات.