مفاهيم مجموعة المهارات في Azure الذكاء الاصطناعي Search
هذه المقالة مخصصة للمطورين الذين يحتاجون إلى فهم أعمق لمفاهيم مجموعة المهارات وتكوينها، وتفترض الإلمام بالمفاهيم عالية المستوى الذكاء الاصطناعي المطبقة في Azure الذكاء الاصطناعي Search.
مجموعة المهارات هي كائن قابل لإعادة الاستخدام في Azure الذكاء الاصطناعي Search المرفق بمفهرس. يحتوي على واحد أو أكثر من المهارات التي تستدعي الذكاء الاصطناعي المضمنة أو المعالجة المخصصة الخارجية عبر المستندات التي تم استردادها من مصدر بيانات خارجي.
يوضح الرسم التخطيطي التالي تدفق البيانات الأساسي لتنفيذ مجموعة المهارات.
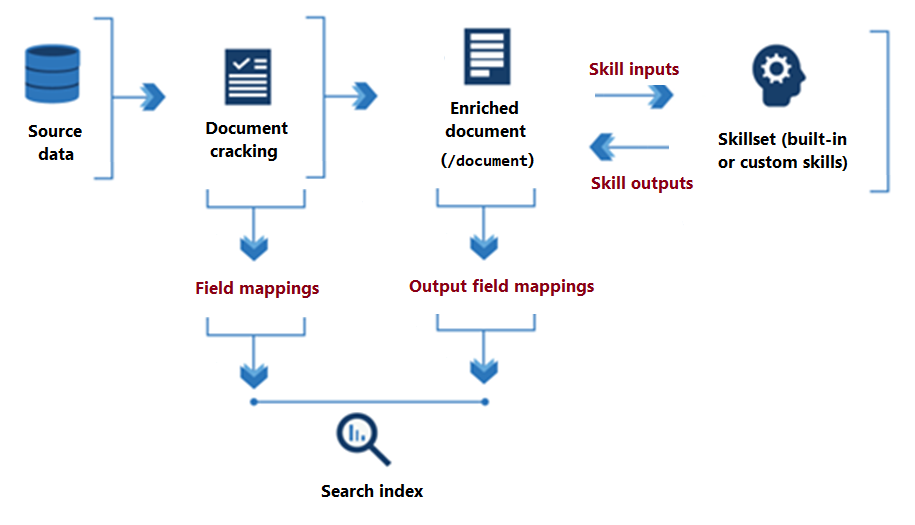
منذ بداية معالجة مجموعة المهارات إلى نهايتها، تقرأ المهارات وتكتب في وثيقة غنية موجودة في الذاكرة. في البداية، المستند الذي تم إثرائه هو المحتوى الخام المستخرج من مصدر بيانات (تم توضيحه كعقدة "/document" الجذر). مع كل تنفيذ مهارة، يكتسب المستند الذي تم إثراؤه البنية والمادة حيث تكتب كل مهارة ناتجها كعقد في الرسم البياني.
بعد تنفيذ مجموعة المهارات، يجد إخراج مستند تم إثراؤه طريقه إلى فهرس من خلال تعيينات حقل الإخراج المعرفة من قبل المستخدم. يتم تعريف أي محتوى أولي تريد نقله سليما، من المصدر إلى الفهرس، من خلال تعيينات الحقول.
لتكوين الذكاء الاصطناعي المطبقة، حدد الإعدادات في مجموعة المهارات والمفهرس.
تعريف مجموعة المهارات
مجموعة المهارات هي مجموعة من مهارات واحدة أو أكثر تقوم بإجراء إثراء، مثل ترجمة النص أو التعرف البصري على الحروف (OCR) على ملف صورة. يمكن أن تكون المهارات هي المهارات المضمنة من Microsoft، أو مهارات مخصصة لمنطق المعالجة الذي تستضيفه خارجيا. تنتج مجموعة المهارات مستندات ثرية إما يتم استهلاكها أثناء الفهرسة أو العرض على مخزن المعرفة.
المهارات لها سياق ومدخلات ومخرجات:
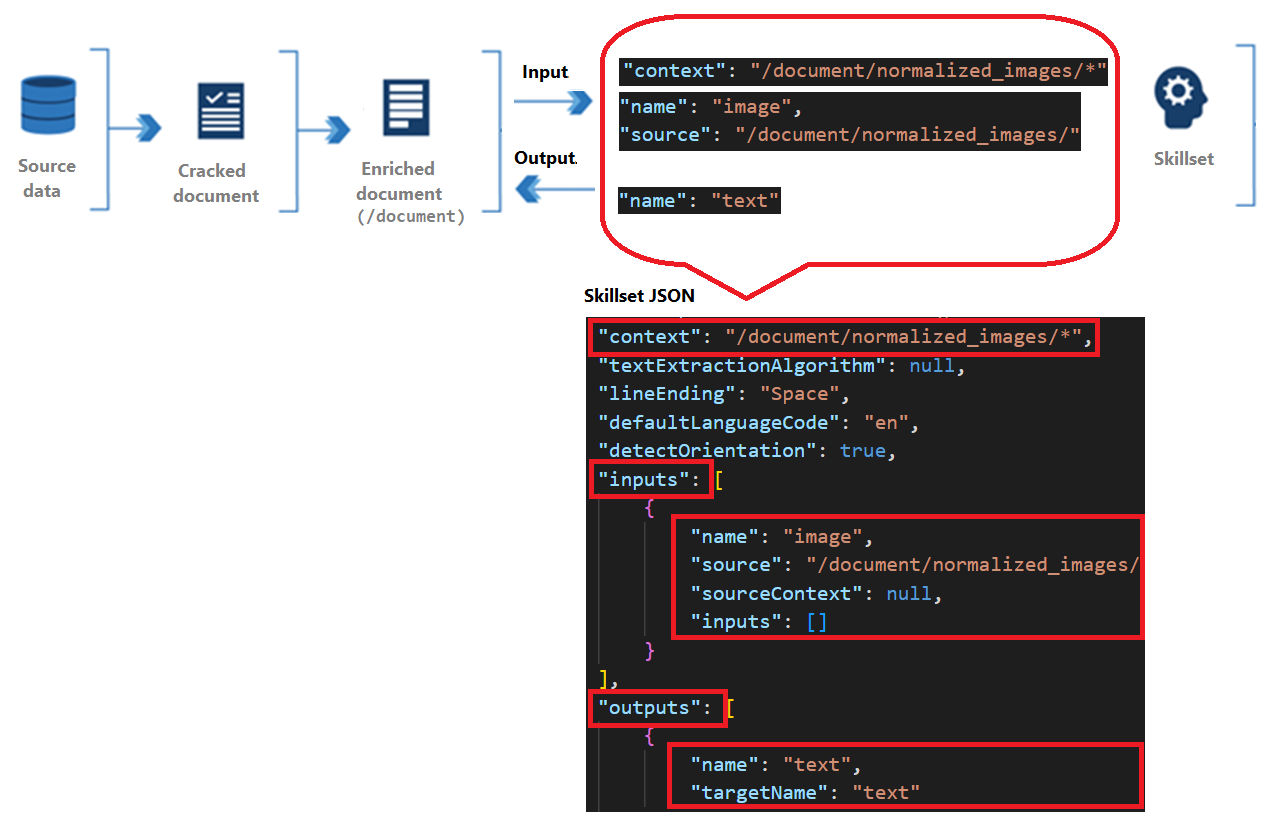
يشير السياق إلى نطاق العملية، والتي يمكن أن تكون مرة واحدة لكل مستند أو مرة واحدة لكل عنصر في مجموعة.
تنشأ المدخلات من العقد في مستند تم إثراؤه، حيث يحدد "المصدر" و"الاسم" عقدة معينة.
يتم إرسال الإخراج مرة أخرى إلى المستند الذي تم إثرائه كعقدة جديدة. القيم هي العقدة "name" ومحتوى العقدة. إذا تم تكرار اسم عقدة، يمكنك تعيين اسم هدف لفك الغموض.
سياق المهارة
كل مهارة لها سياق، والذي يمكن أن يكون المستند بأكمله (/document) أو عقدة أقل في الشجرة (/document/countries/*).
يحدد السياق ما يلي:
عدد مرات تنفيذ المهارة، أو أكثر من قيمة واحدة (مرة واحدة لكل حقل، لكل مستند)، أو لمجموعة، حيث تؤدي إضافة إلى
/*استدعاء المهارة لكل مثيل في المجموعة.إعلان الإخراج، أو حيث تتم إضافة مخرجات المهارة في شجرة الإثراء. تتم دائما إضافة المخرجات إلى الشجرة كتوابع لعقدة السياق.
شكل المدخلات. بالنسبة للمجموعات متعددة المستويات، يؤثر تعيين السياق إلى المجموعة الأصل على شكل إدخال المهارة. على سبيل المثال، إذا كان لديك شجرة إثراء مع قائمة بالبلدان/المناطق، كل منها تم إثراؤه بقائمة من الحالات التي تحتوي على قائمة بالرموز البريدية، فإن كيفية تعيين السياق تحدد كيفية تفسير الإدخال.
السياق إدخال شكل الإدخال استدعاء المهارة /document/countries/*/document/countries/*/states/*/zipcodes/*قائمة بجميع الرموز البريدية في البلد/المنطقة مرة واحدة لكل بلد/منطقة /document/countries/*/states/*/document/countries/*/states/*/zipcodes/*قائمة بالرموز البريدية في الحالة مرة واحدة لكل مجموعة من البلد/المنطقة والدولة
تبعيات المهارات
يمكن تنفيذ المهارات بشكل مستقل وبالتوازي، أو بالتتابع إذا قمت بتغذية مخرجات مهارة واحدة في مهارة أخرى. يوضح المثال التالي مهرتين مضمنتين تنفذان بالتسلسل:
المهارة رقم 1 هي مهارة تقسيم النص التي تقبل محتويات حقل المصدر "reviews_text" كمدخل، وتقسيم هذا المحتوى إلى "صفحات" مكونة من 5000 حرف كإخراج. يمكن أن يؤدي تقسيم النص الكبير إلى أجزاء أصغر إلى نتائج أفضل لمهارات مثل الكشف عن المشاعر.
المهارة رقم 2 هي مهارة الكشف عن المشاعر تقبل "الصفحات" كمدخل، وتنتج حقلا جديدا يسمى "التوجه" كإخراج يحتوي على نتائج تحليل المشاعر.
لاحظ كيف يتم استخدام إخراج المهارة الأولى ("الصفحات") في تحليل المشاعر، حيث "/document/reviews_text/pages/*" هو كل من السياق والإدخل. لمزيد من المعلومات حول صياغة المسار، راجع كيفية الرجوع إلى عمليات الإثراء.
{
"skills": [
{
"@odata.type": "#Microsoft.Skills.Text.SplitSkill",
"name": "#1",
"description": null,
"context": "/document/reviews_text",
"defaultLanguageCode": "en",
"textSplitMode": "pages",
"maximumPageLength": 5000,
"inputs": [
{
"name": "text",
"source": "/document/reviews_text"
}
],
"outputs": [
{
"name": "textItems",
"targetName": "pages"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.SentimentSkill",
"name": "#2",
"description": null,
"context": "/document/reviews_text/pages/*",
"defaultLanguageCode": "en",
"inputs": [
{
"name": "text",
"source": "/document/reviews_text/pages/*",
}
],
"outputs": [
{
"name": "sentiment",
"targetName": "sentiment"
},
{
"name": "confidenceScores",
"targetName": "confidenceScores"
},
{
"name": "sentences",
"targetName": "sentences"
}
]
}
. . .
]
}
شجرة الإثراء
المستند الذي تم إثرائه هو بنية بيانات مؤقتة تشبه الشجرة تم إنشاؤها أثناء تنفيذ مجموعة المهارات التي تجمع جميع التغييرات التي تم إدخالها من خلال المهارات. بشكل جماعي، يتم تمثيل عمليات الإثراء كتسلسل هرمي للعقد القابلة للعنوان. تتضمن العقد أيضا أي حقول غير مريشة يتم تمريرها حرفيا من مصدر البيانات الخارجي.
يوجد مستند تم إثرائه طوال مدة تنفيذ مجموعة المهارات، ولكن يمكن تخزينه مؤقتا أو إرساله إلى مخزن معارف.
في البداية، المستند الذي تم إثرائه هو ببساطة المحتوى المستخرج من مصدر بيانات أثناء تكسير المستند، حيث يتم استخراج النص والصور من المصدر وإتاحتها لتحليل اللغة أو الصورة.
المحتوى الأولي هو بيانات التعريف وعقدة الجذر (document/content). عادة ما تكون عقدة الجذر عبارة عن مستند كامل أو صورة تمت تسويتها يتم استخراجها من مصدر بيانات أثناء تكسير المستند. تختلف كيفية توضيحها في شجرة الإثراء لكل نوع مصدر بيانات. يوضح الجدول التالي حالة مستند يدخل في مسار الإثراء للعديد من مصادر البيانات المدعومة:
| مصدر البيانات\وضع التحليل | الإعداد الافتراضي | JSON وخطوط JSON وCSV |
|---|---|---|
| مخزن البيانات الثنائية الكبيرة | /مستند/محتوى /document/normalized_images/* … |
/document/{key1} /document/{key2} … |
| عنوان SQL لـ Azure | /document/{column1} /document/{column2} … |
غير متوفر |
| Azure Cosmos DB | /document/{key1} /document/{key2} … |
غير متوفر |
مع تنفيذ المهارات، تتم إضافة الإخراج إلى شجرة الإثراء كعقد جديدة. إذا كان تنفيذ المهارة عبر المستند بأكمله، تتم إضافة العقد في المستوى الأول ضمن الجذر.
يمكن استخدام العقد كمدخلات لمهارات انتقال البيانات من الخادم. على سبيل المثال، قد تصبح المهارات التي تنشئ محتوى، مثل السلاسل المترجمة، مدخلات للمهارات التي تتعرف على الكيانات أو تستخرج العبارات الرئيسية.
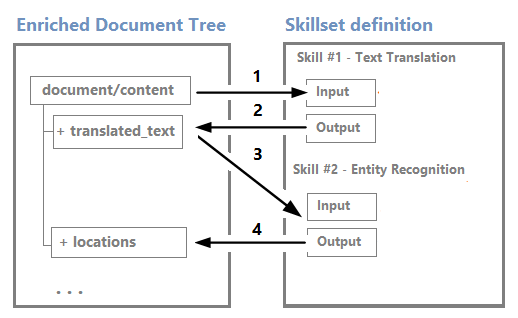
على الرغم من أنه يمكنك تصور شجرة الإثراء والعمل معها من خلال محرر مرئيات جلسات تتبع الأخطاء، إلا أنه في الغالب بنية داخلية.
عمليات الإثراء غير قابلة للتغيير: بمجرد إنشائها، لا يمكن تحرير العقد. نظرا لأن مجموعات المهارات الخاصة بك تصبح أكثر تعقيدا، فإن شجرة الإثراء الخاصة بك، ولكن ليس كل العقد في شجرة الإثراء تحتاج إلى الوصول إلى الفهرس أو مخزن المعرفة.
يمكنك الاستمرار بشكل انتقائي فقط في مجموعة فرعية من مخرجات الإثراء بحيث تحتفظ فقط بما تنوي استخدامه. تحدد تعيينات حقل الإخراج في تعريف المفهرس المحتوى الذي يتم استيعابه فعليا في فهرس البحث. وبالمثل، إذا كنت تقوم بإنشاء مخزن معارف، يمكنك تعيين المخرجات إلى أشكال تم تعيينها للإسقاطات.
إشعار
يتيح تنسيق شجرة الإثراء لمسار الإثراء إرفاق بيانات التعريف إلى أنواع البيانات الأولية حتى. لن تكون بيانات التعريف كائن JSON صالحا، ولكن يمكن عرضها بتنسيق JSON صالح في تعريفات الإسقاط في مخزن المعرفة. لمزيد من المعلومات، راجع مهارة Shaper.
تعريف المفهرس
يحتوي المفهرس على خصائص ومعلمات تستخدم لتكوين تنفيذ المفهرس. ومن بين هذه الخصائص التعيينات التي تعين مسار البيانات إلى الحقول في فهرس البحث.

هناك مجموعتان من التعيينات:
يقوم "fieldMappings" بتعيين حقل مصدر إلى حقل بحث.
يقوم "outputFieldMappings" بتعيين عقدة في مستند تم إثرائه إلى حقل بحث.
تحدد الخاصية "sourceFieldName" إما حقلا في مصدر البيانات أو عقدة في شجرة الإثراء. تحدد الخاصية "targetFieldName" حقل البحث في فهرس يتلقى المحتوى.
مثال الإثراء
باستخدام مجموعة مهارات الفندق يستعرض كنقطة مرجعية، يشرح هذا المثال كيفية تطور شجرة الإثراء من خلال تنفيذ المهارات باستخدام الرسومات التخطيطية المفاهيمية.
يوضح هذا المثال أيضا:
- كيفية عمل سياق المهارة ومدخلاتها لتحديد عدد المرات التي تنفذ فيها المهارة
- ما هو شكل الإدخال الذي يستند إلى السياق
في هذا المثال، تتضمن حقول المصدر من ملف CSV مراجعات العملاء حول الفنادق ("reviews_text") والتقييمات ("reviews_rating"). يضيف المفهرس حقول بيانات التعريف من تخزين Blob، وتضيف المهارات نصا مترجما ودرجات التوجه واكتشاف العبارة الرئيسية.
في مثال مراجعات الفندق، تمثل "وثيقة" ضمن عملية الإثراء مراجعة فندقية واحدة.
تلميح
يمكنك إنشاء فهرس بحث ومخزن معارف لهذه البيانات في مدخل Microsoft Azure أو واجهات برمجة تطبيقات REST. يمكنك أيضا استخدام جلسات تتبع الأخطاء للحصول على رؤى حول تكوين مجموعة المهارات والتبعيات والتأثيرات على شجرة الإثراء. يتم سحب الصور في هذه المقالة من جلسات تصحيح الأخطاء.
من الناحية المفاهيمية، تبدو شجرة الإثراء الأولية كما يلي:

العقدة الجذر لجميع عمليات الإثراء هي "/document". عند العمل مع مفهرسات الكائنات الثنائية كبيرة الحجم، تحتوي العقدة على "/document" عقد تابعة ل "/document/content" و "/document/normalized_images". عندما تكون البيانات CSV، كما في هذا المثال، تعين أسماء الأعمدة إلى العقد الموجودة أسفل "/document".
المهارة رقم 1: تقسيم المهارة
عندما يتكون محتوى المصدر من أجزاء كبيرة من النص، فمن المفيد تقسيمه إلى مكونات أصغر لمزيد من الدقة في اللغة والمشاعر واكتشاف العبارة الرئيسية. هناك حبتان متاحتان: الصفحات والجمل. تتكون الصفحة من حوالي 5000 حرف.
عادة ما تكون مهارة تقسيم النص أولا في مجموعة المهارات.
"@odata.type": "#Microsoft.Skills.Text.SplitSkill",
"name": "#1",
"description": null,
"context": "/document/reviews_text",
"defaultLanguageCode": "en",
"textSplitMode": "pages",
"maximumPageLength": 5000,
"inputs": [
{
"name": "text",
"source": "/document/reviews_text"
}
],
"outputs": [
{
"name": "textItems",
"targetName": "pages"
}
]
مع سياق "/document/reviews_text"مهارة ، يتم تنفيذ المهارة المنقسمة مرة واحدة ل reviews_text. إخراج المهارة هو قائمة حيث reviews_text يتم تقسيمها إلى 5000 مقطع من الأحرف. يتم تسمية pages الإخراج من المهارة المنقسمة وتتم إضافته إلى شجرة الإثراء. تسمح لك الميزة targetName بإعادة تسمية إخراج مهارة قبل إضافتها إلى شجرة الإثراء.
تحتوي شجرة الإثراء الآن على عقدة جديدة موضوعة ضمن سياق المهارة. تتوفر هذه العقدة لأي مهارة أو إسقاط أو تعيين حقل إخراج.

للوصول إلى أي من عمليات الإثراء المضافة إلى عقدة بواسطة مهارة، يلزم المسار الكامل للإثراء. على سبيل المثال، إذا كنت تريد استخدام النص من العقدة pages كمدخل لمهارة أخرى، فحدده ك "/document/reviews_text/pages/*". لمزيد من المعلومات حول المسارات، راجع الإثراء المرجعي.
اكتشاف اللغة للمهارة #2
تتضمن مستندات مراجعة الفنادق ملاحظات العملاء المعبر عنها بلغات متعددة. تحدد مهارة الكشف عن اللغة اللغة المستخدمة. ثم سيتم تمرير النتيجة إلى استخراج العبارة الرئيسية واكتشاف التوجه (غير معروض)، مع مراعاة اللغة عند اكتشاف المشاعر والعبارات.
في حين أن مهارة الكشف عن اللغة هي المهارة الثالثة (المهارة #3) المحددة في مجموعة المهارات، فإنها المهارة التالية التي يجب تنفيذها. لا يتطلب أي مدخلات لذلك ينفذ بالتوازي مع المهارة السابقة. مثل المهارة المنقسمة التي سبقتها، يتم أيضا استدعاء مهارة الكشف عن اللغة مرة واحدة لكل مستند. تحتوي شجرة الإثراء الآن على عقدة جديدة للغة.

المهارات رقم 3 و #4 (تحليل المشاعر واكتشاف العبارة الرئيسية)
تعكس ملاحظات العملاء مجموعة من التجارب الإيجابية والسلبية. تحلل مهارة تحليل التوجه التعليقات وتعين درجة على طول سلسلة متصلة من السلبية إلى الأرقام الإيجابية، أو محايدة إذا كان التوجه غير محدد. بالتوازي مع تحليل المشاعر، يحدد الكشف عن العبارة الرئيسية ويستخرج الكلمات والعبارات القصيرة التي تظهر تبعية.
نظرا إلى سياق ، يتم استدعاء كل من /document/reviews_text/pages/*تحليل المشاعر ومهارات العبارة الرئيسية مرة واحدة لكل عنصر من العناصر في pages المجموعة. سيكون الإخراج من المهارة عقدة ضمن عنصر الصفحة المقترنة.
يجب أن تكون الآن قادرا على النظر إلى بقية المهارات في مجموعة المهارات وتصور كيف تستمر شجرة الإثراء في النمو مع تنفيذ كل مهارة. بعض المهارات، مثل مهارة الدمج ومهارة shaper، تنشئ أيضا عقدا جديدة ولكن فقط تستخدم البيانات من العقد الموجودة ولا تنشئ إثراء جديدا صافيا.

تشير ألوان الموصلات في الشجرة أعلاه إلى أن عمليات الإثراء تم إنشاؤها بواسطة مهارات مختلفة ويجب معالجة العقد بشكل فردي ولن تكون جزءا من الكائن الذي تم إرجاعه عند تحديد العقدة الأصل.
مهارة #5 مهارة Shaper
إذا كان الإخراج يتضمن مخزن معارف، أضف مهارة Shaper كخطوة أخيرة. تنشئ مهارة Shaper أشكال بيانات خارج العقد في شجرة الإثراء. على سبيل المثال، قد تحتاج إلى دمج عقد متعددة في شكل واحد. يمكنك بعد ذلك عرض هذا الشكل كجدول (تصبح العقد الأعمدة في جدول)، وتمرير الشكل بالاسم إلى إسقاط جدول.
من السهل العمل مع مهارة Shaper لأنها تركز على التشكيل تحت مهارة واحدة. بدلا من ذلك، يمكنك اختيار التشكيل المضمن ضمن الإسقاطات الفردية. لا تضيف مهارة Shaper شجرة الإثراء أو ينتقص منها، لذلك لا يتم تصورها. بدلا من ذلك، يمكنك التفكير في مهارة Shaper على أنها الوسيلة التي يمكنك من خلالها إعادة ضبط شجرة الإثراء التي لديك بالفعل. من الناحية المفاهيمية، يشبه ذلك إنشاء طرق عرض خارج الجداول في قاعدة بيانات.
{
"@odata.type": "#Microsoft.Skills.Util.ShaperSkill",
"name": "#5",
"description": null,
"context": "/document",
"inputs": [
{
"name": "name",
"source": "/document/name"
},
{
"name": "reviews_date",
"source": "/document/reviews_date"
},
{
"name": "reviews_rating",
"source": "/document/reviews_rating"
},
{
"name": "reviews_text",
"source": "/document/reviews_text"
},
{
"name": "reviews_title",
"source": "/document/reviews_title"
},
{
"name": "AzureSearch_DocumentKey",
"source": "/document/AzureSearch_DocumentKey"
},
{
"name": "pages",
"sourceContext": "/document/reviews_text/pages/*",
"inputs": [
{
"name": "Sentiment",
"source": "/document/reviews_text/pages/*/Sentiment"
},
{
"name": "LanguageCode",
"source": "/document/Language"
},
{
"name": "Page",
"source": "/document/reviews_text/pages/*"
},
{
"name": "keyphrase",
"sourceContext": "/document/reviews_text/pages/*/Keyphrases/*",
"inputs": [
{
"name": "Keyphrases",
"source": "/document/reviews_text/pages/*/Keyphrases/*"
}
]
}
]
}
],
"outputs": [
{
"name": "output",
"targetName": "tableprojection"
}
]
}
الخطوات التالية
مع مقدمة ومثال خلفك، حاول إنشاء مجموعة المهارات الأولى باستخدام المهارات المضمنة.
الملاحظات
قريبًا: خلال عام 2024، سنتخلص تدريجيًا من GitHub Issues بوصفها آلية إرسال ملاحظات للمحتوى ونستبدلها بنظام ملاحظات جديد. لمزيد من المعلومات، راجع https://aka.ms/ContentUserFeedback.
إرسال الملاحظات وعرضها المتعلقة بـ