تدريب نموذج الانحدار باستخدام التعلم الآلي الآلي وPython (SDK v1)
ينطبق على: Python SDK azureml v1
Python SDK azureml v1
في هذه المقالة، ستتعلم كيفية تدريب نموذج انحدار باستخدام Azure التعلم الآلي Python SDK باستخدام Azure التعلم الآلي Automated ML. يتوقع نموذج الانحدار أسعار الركاب لسيارات الأجرة التي تعمل في مدينة نيويورك (NYC). يمكنك كتابة التعليمات البرمجية باستخدام Python SDK لتكوين مساحة عمل مع البيانات المعدة وتدريب النموذج محليا باستخدام معلمات مخصصة واستكشاف النتائج.
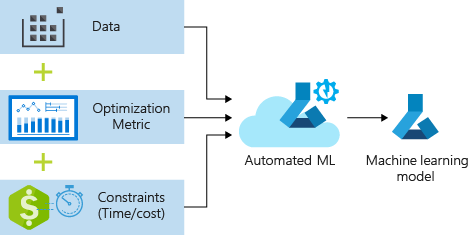
تقبل العملية بيانات التدريب وإعدادات التكوين. يتكرر تلقائيا من خلال مجموعات من أساليب تسوية الميزات/التوحيد القياسي المختلفة والنماذج وإعدادات المعلمات الفائقة للوصول إلى أفضل نموذج. يوضح الرسم التخطيطي التالي تدفق العملية لتدريب نموذج الانحدار:
المتطلبات الأساسية
اشتراك Azure. يمكنك إنشاء حساب مجاني أو مدفوع من Azure التعلم الآلي.
مساحة عمل Azure التعلم الآلي أو مثيل حساب. لإعداد هذه الموارد، راجع التشغيل السريع: بدء استخدام Azure التعلم الآلي.
احصل على بيانات العينة المعدة لتمارين البرنامج التعليمي عن طريق تحميل دفتر ملاحظات في مساحة العمل الخاصة بك:
انتقل إلى مساحة العمل في Azure التعلم الآلي studio، وحدد Notebooks، ثم حدد علامة التبويب Samples.
في قائمة دفاتر الملاحظات، قم بتوسيع عقدة Samples>SDK v1>tutorials>regression-automl-nyc-taxi-data.
حدد دفتر ملاحظات regression-automated-ml.ipynb .
لتشغيل كل خلية دفتر ملاحظات كجزء من هذا البرنامج التعليمي، حدد استنساخ هذا الملف.
النهج البديل: إذا كنت تفضل ذلك، يمكنك تشغيل تمارين البرنامج التعليمي في بيئة محلية. يتوفر البرنامج التعليمي في مستودع Azure التعلم الآلي Notebooks على GitHub. لهذا النهج، اتبع هذه الخطوات للحصول على الحزم المطلوبة:
ثبّت
automlالعميل الكامل.pip install azureml-opendatasets azureml-widgetsقم بتشغيل الأمر على جهازك المحلي للحصول على الحزم المطلوبة.
اشرع في تنزيل وإعداد البيانات.
تحتوي حزمة Open Datasets على فئة تمثل كل مصدر بيانات (مثل NycTlcGreen) لتصفية معلمات التاريخ بسهولة قبل التنزيل.
تستورد التعليمات البرمجية التالية الحزم الضرورية:
from azureml.opendatasets import NycTlcGreen
import pandas as pd
from datetime import datetime
from dateutil.relativedelta import relativedelta
الخطوة الأولى هي إنشاء إطار بيانات لبيانات سيارة الأجرة. عند العمل في بيئة غير Spark، تسمح حزمة Open Datasets بتنزيل شهر واحد فقط من البيانات في كل مرة مع فئات معينة. يساعد هذا الأسلوب على تجنب MemoryError المشكلة التي يمكن أن تحدث مع مجموعات البيانات الكبيرة.
لتنزيل بيانات سيارة الأجرة، قم بإحضار شهر واحد في كل مرة بشكل متكرر. قبل إلحاق المجموعة التالية من البيانات إلى green_taxi_df إطار البيانات، عينة عشوائيا 2000 سجل من كل شهر، ثم معاينة البيانات. يساعد هذا الأسلوب على تجنب انتفاخ إطار البيانات.
تنشئ التعليمات البرمجية التالية إطار البيانات، وإحضار البيانات، وتحميلها في إطار البيانات:
green_taxi_df = pd.DataFrame([])
start = datetime.strptime("1/1/2015","%m/%d/%Y")
end = datetime.strptime("1/31/2015","%m/%d/%Y")
for sample_month in range(12):
temp_df_green = NycTlcGreen(start + relativedelta(months=sample_month), end + relativedelta(months=sample_month)) \
.to_pandas_dataframe()
green_taxi_df = green_taxi_df.append(temp_df_green.sample(2000))
green_taxi_df.head(10)
يعرض الجدول التالي العديد من أعمدة القيم في نموذج بيانات سيارة الأجرة:
| رقم المورد | رمز lpep لتاريخ ووقت الركوب | وقت وتاريخ الوصول ورمز lpep | passengerCount | tripDistance | puLocationId | doLocationId | pickupLongitude | إحداثيات خط طول الركوب | dropoffLongitude | ... | نوع الدفع | مقدار الأجرة | extra | mtaTax | تكلفة رسوم التحسين | مقدار الإكرامية | المبلغ | ehailFee | totalAmount | tripType |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 | 2015-01-30 18:38:09 | 2015-01-30 19:01:49 | 1 | 1.88 | بلا | بلا | -73.996155 | 40.690903 | -73.964287 | ... | 1 | 15.0 | 1.0 | 0.5 | 0.3 | 4.00 | 0.0 | بلا | 20.80 | 1.0 |
| 1 | 2015-01-17 23:21:39 | 2015-01-17 23:35:16 | 1 | 2.70 | بلا | بلا | -73.978508 | 40.687984 | -73.955116 | ... | 1 | 11.5 | 0.5 | 0.5 | 0.3 | 2.55 | 0.0 | بلا | 15.35 | 1.0 |
| 2 | 2015-01-16 01:38:40 | 2015-01-16 01:52:55 | 1 | 3.54 | بلا | بلا | -73.957787 | 40.721779 | -73.963005 | ... | 1 | 13.5 | 0.5 | 0.5 | 0.3 | 2.80 | 0.0 | بلا | 17.60 | 1.0 |
| 2 | 2015-01-04 17:09:26 | 2015-01-04 17:16:12 | 1 | 1.00 | بلا | بلا | -73.919914 | 40.826023 | -73.904839 | ... | 2 | 6.5 | 0.0 | 0.5 | 0.3 | 0.00 | 0.0 | بلا | 7.30 | 1.0 |
| 1 | 2015-01-14 10:10:57 | 2015-01-14 10:33:30 | 1 | 5.10 | بلا | بلا | -73.943710 | 40.825439 | -73.982964 | ... | 1 | 18.5 | 0.0 | 0.5 | 0.3 | 3.85 | 0.0 | بلا | 23.15 | 1.0 |
| 2 | 2015-01-19 18:10:41 | 2015-01-19 18:32:20 | 1 | 7.41 | بلا | بلا | -73.940918 | 40.839714 | -73.994339 | ... | 1 | 24.0 | 0.0 | 0.5 | 0.3 | 4.80 | 0.0 | بلا | 29.60 | 1.0 |
| 2 | 2015-01-01 15:44:21 | 2015-01-01 15:50:16 | 1 | 1.03 | بلا | بلا | -73.985718 | 40.685646 | -73.996773 | ... | 1 | 6.5 | 0.0 | 0.5 | 0.3 | 1.30 | 0.0 | بلا | 8.60 | 1.0 |
| 2 | 2015-01-12 08:01:21 | 2015-01-12 08:14:52 | 5 | 2.94 | بلا | بلا | -73.939865 | 40.789822 | -73.952957 | ... | 2 | 12.5 | 0.0 | 0.5 | 0.3 | 0.00 | 0.0 | بلا | 13.30 | 1.0 |
| 1 | 2015-01-16 21:54:26 | 2015-01-16 22:12:39 | 1 | 3.00 | بلا | بلا | -73.957939 | 40.721928 | -73.926247 | ... | 1 | 14.0 | 0.5 | 0.5 | 0.3 | 2.00 | 0.0 | بلا | 17.30 | 1.0 |
| 2 | 2015-01-06 06:34:53 | 2015-01-06 06:44:23 | 1 | 2.31 | بلا | بلا | -73.943825 | 40.810257 | -73.943062 | ... | 1 | 10.0 | 0.0 | 0.5 | 0.3 | 2.00 | 0.0 | بلا | 12.80 | 1.0 |
من المفيد إزالة بعض الأعمدة التي لا تحتاجها للتدريب أو إنشاء ميزات أخرى. على سبيل المثال، يمكنك إزالة عمود lpepPickupDatetime لأن التعلم الآلي التلقائي يعالج تلقائيا الميزات المستندة إلى الوقت.
تزيل التعليمات البرمجية التالية 14 عمودا من بيانات العينة:
columns_to_remove = ["lpepDropoffDatetime", "puLocationId", "doLocationId", "extra", "mtaTax",
"improvementSurcharge", "tollsAmount", "ehailFee", "tripType", "rateCodeID",
"storeAndFwdFlag", "paymentType", "fareAmount", "tipAmount"
]
for col in columns_to_remove:
green_taxi_df.pop(col)
green_taxi_df.head(5)
باشر تنقية البيانات
الخطوة التالية هي تنظيف البيانات.
تقوم التعليمات البرمجية التالية بتشغيل الدالة describe() على إطار البيانات الجديد لإنتاج إحصائيات ملخصة لكل حقل:
green_taxi_df.describe()
يعرض الجدول التالي إحصائيات ملخصة للحولات المتبقية في بيانات العينة:
| رقم المورد | passengerCount | tripDistance | pickupLongitude | إحداثيات خط طول الركوب | dropoffLongitude | dropoffLatitude | totalAmount | |
|---|---|---|---|---|---|---|---|---|
| count | 24000.00 | 24000.00 | 24000.00 | 24000.00 | 24000.00 | 24000.00 | 24000.00 | 24000.00 |
| دني | 1.777625 | 1.373625 | 2.893981 | -73.827403 | 40.689730 | -73.819670 | 40.684436 | 14.892744 |
| الامراض المنقوله جنسيا | 0.415850 | 1.046180 | 3.072343 | 2.821767 | 1.556082 | 2.901199 | 1.599776 | 12.339749 |
| دقيقه | ١.٠٠ | 0.00 | 0.00 | -74.357101 | 0.00 | -74.342766 | 0.00 | -120.80 |
| 25% | 2.00 | 1.00 | 1.05 | -73.959175 | 40.699127 | -73.966476 | 40.699459 | 8.00 |
| 50% | 2.00 | 1.00 | 1.93 | -73.945049 | 40.746754 | -73.944221 | 40.747536 | 11.30 |
| 75% | 2.00 | 1.00 | 3.70 | -73.917089 | 40.803060 | -73.909061 | 40.791526 | 17.80 |
| max | 2.00 | 8.00 | 154.28 | 0.00 | 41.109089 | 0.00 | 40.982826 | 425.00 |
تكشف إحصائيات الملخص عن العديد من الحقول الخارجية، وهي قيم تقلل من دقة النموذج. لمعالجة هذه المشكلة، قم بتصفية حقول خط العرض/خط الطول (lat/long) بحيث تكون القيم ضمن حدود منطقة مانهاتن. يقوم هذا النهج بتصفية رحلات سيارات الأجرة الطويلة أو الرحلات التي تعتبر قيمة خارجة عن العلاقة بينهما مع ميزات أخرى.
بعد ذلك، قم بتصفية tripDistance الحقل للقيم الأكبر من الصفر ولكن أقل من 31 ميلا (مسافة الهادر بين الزوجين lat/long). تلغي هذه التقنية الرحلات الطويلة التي لها تكلفة رحلة غير متناسقة.
وأخيرا، يحتوي الحقل على totalAmount قيم سالبة لأجرة سيارات الأجرة، والتي لا معنى لها في سياق النموذج. passengerCount يحتوي الحقل أيضا على بيانات غير صحيحة حيث يكون الحد الأدنى للقيمة صفرا.
تقوم التعليمات البرمجية التالية بتصفية هذه القيم الشاذة باستخدام دالات الاستعلام. ثم تزيل التعليمات البرمجية الأعمدة القليلة الأخيرة غير الضرورية للتدريب:
final_df = green_taxi_df.query("pickupLatitude>=40.53 and pickupLatitude<=40.88")
final_df = final_df.query("pickupLongitude>=-74.09 and pickupLongitude<=-73.72")
final_df = final_df.query("tripDistance>=0.25 and tripDistance<31")
final_df = final_df.query("passengerCount>0 and totalAmount>0")
columns_to_remove_for_training = ["pickupLongitude", "pickupLatitude", "dropoffLongitude", "dropoffLatitude"]
for col in columns_to_remove_for_training:
final_df.pop(col)
الخطوة الأخيرة في هذا التسلسل هي استدعاء الدالة describe() مرة أخرى على البيانات لضمان عمل التطهير كما هو متوقع. لديك الآن مجموعة معدة ومنظفة من بيانات سيارات الأجرة والعطلات والطقس لاستخدامها في تدريب نموذج التعلم الآلي:
final_df.describe()
تكوين مساحة العمل
أنشئ كائن مساحة عمل من مساحة العمل الموجودة. تُمثل مساحة العمل فئة تقبل اشتراك Azure الخاص بك ومعلومات المورد الخاصة بك. كما أنها تنشئ موردًا سحابيًّا لمراقبة وتتبع تشغيل النموذج الخاص بك.
تستدعي التعليمات البرمجية التالية الدالة Workspace.from_config() لقراءة ملف config.json وتحميل تفاصيل المصادقة في كائن يسمى ws.
from azureml.core.workspace import Workspace
ws = Workspace.from_config()
ws يتم استخدام الكائن في بقية التعليمات البرمجية في هذا البرنامج التعليمي.
تقسيم البيانات إلى مجموعات تدريب واختبار
تقسيم البيانات إلى مجموعات تدريب واختبار باستخدام الدالة train_test_split في مكتبة scikit-learn . هذه الدالة تفصل البيانات إلى «س» (ميزات) مجموعة بيانات لتدريب النموذج، و«ص» (القيم التي سيتم التنبؤ بها) مجموعة بيانات للاختبار.
تحدد المعلمة test_sizeالنسبة المئوية للبيانات التي سيتم تخصيصها للاختبار. تعين المعلمة random_state مولدًا عشوائيًّا بحيث تكون تقسيمات اختبار التدريب حتمية.
تستدعي التعليمات البرمجية التالية الدالة train_test_split لتحميل مجموعات البيانات x وy:
from sklearn.model_selection import train_test_split
x_train, x_test = train_test_split(final_df, test_size=0.2, random_state=223)
الغرض من هذه الخطوة هو إعداد نقاط البيانات لاختبار النموذج النهائي الذي لا يستخدم لتدريب النموذج. تستخدم هذه النقاط لقياس الدقة الحقيقية. النموذج المدرب تدريبا جيدا هو النموذج الذي يمكنه إجراء تنبؤات دقيقة من البيانات غير المرئية. لديك الآن بيانات معدة للتدريب التلقائي لنموذج التعلم الآلي.
تدريب النموذج تلقائيا
لتدريب نموذج تلقائيًّا، يجب اتخاذ الخطوات التالية:
حدد إعدادات تشغيل التجربة. أرفق بيانات التدريب بالتكوين، وعدل الإعدادات التي تتحكم في عملية التدريب.
أرسل التجربة لضبط الطراز. بعد إرسال التجربة، تتكرر العملية من خلال خوارزميات التعلم الآلي المختلفة وإعدادات المعلمات الفائقة، مع الالتزام بالقيود المحددة. إنه يختار النموذج الأنسب من خلال تحسين مقياس الدقة.
تحديد إعدادات التدريب
حدد معلمة التجربة وإعدادات الطراز للتدريب. اعرض قائمة الإعداداتالكاملة. يستغرق إرسال التجربة باستخدام هذه الإعدادات الافتراضية ما يقرب من 5-20 دقيقة. لتقليل وقت التشغيل، قم بتقليل المعلمة experiment_timeout_hours .
| الخاصية | القيمة في هذا البرنامج التعليمي | الوصف |
|---|---|---|
iteration_timeout_minutes |
10 | الحد الزمني بالدقائق لكل تكرار. زد هذه القيمة لمجموعات البيانات الكبيرة التي تحتاج إلى مزيد من الوقت لكل تكرار. |
experiment_timeout_hours |
0.3 | الحد الأقصى للوقت بالساعات الذي يمكن أن تستغرقه جميع التكرارات المجمعة قبل إنهاء التجربة. |
enable_early_stopping |
صواب | ضع علامة لتمكين الإنهاء المبكر إذا لم تتحسن النتيجة على المدى القصير. |
primary_metric |
spearman_correlation | المقياس الذي تريد تحسينه. يتم اختيار النموذج الأنسب بناء على هذا المقياس. |
featurization |
auto | تسمح القيمة التلقائية للتجربة بالمعالجة المسبقة لبيانات الإدخال، بما في ذلك معالجة البيانات المفقودة، وتحويل النص إلى رقمي، وما إلى ذلك. |
verbosity |
logging.INFO | التحكم في مستوى تسجيل الدخول. |
n_cross_validations |
5 | عدد تقسيمات التحقق من الصحة المتقاطعة التي يجب إجراؤها عند عدم تحديد بيانات التحقق من الصحة. |
ترسل التعليمات البرمجية التالية التجربة:
import logging
automl_settings = {
"iteration_timeout_minutes": 10,
"experiment_timeout_hours": 0.3,
"enable_early_stopping": True,
"primary_metric": 'spearman_correlation',
"featurization": 'auto',
"verbosity": logging.INFO,
"n_cross_validations": 5
}
تتيح لك التعليمات البرمجية التالية استخدام إعدادات التدريب المحددة كمعلمة **kwargs AutoMLConfig لكائن. بالإضافة إلى ذلك، يمكنك تحديد بيانات التدريب ونوع النموذج، وهو regression في هذه الحالة.
from azureml.train.automl import AutoMLConfig
automl_config = AutoMLConfig(task='regression',
debug_log='automated_ml_errors.log',
training_data=x_train,
label_column_name="totalAmount",
**automl_settings)
إشعار
تصبح خطوات المعالجة المسبقة التلقائية ل ML (تسوية الميزات، ومعالجة البيانات المفقودة، وتحويل النص إلى رقمي، وما إلى ذلك) جزءا من النموذج الأساسي. عند استخدام النموذج للتنبؤات، يتم تطبيق نفس خطوات المعالجة المسبقة المطبقة أثناء التدريب على بيانات الإدخال تلقائيا.
تدريب نموذج الانحدار التلقائي
أنشئ كائن تجربة في مساحة العمل الخاصة بك. تعمل التجربة كحاوية لعمليات المهام الفردية الخاصة بك. مرر الكائن المحدد automl_config إلى التجربة، ثم قم بتعيين الإخراج إلى True لعرض التقدم أثناء المهمة.
بعد بدء التجربة، يتم عرض تحديثات الإخراج مباشرة أثناء تشغيل التجربة. لكل تكرار، ترى نوع النموذج ومدة التشغيل ودقة التدريب. يتتبع الحقل BEST أفضل درجة تدريب قيد التشغيل استنادا إلى نوع المقياس الخاص بك:
from azureml.core.experiment import Experiment
experiment = Experiment(ws, "Tutorial-NYCTaxi")
local_run = experiment.submit(automl_config, show_output=True)
وهذه هي المخرجات:
Running on local machine
Parent Run ID: AutoML_1766cdf7-56cf-4b28-a340-c4aeee15b12b
Current status: DatasetFeaturization. Beginning to featurize the dataset.
Current status: DatasetEvaluation. Gathering dataset statistics.
Current status: FeaturesGeneration. Generating features for the dataset.
Current status: DatasetFeaturizationCompleted. Completed featurizing the dataset.
Current status: DatasetCrossValidationSplit. Generating individually featurized CV splits.
Current status: ModelSelection. Beginning model selection.
****************************************************************************************************
ITERATION: The iteration being evaluated.
PIPELINE: A summary description of the pipeline being evaluated.
DURATION: Time taken for the current iteration.
METRIC: The result of computing score on the fitted pipeline.
BEST: The best observed score thus far.
****************************************************************************************************
ITERATION PIPELINE DURATION METRIC BEST
0 StandardScalerWrapper RandomForest 0:00:16 0.8746 0.8746
1 MinMaxScaler RandomForest 0:00:15 0.9468 0.9468
2 StandardScalerWrapper ExtremeRandomTrees 0:00:09 0.9303 0.9468
3 StandardScalerWrapper LightGBM 0:00:10 0.9424 0.9468
4 RobustScaler DecisionTree 0:00:09 0.9449 0.9468
5 StandardScalerWrapper LassoLars 0:00:09 0.9440 0.9468
6 StandardScalerWrapper LightGBM 0:00:10 0.9282 0.9468
7 StandardScalerWrapper RandomForest 0:00:12 0.8946 0.9468
8 StandardScalerWrapper LassoLars 0:00:16 0.9439 0.9468
9 MinMaxScaler ExtremeRandomTrees 0:00:35 0.9199 0.9468
10 RobustScaler ExtremeRandomTrees 0:00:19 0.9411 0.9468
11 StandardScalerWrapper ExtremeRandomTrees 0:00:13 0.9077 0.9468
12 StandardScalerWrapper LassoLars 0:00:15 0.9433 0.9468
13 MinMaxScaler ExtremeRandomTrees 0:00:14 0.9186 0.9468
14 RobustScaler RandomForest 0:00:10 0.8810 0.9468
15 StandardScalerWrapper LassoLars 0:00:55 0.9433 0.9468
16 StandardScalerWrapper ExtremeRandomTrees 0:00:13 0.9026 0.9468
17 StandardScalerWrapper RandomForest 0:00:13 0.9140 0.9468
18 VotingEnsemble 0:00:23 0.9471 0.9471
19 StackEnsemble 0:00:27 0.9463 0.9471
استكشاف النتائج
استكشف نتائج التدريب التلقائي باستخدام أداة Jupyter. تتيح لك الأداة رؤية رسم بياني وجدول لجميع تكرارات المهمة الفردية، إلى جانب مقاييس دقة التدريب وبيانات التعريف. وبالإضافة إلى ذلك، يمكنك التصفية بناءً على مقاييس دقة مختلفة عن مقياسك الأساسي باستخدام محدد القائمة المنسدلة.
تنتج التعليمات البرمجية التالية رسما بيانيا لاستكشاف النتائج:
from azureml.widgets import RunDetails
RunDetails(local_run).show()
تفاصيل التشغيل لأداة Jupyter:

مخطط الرسم البياني لعنبر واجهة المستخدم Jupyter:

استرداد أفضل نموذج
تتيح لك التعليمات البرمجية التالية تحديد أفضل نموذج من التكرارات الخاصة بك. ترجع الدالة get_output أفضل نموذج من حيث التشغيل والمواءمة لآخر عملية استدعاء ملائمة. باستخدام التحميلات الزائدة على الدالة get_output ، يمكنك استرداد أفضل نموذج تشغيل وملاءم لأي مقياس مسجل أو تكرار معين.
best_run, fitted_model = local_run.get_output()
print(best_run)
print(fitted_model)
اختبار أفضل دقة للنموذج
استخدم أفضل طراز لتشغيل التنبؤات في مجموعة بيانات الاختبار للتنبؤ بأجور سيارات الأجرة. predict تستخدم الدالة أفضل نموذج وتتنبأ بقيم y، وتكلفة الرحلة، من x_test مجموعة البيانات.
تطبع التعليمات البرمجية التالية أول 10 قيم تكلفة متوقعة y_predict من مجموعة البيانات:
y_test = x_test.pop("totalAmount")
y_predict = fitted_model.predict(x_test)
print(y_predict[:10])
احسب root mean squared error للنتائج. y_test تحويل إطار البيانات إلى قائمة ومقارنتها بالقيم المتوقعة. mean_squared_error تأخذ الدالة صفيفين من القيم وتحسب متوسط الخطأ التربيعي بينهما. أخذ الجذر التربيعي للنتيجة يعطي خطأ في وحدات المتغير «ص» نفسها؛ أي التكلفة. وهو يشير تقريبًا إلى أي مدى تعد تنبؤات أجرة سيارة الأجرة ضمن الأسعار الفعلية.
from sklearn.metrics import mean_squared_error
from math import sqrt
y_actual = y_test.values.flatten().tolist()
rmse = sqrt(mean_squared_error(y_actual, y_predict))
rmse
شغل التعليمة البرمجية التالية لحساب متوسط خطأ النسبة المئوية المطلقة (MAPE) باستخدام مجموعتَي البيانات y_actual وy_predict الكاملتَين. يحسب هذا المقياس الفرق المطلق بين كل قيمة متوقعة وقيمة فعلية، ويخصم كل الفروقات. بعد ذلك، يعبر عن هذا المجموع بنسبة مئوية من إجمالي القيم الفعلية.
sum_actuals = sum_errors = 0
for actual_val, predict_val in zip(y_actual, y_predict):
abs_error = actual_val - predict_val
if abs_error < 0:
abs_error = abs_error * -1
sum_errors = sum_errors + abs_error
sum_actuals = sum_actuals + actual_val
mean_abs_percent_error = sum_errors / sum_actuals
print("Model MAPE:")
print(mean_abs_percent_error)
print()
print("Model Accuracy:")
print(1 - mean_abs_percent_error)
وهذه هي المخرجات:
Model MAPE:
0.14353867606052823
Model Accuracy:
0.8564613239394718
من اثنَين من مقاييس دقة التنبؤ، ترى أن النموذج جيد إلى حد ما في التنبؤ بأسعار سيارات الأجرة من ميزات مجموعة البيانات، ويكون ذلك عادةً داخل +- 4.00 دولارات، وحوالي نسبة خطأ قدرها 15%.
عملية تطوير نموذج التعلم الآلي التقليدية كثيفة الموارد للغاية. يتطلب الأمر معرفة كبيرة بالمجال والاستثمار في الوقت لتشغيل ومقارنة نتائج عشرات النماذج. يعد استخدام التعلم الآلي التلقائي وسيلة رائعة لاختبار نماذج مختلفة كثيرة للسيناريو الخاص بك سريعًا.
تنظيف الموارد
إذا كنت لا تخطط للعمل على برامج تعليمية أخرى التعلم الآلي Azure، فأكمل الخطوات التالية لإزالة الموارد التي لم تعد بحاجة إليها.
عملية إيقاف الحساب
إذا كنت تستخدم حسابا، يمكنك إيقاف الجهاز الظاهري عندما لا تستخدمه وتقليل التكاليف:
انتقل إلى مساحة العمل في Azure التعلم الآلي studio، وحدد Compute.
في القائمة، حدد الحساب الذي تريد إيقافه، ثم حدد إيقاف.
عندما تكون مستعدا لاستخدام الحساب مرة أخرى، يمكنك إعادة تشغيل الجهاز الظاهري.
حذف موارد أخرى
إذا كنت لا تخطط لاستخدام الموارد التي أنشأتها في هذا البرنامج التعليمي، يمكنك حذفها وتجنب تكبد المزيد من الرسوم.
اتبع هذه الخطوات لإزالة مجموعة الموارد وجميع الموارد:
في مدخل Azure، انتقل إلى مجموعات المورد.
في القائمة، حدد مجموعة الموارد التي أنشأتها في هذا البرنامج التعليمي، ثم حدد حذف مجموعة الموارد.
في موجه التأكيد، أدخل اسم مجموعة الموارد، ثم حدد حذف.
إذا كنت تريد الاحتفاظ بمجموعة الموارد، وحذف مساحة عمل واحدة فقط، فاتبع الخطوات التالية:
في مدخل Microsoft Azure، انتقل إلى مجموعة الموارد التي تحتوي على مساحة العمل التي تريد إزالتها.
حدد مساحة العمل، وحدد خصائص، ثم حدد حذف.
الخطوة التالية
الملاحظات
قريبًا: خلال عام 2024، سنتخلص تدريجيًا من GitHub Issues بوصفها آلية إرسال ملاحظات للمحتوى ونستبدلها بنظام ملاحظات جديد. لمزيد من المعلومات، راجع https://aka.ms/ContentUserFeedback.
إرسال الملاحظات وعرضها المتعلقة بـ