البرنامج التعليمي: إنشاء مسارات التعلم الآلي للإنتاج
ينطبق على: Python SDK azure-ai-ml v2 (الحالي)
Python SDK azure-ai-ml v2 (الحالي)
إشعار
للحصول على برنامج تعليمي يستخدم SDK الإصدار 1 لإنشاء مسار، راجع البرنامج التعليمي: إنشاء مسار Azure Machine Learning لتصنيف الصور
يتمثل جوهر مسار التعلم الآلي في تقسيم مهمة التعلم الآلي الكاملة إلى سير عمل متعدد الخطوات. كل خطوة تمثل مكوناً قابلاً للإدارة يمكن تطويره وتحسينه وتكوينه وأتمتته بشكل فردي. يتم توصيل الخطوات من خلال واجهات محددة جيداً. تنسق خدمة البنية الأساسية للتعلم الآلي من Microsoft Azure تلقائياً جميع التبعيات بين خطوات البنية الأساسية. يتم توحيد فوائد استخدام البنية الأساسية لبرنامج ربط العمليات التجارية لممارسة MLOps، والتعاون الجماعي القابل للتطوير، وكفاءة التدريب وتقليل التكلفة. لمعرفة المزيد حول فوائد البنية الأساسية لبرنامج ربط العمليات التجارية، راجع ما هي البنية الأساسية لبرنامج ربط العمليات التجارية التعلم الآلي Azure.
في هذا البرنامج التعليمي، يمكنك استخدام Azure التعلم الآلي لإنشاء مشروع تعلم آلي جاهز للإنتاج، باستخدام Azure التعلم الآلي Python SDK v2.
وهذا يعني أنك ستكون قادرا على الاستفادة من Azure التعلم الآلي Python SDK من أجل:
- الحصول على مؤشر لمساحة عمل Azure التعلم الآلي
- أنشئ أصول بيانات التعلم الآلي من Microsoft Azure
- إنشاء مكونات Azure التعلم الآلي القابلة لإعادة الاستخدام
- إنشاء مسارات Azure التعلم الآلي والتحقق من صحتها وتشغيلها
أثناء هذا البرنامج التعليمي، يمكنك إنشاء مسار Azure التعلم الآلي لتدريب نموذج للتنبؤ الافتراضي للائتمان. تعالج البنية الأساسية لبرنامج ربط العمليات التجارية خطوتين:
- تحضير البيانات
- تدريب وتسجيل النموذج المدرب
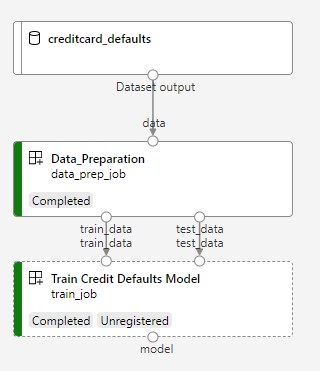
تعرض الصورة التالية مسارا بسيطا كما سترى في استوديو Azure بمجرد إرساله.
الخطوتان هما إعداد البيانات الأولى والتدريب الثاني.
يوضح هذا الفيديو كيفية البدء في Azure التعلم الآلي studio بحيث يمكنك اتباع الخطوات الواردة في البرنامج التعليمي. يوضح الفيديو كيفية إنشاء دفتر ملاحظات وإنشاء مثيل حساب واستنساخ دفتر الملاحظات. كما يتم وصف الخطوات في الأقسام التالية.
المتطلبات الأساسية
-
لاستخدام Azure التعلم الآلي، ستحتاج أولا إلى مساحة عمل. إذا لم يكن لديك واحد، فأكمل إنشاء الموارد التي تحتاجها للبدء في إنشاء مساحة عمل ومعرفة المزيد حول استخدامها.
-
سجل الدخول إلى الاستوديو وحدد مساحة العمل إذا لم تكن مفتوحة بالفعل.
أكمل البرنامج التعليمي تحميل بياناتك والوصول إليها واستكشافها لإنشاء أصل البيانات الذي تحتاجه في هذا البرنامج التعليمي. تأكد من تشغيل جميع التعليمات البرمجية لإنشاء أصل البيانات الأولي. استكشف البيانات وراجعها إذا كنت ترغب في ذلك، ولكنك ستحتاج فقط إلى البيانات الأولية في هذا البرنامج التعليمي.
-
افتح دفتر ملاحظات أو أنشئه في مساحة العمل:
- إنشاء دفتر ملاحظات جديد، إذا كنت تريد نسخ/لصق التعليمات البرمجية في الخلايا.
- أو افتح البرامج التعليمية/get-started-notebooks/pipeline.ipynb من قسم Samples في الاستوديو. ثم حدد استنساخ لإضافة دفتر الملاحظات إلى ملفاتك. (راجع مكان العثور على العينات.)
تعيين نواة
في الشريط العلوي أعلى دفتر الملاحظات المفتوح، أنشئ مثيل حساب إذا لم يكن لديك مثيل بالفعل.

إذا تم إيقاف مثيل الحساب، فحدد Start compute وانتظر حتى يتم تشغيله.

تأكد من أن النواة، الموجودة في أعلى اليمين، هي
Python 3.10 - SDK v2. إذا لم يكن الأمر كما هو، فاستخدم القائمة المنسدلة لتحديد هذا النواة.
إذا رأيت شعارا يشير إلى أنك بحاجة إلى المصادقة، فحدد المصادقة.



هام
يحتوي باقي هذا البرنامج التعليمي على خلايا دفتر ملاحظات البرنامج التعليمي. انسخها/الصقها في دفتر الملاحظات الجديد، أو قم بالتبديل إلى دفتر الملاحظات الآن إذا قمت باستنساخه.
إعداد موارد خط الأنابيب
يمكن استخدام إطار عمل Azure التعلم الآلي من CLI أو Python SDK أو واجهة الاستوديو. في هذا المثال، يمكنك استخدام Azure التعلم الآلي Python SDK v2 لإنشاء مسار.
قبل إنشاء البنية الأساسية لبرنامج ربط العمليات التجارية، تحتاج إلى الموارد التالية:
- أصل البيانات للتدريب
- بيئة البرنامج لتشغيل خط الأنابيب
- مورد حساب إلى حيث يتم تشغيل المهمة
إنشاء مقبض لمساحة العمل
قبل أن نتعمق في التعليمات البرمجية، تحتاج إلى طريقة للإشارة إلى مساحة العمل الخاصة بك. ستقوم بإنشاء ml_client مقبض لمساحة العمل. ثم ستستخدم ml_client لإدارة الموارد والوظائف.
في الخلية التالية، أدخل معرف الاشتراك واسم مجموعة الموارد واسم مساحة العمل. للعثور على هذه القيم:
- في شريط أدوات أستوديو Azure Machine Learning العلوي الأيمن، حدد اسم مساحة العمل الخاصة بك.
- انسخ قيمة مساحة العمل ومجموعة الموارد ومعرف الاشتراك في التعليمات البرمجية.
- ستحتاج إلى نسخ قيمة واحدة، وإغلاق المنطقة ولصقها، ثم العودة إلى القيمة التالية.
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
# authenticate
credential = DefaultAzureCredential()
SUBSCRIPTION="<SUBSCRIPTION_ID>"
RESOURCE_GROUP="<RESOURCE_GROUP>"
WS_NAME="<AML_WORKSPACE_NAME>"
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id=SUBSCRIPTION,
resource_group_name=RESOURCE_GROUP,
workspace_name=WS_NAME,
)
إشعار
لن يؤدي إنشاء MLClient إلى الاتصال بمساحة العمل. تهيئة العميل كسولة، ستنتظر للمرة الأولى التي يحتاج فيها إلى إجراء مكالمة (سيحدث هذا في خلية التعليمات البرمجية التالية).
تحقق من الاتصال عن طريق إجراء استدعاء إلى ml_client. نظرا لأن هذه هي المرة الأولى التي تجري فيها مكالمة إلى مساحة العمل، فقد يطلب منك المصادقة.
# Verify that the handle works correctly.
# If you ge an error here, modify your SUBSCRIPTION, RESOURCE_GROUP, and WS_NAME in the previous cell.
ws = ml_client.workspaces.get(WS_NAME)
print(ws.location,":", ws.resource_group)
الوصول إلى أصل البيانات المسجلة
ابدأ بالحصول على البيانات التي قمت بتسجيلها مسبقا في البرنامج التعليمي: تحميل بياناتك والوصول إليها واستكشافها في Azure التعلم الآلي.
- يستخدم Azure التعلم الآلي كائن
Dataلتسجيل تعريف قابل لإعادة الاستخدام للبيانات، واستهلاك البيانات داخل البنية الأساسية لبرنامج ربط العمليات التجارية.
# get a handle of the data asset and print the URI
credit_data = ml_client.data.get(name="credit-card", version="initial")
print(f"Data asset URI: {credit_data.path}")
إنشاء بيئة عمل لخطوات خطوط الأنابيب
حتى الآن، قمت بإنشاء بيئة تطوير على مثيل الحساب، آلة التطوير الخاصة بك. تحتاج أيضا إلى بيئة لاستخدامها لكل خطوة من خطوات المسار. يمكن أن يكون لكل خطوة بيئتها الخاصة، أو يمكنك استخدام بعض البيئات الشائعة لخطوات متعددة.
في هذا المثال، يمكنك إنشاء بيئة conda لوظائفك، باستخدام ملف conda yaml. أولاً، أنشئ دليلاً لتخزين الملف فيه.
import os
dependencies_dir = "./dependencies"
os.makedirs(dependencies_dir, exist_ok=True)
الآن، قم بإنشاء الملف في دليل التبعيات.
%%writefile {dependencies_dir}/conda.yaml
name: model-env
channels:
- conda-forge
dependencies:
- python=3.8
- numpy=1.21.2
- pip=21.2.4
- scikit-learn=0.24.2
- scipy=1.7.1
- pandas>=1.1,<1.2
- pip:
- inference-schema[numpy-support]==1.3.0
- xlrd==2.0.1
- mlflow== 2.4.1
- azureml-mlflow==1.51.0
تحتوي المواصفات على بعض الحزم المعتادة، التي تستخدمها في البنية الأساسية لبرنامج ربط العمليات التجارية الخاصة بك (numpy، pip)، جنبا إلى جنب مع بعض Azure التعلم الآلي حزم معينة (azureml-mlflow).
حزم التعلم الآلي Azure ليست إلزامية لتشغيل وظائف Azure التعلم الآلي. ومع ذلك، تتيح لك إضافة هذه الحزم التفاعل مع Azure التعلم الآلي لتسجيل المقاييس وتسجيل النماذج، كل ذلك داخل مهمة Azure التعلم الآلي. يمكنك استخدامها في البرنامج النصي للتدريب لاحقا في هذا البرنامج التعليمي.
استخدم ملف yaml لإنشاء هذه البيئة المخصصة وتسجيلها في مساحة العمل الخاصة بك:
from azure.ai.ml.entities import Environment
custom_env_name = "aml-scikit-learn"
pipeline_job_env = Environment(
name=custom_env_name,
description="Custom environment for Credit Card Defaults pipeline",
tags={"scikit-learn": "0.24.2"},
conda_file=os.path.join(dependencies_dir, "conda.yaml"),
image="mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest",
version="0.2.0",
)
pipeline_job_env = ml_client.environments.create_or_update(pipeline_job_env)
print(
f"Environment with name {pipeline_job_env.name} is registered to workspace, the environment version is {pipeline_job_env.version}"
)
بناء خط أنابيب التدريب
الآن بعد أن أصبح لديك جميع الأصول المطلوبة لتشغيل البنية الأساسية لبرنامج ربط العمليات التجارية الخاصة بك، فقد حان الوقت لبناء البنية الأساسية لبرنامج ربط العمليات التجارية نفسها.
مسارات Azure التعلم الآلي هي مهام سير عمل التعلم الآلي القابلة لإعادة الاستخدام التي تتكون عادة من عدة مكونات. الحياة النموذجية للمكون هي:
- اكتب مواصفات yaml للمكون، أو قم بإنشائها برمجيا باستخدام
ComponentMethod. - اختيارياً، قم بتسجيل المكون باسم وإصدار في مساحة العمل الخاصة بك، لجعله قابلاً لإعادة الاستخدام وقابلاً للمشاركة.
- قم بتحميل هذا المكون من التعليمة البرمجية لخط الأنابيب.
- تنفيذ البنية الأساسية لبرنامج ربط العمليات التجارية باستخدام مدخلات المكون ومخرجاته ومعلماته.
- إرسال البنية الأساسية.
هناك طريقتان لإنشاء مكون، تعريف برمجي و yaml. يرشدك القسمان التاليان خلال إنشاء مكون في كلا الاتجاهين. يمكنك إما إنشاء المكونين بتجربة كلا الخيارين أو اختيار الأسلوب المفضل لديك.
إشعار
في هذا البرنامج التعليمي للتبسيط نستخدم نفس الحساب لجميع المكونات. ومع ذلك، يمكنك تعيين حسابات مختلفة لكل مكون، على سبيل المثال عن طريق إضافة سطر مثل train_step.compute = "cpu-cluster". لعرض مثال على إنشاء مسار بحسابات مختلفة لكل مكون، راجع قسم مهمة البنية الأساسية لبرنامج ربط العمليات التجارية في البرنامج التعليمي cifar-10 pipeline.
إنشاء المكون 1: إعداد البيانات (باستخدام التعريف البرنامجي)
لنبدأ بإنشاء المكون الأول. يعالج هذا المكون المعالجة المسبقة للبيانات. يتم تنفيذ مهمة المعالجة المسبقة في ملف data_prep.py Python.
قم أولاً بإنشاء مجلد مصدر لمكون data_prep:
import os
data_prep_src_dir = "./components/data_prep"
os.makedirs(data_prep_src_dir, exist_ok=True)
ينفذ هذا البرنامج النصي المهمة البسيطة المتمثلة في تقسيم البيانات إلى مجموعات بيانات القطار والاختبار. يقوم Azure التعلم الآلي بتحميل مجموعات البيانات كمجلدات إلى الحسابات، لذلك، أنشأنا دالة select_first_file مساعدة للوصول إلى ملف البيانات داخل مجلد الإدخال المحمل.
يتم استخدام MLFlow لتسجيل المعلمات والمقاييس أثناء تشغيل البنية الأساسية لبرنامج ربط العمليات التجارية.
%%writefile {data_prep_src_dir}/data_prep.py
import os
import argparse
import pandas as pd
from sklearn.model_selection import train_test_split
import logging
import mlflow
def main():
"""Main function of the script."""
# input and output arguments
parser = argparse.ArgumentParser()
parser.add_argument("--data", type=str, help="path to input data")
parser.add_argument("--test_train_ratio", type=float, required=False, default=0.25)
parser.add_argument("--train_data", type=str, help="path to train data")
parser.add_argument("--test_data", type=str, help="path to test data")
args = parser.parse_args()
# Start Logging
mlflow.start_run()
print(" ".join(f"{k}={v}" for k, v in vars(args).items()))
print("input data:", args.data)
credit_df = pd.read_csv(args.data, header=1, index_col=0)
mlflow.log_metric("num_samples", credit_df.shape[0])
mlflow.log_metric("num_features", credit_df.shape[1] - 1)
credit_train_df, credit_test_df = train_test_split(
credit_df,
test_size=args.test_train_ratio,
)
# output paths are mounted as folder, therefore, we are adding a filename to the path
credit_train_df.to_csv(os.path.join(args.train_data, "data.csv"), index=False)
credit_test_df.to_csv(os.path.join(args.test_data, "data.csv"), index=False)
# Stop Logging
mlflow.end_run()
if __name__ == "__main__":
main()
الآن بعد أن أصبح لديك برنامج نصي يمكنه تنفيذ المهمة المطلوبة، قم بإنشاء مكون Azure التعلم الآلي منه.
استخدم الغرض CommandComponent العام الذي يمكنه تشغيل إجراءات سطر الأوامر. يمكن لإجراء سطر الأوامر هذا استدعاء أوامر النظام أو تشغيل برنامج نصي. يتم تحديد المدخلات/المخرجات في سطر الأوامر عبر تدوين ${{ ... }}.
from azure.ai.ml import command
from azure.ai.ml import Input, Output
data_prep_component = command(
name="data_prep_credit_defaults",
display_name="Data preparation for training",
description="reads a .xl input, split the input to train and test",
inputs={
"data": Input(type="uri_folder"),
"test_train_ratio": Input(type="number"),
},
outputs=dict(
train_data=Output(type="uri_folder", mode="rw_mount"),
test_data=Output(type="uri_folder", mode="rw_mount"),
),
# The source folder of the component
code=data_prep_src_dir,
command="""python data_prep.py \
--data ${{inputs.data}} --test_train_ratio ${{inputs.test_train_ratio}} \
--train_data ${{outputs.train_data}} --test_data ${{outputs.test_data}} \
""",
environment=f"{pipeline_job_env.name}:{pipeline_job_env.version}",
)
اختياريا، قم بتسجيل المكون في مساحة العمل لإعادة استخدامها في المستقبل.
# Now we register the component to the workspace
data_prep_component = ml_client.create_or_update(data_prep_component.component)
# Create (register) the component in your workspace
print(
f"Component {data_prep_component.name} with Version {data_prep_component.version} is registered"
)
إنشاء المكون 2: التدريب (باستخدام تعريف yaml)
يستهلك المكون الثاني الذي تقوم بإنشائه بيانات التدريب والاختبار، وتدريب نموذج يستند إلى شجرة وإرجاع نموذج الإخراج. استخدم قدرات تسجيل Azure التعلم الآلي لتسجيل تقدم التعلم وتصوره.
لقد استخدمت الفئة CommandComponent لإنشاء المكون الأول الخاص بك. هذه المرة يمكنك استخدام تعريف yaml لتعريف المكون الثاني. كل طريقة لها مزاياها الخاصة. يمكن بالفعل التحقق من تعريف yaml على طول التعليمة البرمجية، وسيوفر تتبع المحفوظات القابل للقراءة. يمكن أن تكون الطريقة البرمجية باستخدام CommandComponent أسهل مع وثائق الفصل المضمنة وإكمال التعليمات البرمجية.
قم بإنشاء دليل لهذا المكون:
import os
train_src_dir = "./components/train"
os.makedirs(train_src_dir, exist_ok=True)
قم بإنشاء برنامج نصي للتدريب في الدليل:
%%writefile {train_src_dir}/train.py
import argparse
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import classification_report
import os
import pandas as pd
import mlflow
def select_first_file(path):
"""Selects first file in folder, use under assumption there is only one file in folder
Args:
path (str): path to directory or file to choose
Returns:
str: full path of selected file
"""
files = os.listdir(path)
return os.path.join(path, files[0])
# Start Logging
mlflow.start_run()
# enable autologging
mlflow.sklearn.autolog()
os.makedirs("./outputs", exist_ok=True)
def main():
"""Main function of the script."""
# input and output arguments
parser = argparse.ArgumentParser()
parser.add_argument("--train_data", type=str, help="path to train data")
parser.add_argument("--test_data", type=str, help="path to test data")
parser.add_argument("--n_estimators", required=False, default=100, type=int)
parser.add_argument("--learning_rate", required=False, default=0.1, type=float)
parser.add_argument("--registered_model_name", type=str, help="model name")
parser.add_argument("--model", type=str, help="path to model file")
args = parser.parse_args()
# paths are mounted as folder, therefore, we are selecting the file from folder
train_df = pd.read_csv(select_first_file(args.train_data))
# Extracting the label column
y_train = train_df.pop("default payment next month")
# convert the dataframe values to array
X_train = train_df.values
# paths are mounted as folder, therefore, we are selecting the file from folder
test_df = pd.read_csv(select_first_file(args.test_data))
# Extracting the label column
y_test = test_df.pop("default payment next month")
# convert the dataframe values to array
X_test = test_df.values
print(f"Training with data of shape {X_train.shape}")
clf = GradientBoostingClassifier(
n_estimators=args.n_estimators, learning_rate=args.learning_rate
)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(classification_report(y_test, y_pred))
# Registering the model to the workspace
print("Registering the model via MLFlow")
mlflow.sklearn.log_model(
sk_model=clf,
registered_model_name=args.registered_model_name,
artifact_path=args.registered_model_name,
)
# Saving the model to a file
mlflow.sklearn.save_model(
sk_model=clf,
path=os.path.join(args.model, "trained_model"),
)
# Stop Logging
mlflow.end_run()
if __name__ == "__main__":
main()
كما ترى في هذا البرنامج النصي التدريبي، بمجرد تدريب النموذج، يتم حفظ ملف النموذج وتسجيله في مساحة العمل. يمكنك الآن استخدام النموذج المسجل في استنتاج نقاط النهاية.
بالنسبة لبيئة هذه الخطوة، يمكنك استخدام إحدى بيئات Azure التعلم الآلي المضمنة (المنسقة). تخبر العلامة azureml النظام باستخدام البحث عن الاسم في بيئات منظمة.
أولاً، قم بإنشاء ملف yaml الذي يصف المكون:
%%writefile {train_src_dir}/train.yml
# <component>
name: train_credit_defaults_model
display_name: Train Credit Defaults Model
# version: 1 # Not specifying a version will automatically update the version
type: command
inputs:
train_data:
type: uri_folder
test_data:
type: uri_folder
learning_rate:
type: number
registered_model_name:
type: string
outputs:
model:
type: uri_folder
code: .
environment:
# for this step, we'll use an AzureML curate environment
azureml:AzureML-sklearn-1.0-ubuntu20.04-py38-cpu:1
command: >-
python train.py
--train_data ${{inputs.train_data}}
--test_data ${{inputs.test_data}}
--learning_rate ${{inputs.learning_rate}}
--registered_model_name ${{inputs.registered_model_name}}
--model ${{outputs.model}}
# </component>
الآن قم بإنشاء المكون وتسجيله. يسمح لك تسجيله بإعادة استخدامه في البنية الأساسية لبرنامج ربط العمليات التجارية الأخرى. أيضا، يمكن لأي شخص آخر لديه حق الوصول إلى مساحة العمل الخاصة بك استخدام المكون المسجل.
# importing the Component Package
from azure.ai.ml import load_component
# Loading the component from the yml file
train_component = load_component(source=os.path.join(train_src_dir, "train.yml"))
# Now we register the component to the workspace
train_component = ml_client.create_or_update(train_component)
# Create (register) the component in your workspace
print(
f"Component {train_component.name} with Version {train_component.version} is registered"
)
إنشاء خط الأنابيب من المكونات
الآن بعد أن تم تحديد كلا المكونين وتسجيلهما، يمكنك البدء في تنفيذ خط الأنابيب.
هنا، يمكنك استخدام بيانات الإدخال ونسبة التقسيم واسم النموذج المسجل كمتغيرات إدخال. ثم اتصل بالمكونات وقم بتوصيلها عبر معرفات المدخلات/المخرجات الخاصة بها. يمكن الوصول إلى مخرجات كل خطوة عبر خاصية .outputs.
يتم إرجاع دالات Python بواسطة العمل كأي دالة Python عادية نستخدمها load_component() داخل البنية الأساسية لبرنامج ربط العمليات التجارية لاستدعاء كل خطوة.
للتعليمات البرمجية للبنية الأساسية لبرنامج ربط العمليات التجارية، يمكنك استخدام مصمم معين @dsl.pipeline يحدد البنية الأساسية لبرنامج ربط العمليات التجارية التعلم الآلي Azure. في المصمم، يمكننا تحديد وصف خط الأنابيب والموارد الظاهرية مثل الحساب والتخزين. مثل دالة Python، يمكن أن يكون للبنية الأساسية لبرنامج ربط العمليات التجارية مدخلات. يمكنك بعد ذلك إنشاء مثيلات متعددة لخط أنابيب واحد بمدخلات مختلفة.
هنا، استخدمنا بيانات الإدخال ونسبة الانقسام واسم النموذج المسجل كمتغيرات إدخال. ثم نقوم باستدعاء المكونات وربطها عبر معرفات المدخلات/المخرجات. يمكن الوصول إلى مخرجات كل خطوة عبر خاصية .outputs.
# the dsl decorator tells the sdk that we are defining an Azure Machine Learning pipeline
from azure.ai.ml import dsl, Input, Output
@dsl.pipeline(
compute="serverless", # "serverless" value runs pipeline on serverless compute
description="E2E data_perp-train pipeline",
)
def credit_defaults_pipeline(
pipeline_job_data_input,
pipeline_job_test_train_ratio,
pipeline_job_learning_rate,
pipeline_job_registered_model_name,
):
# using data_prep_function like a python call with its own inputs
data_prep_job = data_prep_component(
data=pipeline_job_data_input,
test_train_ratio=pipeline_job_test_train_ratio,
)
# using train_func like a python call with its own inputs
train_job = train_component(
train_data=data_prep_job.outputs.train_data, # note: using outputs from previous step
test_data=data_prep_job.outputs.test_data, # note: using outputs from previous step
learning_rate=pipeline_job_learning_rate, # note: using a pipeline input as parameter
registered_model_name=pipeline_job_registered_model_name,
)
# a pipeline returns a dictionary of outputs
# keys will code for the pipeline output identifier
return {
"pipeline_job_train_data": data_prep_job.outputs.train_data,
"pipeline_job_test_data": data_prep_job.outputs.test_data,
}
استخدم الآن تعريف خط الأنابيب الخاص بك لإنشاء مثيل لخط أنابيب مع مجموعة البيانات الخاصة بك ومعدل تقسيم الاختيار والاسم الذي اخترته لنموذجك.
registered_model_name = "credit_defaults_model"
# Let's instantiate the pipeline with the parameters of our choice
pipeline = credit_defaults_pipeline(
pipeline_job_data_input=Input(type="uri_file", path=credit_data.path),
pipeline_job_test_train_ratio=0.25,
pipeline_job_learning_rate=0.05,
pipeline_job_registered_model_name=registered_model_name,
)
إرسال المهمة
حان الوقت الآن لإرسال المهمة للتشغيل في Azure التعلم الآلي. هذه المرة تستخدم create_or_update على ml_client.jobs.
هنا يمكنك أيضا تمرير اسم التجربة. التجربة عبارة عن حاوية لجميع التكرارات التي يقوم بها المرء في مشروع معين. سيتم سرد جميع المهام المرسلة تحت نفس اسم التجربة بجوار بعضها البعض في Azure التعلم الآلي studio.
بمجرد الانتهاء، يسجل المسار نموذجا في مساحة العمل الخاصة بك نتيجة للتدريب.
# submit the pipeline job
pipeline_job = ml_client.jobs.create_or_update(
pipeline,
# Project's name
experiment_name="e2e_registered_components",
)
ml_client.jobs.stream(pipeline_job.name)
يمكنك تعقب تقدم البنية الأساسية لبرنامج ربط العمليات التجارية باستخدام الارتباط الذي تم إنشاؤه في الخلية السابقة. عند تحديد هذا الارتباط لأول مرة، قد ترى أن البنية الأساسية لبرنامج ربط العمليات التجارية لا تزال قيد التشغيل. بمجرد اكتماله، يمكنك فحص نتائج كل مكون.
انقر نقرا مزدوجا فوق مكون نموذج Train Credit Defaults.
هناك نتيجتان مهمتان سترغبان في رؤيتها حول التدريب:
عرض سجلاتك:
- حدد علامة التبويب Outputs+logs.
- افتح المجلدات إلى
user_logs>std_log.txtيعرض هذا القسم stdout تشغيل البرنامج النصي.
عرض المقاييس: حدد علامة التبويب Metrics . يعرض هذا القسم مقاييس مسجلة مختلفة. في هذا المثال. mlflow
autologging، قام بتسجيل مقاييس التدريب تلقائياً.


نشر النموذج كنقطة نهاية عبر الإنترنت
لمعرفة كيفية نشر النموذج الخاص بك إلى نقطة نهاية عبر الإنترنت، راجع نشر نموذج كبرنامج تعليمي لنقطة نهاية عبر الإنترنت.
تنظيف الموارد
إذا كنت تخطط للمتابعة الآن إلى البرامج التعليمية الأخرى، فانتقل إلى الخطوات التالية.
إيقاف حساب مثيل
إذا كنت لن تستخدمه الآن، فأوقف مثيل الحساب:
- في الاستوديو، في منطقة التنقل اليسرى، حدد Compute.
- في علامات التبويب العليا، حدد "Compute instances"
- حدد "compute instance" في القائمة.
- في شريط الأدوات العلوي، حدد "Stop".
حذف كافة الموارد
هام
يمكن استخدام الموارد التي قمت بإنشائها كمتطلبات أساسية لبرامج تعليمية أخرى في Azure ومقالات إرشادية.
إذا كنت لا تخطط لاستخدام الموارد التي أنشأتها، فاحذفها، حتى لا تتحمل أي رسوم:
من مدخل Microsoft Azure، حدد Resource groups من أقصى الجانب الأيمن.
من القائمة، حدد مجموعة الموارد التي أنشأتها.
حدد Delete resource group.
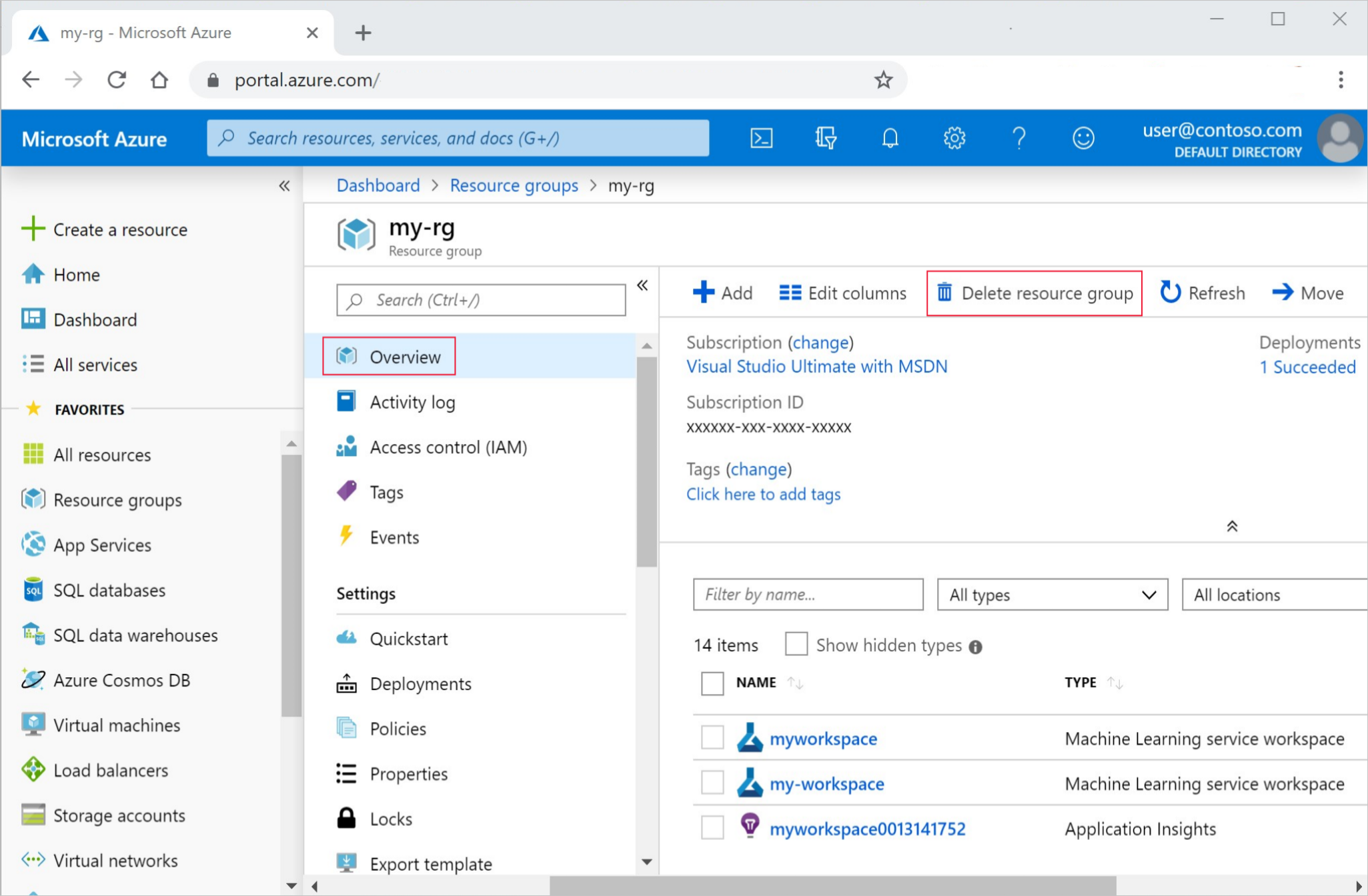
أدخل اسم مجموعة الموارد. ثم حدد حذف.
الخطوات التالية
تعرف على كيفية جدولة مهام مسار التعلم الآلي