المفهرسات في Azure الذكاء الاصطناعي Search
المفهرس في Azure الذكاء الاصطناعي Search هو متتبع ارتباطات يستخرج البيانات النصية من مصادر بيانات السحابة ويملأ فهرس بحث باستخدام تعيينات من حقل إلى حقل بين بيانات المصدر وفهرس البحث. يشار إلى هذا الأسلوب أحيانا باسم "نموذج السحب" لأن خدمة البحث تسحب البيانات دون الحاجة إلى كتابة أي تعليمة برمجية تضيف البيانات إلى فهرس.
تدفع المفهرسات أيضا تنفيذ مجموعة المهارات والإثراء الذكاء الاصطناعي، حيث يمكنك تكوين المهارات لدمج المعالجة الإضافية للمحتوى في الطريق إلى فهرس. بعض الأمثلة هي التعرف البصري على الحروف على ملفات الصور، ومهارة تقسيم النص لتقسيم البيانات، والترجمة النصية للغات متعددة.
تستهدف المفهرسات مصادر البيانات المدعومة. يحدد تكوين المفهرس مصدر بيانات (أصل) وفهرس بحث (وجهة). تحتوي العديد من المصادر، مثل Azure Blob Storage، على المزيد من خصائص التكوين الخاصة بنوع المحتوى هذا.
يمكنك تشغيل المفهرسات عند الطلب أو على جدول تحديث بيانات متكرر يتم تشغيله كل خمس دقائق. تتطلب التحديثات الأكثر تكرارا "نموذج دفع" يقوم بتحديث البيانات في وقت واحد في كل من Azure الذكاء الاصطناعي Search ومصدر البيانات الخارجي.
تقوم خدمة البحث بتشغيل مهمة مفهرس واحدة لكل وحدة بحث. إذا كنت بحاجة إلى معالجة متزامنة، فتأكد من أن لديك نسخا متماثلة كافية. لا تعمل المفهرسات في الخلفية، لذلك قد تكتشف تقييد استعلام أكثر من المعتاد إذا كانت الخدمة تحت الضغط.
سيناريوهات المفهرس وحالات الاستخدام
يمكنك استخدام المفهرس كوسيلة وحيدة لاستيعاب البيانات، أو بالاشتراك مع تقنيات أخرى. يلخص الجدول التالي السيناريوهات الرئيسية.
| السيناريو | الاستراتيجية |
|---|---|
| مصدر بيانات واحد | هذا النمط هو أبسط: مصدر بيانات واحد هو موفر المحتوى الوحيد لفهرس البحث. توفر معظم مصادر البيانات المدعومة شكلا من أشكال الكشف عن التغيير بحيث تلتقط عمليات تشغيل المفهرس اللاحقة الفرق عند إضافة المحتوى أو تحديثه في المصدر. |
| مصادر بيانات متعددة | يمكن أن تحتوي مواصفات المفهرس على مصدر بيانات واحد فقط، ولكن يمكن أن يقبل فهرس البحث نفسه المحتوى من مصادر متعددة، حيث يجلب كل تشغيل مفهرس محتوى جديدا من موفر بيانات مختلف. يمكن لكل مصدر المساهمة بحصته من المستندات الكاملة، أو ملء الحقول المحددة في كل مستند. لإلقاء نظرة فاحصة على هذا السيناريو، راجع البرنامج التعليمي: الفهرس من مصادر بيانات متعددة. |
| مفهرسات متعددة | عادة ما يتم إقران مصادر بيانات متعددة مع مفهرسات متعددة إذا كنت بحاجة إلى تغيير معلمات وقت التشغيل أو الجدول الزمني أو تعيينات الحقول. يعد توسيع نطاق Azure الذكاء الاصطناعي Search عبر المناطق سيناريو آخر. قد يكون لديك نسخ من فهرس البحث نفسه في مناطق مختلفة. لمزامنة محتوى فهرس البحث، قد يكون لديك مفهرسات متعددة تسحب من نفس مصدر البيانات، حيث يستهدف كل مفهرس فهرس بحث مختلف في كل منطقة. تتطلب الفهرسة المتوازية لمجموعات البيانات الكبيرة جدا أيضا استراتيجية متعددة المفهرسات، حيث يستهدف كل مفهرس مجموعة فرعية من البيانات. |
| تحويل المحتوى | يدفع المفهرسون تنفيذ مجموعة المهارات والإثراء الذكاء الاصطناعي. يتم تعريف تحويلات المحتوى في مجموعة المهارات التي تقوم بإرفاقها بالمفهرس. يمكنك استخدام المهارات لدمج تجميع البيانات والتح متجهاتها. |
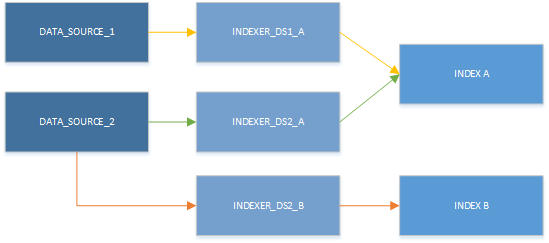
يجب أن تخطط لإنشاء مفهرس واحد لكل فهرس مستهدف ومجموعة مصادر البيانات. يمكن أن يكون لديك مفهرسات متعددة تكتب في نفس الفهرس، ويمكنك إعادة استخدام نفس مصدر البيانات لمفهرسات متعددة. ومع ذلك، يمكن للمفهرس استهلاك مصدر بيانات واحد فقط في كل مرة، ويمكنه الكتابة إلى فهرس واحد فقط. كما يوضح الرسم التالي، يوفر مصدر بيانات واحد إدخالا إلى مفهرس واحد، والذي يقوم بعد ذلك بتعبئة فهرس واحد:

على الرغم من أنه يمكنك استخدام مفهرس واحد فقط في كل مرة، يمكن استخدام الموارد في مجموعات مختلفة. تتمثل الميزة الرئيسية للتوضيح التالي في ملاحظة أنه يمكن إقران مصدر البيانات بأكثر من مفهرس واحد، ويمكن للعديد من المفهرسات الكتابة إلى نفس الفهرس.
مصادر البيانات المدعومة
تقوم المفهرسات بتتبع ارتباطات مخازن البيانات على Azure وخارج Azure.
- مخزن البيانات الثنائية كبيرة الحجم لـ Azure
- Azure Cosmos DB
- Azure Data Lake Storage Gen2
- قاعدة بيانات Azure SQL
- مساحة تخزين Azure Table
- مثيل Azure SQL المدار
- SQL Server على أجهزة Azure الظاهرية
- ملفات Azure (في المعاينة)
- Azure MySQL (في المعاينة)
- SharePoint في Microsoft 365 (في المعاينة)
- Azure Cosmos DB ل MongoDB (في المعاينة)
- Azure Cosmos DB ل Apache Gremlin (في المعاينة)
Azure Cosmos DB ل Cassandra غير مدعوم.
تقبل المفهرسات مجموعات الصفوف المسطحة، مثل جدول أو طريقة عرض، أو عناصر في حاوية أو مجلد. في معظم الحالات، يقوم بإنشاء مستند بحث واحد لكل صف أو سجل أو عنصر.
يمكن إجراء اتصالات المفهرس بمصادر البيانات البعيدة باستخدام اتصالات الإنترنت القياسية (العامة) أو الاتصالات الخاصة المشفرة عند استخدام ارتباط خاص مشترك. يمكنك أيضا إعداد الاتصالات للمصادقة باستخدام هوية مدارة. لمزيد من المعلومات حول الاتصالات الآمنة، راجع وصول المفهرس إلى المحتوى المحمي بواسطة ميزات أمان شبكة Azure الاتصال إلى مصدر بيانات باستخدام هوية مدارة.
مراحل الفهرسة
عند التشغيل الأولي، عندما يكون الفهرس فارغا، سيقوم المفهرس بقراءة جميع البيانات المتوفرة في الجدول أو الحاوية. في عمليات التشغيل اللاحقة، يمكن للمفهرس عادة الكشف عن البيانات التي تم تغييرها واستردادها فقط. بالنسبة إلى بيانات الكائن الثنائي كبير الحجم، يكون الكشف عن التغيير تلقائيا. بالنسبة لمصادر البيانات الأخرى مثل Azure SQL أو Azure Cosmos DB، يجب تمكين الكشف عن التغيير.
لكل مستند يتلقاه، يقوم المفهرس بتنفيذ خطوات متعددة أو تنسيقها، بدءا من استرداد المستند إلى "التسليم" لمحرك البحث النهائي للفهرسة. اختياريا، يدفع المفهرس أيضا تنفيذ مجموعة المهارات والمخرجات، على افتراض تحديد مجموعة المهارات.

المرحلة 1: تكسير المستند
تكسير المستند هو عملية فتح الملفات واستخراج المحتوى. يمكن استخراج المحتوى المستند إلى النص من ملفات على خدمة أو صفوف في جدول أو عناصر في حاوية أو مجموعة. إذا أضفت مجموعة مهارات ومهارات الصور، يمكن أن يؤدي تكسير المستندات أيضا إلى استخراج الصور ووضعها في قائمة الانتظار لمعالجة الصور.
اعتمادا على مصدر البيانات، سيحاول المفهرس عمليات مختلفة لاستخراج محتوى يمكن فهرسته:
عندما يكون المستند ملفا يحتوي على صور مضمنة، مثل ملف PDF، يقوم المفهرس باستخراج النص والصور وبيانات التعريف. يمكن للمفهرسات فتح الملفات من Azure Blob Storage وAzure Data Lake Storage Gen2 وSharePoint.
عندما يكون المستند سجلا في Azure SQL، سيقوم المفهرس باستخراج محتوى غير ثنائي من كل حقل في كل سجل.
عندما يكون المستند سجلا في Azure Cosmos DB، سيقوم المفهرس باستخراج محتوى غير ثنائي من الحقول والحقول الفرعية من مستند Azure Cosmos DB.
المرحلة 2: تعيينات الحقول
يستخرج المفهرس نصا من حقل مصدر ويرسله إلى حقل وجهة في فهرس أو مخزن معارف. عندما تتزامن أسماء الحقول وأنواع البيانات، يكون المسار واضحا. ومع ذلك، قد تحتاج إلى أسماء أو أنواع مختلفة في الإخراج، وفي هذه الحالة تحتاج إلى إخبار المفهرس بكيفية تعيين الحقل.
لتحديد تعيينات الحقول، أدخل الحقلين المصدر والوجهة في تعريف المفهرس.
يحدث تعيين الحقل بعد تكسير المستند، ولكن قبل التحويلات، عندما يقرأ المفهرس من المستندات المصدر. عند تعريف تعيين حقل، يتم إرسال قيمة الحقل المصدر كما هي إلى حقل الوجهة بدون تعديلات.
المرحلة 3: تنفيذ مجموعة المهارات
يعد تنفيذ مجموعة المهارات خطوة اختيارية تستدعي معالجة الذكاء الاصطناعي المضمنة أو المخصصة. يمكن أن تضيف مجموعات المهارات التعرف البصري على الأحرف (OCR) أو أشكالا أخرى من تحليل الصور إذا كان المحتوى ثنائيا. يمكن أن تضيف مجموعات المهارات أيضا معالجة اللغة الطبيعية. على سبيل المثال، يمكنك إضافة ترجمة نصية أو استخراج العبارة الرئيسية.
مهما كان التحول، فإن تنفيذ مجموعة المهارات هو المكان الذي يحدث فيه الإثراء. إذا كان المفهرس عبارة عن مسار، يمكنك التفكير في مجموعة المهارات على أنها "مسار داخل البنية الأساسية لبرنامج ربط العمليات التجارية".
المرحلة 4: تعيينات حقل الإخراج
إذا قمت بتضمين مجموعة مهارات، فستحتاج إلى تحديد تعيينات حقل الإخراج في تعريف المفهرس. يظهر ناتج مجموعة المهارات داخليا كبنية شجرة يشار إليها باسم مستند غني. تسمح لك تعيينات حقول الإخراج بتحديد أجزاء هذه الشجرة المراد تعيينها إلى حقول في الفهرس.
على الرغم من التشابه في الأسماء، تقوم تعيينات حقول الإخراج وتعيينات الحقول بإنشاء اقترانات من مصادر مختلفة. تربط تعيينات الحقول محتوى الحقل المصدر بالحقل الوجهة في فهرس بحث. تقوم تعيينات حقول الإخراج بربط محتوى مستند تم إثرائه داخليا (مخرجات المهارة) بالحقول الوجهة في الفهرس. على عكس تعيينات الحقول، التي تعتبر اختيارية، يلزم تعيين حقل إخراج لأي محتوى تم تحويله يجب أن يكون في الفهرس.
تعرض الصورة التالية نموذج تمثيل جلسة تصحيح أخطاء المفهرس لمراحل المفهرس: تكسير المستندات وتعيينات الحقول وتنفيذ مجموعة المهارات وتعيينات حقول الإخراج.

سير العمل الأساسي
يمكن للمفهرسات تقديم ميزات فريدة لمصدر البيانات. في هذا الصدد، ستختلف بعض جوانب تكوين المفهرس أو مصدر البيانات حسب نوع المفهرس. ومع ذلك، تشترك جميع المفهرسات في نفس التكوين والمتطلبات الأساسية. يتم تناول الخطوات الشائعة لجميع المفهرسات أدناه.
الخطوة 1: إنشاء مصدر بيانات
تتطلب المفهرسات كائن مصدر بيانات يوفر سلسلة الاتصال وربما بيانات اعتماد. مصادر البيانات هي كائنات مستقلة. يمكن لمفهرسات متعددة استخدام نفس كائن مصدر البيانات لتحميل أكثر من فهرس واحد في كل مرة.
يمكنك إنشاء مصدر بيانات باستخدام أي من هذه الأساليب:
- باستخدام مدخل Microsoft Azure، في علامة التبويب مصادر البيانات لصفحات خدمة البحث، حدد إضافة مصدر بيانات لتحديد تعريف مصدر البيانات.
- باستخدام مدخل Microsoft Azure، يقوم معالج استيراد البيانات إخراج مصدر بيانات.
- باستخدام واجهات برمجة تطبيقات REST، اتصل بإنشاء مصدر بيانات.
- باستخدام Azure SDK ل .NET، اتصل بفئة SearchIndexerDataSource الاتصال ion
الخطوة 2: إنشاء فهرس
سيقوم المفهرس بأتمتة بعض المهام المتعلقة ب استيعاب البيانات، ولكن إنشاء فهرس ليس واحدا منها بشكل عام. كشرط أساسي، يجب أن يكون لديك فهرس معرف مسبقا يحتوي على حقول هدف مقابلة لأي حقول مصدر في مصدر البيانات الخارجي. يجب أن تتطابق الحقول حسب الاسم ونوع البيانات. إذا لم يكن الأمر كما هو، يمكنك تعريف تعيينات الحقول لإنشاء الاقتران.
لمزيد من المعلومات، راجع إنشاء فهرس.
الخطوة 3: إنشاء المفهرس وتشغيله (أو جدولته)
يتكون تعريف المفهرس من خصائص تحدد المفهرس بشكل فريد، وتحدد مصدر البيانات والفهرس الذي يجب استخدامه، وتوفر خيارات تكوين أخرى تؤثر على سلوكيات وقت التشغيل، بما في ذلك ما إذا كان المفهرس يعمل عند الطلب أو على جدول زمني.
ستحدث أي أخطاء أو تحذيرات حول الوصول إلى البيانات أو التحقق من صحة مجموعة المهارات أثناء تنفيذ المفهرس. حتى يبدأ تنفيذ المفهرس، تكون الكائنات التابعة مثل مصادر البيانات والفهارس ومجموعات المهارات سلبية على خدمة البحث.
لمزيد من المعلومات، راجع إنشاء مفهرس
بعد تشغيل المفهرس الأول، يمكنك إعادة تشغيله عند الطلب أو إعداد جدول زمني.
يمكنك مراقبة حالة المفهرس في المدخل أو من خلال Get Indexer Status API. يجب عليك أيضا تشغيل الاستعلامات على الفهرس للتحقق من أن النتيجة هي ما كنت تتوقعه.
لا تحتوي المفهرسات على موارد معالجة مخصصة. بناء على ذلك، قد تظهر حالة المفهرسات ك الخاملة قبل التشغيل (اعتمادا على المهام الأخرى في قائمة الانتظار) وقد لا تكون أوقات التشغيل متوقعة. تعرف عوامل أخرى أداء المفهرس أيضا، مثل حجم المستند وتعقيد المستند وتحليل الصور وغيرها.
الخطوات التالية
الآن بعد أن تعرفت على المفهرسات، فإن الخطوة التالية هي مراجعة خصائص المفهرس والمعلمات والجدولة ومراقبة المفهرس. بدلا من ذلك، يمكنك العودة إلى قائمة مصادر البيانات المدعومة للحصول على مزيد من المعلومات حول مصدر معين.
الملاحظات
قريبًا: خلال عام 2024، سنتخلص تدريجيًا من GitHub Issues بوصفها آلية إرسال ملاحظات للمحتوى ونستبدلها بنظام ملاحظات جديد. لمزيد من المعلومات، راجع https://aka.ms/ContentUserFeedback.
إرسال الملاحظات وعرضها المتعلقة بـ