Quickstart: ابدأ الأمر باستخدام التعلم الآلي من Microsoft Azure
ينطبق على: Python SDK azure-ai-ml v2 (الحالي)
Python SDK azure-ai-ml v2 (الحالي)
هذا البرنامج التعليمي هو مقدمة لبعض الميزات الأكثر استخداما لخدمة Azure التعلم الآلي. في ذلك، ستقوم بإنشاء نموذج وتسجيله ونشره. سيساعدك هذا البرنامج التعليمي على التعرف على المفاهيم الأساسية ل Azure التعلم الآلي واستخدامها الأكثر شيوعا.
ستتعلم كيفية تشغيل مهمة تدريب على مورد حساب قابل للتطوير، ثم توزيعه، وأخيرا اختبار التوزيع.
ستقوم بإنشاء برنامج نصي للتدريب للتعامل مع إعداد البيانات وتدريب نموذج وتسجيله. بمجرد تدريب النموذج، ستقوم بنشره كنقطة نهاية، ثم استدعاء نقطة النهاية للاستدلال.
الخطوات التي ستتخذها هي:
- إعداد مقبض لمساحة عمل Azure التعلم الآلي
- إنشاء البرنامج النصي للتدريب الخاص بك
- إنشاء مورد حساب قابل للتطوير، نظام مجموعة حساب
- إنشاء وتشغيل مهمة أمر من شأنها تشغيل البرنامج النصي للتدريب على مجموعة الحوسبة، التي تم تكوينها مع بيئة الوظيفة المناسبة
- عرض إخراج البرنامج النصي للتدريب الخاص بك
- نشر النموذج الذي تم تدريبه حديثاً كنقطة نهاية
- استدعاء نقطة نهاية Azure التعلم الآلي للاستدلال
شاهد هذا الفيديو للحصول على نظرة عامة حول الخطوات الواردة في هذا التشغيل السريع.
المتطلبات الأساسية
-
لاستخدام Azure التعلم الآلي، ستحتاج أولا إلى مساحة عمل. إذا لم يكن لديك واحد، فأكمل إنشاء الموارد التي تحتاجها للبدء في إنشاء مساحة عمل ومعرفة المزيد حول استخدامها.
-
سجل الدخول إلى الاستوديو وحدد مساحة العمل إذا لم تكن مفتوحة بالفعل.
-
افتح دفتر ملاحظات أو أنشئه في مساحة العمل:
- إنشاء دفتر ملاحظات جديد، إذا كنت تريد نسخ/لصق التعليمات البرمجية في الخلايا.
- أو افتح البرامج التعليمية/get-started-notebooks/quickstart.ipynb من قسم Samples في studio. ثم حدد استنساخ لإضافة دفتر الملاحظات إلى ملفاتك. (راجع مكان العثور على العينات.)
تعيين نواة
في الشريط العلوي أعلى دفتر الملاحظات المفتوح، أنشئ مثيل حساب إذا لم يكن لديك مثيل بالفعل.

إذا تم إيقاف مثيل الحساب، فحدد Start compute وانتظر حتى يتم تشغيله.

تأكد من أن النواة، الموجودة في أعلى اليمين، هي
Python 3.10 - SDK v2. إذا لم يكن الأمر كما هو، فاستخدم القائمة المنسدلة لتحديد هذا النواة.
إذا رأيت شعارا يشير إلى أنك بحاجة إلى المصادقة، فحدد المصادقة.



هام
يحتوي باقي هذا البرنامج التعليمي على خلايا دفتر ملاحظات البرنامج التعليمي. انسخها/الصقها في دفتر الملاحظات الجديد، أو قم بالتبديل إلى دفتر الملاحظات الآن إذا قمت باستنساخه.
إنشاء مقبض لمساحة العمل
قبل أن نتعمق في التعليمات البرمجية، تحتاج إلى طريقة للإشارة إلى مساحة العمل الخاصة بك. مساحة العمل هي المورد ذو المستوى الأعلى للتعلم الآلي من Microsoft Azure، حيث توفر مكانًا مركزيًا للعمل مع جميع البيانات الاصطناعية التي تنشئها عند استخدام التعلم الآلي من Microsoft Azure.
ستقوم بإنشاء ml_client مقبض لمساحة العمل. ثم ستستخدم ml_client لإدارة الموارد والوظائف.
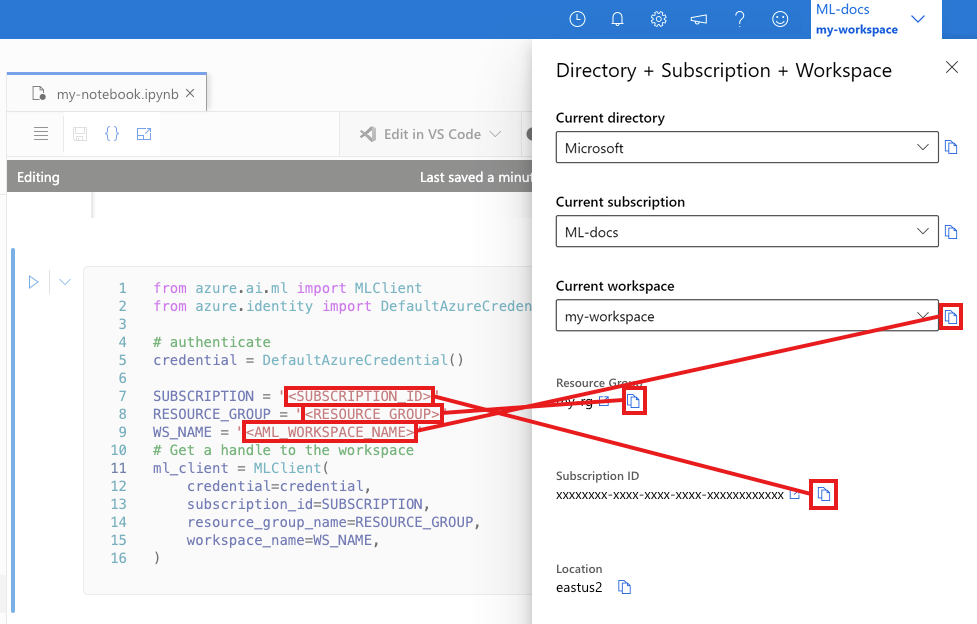
في الخلية التالية، أدخل معرف الاشتراك واسم مجموعة الموارد واسم مساحة العمل. للعثور على هذه القيم:
- في شريط أدوات أستوديو Azure Machine Learning العلوي الأيمن، حدد اسم مساحة العمل الخاصة بك.
- انسخ قيمة مساحة العمل ومجموعة الموارد ومعرف الاشتراك في التعليمات البرمجية.
- ستحتاج إلى نسخ قيمة واحدة، وإغلاق المنطقة ولصقها، ثم العودة إلى القيمة التالية.
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
# authenticate
credential = DefaultAzureCredential()
SUBSCRIPTION="<SUBSCRIPTION_ID>"
RESOURCE_GROUP="<RESOURCE_GROUP>"
WS_NAME="<AML_WORKSPACE_NAME>"
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id=SUBSCRIPTION,
resource_group_name=RESOURCE_GROUP,
workspace_name=WS_NAME,
)
إشعار
لن يؤدي إنشاء MLClient إلى الاتصال بمساحة العمل. تهيئة العميل كسولة، ستنتظر للمرة الأولى التي يحتاج فيها إلى إجراء مكالمة (سيحدث هذا في خلية التعليمات البرمجية التالية).
# Verify that the handle works correctly.
# If you ge an error here, modify your SUBSCRIPTION, RESOURCE_GROUP, and WS_NAME in the previous cell.
ws = ml_client.workspaces.get(WS_NAME)
print(ws.location,":", ws.resource_group)
إنشاء برنامج نصي للتدريب
لنبدأ بإنشاء البرنامج النصي للتدريب - ملف main.py Python.
قم أولا بإنشاء مجلد مصدر للبرنامج النصي:
import os
train_src_dir = "./src"
os.makedirs(train_src_dir, exist_ok=True)
يعالج هذا البرنامج النصي المعالجة المسبقة للبيانات، وتقسيمها إلى بيانات اختبار وتدريب. ثم يستهلك هذه البيانات لتدريب نموذج يستند إلى شجرة وإرجاع نموذج الإخراج.
سيتم استخدام MLFlow لتسجيل المعلمات والمقاييس أثناء تشغيل خط الأنابيب.
تستخدم الخلية أدناه سحر IPython لكتابة البرنامج النصي للتدريب في الدليل الذي أنشأته للتو.
%%writefile {train_src_dir}/main.py
import os
import argparse
import pandas as pd
import mlflow
import mlflow.sklearn
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import classification_report
from sklearn.model_selection import train_test_split
def main():
"""Main function of the script."""
# input and output arguments
parser = argparse.ArgumentParser()
parser.add_argument("--data", type=str, help="path to input data")
parser.add_argument("--test_train_ratio", type=float, required=False, default=0.25)
parser.add_argument("--n_estimators", required=False, default=100, type=int)
parser.add_argument("--learning_rate", required=False, default=0.1, type=float)
parser.add_argument("--registered_model_name", type=str, help="model name")
args = parser.parse_args()
# Start Logging
mlflow.start_run()
# enable autologging
mlflow.sklearn.autolog()
###################
#<prepare the data>
###################
print(" ".join(f"{k}={v}" for k, v in vars(args).items()))
print("input data:", args.data)
credit_df = pd.read_csv(args.data, header=1, index_col=0)
mlflow.log_metric("num_samples", credit_df.shape[0])
mlflow.log_metric("num_features", credit_df.shape[1] - 1)
train_df, test_df = train_test_split(
credit_df,
test_size=args.test_train_ratio,
)
####################
#</prepare the data>
####################
##################
#<train the model>
##################
# Extracting the label column
y_train = train_df.pop("default payment next month")
# convert the dataframe values to array
X_train = train_df.values
# Extracting the label column
y_test = test_df.pop("default payment next month")
# convert the dataframe values to array
X_test = test_df.values
print(f"Training with data of shape {X_train.shape}")
clf = GradientBoostingClassifier(
n_estimators=args.n_estimators, learning_rate=args.learning_rate
)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(classification_report(y_test, y_pred))
###################
#</train the model>
###################
##########################
#<save and register model>
##########################
# Registering the model to the workspace
print("Registering the model via MLFlow")
mlflow.sklearn.log_model(
sk_model=clf,
registered_model_name=args.registered_model_name,
artifact_path=args.registered_model_name,
)
# Saving the model to a file
mlflow.sklearn.save_model(
sk_model=clf,
path=os.path.join(args.registered_model_name, "trained_model"),
)
###########################
#</save and register model>
###########################
# Stop Logging
mlflow.end_run()
if __name__ == "__main__":
main()
كما ترى في هذا البرنامج النصي، بمجرد تدريب النموذج، يتم حفظ ملف النموذج وتسجيله في مساحة العمل. يمكنك الآن استخدام النموذج المسجل في استنتاج نقاط النهاية.
قد تحتاج إلى تحديد تحديث لمشاهدة المجلد الجديد والبرنامج النصي في ملفاتك.
تكوين الأمر
الآن بعد أن أصبح لديك برنامج نصي يمكنه تنفيذ المهام المطلوبة، والمجموعة الحسابية لتشغيل البرنامج النصي، ستستخدم أمر الغرض العام الذي يمكنه تشغيل إجراءات سطر الأوامر. يمكن لإجراء سطر الأوامر هذا استدعاء أوامر النظام أو تشغيل برنامج نصي.
هنا، ستقوم بإنشاء متغيرات الإدخال لتحديد بيانات الإدخال ونسبة التقسيم ومعدل التعلم واسم النموذج المسجل. سيقوم البرنامج النصي للأمر ب:
- استخدم بيئة تحدد البرامج ومكتبات وقت التشغيل المطلوبة للبرنامج النصي للتدريب. يوفر Azure التعلم الآلي العديد من البيئات المنسقة أو الجاهزة، والتي تعد مفيدة لسيناريوهات التدريب والاستدلال الشائعة. ستستخدم إحدى هذه البيئات هنا. في البرنامج التعليمي: تدريب نموذج في Azure التعلم الآلي، ستتعلم كيفية إنشاء بيئة مخصصة.
- تكوين إجراء سطر الأوامر نفسه -
python main.pyفي هذه الحالة. يمكن الوصول إلى المدخلات/المخرجات في الأمر عبر التعليمة البرمجية${{ ... }}. - في هذه العينة، نقوم بالوصول إلى البيانات من ملف على الإنترنت.
- نظرا لعدم تحديد مورد حساب، سيتم تشغيل البرنامج النصي على نظام مجموعة حساب بلا خادم يتم إنشاؤه تلقائيا.
from azure.ai.ml import command
from azure.ai.ml import Input
registered_model_name = "credit_defaults_model"
job = command(
inputs=dict(
data=Input(
type="uri_file",
path="https://azuremlexamples.blob.core.windows.net/datasets/credit_card/default_of_credit_card_clients.csv",
),
test_train_ratio=0.2,
learning_rate=0.25,
registered_model_name=registered_model_name,
),
code="./src/", # location of source code
command="python main.py --data ${{inputs.data}} --test_train_ratio ${{inputs.test_train_ratio}} --learning_rate ${{inputs.learning_rate}} --registered_model_name ${{inputs.registered_model_name}}",
environment="AzureML-sklearn-1.0-ubuntu20.04-py38-cpu@latest",
display_name="credit_default_prediction",
)
إرسال المهمة
حان الوقت الآن لإرسال المهمة للتشغيل في Azure التعلم الآلي. هذه المرة سوف تستخدم create_or_update في ml_client.
ml_client.create_or_update(job)
عرض إخراج الوظيفة وانتظار إكمال المهمة
عرض المهمة في Azure التعلم الآلي studio عن طريق تحديد الارتباط في إخراج الخلية السابقة.
سيبدو إخراج هذه المهمة مثل هذا في استوديو Azure التعلم الآلي. استكشف علامات التبويب للحصول على تفاصيل مختلفة مثل المقاييس والمخرجات وما إلى ذلك. بمجرد الانتهاء، ستسجل الوظيفة نموذجا في مساحة العمل الخاصة بك نتيجة للتدريب.
هام
انتظر حتى تكتمل حالة المهمة قبل العودة إلى دفتر الملاحظات هذا للمتابعة. ستستغرق المهمة من دقيقتين إلى 3 دقائق للتشغيل. قد يستغرق الأمر وقتا أطول (حتى 10 دقائق) إذا تم تقليص مجموعة الحوسبة إلى صفر عقد ولا تزال البيئة المخصصة قيد الإنشاء.
نشر النموذج كنقطة نهاية عبر الإنترنت
قم الآن بتوزيع نموذج التعلم الآلي الخاص بك كخدمة ويب في سحابة Azure، online endpoint.
لنشر خدمة التعلم الآلي، ستستخدم النموذج الذي سجلته.
إنشاء نقطة نهاية جديدة عبر الإنترنت
الآن بعد أن أصبح لديك نموذج مسجل، حان الوقت لإنشاء نقطة النهاية عبر الإنترنت. يجب أن يكون اسم نقطة النهاية فريداً في منطقة Azure بأكملها. في هذا البرنامج التعليمي، ستقوم بإنشاء اسم فريد باستخدام UUID.
import uuid
# Creating a unique name for the endpoint
online_endpoint_name = "credit-endpoint-" + str(uuid.uuid4())[:8]
أنشئ نقطة النهاية:
# Expect the endpoint creation to take a few minutes
from azure.ai.ml.entities import (
ManagedOnlineEndpoint,
ManagedOnlineDeployment,
Model,
Environment,
)
# create an online endpoint
endpoint = ManagedOnlineEndpoint(
name=online_endpoint_name,
description="this is an online endpoint",
auth_mode="key",
tags={
"training_dataset": "credit_defaults",
"model_type": "sklearn.GradientBoostingClassifier",
},
)
endpoint = ml_client.online_endpoints.begin_create_or_update(endpoint).result()
print(f"Endpoint {endpoint.name} provisioning state: {endpoint.provisioning_state}")
إشعار
توقع أن يستغرق إنشاء نقطة النهاية بضع دقائق.
بمجرد إنشاء نقطة النهاية، يمكنك استردادها كما يلي:
endpoint = ml_client.online_endpoints.get(name=online_endpoint_name)
print(
f'Endpoint "{endpoint.name}" with provisioning state "{endpoint.provisioning_state}" is retrieved'
)
نشر النموذج إلى نقطة النهاية
بمجرد إنشاء نقطة النهاية، انشر النموذج باستخدام البرنامج النصي للإدخال. يمكن أن يكون لكل نقطة نهاية عمليات نشر متعددة. يمكن تحديد نسبة استخدام الشبكة المباشرة إلى عمليات النشر هذه باستخدام القواعد. هنا ستنشئ عملية نشر واحدة تتعامل مع 100% من حركة مرور البيانات الواردة. لقد اخترنا اسماً لونياً للنشر، على سبيل المثال، عمليات النشر الأزرق، الأخضر، الأحمر، وهي عشوائية.
يمكنك التحقق من صفحة Models على Azure التعلم الآلي studio، لتحديد أحدث إصدار من النموذج المسجل. بدلاً من ذلك، سوف تسترد التعليمة البرمجية أدناه أحدث رقم إصدار لتستخدمه.
# Let's pick the latest version of the model
latest_model_version = max(
[int(m.version) for m in ml_client.models.list(name=registered_model_name)]
)
print(f'Latest model is version "{latest_model_version}" ')
انشر أحدث إصدار من النموذج.
# picking the model to deploy. Here we use the latest version of our registered model
model = ml_client.models.get(name=registered_model_name, version=latest_model_version)
# Expect this deployment to take approximately 6 to 8 minutes.
# create an online deployment.
# if you run into an out of quota error, change the instance_type to a comparable VM that is available.
# Learn more on https://azure.microsoft.com/pricing/details/machine-learning/.
blue_deployment = ManagedOnlineDeployment(
name="blue",
endpoint_name=online_endpoint_name,
model=model,
instance_type="Standard_DS3_v2",
instance_count=1,
)
blue_deployment = ml_client.begin_create_or_update(blue_deployment).result()
إشعار
توقع أن يستغرق هذا النشر حوالي 6 إلى 8 دقائق.
عند الانتهاء من النشر، تكون جاهزا لاختباره.
اختبار مع نموذج الاستعلام
بمجرد نشر النموذج إلى نقطة النهاية، يمكنك تشغيل الاستدلال معه.
قم بإنشاء ملف طلب عينة باتباع التصميم المتوقع في طريقة التشغيل في البرنامج النصي للدرجات.
deploy_dir = "./deploy"
os.makedirs(deploy_dir, exist_ok=True)
%%writefile {deploy_dir}/sample-request.json
{
"input_data": {
"columns": [0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22],
"index": [0, 1],
"data": [
[20000,2,2,1,24,2,2,-1,-1,-2,-2,3913,3102,689,0,0,0,0,689,0,0,0,0],
[10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 10, 9, 8]
]
}
}
# test the blue deployment with some sample data
ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
request_file="./deploy/sample-request.json",
deployment_name="blue",
)
تنظيف الموارد
إذا كنت لن تستخدم نقطة النهاية، فاحذفها للتوقف عن استخدام المورد. تأكد من عدم وجود عمليات نشر أخرى تستخدم نقطة نهاية قبل حذفها.
إشعار
توقع أن يستغرق الحذف الكامل حوالي 20 دقيقة.
ml_client.online_endpoints.begin_delete(name=online_endpoint_name)
إيقاف حساب مثيل
إذا كنت لن تستخدمه الآن، فأوقف مثيل الحساب:
- في الاستوديو، في منطقة التنقل اليسرى، حدد Compute.
- في علامات التبويب العليا، حدد "Compute instances"
- حدد "compute instance" في القائمة.
- في شريط الأدوات العلوي، حدد "Stop".
حذف كافة الموارد
هام
يمكن استخدام الموارد التي قمت بإنشائها كمتطلبات أساسية لبرامج تعليمية أخرى في Azure ومقالات إرشادية.
إذا كنت لا تخطط لاستخدام الموارد التي أنشأتها، فاحذفها، حتى لا تتحمل أي رسوم:
من مدخل Microsoft Azure، حدد Resource groups من أقصى الجانب الأيمن.
من القائمة، حدد مجموعة الموارد التي أنشأتها.
حدد Delete resource group.
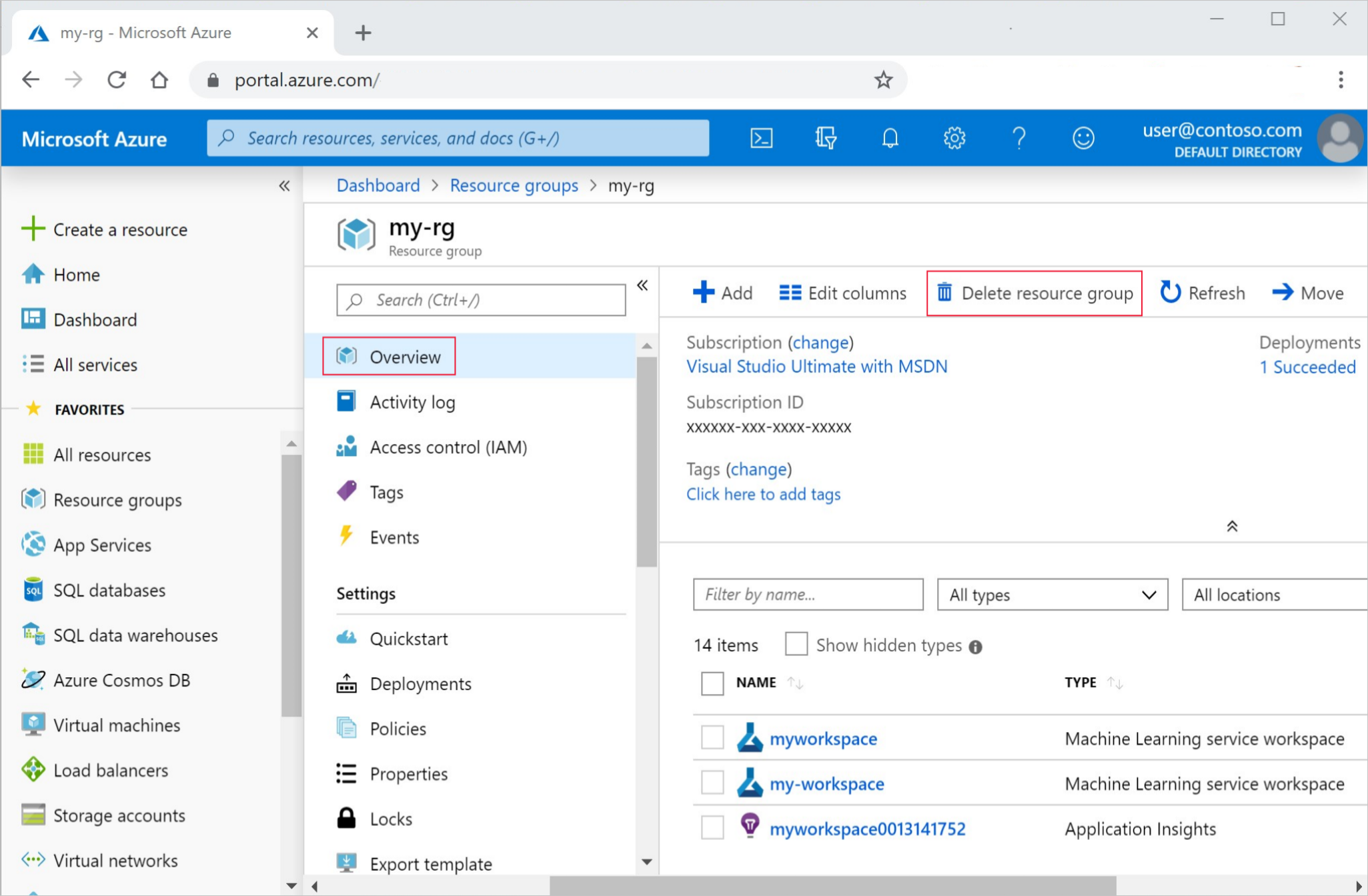
أدخل اسم مجموعة الموارد. ثم حدد حذف.
الخطوات التالية
الآن بعد أن أصبحت لديك فكرة عما ينطوي عليه تدريب النموذج ونشره، تعرف على المزيد حول العملية في هذه البرامج التعليمية:
| برنامج تعليمي | الوصف |
|---|---|
| تحميل بياناتك والوصول إليها واستكشافها في Azure التعلم الآلي | تخزين البيانات الكبيرة في السحابة واستردادها من دفاتر الملاحظات والبرامج النصية |
| تطوير النموذج على محطة عمل سحابية | بدء النماذج الأولية وتطوير نماذج التعلم الآلي |
| تدريب نموذج في Azure التعلم الآلي | التعمق في تفاصيل تدريب نموذج |
| نشر نموذج كنقطة نهاية عبر الإنترنت | التعمق في تفاصيل نشر نموذج |
| إنشاء مسارات التعلم الآلي للإنتاج | تقسيم مهمة تعلم آلي كاملة إلى سير عمل متعدد الخطوات. |